基于改进Tiny-yolov3算法的安全帽佩戴检测
2021-02-07钟鑫豪龙永红何震凯李培云
钟鑫豪,龙永红,何震凯,李培云
(湖南工业大学 交通工程学院,湖南 株洲 412007)
0 引言
在铁路施工中,安全是施工项目中最重要的一部分,每年在施工工程中由于未佩戴安全帽导致的安全事故时有发生。在国内,人工监测安全帽的佩戴占大多数,这不仅耗时耗力,如果监管不力还会导致严重的后果。因此,智能检测施工人员佩戴安全帽就十分有益,对此,本文通过图像处理的方式对施工人员佩戴安全帽的检测进行了研究。
国内外学者对此都做了大量的工作和研究,现有的检测佩戴安全帽的目标检测方法主要为两类。
另一种方法则是基于深度学习的目标检测识别算法。该方法凭借着卷积神经网络的无需手动设计图像特征这一优势[4-5],逐渐获得许多研究者的青睐。对于该类方法目前的目标检测方法主要有两类,第一类是“two-stage”深度学习方法,它基于区域提名,输入图片进去先生成候选框,然后对生成的候选框进行分类。例如R-CNN[6-8]、R-FCN[9]等算法。第二类则是“one-stage”的端对端深度学习算法,输入图片后直接对整个图片进行预测、定位和分类。例如yolo、SSD[10]等算法,此类方法由于在检测步骤上比第一种方法简化了一些步骤,因此检测速度较第一类快,但是精度较低。虽然基于深度学习的目标检测方法相比于传统的目标检测方法有着鲁棒性较高、检测精度较好的特点,但是由于卷积神经网络的复杂性,对图片集的训练将消耗许多计算资源,并且要达到实时检测的目的对计算机的配置要求很高。因此,本文提出一种改进Tiny-yolov3 的安全帽检测方法。
1 Tiny-yolov3 算法改进
1.1 Tiny-yolov3 算法简介
yolo 系列算法是J. Redmon 等[11-13]提出的基于深度学习的目标检测模型,由于它的提出是为实现高精度的在线目标检测,因此yolo 系列算法采用的是one-stage 的目标检测算法,其中yolov3 是该系列中最新提出的改进算法。并且该算法在Coco 等数据集上有不俗表现,在工业和商用上均有广泛的应用。而本次采用的Tiny-yolov3 算法是在yolov3算法的平台上的轻量级的实时检测算法,将yolov3上的特征网络Darknet-53 的53 层神经网络简化为13 层,因此它的检测速度比yolov3 快许多。其卷积结构仍然使用与yolov3 相同的全卷积网络(convolutionl networks,FNC)和批量标准化(batch normalization)等。
Tiny-yolov3 结构如图1 所示,它主要由卷积层和池化层构成,分别有7 层卷积层和6 层池化层(max pooling),网络中每层卷积层或者池化层后的特征图尺寸分别表示分辨率宽、分辨率高、通道数。

图1 Tiny-yolov3 网络结构图Fig. 1 Tiny-yolov3 network structure diagram
Tiny-yolov3 的工作流程如下:首先,输入一张图片,将图片划为S×S的网格,而每个网格内出现B个预测框;然后对预测框内的目标进行类型检测;最后输出检测目标的置信度和检测框。而置信度的计算式为

