基于局部图互信息最大化的异构图神经网络方法①
2021-02-11朱志华范鑫鑫毕经平
朱志华 范鑫鑫 毕经平 武 超*
(*中国科学院大学 北京100049)
(**中国科学院计算技术研究所 北京100190)
(***中国电子科技集团公司电子科学研究院 北京100041)
0 引言
异构图(heterogeneous graph,HG)作为数据挖掘中一个新的发展方向[1],为研究者提供了一种融合多种异质信息的有效工具。同时,图表示学习[2]作为一种学习节点低维向量表征的便捷工具,为下游各种应用,如推荐[3]、检索[4]、用户去匿名化[5]等,提供有效的支持。相比于传统的异构图表示学习方法,异构图神经网络(heterogeneous graph neural network,HGNN)由于其强大的表达能力及有效结合节点属性特征与结构信息的特点,开始成为研究重点。然而,当前大部分的异构图神经网络都是半监督模式的,即需要充足的带标签的样本进行模型的训练。但是,在现实场景中,通常无法获得充足的带标签的数据,从而限制了这些算法的使用。
为了应对训练样本稀缺的问题,无监督的异构图神经网络引起了学者们的广泛研究兴趣。现有的无监督的异构图神经网络主要分为两类,即基于近邻的方法[6-7]和基于互信息的方法[8]。其中,基于近邻的方法仅可以保留有限范围(低价)的节点相似度,缺乏保留高价甚至是全局结构信息的机制。为了保留图的全局结构信息,深度图互信息最大化(deep graph infomax,DGI)[8]与深度异构图互信息最大化(heterogeneous deep graph infomax,HDGI)[9]等方法提供了一种同时考虑全局和局部图结构的新方向,即最大化节点局部表征与全局图表征之间的互信息,并获得了很好的效果。但是,全局图表征通常只能够对粗粒度的结构信息进行保留,无法表达节点局部结构中近邻的特征及其分布的信息,易导致节点表征发生过平滑(over-smoothing);同时,DGI与HDGI 中使用的图读出操作(readout)需要满足单射(injective)限制,但在实际情况下该限制过于严格。如果图读出操作不是单射的,则全局图表征中包含的输入图信息将随着图大小的增加而减少,从而导致节点局部表征质量下降。
针对该问题,Peng 等人[10]提出图互信息(graphical mutual information,GMI)的概念,通过比较由节点k阶近邻组成的子图与每个节点的表征向量直接获得互信息,实现对近邻的特征及其分布等细粒度信息的提取。然而,该概念仅针对同构图提出,无法直接应用到异构图当中。换句话说,GMI 无法适应异构图中异质性(heterogeneity)产生的各异节点分布与节点输入特征。此外,异构图中节点间通常存在不同语义的关系,并且这些关系之间表现出不同程度的兼容性。在没有先验知识的指导下,会使得模型更倾向于最大化某些特定关系上的图互信息,从而忽略其他可能存在的语义关系,即使得模型发生语义层面上的过拟合问题。
