基于循环一致生成对抗网络的多模态影像刚性配准
2021-02-07郭翌吴香奕吴茜陈志徐榭裴曦
郭翌,吴香奕,吴茜,陈志,徐榭,裴曦
1.中国科学技术大学物理学院工程与应用物理系,安徽合肥230026;2.安徽医科大学,安徽合肥230032
前言
图像配准是大多数医学影像分析问题的一个基本步骤,广泛应用于医学诊断、手术放射治疗规划、图谱构建、增强现实、疗效分析评价和医学图像分割等[1-3]。医学影像配准分为刚性配准与非刚性配准,其中刚性配准方法通过寻找固定图像(Fixed Image)和浮动图像(Moving Image)之间的旋转平移变换矩阵对齐两幅图像[4]。刚性配准不仅为进一步的非刚性配准提供前提基础、节省图像优化迭代的计算时间,同时能直观地显示不同模态之间图像的解剖结构差异,辅助医生进行准确勾画。传统的配准方法包括基于表面的方法、基于点的方法(通常基于解剖标记物)和基于体素的方法[5]。尽管基于表面的方法和基于点的方法在图像配准中仍占有一席之地,但基于体素的方法借助于计算机技术快速发展的优势而得到了广泛应用[5]。基于体素的方法的目标是通过计算两个输入图像之间的相似性获得几何变换参数,而不需要预先提取特征[6]。但是这些传统的配准方法往往需要迭代计算相似性度量如均方误差、互信息与归一化互信息(NMI)等,由于相似性度量在参数空间上的非凸性等问题,使得配准过程较为耗时且鲁棒性较差[1-2]。除此之外,其他方法如基于强度的特征选择算法通过提取出与强度对应的图像特征进行图像配准,然而提取出的特征在解剖学方面难以很好地对应[7-9]。
近年来,深度学习方法在图像分割、图像变换、图像分类和高分辨率图像重建等许多领域取得了巨大成功。已有文献报道深度学习方法在图像配准中的应用,证实该方法的可行性。Miao等[10]使用卷积回归神经网络(CNN)进行实时的数字重建放射影像和X-ray影像的刚性配准。Liao等[11]采用CNN和强化学习方法对计算机断层扫描影像(CT)和锥形束CT影像进行迭代刚性配准。Jaderberg等[12]提出空间变换网络进行输入图像的空间对齐。为了改进CNN网络鲁棒性不足的问题,Miao等[13]利用全卷积神经网络(FCN)代替CNN进行脊柱的2D/3D刚性配准。另外,Gutierrez-Becker等[14]采用有监督式的回归网络模型进行脑部核磁共振图像(MRI)的刚性配准。尽管上述网络模型比传统迭代计算配准方法提升了配准速度,但是这些网络模型大多是有监督网络(即需要预先配准好的真实结果)或者需要使用相似性度量参数,这从数据获取与配准结果精确度的角度上阻碍了网络模型的训练。
