多判别器循环生成对抗网络的素描人脸合成
2021-02-04周华强杜康宁
周华强,曹 林,杜康宁
1.北京信息科技大学 光电测试技术及仪器教育部重点实验室,北京100101
2.北京信息科技大学 信息与通信工程学院,北京100101
素描人脸合成是指在给定训练光学人脸图像集和素描人脸图像集的情况下,根据一张光学人脸图像合成出一张素描人脸图像。随着合成技术的发展,素描人脸合成在数字娱乐产业和刑侦领域中发挥着重要的作用[1]。就刑侦领域而言,可能存在以下状况:在视频监控中提取到的人物面部照片分辨率较低,或受到姿势、光线的影响没有获取到清晰图像,不能为身份识别提供证据,此时需要由法医从被记录的视频或目击者的描述中绘制出素描图像来进行匹配。但是素描人脸图像和光学人脸图像属于异质图像,二者很难取得良好的识别效果,此时素描人脸合成对犯罪嫌疑人的识别起到替代作用[2]。在数字娱乐领域,素描图像被用作个人资料头像越来越受智能手机和社交网络用户的欢迎,光学人脸图片转换为素描风格图片在社交美图软件市场也得到了广泛应用。
目前已知的素描人脸合成方法主要有模型驱动和数据驱动两类。基于数据驱动的代表方法有Wang 和Tang[3]提出的基于概率图形的马尔可夫随机场模型以及基于子空间学习的局部线性嵌入[4]合成方法。基于模型驱动的主要方法有多变量输出回归方法[5]以及基于贝叶斯学习[6]的方法等。上述方法得到的合成图像素描效果和艺术家手绘的素描人脸图像相比,没有很好地捕捉个人细节,导致合成出来的素描人像与光学人像相似度不够;合成的素描缺乏艺术性,在对比过程中发现有些方法由于过度平滑丢失了素描的风格。
近年来,生成对抗网络(Generative Adversarial Network,GAN)[7]由于其强大的生成能力在计算机视觉领域取得巨大的成功。特别是传统GAN及其变体在图像生成[8]、图像编辑[9]、表示学习[10]、运动模糊图像复原[11]等方面取得了令人瞩目的成绩,弥补了传统方法的不足。Guérin 等人提出使用CGAN 进行地表模型绘制[12]应用于电影和游戏领域中,Isola等[13]提出基于像素的生成对抗网络考虑使用成对数据集进行图像风格转换,Zhu等人[14]提出了CycleGAN使用无监督学习进行图像风格转换。王孝顺等人[15]提出了LSTGAN 与单领域判别训练法进行迁移学习。
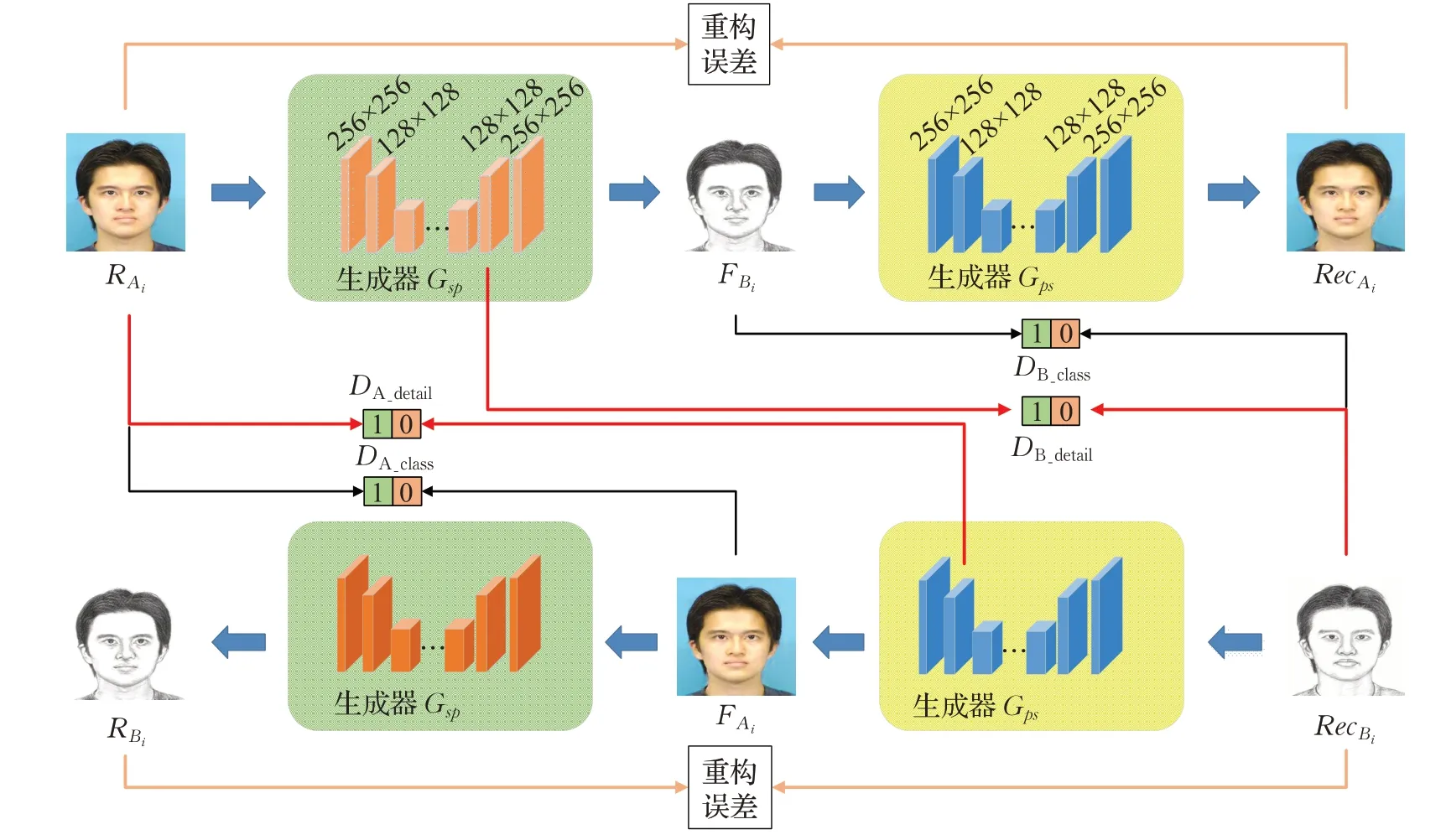
图1 MDC-GAN结构图
