用于非精确图匹配的改进注意图卷积网络
2021-02-05李昌华李智杰
李昌华,刘 艺,李智杰
(西安建筑科技大学 信息与控制工程学院,西安 710055)
1 引 言
图结构信息在生活中普遍存在,例如,社交网络,生物网络和分子结构等都可以由图的节点和边表示.研究人员已经在图中以监督和非监督的方式对许多重要的机器学习应用进行了广泛的研究[1],例如图像分类、自然语言处理、强化学习以及推荐系统,但图数据的复杂性给许多任务带来了巨大的挑战.由于从大量图数据中获取有意义的信息的重要性,其中图分类问题是该领域的中心任务之一.目前,最受欢迎的技术是核方法:1)图嵌入算法,将图结构嵌入到向量空间,得到图结构的向量化表示,然后直接应用基于向量的核函数处理,但是这类方法将结构化数据降维到向量空间损失了大量结构化信息;2)图核算法,它使用核函数来测量图之间的半正定图相似性[2].然后可以在相似性矩阵上进行分类任务.通过使用支持向量机[3]等监督算法.通过将图分解为子结构,图核能够直接处理图数据而无需将其转换为特征向量.既保留了核函数计算高效的优点,又包含了图数据在希尔伯特高维空间的结构化信息,使得它在节点分类、链路预测、节点聚类等方面取得了巨大成功.然而,基于图核的算法仍然受到自然限制.近年来,基于深度学习的方法(如图神经网络)也已广泛应用于网络表示,并被证明大大优于传统方法.GNN可以了解数据的局部结构和特征.该模型可以直接对图数据进行特征学习.但是,虽然图结构数据保留了更多的关系信息,与其他数据格式相比,它也会产生更复杂的噪声.如何在筛选图中每个节点的复杂噪声引起的干扰的同时学习良好的表示已成为一项重大挑战.
图数据在很多方面都很复杂;例如,当尺寸变化时,不同子图的拓扑结构信息是变化无常的.处理这种分散的信息时,大多数现有的图神经网络框架受到两个因素的限制:1)当只使用最大的子图结构用于邻域聚合时,在图卷积中容易丢失早期提取的重要信息;2)使用平均/最大池化时,易损失每个节点或节点之间的拓扑.
本文通过在图卷积运算中引入自注意技术,以捕获图中的任意局部结构信息,提出自注意分层图池化的方法,用较少的参数以端到端的方式学习分层表示,用于图分类任务.
2 基于图卷积网络的图匹配算法
2.1 图匹配问题
本文研究的图对象是指拓扑图,它是由节点和边组成的网络.图可以表示为g=(Vg,Eg,Ag,Xg),其中Vg是顶点集合vi,i= 1,…,n.Eg表示节点之间的边,表示为ei,j=
2.2 传统图卷积网络
图卷积有许多定义.其他类型的图卷积可以提高性能.具有k深度的图卷积的一般形式可以通过广泛遵循的卷积结构递归地表达,表示为:
(1)
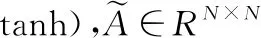
2.3 池化方法
图卷积层的池化方法有全局池化和分层池化[4].图1是全局池化和分层池化的结构图.目前,常用的图神经网络是利用传统的图卷积方法,使用全局池化的方法,即将每一跳的结果都作为下一步的输入,然后将最终结果输入线性聚合层中(即全局池化),缺点是随着层数的增加,在每个卷积步骤期间丢失大量早期信息,这严重影响最终预测输出(仅仅是k-hop的子结构信息)(如左图所示).本文提出的自注意图卷积池化方法,使用分层池化的方法,即通过将每个卷积步骤的信息进行聚合,从每一跳中获取有用信息,最终结果输入到线性层来解决该问题(如右图所示).
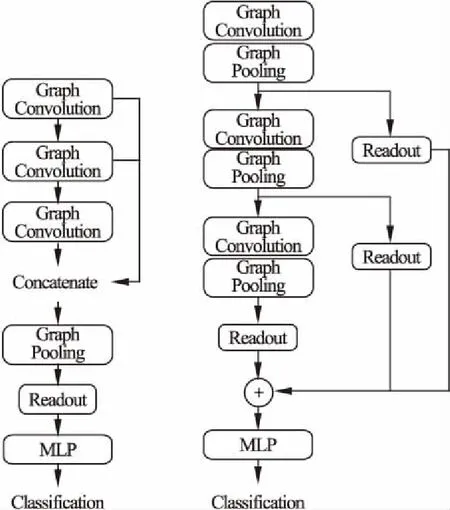
图1 全局池化结构(左)和分层池化结构(右)Fig.1 Global pooling structure(left)and hierarchical pooling structure(right)
3 基于改进注意图网络的图匹配算法
3.1 自注意机制
近年来,注意力模型广泛应用于深度学习的各个领域,例如,图像处理、语音识别、自然语言处理等领域.因此,了解注意力机制对研究人员来说十分重要.