生成对抗网络(Generative Adversarial Networks,GANs)是一种深度学习网络模型,它至少由两个部分组成:生成器和判别器,使得生成的数据具有与真实数据相同的分布[15]。为了克服在某些应用中获取图像对的困难,Zhu等[16]和Isola[17]等提出了循环一致生成对抗网络(Cycle-consistent Generative Adversarial Networks, CycleGAN),该网络能够在没有成对训练数据的情况下,学习从输入到输出图像的映射。近年来,一些基于GANs的医学图像配准研究已经被报道。Tanner 等[18]通过结合两种多模态图像相似性测量NMI 和模态独立邻域描述符(Modality Independent Neighborhood Descriptor,MIND)研究GANs在多模态医学图像配准中的应用,但是该研究仅将GANs用于生成中间图像,而非直接用于图像配准。Fan 等[19]提出了一种对抗性相似网络自动学习相似性度量,用于训练脑部MRI 配准。Mahapatra 等[1]在成本函数中采用了新的约束条件,将GANs用于多模态医学图像配准,确保训练后的网络能够轻松生成真实、具有合理变形场的图像。尽管上述工作在一定程度上验证了GANs 在图像配准方面应用的可行性,这些方法在神经网络训练过程中仍需要有真实配准结果对判别器进行训练,因此这些网络容易受到配准结果质量的影响。
本文提出一种基于CycleGAN 的CT 与MR 图像3D 刚性配准网络,该网络与其他图像配准神经网络相比,具有如下特点:(1)完全无监督性,即不需要预先配准的真实结果;(2)端对端网络,即不产生中间图像,只需输入待配准的图像即可得到配准结果;(3)不需使用传统的相似性度量参数。
1 材料与方法
1.1 数据预处理
神经网络训练前需要对图像数据进行预处理。良好的数据预处理能够帮助神经网络加速收敛,同时得到更精确的结果。本研究采用75例腹部病例作为训练与测试数据集,每个病例包含1幅CT图像与1幅MR图像。所有图像数据(包括CT与MR数据)均进行图像标准化处理,同时将所有病例进行图像重采样并进行图像剪裁。重采样后的图像分辨率为1 mm×1 mm×5 mm,图像剪裁后大小为400 mm×400 mm,去除多余的空气部分。为使图像细节更为突出,设置CT图像像素值的窗宽窗位分别为350和40,即将图像原本的CT值范围限制在(-135,215)范围内,MR图像不变。完成以上步骤后,对图像数据进行归一化,将所有图像像素值映射到(-1,1)范围内。所有图像数据分为训练数据集与测试数据集,其中65例病例作为训练数据集,10例病例作为测试数据集,并与Elastix软件配准结果进行比较。
1.2 网络训练流程
