集成学习模型的堆芯物理关键参数预测
2021-02-10马季郝琛谢晓芹生义
马季, 郝琛, 谢晓芹, 生义
(1.哈尔滨工程大学 核安全与仿真技术国防重点学科实验室,黑龙江 哈尔滨 150001; 2.哈尔滨工程大学 计算机科学与技术学院,黑龙江 哈尔滨 150001)
针对某些堆芯关键参数(如功率分布)的不确定性分析需要采用抽样统计的方法,不可避免地需要进行大量重复计算,使得分析过程面临计算量巨大、耗时很长的问题,需要得到精确不确定性分析结果的同时减少计算量。作为人工智能的核心,机器学习在近几年来得到了迅速的发展,众多成果已用到反应堆工程计算领域,其中以机器学习预测模型替代数值求解过程[1-3]及经验模型预测[4-5]的应用最广泛。其优势在于通过分析输入数据与输出参数的关系训练机器学习模型,训练后的模型在给定输入参数后可快速得到目标输出参数。当实际计算过程所需的计算代价较大时,采用训练完备的机器学习预测模型替代传统计算过程,可以获得精度和效率的双重收益。采用高保真技术的反应堆精细化中子输运计算由于能群、计算网格划分更加精细,需要较长的计算时间,基于抽样统计方法使用此计算工具开展针对堆芯关键参数的不确定性分析必然会耗费不可接受的计算时间。因此采用机器学习预测模型替代精细化中子输运计算以实现进一步不确定性分析是解决上述问题的一种可行方案。
本文开展了通过训练机器学习模型替代精细化中子输运计算的方法研究及分析,以实现对堆芯关键参数的准确、快速预测。构建2D、3D C5G7基准算例预测模型,实现以宏观核截面为输入的堆芯有效增殖因子预测;以C5G7单组件瞬态问题宏观核截面及瞬态参数为输入的全局功率、全局反应性、中子代时间和缓发中子份额预测。同时,选择平均绝对误差、平均标准误差及方差偏离矩阵为评价指标检验预测模型的预测效果。从计算精度、计算时间2个角度对预测结果进行评价,同时从训练样本数目及机器学习模型2个角度分析预测效果的影响因素。
1 集成学习模型及评价指标
本文建立的预测模型为集成学习模型,即通过构建、结合多个学习器来完成学习任务,以达到预测能力和鲁棒性明显优于单一学习器的学习性能。
1.1 集成学习模型-堆叠法
堆叠法[6]是一种分层模型集成学习框架。以2层堆叠为例,第1层由多个基学习器组成,它的输入为原始训练集,每个基学习器进行K折训练;第2层模型以第1层基学习器的输出作为训练集进行再训练,最终得到完整的堆叠法模型。图1为单个基学习器采用5折交叉验证的堆叠法模型示意图,简要过程为:

