基于场景模态深度理解网络的单目图像深度理解
2021-02-05李大威
陈 扬,李大威
(东华大学信息科学与技术学院,上海 201620)
0 概述
随着信息技术的发展,视频场景深度(距离)信息的重要性日益显现。深度图像(也称距离图像)是一种常用的场景深度描述方式,其中每个像素值代表场景中某一点与传感器或扫描仪的距离。目前,深度图像已广泛应用于无人驾驶[1-2]、智能机器人[3]以及人脸识别[4]等领域。例如在无人驾驶领域,车辆在行驶中需实时获取包含周围行人与车辆距离信息的深度图像。目前,Kinect、立体匹配以及激光雷达等现有深度图像获取方法所需设备昂贵且采集成本较高,捕获的深度图像存在分辨率低与大面积深度缺失等问题。基于单目彩色图像的深度理解技术是使用模式识别或机器学习算法从一幅RGB图像中理解出场景中每个像素与传感器的距离,由于其具有成本低廉、性能稳定等优势,因此成为研究人员关注的热点。而在单目彩色图像深度理解技术中,相机在成像时会不可逆地损失景物三维结构信息,造成一张彩色2D图像可与无数真实场景对应,且单幅图像也缺乏用于恢复场景深度的有效辅助线索[5]。因此,单目彩色图像深度理解成为当前计算机视觉领域极具挑战性的研究课题之一。
早期关于单目彩色图像深度理解的研究主要基于图像中物体的几何结构特点以及物体与物体的相互关系进行计算,例如从阴影中恢复形状[6]、从对焦[7]或离焦信息[8]获取深度等。上述方法仅适用于有限种类的场景,并需要额外的辅助信息,严重限制了模型的泛化能力。近年来,深度卷积神经网络(Deep Convolutional Neural Network,DCNN)在计算机视觉领域取得众多突破性进展,研究人员将深度学习[9-11]引入单目彩色图像深度理解方法,虽然其形成的深度图像质量远高于传统图像处理方法,但是也存在局限性。例如:深度卷积网络从图像中提取大量特征,然而物体颜色、场景光照、墙壁纹理与图案等多种图像特征对深度理解任务无用处,并造成计算量过大,同时增加网络的不确定性和学习难度;大部分深度学习方法将深度理解视为回归问题,虽然这种思路能有效用于图像分类,但深度理解是一种比分类更复杂的连续距离预测问题[12-13],其用回归方法求解效果并不理想;现有深度神经元网络随着层数增加其错误信息会不断累积[14],导致深度理解结果质量较差。
针对上述问题,本文提出一种场景模态深度理解网络(Scene Modality Depth Understanding Network,SMDUN)以解决单目彩色图像深度理解问题。SMDUN以堆叠沙漏网络为主框架[15]反复进行自下而上和自上而下的特征提取过程以融合低层次纹理与高级语义特征,在每一层级上使用独立损失函数去除无意义特征,采用不同分辨率的场景模态离散标签指导网络提取有效特征,引入有序回归码和极大似然译码[16]减少误差积累,并优化离散标签的学习过程。
1 相关工作
从单幅彩色图像中理解深度是一项具有挑战性的任务。早期研究主要基于图像中物体的几何结构特点展开,其研究场景种类与模型泛化能力较有限。目前,随着深度卷积网络在计算机视觉领域的深入发展,基于深度学习的方法已成为研究单目彩色图像深度理解的主流方法。与使用人工定义特征进行深度理解的研究相比,基于深度卷积网络的方法能从彩色图像中提取更多有利于深度理解的线索,得到的深度预测图像质量更佳。文献[9]使用深度学习方法对图像深度理解进行研究,提出一种双栈卷积神经网络(Convolutional Neural Network,CNN),先得到粗略的全局预测结果,再使用局部特征对其进行优化。