意图识别与语义槽填充的双向关联模型
2021-02-04王丽花杨文忠理姗姗
王丽花,杨文忠,姚 苗,王 婷,理姗姗
1.新疆大学 软件学院,乌鲁木齐830046
2.新疆大学 信息科学与工程学院,乌鲁木齐830046
目前阶段的人机交互方式主要以人机对话为主,如谷歌Home、天猫精灵等。口语理解是人机对话系统中的重要环节,旨在形成一个语义框架来捕获用户话语或查询的语义[1]。意图识别和语义槽填充又是口语理解的两个重要子任务,通过意图识别挖掘用户在自然语言中表达的意图,再利用语义槽填充提取话语中的语义概念。
对于给定的一组用户话语,意图识别是在句子层面理解整个语句的语义,然后识别出该语句的意图[2];语义槽填充任务在单词级别标注这句话,每个词对应一个槽标签,最终输出与输入序列长度相同的槽标签序列。如表1为意图识别和语义槽填充任务的一个标注实例,取Snips[3]数据集中的一条数据“play a popular chant by Brian Epstein”作为输入。在语义槽标注时采用Begin/In/Out(BIO)标签标注分词结果,槽标注结果如“Slots”一行所示,槽标签“B-artist I-artist”为艺术家的名字,意图的识别结果如“Intent”一行。输入的话语通过意图识别与语义槽填充任务处理之后,形成一个简单的语义框架,可以很好地捕捉用户话语的语义。

表1 用户话语标注示意表
意图识别和语义槽填充作为口语理解的两个关键子任务,两者之间存在紧密的联系,考虑到单独研究意图识别和语义槽填充模型容易出现误差传播,使口语理解性能下降,提出意图识别语义槽填充的联合模型[4]。基于此本文提出了基于门控机制的双向关联模型(Bidirectional Association Gate,BiAss-Gate)来完善现有的联合模型,通过深入挖掘意图识别与语义槽填充之间的联系,建立双向关联机制,弥补了现有联合模型中存在的浅层关联、单向关联的不足。
1 相关工作
在传统的研究中,意图识别和语义槽填充任务分别单独处理。
意图识别常被视为多分类任务。对于给定的一组话语,预测出该话语所对应的意图类型。常用的意图分类方法有支持向量机(Support Vector Machine,SVM)[5]、朴素贝叶斯[6],近年来,深度神经网络方法也被用来进行意图分类[7],并取得了不错的效果。文献[8]提出了一种基于注意力机制的CNN(Convolutional Neural Networks)-LSTM(Long Short-Term Memory)模型来预测用户意图,并将无监督聚类方法应用于用户意图分类。文献[9]提出基于门控机制的信息共享网络来检测口语意图。
语义槽填充通常被视为序列标注任务,对于给定的一组话语,输出所对应的最大概率的槽标签序列[10]。条件随机场(Conditional Random Fields,CRF)[11]和长短时记忆网络(LSTM)[12]常常被用来处理序列标注任务。文献[13]用递归神经网络(Recursive Neural Network,RecNNs)来处理语义槽填充任务;文献[14]用语句级信息和编码器LSTM来填充语义槽。