针对上述问题,本文提出了一种无监督的异构图神经网络方法,即基于局部异构图互信息最大化(heterogeneous graphical mutual infomax,HGMI)的方法。该方法首先利用元路径(meta-path)[1]对异构图中涉及的语义关系进行建模,然后利用图卷积模块和语义级别的注意力机制来融合不同的关系语义,并为每个节点生成有效的局部表征。该方法将图互信息应用到异构图中,通过最大化单个节点与局部子图间在拓扑以及输入特征上的互信息,来处理无监督的设置;同时通过在目标函数中共享语义级别的注意力权重,使得模型对所有语义关系均保持一定的关注度,以解决语义层面上可能发生的过拟合问题。本文的主要贡献如下:(1)提出了一种无监督的、基于局部图互信息的异构图神经网络模型;(2)提出了一种注意力平衡机制,用于防止语义层面过拟合的发生;(3)基于真实的异构图数据集进行了实验,相比基于全局图互信息的方法,可以将数据集DBLP/IMDB 上的节点分类任务的micro-F1提高大约3%/9%,同时将DBLP/IMDB 上的节点聚类任务的调整兰德系数(adjusted Rand index,ARI)提高约23%/46%。
本文剩余部分总结如下。第1 节介绍了异构图表示学习与异构图神经网络的相关工作。第2 节介绍了本文中使用的基本符号和相关问题定义,包括异构图与图互信息的定义。第3 节详细描述了本文提出的基于局部图互信息最大化的异构图神经网络模型HGMI。第4 节通过充分的实验对本研究中提出的方法进行了有效的验证。第5 节对全文内容进行了总结。
1 相关工作
现实世界中图结构具有普遍性,图表示学习已成为一个备受关注的主题[2]。作为包含丰富结构信息的数据类型,许多模型[11-12]基于图的结构学习节点的向量表征。DeepWalk[13]利用Skip-Gram,通过在图上进行一组随机游走来学习节点嵌入。此外,一些方法[14-15]则通过矩阵分解来提取结构信息。但是,以上所有方法只能用于同构图,无法解决异构图中的图表示学习问题。
为了处理图的异质性,metapath2vec[16]利用预先定义的元路径指导随机游走进行采样,并通过异构图中的Skip-Gram 学习节点的表征。HIN2Vec[17]则在执行预测任务的同时,学习节点和元路径的表征向量。Wang 等人[18]通过添加注意力机制,使得模型可以有效地学习来自多个、由元路径定义的同构图的信息。从属性图的角度进行考虑,SHNE[19]通过异构Skip-Gram 和深度语义编码的联合优化来捕获结构紧密性和非结构化语义关系。另外,许多面向知识图谱的方法[20-22]通常也可以应用于其他异构图。
