基于超统计的多阶段航空发动机剩余寿命预测
2021-02-05刘君强胡东斌潘春露雷凡赵倩茹
刘君强,胡东斌,潘春露,雷凡,赵倩茹
(1.南京航空航天大学 民航学院,南京211000; 2.南京航空航天大学 外国语学院,南京211000)
航空发动机的复杂性与精密性使之成为“工业之花”,而其安全与高效工作直接决定了航空运输的安全与效益,因此对它进行健康管理及剩余寿命预测至关重要。现代航空器的采购费用和使用保障费用日益庞大,据美军官方统计,在武器装备的全寿命周期费用中,使用与保障费用占到了总费用的72%[1]。与使用保障费用相比,维修保障费用在技术上更具有可压缩性。而故障预测与健康管理(Prognostic and Health Management,PHM)正是压缩维修保障费用的一个重要手段[2]。
在民航发动机的运行保障中,传统的方法是凭借检查发动机以判断其运行状况。近年来,越来越多的国内外研究员通过先进的PHM 技术对航空发动机的健康状态进行深入研究,主要内容包括发动机健康监测[3]、发动机失效机理[4]、发动机寿命预测等方面[5]。
在剩余寿命(Remaining Useful Life,RUL)预测模型研究中,主要包括基于数据驱动的方法、基于物理模型的方法和融合的方法。然而,航空发动机因设计结构复杂导致其物理模型难以确定,基于物理模型的方法和融合的方法,目前的研究较少。
大多研究人员采用基于数据驱动的方法对航空发动机的RUL进行预测。任淑红和左洪福[6]基于排气温度裕度(EGTM)对航空发动机进行RUL预测,但是仅通过单参数的RUL预测不能客观反映整台发动机的健康状况。赵广社等[7]基于多源数据对航空发动机进行RUL预测。张马兰[8]发现航空发动机RUL退化曲线前后阶段呈不同的退化模式,采用Kalman滤波(KF)和粒子滤波算法对其进行研究。Ram in和M ing[9]采用集成多参数的方法进行发动机RUL预测。综上可知,发动机RUL预测已经从单参数方法逐渐过渡到多参数方法。
Baraldi等[10]提出一种基于KF模型的退化预测系统进行RUL的预测。Cavarzere和Venturini[5]通过4种不同的方法对比对航空发动机的性能进行预测。An等[11]使用粒子滤波器来估计退化模型的参数。
对于航空发动机退化过程存在多阶段性的问题,张马兰[12]将航空发动机退化过程分为2个阶段;黄亮等[13]基于W iener过程开始对发动机进行两阶段RUL预测的研究。此外,国内较少有学者对发动机的多阶段退化及RUL预测问题进行研究。
因此,本文提出了一个基于超统计的多阶段航空发动机RUL预测模型,该模型可通过多源监测参数和突变点检测,将发动机退化过程划分为若干个退化阶段,从而精确预测发动机的RUL,并对该模型的收敛性给予了相应证明。基于该模型,本文提出了相应的算法,该算法先对航空发动机各个参数的时间序列进行多阶段退化识别;再采用无迹卡尔曼滤波(UKF)对融合的时变参数进行滤波处理;最后通过非线性拟合对发动机RUL进行预测。本文通过美国NASA提供的涡扇发动机数据对该算法的有效性进行了实验验证,结果表明,该算法在发动机性能退化中的预测具有较好的适应性,能更准确地预测发动机的RUL。
1 航空发动机RUL预测模型
针对传统航空发动机RUL预测模型无法客观描述多阶段性能衰退过程及对于RUL预测精度不高的问题,本文提出了航空发动机RUL预测模型以取得更准确的发动机RUL估计,该模型包含以下4部分:超统计理论、突变点检测、UKF、非线性预测。
1.1 模型组成
1)超统计理论
超统计理论作为统计物理学的一个分支,致力于研究非线性与非平衡系统,通过叠加多个不同的统计模型来描述目标模型的特征[14]。本文研究的是分布函数不变、分布参数变化的非平稳时间序列。将复杂的航空发动机系统抽象为2个部分的叠加,其一是相对微观的稳定平衡系统,即某时刻发动机的各个指标;另一部分是对应的宏观系统,即发动机整体性能,该系统服从一定统计分布F(x),随着使用时间的增加而缓慢变化。通过微观系统与宏观系统模型的叠加,可以描述随时间变化的复杂系统的分布模型。本文通过超统计理论对航空发动机的健康状态进行分析建模。
从微观角度建模。运用统计学方法对发动机指标变化情况进行分析,一般情况下,在环境参数ν一定的情况下,发动机健康状况异常的条件概率密度为
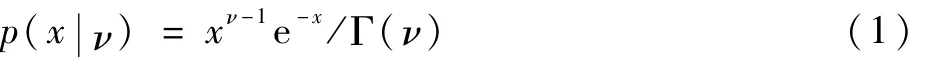
式中:Γ(ν)为Gamma函数;ν由发动机的运行状况决定,是一个受客流量大小、气候条件、运营维护(维修人员的故障检测、故障排除)[15]、线路设备故障等影响因素的正值参数。
从宏观角度建模。健康指标的状况是随着时间的推移而不断变化的,由于在时间维度上环境参数ν是变动的,这使得在较大的时间尺度内,健康指标的受损分布模型是一个与时间变量t相叠加的统计变量分布模型;引入时间维度的参数δ,可用δt替换x,则有式(2)成立:
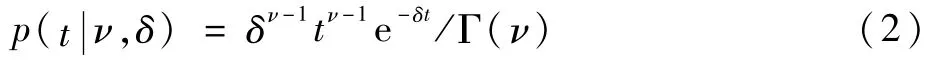
那么在较大的时间尺度内,宏观的发动机受损分布模型为微观与宏观模型的叠加。发动机受损的边际分布为
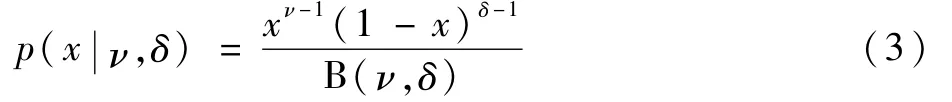
式中:B(ν,δ)为Beta函数。因此,发动机受损分布服从Beta分布模型。