文献[17]采用双流CNN从单幅图像中恢复深度,在双流网络中,一条流产生深度特征,另外一条流产生深度梯度特征,将两种特征融合后得到精细的深度图像。文献[18]利用深度学习网络中间层的输出提供互补信息,采用连续CRF模型对网络中间层输出信息进行整合,以实现对单幅图像的有效深度估计。文献[19]提出一种无监督的单目彩色图像深度理解框架,使用立体图基于光度重建损失函数进行视差估计得到深度图像。文献[20]在文献[19]的基础上提出左右一致性检验方法,结合L1损失和结构相似性(Structural Similarity,SSIM)得到平滑的深度图像预测信息。文献[21]提出一种基于几何感知的对称域自适应框架,通过训练图像样式转换器和深度估计器,实现彩色图像与深度图像的样式转换。上述基于深度学习的方法大部分将深度理解问题视为回归问题来处理,此类方法能有效解决图像分类和语义分割问题,然而深度理解任务中表示深度的每个像素都是连续值,对其进行预测远比离散的分类问题复杂。对此,文献[13]基于有序回归思想,将连续的深度理解任务转换为具有前后关联性的离散深度标签分类问题,降低了深度理解的难度,但其在将深度图像离散化处理成训练标签的同时丢失大量深度信息,造成所得预测图像特征丢失。文献[22]基于图像级全局特征和像素级局部特征,通过有序回归概率信息将离散的有序回归结果转换为连续值处理,但其仅通过分类概率推测出一个连续的深度值,不能解决标签在离散化阶段信息丢失的问题。
此外,上述方法均基于图像的纹理信息进行深度理解,容易使网络学习到墙壁的纹理特征等大量无关特征,在增大计算量的同时提升了学习难度和网络不确定性。因此,文献[15]将不同层级的特征进行反复处理和融合以提取有效特征。文献[23]通过在每一层级单独计算损失函数来丢弃无用特征。但上述方法随着网络深度的增加易产生误差积累,造成在预测深度图中不合理的几何分布。文献[14]提出一种基于网络先前层级特征对当前层级特征进行补充和修正的策略,然而在该特征优化机制下,由于先前低层级特征远不如当前层级特征丰富,因此其对特征的优化能力有限。
2 场景模态深度理解网络
本文提出的场景模态深度理解网结构如图1所示。该网络的特点为:1)网络采用多层次堆叠沙漏结构,并使用连续与离散两种标签进行训练;2)在SMDUN中逐次使用场景模态特征提取模块(Scene Modality Feature Extraction Module,SMFEM),并基于综合损失函数指导网络从低层级到高层级理解深度信息;3)通过误差修正模块(Error Correction Module,ECM)和极大似然译码优化模块(Maximum Likelihood Decoding Optimization Module,MLDOM)修正中间层的错误特征,以减少累计误差。
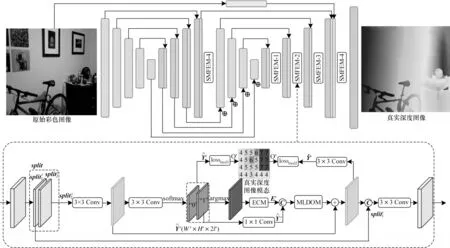
图1 场景模态深度理解网络结构Fig.1 Structure of scene modality depth understanding network
2.1 SMDUN框架
文献[15]使用堆叠沙漏结构网络成功解决图像中人体关节点检测问题,文献[24]证明了堆叠沙漏网络可用于双目立体视觉系统的深度估计,因此,本文提出的SMDUN采用堆叠沙漏结构提取和理解图像深度特征。SMDUN通过中间指导和反复自下而上与自上而下的过程,有效融合了低层次纹理与高级语义特征。RGB图像通过沙漏网络的第一个编码器提取图像底层特征,特征图的分辨率从W×H降至特征图在解码器中通过跳链补充图像底层特征,并逐层级提高特征的分辨率至第二个编码器降低特征的分辨率至并将每一层级输出特征与第一个解码器相应层级的特征相加。特征图在第二个解码中通过跳链从第一个编码器和彩色图像中补充图像底层特征,并输出分辨率为W×H的图像深度理解结果。