图1 堆叠法示意Fig.1 Sketch map of stacking framework
1) 使用一个基础模型作为Model进行5折交叉验证,5折交叉验证的含义为取4折作为训练数据,另外1折作为测试数据。交叉验证过程为:基于训练数据模型,随后基于训练数据训练生成的模型对测试数据进行预测。在第1次交叉验证完成后会得到关于当前测试数据的预测值,记为a1;
2) 对数据集自身的测试数据进行预测得到预测值,这部分预测值将作为第2层模型测试数据的一部分,记为b1。5折交叉验证即为将以上过程实施5次,最终生成针对测试数据a1、a2、a3、a4、a5,对测试数据的预测结果为数据b1、b2、b3、b4、b5。
3) 在完成对Model1的整个步骤之后,得到的a1、a2、a3、a4、a5,即为对整个训练数据的预测值,将它们的组合记为矩阵A1;将b1、b2、b3、b4、b5相加取平均值,得到矩阵B1。则A1即为第2层模型的训练数据,B1为第2层模型的测试数据。
以上为单个基学习器的stacking模型实施流程,通常情况下stacking模型的第1层包含多个基学习器,即可能存在Model2至ModelN,对于这些模型可重复以上步骤,在整个流程结束之后将得到A2,A3,…,AN,B2,B3,…,BN矩阵,随后将A2,A3,…,AN合并为N列的矩阵作为训练数据,B2,B3,…,BN合并为N列的矩阵作为测试数据,并让第2层模型基于新的训练数据及测试数据进行训练和测试。
本文采用的集成学习中的堆叠模型分为2层:第1层采用的基学习器为弹性网络模型和梯度推进模型,每个基学习器采用5折交叉验证:弹性网络是一种同时使用L1范数和L2范数作为先验正则项训练的线性回归模型,能实现输入参数数量远小于输出参数数量时的精确预测;梯度推进模型属于集成学习中的boosting算法,在大样本、复杂非线性系统中具有较大的优势[7];第2层采用的元学习器为最小绝对值选择与收缩算子模型,它是一种有偏估计方法,由于在模型中加入了惩罚项,使变量集合简化、稀疏,从而使模型更加精炼[8]。本文构建的堆叠融合模型,可以集中各基学习器的优势,在实现精确预测的同时保持计算的稳定性。