2)突变点检测
航空发动机在服役期间,RUL逐渐缩短,通过突变点搜索模型根据时间序列显著性变化可以获得发动机潜在的性能突变位置,从而完成发动机衰退过程的阶段性划分。为了确定发动机突变点的准确位置,本文引入了真假突变点的概念:真突变点是通过突变点搜索与显著性分析,确认该时刻发动机性能相较前一时刻确实发生较大变化且满足统计显著性要求的突变点。假突变点是经分析,不满足显著性要求的突变点,这类假突变点将被剔除。该模型包括合并偏差SD(i)、t检验的统计量T(i)、统计显著性P(Tmax)3部分的计算。
合并偏差SD(i)的计算为

t检验的统计量T(i)的计算为

式中:n1和n2分别为分割点i左边部分和右边部分的点的总数;u1(i)和u2(i)分别为分割点i左边部分和右边部分的均值;S1(i)和S2(i)分别为i点前半部分和后半部分的标准偏差;T(i)分别为用于量化分割点i两侧差异程度的t检验统计值。
统计显著性P(Tmax)的计算为

式中:通过Monte-Carlo方法得η=4.19 ln m-11.54,m 为时间序列长度;ν=0.4,δ=m-2;Bx(a,b)为不完全Beta函数。通常情况下,L0≥25,P可取0.5~0.95,L0为最小分割长度。
3)UKF
UKF使用线性Kalman滤波的框架,对协方差预测矩阵使用无迹变换(UT)来处理均值和协方差的非线性传递问题[16]。UT变换即按照某一规则选取一定数目的样本点去近似一个正态分布进行UT变换,获得与原样本点具有相同均值与方差的Sigma点[17],从而有效克服线性Kalman滤波线性化误差较大的缺点。
针对某一非线性系统:

式中:Xk为k时刻被估计状态矩阵;Zk为k时刻被估计观测序列;Г为系统噪声驱动矩阵;W 为过程白噪声矩阵,具有协方差矩阵Q;V为观测噪声矩阵,具有协方差矩阵R。
该模型包括建立Sigma点矩阵、时间更新、观测更新3部分。
Sigma点矩阵及对应权值的计算[17]:
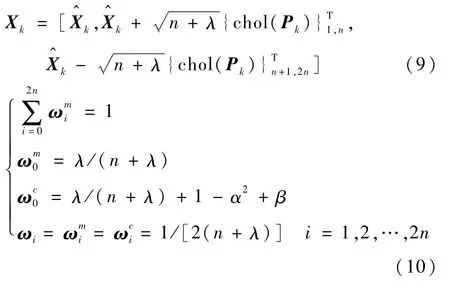
式中:n为随机变量维数;chol(Pk)为Pk的Cholesky分解;{chol(Pk)}T1,n为Pk的Cholesky分解所获得的下三角矩阵的第1~n列;Xi(i=0,1,…,2n)被称为Sigma点集;λ=α2(n+k)-n为一个缩放的尺度参数,α的取值范围一般为10-4≤α≤1,k的取值一般设置为0;采样点的权值ω上标m为均值,c为协方差,下标为第i个采样点;β包含着x的分布信息,当x符合正态分布时,β=2。
时间更新的计算为
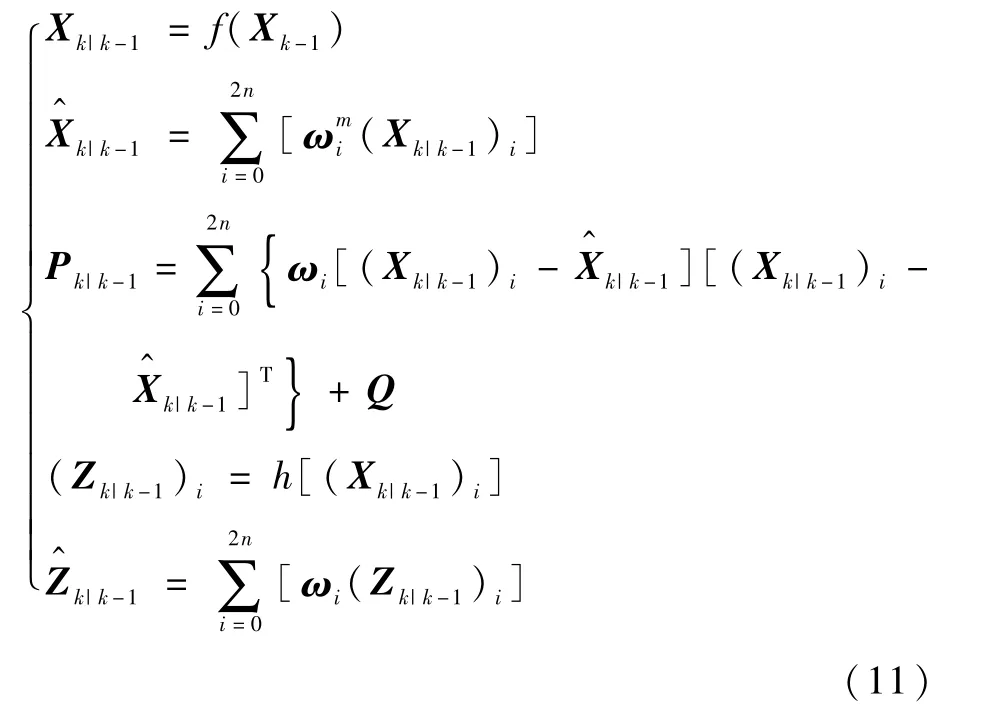
式中:Xk|k-1=f(Xk-1)为Xk-1的每一列向量通过f(x)变换得到Xk|k-1的每一个列向量;(Xk|k-1)i为Xk|k-1的第i列;Zk|k-1=h(Xk|k-1)与Xk|k-1=f(Xk-1)的变换相似。
观测更新的计算为

4)非线性预测
考虑到多项式函数具有逼近任何非线性函数的能力,滤波后多阶段的时变参数通过非线性拟合的方法对发动机RUL进行预测。

1.2 多阶段航空发动机RUL预测过程的收敛性
通过多阶段航空发动机RUL预测模型准确估计监测参数,以获得航空发动机真实的运行状态与RUL,这要求运用模型的过程具有某种收敛性。
定理1对于发动机性能退化数据,基于超统计的多阶段航空发动机RUL预测模型具有收敛性。
证明思路首先证明UKF具有收敛性;其次证明基于超统计的多阶段划分只能划分出有限个阶段;最后证明两者相融合后模型仍然具有收敛性。

