基于语义分割的红外和可见光图像融合
2021-02-06周华兵侯积磊张彦铎吴云韬马佳义
周华兵 侯积磊 吴 伟 张彦铎 吴云韬 马佳义
1(武汉工程大学计算机科学与工程学院 武汉 430205)2(智能机器人湖北省重点实验室(武汉工程大学) 武汉 430205)3(武汉大学电子信息学院 武汉 430072)(zhouhuabing@gmail.com)
图像融合是一种增强技术,其目的是将不同类型传感器获取的图像结合起来,生成一幅信息丰富的图像,以便于后续处理[1].通过不同类型传感器获取的图像一般并不是对齐的,会有一定的偏移,需要配准后才能融合[2-4].本文主要解决精确配准条件下的图像融合问题,其在语义上具有逐像素(per pixel)的对应关系.
红外和可见光图像融合是图像融合的重要分支,红外图像可以根据辐射信息来突出目标,并且不受天气和光线的影响,可见光图像拥有较高的分辨率,图像更清晰,符合人类视觉习惯[5-8].红外和可见光图像融合既可以保留红外图像的对比度信息,又可以保留可见光图像的高分辨率.
传统的图像融合方法多是基于多尺度分解的思路.包括拉普拉斯金字塔变换(Laplacian pyramid transform, LP)[9]、双树复小波变换(dual-tree complex wavelet transform, DTCWT)[10]、非下采样轮廓波变换(nonsubsampled contourlet transform, NSCT)[11]等方法.随着视觉显著性相关研究的深入,出现越来越多基于视觉显著性的图像融合方法.Zhang等人[12]提出一种基于显著性区域提取的红外和可见光图像融合方法.首先基于显著性分析和自适应阈值算法提取出红外图像的目标区域,然后采用非下采样剪切波变换得到背景区域融合系数,完成融合任务.但这种方法得到的融合图像中目标区域直接使用了红外图像中的目标区域,丢失了可见光图像中相应区域的信息.
随着深度学习的火爆,近年来,基于深度学习的红外和可见光图像融合方法越来越多.如:Ma等人[13]的FusionGAN使用生成式对抗神经网络来完成融合任务,通过生成器和鉴别器的对抗,来使融合图像保留更丰富的信息.Zhang等人[14]的PMGI从图像梯度和对比度2条路径来提取图像信息,并且在同一条路径上使用特征重用,以避免由于卷积而丢失图像信息.同时,在2条路径之间引入了路径传递块,实现了不同路径间的信息交换,保证了融合图像有更丰富的信息.但这些融合方法都是将红外和可见光图像整体放进同一个网络框架下,对源图像中的目标和背景采用同一种处理方式,没有针对性,不可避免地损失了源图像的部分信息.
红外和可见光图像具有丰富的语义信息,语义信息可以用来提取图像中的目标区域,也可以遮挡图像中的干扰区域.语义分割可以将图像转换为具有语义信息的掩膜,是计算机视觉研究的热门方向[15].一般的分类卷积神经网络(convolutional neural network, CNN),会在网络的最后加入一些全连接层,经过softmax后就可以获得类别概率信息.但是这个概率信息是1维的,即只能标识整个图像的类别,不能标识每个像素点的类别.Long等人[16]提出的全卷积网络(fully convolutional network, FCN)将CNN的全连接层替换成卷积层,这样就可以获得一幅2维特征图,从而成功解决了语义分割问题.Chen等人[17]提出的Deeplabv3+采用了编码解码网络结构,逐步重构图像空间信息来更好的捕捉物体边界.并在网络结构中引入了空间金字塔池化模块(spatial pyramid pooling, SPP),利用多种比例感受野的不同分辨率特征来挖掘图像多尺度的上下文内容信息.
为了在融合任务中更具有针对性地保留源图像目标和背景区域的信息,本文基于语义分割和生成式对抗神经网络提出了一种新的红外和可见光图像融合方法,在融合任务中引入语义分割,实现了图像融合时对目标区域和背景区域采用不同的融合策略,解决了现有融合方法对源图像不同区域针对性不足的问题.本文的融合结果在目标区域保留了红外图像的对比度,在背景区域保留了可见光图像的纹理细节,图像信息更丰富,视觉效果更好.
1 融合方法
为了实现对目标和背景区域融合时的不同偏好,本文提出一种基于语义分割的红外和可见光图像融合方法,流程图如图1所示,步骤如下:
1) 通过语义分割,得到带有红外图像目标区域语义信息的掩膜Im.