SMDUN采用逐层级优化的方式以降低网络不确定性与无效特征的影响,同时提高网络的收敛能力与预测精度。大多数深度理解网络[9,14]使用连续的深度值标签指导网络中间层级特征,这容易造成网络的不确定性,导致其难以学习到有效特征。文献[13]将有序回归的思想引入深度理解与估计任务,使连续的深度估计任务转换为具有前后关联性的离散深度标签分类问题,有效降低了深度理解难度。有序回归使得深度特征理解与编码译码方法相结合,为深度估计问题提供编译码理论支撑。
离散图像标签虽然可以降低计算量,但与连续的深度真实图相比,会造成较多的信息丢失,且在有序回归码的特征提取与计算中容易产生错误。为解决上述问题,本文提出场景模态特征提取模块SMFEM。在图1中,在沙漏网络解码器各阶段输出后增加SMFEM以实现逐层级优化。在SMFEM中,输入特征图被分为两部分,将作为前馈残差的低层次特征,使用场景模态离散标签训练并经MLDOM模块优化后得到特征再将两部分特征进行拼接确保所获得特征的完整性,最后通过3×3卷积得到SMFEM的输出特征。
2.2 场景模态特征的提取
逐层级特征优化广泛应用于图像语义分割、深度估计和边缘检测[25-27]等结构化的训练任务中。文献[23]采用多分辨率训练标签指导特征,并在每一层级后计算独立的损失函数,减少了对无用特征的学习。因此,通常将多次使用不同采样率进行降采样后所得真实深度图像作为多分辨率训练标签进行训练[9,14]。然而,真实深度图像中每个位置的值是连续的浮点值,这增加了训练难度与网络不确定性。实际上,深度图像中最重要的信息是远和近的相对概念,可利用离散的数字类别标签(离散的标签类似于语义分割中物体类的概念,可参照成熟语义分割网络的标签训练方式进行训练)对相对距离进行编码,再使用编码后的深度图像进行训练。基于相对距离关系进行离散化后所得真实深度图像称为场景模态。为了对场景模态标签进行训练,设计场景模态特征提取模块SMFEM。
针对上述问题,本文提出多分辨率的场景模态标签构建方式,从深度图像中提取M种场景模态标签,如图2所示(彩色效果参见《计算机工程》官网HTML版)。多分辨率的场景模态标签Modality={Ms,s=1,2,…,M},其中Ms为SMDUN中第s种标签,Ms(x,y)表示标签Ms中位置(x,y)的值,Ws和Hs分别为标签的宽度和高度,Ms(x,y)标签取值区间为{0,1,…,ls-1},ls为本级场景模态的相对距离级数,本文中该值取2的幂次。
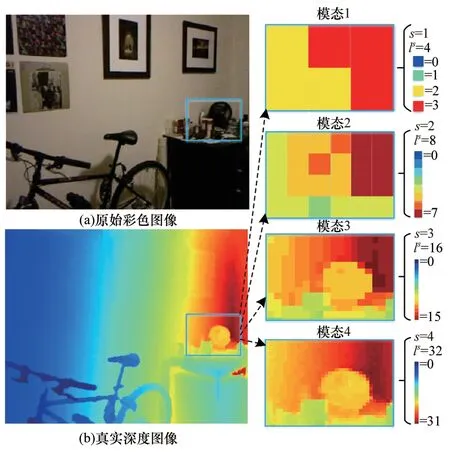
图2 深度图像与场景模态标签Fig.2 Depth image and scene modality labels
场景模态标签由相对距离计算生成,通过远、近、较远与较近等模糊概念描述图像的空间分布。相对距离场景模态标签的计算步骤如下:
1)采用式(1)中线性归一化算法计算得到每个位置的相对距离深度标签Dr:
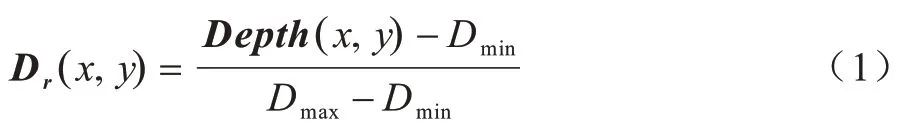
其中,Depth为当前深度图,Dmin为当前深度图的最小深度值,Dmax为当前深度图的最大深度值。

其中,α和β分别为本层场景模态中Dr标签的最小值和最大值,ls为离散化区间数。为避免实际距离为0造成对数无法计算,对α和β添加偏移量1成为α*和β*,因此实际非均匀离散化取值区间为[α*,β*]。
