多尺度多核高斯过程隐变量模型
2021-02-05周培春吴兰岸
周培春,吴兰岸
(1.玉林师范学院计算机科学与工程学院,广西玉林 537000;2.南宁师范大学计算机与信息工程学院,南宁 530299)
0 概述
在机器学习和模式识别任务中,图像数据作为一种特殊的数据形式广泛应用于人脸识别[1]、表情识别[2]、年龄估计[3]等场景中,而此类数据通常具有较高的维度导致机器学习模型计算复杂度高且容易产生过拟合等维数灾难问题。为应对上述挑战,主成分分析[4]、高斯过程隐变量模型(Gaussian Process Latent Variable Model,GPLVM)[5]、线性判别分析[6]、自编码器[7]和字典学习[8]等数据降维和特征学习方法陆续被提出并取得了较好的成果,其中GPLVM作为一种贝叶斯非参数降维模型,具有非线性学习、不确定性量化和非参数柔性建模等特性[5],近年来在图像识别领域得到广泛应用[9-11]。然而原始GPLVM作为一种无监督的降维模型,利用高斯过程构建由隐变量空间到观测变量空间的映射,进而通过求解最大化似然函数的方式获得最佳隐变量并实现数据降维。
图像数据信息通常分为像素值信息、特征空间信息和语义标记信息3类。像素值信息指图像中各像素值的大小所包含的信息,通常可以被PCA、字典学习、GPLVM等降维方法直接利用,从而实现数据降维。特征空间信息指图像像素及其局部区域之间所具有的相关性信息[12-13]。图像语义标记信息指人们通过自身认知和图像所包含的内容为图像标注的信息[14-15],如图像注释、类别标记等。然而,原始GPLVM在建模过程中仅假设观测变量的特征之间相互独立,因此通常无法有效利用图像数据自身包含的特征空间结构信息和语义标记信息。为此,本文对原始GPLVM进行改进,提出一种多尺度多核高斯过程隐变量模型(Multi-Scale Multi-Kernel Gaussian Process Latent Variable Model,MSMK-GPLVM)。
1 相关工作
1.1 高斯过程隐变量模型
GPLVM是一种无监督的概率、非线性、隐变量模型。在GPLVM定义中,假设已观测到N个样本Χ=[x1,x2,…,xN]T∈ℝN×D,其中xn∈ℝD表示第n个样本对应的输入,本文目标是求解每个观测变量xn对应的隐变量zn∈ℝQ,Q≪D,因此GPLVM可以通过求解观测变量对应隐变量的方式实现数据降维。具体地,GPLVM假设每个样本xn的生成过程如下:

其中:xnd为第n个样本的第d个特征;εnd为噪声项且服从高斯分布p(εn)=N(εn|0,σ2);函数f(d·)具有高斯过程先验,因此fd~N(0,K),fd表示函数f(d·)在隐变量集合Z=[z1,z2,…,zN]上对应N个输出组成的向量;K表示核函数k(·,·)在隐变量集合Z上对应的核矩阵Kij=k(zi,z)j。通过将中间变量fd进行积分可以得到如下边际似然函数:
其中:θ表示GPLVM的核函数及噪声分布中包含的超参数;σ2表示噪声方差;x:,d表示矩阵Χ的第d列元素组成的向量;I表示单位矩阵;|K+σ2I|表示矩阵(K+σ2I)的行列式。在模型优化过程中,GPLVM通过最大化上述似然函数的方式对隐变量Z和超参数θ进行求解,最终实现数据降维。
尽管GPLVM具有较强的非线性学习和不确定性量化等能力,但其却无法有效利用数据的语义标记信息,从而导致在图像分类、人脸识别等任务中的性能无法满足用户需求,其原因主要为GPLVM在模型构建过程中没有对数据标记的生成过程进行有效的建模和表示,因此无法直接将其应用于监督学习任务中。
1.2 监督型高斯过程隐变量模型
为实现GPLVM的监督学习并充分利用数据中包含的语义标记信息,近年来已有一些监督型GPLVM被提出,其中主要包括判别高斯过程隐变量模型(D-GPLVM)[14]、监督高斯过程隐变量模型(S-GPLVM)[15]和监督隐线性高斯过程隐变量模型(SLLGPLVM)[15]。为对监督型GPLVM进行详细说明,假设除了观测变量Χ,本文还获取了每个样本对应的类别标记y∈ℝN,其中第n个元素yn∈{1,2,…,C}表示第n个样本所属类别,C表示类别总数。
为利用数据标记信息,D-GPLVM构建一种基于广义判别分析(Generalized Discriminant Analysis,GDA)的隐变量先验分布,具体如下:
其中:Zd为归一化常量;表示先验的全局伸缩因子;J为依赖于Χ的函数,Sω和Sb分别为在隐变量Χ上依据标记y计算出的类内和类间散度矩阵。将式(3)中的先验分布加入GPLVM中可以获得隐变量Χ后验分布,并通过最大化此后验分布或等价地最小化式(4)获得最佳的隐变量和超参数。