针对素描人脸合成问题,本文提出一种多判别器循环生成对抗网络(Multi-Discriminator Cyclic Generative Adversarial Network,MDC-GAN)。该方法在传统CycleGAN 的基础上,引入了多判别器网络结构与重构误差损失,避免了传统方法中繁冗的计算步骤,克服了传统GAN 模式易崩溃问题,优化CycleGAN 网络结构,提高合成素描图像质量。在判别网络中采用多判别器提供多通道特征融合方法提取图像特征,通过添加产生一维输出的卷积层使提取的特征能够表示更多图像信息。新增加的重构误差损失能够实现网络整体的反向传递优化,并且重构误差损失在训练过程中定义为正则化,对损失函数进行限制,有效避免训练过拟合,提高训练时网络的稳定性。并且本文方法在处理光学面部图像中的非人脸特征(如眼镜、围巾等)时,也表现出很好的鲁棒性和准确性。
1 多判别器生成对抗网络
1.1 网络结构
传统GAN网络由一个生成模型和一个判别模型构成,在训练过程中二者构成一个动态的“博弈”过程[16]。但是传统GAN 的网络结构是单向生成,采用单一生成对抗损失优化网络参数,在训练过程中会导致多个样本映射到同一个分布,从而容易导致网络的模式崩溃。所以本文采用双层循环对抗网络[14]的方式,有效避免了传统网络的缺点。该方法新增的多判别器网络(图1中红色箭头所示)可以有效克服生成的素描图像细节特征不明显、缺乏真实感的问题;重构误差损失(图1中橙色箭头所示)计算生成图像和目标图像之间的L1距离,实现生成结果对整个网路的反向传递,增强原有网络稳定性。
1.1.1 素描人脸合成模型
假设给定一个数据集U由光学人脸图像-素描人脸图像对组成,本文方法中素描人脸合成的目标是学习两个功能:B′=fps(A)代表光学人脸图像A 生成素描人脸图像B′;A′=fsp(B)代表素描人脸图像B 生成光学人脸图像A′。
本文方法包含四个生成模型,四个判别模型,MDCGAN 素描人脸合成框架如图1 所示。其中两个Gps为相同的生成器模型,共享相同参数,两个Gsp生成器模型同理。生成器Gps采用真实的光学人脸图像RA作为输入,并输出合成的素描人脸图像FB;Gsp的目标是将素描人脸图像转换为光学人脸图像,它将FB转换回输入的图像本身,这里本文将其表示为RecA。因此,一般过程可以表示为:
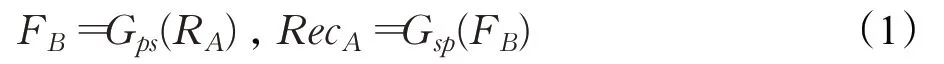
同样,素描到照片转换可以表示为:
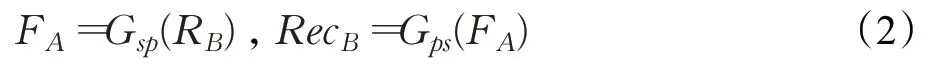
如图1所示,MDC-GAN的生成器模型Gps和Gsp分别在不同分辨率级别生成和输出图像,四个判别器模型分别为用以鉴别生成图像的真实性。由于GAN网络在生成不同分辨率层级图像的过程中,会随着像素空间维数的增加,出现由像素空间不均匀覆盖而导致的伪影。针对GAN网络在伪影问题的局限性,本文选用多个独立的判别子网络对不同分辨率层级的图像进行监督,并向生成器提供对抗性反馈,形成隐式迭代的细化特征映射,从而生成高质量图像。本文结构采用四个结构相对简单的判别子网络,只在训练阶段约束网络,减少测试阶段网络的参数量和计算量。