本文采用开源Python发行版本Anaconda 4.9.2中的科学包Jupyter 6.2.0进行以上算法建模及运行。
1.2 评价指标
机器学习模型的预测结果可能受到多种因素影响而导致学习率不高、预测结果不准确等问题,通常情况下,随着训练数据的增加,模型预测结果的准确率会接近于1,最终在一定范围内将不再变化[9]。为了更好地对学习效果进行评价,应当选择恰当的评价指标,本文使用的评价指标为均方误差MSE、平均绝对值误差MAE及回归平方和与总平方和之比Q2分别为:
(1)
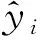
变量含义同均方误差,MAE值越小表明训练效果越好。
方差偏离矩阵Q2为:
(2)
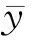
对于通量分布、堆芯棒功率等分布量,以误差分布作为评价指标,即计算堆芯每个棒位置处的均方根误差,最后给出均方根误差的分布。均方根误差为:
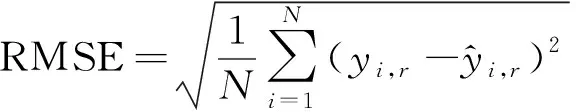
(3)
式中r为棒在堆芯中的位置。
2 C5G7问题预测验证与分析
本文选择的验证问题为由经济合作与发展组织核能机构发布的确定论中子输运计算验证基准题C5G7问题。采用建立的训练模型针对上述计算问题开展输入参数和输出响应的特征捕捉,可以学习得到代替精细化物理计算过程的预测模型。本节将就C5G7的3个计算问题,对预测模型的计算精确性、计算效率进行验证,并开展训练效果影响因素分析。
2.1 C5G7问题
2.1.1 C5G7稳态问题
C5G7稳态问题[10]包括2D、3D问题。基准问题是由16个燃料组件构成的小型水堆全堆芯问题,因此它可以简化为由4个燃料组件构成的1/4堆芯。2D模型的规模为64.26 cm×64.26 cm,组件宽度为21.42 cm,下、右边界采用真空边界条件,上、左边界采用全反射边界条件以实现堆芯的对称结构。单个燃料组件采用17×17方形栅元布置,其中包括264个燃料栅元,24个导向管栅元(用于插拔控制棒)和1个位于中心的测量通道。对于UO2燃料组件,仅有一种燃料类型,而MOX燃料组件则包括4.3%、7.0%和8.7% 3种富集度的燃料。2D C5G7模型的几何布置如图2所示。
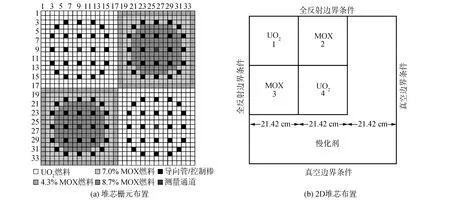