证明
1)在时间序列中,UKF具有收敛性。

2)基于超统计的多阶段划分只能划分出有限个阶段。
通过对突变点搜索得到了突变位置,由于被划分的观测序列的长度有限的,那么进行分割后将得到一个长度更小的子序列,且子序列的个数有限。
因此,基于超统计的多阶段突变点搜索,只能划分出有限个阶段。
3)融合后的多阶段RUL预测模型具有收敛性。

由此可证明,对于发动机性能退化数据,基于超统计的多阶段航空发动机RUL预测模型具有收敛性。
证毕
2 算 法
2.1 BS-M SF算法
本文提出了基于超统计理论的多阶段分割滤波(Multi-stage Segmentation Filtering based on Super statistics theory,BS-MSF)算法,如图1所示。
BS-MSF算法包括以下6个过程:①对数据进行预处理;②进行基于超统计的突变点划分;③进行多参数的融合;④接着进行多阶段UKF;⑤通过非线性拟合得到退化模型非时变参数;⑥进行RUL预测。
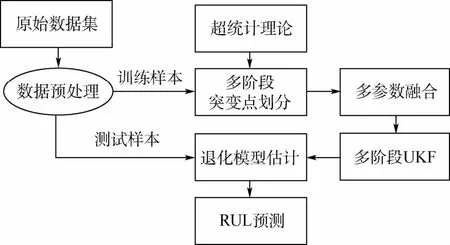
图1 BS-MSF算法Fig.1 BS-MSF algorithm
步骤1数据预处理。采用式(14)对数据进行归一化无量纲处理:

式中:min为由Sin经过无量纲处理后得到的值;Si0为第i个监测参数的第1个循环时的监测值;Sin为第i个监测参数的第n个循环时的监测值;Si1为第i个监测参数的最后1个循环时的参数。
步骤2基于超统计理论的突变点划分。分别计算合并偏差SD(i)、t检验的统计量T(i)、T(i)中的最大Tmax的统计显著性P(Tmax)对监测参数的时间序列进行分割。设置最小分割长度L0和统计显著性临界值P,当分割后的序列长度小于L0时,不再继续分割;如果P(Tmax)≥P,则当前点为突变点,继续进行分割,否则不分割。根据突变点显著性的大小进行分析,将满足显著性要求的突变点视为真突变点,不满足显著性要求的突变点视为假突变点。
步骤3多参数融合。采用式(15)对各监测参数的各阶段数据进行融合,生成多阶段健康指标H I[17]。
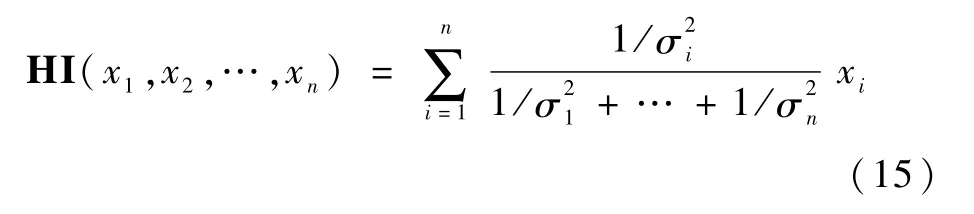
步骤4.1 无迹滤波处理。令与P0分别为原始数据的均值与方差,滤波参数初始化;采用式(9)对健康参数H I进行无迹变换处理;再采用式(11)、式(12)求解第一阶段的时间更新参数与观测更新参数。
步骤4.2 利用上一阶段的时间更新参数与观测更新参数计算下一阶段的相关参数,直至计算出全周期的时变参数|k。
步骤5非线性拟合。利用式(13)对发动机的时变参数进行非线性拟合,获得各阶段非时变参数。
步骤6利用非时变参数对测试集中的数据进行RUL预测并判断模型的预测效果。
2.2 算法优点
1)基于超统计理论,通过对突变点的搜索,对发动机的衰退过程进行阶段性的划分,以“多阶段退化”代替“正常与故障”2种状态,更符合发动机实际退化特点。
2)采用多参数的信息融合方法表征发动机整体的健康状况,避免单参数预测造成结果的不稳定,可充分利用监测参数所包含的信息。
3)状态空间方法通过状态转化关系描述揭示系统的内在规律,并且将状态变化与时间变量结合,建立了时间序列的预测模型。
4)UKF算法基于带噪声的观测数据递推得到预测模型的时变参数,因此预测结果精度较高且具有较好的预测演化过程;另外,该算法仅使用发动机的观测数据,不需要大量的失效数据,因而符合实际工程应用。
3 实验分析
本文选取了美国NASA涡扇发动机数据中与温度、压强、转速有关的T24,T30,T50,P30,Nf,Nc,T48 7种气路性能参数作为实验数据[19],参数的具体含义如表1所示。
步骤1本文以美国NASA发布的数据为训练样本,研究发动机性能衰退的阶段性特点,采用式(13)对数据进行归一化处理,使其不同的监测数据经变换统一到同一区间,结果如图2所示。
步骤2基于超统计理论的多阶段分割算法进行阶段划分。在训练样本集中,本文采用L0的取值为25,超参数q的取值为0.95进行阶段分割,例如对T24的阶段划分,结果如图3所示,其中与纵轴平行的线段为分割点,阴影区域为严重突变区域。
例如,参数T24初步划分后的分割点分别为:141、192、219、252、270,相应突变点对应的显著性如表2所示。