其中,L表示GPLVM的负对数边际似然,LS表示加入监督信息后的对数后验分布。值得注意的是在式(4)中为便于描述,本文省略了对核函数超参数先验的假设,因此在式(4)中缺少文献[15]中所述的超参数正则化项。可以看出,D-GPLVM为GDA与GPLVM结合而成的模型,GDA先验为GPLVM提供了数据标记中包含的语义判别信息。同时可以看出,当σd→0时,D-GPLVM退化为GDA;反之,当σd→+∞时,D-GPLVM退化为GPLVM。
与D-GPLVM不同,S-GPLVM通过分别构建由隐变量到观测变量的类别标记映射方式实现了监督型GPLVM。将样本标记yn转化为由1和-1组成的向量的形式,从而获得样本的标记矩阵Y=[y1,y2,…,yN]T∈ℝN×C。若第n个样本属于第c类,则其对应的标记向量yn中第c个元素的值为1,其他元素的值为-1。S-GPLVM假设Χ和Y均是由隐变量Z通过服从高斯过程的函数生成,且Χ和Y在Z条件下相互独立,进而可以获得隐变量Z的后验分布为:
最终得到如下目标函数:
Ky表示与Y生成相关的核矩阵,表示噪声方差。可以看出,S-GPLVM通过使Χ和Y共享隐变量Z的方式实现了语义标记信息和输入信息的联合建模。这使得隐变量Z具有更优的判别能力,有效提升了GPLVM在分类和回归任务中的性能。
SLLGPLVM通过直接构建由观测变量Χ到隐变量Z的投影方式实现了GPLVM的监督学习。与原始GPLVM类似,其假设隐变量可以通过一个服从高斯过程的函数投影并加入噪声得到观测变量。然而SLLGPLVM假设GPLVM生成标记Y而不是原始GPLVM中的Χ,同时其假设隐变量可以通过一个线性投影函数由输入变量Χ得到,从而构建由Χ到Z和由Z到Y的映射关系,使得GPLVM可以显式地嵌入标记信息。整个生成过程具体如下:
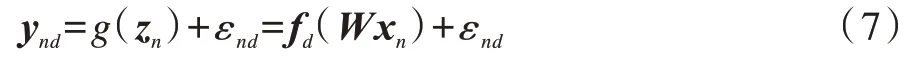
其中,g(·)表示线性投影函数,可以看出SLLGPLVM将隐变量学习问题转化为参数矩阵W的学习问题,因此其具有更少的参数量,同时能够有效解决D-GPLVM中先验信息与真实数据信息不相符的问题,以及S-GPLVM中需要存储和操作两个核矩阵K和Ky所导致的高复杂度问题。
1.3 现有模型存在的问题
虽然现有监督型GPLVM已在某些特定任务中有效提升了GPLVM隐变量的判别性能,但是这些模型仍然存在一定问题从而限制了其应用范围,如D-GPLVM和S-GPLVM在对新样本进行预测时需要通过优化求解方式计算出对应新样本的隐变量,因此预测的时间复杂度过高,限制了其在快速预测任务中的应用。尽管这两个模型均可以通过添加反向约束[16]的方式实现非优化式的预测,但该反向约束同时也限制了模型的表示能力。SLLGPLVM利用构建由输入变量到隐变量的线性投影方式实现新样本的快速预测,然而此类简单的线性映射通常无法满足真实应用场景中复杂非线性任务的需求。另外,现有监督型GPLVM采用相对简单的方式对标记信息进行建模,一般情况下无法挖掘出真正的复杂语义信息,从而造成标记信息流失。