图2 C5G7栅元排布及2D堆芯布置Fig.2 Fuel pin configuration and 2D layout of C5G7
3D C5G7模型则是在2D模型的基础上将燃料区延伸至轴向高度为128.52 cm,同时堆芯的上部和下部增加厚度均为21.42 cm轴向反射材料,最终构成规模为64.26 cm×64.26 cm×171.36 cm的三维计算问题。3D C5G7模型的几何布置如图3所示。
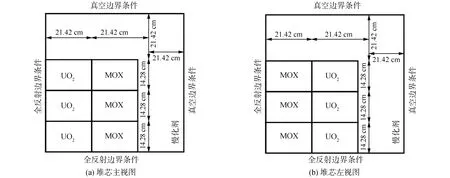
图3 3D C5G7布置Fig.3 3D configuration of C5G7 problem
本文对2D/3D C5G7问题进行训练所采用的输入数据为堆芯材料宏观截面,输出数据为全堆芯有效增殖因子。
2.1.2 3D C5G7单组件瞬态问题
C5G7单组件瞬态问题描述了单个UO2组件在0.1 s内,由控制棒插入深度为20 cm变为堆芯活性区不插棒状态的过程。堆芯四周采用全反射边界条件,堆芯上下由于布置了反射材料因此采用真空边界条件,3D C5G7单组件瞬态问题的几何描述如图4所示。为了实现动态过程的精确模拟,需要对事件发生时间进行时间步的精确划分,本文选择的时间步长为5 ms。
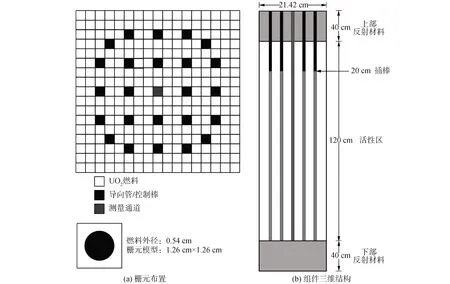
图4 3D C5G7单组件几何布置Fig.4 Geometry layout of 3D C5G7 single assembly
不同于稳态问题,本文对3D C5G7单组件瞬态问题进行训练所采用的输入数据除了堆芯材料宏观截面外,还包括中子速度、缓发中子份额、缓发中子能谱及缓发中子衰变常数;输出数据包括堆芯相对功率、反应性、有效缓发中子份额、中子代时间。
2.2 训练规模及参数设置
稳态及瞬态问题的输入参数和输出参数均不一致,本文对2种问题进行训练和验证时采用的训练样本和测试样本数目也不相同。表1展示了不同计算问题的输入、输出参数规模及训练、测试数目设置情况。对于训练样本和测试样本的选择目前尚无定论,一般按照8∶2或7∶3的比例进行设置,本文根据7∶3并结合实际产生的总样本数设置了不同问题的训练参数。
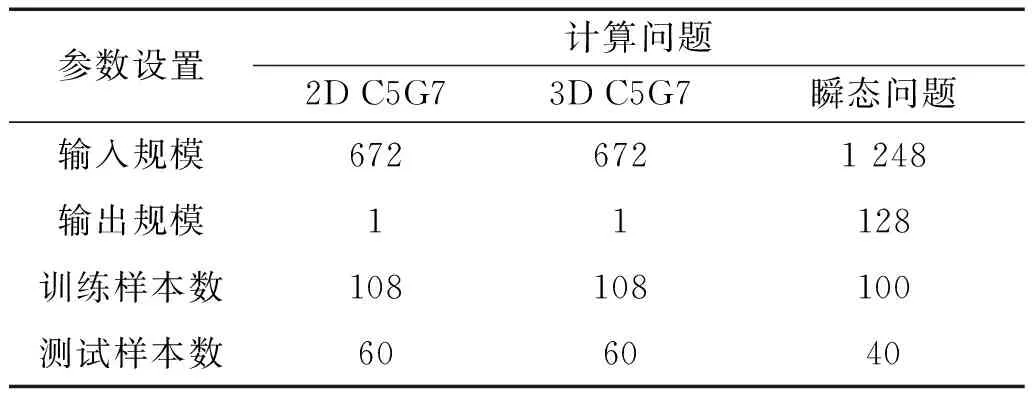