1.1.2 生成网络
传统GAN 的生成网络由简单的卷积层和反卷积层组成,提取出的图像特征所传递的信息质量不高,容易丢失图像的细节特征,导致生成图像模糊。而本文选用深度神经网络提取图像信息,利用生成器子网络中隐藏存在的不同分辨率的特征图映射,在低分辨率阶段捕捉图像细节特征,建立浅层信息与深层信息的传递通道,改变原有的单一线性结构。对于深度神经网络,加深网络层次是提高精度的有效手段,但是持续加深网络深度会出现梯度弥散的问题。其原因在于反向传播中误差不断积累,导致网络最初几层梯度值接近为0,从而无法收敛。测试发现,当深层网络层数达到20层以上,会随层数增加,收敛效果越来越差,出现深层网络退化问题。
针对上述问题,本文生成器借鉴深度残差网络(Residual Network,ResNet)[17]的网络结构,共包含3 个部分:前部是3 个卷积层,中部是9 个残差块,后部是2个转置卷积和1个卷积层,共15层。卷积层结构如图2所示,其中第一层和最后一层的卷积核尺寸为7×7,其余层卷积核尺寸均为3×3。在每次进行卷积操作前对特征图进行边缘补零(Zero-Padding)处理,用于防止图像边缘信息点丢失,并保持输入与输出维度相同。卷积结束后对特征图进行实例归一化(Instance Normalization)处理,目的在于归一化当前层输入,减小特征图中不同通道的均值和方差对图像风格的影响,并且加速模型收敛,提升网络稳定性。最后卷积激活层中采用带泄露修正线性单元(Leaky Rectified Linear Unit,LeakyReLU)作为激活函数,转置卷积激活层中将修正线性单元(Rectified Linear Unit,ReLU)设置为激活函数。转置卷积层依次对不同分辨率的特征图进行上采样。每个转置卷积层的特征图谱通过3×3卷积层进行转发,生成不同分辨率的输出图像。
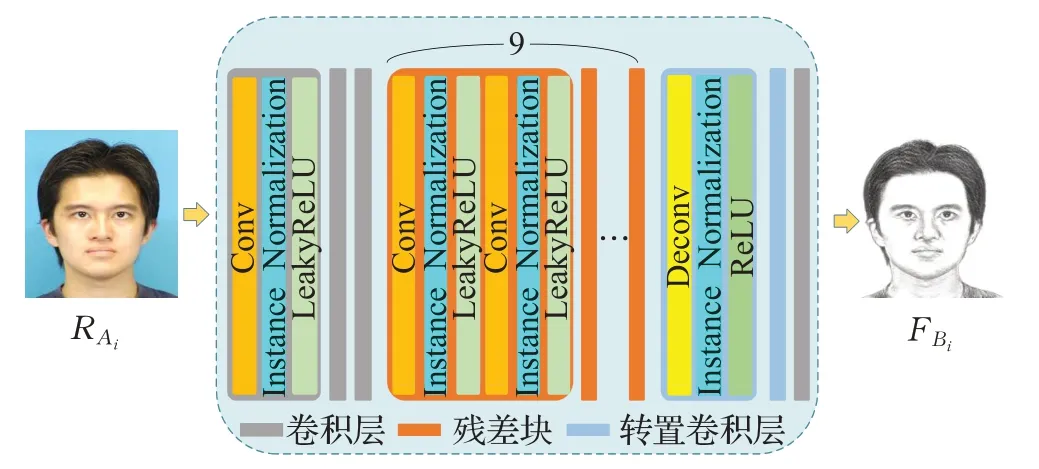
图2 生成器网络图
1.1.3 判别网络
GAN网络中判别器模型的目的是学习生成图像与真实图像之间的差异,通过与生成器形成对抗学习的方式,提升识别出真假样本的准确率以及优化生成模型参数,联合生成器下降梯度,提高生成图像的质量。
传统GAN 网络判别器采用单层特征表达图像信息,在识别过程中容易造成图像细节丢失。本文使用70×70PatchGAN[13]构建判别器模型,与全图像输入的判别器相比其维度降低,所需参数更少,可以处理任意大小的图像。而且PatchGAN判别模型中图像间像素距离仅存在于每一个Patch,而不是整张图像。这样在素描人脸合成过程中,可以有效捕捉人脸中的一些高频细节特征,例如面部纹理风格;而全局和低频特征则由对偶联合损失捕捉,从而合成的人脸图像细节更丰富,更具素描风格。