3)在Dd中均匀划分Ws×Hs个区域(Ws与Hs的取值与这一级场景模态标签的长度和宽度相关),计算每个区域的平均值,得到粗略的场景模态标签。
4)针对粗略的场景模态标签,分别采用式(1)和式(2)计算其相对距离Depthr和离散化过程,得到最终的场景模态标签Ms。
场景模态标签Ms由0~ls-1构成,Ms与阈值tis的关系如下:
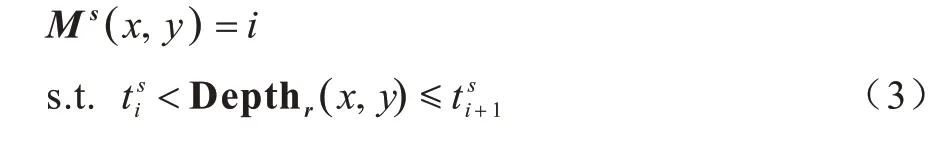
为提升网络容错能力并增加训练过程的稳定性,本文对场景模态离散标签未使用常见的one-hot型编码。例如,某个位置的真实相对深度为4,网络预测为5,对于one-hot型编码而言,其错误产生的损失与预测为8所产生的损失接近,然而实际上相对深度具有一定关联性(5与4的差值比8与4的差值更小),给予更小的损失更合理。因此,本文设计一种有序回归码。
有序回归方法是将一个复杂的多分类任务转换为ls-1个简单的二分类任务,在网络的训练和推理过程中,将标签Ms转换为有序回归码Os,Os的分辨率为Ws×Hs×Ls,其中Ls=ls-1。Ms与Os在(x,y)位置存在以下关系式:
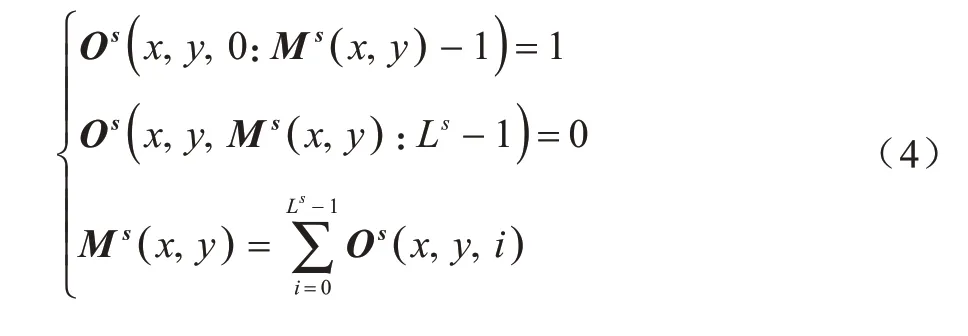
有序回归码Os在(x,y,i) 的每一个维度值实际上是一个二分类任务,其值为0与1的训练过程,在训练中得到一个二分类标签的概率张量Ys,其分辨率为Ws×Hs×(2×Ls)。Ys由两层大小为Ws×Hs×Ls的特征层构成(在图1中以“0”与“1”表示),其中“0”特征层表示经过网络得到的有序回归码中二分类结果为标签0的概率,“1”特征层是将有序回归码每位为1的概率按由大到小排序后得到的特征层。

其中,η(·)为指示函数,满足η(true)=1且η(false)=1。Ps("0")为位置(x,y)处有序回归码第i位为0的概率,而Ps("1")为有序回归码第i位为1的概率,Ps("0")和Ps("1")中同一位置的值之和为1,满足以下关系式:
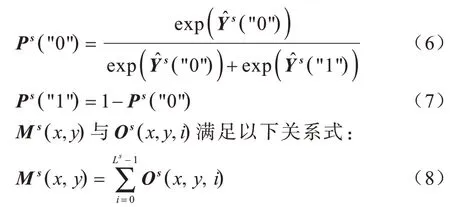
由场景模态可得到相对深度值,计算公式如下:
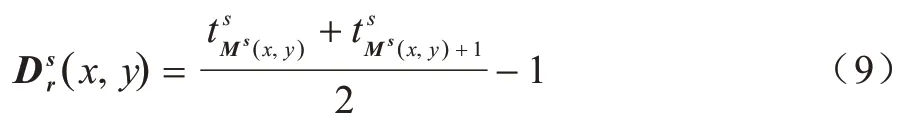
深度卷积神经网络通常存在欠拟合和过拟合现象,多层级的深度卷积神经网络在训练和推理阶段将当前层级的结果直接送入下一层模块的同时,也会将当前层级的误差与噪声传递到后续网络,造成误差不断积累并最终呈现在预测深度图像中,因此需及时对网络中的错误进行校正。在所估计的场景模态有序回归码中,包含有序回归码的内在逻辑错误(以下称为逻辑错误)和有序回归码的二分类精度错误(以下称为精度错误),这两种有序回归码错误示例与误差修正模块中对应的卷积修正方式如图3所示。图3(a)为有序回归码的逻辑错误和使用1×1卷积修正的方式。在场景模态的某一个位置上出现逻辑错误,具体表现为:在值为4的场景模态上,本应是“1,1,1,1”的有序回归码在第2位(从第0位开始)发生错误变为“1,1,0,1”。从逻辑上来看这是错误的,因为本文定义的有序回归码不能出现0,1交替的情况。然而在实际网络训练过程中,难以避免此类错误,且无法在训练中直接对有序回归码的具体值进行赋值操作(例如将错误的0替换为1),只能以卷积和反向传播的形式进行纠错。图3(b)为有序回归码的精度错误和使用3×3卷积与空洞卷积对其修正的方式。在场景模态的某一位置上出现精度错误,具体表现为:在值为4的场景模态上,本应是“1,1,1,1”的有序回归码发生错误变为“1,1,1,1,1”,导致该位置场景模态实际上变为5,由于场景模态反映相对距离,因此会影响后续深度理解的精确性。