2) 使用掩膜Im带有的语义信息来处理红外图像Ir和可见光图像Iv,得到红外图像的目标区域Ir1和背景区域Ir2,以及可光图像的目标区域Iv1和背景区域Iv2.
3) 将红外图像的目标区域Ir1和可见光图像的目标区域Iv1融合得到融合图像If1.
4) 将红外图像的背景区域Ir2和可见光图像的背景区域Iv2融合得到融合图像If2.
5) 将If1和If2融合得到最终融合图像If.
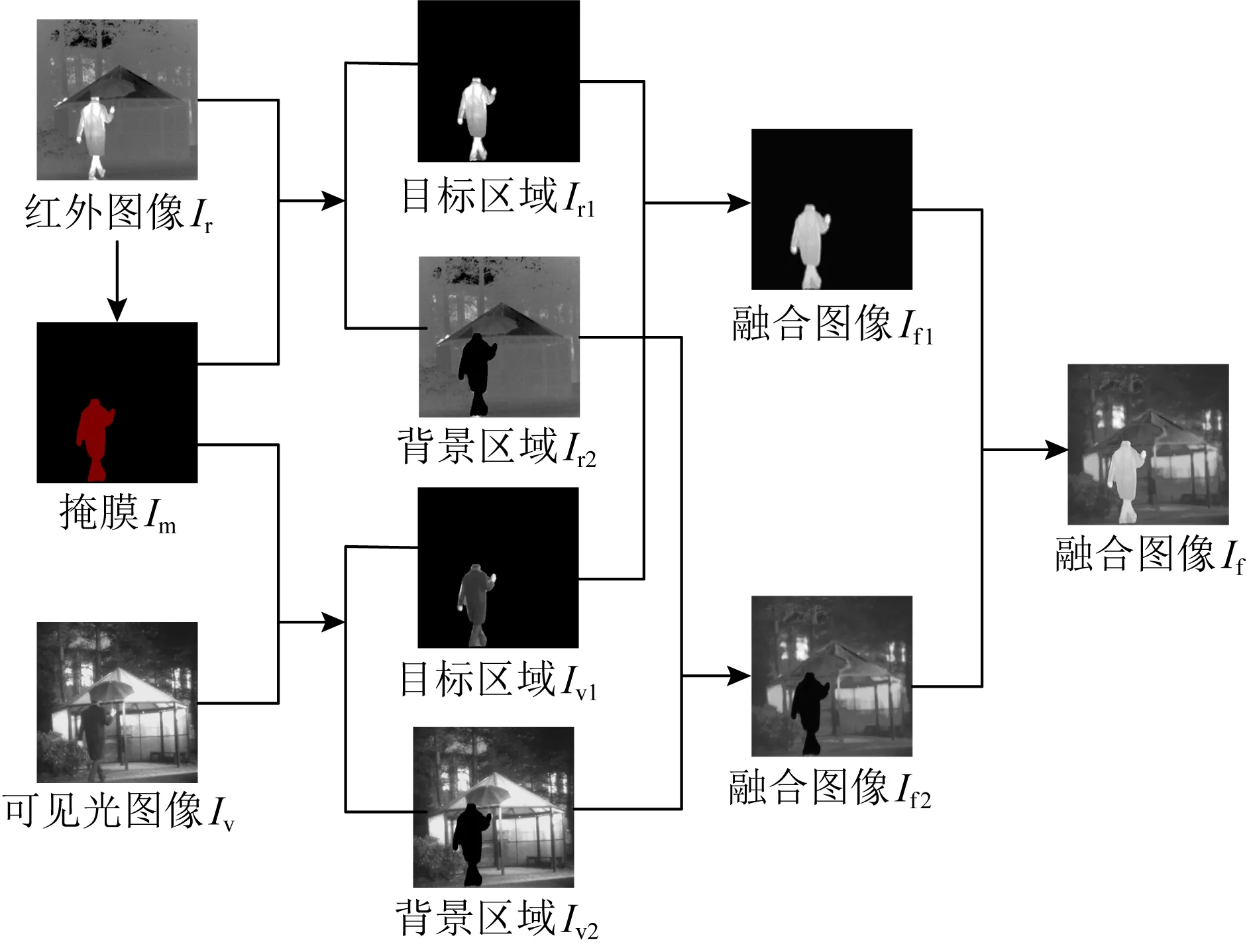
Fig. 1 Schematic of infrared and visual image fusion based on semantic segmentation图1 基于语义分割的红外和可见光融合
2 语义分割
红外和可见光图像融合是为了融合图像目标区域保留更多的红外图像信息,背景区域保留更丰富的可见光图像信息[18].为了达到这个目的,本文将语义分割引入图像融合,用带有语义信息的掩膜提取红外和可见光图像的目标和背景区域.