除了上述问题外,现有GPLVM模型在处理图像数据时无法有效利用数据的空间结构信息。如图1所示,两个相邻的像素值a1和a2通常具有一定的相关性和相似性。同理,两个局部区域之间通常也存在较强的相关性,如图1中b1和b2所示。由于现有GPLVM并没有对观测变量特征之间的相关性进行任何的假设和建模,无法进一步提升模型性能,因此本文主要研究在处理图像数据时如何能够兼顾语义标记信息和空间结构信息来构建GPLVM,从而有效提升其在人脸识别、图像分类等应用中的综合性能。
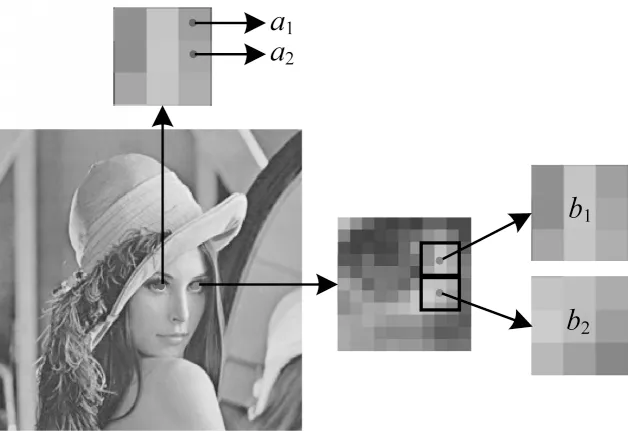
图1 图像相邻像素及区域之间的相关性Fig.1 Correlations between adjacent pixels and regions of the image
2 MSMK-GPLVM构建与优化
2.1 模型构建
为便于描述,本文后续内容将使用上文中的变量定义。在模型构建过程中,主要从图像空间结构信息和语义标记信息两方面对GPLVM的扩展方式进行分析与研究。

通过将每个样本(不同尺度的图像)对应的隐变量进行非线性变换再相加的方式,得到第n个样本对应的隐变量:
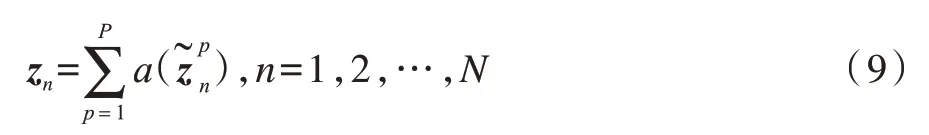
其中a(·)表示神经网络中的激活函数。由上述构建过程可知,本文提出的多尺度特征融合方法与神经网络中的空间金字塔池化方法[17]非常相似,然而两者也有明显区别:1)空间金字塔池化主要是为了解决卷积神经网络无法处理任意尺度的图像而设计的方法,其进行池化时的核大小是根据图像大小自动确定,而本文多尺度特征融合方法主要是将其应用于图像多尺度特征提取,其处理的原始图像大小相同;2)本文模型在特征融合时使用一个非线性变换函数,因此其具有更强的非线性学习能力,而空间金字塔池化通过将多尺度特征合并为一个大向量的方式实现多尺度特征融合,其非线性学习能力主要体现在后续的全连接层中。当a(·)为线性函数时,本文多尺度特征融合方法可以退化为包含线性投影层的空间金字塔池化方法。