注意力机制最早是在视觉领域内提出来的,2014年google mind团队[5]在RNN模型上中应用Attention机制用于图像分类,随后,Bahdanau将Attention机制运用到自然语言处理领域上,后来,Attention机制被广泛的应用于基于RNN和CNN等网络模型中,用于NLP领域中.2017年,Vaswani等人[6]提出了自注意力机制,用来学习文本表示.自此,自注意力机制成为研究人员近几年来研究的热点.
Attention机制其实是从大量信息中筛选出对当前任务目标中更有效的信息.下面给出Attention的计算过程,如在NLP中,在计算attention时主要分为3步,第1步是将查询和每个键-值进行相似度计算得到权重,常用的相似度函数有点积、拼接、感知机等;然后第2步一般是使用一个softmax函数对这些权重进行归一化;最后将权重和相应的键值、进行加权求和得到最后的attention.
自注意机制是注意力机制的一种特殊情况,在self-attention中,Q=K=V每个序列中的单元和该序列中所有单元进行attention计算[7].
3.2 提出的算法模型
为了解决传统图卷积网络模型的缺点,提出了一种新的双重注意图卷积网络(Dual Attention Graph Convolutional Networks,DAGCN).它主要是由两个模块组成.即注意图卷积模块和自注意池化层.DAGCN的工作原理如下:首先通过利用注意图卷积网络来自动学习子图结构(k-hop neighbor),其次,再加入自注意池化层,将最终图嵌入矩阵M发送到线性层以进行最终预测.
·注意图卷积模块 注意图卷积模块由几个注意图卷积层构成.每个层采用特征X和邻接矩阵A来从不同跳的邻域提取顶点的分层局部子结构特征.
·自注意池化层 注意池层使用节点嵌入来学习不同方面的多个图表示,并输出固定大小的矩阵图嵌入.
3.3 注意图卷积模型
在公式(1)中,除了Hk之外,每个步骤中的结果只能用于生成下一个卷积结果.随着卷积层数的增加,将丢失大量早期信息,并且只有最后的卷积结果Hk(代表最大的子图)可用于后续任务.这种操作可能会导致严重的信息丢失.卷积层仅捕获k跳本地结构.
DAGCN模型中的注意图卷积层旨在通过集中聚合来自每个卷积步骤的信息来解决该问题.不仅依赖于k-hop卷积结果,而且还可以从每一跳中捕获有价值的信息.因此,卷积结果将是包含来自不同跳跃卷积过程的最有价值信息的分层表示.分层节点表示γvn表示如下:
(2)
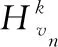
为了最大化深度学习的优势并学习更深层次的潜在特征,使用残差学习技术来叠加注意卷积层并开发注意图卷积模块以获得更好的最终节点表示γvn.每个注意图卷积层的输入是前一层输出和原始X的总和.最后,使用一个密集层来处理来自每个卷积层的输出组合.
(3)
(4)
其中Dense()是一个密集层,它结合了每个注意图卷积层的输出.
3.4 自注意池化
注意机制已被广泛用于最近的深度学习研究中[5-7].目的是将任意图编码为固定大小的嵌入矩阵,同时最大化节点表示下的信息.本文通过将从卷积模块获知的图的节点表示作为输入来使用注意力机制来输出权重向量α.
β=softmax(u2tanh(u1GT))
(5)
在该公式中,u1和u2是分别具有c-by-c和c-by-r形状的权重矩阵,其中r是针对子空间的数量设置的超参数,以从节点表示学习图表示.当r≥1时,α变为权重矩阵而不是矢量,然后可以将公式(5)写为:
B=softmax(u2tanh(u1GT))
(6)
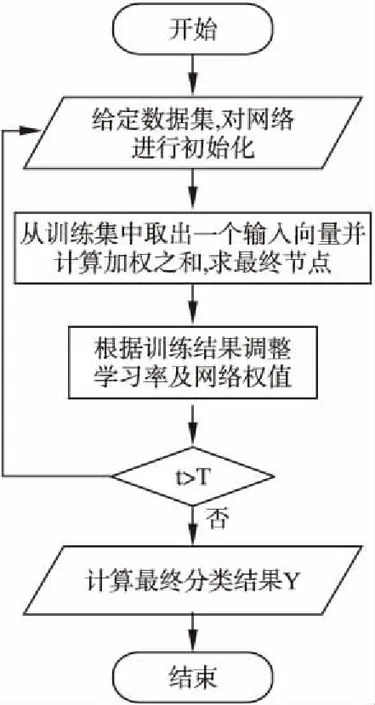
图2 DAGCN算法流程图Fig.2 DAGCN algorithm flow chart
B的每一行代表一个节点在不同子空间中的权重.softmax函数沿其输入的第二维执行.然后,根据来自公式(6)的B进行加权求和,以获得具有形状n-by-r的图表示矩阵M.