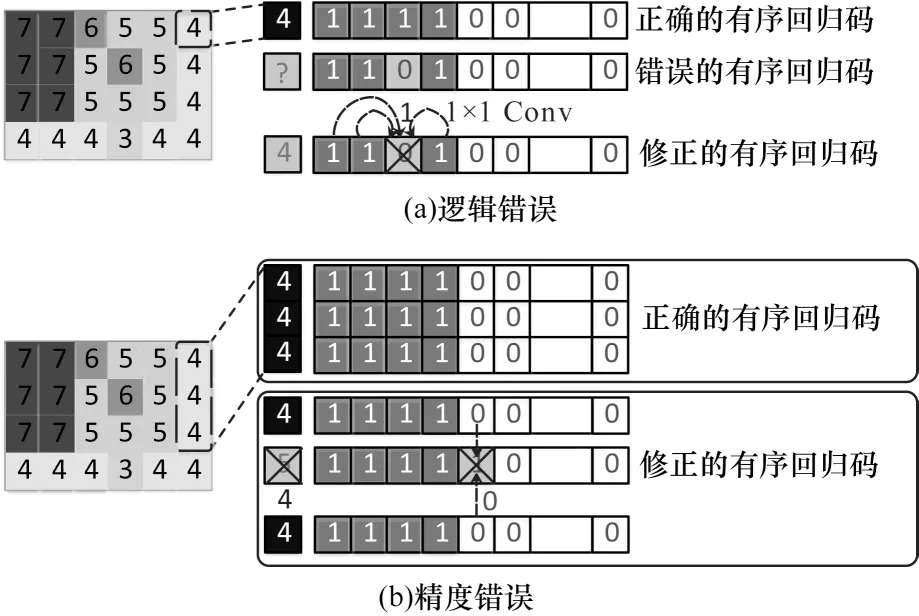
图3 有序回归码的两种错误示例与卷积修正方式Fig.3 Two error examples and convolution correction methods of ordinal regression codes
为避免这两种训练中常见的有序回归码错误,本文设计一种包含多种基本卷积的误差修正模块,其结构如图4所示。中出现的两种有序回归错误源于在一系列二分类任务上产生的分类错误。对于内在逻辑错误,可通过1×1卷积学习有序回归码的规则。如图3(a)所示,经过1×1卷积后,同一串有序回归码前后的正确码字经过卷积能对逻辑错误位产生影响,并在一定程度上消除错误;对于精度错误,只凭当前场景模态位置信息不足以修正,本文通过3×3卷积和多层空洞卷积,以类似于多层空洞池化模块的卷积连接方式[28](见图3(b))充分提取场景模态中相邻位置的特征来克服当前的分类精度错误。将ECM每一阶段产生的多尺度特征进行拼接,最终得到修正后的场景模态特征Es。
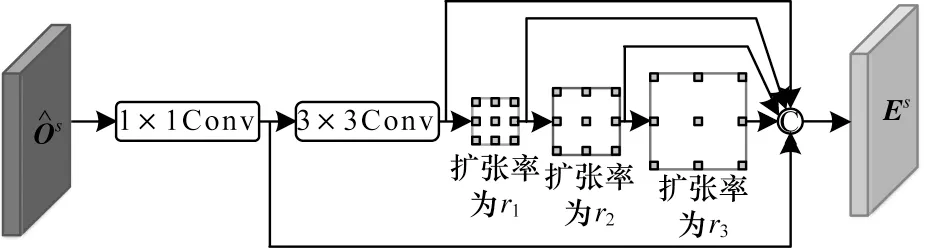
图4 误差修正模块结构Fig.4 Structure of error correction module
2.3 极大似然译码优化模块
本节设计一种极大似然译码优化模块,该模块将预测的有序回归码作为包含错误和噪声的接收码,将场景模态真实值的有序回归码Os作为发送码,并使接收码最大限度地逼近发送码。MLDOM从预测结果中得到场景模态的优化特征,将其与MFs相加得到优化的场景模态特征再将与拼接得到整个SMFEM的输出特征。

在实际物理系统中,由于只存在信息从发送到接收的因果前向转移概率(先验概率)p(r|c),信道中不存在后验概率p(c|r),只能通过先验概率近似计算后验概率。根据贝叶斯公式得到先验概率和后验概率的关系式如下:

在式(13)计算过程中,不仅计算量过大,而且似然函数也难以确定,因此本文以卷积实现局部的极大似然译码,通过较少的计算量得到一个次优解。采用局部计算近似得到极大似然译码的原因如下:1)场景模态采用类似于深度图像的相对距离,由于目标表面为深度连续的[24],因此其中每个坐标的相对深度与邻域关联紧密;2)目标级信息描述了图像场景的整体结构和具体物体的粗略位置关系(全局特征);3)像素级信息使物体表面在场景中的深度值(局部特征)更精确,可通过网络在训练阶段以卷积和池化的方式学习到。虽然在不同图像中场景会发生改变,但场景中同种物体特征不会发生变化。例如,在客厅学习到的桌子特征同样适用于厨房中的桌子。因此,局部特征不会随着场景的改变而失效,具有较高的鲁棒性。
基于上述分析,将输入MLDOM的特征转化成大小为Ws×Hs×Ns的特征层,其中Ns为当前极大似然译码相关的码长,再将极大似然译码转换为局部最优似然译码,该过程主要包括两步:1)将特征层均分为16层的子特征层,其中每层通道数为再分别进行极大似然译码计算;2)在每个子特征层中,以对数似然的方式将概率连乘计算变为连加计算,再采用5×5的平均池化操作将连加限制在局部范围内进行,最后利用argmax函数获取局部最优的特征编码完成式(13)的近似计算。图5为极大似然译码优化模块的结构,其中对译码过程的先验概率逼近过程进行展示,由场景模态标签带来的损失沿虚线传递给每个单独的译码过程,以保证最优译码方向的正确性。
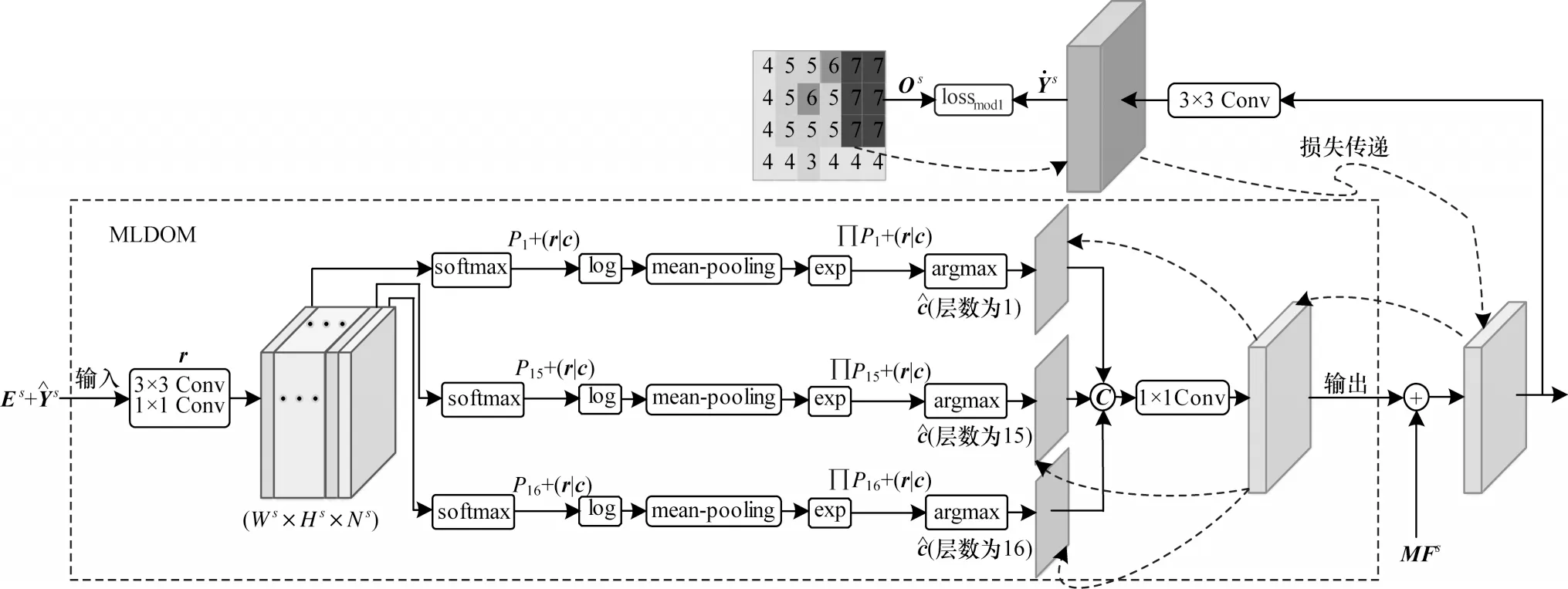