在图像语义标记信息利用方面,本文使用一个多核高斯过程模型[17-19]来构建由隐变量到样本标记的映射。具体地,定义由隐变量到样本标记的生成过程,具体如下:
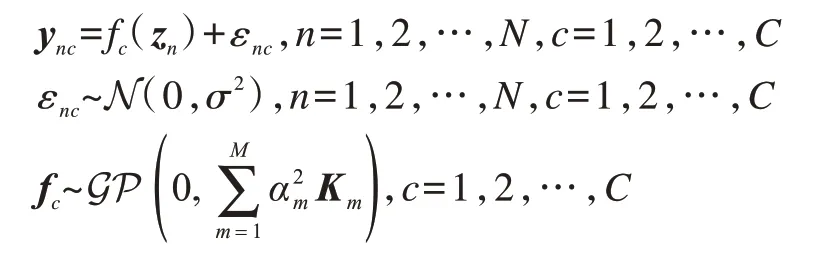
其中,εnc为服从高斯分布的噪声,f(c·)为服从多核高斯过程先验分布的函数为M个核函数组合的权重。可以看出,fc服从的高斯过程先验是一个多核高斯过程,其中的协方差矩阵由多个核矩阵加权而成。因此,可以认为本文模型是一种多核高斯过程模型。从上述样本标记生成过程可知,MSMKGPLVM通过构建多核高斯过程模型的方式显著地提升了由隐变量到标记映射函数的表示能力,并且可以高效地建模数据标记信息。同时,MSMKGPLVM与多尺度图像特征提取相结合能够有效地对隐变量和数据生成过程进行模拟,提升模型判别和特征学习能力。MSMK-GPLVM结构如图2所示。
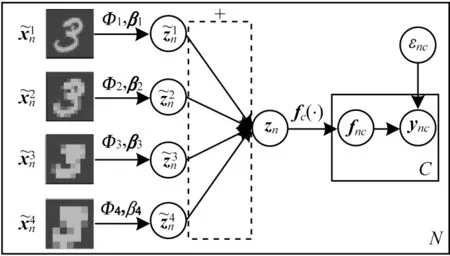
图2 MSMK-GPLVM结构Fig.2 Structure of MSMK-GPLVM
2.2 模型优化
在模型求解过程中,由MSMK-GPLVM生成过程可知噪声εnc服从高斯分布,因此似然函数可写为以下形式:

由于核矩阵Ks关于隐变量Z的导数取决于核函数的形式,因此通常多数核函数(如径向基核函数等)可以直接得出其关于隐变量的导数,而对数似然函数关于核矩阵导数的计算过程具体如下:

基于上述求导过程,利用基于梯度的优化方法对MSMK-GPLVM中的变量进行优化求解。MSMKGPLVM优化算法具体如下:
算法1MSMK-GPLVM优化算法

2.3 新样本预测
在新样本预测中,本文目标是预测给定新样本x*所属的类别标记。与原始GPLVM、D-GPLVM和S-GPLVM相比,MSMK-GPLVM的显著优势是可以直接对新样本进行分类,而GPLVM、D-GPLVM和S-GPLVM在预测出对应的隐变量z*后,通常需要使用KNN算法对样本进行分类。在MSMK-GPLVM预测过程中,首先依据式(8)和式(9)计算出新样本对应的隐变量z*,然后根据高斯过程模型的预测方法得出对应目标值服从高斯分布,其均值和方差计算如下:
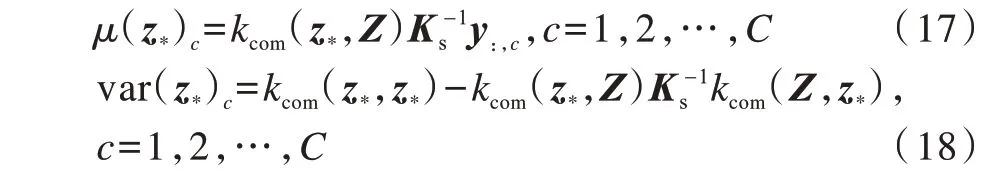