随着深度学习的成功,图神经网络在图表示学习中取得了巨大的进展。图神经网络的核心思想是通过神经网络聚合邻居的特征信息,学习结合节点独立信息和图中相应结构信息的新的特征。大多数的图神经网络是基于半监督/监督学习的,包括图卷积网络(graph convolutional network,GCN)[23]、图注意力网络(graph attention network,GAT)[24]、GraphRNN[25]和SplineCNN[26]。而无监督的图神经网络主要分为基于随机游走的方法[27-28]和基于互信息的方法[8]。
与传统的图神经网络不同,异构图神经网络需要解决异构图中异质性带来的一系列问题,如不同类型、不同语义的节点与边。同样,大多数的异构图神经网络也是基于半监督/监督学习的,包括关系图卷积网络(relational graph convolutional network,RGCN)[20]和异构图注意力网络(heterogeneous graph attention network,HAN)[18]等。而无监督的异构图神经网络则主要分为基于近邻的方法和基于互信息的方法。
2 问题定义
2.1 异构图
一个异构图可以表示为节点与边的集合G=(V,E),该图具有一个节点类型映射函数φ:V→T和一个边类型映射函数ψ:E→R,并且满足| T| +| R| >2。另外,节点的属性和内容可以编码为初始特征矩阵X∈R|V | ×D。
异构图表示学习任务旨在学习包含G的结构信息和X的节点属性信息的低维节点表征H∈R|V | ×d。本文使用Vt表示目标类型的节点集合。为了简化问题设置,利用对称且无向的元路径来表示目标类型节点Vt之间的紧密度。形式上,路径被定义为节点vt1和vtn之间的元路径。进一步地,本文将使用的元路径集表示为Φ={Φ1,Φ2,…,ΦP},其中Φi表示第i个元路径类型。基于定义的元路径可以生成相应的邻接矩阵集合,其中,。
2.2 图互信息
形式上,节点vi的表征hi和其局部子图Gi=(Xi,Ai) 之间的图互信息可以表示为局部互信息(即节点与一个近邻间的互信息)的加权和[10]:
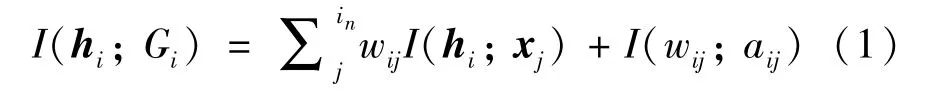

其中,in表示Xi中节点的数目,aij是邻接矩阵Ai中的边权重,wij表示局部互信息I(hi;xj) 对全局互信息I(hi;Gi) 的贡献。
相应地,在异构图中,给定邻接矩阵集合AΦ,异构图互信息可以表示为不同邻接矩阵中给定节点vi与其对应子图间互信息的和:
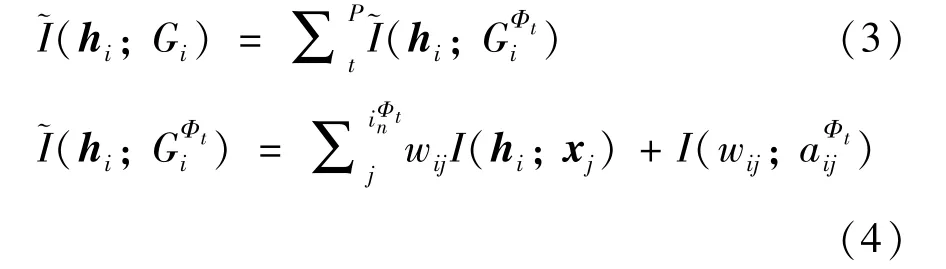
3 基于局部图互信息最大化的异构图神经网络模型
3.1 模型框架
基于局部图互信息最大化的异构图神经网络模型主要由2 个模块组成,即基于元路径的局部表征编码器与局部图互信息计算模块,整体框架如图1所示。
