用于求解粗网有限差分方程的优化并行预处理算法
2021-02-10刘礼勋朱凯杰郝琛李富
刘礼勋, 朱凯杰, 郝琛, 李富
(1.清华大学 核能与新能源技术研究院,北京 100084; 2.哈尔滨工程大学 核科学与技术学院,黑龙江 哈尔滨 150001)
进行全堆芯三维精细化中子输运计算必须依赖于有效的加速手段,粗网有限差分 (coarse mesh finite difference, CMFD) 方法[1]因其便于实施、加速效果好,被广泛地应用在全堆芯输运计算的加速算法中。然而,三维全堆芯Pin尺度的CMFD是一个大型稀疏非对称线性方程组,其系数矩阵的规模可达到上亿级别,高效求解CMFD线性方程组对实现加速至关重要。广义极小残差算法是求解大型非对称线性方程组的优秀方法,但该方法的优越性取决于良好预处理技术的应用,特别是针对条件数很大或者严重病态的线性方程组,高效的预处理技术尤为重要[2]。针对于串行计算,不完全LU分解(incomplete LU decomposition, ILU)、对称超松弛(symmetric over-relaxation, SOR)、块预处理、稀疏近似逆等是很好的预处理技术[3]。但是针对于并行计算,需要采用红黑网格策略,才能充分发挥ILU、SOR的预处理效果[4],但同时带来的问题就是引入不必要的计算等待时间,以及使得程序开发变得异常复杂。目前在核反应堆计算领域,Block-Jacobi不完全LU分解(block-jacobi incomplete LU decomposition, BJILU) 因其实施方便而得到了广泛的应用,如美国的MPACT程序[5],但其仅对各自CPU中的元素进行了预处理,对不同核心间需要信息传递的元素并未做任何预处理。Xu[6]提出了一种简化对称超松弛预处理技术(reduced symmetric over-relaxation, RSOR) 与不完全LU分解的混合预处理方法(RSOR and ILU, RSILU),有效解决了上述问题,但在实际应用中发现该方法有待进一步优化。
本文采用以下2种方法对现有的RSILU预处理进行了优化:1)将不完全LU分解预处理子替换为修正不完全LU分解(modified incomplete LU decomposition, MILU)预处理子,以进一步提高RSILU的预处理效率;2)由严格计算对角块矩阵的逆改为近似计算,以解决RSILU方法在复杂能群结构的多群CMFD问题中,预处理计算耗时过多的问题。利用C5G7-3D基准题和VERA Problem #4基准题搭建CMFD线性方程组对优化后的RSILU方法进行了测试分析。所有测试均基于MPI并行编程模型[7],采用空间区域分解的方式进行并行计算。
1 CMFD线性方程组与GMRES算法
1.1 三维多群CMFD线性方程组
建立在Pin尺度上的三维多群CMFD方程组为:
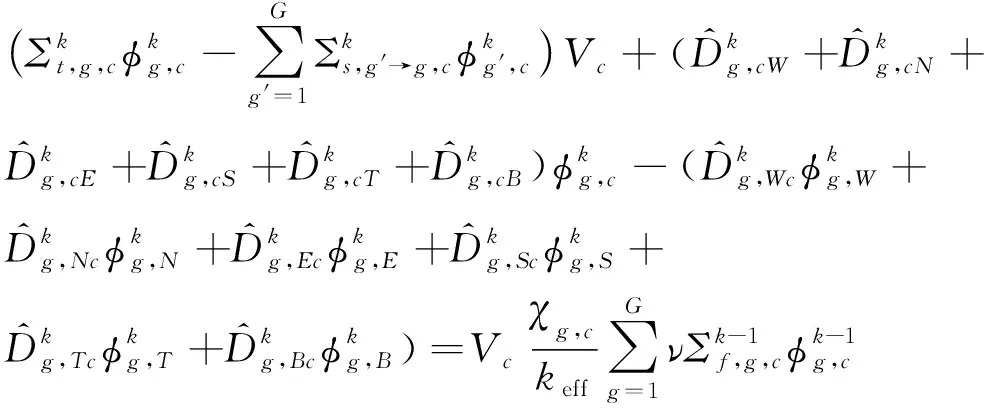
(1)
式中:φ、Σt、Σs、vΣf、χ、keff分别是中子通量密度、总截面、散射截面、吸收截面、裂变谱和有效增殖因子。式(1)在数学上可表示为线性方程组:
Ax=b
(2)
式中:未知量x即为待求的中子通量φ,按照“先能群、后空间”的顺序进行排列;系数矩阵A∈Rn×n是七对角、稀疏、非对称矩阵,其中主对角线的对角块由能群散射矩阵构成:
(3)
式中:D为对角块矩阵;LA和UA为严格非对角块矩阵。对于能群、空间耦合求解的CMFD线性方程组;Di为G×G稠密矩阵(如图1所示);G为能群数;LA,i和UA,i为稀疏矩阵。对几何空间进行区域分解,并基于MPI进行分布式内存计算,此时系数矩阵A可进一步表示为:

图1 对角块中的散射矩阵(47群)Fig.1 The scattering matrix in diagonal block (47 groups)
A=LI+LP+D+UP+UI
(4)
式中:LP和UP是存储在当前CPU内的严格非对角块,LI和UI是存储在不同CPU内的严格非对角块,如图2所示。
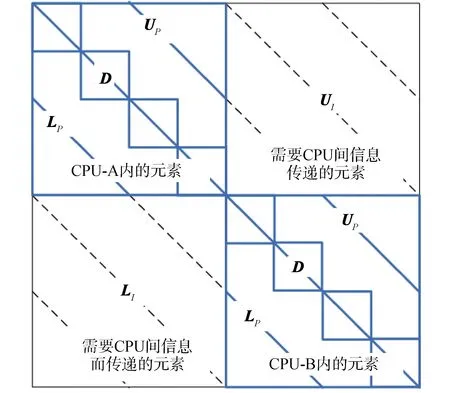
图2 CMFD线性方程组系数矩阵Fig.2 Coefficient matrix of CMFD linear system
1.2 预处理GMRES算法
广义极小残差算法(generalized minimum residual method, GMRES)是求解非对称线性方程组的有效方法,该方法是Krylov子空间法的一种,通过在子空间上进行投影以迭代的形式寻找近似解。记r0=b-Ax0为初始残差向量,由r0生成的Krylov子空间可表示为:
Km(A,r0)=span{r0,Ar0,A2r0,…,Am-1r0}
(5)
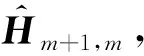
(6)
GMRES方法在Krylov子空间中产生一系列近似解,这些近似解逐步逼近于真解,同时这些近似解的残差向量rm满足二范数最小的性质。rm可表示为:
β=‖r0‖2
(7)
经过m步GMRES算法形成近似解xm满足:
xm=x0+Vmym
(8)
其中ym∈Rn通过极小化式(9)得到,即:
(9)
GMRES方法的优越性取决于良好的预处理技术的应用,特别是针对条件数很大或者严重病态的线性方程组,高效的预处理技术尤为重要。预处理的本质是对线性方程组(2)作同解变换,以右预处理为例:
(10)
式中M为预处理子(预处理矩阵)。本文中采用右预处理GMRES算法求解CMFD线性方程组[8],右预处理GMRES算法如下:
算法1:右预处理GMRES算法
1) 选取初值x0∈Rn, 计算初始残差r0=b-Ax0, 定义β=‖r0‖2,v1=r0/β
2) Forj=1, 2, …,mDo
3) 计算w:=AM-1vj
4) Fori= 1, 2, …,jDo