本文提出的多判别器均采用全卷积网络,多个通道最大程度提取图像高频特征信息,判别器网络中将输入图像映射为70×70 的矩阵(Patch)X,对每个图像局部分块来进行判别。其中Xij的值代表输入图像中一个感受野,为每一个图像局部分块是否为真实样本的概率,最后取输出矩阵中Xij的均值作为PatchGAN判别器的输出。本文方法中加入的判别器将不同分辨率级别的图像转化成多个图像局部分块,对每个块单独判别。判别器网络结构如图3 所示,由五层卷积操作组成,均使用4×4 大小的卷积核,输入为不同分辨率的三通道图像,前四层卷积核数分别为[64,128,256,512],且步长(Stride)为2。在卷积结束后连接批量归一化(Batch Normalization)进行处理,激活层设置LeakyReLU 作为激活函数,第五层的卷积核数为1,步长为1。最后,将特征向量输入至Sigmoid 激活函数[14],判别生成样本是否符合真实样本的分布。
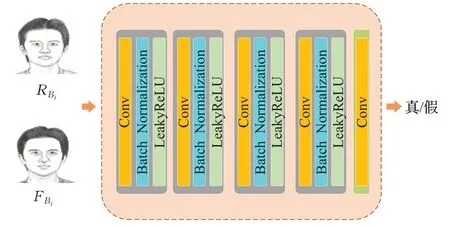
图3 判别器网络图
1.2 损失函数
本文方法联合生成对抗损失、重构误差和对偶联合损失共同训练网络,有效避免了传统GAN 网络中存在的模式易崩溃等问题。为了缩小生成样本与决策边界距离,MDC-GAN中联合使用最小二乘损失和重构误差损失改进CycleGAN中原有的生成对抗损失,并使用对偶联合损失减少多余映射,提高生成图像质量。
1.2.1 生成对抗损失和重构误差
原始CycleGAN 网络中交叉熵的损失函数如式(3)所示:
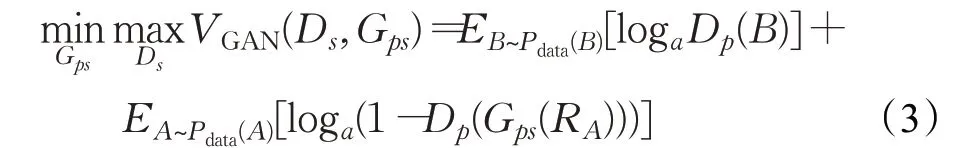
生成器使用交叉熵损失不会进一步优化远离决策边界但被判别器鉴别为真的生成图像,这样会降低生成网络生成图像质量。对比交叉熵损失函数,本文选用的最小二乘损失函数会在判别器判决为真的前提下,把远离决策边界的生成图像重新置于决策边界附近,降低饱和梯度。通过使距决策边界不同的距离度量构建出一个收敛快、鲁棒性高的对抗网络。

式中,Ai~pdata(Ai)是样本A空间的服从的概率分布,Bi~pdata(Bi) 是样本B空间的服从的概率分布,和表示各自样本中的期望值。由式(4)可以得生成网络与判别器的损失函数目标如式(5)所示:

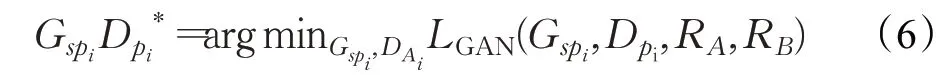