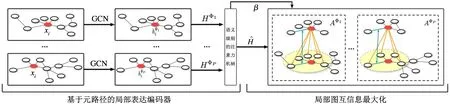
图1 HGMI 的模型框架
首先,给定由一组元路径定义的邻接矩阵,局部表征编码器将分别在每个邻接矩阵中利用图卷积模块生成目标类型节点的表征。然后,通过语义级别的注意力机制整合各个邻接矩阵中生成的节点表征。之后,局部图互信息计算模块将利用生成的节点表征与采样到的、各个邻接矩阵中的局部子图,计算相应的局部图互信息。最终,以最大化互信息作为目标函数,实现对模型参数的训练,并得到优化后的节点表征。
3.2 基于元路径的节点局部表征
在邻接矩阵集合AΦ中,每一个邻接矩阵表示一个同构图,因此,使用一个节点级的编码器生成包含初始节点特征X和AΦi信息的节点表征:

其中,fΦi(·) 表示节点级的编码器。为了能够获得更大的感受野,以获得更多参与运算的信息量,同时有效地整合节点熟悉特征与局部结构特征,选择图卷积网络(GCN)作为节点级编码器,来生成每个邻接矩阵中的节点表征:
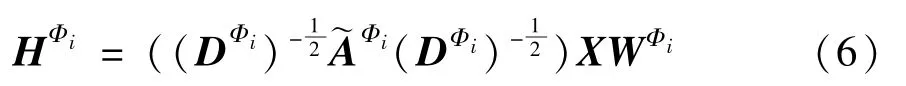
基于特定邻接矩阵学习的节点表征仅包含特定的语义信息。为了获得包含多种关系语义的节点表征,一种直观且有效的解决方案是探索每个元路径应为最终节点表征贡献多少,然后将各自的贡献作为权重聚合各个独立的节点表征。这里通过添加一个语义注意力层Latt来学习相应权重/贡献:
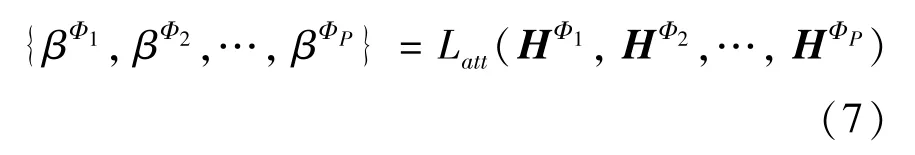
具体通过式(8)~式(10)来计算元路径Φi的重要性。

其中,Wsem表示线性变换参数矩阵,q表示需要学习的注意力语义向量。然后,利用softmax 函数对生成的集合进行正则化,以获得元路径Φi的重要性权重βΦi:

最终,异构图节点表示H将通过节点表征集合的线性组合获得:

虽然本文的语义注意力层是受到HAN[18]的启发,但在模型优化上仍存在着差异。HAN 利用分类交叉熵作为损失函数,学习方向将由训练集中标签样本指导。由于对标签样本的依赖,HAN 容易受到训练集中标签分布的影响,使得模型优化方向向有利于部分占比大的标签的方向偏移,进而造成语义级别注意力权重的分配失衡,并最终影响节点表征的质量。
而在本文的方法中,模型学习的注意力权重是由二元交叉熵损失(binary cross-entropy loss)指导的,即指导模型判断给定节点是否属于指定的局部子图。因此,模型学习到的权重有助于衡量节点在不同分布下与其近邻节点的相似程度,即节点输入特征与其近邻节点的输入特征越相似,分配的权重越大。同时,由于不涉及分类标签,因此权重不会因已知标签而产生偏差。