图5 极大似然译码优化模块结构Fig.5 Structure of maximum likelihood decoding optimization module
2.4 损失函数
本文对SMDUN的总损失函数losstotal定义如下:
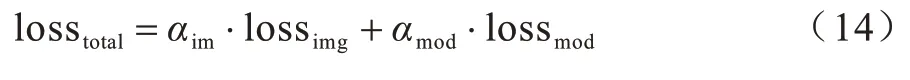
总损失函数主要由预测得到的深度图像和真实深度图像标签之间的损失lossim(g深度图像预测误差)以及场景模态标签的损失lossmod两部分构成,lossimg在整个堆叠沙漏网络的最后进行计算,lossmod在每一层SMFEM内进行计算。
2.4.1 深度预测图和标签深度图之间的损失
深度图像预测误差lossimg主要由Inverse-Huber损失[29]和SSIM指标值[10]两部分组成,其表达式如下:
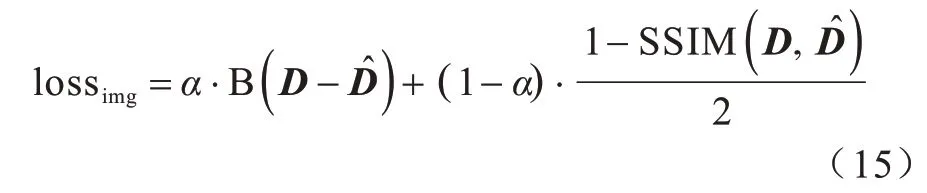
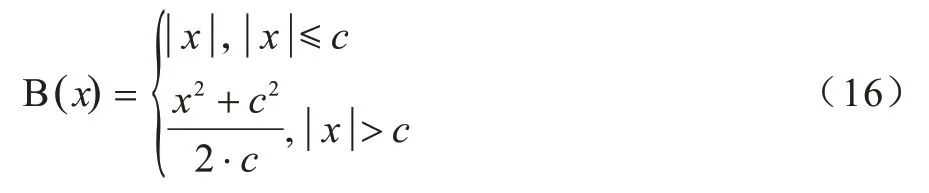
其中,c为阈值。
2.4.2 场景模态损失
本文将场景模态标签损失lossmod定义为全部SMFEM的有序回归损失之和,计算公式如下:

3 实验与结果分析
本文通过实验验证SMDUN的深度理解有效性。通过设计不同的剥离实验分析网络各部分的有效性,并将本文网络与当前流行的其他网络进行对比分析。
3.1 深度理解数据集
当前深度理解网络通常采用NYUv2数据集[29]和KITTI数据集[30]进行实验。
NYUv2数据集提供了由Kinect相机拍摄采集的464个室内场景RGB-D数据,包括12万对彩色图像与深度图像,图像分辨率为640像素×480像素。采用文献[9]定义的训练集与测试集划分方法,在NYUv2数据集的464个场景中选取249个场景用于训练,其余215个场景用于测试。从训练场景中抽取5万对彩色图像和深度图像作为训练集,在测试场景中抽取654对彩色图像和深度图像作为测试集,并对深度图像空缺的区域进行填补,深度值上限设定为10 m。在训练阶段,使用双线性降采样方法将NYUv2数据集中图像分辨率改为256像素×352像素,并将其作为SMDUN的输入和标签数据的默认分辨率。在测试阶段,将网络的预测深度图像恢复到原始图像大小,同时在文献[9]定义的指定区域计算预测结果的定量指标。
KITTI是一个包含双目立体图像和3D点云数据的室外场景数据集,涵盖市区、乡村、高速公路以及校园等56个不同场景,图像分辨率为1 241像素×376像素。采用文献[9]定义的训练集与测试集划分方法,从56个场景中选取28个场景用于训练,其余28个场景用于测试。从训练场景中抽取2.8万对彩色图像和深度图像作为训练集,对测试场景中抽取697对彩色图像和深度图像作为测试集,对稀疏的深度图像进行填补[9],深度值上限设定为80 m。在训练阶段,去掉深度图像上层区域中激光雷达扫描不到的部分,使用双线性降采样方法将KITTI数据集中图像分辨率改为256像素×512像素,并将其作为SMDUN的输入和标签数据的默认分辨率。在测试阶段,将网络的预测深度图像恢复到原始图像大小,同时在文献[9]定义的指定区域计算预测结果的定量指标。
3.2 实验设置
场景模态深度理解网络采用TensorFlow深度学习框架,使用NVIDIA RTX 2080Ti进行训练与测试。SMDUN的第一个编码器网络为ResNet-50,并使用ILSVRC[31]中的预训练模型进行初始化。