为了使生成器的生成图像尽可能接近目标图像,本文采用最小化重构误差LRec。其中重构误差LRe c定义为合成图像与目标图像的L1范数,计算生成图像与目标图像之间的距离。本文使用L1范数能够有效避免训练中多张人脸图像用一个单峰的高斯分布进行拟合,防止生成图像过于平滑;而且L1范数鲁棒性较好,能够更好处理数据中的异常值,忽略生成图像与目标图像之间微小误差,而去处理过大的误差。网络使用L1范数损失使其不会因对单一样本误差值,而影响其他正常的样本,在一定程度上提升训练网络的稳定性。LRec在两个分辨率级别上都被最小化,其函数定义如式(7)所示:
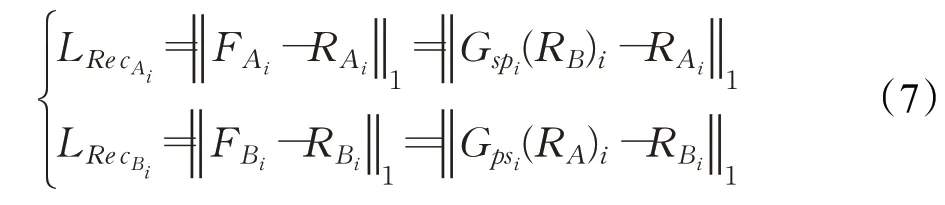
1.2.2 对偶联合损失
从理论上讲,使用生成对抗损失可以学习到输入域和目标域的映射关系,但是由于网络容量大,训练中单独依靠对抗损失可能会出现多余映射的问题,导致生成器任意随机排列输入域到目标域的集合映射,图像转换过程中有效特征信息无法准确映射。因此,本文网络通过在不同分辨率阶段使用对偶联合损失对前后一致性进行了正则化约束,从而减少输入域到目标域可能存在的映射路径;并能够促使网络增加采用更简路径的趋势做映射以保持图像轮廓结构,一定程度提升网络映射性能,有效避免交叉映射。其函数定义式如式(8)所示:

综上所述,完整的损失函数为生成对抗损失、重构误差和对偶联合损失之和,如式(9)所示:

其中αi,βi参数用于调整重构误差损失和对偶联合损失的权重。
2 实验与分析
在本章进行模型简化实验(Ablation Studies),以验证所提出的方法的有效性。并给出了本文方法与现有方法在CUHK(The Chinese University of Hong Kong)[3]和AR(Aleix Martinez and Robert Benavente)[18]两个常用数据集上的定性和定量结果比较。
2.1 实验步骤
(1)数据集:本文方法选用香港中文大学人脸素描库(CUHK)中的188 张学生人脸进行实验,其中每一张光学人脸图像都有对应的素描人脸图像,由艺术家根据一张在正常光照条件下正面拍摄的中性表情照片绘制出。其中选择100 对光学人脸图像-素描人脸图像用作训练集,28 对用作验证集,60 对用作测试集。AR 人脸数据库由阿联酋计算机视觉中心工作人员创建,其中包括123 人超过4 000 张彩色图像,每个人都挑选一张富有表情的正面光学人脸图像和一张艺术家观看照片时绘制的形态夸张的素描人脸图像。AR数据集中光学图像是在不同光照下拍摄,没有限制人物的穿着、化妆品、发型等,而且与光学图像相比素描样本形态夸张,更接近刑侦场景,训练时将123对光学人脸图像-素描人脸图像中100对用作训练集,23对用作测试集。这两个数据库都包含面部特征点坐标,应用最新的人脸对齐算法进行对齐。