7) End Do
8) 计算hj+1,j=‖w‖2,vj+1=w/hj+1,j

10) End Do
12) 计算xm=x0+M-1(Vmym)
13) 如果满足收敛标准则停止;否则置x0:=xm并转向1。
2 RSILU预处理算法及其优化
2.1 RSILU预处理子
预处理矩阵M的选取对GMRES收敛速率影响极大。文献[6]提出了高效的RSILU混合预处理方法,该方法由RSOR和ILU预处理子共同构成,不仅对各自CPU中的元素进行了预处理,还对不同CPU间需要信息传递的元素也进行了预处理,如图3所示。其中,RSOR高效预处理不同CPU间需要信息传递的元素,RSOR预处理子为:
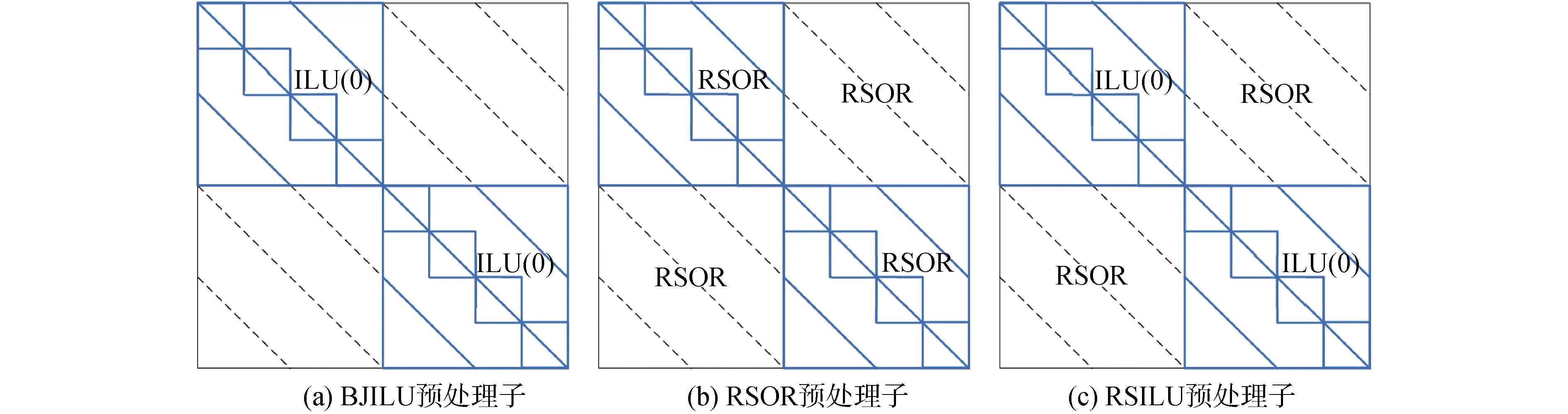
图3 不同预处理算子示意Fig.3 Diagram of different preconditioner
(11)
式中ω为松弛因子。RSOR不需要红黑网格技术,便于实施,并且当核数的增加时GMRES所需的迭代次数保持不变,同时还能保证解的对称性,是一种简单高效的并行预处理算法,更多详细内容可参考文献[6]。
ILU高效预处理各自CPU中的元素,ILU(0)预处理为:
(12)
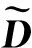
(13)
结合式(11)和式(12),RSILU预处理为:
ω(LI+UI)D-1]
(14)
为减少RSILU预处理实施过程中的存储和计算负担,使用DE替换上式中的D,D为DE的对角元素。最终RSILU预处理子可定义为:
ω(LI+UI)DE-1]
(15)
2.2 RSILU预处理算法的实施步骤
算法2:z=M-1v
2)将w1传递给其他CPU,以用于并行计算
3)计算w2=v-ω(LI+UI)w1