最近,学者们提出将意图识别和语义槽填充联合建模,联合模型可以同时生成每个话语的意图和槽标签序列,利用两个任务之间的关联关系从而进一步提高SLU任务的性能。采用流水线式的级联方式来联合建模不但容易造成误差传播,而且未捕捉到两任务之间的关联关系。文献[15]将基于三角链CRF 的CNN 模型用于意图识别与语义槽填充的联合学习任务;文献[16]使用RecNNs 将句法结构和连续空间的单词、短语表示合并到组合模型中,建立意图识别和语义槽填充的联合模型;文献[17]将基于知识导向结构的注意力机制网络(K-SAN)应用于语言理解任务;文献[18]提出将RNN(Recurrent Neural Network)与CNN共同用于意图识别和语义槽填充的联合任务中,两个任务共享统一的损失函数;文献[19]引入了双向的RNN-LSTM 模型,实现语义槽填充、意图检测和领域分类的联合建模,但未建立语义槽填充和意图识别之间的明确关系;文献[20]提出基于注意力的RNN 模型,但只应用联合损失函数将这两个任务隐式地关联起来;文献[21]提出slot-gated 机制,将意图上下文信息应用于语义槽填充任务,建立了意图到语义槽的单向联系,语义槽填充的性能得到一定提升,但语义槽上下文信息并未用于意图识别任务,未建立两任务之间的双向关联关系。
意图和语义槽是用户行为的语义表征,共享用户话语信息,一个任务的信息可以被另一个任务利用来互相提高彼此的性能[22],意图识别和语义槽填充的上下文信息可为对方任务提供线索,互相促进。因此,本文提出了基于门控机制的双向关联模型(BiAss-Gate)用来处理意图识别和语义槽填充的联合任务。BiAss-Gate 模型建立两个任务间的双向关联,将意图上下文信息和语义槽上下文信息通过双向门控机制进行融合得到特征权重r,r作为两任务之间的互相关联的纽带,实现了意图识别与语义槽填充的双向关联,并使两任务性能互相提升。在ATIS[23]、Snips[3]数据集上都取得了比其他模型更好的性能,证实了本文模型的有效性。
2 相关技术
2.1 词嵌入
将文本转换成词向量是各种NLP(Natural Language Processing)任务中文本向量化的首选技术,one-hot 模型来构建的词向量具有高维稀疏的缺点,它不仅丢失了词义以及词之间的联系,而且无法准确表达不同词之间的相似度。基于此本文使用Mikolov等人[24]提出的word2vec模型来构建词向量,将输入序列的词编码成相对低维稠密的连续向量。word2vec 模型能够捕捉词语的语法和语义,计算词语之间的相似度,并且挖掘人们很难察觉的词语之间的关系,在大部分的NLP 任务上word2vec模型都有很好的表现。
2.2 Bi-LSTM网络
长短期记忆神经网络(Long Short-Term Memory,LSTM)[25]是一种改进之后的循环神经网络(RNN),LSTM网络引入了门机制和单元状态c,它既很好地解决了RNN 不能捕捉长期依赖关系的问题,又避免了RNN所存在的梯度消失和梯度爆炸问题。对于当前时刻的输入xi,经过LSTM单元会产生两个输出,当前时刻的隐藏状态hi和当前时刻的单元状态ci。LSTM的单元状态c用来保存长期的状态,门控机制的三个门用来控制单元状态c所保存的信息,遗忘门决定了上一时刻的单元状态c有多少信息需要保留到当前时刻的ci,输入门决定了当前时刻的输入xi有多少信息需要保留到当前时刻ci,输出门来控制当前时刻的单元状态ci有多少信息输出到当前时刻的隐藏状态hi。计算公式如下:

σ是sigmoid函数,i、f、o、c分别是输入门、遗忘门、输出门和单元状态,W是权重矩阵,例如Wi代表输入门的权重矩阵。b为偏置项,例如bi为输入门的偏置项。是点积运算。
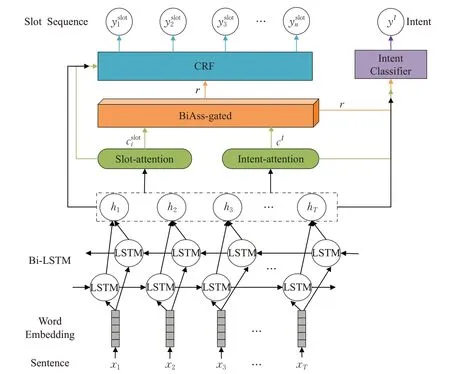
图1 模型框架图
双向长短时记忆网络(Bi-directional Long Short-Term Memory,Bi-LSTM)[13,26]方法广泛应用于序列标注和分类任务,通过Bi-LSTM 可以更好地捕捉双向的语义依赖,建模上下文信息,解决了网络LSTM 无法编码从后到前信息的问题。Bi-LSTM 由前向LSTM 层和后向LSTM层组成,分别用于编码从前到后和从后到前的输入序列信息。将词嵌入层的输出作为Bi-LSTM的输入,前向LSTM层生成隐藏状态hfi,后向LSTM层生成隐藏状态hbi,第i时间步的最终隐藏状态hi由hfi、hbi拼接形成。Bi-LSTM 层最终可以得到与输入序列长度相同的隐藏状态序列Bi-LSTM层的输出被两个任务共享,计算公式如下:
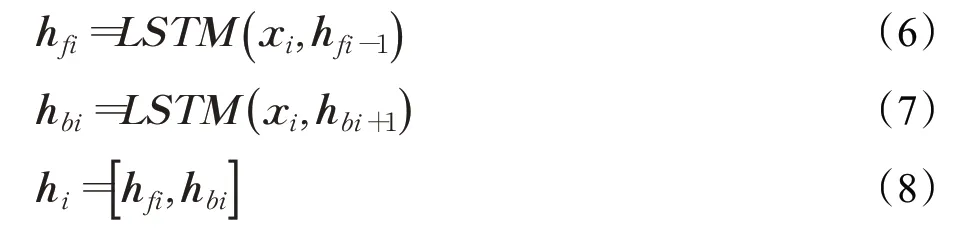
2.3 条件随机场
条件随机场(CRF)[9]是目前序列标注任务的主流模型。CRF模型的目标函数不仅考虑输入的状态特征,而且还引入了标签转移特征,这使它会考虑输出标签之间的顺序,并可以充分利用相邻标签之间的相互关系,在给定输入数据的条件下CRF模型可以输出使目标函数最大化的最优标签序列,另外CRF层还可以从训练数据中学到一些约束规则来保证预测标签序列的合理性[27]。
3 BiAss-Gate模型
3.1 BiAss-Gate模型总体框架
本文提出的基于门控机制的双向关联模型如图1所示。对于给定的一组话语输入序列X[x1,x2,…,xT],首先将X输入到最底层的词嵌入层,通过词嵌入捕捉词之间的语义和联系,并将输入序列映射成词向量矩阵作为Bi-LSTM 网络的输入,然后通过Bi-LSTM 网络捕捉输入序列的上下文依赖关系,并将隐藏状态序列作为注意力层的输入,注意力机制可以捕捉隐藏状态hi无法捕捉到的附加依赖信息[27],通过意图-语义槽注意力层分别获得意图的上下文信息向量cI和语义槽的上下文信息向量。最后将输入到双向关联门控层获得联合权重特征r,并将r作为加权特征应用于两任务,实现双向关联。将隐藏状态序列、上下文向量以及联合权重特征作为意图识别和语义槽填充任务的输入,最后语义槽填充任务采用CRF模型对全局打分得到最优的槽标注序列作为最终的输出。
3.2 意图-语义槽注意力层
Bi-LSTM的每一时刻的隐藏状态hi都承载着整个序列的信息,但信息会在正向和反向传播过程中有所丢失,而注意力机制不但可以捕捉全局联系,并且关注了元素的局部联系,对输入的每个元素考虑不同的权重参数,更加关注与输入的元素相似的部分,而抑制其他无用的信息。本文通过注意力机制[28]选择性地关注Bi-LSTM层中相对重要的一些隐藏状态,并加大它们的权重。通过意图-语义槽注意力层获得意图的上下文信息向量和语义槽的上下文信息向量,利用、构建两任务的联合特征权重r。