其中,kcom(z*,Z)为z*和Z中每个样本取核函数(多核组合函数)的值组成的行向量,kcom(z*,Z)T=kcom(Z,z*),kcom(z*,z*)表示z*与z*取核函数后的值。可以看出,高斯过程模型可以对预测的不确定性(方差)进行建模,有效扩展了其在医疗诊断、自动驾驶等需要对不确定性进行量化任务中的应用。在完成上述计算后,可以利用μ(z*)={μ(z*)1,μ(z*)2,…,μ(z*)C}获得最终的类别标记:
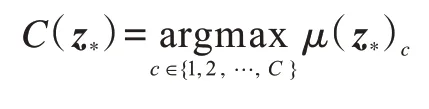
3 实验与结果分析
3.1 数据集与对比方法
在实验过程中,为充分验证MSMK-GPLVM的有效性,分别在多个数据集上与现有隐变量模型进行对比。实验数据集信息如表1所示。
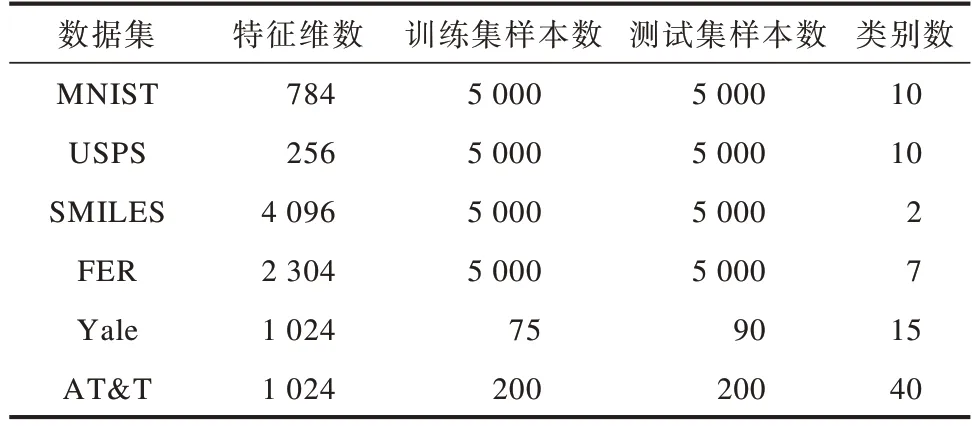
表1 实验数据集Table 1 Experimental dataset
MNIST[20]和USPS[21]均为手写字体数据集,分别包含像素值大小为28×28和16×16的手写数字图片。SMILES[22]数据集是一个包含笑脸和非笑脸两类图像的表情识别数据集,是由LFW中提取图像组成的数据集,包含像素值大小为64×64的图像。FER是Kaggle人脸表情识别竞赛数据集,包含生气、厌恶、恐惧、高兴、悲哀、惊讶、平和7种表情且像素值大小为48×48的图像。Yale和AT&T是两个人脸识别数据集,其中,Yale数据集包含15个人的165张人脸图像(每人11张),AT&T包含40个人的400张人脸图像(每人10张),所有图像均使用人工对齐和裁剪方式规整化至像素值大小为32×32的灰度图像。对于MNIST、USPS、SMILES、FER数据集,本文分别使用5 000个样本作为训练集和测试集。对于Yale数据集,使用每个人的5张人脸图像作为训练集(总数为75),其余6张图像作为测试集(总数为90)。对于AT&T数据,使用每人5张人脸图像作为训练集(总数为200),其余5张图像作为测试集(总数为200)。在训练过程中,在训练集上使用五折交叉验证方法选择模型超参数,主要是对MSMKGPLVM中核函数数量进行选择。最终在整个训练集上基于最佳超参数对模型进行训练,并将训练好的模型在测试集上进行分类性能测试,重复5次上述过程以获得各模型的平均分类准确率。