我们将红外图像和与之对应的标注图作为输入,训练语义分割网络,这里采用Deeplabv3+网络结构.通过此网络,可以得到带有红外图像语义信息的掩膜Im,然后使用掩膜Im提取出红外图像目标区域Ir1和可见光图像目标区域Iv1,如式(1)所示:
Ir1=Im⊙Ir,Iv1=Im⊙Iv.
(1)
接着,再使用掩膜Im将源图像中的目标区域遮挡起来,得到红外图像背景区域Ir2和可见光图像背景区域Iv2,如式(2)所示:
Ir2=(1-Im)⊙Ir,Iv2=(1-Im)⊙Iv,
(2)
其中,⊙为Hadamard乘积.
3 图像融合
3.1 分割图融合
由于融合图像中目标区域和背景区域需要保留的信息差别较大.本文提出的融合方法对目标区域Ir1和Iv1以及背景区域Ir2和Iv2采用不同的融合策略,以便在融合图像不同区域能更具有针对性的保留所需要的信息.
目标区域Ir1和Iv1是为了保留更多红外图像的对比度,要让融合图像If1更接近红外图像目标区域Ir1,网络框架如图2所示.生成器G1的目标是生成融合图像If1去骗过鉴别器D1,鉴别器D1的目标就是将生成融合图像If1和可见光图像目标区域Iv1区分开来,通过这种对抗过程,网络最终能得到信息丰富的融合图像If1.

Fig. 2 Schematic of target area fusion图2 目标区域融合网络结构图
首先将源图像目标区域Ir1和Iv1在通道维度上连接起来,一起输入到生成器G1得到融合图像If1,通过损失函数让融合图像If1保留更多红外图像目标区域Ir1的信息,生成器G1损失函数如式(3)所示:
LG1=Ladv1+λ1L1,
(3)
其中,LG1代表生成器G1整体的损失,λ1是常数,用于平衡2项损失函数L1和Ladv1.Ladv1代表生成器G1和鉴别器D1之间的对抗损失,如式(4)所示:
(4)
其中,N代表融合图像的数量,c代表生成器G1希望鉴别器D1相信的融合图像的值.
生成器G1损失函数中的第2项L1代表目标区域内容损失,如式(5)所示:

(5)
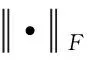
生成器G1在没有鉴别器D1时生成的融合图像会损失大量可见光图像目标区域Iv1的信息.通过生成器G1和鉴别器D1对抗过程,融合图像If1中能加入更多可见光图像目标区域Iv1的信息,鉴别器D1的损失函数如式(6)所示:
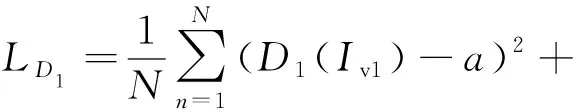
(6)
其中,a和b分别代表Iv1和If1的标签,D1(Iv1)和D1(If1)分别代表Iv1和If1的鉴别结果.
对于背景区域Ir2和Iv2,整体网络框架和目标区域融合网络框架一样采用了生成式对抗神经网络,如图3所示.为了要让融合图像If2更接近可见光图像的背景区域Iv2,我们重新设计了生成器G2和鉴别器D2的损失函数,生成器G2的损失函数如式(7)所示:
(7)
其中,LG2代表生成器G2整体的损失,λ2是常数,用于平衡2项损失函数L2和Ladv2.Ladv2代表生成器G2和鉴别器D2之间的对抗损失,如式(8)所示:
(8)
其中d代表生成器G2希望鉴别器D2相信的融合图像的值.
生成器G2损失函数中的第2项L2代表背景区域内容损失,如式(9)所示:
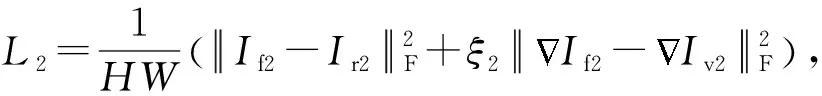
(9)
其中ξ2是常数,用于平衡括号内的左右2项.
生成器G2在没有鉴别器D2时生成的融合图像会损失大量红外图像背景区域Ir2的信息.通过生成器G2和鉴别器D2对抗过程,融合图像If2中能加入更多红外图像背景区域Ir2的信息,鉴别器D2的损失函数如式(10)所示:
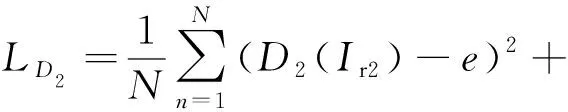
(10)
其中,e和f分别代表Ir2和If2的标签,D2(Ir2)和D2(If2)分别代表Ir2和If2的鉴别结果.