元路径之间通常表现出不同程度的兼容性,换句话说,不同元路径间可能存在相似的节点分布,同样也可能存在极大差异的节点分布。例如在学术社交网络中,以论文作目标节点,论文涉及的领域作为标签。那么,“论文引用关系”与“论文共作关系”之间的兼容性要强于“论文引用关系”与“术语共用关系”之间的兼容性。这是因为,同一作者的论文更大概率上是关注同一个研究领域的,而相同术语可以被多个领域的论文共用。因此,在没有先验知识的指导下,注意力机制会使得模型更倾向于关注出现频率较高的语义所代表的元路径,从而忽略其他出现频率较低的语义所代表的元路径,即使得模型发生语义层面上的过拟合问题。针对该问题,本文提出了一种注意力平衡机制,用于防止语义层面过拟合的发生,详细内容将在下节进行描述。
3.3 局部图互信息最大化
考虑到语义级别注意力机制可能导致的语义过拟合问题,设计了一种注意力平衡机制,使得模型对所有元路径均保持一定的关注度,而不是仅关注一部分特定的元路径。具体通过将局部表征编码器中注意力模块生成的注意力权重以的形式加入到式(3)中,使得从不受关注的元路径获得的互信息可以对模型训练产生一定的影响。换句话说,注意力平衡机制可以在模型优化的过程中,根据生成的注意力权重βΦi实时调整互信息损失所占比重,使得模型可以在一个较为全面的感受野中进行参数更新,直到收敛。
局部图互信息中主要计算的是节点表征与其近邻输入特征间的互信息。如果将添加为I(hi;xj) 的权重,则会干扰注意力权重的选取,导致节点表征聚合过多的噪音信息,使得模型无法得到有效的收敛。相反,如果将添加为的权重,一方面,可以使得节点表征保留不同元路径下的结构信息;另一方面,避免了节点表征在注意力权重的干预下聚合过多不必要的噪音信息。因此,式(3)可以变换为
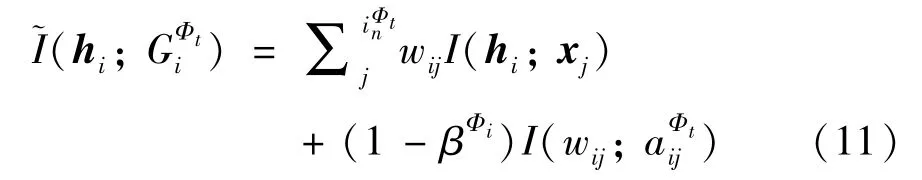
参考MINE[29]的方法,直接最大化式(11)。需要注意的是,MINE 采用Donsker-Varadhan[30]表示联合分布概率与边缘概率乘积之间的KL 散度(Kullback-Leibler divergence)来估计互信息的下界。然而,当更多地关注最大化互信息而不是获得其特定值时,可以使用其他非KL 替代方案,例如Jensen-Shannon 互信息估计器(JSD)[31]和噪声对比估计器(infoNCE)[32],来代替KL 散度。在本文中,参考GMI的实验结果[10],出于有效性和效率的考虑,采用JSD 估计器来最大化式(11)。换句话说,可以通过训练一个判别器/双线性函数D来对采样的正负样本集合进行区分,即判断一个节点的表征是否属于给定的局部子图,以此来估计和最大化互信息。
具体地,利用式(12)来计算I(hi;xj)。

其中,Dw:D × D′表示由一个参数为w的神经网络构成的判别器,x′j为从假设的经验概率分布P 中采样的负样本,sp(x)=log(1+ex) 表示softplus 函数。考虑到不同元路径构成的邻接矩阵中节点的分布不同,使用同一判别器将不利于建模每个元路径的语义信息。因此,本文分别构建不同的判别器对不同邻接矩阵中节点与局部子图间的关系进行判断。给定一个邻接矩阵AΦt,节点vi与其邻居节点的互信息I(hi;xj) 可以表示为