本文对比模型为原始GPLVM、D-GPLVM、S-GPLVM、SLLGPLVM、PCA[23]和LDA[24]。值得注意的是由于GPLVM、PCA和LDA不包含需要交叉验证的超参数,因此本文直接将其在训练集和测试集上进行训练和测试。同时,因为GPLVM、D-GPLVM、S-GPLVM、PCA和LDA不能对样本类别进行直接预测,所以本文使用KNN算法(K=5)对学习到的隐变量进行分类。
3.2 数据降维与可视化
为验证MSMK-GPLVM在数据降维和可视化方面的性能,本文将所有模型应用于MNIST数据降维实验中并将学习到的二维隐变量进行可视化,如图3所示。可以看出,原始GPLVM和PCA由于无法使用样本的语义标记信息,因此其学到的隐变量可区分性较差,而 LDA、S-GPLVM、D-GPLVM、SLLGPLVM和MSMK-GPLVM可以有效使用样本的语义标记信息,因此可以学习到的样本可分性较好。同时,MSMK-GPLVM兼顾了图像数据的多尺度空间结构信息,因此获得了最优的结果,并且当隐变量维度从2增加到3时,其分类性能得到进一步提升。
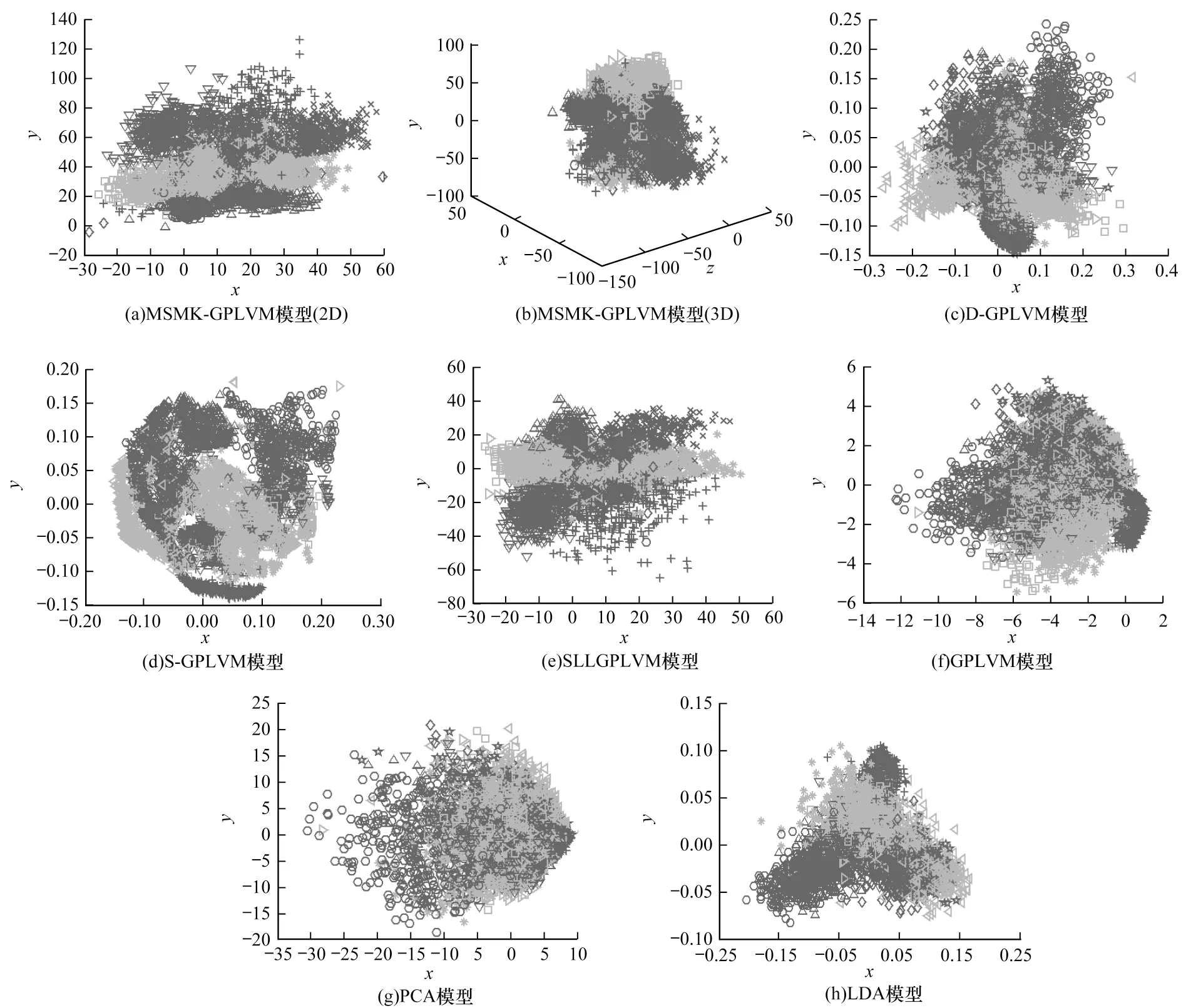
图3 MNIST数据降维和可视化Fig.3 Data dimension reduction and visualization of MNIST
3.3 数据分类
在数据分类实验中将隐变量维度为2、4、6、8、10的情况下所有隐变量模型应用于分类任务,测试其数据分类准确率,实验结果如图4所示。值得注意的是,由于LDA隐变量维度不能大于或等于原始数据的类别数,因此在使用LDA对SMILES数据进行学习时本文仅设置隐变量维度为1,分类准确率为0.819。与此类似,在使用LDA对FER数据集进行学习时,仅设置其隐变量的维度为2、4和6。可以看出,在MNIST、USPS、SMILES、Yale和AT&T数据集上模型分类性能均较高,其主要原因为这5种数据集包含较少的噪声、同一类的数据差异较小。然而,在FER数据集上所有模型的分类准确率均较低,其主要原因为人脸图像表情识别可能会受到姿态、光照、个体差异等多种因素的影响。所有模型的分类准确率均随着隐变量维度的增加而提升,最终趋于稳定,从而证明较高的隐变量维度可以在数据降维过程中获得更多的判别信息。此外,在所有模型中,GPLVM和PCA由于仅使用了样本的输入信息,而无法使用样本的语义标记信息,因此其分类准确率较低。在所有实验数据集上,MSMK-GPLVM获得了最优的分类准确率,充分说明了其采用兼顾样本语义标记信息和多尺度空间结构信息的方式能够有效提升GPLVM的分类性能。