(2)实验过程:在训练模型过程中,网络输入图像的大小为256×256,前100 个周期生成网络与判别网络初始学习率η为0.000 2,后100个周期学习率线性衰减为0。其中αi=1,βi=0.7,采用动量为0.5 的Adam 优化器进行训练,利用梯度一阶矩估计(First Moment Estimation)和二阶矩估计(Second Moment Estimation)动态调整每个参数的学习率在确定范围内,在经过修正一阶矩估计和二阶矩估计的偏差后,经过多次迭代训练使网络模型逐渐收敛,并保存网络参数,网络中批处理大小(Batch-size)为1。本文中所有模型均在PyTorch中实现,GPU 为英伟达公司NVIDIA Titan X(Pascal),其中CUHK 人脸数据集和AR 人脸数据集分别迭代200 次,均用时4 h,且本文改进网络参数规模为30.68×106。其中图像大小为256×256,测试阶段合成单张图片平均耗时约0.140 s,满足实时性要求。
2.2 实验结果与分析
2.2.1 模型有效性实验
本文在CycleGAN的基础上,利用生成器子网络中隐藏在不同级别分辨率的特征图映射关系,提出多判别器循环生成对抗网络的素描人脸合成方法。该方法在生成对抗损失中使用最小二乘损失替换原始网络中的交叉熵损失,使用L1范数描述重构误差损失和对偶联合损失损失。
为了验证本文提出的多判别器网络结构在素描人脸合成的有效性,将本文方法与CycleGAN在CUHK人脸数据库进行验证。CycleGAN与本文方法保持完全相同的数据集和参数进行训练。在CUHK 学生人脸数据库中的生成图像的效果如图4 所示。其中第一行至第四行分别为输入图像、真实图像,以及CycleGAN、本文方法生成的素描人脸图像。

图4 改进方法对比
通过图4所示可以看到,与原始CycleGAN相比,本文方法生成的素描面部图像具有更清晰的轮廓,细节更完整。在面部特征上与原图更相近,尤其是对五官的表现更加准确与锐利;在风格方面,本文方法生成的样本更具有素描风格。表1比较了CycleGAN与本文方法在CUHK 数据集上的结构相似度(Structural Similarity Index,SSIM)[19]和特征相似度(Feature Similarity Index,FSIM)[20]数值,其中度量标准SSIM 和FSIM 的值越大,代表生成的素描图像与输入的真实样本结构越相似,质量越高。由表1可见,本文方法计算出的生成图像与真实图像的SSIM 和FSIM 结果均优于CycleGAN 计算结果,验证本文方法网络结构的有效性。

表1 模型对比实验在CUHK数据库中SSIM值与FSIM值