本研究的神经网络结构基于CycleGAN 网络模型[16-17],网络主要分为4 个部分:两个生成器GAB、GBA和两个判别器DAB、DBA,其中A 为浮动图像,B 为固定图像。刚性变换参数为F,则GAB产生由A 到B 的变换FAB,GBA产生由B到A的变换FBA,DAB和DBA分别用于评价配准后两幅图像的配准程度。整体网络训练流程如图1所示。
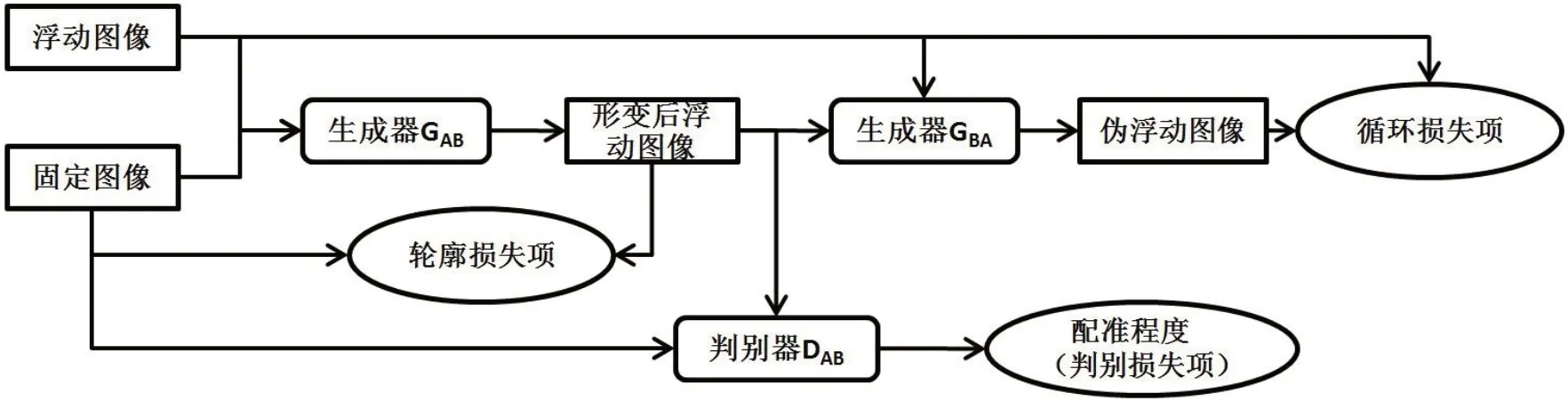
图1 网络训练流程示意图Fig.1 The flow chart of training process
1.3 生成器网络
生成器的目的是根据输入的图像对得到刚性变换参数,具体结构如图2 所示。网络输入为多模态3D 图像对,输出为刚性变换参数与配准后的图像。GAB与GBA的网络结构一致,区别在于GAB中的固定图像为GBA中的浮动图像,GAB中的浮动图像为GBA中的固定图像。生成器网络的输出结果作为判别器网络的输入之一。
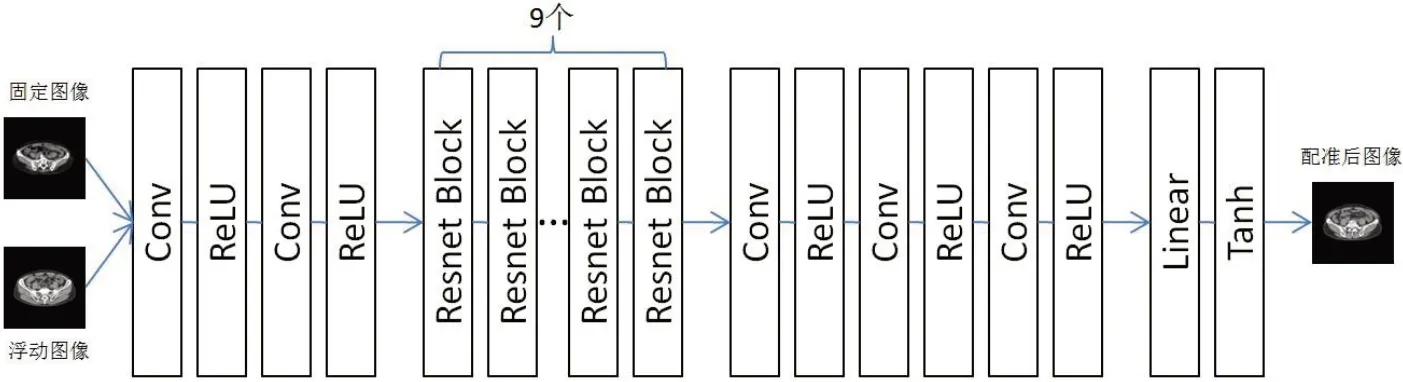
图2 生成器网络结构Fig.2 The structure of the generator network
1.4 判别器网络
判别器网络的目的是根据输入的图像对判断两幅图像的配准程度,具体结构如图3所示。网络的输入为配准后的图像对,输出为图像对的配准程度。图像配准程度用0 至1 区间的数表示,输出结果越接近1,表示图像配准程度越高,输出结果越接近0,表示图像配准程度越低。DAB与DBA的网络结构一致,区别在于DAB中的输入图像对为固定图像与配准后的浮动图像,DBA中的输入图像对为浮动图像与配准后的固定图像。
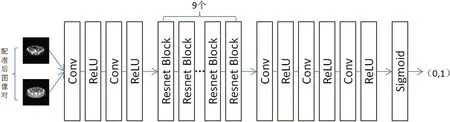
图3 判别器网络结构Fig.3 The structure of the discriminator network
1.5 损失函数
神经网络训练涉及到损失函数的选择,不同的损失函数对网络训练结果具有较大影响。本研究在CycleGAN 网络损失函数的基础上进行了改进,添加了新的损失项,能够对网络进行约束,使得网络更容易收敛。生成器网络的损失函数主要由3 个部分组成:(1)判断损失项L1。该损失项与判别器相关,其作用是使由生成器产生的配准图像对能够“瞒过”判别器,令判别器判定配准结果准确可靠。该损失项的具体公式如公式(1)所示,其中DAB为判别器,A 表示固定图像,B 表示配准后的浮动图像。(2)轮廓损失项L2。为使网络更易收敛,引入待配准图像的轮廓信息作为约束条件,使配准过程朝轮廓重叠的方向进行。其中轮廓信息为图像的外轮廓,损失项为配准图像轮廓之间的Dice 系数,如公式(2)所示,ContourA和ContourB分别为固定图像与配准后浮动图像的外轮廓信息。(3)循环损失项L3。大部分关于图像配准的神经网络只考虑前向传播过程而忽略反向过程,即只训练从浮动图像配准到固定图像,而忽略从固定图像配准到浮动图像,因此这样的网络不具备循环一致性,网络训练的结果不够可靠。