3.2 目标和背景的融合
语义分割后的图像有很多像素为0的区域,这些区域虽然不带信息,对生成器读取图像信息没有影响,但在生成融合图像时,生成器并不能完美识别这些区域,会在这些区域根据学习到的风格生成像素值.为了避免这些像素影响最终融合图像,我们先通过掩膜Im带有的语义信息将融合图像If1中的目标部分提取出来,同时将融合图像If2中的背景部分提取出来,如式(11)(12)所示:
I1=Im⊙If1,
(11)
I2=(1-Im)⊙If2.
(12)
经过处理后的图像I1在目标区域以外区域像素值都为0,I2在背景区域以外区域像素值都为0,我们直接通过简单的像素相加得到最终融合图像If,如式(13)所示:
If=I1+I2.
(13)
3.3 训练过程
本文从公开的对齐数据集TNO(1)https://github.com/Jilei-Hou/FusionDataset中选取了45对不同场景的红外和可见光图像作为训练数据,通过掩膜的语义信息将45对训练数据都分为红外图像目标区域、红外图像背景区域、可见光图像目标区域、可见光图像背景区域4部分.由于45对红外和可见光图像不足以训练一个好的模型,所以本文将stride设置为14来裁剪每一幅图像,裁剪后每个图像块的尺寸都是120×120.这样,我们可以得到23 805对红外和可见光图像块.
对于目标区域Ir1和Iv1,我们从训练数据中选择32对目标区域的红外和可见光图像块,将它们的尺寸填充到132×132作为生成器G1的输入.生成器G1输出的融合图像块尺寸为120×120.然后,将32对目标区域的可见光图像块和融合图像块作为鉴别器D1的输入.我们首先训练鉴别器k次,优化器的求解器是Adam,然后训练生成器,直到达到最大训练迭代次数.在测试过程中,我们不重叠地裁剪测试数据,并将它们批量输入到生成器G1中.然后根据裁剪的先后顺序将生成器G1的结果进行拼接,得到最终的融合图像.
对于背景区域Ir2和Iv2,训练过程中对训练数据裁剪的尺寸与目标区域相同,生成器G2的输入为32对背景区域的红外和可见光图像块,鉴别器D2的输入为32对背景区域的红外图像块和融合图像块.在测试过程中,同样根据裁剪先后顺序将生成器G2的结果进行拼接,得到最终的融合图像.
4 实验与结果分析
本文提出的方法在融合任务中引入了语义分割,为此,我们首先需要构建基于语义分割的红外和可见光图像融合数据集.其次,为了评估本文融合方法的性能,本文选取了FusionGAN,PMGI作为对比实验,通过主观和客观2方面对融合图像进行比较,所有对比实验代码都是公开的源代码,参数均是默认的参数.
4.1 数据集
本文实验所使用的红外和可见光图像来源于公开的对齐数据集TNO.我们首先将图像尺寸统一为450×450,然后挑选出红外图像的目标区域,使用labelme工具对目标区域进行标注,得到红外图像目标区域的标注图(2)https://figshare.com/articles/dataset/TNO_Image_Fusion_Dataset/1008029,再使用Deeplabv3+网络得到带有红外图像语义信息的掩膜,通过掩膜的语义信息将红外和可见光图像分为红外图像目标区域、红外图像背景区域、可见光图像目标区域、可见光图像背景区域4部分.论文发表之后,我们会公开基于语义分割的红外和可见光图像融合数据集.对比实验FusionGAN和PMGI所使用数据与本文实验数据相同,且都将图像尺寸统一为450×450.
4.2 主观评估
主观性能评估是基于人眼视觉系统来评价融合图像质量,因为可见光图像符合人类视觉习惯,所以红外和可见光融合图像应该在一定程度上符合人类视觉习惯.
为了验证本文融合方法的主观性能,选取了几幅图像作为评估数据,如图4所示,前2行分别是红外图像和可见光图像,第3行是掩膜,第4行是FusionGAN的融合结果,第5行是PMGI的融合结果,第6行是本文的融合结果.

