青光眼眼底图像的迁移学习分类方法
2021-02-04徐志京
徐志京,汪 毅
上海海事大学 信息工程学院,上海201306
青光眼是一种慢性、渐进性视觉损伤的眼科疾病,其主要病理特征为视网膜神经节细胞(Retinal Ganglion Cells,RGC)的凋亡和轴突的丧失[1],从而导致视力逐渐下降甚至失明,严重威胁患者的健康。据统计,全球人群中青光眼的患病率为3.54%,约有6 426万人;预计到2020 年和2040 年分别将达7 602 万人和11 182 万人[2]。由于该病具有较高的隐蔽性,患病初期不易被发现,导致患者得不到及时的治疗。数字眼底图像(DFI)是目前检测青光眼的主要工具之一,因而可以利用眼底图像对青光眼进行前期检测,以免病情的进一步恶化。但眼底图像结构性复杂,采用人工识别方法耗时费力且很难得到客观准确的医疗诊断,因此很多学者尝试采用人工智能技术对眼底图像进行患者筛查,但这是一项极具挑战性的工作。尽管如此,相关工作者还是取得了一定的研究成果:Nguyen等人[3]提出一种基于深度卷积神经网络的端到端深度学习系统,自动地从电子医疗记录中学习病理特征并临床预测患病风险。丁蓬莉等人[4]提出基于紧凑的神经网络CompactNet对视网膜图像进行识别分类,但由于实验样本有限,网络在训练的过程中并没有充分提取到相关特征,因此分类准确率并不高。Marcos等人[5]利用卷积神经网络进行视盘分割,然后去除血管,进而提取出其纹理特征并分类,在临床诊断中获得了良好效果。Raghavendra 等人[6]提出一种利用深度学习技术准确检测青光眼的新型计算机辅助诊断(CAD)系统,设计一个18 层的卷积神经网络,经过有效训练提取特征之后进行测试分类,该系统为青光眼患者早期快速辅助诊断提供了良好的解决方案。Chai等人[7]提出一种多分支神经网络(MB-NN)模型,利用该模型从图像中充分提取深层特征并结合医学领域知识实现分类。Balasubramanian等人[8]利用方向梯度直方图(HOG)进行提取特征,并结合支持向量机(SVM)实现对青光眼的分类,但该方法预处理步骤过于繁琐,并且识别准确率并不高。黄元康等人[9]提出基于Markov 随机场理论提取出眼底图像的视盘轮廓,同时在ISNT 法则的基础上采用欧式距离和相关系数识别法分别实现对青光眼眼底图像的识别,但该法需要人工辅助工作才能完成,效率低,自动性较差。
训练一个深度神经网络需要大量的样本,在没有足够多训练样本的情况下,可能导致网络在训练过程中无法充分提取特征或者训练出来的模型泛化能力差。而迁移学习相对于传统的神经网络主要的优势在于不需要大量的训练样本[10],针对目前缺乏大型公开已标记的青光眼数据集,本文引入迁移学习思想,提出了基于R-VGGNet(Reduce-VGGNet)网络模型的青光眼眼底图像识别系统,选择VGG16 深度神经网络作为基本的网络结构,通过对网络结构的改进与微调实现对青光眼患者和正常人眼底图像的判别。相比较于全新学习,采用迁移学习策略,提高了小样本下青光眼患者的识别率。同时,本文还提取出了青光眼眼底图像的感兴趣区域,提高了识别速度与准确率。与传统的识别方法相比,R-VGGNet网络模型具有更好的识别效果。