表1 训练规模及参数设置Table 1 Lists of parameters used in training and testing for cases
对于2D及3D C5G7稳态问题,其输入-输出关系为:
1) 材料宏观截面(输入):包括7个能群结构的UO2、富集度分别为4.3%、7.0%、8.7%的MOX燃料、导向管、测量通道、慢化剂及控制棒等棒束的材料总截面Σt、吸收截面Σa、裂变截面Σf、中子产出截面υΣf、群-群的散射截面Σg→g′、裂变谱χ,共672个参数(值为0也包含在内);
2) HNET-稳态模块(计算模型):自主开发的高保真精细化稳态中子输运计算程序[11];
3) 有效增殖因子keff(输出):有限大增殖介质的中子增殖过程中,某代中子数与相邻前一代中子数之比,用于描述堆芯链式反应的状态。
对于3D C5G7单组件瞬态问题,其输入-输出关系为:
1) 材料宏观截面及瞬态参数(输入):包括7个能群结构的UO2、富集度分别为4.3%、7.0%、8.7%的MOX燃料、导向管、测量通道、慢化剂及控制棒等棒束的材料总截面Σt、吸收截面Σa、裂变截面Σf、中子产出截面υΣf、群-群的散射截面Σg→g′、裂变谱χ、中子速度v;8个能群结构的缓发中子份额、缓发中子能谱及缓发中子衰变常数,共1 248个参数(值为0也包含在内);
2) HNET-瞬态模块(计算模型):自主开发的高保真精细化瞬态中子输运计算程序[12];
3) 输出数据为各时间步下堆芯相对功率、反应性、有效缓发中子份额、中子代时间,共128个参数。
2.3 计算精度验证
2.3.1 2D C5G7稳态问题
2D C5G7稳态问题的输入参数为7个宏观截面,输出参数为有效增殖因子。训练集样本数目为108个,测试集样本数目为60个。图5直观地展示了由预测模型得到的预测值与精细化物理计算结果对比,可以看到,2种计算方法得到的结果基本一致,这在一定程度上表明了建立的机器学习模型实现了对2D C5G7稳态问题输入、输出关系的特征捕捉,具有实现替代精细化计算的可能性。
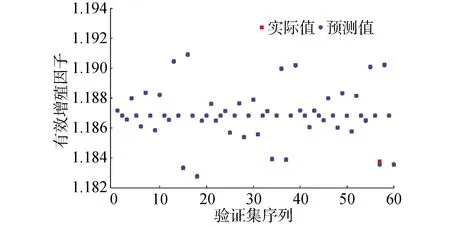
图5 2D C5G7堆芯有效增殖因子预测验证Fig.5 Prediction test for keff of 2D C5G7 problem