T是注意力层的维度,σ是激活函数,ei,k计算的是hk和当前输入向量hi之间的关系分别为hk和hi的权重矩阵。
在意图识别任务中,通过意图注意力层得到意图上下文信息向量cI。计算方式同语义槽上下文向量。
3.3 双向关联门控机制
基于文献[21]提出的slot-gated机制,本文提出基于门控机制的双向关联模型(BiAss-Gate),利用意图上下文向量和语义槽上下文向量来建模意图与语义槽之间的关联关系。本文将意图上下文向量cI和语义槽上下文向量作为双向关联门控层的输入,产生一个双向增强的联合权重向量r,如图2 所示。r越大,说明意图-槽注意力层对序列关注的重合部分占比越大,进一步说明意图与语义槽的相关度越高,联系越紧密。r的计算公式如下:
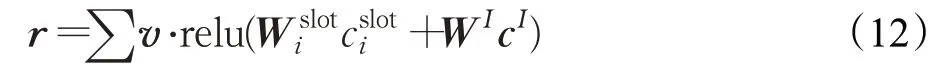
v,W分别为可训练的权重,的联合权重表示,然后再将r作为权重特征和上下文向量、隐藏状态一同用于意图识别和语义槽填充任务。

图2 BiAss-Gate结构图
3.4 意图识别
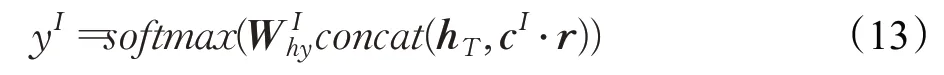
3.5 语义槽填充
虽然可以在模型的最后使用softmax函数得到输出序列,如公式(14),但输出序列的每个槽标签相互独立,它只在每一步中挑选出每个词所对应最大概率值槽标签作为输出,没有考虑到输出序列标签之间的影响,而且会导致输出不合理的标签序列。

因此本文在处理语义槽填充任务时在Bi-LSTM 网络后面加一层CRF。状态特征P是网络模型的输出的打分矩阵,矩阵的元素是输入序列X中第i个单词对应第j个槽标签时的分数,Pi为特征矩阵的第i列,即输入序列的第i个词对应所有可能槽标签的分数向量[29]。槽标签转移特征矩阵用A表示,Ai,j表示从槽标签转移到槽标签的分数。当输入序列X所对应的输出序列为yslot时的得分为公式如下:

训练时,CRF的目标是使正确标签序列的概率最大化。预测时,将得分最高的槽标签序列作为最终输出序列,此时得到的槽标签序列为最优的输出序列[30]。公式如下:

4 实验
4.1 数据集
为验证本文模型的有效性和泛化性,实验采用SLU任务中最常用的两个公开数据集:ATIS(Airline Travel Information Systems)数据集、Snips 数据集。如表2 所示。ATIS 数据集由预订航班用户的音频记录组成,本文使用与文献[21]相同的数据集分割。把ATIS-2 和ATIS-3语料库的4 978条记录划分为训练集和验证集两部分,训练集包含4 478 条,验证集包含500 条,另外测试集的893 条记录来自ATIS-3 NOV93 和DEC94 语料库,训练集包含120个语义槽标签和21个意图类型。

表2 数据集
Snips 数据集是从Snips 个人语音助手中收集得到。训练集、验证集分别包含13 084 条、700 个条记录,并另将700个条记录作为测试集。Snips训练集包含72个语义槽标签和7个意图类型。
在表2 中Vocabulary_size 为词汇量大小;Average Sentence Length 为句子平均长度,Intent_num为意图类型数量;Slot_num 为槽标签数量;Training_set_size、Development_set_size、Test_set_size分别为训练集、验证集和测试集的大小。
4.2 评价标准
在实验中,意图识别和语义槽填充分别采用准确率(Accuracy)和F1 值作为其性能的评价指标,此外,实验还采用句子级(Sentence)的准确率来评判话语级语义框架的性能,句子级准确率就是指在整个测试集中,预测出的意图类型和语义槽标签序列都正确的句子所占的百分比。
4.3 参数设置
实验采用Adam(Adaptive Moment Estimation)优化算法[31]更新神经网络的参数,并使用早停策略防止过拟合。模型参数如表3所示。

表3 模型参数表
其中num_units 为Bi-LSTM 网络隐藏层单元数;batch_size为单次迭代训练批处理样本的个数;num_layers为Bi-LSTM 网络层数;max_epochs 为最大训练周期;learning_rate为模型学习率。
4.4 实验结果
4.4.1 模型实验
将本文模型BiAss-Gate 与其变体BiAss-Gate(without CRF)、BiAss-Gate(Stack-Bi-LSTM)进行对比。从表4 可以看出BiAss-Gate 模型与BiAss-Gate(without CRF)模型相比,特别在Snips数据集上语义槽填充的F1值增长了3.46个百分点,句子级准确率提升了5.58个百分点。CRF 不仅可以提高语义槽填充的性能还优化了话语级语义框架的性能。
本文尝试用堆叠的Bi-LSTM 网络来捕捉输入序列的上下文信息。实验表明,在ATIS和Snips数据集上含单层Bi-LSTM网络的BiAss-Gated模型比含堆叠Bi-LSTM网络的BiAss-Gated(Stack-Bi-LSTM)模型表现更好。因为堆叠的Bi-LSTM 网络加深了网络的深度,虽然可以挖掘更深的语义关系但同时增加了模型的复杂度,对于ATIS、Snips这种句子语义相对简单的数据集,性能提高不明显。