Fig. 4 Fusion results of different methods图4 不同方法融合结果
本文的融合方法通过引入语义分割,实现了对目标和背景区域采用不同的融合策略,与FusionGAN和PMGI相比,3组融合图像中,本文方法的融合结果目标区域保留的对比度信息更丰富,能更好地突出目标,有利于目标检测.背景区域本文的融合结果纹理细节保留的更好,第1组融合结果中,方框内树干的边界清晰,颜色保留的也更接近可见光图像,其他2组结果也是这样,特别是在第3组融合结果中表现最明显,相比与FusionGAN和PMGI,我们的融合结果在树梢的细节和天空的颜色上视觉效果都更好.这说明在融合任务中引入语义信息的方法是可行的,融合图像视觉效果明显优于现有的方法.
4.3 客观评估
主观性能评估虽然能根据人类视觉系统来评估融合图像的质量,但是会受人类主观情绪的影响,为了更全面地评估融合图像的质量,本文还采用了客观性能评估.客观性能评估是依赖于数学模型的评估指标,不受人类视觉系统和主观情绪的干扰,是评价融合图像质量的重要手段,但单一的客观评估指标不能充分反映融合图像的质量,因此,本文采用了3种典型的客观评估指标,分别是熵(EN)、标准差(SD)和互信息(MI).
1) 熵
熵(EN)是统计图像特征的一种常用方法,融合图像的熵反映了图像从红外和可见光图像中获取的信息的多少[19],数学定义如式(14)所示:
(14)
其中,L表示图像灰度级,pl是融合图像中灰度值为l的标准化直方图.熵的值越大,说明融合图像中保留的源图像的信息越丰富,融合方法的性能越好.
2) 标准差
标准差(SD)反映了图像灰度值相对于灰度平均值的离散情况[20],定义如式(15)所示:
(15)
其中,F(i,j)表示融合图像F在(i,j)处的像素值,融合图像F的尺寸为M×N,μ表示融合图像的像素平均值.由于人类视觉系统对对比度信息很敏感,人类的注意力会被高对比度区域所吸引.因此,融合图像的标准差越大表明融合图像对比度越高,意味着融合图像的视觉效果更好.
3) 互信息
互信息(MI)是信息论中的基本概念,可以度量2个随机变量之间的相关性.在图像融合中互信息用来度量源图像和融合图像的相关性[21].红外和可见光图像融合互信息定义如式(16)所示:
MI=MIr,f+MIv,f,
(16)
其中MIr,f和MIv,f分别表示红外图像和可见图像与融合图像的相关性.任意一幅源图像和融合图像之间的互信息可用定义如式(17)所示:
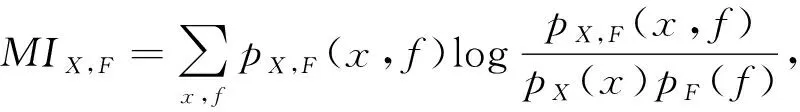
(17)
其中,pX(x)和pF(f)分别表示源图像X和融合图像F的边缘直方图.pX,F(x,f)表示源图像X和融合图像F的联合直方图,互信息越大意味着融合图像与红外和可见光图像相关性越大,融合性能越好.
使用熵、标准差和互信息对5组图像进行客观性能评估,实验结果如表1所示:

Table 1 Objective Evaluation of Fusion Results表1 融合结果客观评估
通过实验表明,相比FusinGAN和PMGI,本文提出的基于语义分割的红外和可见光图像融合方法在3个客观评估指标上表现均为最佳.
熵和互信息有最优的值表明,本文的融合结果从红外和可见光图像中获得的总信息量最多,说明本文的融合方法确实是有效的融合方法,能保留丰富的源图像信息.标准差有最优的值表明,本文的融合图像对比度更高,证明通过引入语义信息,针对性的对目标区域和背景区域采用不同融合方法是有效的,实现了融合图像在目标区域保留更多红外图像信息,背景区域保留更多可见光图像信息.
FusionGAN,PMGI和本文方法的平均运行时间分别为0.058 6 s,0.032 2 s,0.111 8 s.因为本文提出的方法需要目标区域融合网络和背景区域融合网络2个不同的网络,所以本文方法的平均运行时间相比FusionGAN和PMGI有一定增长,但本文方法的融合结果在主客观上相比现有方法提升更为明显.
5 结 论
本文在原有的基于深度学习的红外和可见光图像融合方法基础上,通过语义分割引入图像语义信息,对源图像目标区域和背景区域采用不同的融合方法,以求得到质量更高的融合图像.实验表明,相比现有方法,本文提出的方法达到了预期的效果,融合图像目标区域保留了大量的对比度信息,背景区域保留丰富的纹理细节信息,在主观和客观上都有更好的融合效果.