1 系统设计
1.1 青光眼识别模型
本文搭建的青光眼患者识别系统如图1 所示。该识别系统由三个部分组成:数据集预处理部分、基于迁移学习策略的模型训练与特征提取部分、自动识别分类部分。在对青光眼眼底图像进行识别分类时,需要对原数据集进行一系列的预处理操作,然后将预处理后的图像输入到网络模型中进行迁移训练与特征提取,最后将提取到的特征输入Softmax 分类器进行分类,实现青光眼的识别。
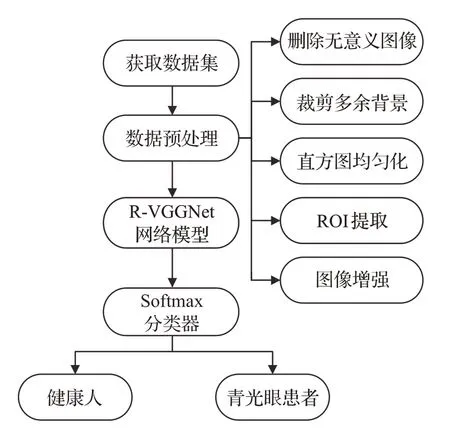
图1 青光眼患者识别模型
1.2 数据集预处理
1.2.1 图像预处理步骤
由于获取的原始数据集存在背景多余、噪声污染、样本容量少、样本分布不均匀等问题,如果直接将原数据集用于网络模型训练,效果会非常不理想。因此,为了达到训练模型的要求,提高模型的准确性,需要对原数据集进行一系列预处理操作。预处理步骤为:(1)删除污染严重,无使用价值的图像。如图2(a)所示;(2)裁剪多余的图像背景。裁剪后的图像如图2(b)所示;(3)直方图均匀化。对于一些曝光不足的图像进行直方图均匀化,改善由光线引起的噪声问题。如图2(c)所示。
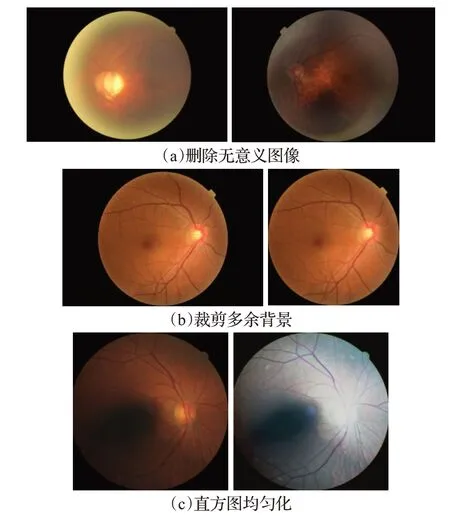
图2 图像的预处理示例
1.2.2 感兴趣区域(ROI)提取
眼底图像是诊断青光眼的重要依据,研究表明,青光眼患者具有三大特征,其中一大特征为青光眼患者的视杯面积与视盘面积之比一般大于0.6,即杯盘比(CDR>0.6)。同时,为了缩短网络处理时间,可以将更小的初始图像作为网络的输入。基于上述两点原因,本文将ROI(Region Of Interest)区域作为深度卷积神经网络的输入,提取出的眼底图像ROI 区域(视杯与视盘部分)如图3所示。
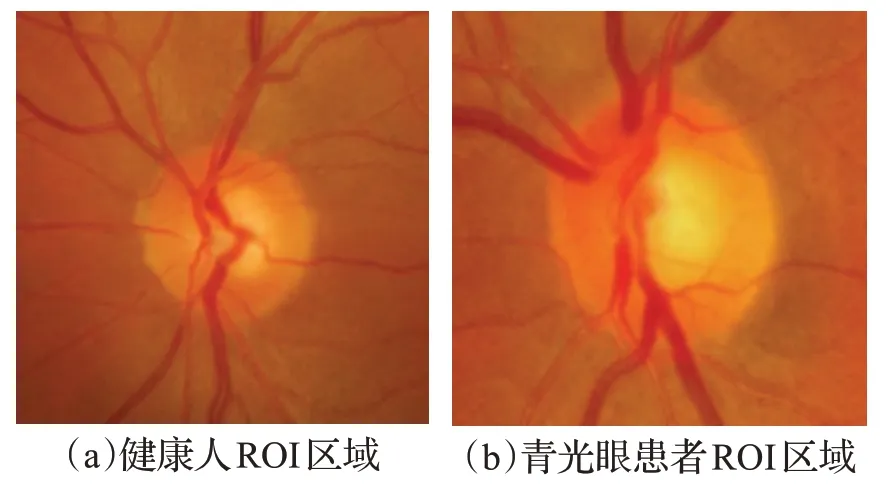
图3 ROI区域示例
1.2.3 图像增强
利用深度学习技术来实现图像分类任务时,需要大量的训练样本,而现实生活中很难获取数以万计的相关图像,特别在医学领域,这一问题体现得尤为明显。因此,需要在已有数据集的基础上进行数据扩充。本文在原数据集的基础上采取平移(水平、竖直两个方向)、旋转(30°、60°、90°、180°)、比例缩放、翻转等方法,实现对样本的扩充。这些变换的目标是生成更多样本以创建更大的数据集,防止过度拟合[11]。由2.1 节数据集简介可知,本文所采用的数据集还存在正负样本分布不均衡的情况,所以,需要对负样本进行适当扩充,从而解决样本不均衡问题。
1.3 R-VGGNet模型训练与特征提取
本文提出的识别网络模型R-VGGNet 以VGG16 网络模型作为基本网络结构,其网络架构图如图4 所示。

