DCFM:基于深度学习的混合推荐模型
2021-02-04张荣梅
陈 彬,张荣梅,张 琦
河北经贸大学 信息技术学院,石家庄050061
随着大数据时代的来临,数字资源呈爆炸式的增长,人们捕获信息的深度、广度和频度也都获得极大的提升,这在丰富人们生活的同时,也带来了信息如何高效匹配和选择困难等诸多问题。于是,推动了智能推荐技术的发展和热潮。推荐系统旨在从海量、异构的数据资源中,快速聚焦和锁定满足用户需求的信息,并推荐给用户。
传统的推荐模型主要是基于内容的推荐、基于协同过滤的推荐以及两者混合的推荐[1]。但这些推荐算法模型大多都仅是对用户-商品评级矩阵进行了分析计算,没有参考用户属性和商品属性,致使推荐精度和准确率不能进一步提升[2]。且传统算法存在数据稀疏[3]的弊端,即指在庞大的用户量和商品量下,实际存在的用户-商品交易数据却少之又少的情况,这也是制约传统推荐算法效果的一大难题。此后学者们将用户和商品属性特征考虑在内,并引入深度学习[4],提出了一些推荐模型:饶健[5]提出了使用基于因子分解机的推荐模型,在MovieLens 数据集上将其与传统推荐模型进行了实验对比,得出加入隐因子特征可以有效提高模型精准度的结论;郁豹等人[6]提出使用DeepFM 模型来实现社交广告的个性化推荐;吴磊等人[7]提出使用DCN模型来改进金融产品商城中商品的分类。这些模型在推荐领域都取得了不错的效果。但基于深度学习的推荐模型研究还很有限,存在很大的研究空间。
为了进一步挖掘用户与交易项目间的特征组合,本文提出了一种基于深度神经网络(Deep Neural Network,DNN)、深度交叉网络(Deep Cross Network,DCN)以及因子分解机(Factorization Machine,FM)的混合推荐模型——DCFM。DCFM模型将用户、商品属性特征分别以低阶特征、线性交叉特征和非线性高阶特征三方面进行分析,充分挖掘属性特征间的内在隐性关联关系,以提高推荐的准确性。
1 相关理论
1.1 FM模型
推荐系统的一大问题就是数据稀疏性问题,这导致推荐算法的训练数据有限,模型训练效果不好,从而使得推荐结果不理想[8]。FM的作用就是解决数据稀疏的情况下,特征如何组合。
普通的线性模型[9]仅仅是将各个特征独立加权求和,忽略了特征与特征之间潜在的深层关系,比如性别特征为“男”的用户,更倾向于“啤酒”和“香烟”这类产品,这就说明用户的某些属性特征与商品的某些属性特征之间存在关联性。所以FM 模型在线性回归模型的基础上加入了特征分量间的关联计算,以二阶多项式为例,FM模型的表达式为:
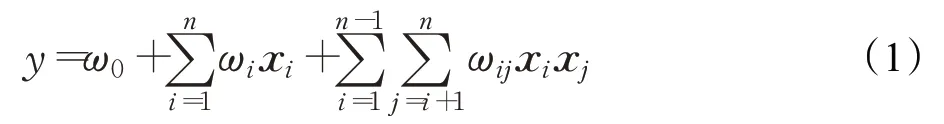
其中,ω0表示常数偏置,n表示样本的特征数量。
在数据稀疏的情况下,xi或xj为0的可能性很大,所以很难训练得到ωij,于是引入辅助向量vi=(vi1,vi2,…,vik)来表示特征xi,如下所示:

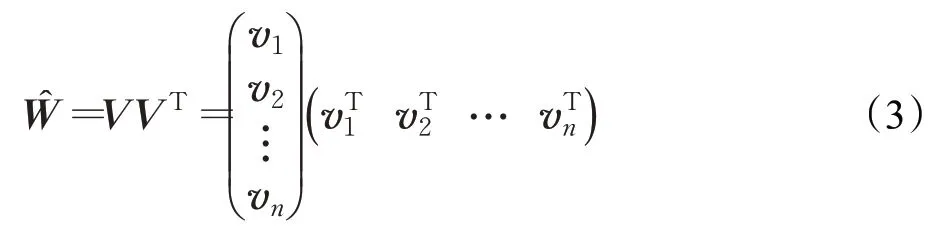
所以FM模型的二次项的计算过程如下:


1.2 DeepFM模型
DeepFM 模型[10]是一种并行结构的融合网络,由两部分组成:因子分解机(FM)部分和深度神经网络(DNN)部分。它是对FM 模型的改进,在理论上,特征间的相互作用可包括无限高阶的可能性,但由于计算复杂度随组合特征阶数的升高而加大,所以常常只将组合特征提取到二阶就不再继续,而高阶部分由深度神经网络DNN训练提取。
在DeepFM模型中,两个并行结构FM和DNN共享同样的输入,并将各部分的输出结果线性拼接后,作为整个模型的输出层。该模型的预测结果可以表示为:

1.3 DCN模型
DCN模型是由交叉网络(Cross Network)和一个深度神经网络(DNN)并行组成。其结构和DeepFM 模型类似,都是从嵌入层处理开始,两部分共享相同输入,并将两部分结果组合作为整体模型的输出层:

与DeepFM不同的是,DCN模型将离散特征和连续特征分开考虑,将离散特征进行编码和嵌入处理后再与连续特征拼接组合。DCN模型可以有效提取有限度的特征相互作用,学习高阶非线性特征相互关联。它弥补了FM浅层结构的限制问题,并将参数共享机制从一层扩展到多层。
2 模型设计
本文提出了一种基于深度神经网络、深度交叉网络以及因子分解机的多特征深度网络推荐模型:DCFM。该模型主要由DNN、Cross Network 和FM 三部分并行组成。如图1所示。
首先是输入层,该模型以用户属性、项目属性特征做为输入,经one-hot处理为稀疏特征向量,再由嵌入层做向量内积计算为稠密特征向量x0,然后主体部分由DNN、Cross Network和FM 三部分并行组成,从低阶交互、组合交互和非线性高阶交互三个角度分别处理输入特征,最后等权重线性加权各部分特征结果作为输出特征,输出特征再进行一层全连接和激活函数作用后,作为模型整体的输出层。

图1 DCFM模型
2.1 模型输入部分
DCFM模型借鉴了输入共享原则,各部分对同一嵌入数据进行关系挖掘,使输出具有关联性和可连接性,这样才能对结果进行线性组合。在输入层,首先是将用户属性特征和商品属性特征以用户ID和商品ID为联合主键拼接,作为输入特征。然后通过全编码嵌入处理作为输入,即是对所有输入特征数据进行编码处理,后再嵌入为稠密特征向量:
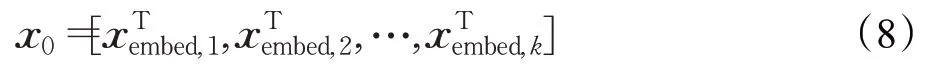
输入处理过程如图2所示。
由于用户和商品的属性信息中包含大量离散数据,所以要先对输入数据进行one-hot 编码处理[11]。one-hot编码是将原某类型属性按照其种类进行编码,编码结果是只有一位为有效值1,其余位都是0。当某一属性包含多种类别,则按照类别总数S构建长度为S的编码串,并由先后出现顺序为其置“1”编码。例如在MovieLens-100K 数据集中共出现有21 种职业类型,则数据集中最先出现的“technician”职业的one-hot 编码为[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1],第二出现的“writer”职业的one-hot 编码为[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0],以此类推。对于性别这类的二值属性,直接用[0]表示“女”,用[1]表示“男”即可。而连续属性特征,如用户年龄,就直接取原值。图2 中的每一组“field”就表示一项属性信息,由于每种属性的种类数不同,所以每组“field”的长度也不相同。

图2 输入处理
这些“field”是one-hot编码得来的,有用数据非常稀疏,所以又要经过一层嵌入层(embedding)作用。嵌入层可以看做是一个全连接层,其中K表示预设的嵌入向量长度。嵌入层的作用有两点:(1)将稀疏数据转换为稠密数据;(2)重新确定了每一组“field”的长度,将其归一到统一长度K[12]。由于每一组“field”中只有一个值为1,所以经由嵌入层计算后,每组“field”对应的embedding向量值就是值为1的节点所对应的权重值。
2.2 模型主体部分
FM 负责提取输入数据的低阶特征。其模型如1.1节介绍。
Cross Network负责提取线性交叉组合特征。交叉网络充分考虑了各个特征间的交叉作用,原始输入层数据在每一层都和当前层数据交叉作用,既保留了原始数据的低阶特征,又交叉作用于深层的高阶特征。交叉层计算结构如图3所示。

图3 交叉层结构
其每一层的计算公式如下:

交叉网络的特殊结构使交叉特征的程度随着层深度的增加而增大,用L表示交叉层数,D表示输入数据的维度,则整个交叉网络的参数量为D×L×2(“2”是因为参数w和b)。由于交叉网络层与层之间是线性计算模型,会限制模型的效果,所以在DCFM 模型中又引入与之并行的深度网络。
DNN负责提取非线性高阶特征。该部分是一个全连接的多层前馈神经网络,其结构是一种非线性映射,能够通过简单非线性处理单元的复合映射,获得复杂的非线性处理能力。与Cross网络不同的是,DNN每个隐层的节点数不一定相同,隐层的计算公式为:

2.3 模型输出部分
DCFM 模型的输出由各部分的输出层线性加权组合而成,其公式可以表示为:
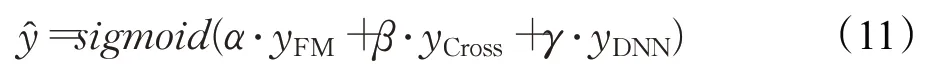
实验所用模型是等权重加权。拼接结果再经由一个全连接层计算,并在激活函数作用后,作为输出结果。该模型从低阶特征、交叉组合特征、高阶非线性特征三个角度充分挖掘输入属性特征间的内在交互关系,实现了有限数据的增广训练,有效缓解了传统推荐算法由于数据稀疏带来的推荐效果不明显的问题。
3 实验及结论
3.1 数据集及实验环境
实验选取了MovieLens电影公开数据集中的一组:MovieLens-100K。
MovieLens 数据集是由明尼苏达大学的Grouplens研究项目收集整理。数据集获取地址:http://files.grouplens.org/datasets/movielens/。MovieLens-100K 数 据 集包含943名用户对1 682部电影的100 000条评分记录,评分采用5分制(1、2、3、4、5)。该数据集主要包含三个文件:用户数据文件(u.user)、项目数据文件(u.item)和评分文件(u.data),其中u.user包含用户的人口统计信息,字段有:用户标识(user id)、年龄(age)、性别(gender)、职业(occupation)和邮编(zip code);u.item 包含电影项目的信息,字段有:电影标识(movie id)、电影标题(movie title)、上映日期(release date)、视频发布日期(video release date)、数据源链接(IMDb URL)和类别属性(genres);u.data包含完整的评级数据,字段有:用户标识(user id)、项目标识(item id)、评分(rating)和时间戳(timestamp)。
实验是Windows7 操作系统下,Intel Core i5-4590处理器,8 GB内存,软件平台是Pycharm2017.3.3专业版,Python3 编程语言,深度学习计算框架采用tensorflow 1.8.0(import tensorflow as tf)。
3.2 模型评估
本文采用多种评估标准来检验模型效果。
(1)分别使用交叉熵和均方根误差RMSE作为损失函数,用于评估推荐模型在算法计算上的误差值,交叉熵计算公式如下所示:

RMSE计算公式如下所示:
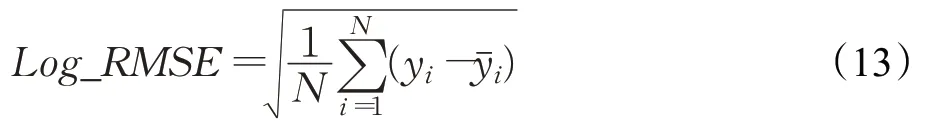
其中,y表示预测结果,表示真实值。
(2)通过混淆矩阵[13]计算精确度(Precision)和召回率(Recall),可用于评估推荐模型在推荐效果上的优劣程度。涉及到的参数和计算方法如下。
TP(True Positive):将正类预测为正类;
TN(True Negative):将负类预测为负类;
FP(False Positive):将负类预测为正类,也称为误报;
FN(False Negative):将正类预测为负类,也称为漏报。
其中,召回率(Recall)和精确度(Precision)的计算公式为:

但是召回率和精确度都有所侧重,不能兼顾。所以采用准确率(Accuracy,Acc)和F1-Score 值[14]用于综合度量模型的效果,计算公式如下:

(3)AUC[15]值,是从样本概率的角度评估推荐结果的优劣,简单介绍,就是在随机抽取的一对样本中(一个正样本,一个负样本),用训练得到的模型来对这两个样本进行预测,预测得到正样本的概率大于负样本概率的概率。计算如下:

其中,M表示正样本数,N表示负样本数,M×N代表总的样本对数。
3.3 实验及超参设置
DCFM 的输入使用到了MovieLens-100K 的全部三个数据文件,其预处理和输入部分过程如下。
(1)首先将用户属性数据和商品属性数据与评分记录拼接处理。用户属性数据以user id字段为主键与评分记录拼接,商品属性数据以item id 字段为主键与评分记录拼接。
(2)对数据文件中的属性字段,处理分为三类:可忽略属性、离散属性、连续属性。在MovieLens-100K数据集中,作者将“user_id”“movie_id”“rating”“unix_timestamp”“movie_title”“release_date”“video_release_date”“IMDb_URL”归为了可忽略属性,这些属性忽略不送入推荐模型,将“age”属性归为连续属性,剩下其他为离散属性。(3)共享输入部分,连续属性和离散属性一并经one-hot编码,再嵌入处理得到稠密特征向量,嵌入向量embedding_size长度设置为8。实验中使用函数实现编码和嵌入操作。
此外,根据“rating”字段,为记录增设了一条“target”字段,如下:

目的是为了推荐模型的二分类,“rating”=1,表示用户对该商品为正向偏好,“rating”=0,表示用户对该商品为负向偏好。
将预处理好的嵌入向量作为FM、DNN 和Cross Network的输入特征,在FM中,一次项直接以输入特征数量n为准,构造满足均值为0,标准差为0.01的n行1列正态分布随机变量矩阵;二次项部分按照式(4)计算,此处辅助向量就是经嵌入处理后的稠密特征向量。DNN中隐层数量为3,每层32个神经元节点,层与层之间采用全连接形式计算,无激活函数作用。Cross Network 层数为3,每层节点数=field_size×embedding_size=23×8=184个,同样是全连接形式。
各部分结果经线性加权1∶1∶1形式组合成输出特征向量,输出层激活函数采用tf.nn.relu,输出层损失函数采用tf.losses.log_loss。为防止实验模型训练过拟合,使用函数tf.contrib.layers.l2_regularizer。在损失函数中加入L2 正则化系数,考虑到梯度爆炸导致的权重参数训练为NaN 问题,将学习率参数选取了一个较小值:0.001。实验每批训练数据大小为1 024,训练代数为10。
3.4 实验结果
实验采用十折交叉验证,将数据集按用户ID 平均分成10 份,保证每份中都含有所有用户的数据记录。依次选用其中的9 份作为训练集,余下的1 份作为测试集,共实验10轮,最终取结果的平均值作为实验记录。
并选取FM、DeepFM 和DCN 作为实验模型对比。如图4所示,是4种模型的交叉熵损失函数图。
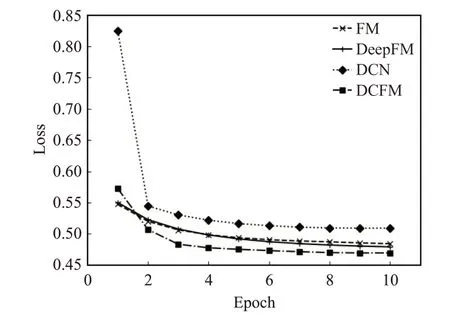
图4 交叉熵损失函数对比图
随着训练代数的增加,损失函数都呈下降趋势,效果最好的是DCFM,其次是DeepFM和FM,DCN的效果较差。
如图5 所示,是4 种模型的均方根误差RMSE 损失函数结果对比图。

图5 RMSE损失函数对比图
由实验结果可知,随着迭代数的增加,RMSE 逐渐下降收敛,DCFM和DCN的效果相近,其次是DeepFM,最差的是FM模型。
综合评估指标:准确率、F1-Score 和AUC 值的实验结果如表1所示。

表1 准确率、F1-Score和AUC值对比%
由实验结果可知,DCFM 模型在准确率(Acc)、F1-Score和AUC值上都有所提高,相较于FM,DCFM的准确率提高了1.16个百分点,F1-Score值提高了0.77个百分点,AUC 提高了0.06 个百分点;相较于DeepFM,DCFM的准确率提高了0.66个百分点,F1-Score值提高了0.42 个百分点,AUC 提高了0.12 个百分点;相较于DCN,DCFM的准确率提高了2.8个百分点,F1-Score值提高了1.8个百分点,AUC提高了0.54个百分点。
由图4、图5 和表1 可以看出,DeepFM 模型的低阶特征与高阶特征组合的模型设计思路能够有效提升推荐效果,DCFM模型在此基础上又加入Cross交叉网络,进一步提取出数据间的交叉组合特征,使推荐的综合性能又有所提高,在各个指标上都优于FM、DeepFM、DCN模型效果。
4 结束语
本文针对于智能商品推荐问题,提出了一种基于深度学习的混合推荐模型DCFM,模型由三部分以并行结构组成:因子分解机、深度神经网络和深度交叉网络,输入层共享权值,输出层线性组合各部分结果。模型充分利用用户属性、商品属性,并挖掘其低阶特征、交叉组合特征和非线性高阶特征用于模型训练。并且与当下效果较好的模型FM、DCN和DeepFM做了实验对比,以交叉熵、均方根误差RMSE分别作为损失函数和混淆矩阵衍生出的多种评估指标为标准,结果证明DCFM模型的推荐效果更好。
该模型通过挖掘用户和商品间的内在交互隐特征,有效缓解了数据稀疏问题,但由于较依赖历史交易记录,在冷启动问题上还有待进一步优化。下一步工作是将传统算法与深度学习进一步融合,形成多Agent框架结构,以期待解决冷启动问题。