通过引入评价指标可以定量判断模型的训练效果。针对2D C5G7稳态问题堆芯有效增殖因子预测结果的MAE、MSE及Q23种评价指标计算结果分别为1.537 60×10-5及1.104 93×10-9,Q2值为0.999 59。文献[3]中开展的反应堆物理计算替代模型研究针对65个少群宏观截面,采用200组训练样本及100组验证样本对组件无限增殖因子进行预测,评价指标MAE及Q2分别为4.11×10-4及0.993。
与文献[3]预测效果对比可以发现,本文建立的训练模型针对2D C5G7稳态问题实现了多输入参数、少训练样本下对计算结果的精确预测。
2.3.2 3D C5G7稳态问题
3D C5G7稳态问题的输入参数同样为7群宏观截面,输出参数为有效增殖因子。训练集样本数目及测试集样本数目与2D问题一直,分别为108和60。图6展示了3D问题下由预测模型得到的有效增殖因子预测值与精细化物理计算结果的对比,2种计算方法得到的结果同样基本一致。
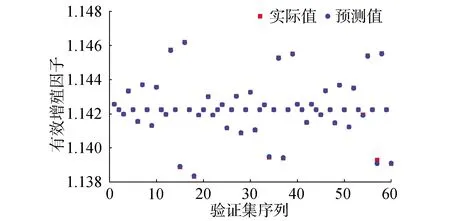
图6 3D C5G7堆芯有效增殖因子预测验证Fig.6 Prediction test for keff of 3D C5G7 problem
3D C5G7稳态问题有效增殖因子预测结果的MAE、MSE及Q23种评价指标计算结果分别为1.546 68×10-5、1.103 19×10-9、0.999 56。结果表明本文所建立的训练模型针对3D C5G7稳态问题同样能实现堆芯有效增殖因子的精确预测。
2.3.3 3D C5G7单组件瞬态问题
对于3D C5G7单组件瞬态问题,利用预测模型实现了堆芯在不同时间下的相对功率、反应性、有效缓发中子份额及中子代时间的预测。图7展示了预测结果与高保真瞬态计算程序的相对误差,可以看到,堆芯功率的相对误差小于1.2%,反应性的相对误差小于0.014%,有效缓发中子份额相对误差小于0.065%,中子代时间相对误差小于0.59%,误差均处于可接受范围内。这也表明了本文所建立的训练模型同样实现了3D C5G7瞬态问题堆芯关键参数的精确预测。
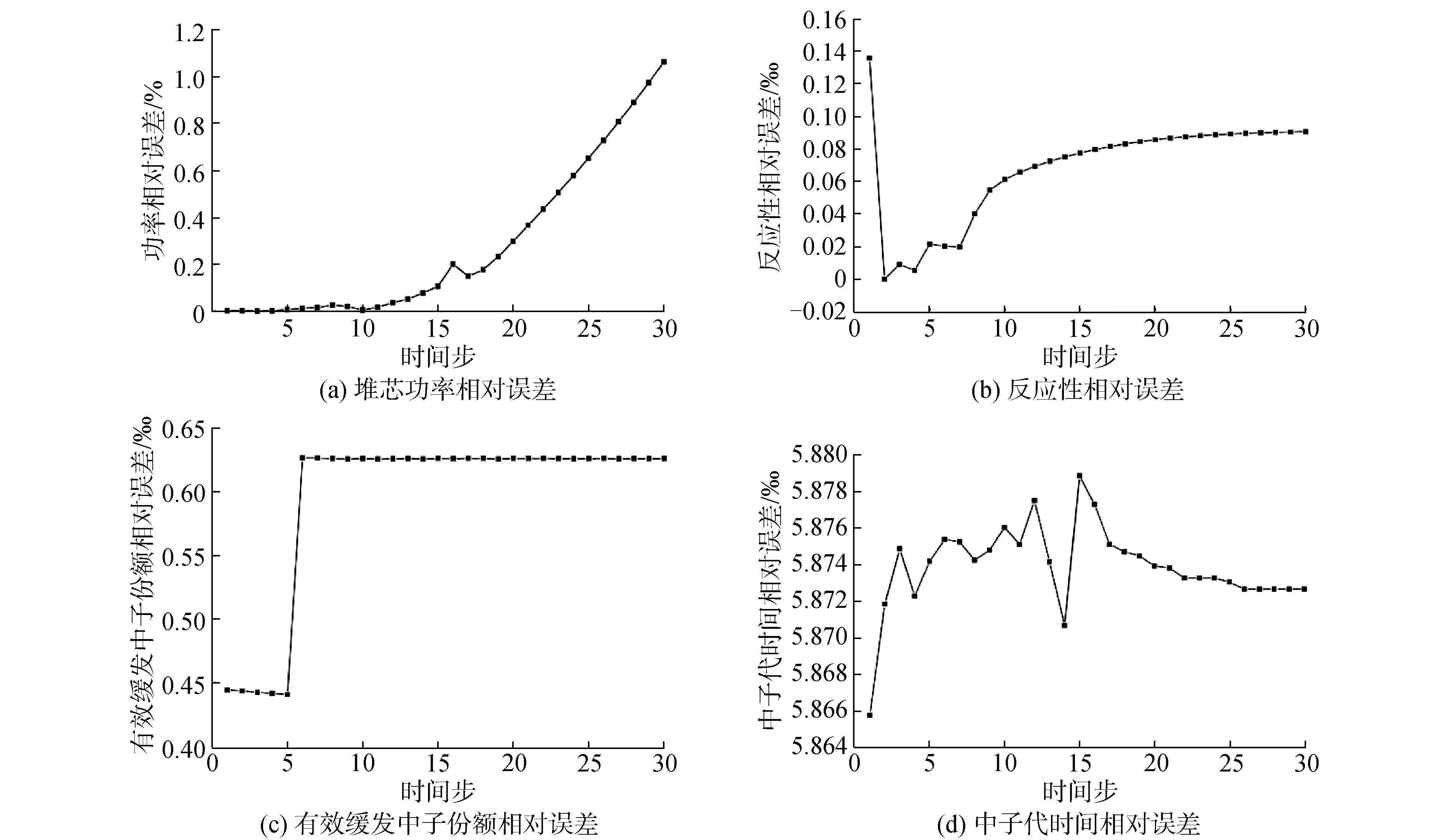
图7 瞬态参数预测相对误差Fig.7 Relative error of transient parameters prediction results