图4 R-VGGNet卷积神经网络架构图
VGG16 网络由3×3 的卷积核和2×2 的最大池化层构成,共13 个卷积层和3 个全连接层[12]。相比较8 层的AlexNet 网络,VGG16 网络最大的特点是通过3×3 滤波器的组合与堆叠,提取出输入领域内更多非常细小的特征[13]。在每组卷积层之后都连接一层最大池化层,并且每个卷积层之后紧跟(Rectified LinearUnit)Relu激活函数,其抑制特性使得神经元具有稀疏激活性,有效解决了梯度弥散问题,同时加速网络收敛。对于任意第i(0<i <16)层:


由于VGG 结构为深度卷积神经网络,其具有强大的特征学习能力,所以被广泛地用于图像识别任务中。本文借助迁移学习思想,利用该网络在ImageNet 数据集上的训练所获得的权重参数,冻结前13层并释放后3层的权重,利用青光眼数据集训练全连接层和Softmax分类器,微调后进行特征提取和分类。
现有的VGG 结构采用三层连接的全连接层,这三层全连接层占了训练参数的绝大部分,对于本文来说,识别任务仅仅只有两类,即识别健康人和青光眼患者的眼底图像,三层的全连接层相对冗余,因此,对VGG16全连接层进行了重新设计,即R-VGGNet,提出用2个全连接层替换原有的3个全连接层,其中设置第1个全连接层输出神经元个数为1 024 个,第2 个全连接层输出神经元个数为2 个,这样得到的网络相对于之前的网络,训练参数大大减少,提升了网络的训练速度,训练时间也得到缩短。
对网络模型的优化本质上就是使损失函数尽可能的小。本文优化算法采用随机梯度下降法(Stochastic Gradient Descent,SGD)和Momentum相结合,设定动量参数为默认值0.9,迭代次数为100次,Batch_size设定为32,初始学习率设定为0.001。学习率采用指数衰减法的更新策略。指数衰减法更新学习率的表达式为:

式中,lr为衰减后的学习率,lr0为初始学习率,dr为衰减系数,gs为当前的迭代次数,ds为衰减步长(即每迭代指定次数更新一次学习率)表示向下取整。在训练过程中代价函数采用交叉熵损失函数,Softmax 计算损失。为了避免过拟合现象,在损失函数中附加L2正则化项,最终的损失函数表达式为:
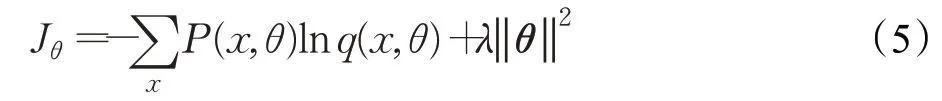
式中,θ为权重,x为批次训练样本,λ为正则化项系数,p为期望的类别概率,q为模型预测的类别概率。在训练过程中,当损失函数的loss值趋于稳定时将学习率再次调小,直至达到最小值时获得最优识别模型,最终设定学习率为0.000 5。
1.4 分类器的设计
设计一个完整的卷积神经网络,其最后部分往往会连接若干全连接层,这是因为全连接层能够将网络提取到的特征映射到样本的标记空间中,因此,全连接层在整个卷积神经网络中实际上起到了“分类器”的作用。该分类器设置了两个全连接层Fc1 和Fc2,由于实验样本有限,为了避免过拟合现象的发生,在全连接层之后加入Dropout 层,并且设置Dropout 率为0.5。同时在每个全连接层之后引入线性修正单元(Relu),用来解决梯度弥散问题[14]。最后将VGG16 原有模型中包含1 000个节点的Softmax 层用一个包含2 个节点的Softmax 层代替。分类器结构图如图5所示。
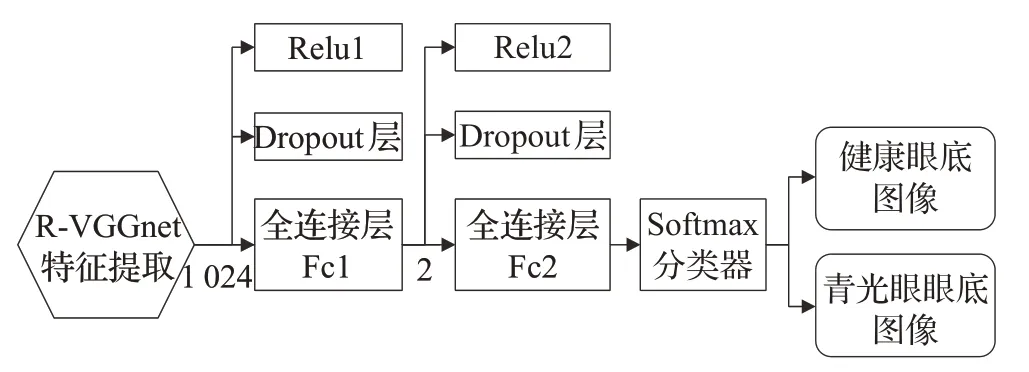
图5 分类器结构图
2 实验结果与分析
2.1 数据集
文章使用的数据集为YiWeiChen等人收集的青光眼数据集(https://github.com/yiweichen04/retina_dataset),该数据集包含了300张健康人的眼底图像和101张青光眼患者的眼底图像,并且均为高分辨率的RGB 彩色图像,如图6所示。