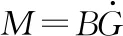
(7)
最后,一个完全连接的层后面跟着一个softmax层,以M为输入,得到了最终的分类结果Y,完成图的分类.
Y=softmax(ZM+C)
(8)
具体算法步骤如下:
1)给定数据集X={x1,x2,…,xn},给定A,T,K,M,其中T是迭代更新,A是无权重邻接矩阵,vn是节点Vn的特征向量,K是卷积运算中hop的数量,M是注意图卷积层的数量.
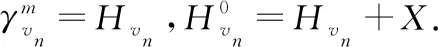
4)利用公式(4)计算所有节点vn∈g的归一化最终节点表示γvn,
5)公式(6)得出归一化注意力池化层的系数矩阵M.
6)利用公式(7)计算图g的权重之和.
7)使用随机梯度更新所有的权重参数.
8)迭代结束后,公式(8)得出Y∈Rn*|c|.
具体的算法流程图如图2所示.
4 实验结果与分析
4.1 数据集
本文使用5个基准生物信息学数据集,根据图分类任务的准确性来评估DAGCN模型(比较DAGCN与图核的图分类精度).使用的数据集是:
·NCI1[8]:NCI是用于抗癌活性分类的生物学数据集.其中原子代表节点,化学键代表边.NCI1数据集分别包含4100个化合物,标签是判断化合物是否有阻碍癌细胞增长得性质.
·MUTAG[9]:MUTAG数据集包含188个硝基化合物,标签是判断化合物是芳香族还是杂芳族.
·PROTEINS[10]:蛋白质是一个图形集合,其中的节点是二级结构元素,边缘表示氨基酸序列或3D空间中的邻域.图分类为酶或非酶.
·PTC[11]:PTC数据集由344种化合物组成,其类别表明对雄性和雌性大鼠有致癌性.
·D&D[12]:D&D数据集是1178种蛋白质结构的数据集,分为酶和非酶.
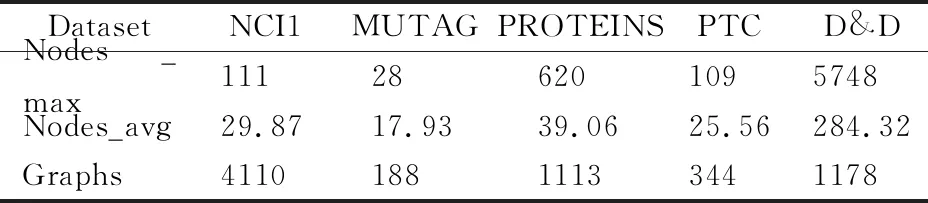
表1 各个数据集的基本信息Table 1 Basic information of each data set
表1是各个数据集的基本信息,其中Nodes_max表示数据集中拓扑图的最大节点数,Nodes_avg表示数据集的平均节点数,Graphs表示数据集中包含的图的数量.
4.2 实验设置
将DAGCN与两个最经典的图核算法、与4种最先进的GCN进行比较:
·图核算法:a)the SP kernel(SP)[13],b)the Weisfeiler-Lehman(WL)[7].
·g-CNNs方法:PSCN[10],ECC[14]
对于图核参数,按照常规设置,采用了与以前工作相同的程序,以便进行公平的比较.所有密集层和卷积层的隐藏层大小设置为64,k从集合{1,5,10}中选择,并且所选择的跳数是k∈{3,5,10}.本文使用Adam[15]优化策略,其中L2正则化和学习率从{0.01,0.001,0.0001}中选择,以确保模型的最佳发挥.批量大小固定为50,并且进行10倍交叉验证(训练9倍,测试1倍),以报告平均分类准确度和标准偏差.WL的高度参数选自集合{0,1,2,3,4,5}.其他的结果来自文献[13].所有实验设置都是相同的,以便进行公平的比较.本文中所有实验环境及配置如表2所示.

表2 实验环境及配置Table 2 Experimental environment and configuration
4.3 实验结果
表3显示了比较深度学习方法的平均分类准确度.表中的“-”表示源代码不可用或先前的报告不包含相关结果.从结果中可以看出,DAGCN模型在5个数据集中,始终优于其他深度学习方法,在D&D上排名第2.特别是,NCI1的分类准确度提高了7%,其他3个数据集(不包括D&D)的准确度提高了1%-3%.在每种情况下,DAGCN都优于PSCN和ECC,证明了简单求和节点特征是无效的,并且会导致拓扑信息的丢失.PSCN与DAGCN在PROTEINS和PTC上的模型大致相同,但在NCI1上糟糕,因为它更有可能过度拟合预定义的节点排序.通过使用注意池化避免这个问题,注意池动态地学习图上的有价值的节点分布.