表4 模型实验对比 %
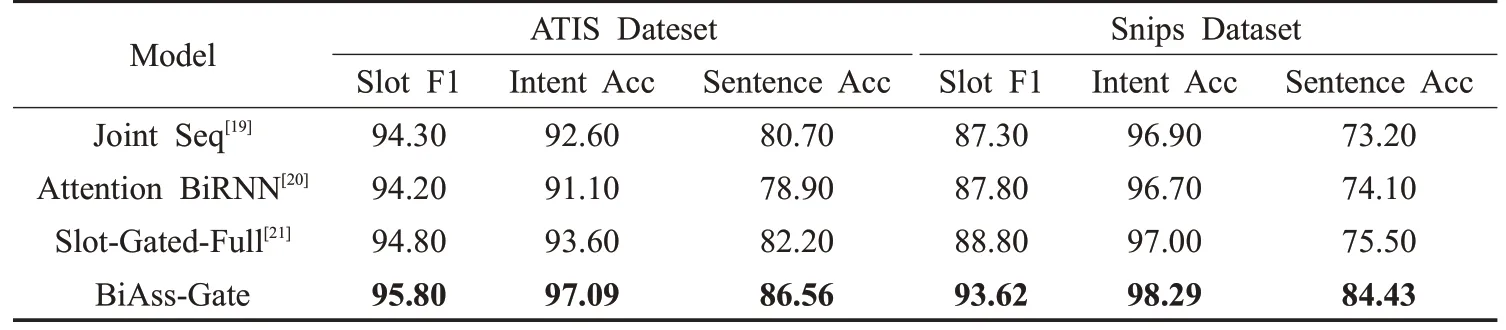
表5 其他模型对比实验 %
4.4.2 对比其他模型实验
为验证本文模型的有效性,将本文模型BiAss-Gate分别与文献[19]中的Joint Seq 模型、文献[20]中的Attention BiRNN模型以及文献[21]中的Slot-Gated-Full的模型进行对比。实验结果如表5 所示,基线模型中,Slot-Gated-Full模型与Joint Seq模型、Attention BiRNN模型相比,取得了最好的性能,说明slot-gated机制比使用共享损失函数更能捕捉意图识别与语义槽填充之间的关联关系。
与Slot-Gated-Full 模型相比,本文模型BiAss-Gate模型在ATIS数据集和Snips数据集上,语义槽填充的F1值分别提高了1、4.82个百分点,意图识别的准确率分别增长了3.49、1.29 个百分点,句子级的准确率分别实现了4.36和8.93个百分点的提升。表明双向关联的BiAss-Gate模型比单向关联的Slot-Gated-Full模型更能很好地挖掘意图识别与语义槽填充任务之间的关联关系,并实现了意图识别和语义槽填充任务性能的互相提升。特别是句子级的准确率提升幅度最大,说明BiAss-Gate模型可以充分利用两任务之间的关联关系,优化联合模型的全局性能。
本文的模型在两个数据集上的性能都取得了明显的提升,但模型在两数据集上性能提升的幅度却存在差异。在ATIS 数据集上,语义槽填充和话语级语义框架的性能比在Snips 数据集上的好,这是因为数据集本身的特点,如表2所示,ATIS数据集与Snips数据集相比句子的平均长度较短,ATIS 语料为同一领域,而Snips 的语料跨多领域,比较复杂。然而Snips 数据集上的意图识别任务的性能比ATIS数据集上的好,因为在Snips数据集语料库远大于ATIS的数据集的情况下,Snips所标注的意图类型数量却远小于ATIS 数据集,ATIS 数据集的类图类型更细粒度化,意图识别的准确率稍低。
5 结束语
为了充分利用意图识别和语义槽填充之间的关系,来提升联合模型的性能,本文提出了BiAss-Gate模型来深度挖掘意图识别与语义槽填充任务之间的关联关系,利用意图和语义槽的上下文信息建立两个任务之间的双向关联,促进两个任务性能的互相提升,进而优化全局性能。BiAss-Gate 模型在ATIS、Snips 数据集上与其他模型进行对比,实验结果表明,本文所提的BiAss-Gate模型在两个数据集上表现出了最佳性能。
本文的模型有一些不足:(1)所选的数据集比较简单,为进一步验证本文模型的有效性,还需在更复杂的数据集上对本文方法进行评估。(2)本文仅采用词级嵌入来捕获输入句子的语义,这使得到的语义关系比较单薄,下一步的工作中将把字符级嵌入与词级嵌入相结合,捕捉更丰富的语义信息来提高SLU的性能。在后续的研究中,将把多意图识别作为研究重点,一个句子中可能包含多个意图,识别句子中的多个意图将会进一步提高SLU的的性能。