图6 眼底图像示例
2.2 实验设计
本实验是基于CPU为Intel i7-7800x,显卡为NVIDIA GeForce GTX1080i 的计算机完成的,深度学习框架选择keras 及tensorflow。由于VGG16 网络的输入层要求为224×224,因此,采用Python 的pillow 库中crop 操作,设定固定的裁剪区域将所有图像的尺寸都裁剪为224×224。同时将数据集分成训练与测试两部分(训练集与测试集的样本比例为9∶1)。为了对比不同网络结构对分类精度的影响、提取ROI对分类精度的影响、同一网络结构不同训练方法对分类精度的影响以及R-VGGNet网络结构和提取ROI操作对时间复杂度影响,本文设计四组对比实验。
第一组对比实验:为了验证网络结构对识别率的影响,本组实验使用提取ROI后的数据集分别对LeNet和R-VGGNet两种不同的网络结构进行实验。
(1)LeNet 网络是用于识别手写数字的简单卷积神经网络,共有8层(包括输入层),属于浅层神经网络。
(2)本文提出的基于迁移学习的R-VGGNet深度卷积神经网络。
第二组对比实验:为了验证提取ROI对识别率的影响,本组实验分别使用未提取ROI 的数据集和提取ROI 的数据集对本文提出的基于迁移学习的R-VGGNet深度卷积神经网络进行实验。
第三组对比实验:为了验证迁移学习的有效性,本组实验将丢弃R-VGGNet 在ImageNet 上学习到的权重参数,采用全新学习策略进行实验。
第四组对比实验:为了验证R-VGGNet 网络结构和提取ROI 操作对时间复杂度的影响,本组实验使用未提取ROI 的数据集和提取ROI 的数据集分别对R-VGGNet网络结构和VGG16网络结构进行实验。
目前对青光眼的识别是一项具有挑战性的工作,不同的研究人员也尝试多种方法来提高识别率。为了进一步验证本文提出的青光眼图像识别模型R-VGGNet的性能,本文还利用自身已有数据集对传统的不同识别方法进行对比实验。
2.3 评价指标
在图像分类任务中,一般从分类的准确率和损失函数值两个方面来评价分类模型的性能。本文损失函数采用交叉熵损失函数,公式在1.3 节已给出。对于分类准确率,令Ntotal代表测试集中视网膜图像的总数量,Nrec代表其中被正确分类的图像数量,则分类准确率可以表示为[15]:

2.4 结果与分析
2.4.1 第一组实验分析
图7(a)和(b)分别展示了提取ROI 后的数据集对R-VGGNet和LeNet两种不同网络结构的实验结果。实验结果表明:当迭代次数为100次时,R-VGGNet深度卷积神经网络的训练准确率(Tracc)和测试准确率(Teacc)略低于LeNet网络,但R-VGGNet网络模型更易于收敛,总体效果好。
2.4.2 第二组实验分析
图8(a)和(b)展示了提取ROI和未提取ROI的数据集作为R-VGGNet模型的输入,经过迁移学习得到的实验结果。实验结果表明:当迭代次数为100时,提取ROI的测试准确率明显高于未提取ROI,提高了近15%。