场景模态深度理解网络的训练过程分为两步:第一步训练侧重于SMDUN的场景模态损失,计算时式(14)中参数αim和αmod分别设置为1.0×10-4和1,网络参数更新使用Adam优化算法,设置Adam算法的学习率为1.0×10-4,参数β1=0.9,β2=0.999;第二步训练侧重于连续标签损失,计算时式(14)中参数αim和αmod分别设置为1和1.0×10-2。Adam优化算法的学习率在迭代中采用多项式衰减策略,初始学习率设置为1.0×10-4,终止学习率设置为1.0×10-5,多项式衰减参数Power=0.9。在NYUv2数据集中,第一步训练和第二步训练的epoch分别为6、35,网络的batch设置为6;在KITTI数据集中,第一步训练和第二步训练的epoch分别为3、35,网络的batch设置为4。
将本文提出的场景模态深度理解网络与DORN[13]网络、GASDA[21]网络、ACAN[22]网络以及文献[9]、文献[11-12]、文献[14]、文献[17]、文献[20]以及文献[32-37]中其他流行的深度网络实验结果从定性和定量上进行比较。
3.3 定量评价指标
本文将SMDUN的实验结果与上述其他网络在以下6种定量指标上进行比较:
1)绝对相关误差(Absolute Relative Error,AbsRel),其计算公式为:
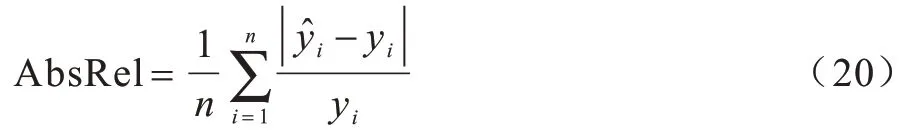
2)均方相关误差(Mean Squared Relative Error,MSqRel),其计算公式为:
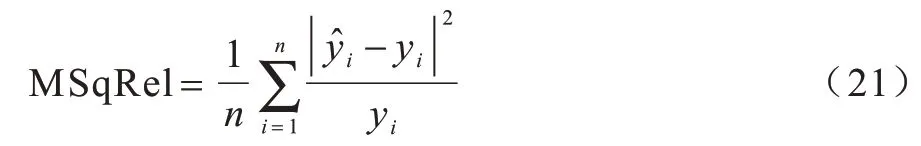
3)均方根误差(Root Mean Squared Error,RMSE),其计算公式为:
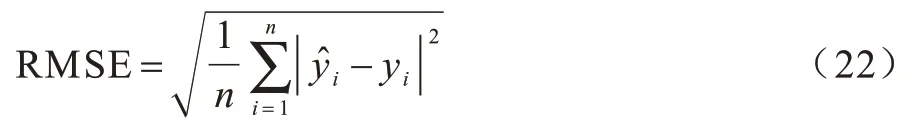
4)对数均方根误差(Root Mean Squared Error in log space,RMSElog),其计算公式为:
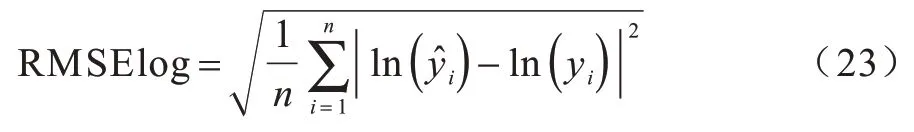
5)对数平均误差(Mean log10 Error,MLog10E),其计算公式为:
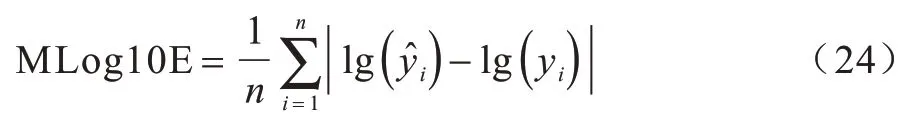
6)阈值准确度δ1、δ2和δ3,其中:

在式(20)~式(25)中,yi是标签图像中的深度值为网络预测的深度图中的值,n为图像的像素个数。
3.4 结果分析
3.4.1 网络模块剥离实验
为验证本文提出的多个模块具备提升网络深度理解性能的能力,分别对各模块进行剥离得到3种不同的网络结构,在NYUv2数据集上分别进行定量实验并与SMDUN进行对比,结果如表1所示。其中:Type-1为剥离所有SMFEM子模块后仅保留堆叠沙漏结构得到的网络;Type-2为在堆叠沙漏结构网络上仅保留图1中SMFEM-3模块得到的网络;Type-3为在堆叠沙漏网络结构上保留相同SMFEM模块,并在SMFEM中去除ECM模块和局部极大似然译码模块得到的网络。可以看出:从Type-1到SMDUN,随着并入场景模态层数与网络子模块的逐渐增加,网络深度理解性能逐步提升;SMDUN全部指标值均为最优,其具有最佳深度估计性能,验证了本文所提出SMFEM模块、ECM子模块以及MLDOM子模块的有效性。
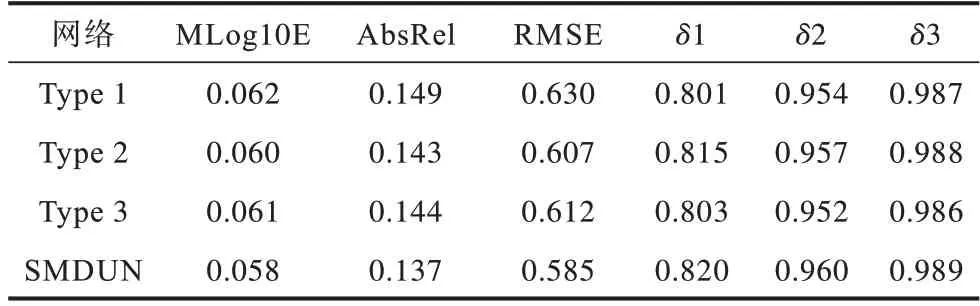
表1 网络模块剥离实验的定量结果Table 1 Quantitative results of network module stripping experiment
3.4.2 理解性能的对比
1)NYUv2数据集实验