为了进一步验证本文损失函数在训练模型中的有效性,在实验中分别设计了四组实验,并在CUHK 数据集进行验证,其中基础网络的网络结构与本文方法相同,损失函数中包含生成对抗损失和对偶联合损失,其中使用交叉熵损失函数描述生成对抗损失。对不同损失函数的生成素描图像的效果如图5 所示。其中第一行至第六行分别为输入图像、真实图像、基础网络、基础网络+LLSGAN(基础网络中最小二乘损失替换交叉熵的损失),基础网络+LRec(基础网络中增加重构误差)、基础网络+LLSGAN+LRec(网络只采用生成对抗损失和重构误差),以及本文方法生成的素描人脸图像,在CUHK 数据库中SSIM 值与FSIM 值的损失对比实验如表2所示。

图5 损失函数对比
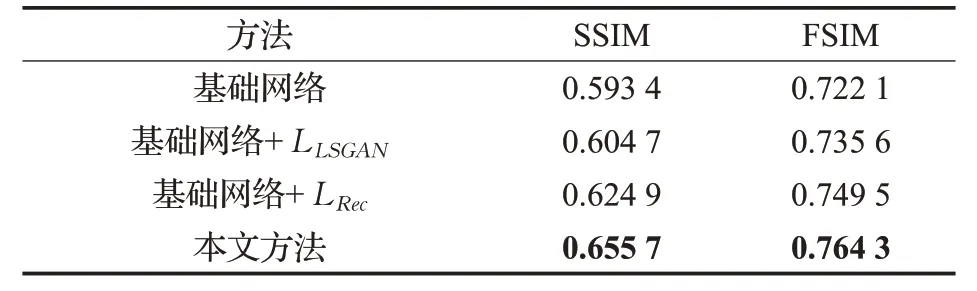
表2 损失对比实验在CUHK数据库中SSIM值与FSIM值
由图5 中可以看出基础网络使用交叉熵损失函数时生成的素描图像的面部细节相对较差,第三行中人物的五官,如嘴唇等,都出现了明显的模糊效果;而第四行使用最小二乘函数作为生成对抗损失后,生成的素描面部图像细节更加清晰,克服了模糊效应。但是由于重构误差的缺失,导致部分发型特征缺失(红色标记);第五行使用重构误差的生成图像中面部特征未出现较大误差,面部清晰度较低;第六行网络损失函数中不包含对偶联合损失,生成的素描图像中第一张样本人物发型轮廓模糊,第二张面部五官轮廓模糊,第三张图像与真实图像形态差异较大(红色标记);本文方法中的素描图像均未出现面部失真、特征缺失等问题。通过对比不同改进方法的生成图像来看,本文方法的生成图像特征完整,细节清晰,更具素描风格,并由表2 可见,本文方法的SSIM 和FSIM 值均优于其余损失对比组,验证本文方法损失函数的有效性。
2.2.2 方法对比实验
本文方法与现有不同类型的素描人脸合成方法进行了对比实验,并且和有效性实验一样,使用结构相似度(SSIM)和特征相似度(FSIM)进行量化对比,度量结果如表3所示。在CUHK的合成效果如图6所示。其中第一行为输入光学图像,第二行为真实素描图像,第三行至第七行分别为马尔可夫权重场(Markov Weight Field,MWF)[21]、Pix2Pix[13]、CycleGAN、DiscoGAN[22]、本文方法生成的素描人脸图像。

表3 CUHK数据库中SSIM值与FSIM值

图6 不同合成方法在CUHK上的对比
由图6 可以看出,传统方法中MWF 的合成效果比较模糊,而CycleGAN、DiscoGAN、Pix2Pix 等方法由于在生成高分辨率图像时网络的不稳定性,往往会在生成图像中产生小块的伪影。相比之下,本文方法(MDCMAN)能够对隐藏层进行监督,最大程度保留图像高频特征,最小化素描图像的伪影,并且本文方法的生成样本更接近素描风格。此外,由于在训练模型时可能出现参数丢失,使得DiscoGAN 的合成样本出现颜色失真,缺乏素描风格。因此,本文使用目标和合成图像之间的重构误差约束网络,增强网络稳定性。由表3 可见,本文方法在CUHK数据集下SSIM值和FSIM值分别优于其他方法的计算值,说明MDC-GAN生成的素描图像质量更高,与原图结构更相似。