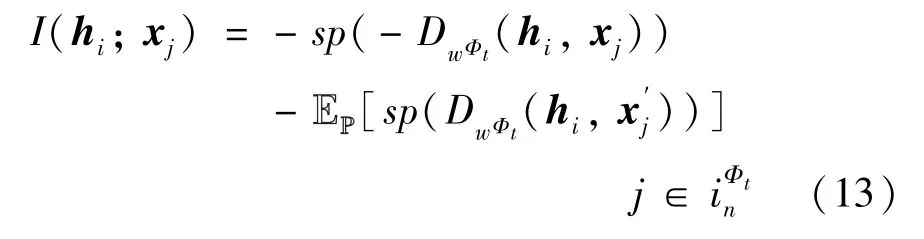
为了有效捕获节点的结构特征,本文将邻接矩阵定义为无权重的邻接矩阵,然后利用交叉熵替代JSD 估计器来最大化:
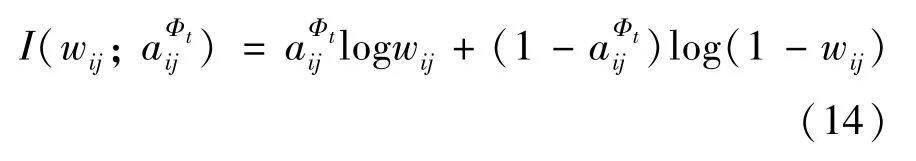
综上所述,结合式(11)~式(14),可以得到最终的目标函数:

其中,I(hi;xj) 用以计算节点表征向量与近邻属性特征向量之间的互信息,通过最大化该互信息将促使节点表征捕获子图中属性特征的分布,进而在全局视角中,使得具有相似属性特征分布的节点生成相似的表征;而则计算2 个节点间存在边链接的概率。通过最大化此概率,可以保证节点表征保留低价近似度(low-proximity),进而在局部视角中,使得相连节点间具有相似的表征。因此,通过对目标函数式(15)进行优化,既可以保证全局视角中具有相似属性特征的节点表征的相似性,又可以保留局部视角中结构的近似性。此外,通过注意力平衡机制权衡多个元路径下的损失,有利于节点表征捕获语义上下文信息。
4 实验与结果分析
4.1 数据集
分别在DBLP 与IMDB 2 种异构图数据集上评估本文提出的HGMI 方法,相关统计数据如表1 所示。
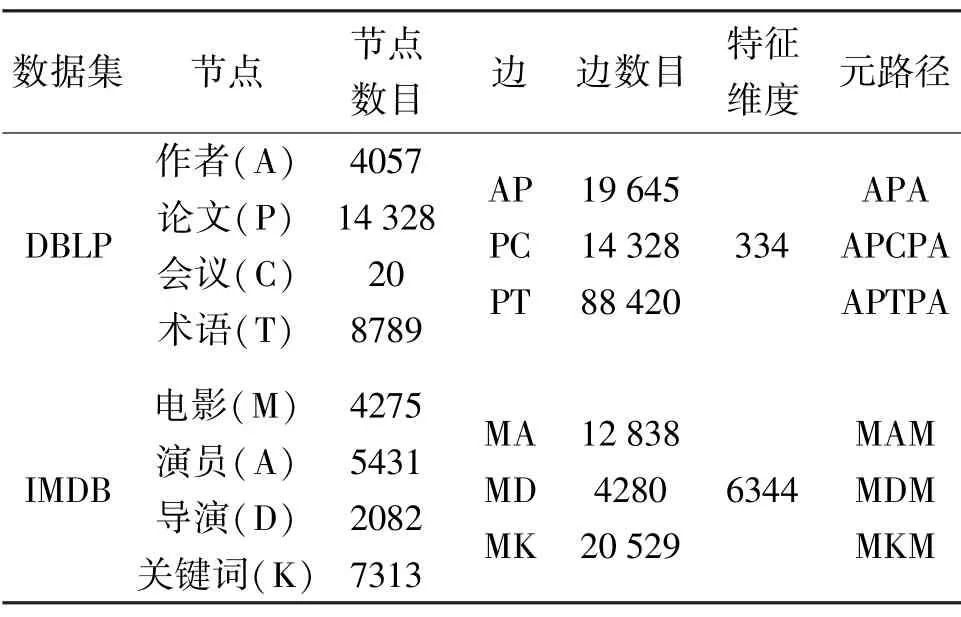
表1 实验数据统计信息
DBLP 数据集是一种研究论文集,其中每篇论文包含相应的发表会议、作者与关键词等信息。作者节点可划分为4 个研究领域,即数据库、数据挖掘、信息检索和机器学习。本文选择作者作为目标节点,并使用作者所属的研究领域作为标签。最初的特征则是根据作者的个人资料利用词袋模型生成的。
IMDB 数据集是关于电影的知识图数据,可以分为3 种类型,即动作、喜剧和戏剧。本文选择电影作为目标节点,并使用电影的类型作为标签。电影的特征则由色彩、标题、语言、关键字、国家、评分、年份以及TF-IDF 编码组成。
4.2 对比方法与相关设置
本文将对比方法分成两类,分别是无监督的图表示学习方法和有监督的图表示学习方法。
其中,无监督的图表示学习方法包括:(1)Raw Feature,即将初始的输入特征作为节点表征;(2)3 个异构图表示学习方法,即Metapath2vec (M2V)、HDGIC与HDGIA,其中HDGIC表示使用GCN 作为特征生成模块的HDGI,而HDGIA则表示使用GAT 作为特征生成模块的HDGI;(3)2 个同构图表示学习方法DGI[8]与GMI[10]。
有监督的图表示学习方法包括2 个异构图神经网络模型RGCN[20]与HAN 和2 个同构图神经网络模型GCN 和GAT。
需要注意的是,对于专为同构图而设计的方法,即DGI、GMI、GCN、GAT,不考虑图的异质性,而是构造基于元路径的邻接矩阵,报告其中最佳的结果。