2.4 计算效率验证
基于机器学习的替代模型代替传统高保真计算需要保证精度和计算时间的双重收益,本节对计算时间进行测试。表4列出了不同计算问题使用传统计算方式与预测模型的计算时间对比,可以看到对于2D、3D C5G7问题训练模型进行60组结果预测所需的计算时间在70 s以内,远低于采用高保真计算使用的时间;对于瞬态问题而言,由于输出参数增多,因此时间收益相较于稳态问题有所减少,但相比于传统计算仍有33倍的计算时间收益。这表明采用基于机器学习的预测模型代替高保真计算所带来的计算时间收益十分可观,也表明了预测模型达到了精度与计算时间的双重收益,满足了开展进一步不确定性分析的2项基本前提。

表2 计算时间对比Table 2 Comparison of computational time
值得一提的是,训练时间应当包含训练样本产生的时间,即进行多次高保真计算的时间,这也带来了一定的计算代价。然而,以训练模型开展后续分析相比采用高保真计算仍能减少大量计算时间。综合考虑,采用训练模型替代高保真计算的方案仍是可以采纳的。
2.5 训练集数目对训练效果的影响
训练样本数是模型训练过程中非常重要的参数,它对模型的训练效果具有很大影响。通常情况下,训练样本数越大,模型训练效果越好,但无限制的增加训练样本数势必会增加很多不必要的训练时间;同时,采用数量不足的训练样本数则达不到好的训练效果,因此有必要进行训练样本数目对训练效果影响的分析。
表3列出了在不同训练样本数目下,对2D C5G7问题keff的预测模型评价指标的计算值,测试样本数均为60。随着样本数目增加,MAE、MSE值逐渐减小,Q2值逐渐增大,结果符合预期。从图8可以更直观的看到这样的变化趋势,但在训练样本数目为20时,Q2值大于采用30、40个训练样本。事实上,这并不能说明样本数目为20时即可得到合理的预测结果。虽然Q2在训练样本数目为20时较大,但预测结果与实际计算结果的方差相对误差为11%,这对后续的不确定性分析结果会带来负面的影响。同时,从图8中可以发现当训练样本数大于100时,Q2值已经很接近于1,此时预测结果和实际计算结果的方差相对误差为1%,即采用大于等于100个训练样本时,模型的训练效果是符合要求的。因此,在评价训练效果时,应综合考虑预测精度与方差分布,避免由训练模型引入新的不确定度。