为了进一步验证本文方法的合成效果,与现有不同类型的素描人脸合成方法在AR人脸数据库的对比验证如图7所示。其中第一行为输入光学图像,第二行为真实素描图像,第三行至第七行分别为LLE[23]、MWF、Pix2Pix、DiscoGAN、本文方法生成的素描人脸图像,同时也对生成图像进行了定量值比较,如表4所示。
使用AR人脸数据库进行素描人脸合成更具有挑战性,因为原始图像中人物面部细节更多,并加入了人物饰物。从图7可以看出,传统方法合成的素描人脸图像中,由于LLE方法可能在寻找最优图像块集合过程中丢失较多高频信息,导致生成的图像出现了部分伪影(第三行红色标记),并且出现图像轮廓模糊;MWF 方法生成的图像面部失真严重;Pix2Pix、DiscoGAN 方法生成的图像伪影较传统方法减少,但仍然存在(第三、四行红色标记)。并且DiscoGAN 训练阶段采用S 形交叉熵作为对抗损失,很难使生成模型达到最优,导致面部清晰度较低。而本文方法的合成效果明显优于其他方法,并且面部轮廓清晰,同时保留高频细节和最小化伪影。并且在眼睛、胡须、发型等面部特征方面,即使在拍摄时人物环境出现干扰因素,例如眼镜出现反光等,仍具有较好鲁棒性。所以本文方法生成的图像质量较现有方法相比取得了更好的结果,与真实素描图像重合度更高。并且由表4 定量分析可以看出,面对复杂的AR 人脸数据库,本文方法较其他方法仍表现出优异性。

图7 不同合成方法在AR上的对比

表4 AR数据库中SSIM值与FSIM值
通过模型简化实验,与现有方法比较,并且对生成的素描图像进行定性与定量的实验分析表明,本文提出的多判别器循环生成对抗网络(MDC-GAN)的素描人脸合成方法,能够生成更真实的素描图像,并且在多种质量标准(SSIM和FSIM)比较方面,本文方法均能取得显著的改进,输出高质量图像。
3 结束语
本文提出了一种基于多判别器循环生成对抗网络的素描人脸合成方法。该方法提出对判别器子网络隐藏层进行对抗性监督的网络结构,通过多判别网络对生成网络的反馈传递优化完善生成图像中高频特征细节,并且使用最小二乘损失描述生成对抗损失,结合重构误差损失和对偶联合损失,生成高质量图像。实验结果表明,本文方法较其他方法在主观视觉和客观量化等方面都取得了更好的评价,能够获得细节完整、轮廓清晰的高质量素描面部图像,能够充分应对复杂情况下的生成素描图像任务并具有良好的鲁棒性。