本文提出的HGMI 方法使用Adam 优化器进行优化,并设定学习率为0.01。同时设定节点表征的维度为512,注意力表征的维度为8。使用Pytorch来实现本文的模型,并在带有2 个GTX-1080ti GPU的服务器中进行实验。
4.3 实验结果与分析
在节点分类任务中,本文为无监督学习方法训练逻辑回归分类器进行分类,而有监督方法则作为端到端模型直接输出分类结果。分别取数据集的20%和80%作为训练集进行实验。另外,选择10%的数据作为验证集,以及10%的数据作为测试集。为了保证结果的稳定性,将分类任务重复10 次,计算平均的宏F1 值(macro-F1)和微F1 值(micro-F1)。
考虑到实验所用的数据集以及相关的评估方法、指标均与HGDI[9]相同,因此,直接与文献[9]中的实验结果进行比较。实验结果如表2 所示。
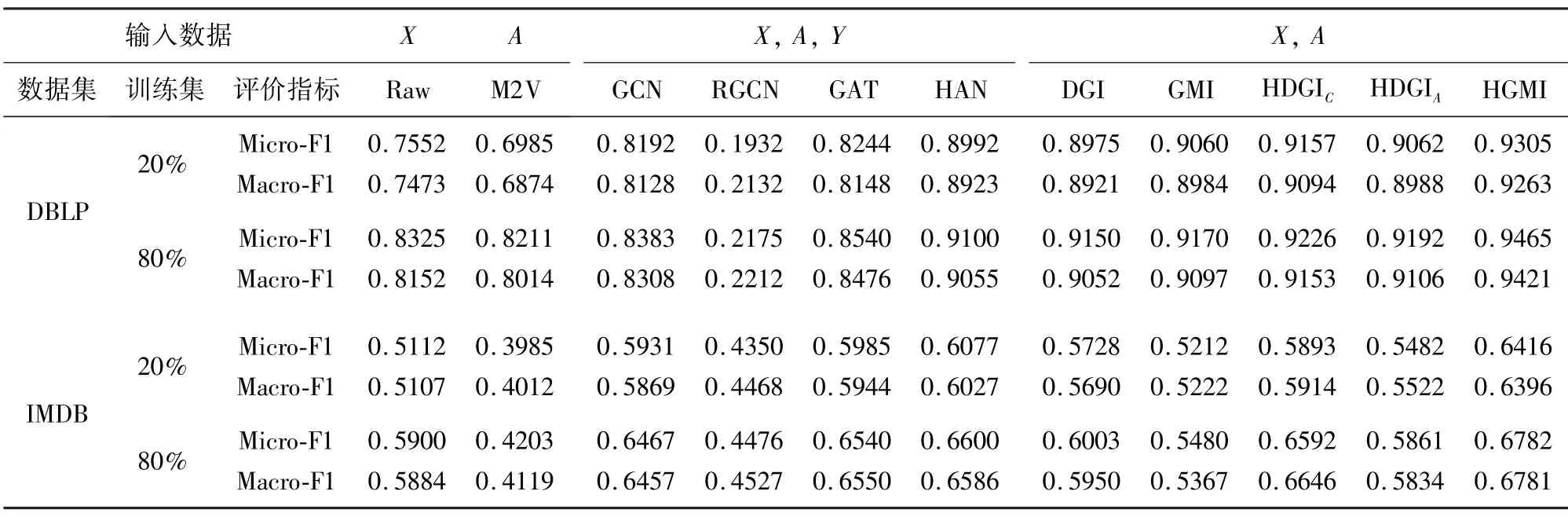
表2 节点分类任务结果
从表2 中不难看出,基于异构图的方法,即HAN、HDGI 和HGMI,通常要优于面向同构图的方法,即GCN、GAT、DGI 和GMI,这说明挖掘与保留异构图中的丰富语义信息有利于提高节点表征的质量。同时,对比以输入特征直接作为节点表征的实验结果,可以有效排除输入特征是导致模型获得较好性能的主要因素的可能性。同样,对比仅利用语义关系/网络结构进行表示学习的M2V,有效结合输入特征与结构信息的异构图表示学习方法通常可以获得更好的节点表征。
与有监督的图神经网络方法的实验结果相比,基于互信息的无监督图神经网络方法同样可以获得较好的实验效果,甚至是表现得更好,如HGMI 与HDGI。这表明在缺少监督信息的场景下,基于互信息的无监督图神经网络方法会是很好的选择。该观察结果还表明,通过有监督的方式在图结构中学习到的特征可能存在局限性,即易受来自数据标签的分布或是下游任务表现出的偏好的影响。而这些局限性可能严重影响表示学习方法在真实场景中的应用。
此外,对比HGMI 与HDGI 的结果,可以发现本文方法的分类效果在2 个数据集中均有提升,这充分反映了在同时考虑多个、具有不同结构的邻接矩阵时,引入局部图互信息以及注意力平衡机制的必要性。一方面,局部图互信息可以使模型更关注节点近邻的信息,而不是全图的信息,从而避免引入不必要的噪音信息;另一方面,注意力平衡机制可以使得模型对所有的元路径均保留一定的关注,而不是过度关注某个/部分元路径,从而使得节点表征获得来自其余语义关系的信息。
另外,在IMDB 数据集中,GMI 的效果要差于DGI 的效果。这主要是因为,在IMDB 数据集中,目标节点间通过元路径构建的关联关系往往是弱相关的,例如,同一个导演可能指导不同类型的影片,而同一个演员也可能出演不同类型的影片。因此,这种弱相关性往往会引入较多的噪音,即具体不同输入特征的邻居节点。不同于GMI,HGMI 通过注意力机制聚合不同邻接矩阵中近邻的信息,从而过滤噪音信息,保证节点表征的质量。