式中:Pr(o)为目标o存在的概率,一般为0 或者1;Riou为预测框和真实包含目标框的交并比。
因此,置信度的数值是由每个网格中包含检测目标的概率和预测框的准确度共同决定的。
训练模型时,Tiny-yolov3 使用的损失函数与yolov3 相同,主要由预测框的位置(x,y),预测框的长宽(w,h),预测类别(class),以及预测置信度(confidence)确定。损失函数公式如下:
肺癌患者机体免疫功能低下,临床上采用放化疗、手术以及侵袭性操作治疗增加了患者对病原菌的易感性,极易引起患者院内感染[1-8]。由于临床上大量广谱抗生素的应用,以前无致病或致病能力弱的细菌导致的感染不断增多,细菌也出现严重耐药性。合并感染会增加患者的治疗难度,影响预后,严重者可导致死亡[3-4]。为探讨肺癌患者院内感染的相关危险因素,本文回顾性分析83例肺癌患者合并院内感染的临床资料,现报告如下。
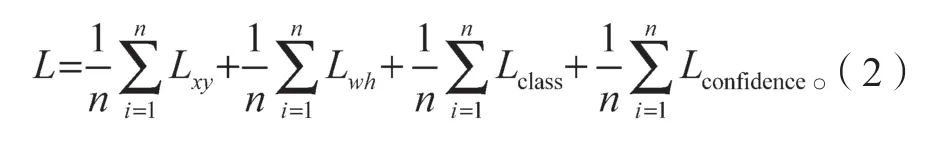
式中:n为预测框个数;Lxy为预测框位置误差;Lwh为预测框长宽误差;Lclass为类别预测误差;Lconfidence为置信度误差。
1.2 添加残差网络
由于Tiny-yolov3 的神经网络采用了yolov3 的简化神经网络模型,因此与yolov3 相比,其速度快上许多,但是检测精度随之下降。提高深度学习模型的检测精度最常用的方法是增加网络深度,即增加卷积层数。卷积神经网络层数越深,收敛的可能性越小,浅网络提取的小对象的特征随着网络的加深而被稀释。如果网络太深,当在图层之间传递要素信息时,也会导致要素信息丢失。因此,课题组在原始网络的第4 层和第7 层之间添加了残差网络结构。残差网络使用1×1 个卷积层和3×3 个卷积层提取特征。将输入结构之前的特征图添加到残差结构之后生成的特征图中,同时将浅层信息和深层信息传输到下一个卷积层以提取特征。这样,可以减少在层之间通过时特征信息的这种丢失,并且可以提高网络检测的准确性。残差模块如图2 所示,其中n指输入通道数,C指通道数,t指通道扩张或压缩的倍数。

图2 残差网络结构Fig. 2 Residual network structure
1.3 损失函数与筛选预测框的改进
Tiny-yolov3 的评估方法与yolov3 相同,交并比(intersection over union,IOU)是预测框与真实框的交并集,是目标检测重要的评估方法。由交并比能得出损失函数,目标检测的损失函数一般由分类损失函数(classificition loss)和回归损失函数(bounding box)构成。而由于Tiny-yolov3 的初始Riou存在一些问题:
1)当预测框和真实框不相交,即Riou=0 时,Loss 值无法进行评估;
2)当存在两框重叠并且Riou相同的情况,但是位置预测框位置不相同时,Loss值无法区分相交情况下的不同。因此,课题组提出用距离交并比DIOU_Loss(Distance_IOU_Loss)来代替IOU_Loss做损失函数的评估。距离交并比计算式如式(3)。

式中:A为真实框;B为预测框;为真实框和预测框的交集区域;为真实框和预测框的并集区域;Deuclidean为最小外接框对角线距离;Dcenter为两个中心点的欧氏距离。
本文将原算法中的筛选预测框的NMS 算法Rdiou改进为Ldiou算法,如式(4)所示:

当使用DIOU 算法来检测目标时,将会考虑预测框、真实框的重叠面积和两者的中心距离,当存在预测框在真实框里面时,直接计算两个框之间的距离,从而达到快速收敛的目的,并且解决了无法区分预测框在真实框内部时无法区分相对位置的问题。
2 实验
2.1 实验平台
本文的实验是在windows10 环境下完成的算法搭建,硬件环境如下:处理器,AMD Ryzen5 3600 3.6 GHz;GPU 显卡,RTX2060SUPER,显卡的内存为8 GB;计算机内存为16 GB。软件上安装了Visual Studio2015、python 3.6.5,并且同时安装了CUDA10.3 和cudnn9.0.0,以支持NVIDIA GPU 的使用,深度学习框架为Caffe[14]。
2.2 数据集制作
本文针对所研究的问题,制作了一个规模适中的数据集。数据来源于监控视频截图、网络爬虫和图片库收集。为保证训练出的模型具备较高鲁棒性和多场景检测能力,样本图片中的施工人员的拍摄角度各异,光照的条件也有所不同。课题组按照Pascal VOC 的数据集格式构建了自己的数据集,数据集包括5 323 张图片,并采用labellmg 工具对图像进行分类和标定后生成XML 文件,界面见图3 所示。