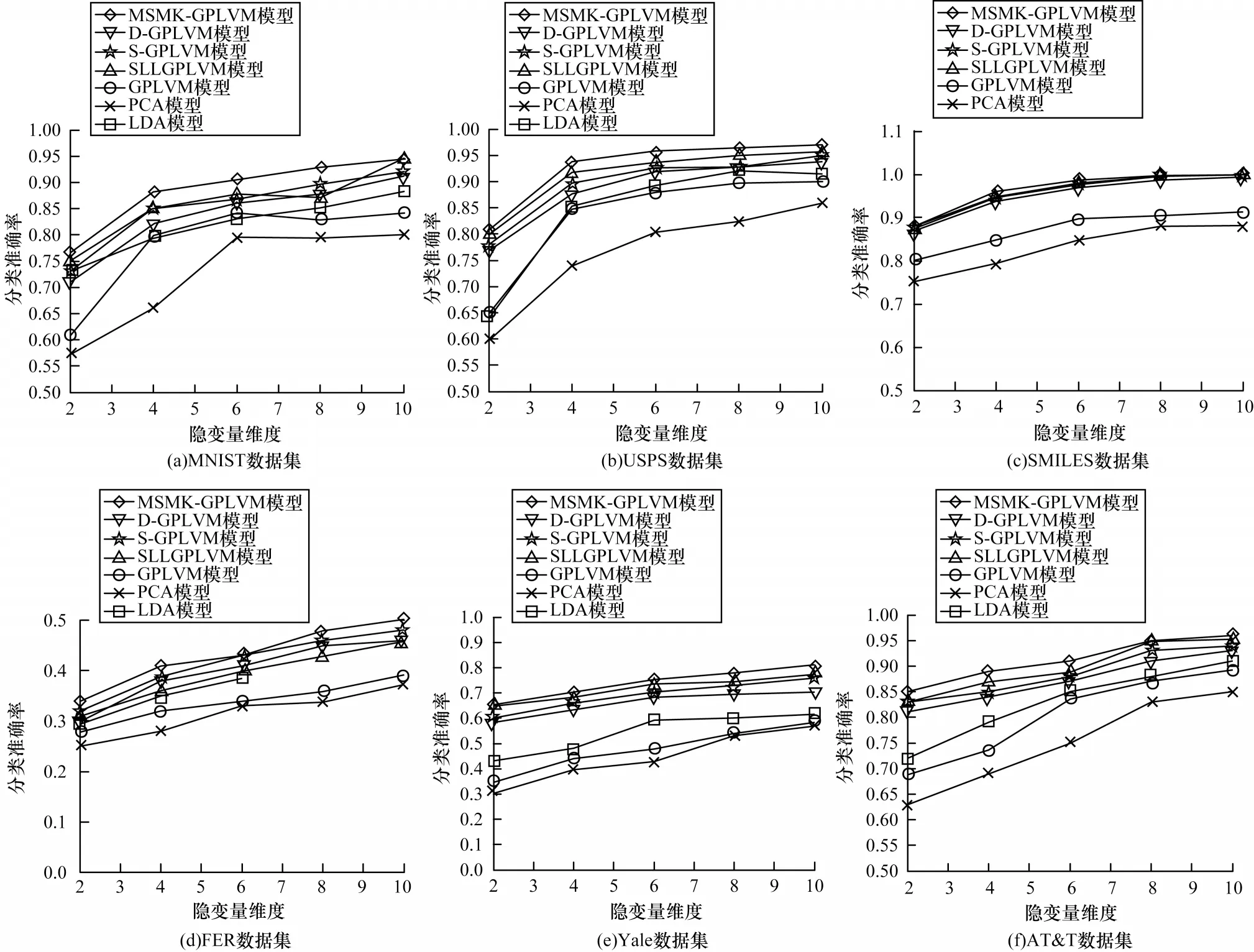
图4 MSMK-GPLVM与其他隐变量模型的分类准确率对比Fig.4 Comparison of classification accuracy of MSMK-GPLVM and other latent variable models
3.4 不同训练样本数下模型分类性能比较
本文在包含不同数量训练样本数的训练集上对MSMK-GPLVM、D-GPLVM、S-GPLVM、SLLGPLVM、GPLVM、PCA和LDA模型的分类准确率进行比较,实验结果如表2和表3所示,其中,Tr表示每个人用于训练的图像数,Te表示每个人用于测试的图像数。例如,Tr2/Te9表示在Yale数据集中每个人有2张图像作为训练集,9张图像作为测试集。
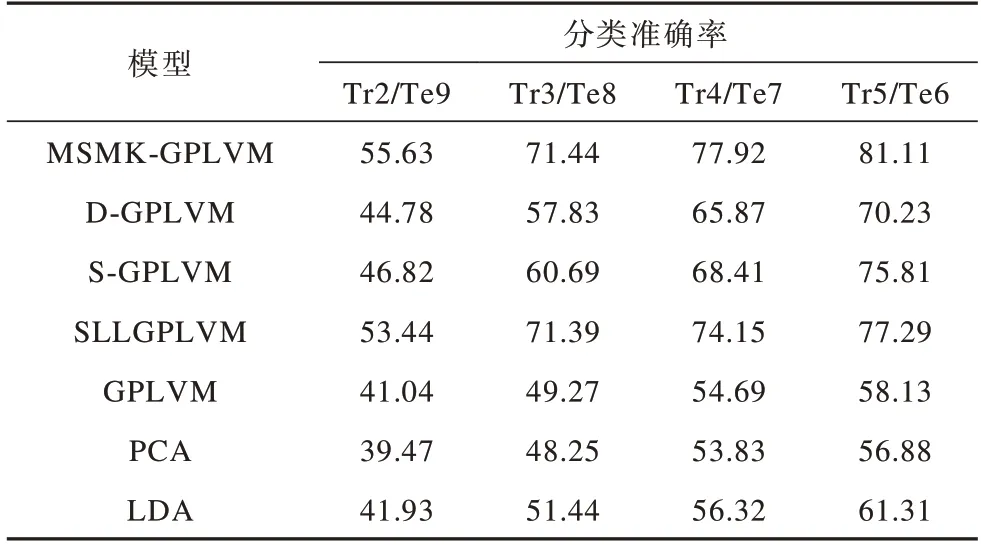
表2 7种模型在Yale数据集上的分类准确率比较Table 2 Comparison of classification accurary of seven models on Yale dataset %
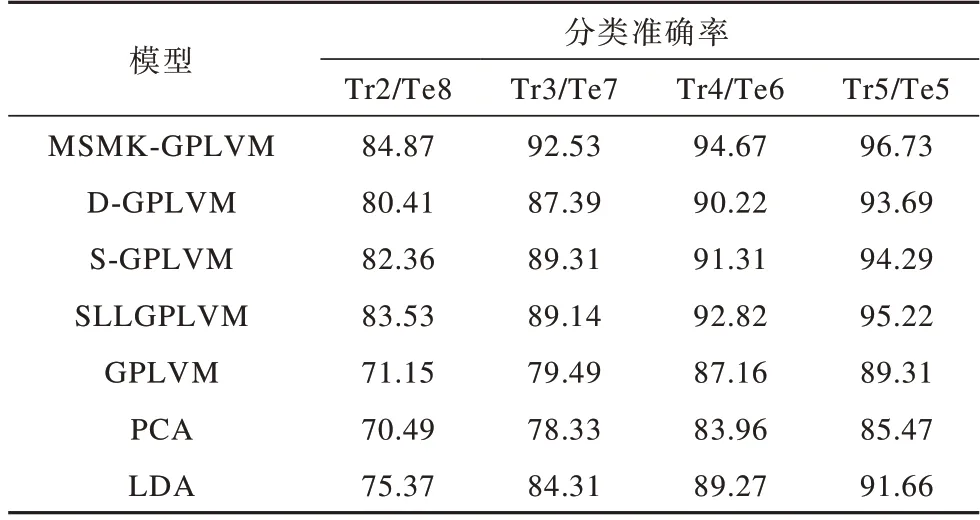
表3 7种模型在AT&T数据集上的分类准确率比较Table 3 Comparison of classification accuary of seven models on AT&T dataset %
由表2、表3可以看出,由于AT&T数据集包含更多的训练图像(该数据集包含人数多于Yale),因此模型在AT&T数据集上的分类准确率高于其在Yale数据集上。同时,PCA和GPLVM均为无监督模型,分类准确率均低于其他监督型模型,而在所有情况下MSMKGPLVM的分类准确率均高于其他模型,说明其在不同样本数下均有较优的性能,适用于不同规模的高维数据学习任务。
4 结束语
本文针对GPLVM无法有效利用图像特征空间结构信息和语义标记信息的问题,提出一种多尺度多核GPLVM(MSMK-GPLVM)。实验结果表明,MSMK-GPLVM能够对图像空间结构信息和语义标记信息进行有效利用,进一步提升其在图像识别任务和数据可视化任务中的整体性能。但由于MSMK-GPLVM在多尺度投影的构建过程中引入了较多的冗余特征,因此后续将针对冗余特征的选择及隐变量维度和核函数的确定做进一步研究。