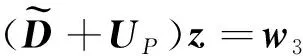
2.3 优化的RSILU预处理算法
2.3.1 MILU替换ILU
(16)
2.3.2 对角块矩阵的近似求逆
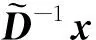
3 预处理效果验证
为验证优化后的RSILU算法的预处理效果,本文基于C语言开发了预处理GMRES求解器,并选用C5G7-3D基准题[9-11]和VERA Problem #4基准题[12]搭建pin尺度单群/多群CMFD线性方程组作为测试题(见表1),其中单群CMFD通过对多群CMFD进行能群归并得到[9],单群CMFD方程组的系数矩阵没有对角块,是一个传统的7对角矩阵。为了后续表述更简便,优化前的RSILU算法用RSILU-old表示,优化后的RSILU算法用RSILU-new表示。

表1 CMFD线性方程组介绍Table 1 CMFD linear system information
预处理GMRES选用相对残差10-8作为收敛标准。串行计算环境:Inter(R) Core(TM) i5-7200U CPU@2.71Hz, RAM 8.0GB;并行计算环境:“天河一号”超级计算机,采用商用InfiniteBand网络连接,每个计算节点包含28个计算核心(14个2×Intel Xeon CPU E5-2690 v4 @2.60 GHz),RAM 128 GB。编译器选用英特尔编译器Intel-16.0.3;MPI编译环境选用mvapich2-2.2。
3.1 C5G7-3D基准题
3.1.1 串行计算
图4中给出了串行环境下,RSOR、RSILU-old和RSILU-new预处理GMRES求解一次C5G7-3D单群/多群CMFD线性方程组的迭代次数和计算时间。由图4可知:
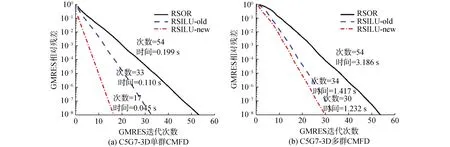
图4 不同预处理算法下串行GMRES的收敛历史Fig.4 Convergence history of serial GMRES method preconditioned by different preconditionor
1) 3种的预处理算子中,RSILU-new收敛最快,计算用时也最少,RSILU-old次之,最次是RSOR;
2) RSILU-new针对单群CMFD的预处理效果要优于多群CMFD。单群CMFD下RSILU-new预处理效果显著优于RSILU-old;多群CMFD下RSILU-new的预处理效果略优于RSILU-old。
3.1.2 并行计算
图5和图6给出了不同核数下BJILU、RSILU-old和RSILU-new预处理GMRES求解C5G7-3D单群/多群CMFD线性方程组的迭代次数和计算时间。图7和图8分别给出了不同核数下RSOR、BJILU、RSILU-old、RSILU-new、和串行ILU(SILU)预处理GMRES求解C5G7-3D单群/多群CMFD线性方程组的残差收敛历史。其中,SILU是指GMRES在串行环境下用ILU(0)作预处理时的收敛结果,用作对照,以显现出各种预处理算法在并行核数逐渐增加时的预处理效果的变化趋势。
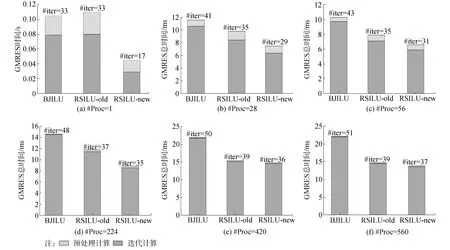
图5 不同预处理算法下并行GMRES求解C5G7-3D单群CMFD计算时间比较Fig.5 Computing time of parallel GMRES preconditioned by different preconditionor for one-group CMFD of C5G7-3D

图6 不同预处理算法下并行GMRES求解C5G7-3D多群CMFD计算时间比较Fig.6 Computing time of parallel GMRES preconditioned by different preconditionor for multigroup CMFD of C5G7-3D

图7 不同预处理算法下并行GMRES求解C5G7-3D单群CMFD收敛历史比较Fig.7 Convergence history of parallel GMRES preconditioned by different preconditionor for one-group CMFD of C5G7-3D