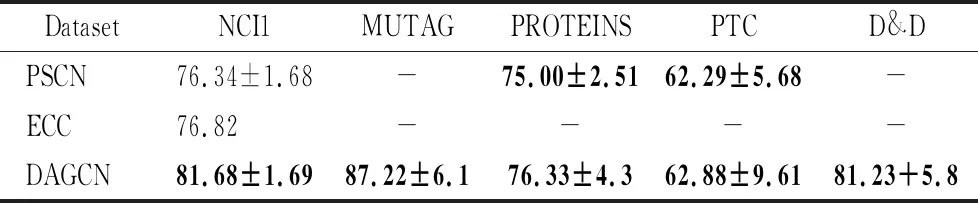
表3 深度学习算法的平均分类准确率Table 3 Average classification accuracy of deep learning algorithms
表4显示了比较图核算法的平均分类准确度.将DAGCN模型与最先进的图核算法进行比较,由表4可知,尽管所有数据集都使用了单一结构,但DAGCN与最先进的图核非常竞争,其中包括MUTAG,PROTEINS和D&D的准确性最高.与WL相比,DAGCN在所有数据集上的精度都更高(除NCI1外),这表明DAGCN能够更有效地利用节点和结构信息.
为了评价分类效率,进行对比实验,可用一些指标(错误率,准确率,召回率等)对模型进行评价(如图3所示).
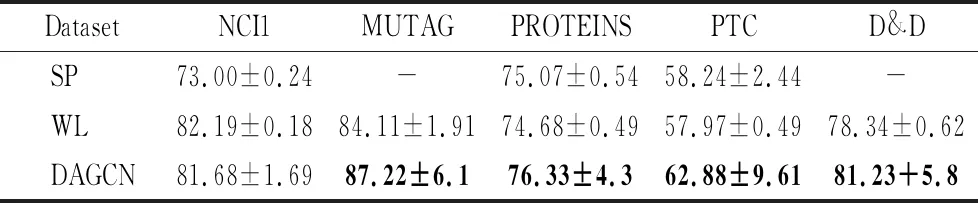
表4 图核算法的平均分类准确率Table 4 Average classification accuracy of the graph kernel algorithm
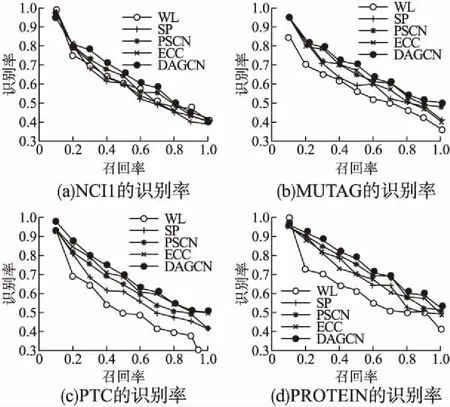
图3 4种算法的分类识别率Fig.3 Classification recognition rate of four algorithm
4.4 结果分析
4.4.1 复杂度对比
图核首先需要计算训练中每两个图之间的相似度数据集以形成相似性矩阵.给定大小的数据集N,则需要N(N- 1)/2个计算步骤.当数据集的大小时,这个数字随着数据集的尺寸的增加呈指数增长.另外,计算一对图之间的相似度也是基于图中的节点数.这限制了图核仅适用于小型数据集.通过设计,DAGCN的计算复杂度数据集大小和图的大小均线性增长.
4.4.2 图识别结果的比较
本文利用图的识别率指标比较了DAGCN和现有方法.本文将密集隐藏层的输出用作图数据的特征向量.由图3可知,在PTC,PROTEIN,NCI1和MUTAG数据集上,DAGCN优于其他方法.DAGCN在大多数数据集上均优于最近提出的g-CNN方法,因为对节点邻域进行正则化的过程会导致丢失有关节点邻域的信息,提出的DAGCN模型消除了节点邻域正则化期间的本地信息丢失.
5 结束语
在本文中,提出了一种新的双重注意图卷积网络(DAGCN)模型,其核心思想是最大限度地利用图输入的原始信息.使用注意机制来解决传统GCN模型的弱点.DAGCN模型中的注意力卷积层能够捕获比其他模型更多的层次结构信息,并提供单个节点和整个图的更多信息表示.注意力池层通过使用自注意机制来关注图的不同方面,生成固定大小的图嵌入矩阵.实验结果表明,DAGCN模型在多个标准数据集中优于其他深度学习方法和大多数图核.