表1 用于发动机RUL预测的重要监测参数Table 1 M ajor m onitoring param eters for p rediction of engine RUL

图2 归一化的监测序列Fig.2 Normalized monitoring sequence
将该特征参数的各分割点根据其显著性由高到低进行排序,对应显著性水平最高的4个突变点作为该特征参数的最终突变点。因此,参数T24划分后的真分割点为:141、192、219、252循环时,而第270循环时为假突变点被剔除。同理得7个特征参数的多阶段分割结果如表3所示。

图3 T24的突变点与退化量Fig.3 Mutation point and degradation quantity of T24

表2 T24突变点的显著性Table 2 Significance of m utation point of T24
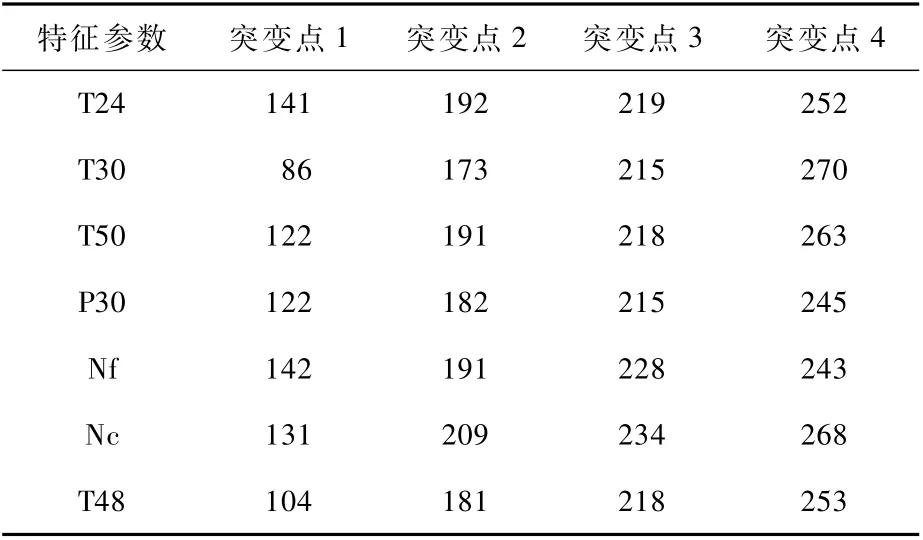
表3 各特征参数的对应突变点Tab le 3 Corresponding m u tation poin t of each characteristic param eter
可见,7组特征参数的4个突变点没有严格在同一个点上,但也比较接近,对整体的突变点位置求解采用计算平均值的方法,最终确定训练序列中4个突变点的具体位置在:第121循环时、第188循环时、第221循环时、第256循环时。
步骤3采用式(15)将7个监测参数的数据进行融合。对5个阶段的7个参数进行融合后的综合健康指标如图4所示。
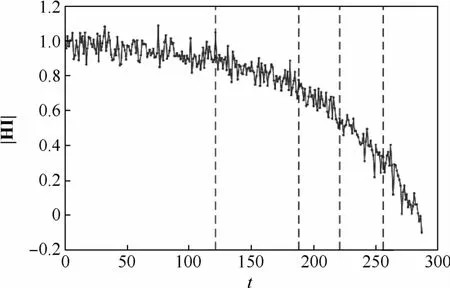
图4 多阶段非线性融合H I序列Fig.4 Multi-stage nonlinear fusion of H I sequence