图7 R-VGGNet和LeNet训练和测试的准确率曲线

图8 提取ROI和未提取ROI训练和测试的准确率曲线
2.4.3 第三组实验分析
根据图7(a)和图8(a)的实验结果图,可以看出采用迁移学习策略的R-VGGNet 网络模型在测试集上准确率达到了0.9,而采用全新学习的方式对R-VGGNet进行训练,在测试集上的准确率为0.85。图9 展示了R-VGGNet 模型迭代次数为100 时的训练与测试的loss曲线图,其中测试的loss 值约为0.3。说明该网络在ImageNet数据集上学习到了特征,而这些特征有助于对眼底图像进行分类。

图9 R-VGGNet模型训练和测试的loss曲线
表1总结了上述三组实验迭代100轮在训练集和测试集上的准确率。由表1可知,本文提出的基于ROI和迁移学习的青光眼眼底图像识别方法的分类精度最高。

表1 三组实验迭代100轮的准确率
2.4.4 第四组实验分析
图10 展示了迭代次数为100 时,采用未提取ROI和提取ROI 的数据集分别对R-VGGNet 和VGG16 进行实验,实验结果表明:将提取ROI 的数据集作为R-VGGNet 网络的输入,其训练时间耗时最短,识别速度最快。
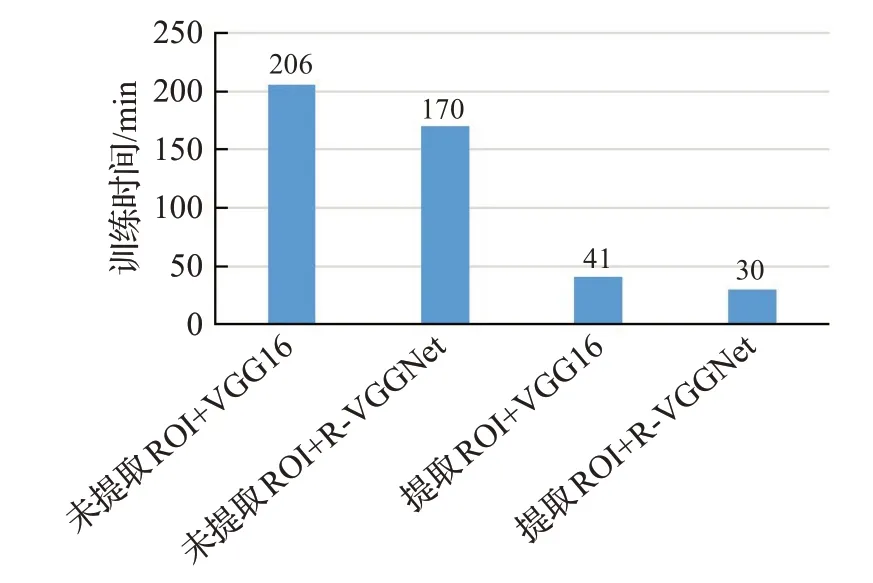
图10 时间复杂度对比
2.4.5 不同方法的比较
为了验证本文方法的有效性,在保证实验环境相同,预处理环节一致的情况下,对不同的识别方法进行对比实验。表2总结了不同方法的分类准确率。
根据表2 可知,本文提出的识别模型R-VGGNet 明显提高了特征提取能力,其识别精度优于其他传统分类方法。

表2 不同方法的分类准确率
3 结束语
针对目前缺乏大型公开已标记的青光眼眼底图像数据集,为了解决小样本学习能力不足、分类精度低等问题。本文借助迁移学习思想和深度卷积神经网络对青光眼眼底图像进行分类,进而判断是否患有青光眼。对VGG网络结构进行重新设计,简化了全连接层,达到减少训练参数,缩短训练时间的目的。同时根据青光眼患者的眼底特征提取其感兴趣区域(ROI),将其作为网络模型的输入,实验结果表明本文提出的分类识别模型提高了识别率。为了进一步提高该模型的识别率和广泛的适用性,在后续的研究工作中将进一步对图像预处理环节进行优化,同时利用其他数据集对该模型进行多次验证,以提高模型的鲁棒性。