图3 labellmg 界面Fig. 3 Labellmg interface
标记者的类型和坐标位置信息,通过程序将XML 文件转换为TXT 文件输入到训练集中。本实验按照7:2:1 的比例设置训练集、验证集和测试训练后的模型集。
2.3 实验指标
本实验的结果评估标准主要为识别准确率p(precision)、召回率r(recall)、平均精确率均值(mean average precision,mAP)和检测速度FPS。首先,p表示在识别的正样本中,真实样本所占的比率,即
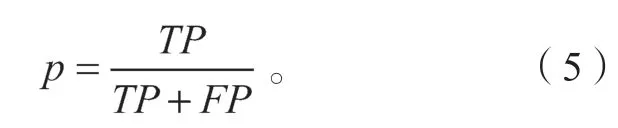
式中:TP为正确分类为正样本的数;FP为将目标错误分为正样本的数。
r表示识别正确的正样本在总样本数中所占的比例,即
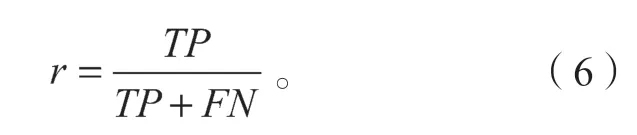
式中FN为被错误划分为负样本的正样本数。
如果只用precision 或recall 作为衡量一个模型检测精度的优劣显然不合适。因此,课题组还需要目标检测中最重要的指标之一的mAP,是多个验证集的平均AP 值,mAP 是由Precision-recall 曲线与坐标轴包围区域的面积。n为计算的组数,则差值近似的公式为
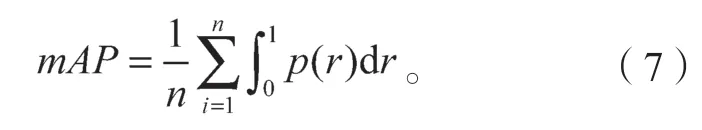
2.4 实验结果分析
课题组使用官网上提供的Tiny-yolov3 的权重参数作为权重训练的初始参数,并根据自制的训练集进行参数微调以达到最佳训练效果,部分试验参数调整如表1 所示。
网络参数按照表1 进行了Tiny-yolov3 和本文改进后的Tiny-yolov3 算法训练和验证,并分别计算了识别准确率p、召回率r、平均精确率均值mAP和检测速度FPS,结果如表2 所示。
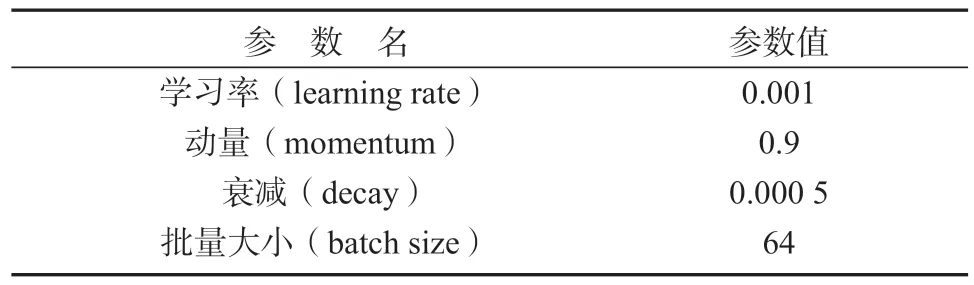
表1 网络参数说明表Table 1 Network parameter description table

表2 各算法的检测结果参数Table 2 Parameters of detection results of each algorithm
从表2 所示结果来看,改进后的Tiny-yolov3 在准确率和召回率上分别有着4.6%和3.9%的提升,在最关键的mAP上也有4.1%的提升。由于改进的网络上增加了残差结构,因此比原网络的FPS慢一点,但是影响不大,依然能满足实时性的要求。另外,为了更直观地表现两种算法的差异,选取了一些两种算法检测的效果图。图4 为本文安全帽佩戴检测改进算法与原算法Tiny-yolov3 的比较结果图。其中,图a、d、g 为原图,图b、e、h 为Tiny-yolov3 检测结果,图c、f、i 为本文改进的Tiny-yolov3 算法的实验结果。对原图1 的检测中,图b 漏检了左前的一位佩戴了安全帽的人,图c 没有漏检;对原图2 的检测中,图e 漏检了后面佩戴了安全帽的人和被遮挡的人,图f 没有漏检佩戴安全帽人员,但是漏检了一些被遮挡的人;对原图3 的检测中,图h 中漏检了后面的2 人与右侧的人,图i 无人漏检。从实验结果比较来看,本文的改进算法能更好地检测出小目标。


图4 实验结果Fig.4 Experimental results
3 结语
本文基于Tiny-yolov3 的深度学习算法,通过在特征提取网络上加入残差网络模块,在不太影响检测速度的情况下,提高了小目标特征的获取。同时,在损失函数与筛选框的优化中,引入了DIOU_Loss 的重合边界框的误差计算以提高目标的识别准确率。通过理论分析与实验结果表明:改进后的Tiny-yolov3与原算法相比,识别准确率提高了4.6%,召回率提高了3.9%,平均精确率均值提高了4.1%,帧率达到63 帧/s,满足实时监测的要求。但是,与yolov3 等大型检测网络比起来,小目标检测的识别准确率有待加强。因此,接下来的工作是如何提高更小目标的检测准确率。