由图5(e)可见,通过多阶段的UKF预测性能比卡尔曼滤波的效果更优,具有更小的绝对误差,能更好地模拟发动机真实的退化过程。
步骤5非线性拟合。经过3种方式滤波的仿真计算,本文通过非线性拟合的方式,对发动机寿命衰退进行建模。
将不同的非时变参数作对比,通过单阶段KF滤波拟合状况最优概率的预测模型为
(a0,a1,a2)=(-1.857,0.02257,-6.164×10-5)
通过多阶段KF滤波最终确定拟合状况最优概率的预测模型:
第4阶段:
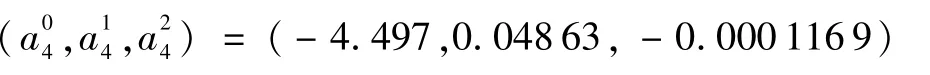
第5阶段:
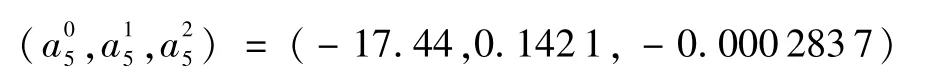
通过多阶段UKF滤波最终确定拟合状况最优概率的预测模型:
第4阶段:
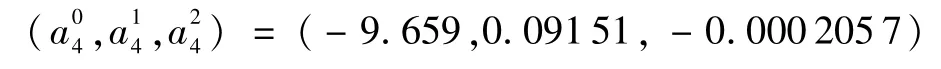
第5阶段:

寿命预测演化过程如图6所示,其拟合误差结果如表4所示。
可见,随着飞行循环时的增加,对于发动机RUL的拟合越来越准确。
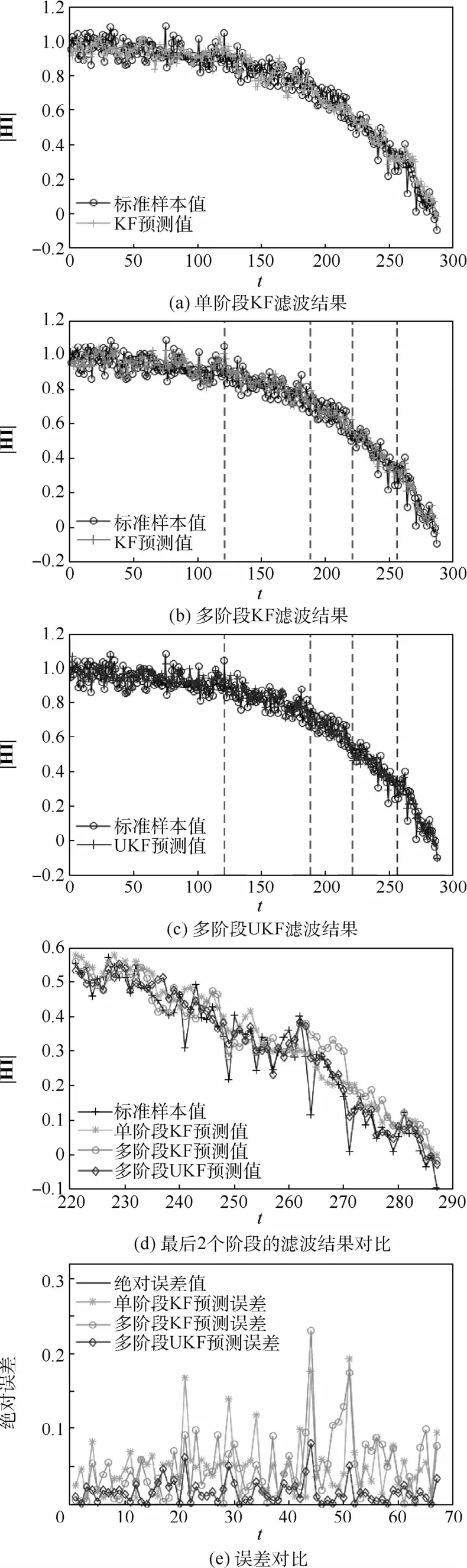
图5 滤波结果比较Fig.5 Comparison of filtering results
对于利用该方法对发动机RUL预测结果的优劣,可以用相对误差、误差平方和、均方根误差进行评价[20],本文将测试样本集中数据通过相同的方法进行计算处理,并对以上3种RUL预测模型做了多次实验。