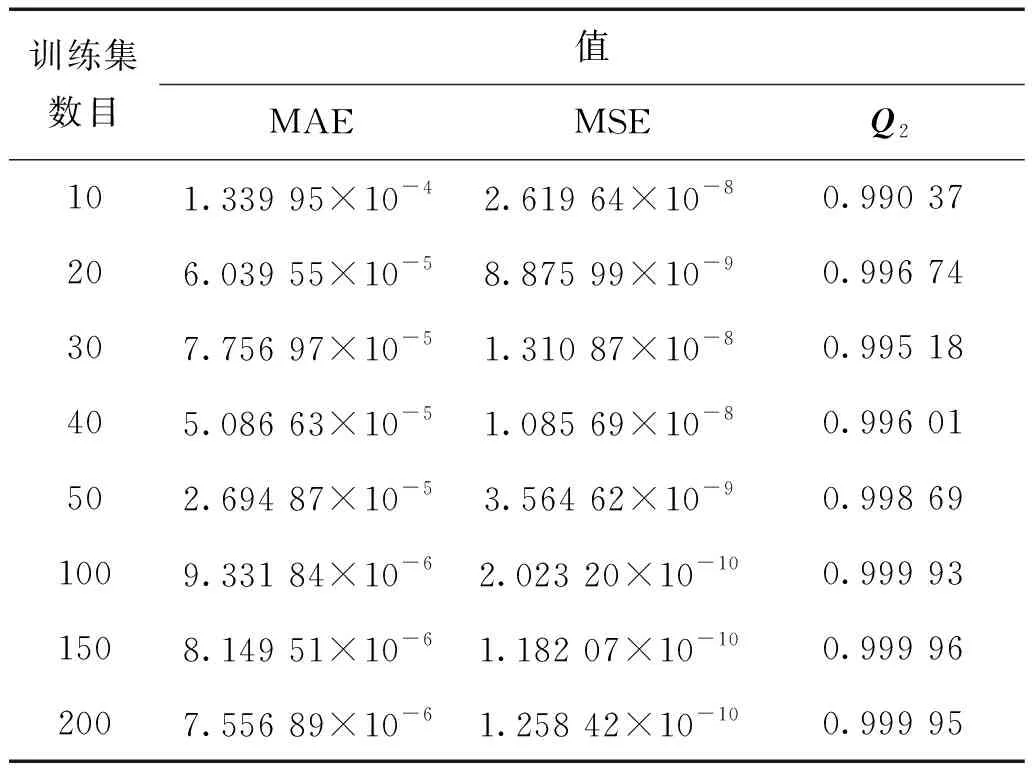
表3 训练集数目对训练效果的影响Table 3 Effect of training data number on prediction accuracy
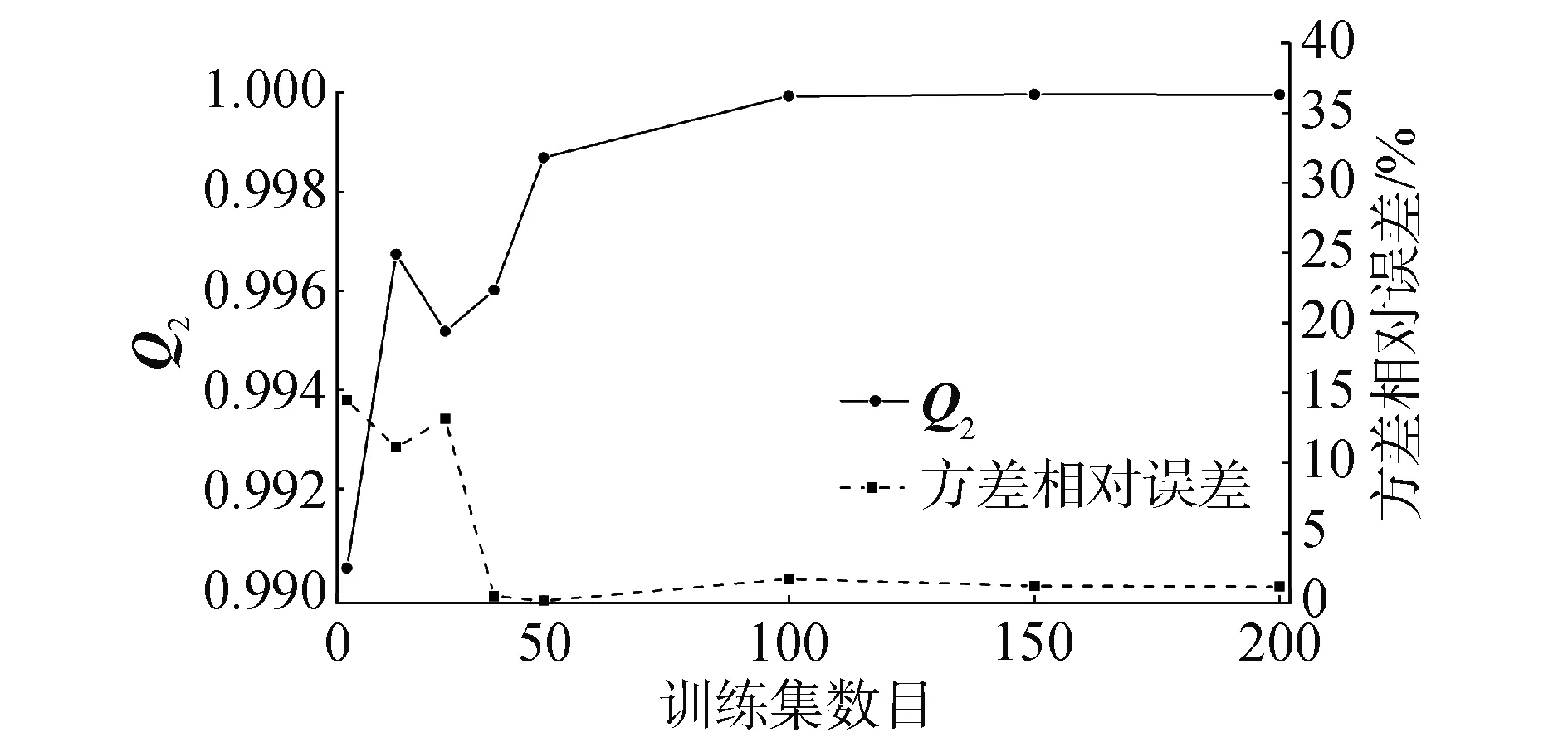
图8 训练样本数目对预测效果的影响Fig.8 Prediction accuracy change with number of training sets
2.6 不同模型对训练效果的影响
本文采用2层堆叠的集成学习模型开展针对堆芯关键参数的预测,第1层计算模型分别为ENet、GBoost及KRR,第2层计算模型为lasso。事实上,不同模型可以单独完成训练、预测工作,因此本节将分别单独使用以上4种模型对2D C5G7问题的堆芯keff进行训练和测试,训练样本数均为100,测试样本数均为60。表4展示了采用以上模型单独预测的评价指标计算值。可以发现,KRR及GBoost方法建立的预测模型预测效果较差,但基于ENet、lasso方法的预测模型可以得到很好的预测结果。
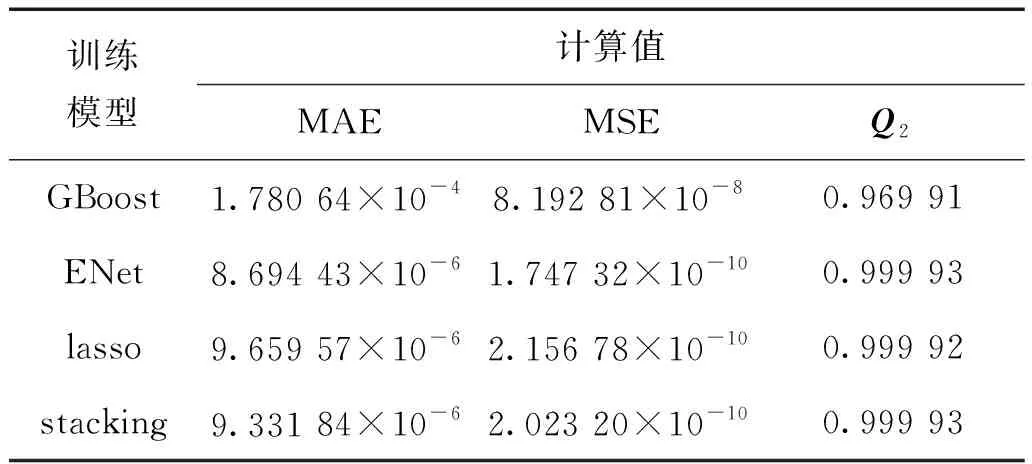
表4 训练模型对训练效果的影响Table 4 Effect of training model on prediction accuracy
单就结果而言,采用单一方法建立的预测模型也可以得到精确的预测结果,但堆叠模型相比单一模型具有更显著的优势,如不需要太多的调参和特征选择,模型鲁棒性更强等。因此,堆叠模型仍是推荐的训练模型。
3 结论
1) 本文开展的样本数目对预测效果的分析结果表明,当训练样本数目为100时可以得到满足要求的预测结果,堆叠模型在实现精确预测的同时能保证其鲁棒性。
2) 以基于机器学习的预测模型替代抽样统计过程中大量重复的精细化物理计算开展不确定性分析是可行的研究方案。
本文建立的堆叠模型为进一步实现以核截面为不确定性来源的堆芯关键参数不确定性量化与分析提供了良好的工具基础。该模型的应用范围并不限于此,进一步可开展共振计算、燃耗计算、物理热工耦合计算的替代计算。同时,在开展规模更大、耗时更长的计算结果预测时,本文建立的替代模型将获得更大的时间收益。