图8 不同预处理算法下并行GMRES求解C5G7-3D多群CMFD收敛历史比较Fig.8 Convergence history of parallel GMRES preconditioned by different preconditionor for multigroup CMFD of C5G7-3D
不同预处理算法比较如图5~8所示,可知:
1) 随着并行核数的增加,RSILU-old、RSILU-new和BJILU的预处理GMRES计算时间逐渐减少,GMRES迭代次数逐渐增加,但迭代次数随核数的增长地很缓慢;
2) 随着并行核数的增加,RSILU-old和RSILU-new的预处理效果的差距不断缩小,但RSILU-new效果始终不差于RSILU-old,且始终优于BJILU;
3) RSILU-new针对单群CMFD的预处理效果要优于多群CMFD,且RSILU-new针对单群CMFD的预处理效果甚至可以超过SILU (如图7中的(a)~(c)所示)。
3.2 VERA problem #4 基准题
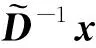
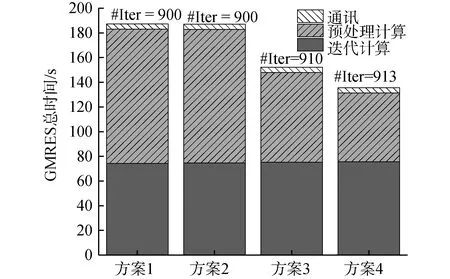
图9 不同计算方案下的RSILU-new预处理并行GMRES用时Fig.9 The calculation time of RSILU-new preconditioned parallel GMRES method with different strategy
BJILU、RSILU-old和RSILU-new预处理效果的测试结果如表2和图10所示。从结果中可以看出:不论是单群CMFD还是多群CMFD、BJILU和RSILU-old相比,RSILU-new预处理效果都是最优的,不仅GMRES的迭代次数是最少的,而且迭代计算和预处理计算的耗时也是最少的。其中,RSILU-new的预处理计算耗时仅是RSILU-old的1/2左右。整体GMRES的计算耗时相比于优化之前减少30%。
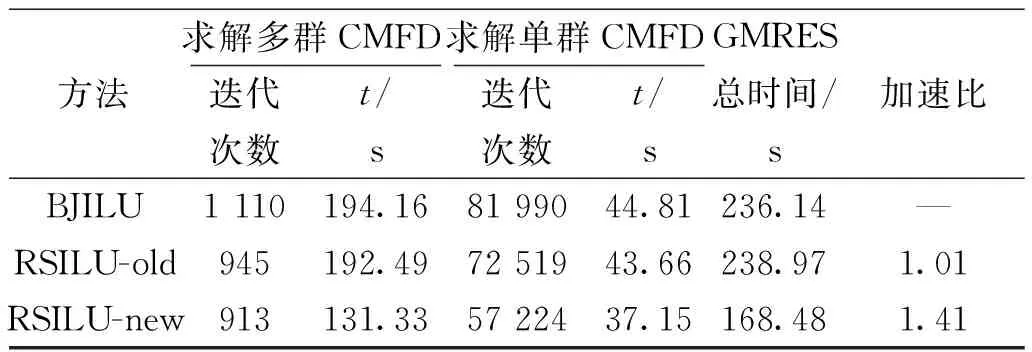
表2 BJILU、RSILU-old和RSILU-new预处理并行GMRES完整求解VERA problem #4基准题Table 2 BJILU, RSILU-old and RSILU-new preconditioned parallel GMRES for solving VERA problem #4 benchmark

图10 BJILU、RSILU-old和RSILU-new预处理GMRES用时Fig.10 The calculation time of GMRES precoditioned by BJILU, RSILU-old and RSILU-new
3 结论
1)优化后的RSILU弥补了该方法之前的一些缺陷,进一步提高了RSILU预处理并行GMRES方法求解大规模CMFD线性方程组的计算效率。
2)本文中的并行GMRES算法仅基于MPI编程模型,未来可开发MPI和OpenMP混合并行编程技术进一步减少处理器间的通信时间,从而提高并行效率。