图6 寿命演化过程Fig.6 Life evolution process

表4 拟合误差Table 4 Fitting errors
步骤6寿命预测。实验中绝对偏差与相对误差的定义为
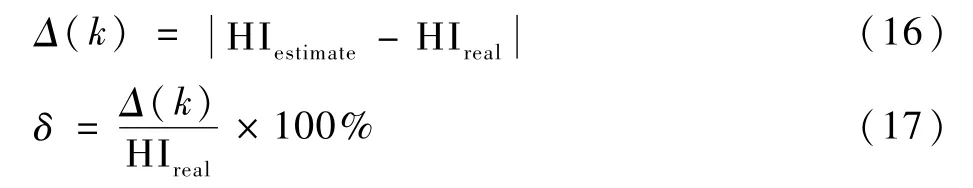
式中:HIestimate为预测寿命;HIreal为实际寿命值。
多次实验的预测误差结果如表5所示。不难发现,单阶段KF的相对误差比多阶段KF的误差要高得多,而多阶段UKF的误差均值在大多数情况下是比多阶段KF更小的,这证明了UKF的状态估计准确性在多数情况下优于KF的估计,但也并不绝对,如第2次实验中,多阶段KF的偏差均值比多阶段UKF更小,也就是说,UKF在处理非线性问题中从概率统计的意义上优于KF。
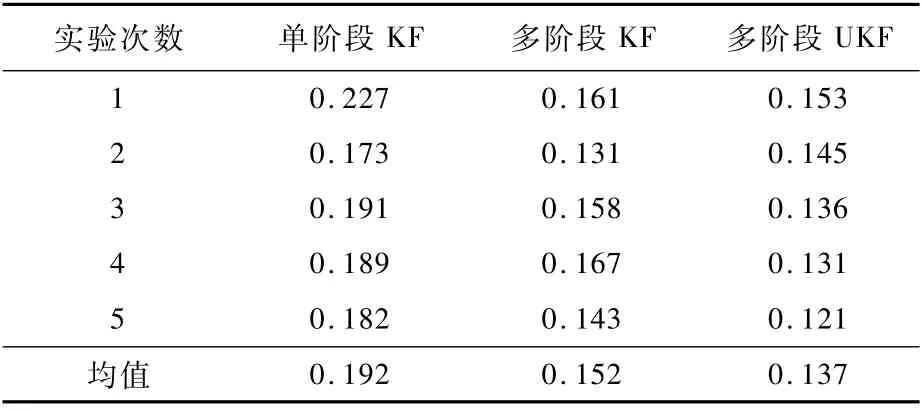
表5 预测误差Tab le 5 Prediction er rors
4 结 论
本文提出了一种多阶段航空发动机RUL预测模型与相应的BS-MSF预测算法。通过实验对本文模型与算法进行验证,结果证明了该方法的合理性。本文提出的理论模型与算法主要贡献如下:
1)采用超统计分割算法对航空发动机的RUL阶段进行划分,在确定了发动机退化阶段的同时,用退化阶段客观描述发动机RUL的长短。
2)UKF滤波算法克服了KF的系统初始值不确定、线性假设前提带来滤波效果下降的缺点,UKF滤波算法降低了5.5%误差,在退化过程中对发动机真实性能的把握具有更好的适应性。
因此,基于多阶段航空发动机RUL预测模型的BS-MSF算法是一种能对发动机状态进行跟踪与RUL预测的有效算法。