为了克服这一缺点,CycleGAN 加入了循环损失项,保证了结果的一致性。如公式(3)所示,其中B'表示浮动图像,A表示固定图像。总的生成器网络损失函数LG如公式(4)所示。除了生成器网络具有损失函数之外,判别器网络的损失函数如公式(5)所示,其中D代表判别器,公式的第1项表示由生成器产生的图像经判别器判断为假,公式第2项表示对于配准好的图像经判别器判断为真。
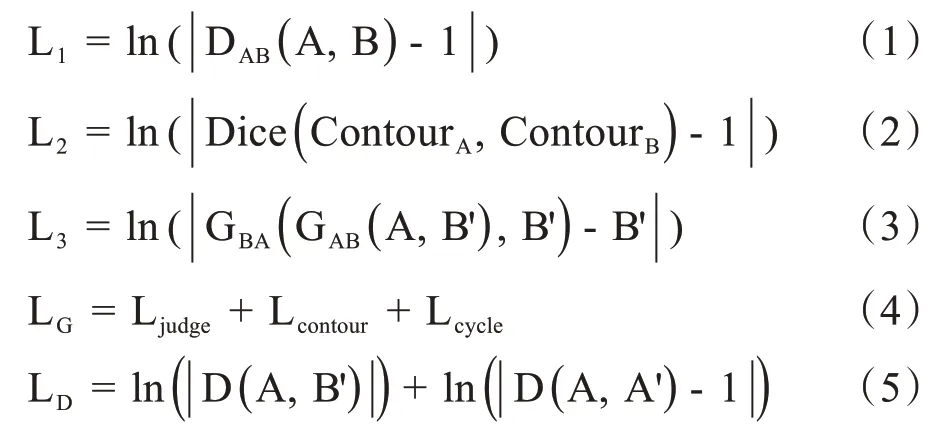
在判别器训练过程中,需要为判别器提供判断依据,即输入参考结果。大部分基于GANs网络的配准工作均采用了预先配准好的医学图像对参考结果进行训练[1,19]。这些方法的缺点在于:(1)需要采用其他传统迭代方法对图像对进行预先配准,无法保证配准结果的准确性与稳定性。(2)网络训练的精度随预先配准结果的精度而变,且不能超过预先配准方法的配准精度。为了避免采用传统迭代方法进行预先配准的缺点,考虑在图像配准过程中影响配准结果的主要因素为图像对之间的像素分布情况和轮廓形状等,次要因素为图像对之间对应位置像素值之间的差异,因此构造出与固定图像具有相同像素分布的图像代替采用传统迭代方法得到的配准结果图像。公式(5)中A'表示与固定图像具有相同的像素分布,同时像素值不同的构造图像。
1.6 硬件平台
本研究中所采用的硬件设备参数如下:操作系统为64位Windows10操作系统,CPU为Intel i7-8700K,主频 为3.70 GHz,内 存 为16 GB,GPU 为NVIDIA GeForceGTX 1070 Ti,显存为8 GB。由于计算机显存限制,在网络训练过程中需要限制输入图像大小。本研究对原始输入图像进行了重采样与剪裁,生成器与判别器的输入图像尺寸为128×128×24。
2 结果
本研究共应用75 例腹部病例作为训练与测试数据集,其中65例病例作为训练数据集,10例病例作为测试数据集。采用Python与Pytorch作为神经网络搭建语言与框架,使用Adam 作为网络的优化器[20]。我们将提出的方法与Elastix[21-22]配准结果进行对比,详细比较了传统迭代配准方法与本方法之间的配准精度与配准时间。
2.1 网络训练结果
网络训练的学习率前400次循环为0.000 1,400~600次循环为0.000 05,600~1 000次循环为0.000 01,总循环次数为1 000。神经网络训练总共耗时3 h。图4为网络训练结束后生成器损失函数曲线图,其中黄线代表轮廓损失项,绿线代表判断损失项,红线代表循环损失项,蓝线代表生成器总损失项。曲线图的横坐标表示训练迭代次数,纵坐标表示损失值。所有损失项均取对数。