表2为本文SMDUN和其他深度网络在NYUv2数据集上的定量实验结果。可以看出,SMDUN属于性能最好的第一梯队网络,在最重要的Mlog10E和AbsRel这两项指标中均达到最优值,验证了其有效性(表2中“-”表示该值不存在)。
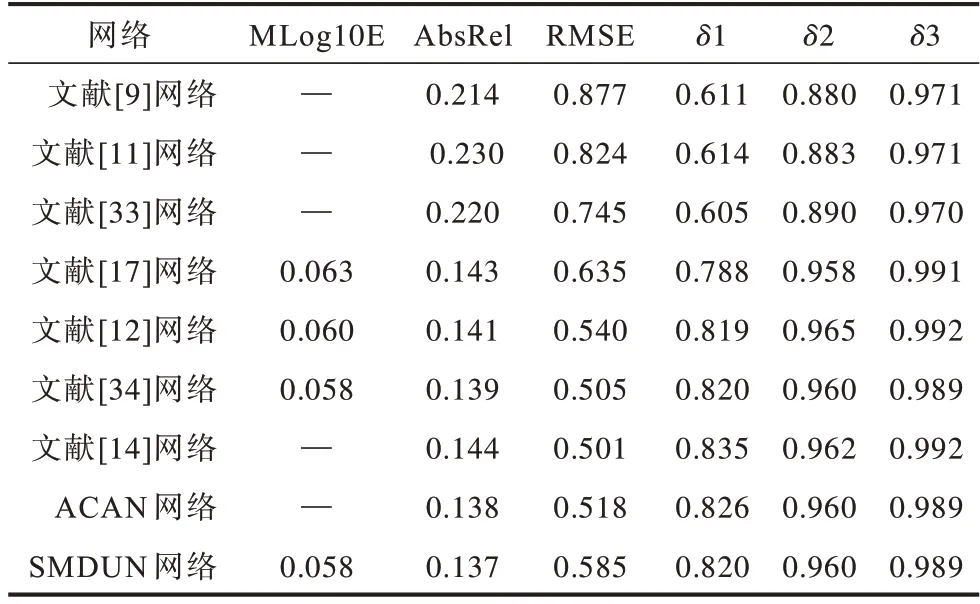
表2 不同网络在NYUv2数据集上定量结果的对比Table 2 Comparison of quantitative results of different networks on NYUv2 dataset
图6为不同网络在NYUv2数据集上的深度预测定性实验结果(彩色效果参见《计算机工程》官网HTML版)。可以看出:文献[9]网络能获得粗略的三维空间结构但误差较大,物体边缘较模糊;文献[29]网络所得深度图像总体误差相对较低,但其深度信息过于平滑,场景中较小物体难以分辨且物体轮廓存在不合理的形变;文献[13]网络所得深度图像整体上较模糊,丢失大量细节信息且存在明显的网格效应;SMDUN与真实图像更接近,所得深度图像包含更多细节信息且场景中物体轮廓更清晰。

图6 不同网络在NYUv2数据集上定性结果的对比Fig.6 Comparison of qualitative results of different networks on NYUv2 dataset
2)KITTI数据集实验
表3为本文SMDUN和其他网络在KITTI数据集上的定量实验结果。可以看出,SMDUN有5个定量指标取得最优值,RMSE值为次优,表明SMDUN可有效解决单目RGB图像的深度理解问题。
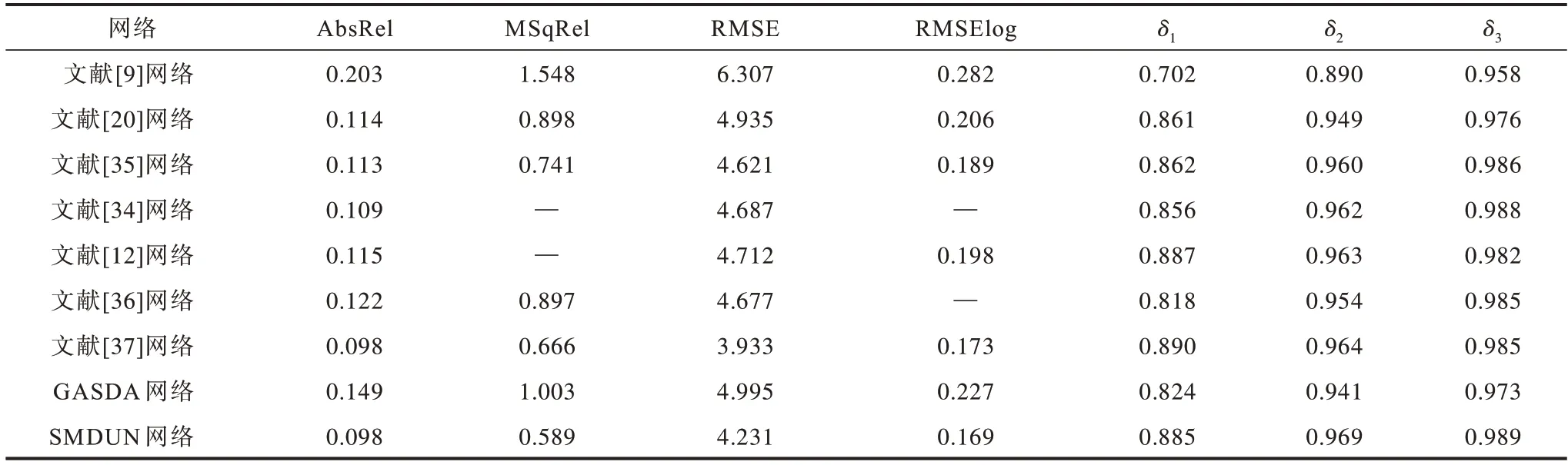
表3 不同网络在KITTI数据集上定量结果的对比Table 3 Comparison of quantitative results of different networks on KITTI dataset
图7为不同网络在KITTI数据集上的深度预测定性实验结果(彩色效果参见《计算机工程》官网HTML版)。可以看出:文献[20]网络所得深度图像中物体轮廓较清晰,但其与真实深度图像标签存在较大误差;文献[13]网络的定性结果整体模糊并存在明显的网格效应;SMDUN与真实深度图像在定性结果上更接近,所得深度图像包含更多细节信息且场景中物体轮廓更清晰。
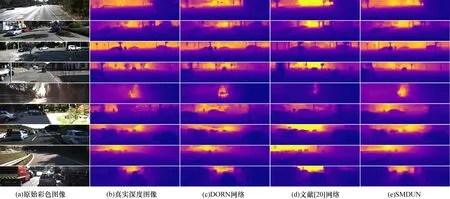
图7 不同网络在KITTI数据集上定性结果的对比Fig.7 Comparison of qualitative results of different networks on KITTI dataset
4 结束语
本文提出一种用于单目图像深度理解的场景模态深度理解网络。以堆叠沙漏网络为主框架,使用不同分辨率的场景模态离散标签指导网络每一层级特征的有效提取,在堆叠沙漏网络中逐次利用场景模态获取特征,采用综合损失函数指导网络从低层级到高层级理解深度信息,并设计误差修正子模块和极大似然译码优化子模块修正网络中间层级的错误特征以减少误差累计,同时对离散深度标签进行有序回归编码,增加网络容错能力并提升训练的精确度和稳定性。实验结果表明,相较NYUv2、GASDA和DORN等深度网络,该网络在NYUv2数据集上绝对相关误差与对数平均误差均最小,在KITTI数据集上均方相关误差最小,其预测出的深度图像包含较多细节信息且目标轮廓更清晰。后续考虑将极大似然译码优化模块应用于其他深度学习任务,以协助解决语义分割与人体关节点检测等问题。