在节点聚类任务中,利用K-mean 算法对生成的节点表征进行聚类。其中,聚类的簇数被设定为目标节点的类别种类的数目。在该任务中,仅比较无监督的方法,即Raw、M2V、DGI、GMI、HDGI 与HGMI。同样重复进行10 次聚类任务,并在表3 中展示平均的标准互信息(normalized mutual information,NMI)和调整兰德系数(ARI)。
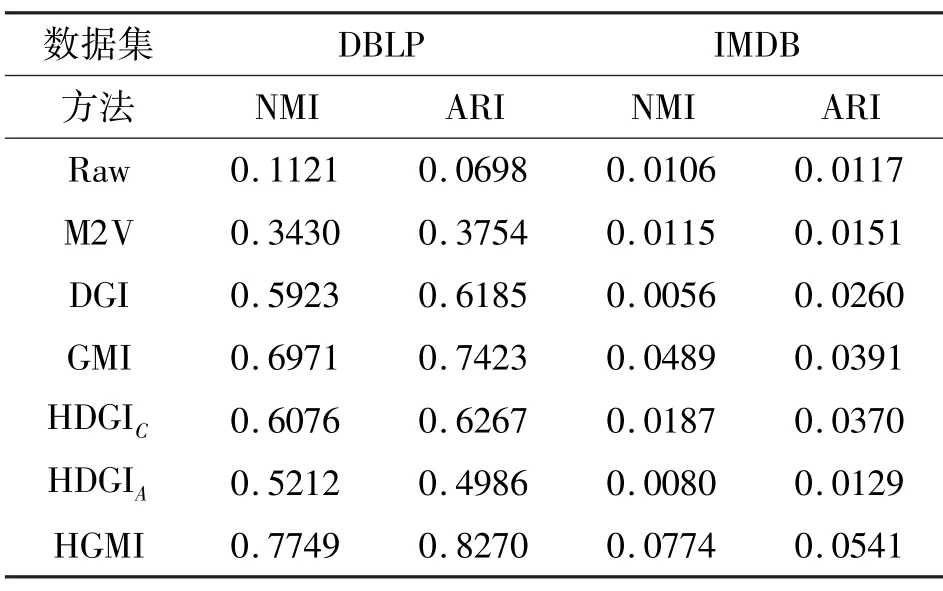
表3 节点聚类任务结果
从表3 中不难看出HGMI 始终要优于其他的对比方法。结合节点分类任务的结果,发现对比方法均存在不同程度的过平滑问题,即局部结构中的节点表征变得过于相似。换句话说,相似的节点表征在一定程度上有利于分类器对节点进行分类;反之,在进行节点聚类时,相似的节点表征则会使得节点聚集在一起,从而变得无法区分。而通过综合考虑多个邻接矩阵下的近邻的分布情况,以及有选择地从中提取有用的信息,HGMI 可以有效地防止过平滑问题的发生。
为了进一步说明注意力平衡机制起到的作用,分别可视化HGMI、HDGI 以及去除注意力平衡机制的HGMIna在IMDB 数据集上最终的注意力权重,结果如图2 所示。
从图2 中可以看出,HDGI 主要关注MKM 关系;相反,HGMIna则主要关注MDM 与MAM 关系。这不难理解,MKM 通过电影间相同的关键词构建关系,由于多数关键词的通用性,使得电影节点连接得更为紧密、表征变得更为相似,导致图读出操作(readout)生成的全局图表征与节点表征具有更大的互信息,从而使得MKM获得较大的关注。反之,MDM 与MAM 往往会使得少量、具有相似属性/特征的节点聚集在一起,使得局部子图与节点表征间的互信息变大。

图2 IMDB 数据集中不同元路径的注意力权重
而在加入了注意力平衡机制后,HGMI 不仅可以对MDM 与MAM 保持较高的注意力权重,同时,也会为MKM 分配一定的权重,而不是直接将其忽略。通过这种方式,HGMI 可以聚合到在MDM 与MAM 中接触不到的节点的特征。
5 结论
本文主要讨论了利用图互信息进行无监督的异构图表示学习的方法。首先通过元路径将异构图转化为多个具有特定语义的同构图;然后在每个同构图中进行图卷积操作,并利用注意力机制对相同节点的不同表征进行融合;在此基础上,最大化每个图中局部子图与节点表征间的互信息,使得节点表征可以有效聚合不同语义关系下近邻的输入特征。同时,为防止语义过拟合的发生,引入注意力平衡机制,使得模型对所有语义关系均保持一定的关注度。实验结果表明,本文方法相比于其他方法,可以在节点分类与节点聚类任务中获得更好的效果。