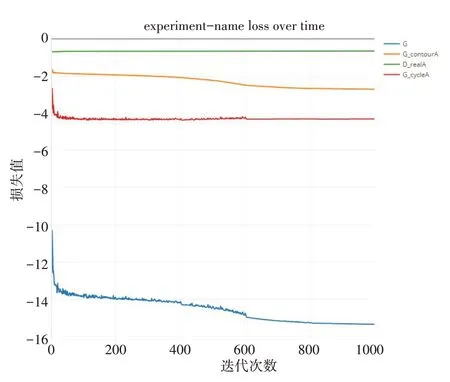
图4 神经网络生成器损失函数曲线图Fig.4 Loss function curve of the network
可以看出,网络训练在前20 次循环训练时损失项下降较为迅速,20~600 次循环训练之间下降速度变缓,600 次循环训练后损失函数趋于平缓。其中,轮廓损失项下降梯度较小,循环损失项对生成器总损失函数下降的贡献率较大,保证了网络训练结果是循环一致的。
2.2 结果对比
分别采用本研究提出的方法与Elastix 对测试集图像数据进行3D 刚性配准,分别计算未配准前与配准后图像对之间的Dice系数进行比较。10例测试病例的配准前CT与MR图像之间外轮廓Dice系数与采用不同方法配准后的图像对Dice 系数:配准前10 例测试病例的Dice 系数为0.858,Elastix 配准结果平均Dice 系数为0.926,本研究方法配准结果平均Dice 系数为0.925。可以看出采用Elastix配准软件与本研究方法进行刚性配准后图像对的Dice 系数均比配准前有所提高,同时本研究方法的配准精度与Elastix 配准结果相当。在配准耗时上,Elastix软件配准平均耗时12.1 s,而本方法为0.04 s,平均加速比达到了302。由于医学影像往往在刚性配准后还需要进行形变配准,因此快速有效的刚性配准方法能够缩短图像配准流程的时间,提高效率。
图5 显示配准前图像对以及采用不同方法配准后图像对之间的差异。其中差异图像中红色部分代表浮动图像,绿色部分代表固定图像。对比不同刚性配准方法得到的结果,可以看出Elastix 配准结果与本研究方法配准结果基本一致。
2.3 结果分析
上述结果表明采用CycleGAN 方法进行腹部3D多模态影像刚性配准具有良好的应用性,既保证了配准结果精度,又极大缩短了配准时间。由于网络训练完全无监督,不要求真实配准结果,该网络易于扩展到其他部位多模态影像配准(如头颈部病例),同时本研究将在刚性配准基础上进一步将网络拓展至多模态影像弹性配准。
3 讨论
传统的医学图像配准大多采用迭代计算方法,相对耗时。同时迭代计算的相似性测度在参数空间上可能存在有非凸性问题,因此在配准过程中往往需要根据不同情况选择合适的相似性度量以及优化方法才能达到满意的配准需求。本文提出了一种基于CycleGAN 的3D 多模态影像刚性配准方法,相比较于其他已有的图像配准网络,该网络是端对端的无监督网络,不需要预先配准的真实结果,同时在网络训练过程中不需采用任何的相似性测量。在原有CycleGAN 损失函数基础上,本研究提出了新的函数损失项,有助于神经网络朝预定方向训练,同时增强了网络的收敛性。测试结果表明,与传统迭代配准方法相比,本研究提出的方法极大降低了图像配准时间,保持了图像配准精度。
