基于LSH的shapelets转换方法
2021-02-04丁智慧乔钢柱
丁智慧,乔钢柱,程 谭,宿 荣
中北大学 大数据学院,太原030051
时间序列是随时间观测和变化的一系列时值,广泛用于金融行业[1]、医疗领域[2]、天气预测[3]等。近年来随着时间积累和数据类别的增长,时间序列的数量和维度也大量增长,海量高维数据的分析处理成了目前各个行业面临的挑战。时间序列数据的分类问题是数据挖掘中一类重要方法,其目的是从已标定类别的训练集中提取出带有能够区分类别的显著性特征,分类器根据这些特征与未标记类别的时间序列之间的相似性进行分类。根据文献[4]将时间序列分类算法分为基于全局特征的算法、基于局部特征的算法和集成算法。基于全局特征的算法是将整条时间序列作为特征进行相似性比较,解决该类问题最具代表的方法是基于欧氏距离(Euclidean Distance)和动态时间规整(Dynamic Time Wrapping,DTW)的最近邻(1-NN)算法,但采用欧氏距离会因为相位漂移影响结果,而DTW 算法消耗大量的时间和空间,只适用于小型数据集,对海量数据无能为力。近些年的研究均集中于寻找更优秀的距离度量方法[5-8],例如Batista 等人[6]提出复杂性不变的度量方式(CID)、Jeong 等人[8]提出全局加权DTW(WDTW)增加了一个基于扭曲路径中各点之间的扭曲距离的乘法权重惩罚。基于局部特征的算法将时间序列的一部分作为特征,有分段聚集近似(PAA)[9]、符号聚集近似(SAX)[10]等分段表示方法,以及通过选择多个区间并使用汇总测度作为特征的分类方法[11],基于shapelets 的分类算法[12]枚举出数据集中所有的子序列,通过信息增益选择最佳shapelets 作为决策树节点分类准则,具有分类精度高、速度快、可解释性强的优点。
基于集成的算法是集成多种时间序列分类方法,Bagnall 等人[13]提出COTE 使用了35 种分类器,具有很高的分类精度,但相对耗时严重。本文主要研究基于shapelets的时间序列分类算法,并证明提出的算法在保证分类精度的前提下大幅度减少耗时。
shapelets是时间序列的子序列,是最能代表其所属类别的时间序列,它可以较为充分地说明各个类别之间的差异,使得分类结果具有更强的可解释性。近年来使用shapelets 和序列之间的相似性作为判别特征来解决时间序列的分类问题已经成为当前一个新的研究热点。基于shapelets的分类算法最初由Ye等人[12]所提出,它将shapelets的发现过程嵌入到决策树中,并使用信息增益来评估对象的质量,提高了分类的准确性,但该分类算法时间复杂度为O(n2m4),这使得该方法在大部分情况下无法适用。
针对上述方法中候选集规模庞大、计算耗时长的问题,Rakthanmanon 等人[14]提出一种基于符号聚合近似(SAX)离散化表示的快速shapelets 发现算法(Fast Shapelete,FS);Grabocka等人[15]提出了Learned Shapelet(LS)算法,该算法采用启发式梯度下降shapelets搜索过程。李祯盛等人[16]将转换过程进行主成分分析进行降维,该方法虽然缩短了时间但降维造成了信息缺失,从而降低了分类准确性。以上算法在shapelets 提取过程中均同时构造分类器,一定程度上受应用场景的限制。
Lines 等人[17]提出的shapelets 转换技术将shapelets的发现过程与分类器相分离,从数据集中选取出质量最好的k个shapelets,接着将每一条时间序列到这些shapelets的距离转换成该时间序列的k个属性,将原数据集转换到新的数据空间,在提高精度的同时保留了shapelets的可解释性,可以根据具体情况结合不同的分类器使用。
Ji 等人[18]使用子类分割方法对训练机进行采样,确定局部最远偏移点(LFDPs),并选择两个不相邻的LFDPs 之间的子序列作为shapelets 候选。Hills 等人在文献[19]提出对shapelets 进行聚类以缩减候选集,并同时使用三种不同的方法衡量shapelets 的质量。原继东等人[20]针对上述方法中候选集大量相似和无法确定k取值的问题提出了shapelets剪枝和覆盖方法,上述两种方法均是在shapelets完全提取后进行剪枝操作,导致所耗时间甚至多于原始shapelets发现时间。
虽然上述针对shapelets 转换技术的研究都能在一定程度上提升运算速度,但随着数据规模的快速增长,传统方法由于逐个计算候选集中每一个子序列的质量,再逐一比较选择出最好shapelets,因此总体而言仍存在着计算耗时的问题。针对上述缺点,本文提出了一种基于改进LSH的shapelets转换方法,该方法先进行一次预扫描,根据形状快速去除相似冗余,随后采用文献[20]所提的shapelets覆盖的方法确定最终shapelets集合,最后进行数据集转换。该算法由于先根据形状的相似性过滤挑选候选序列,因而无需进行大量shapelets质量计算,从而大大降低了计算耗时。
1 相关知识与定义
定义1(时间序列及子序列)时间序列T=(t1,t2,…,tn)是按相等的时间间隔采样的数据点构成的序列,其中ti(i∈1,2,…,n)是任意的实数,n为时间序列的长度。子序列S=(ti,ti+1,ti+2,…,ti+l-1)是一条时间序列中从位置开始,长度为l的一段连续的序列,其中1 ≤i≤m-l+1。
定义2(时间序列的距离)将长度为m的两条时间序列A=(a1,a2,…,am)和B=(b1,b2,…,bm)看作向量,它们之间的距离Dist(A,B)用欧几里德范数表示,如式(1):
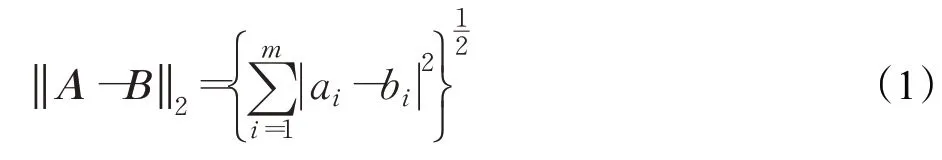
定义3(子序列和时间序列的距离)对于长度不同的子序列S和时间序列T,距离定义为S与T中长度与S相同的子序列的距离的最小值,即,其中Ti表示T中长度与S相同的所有子序列。
定义4(信息增益)设数据集D被划分为数据子集D1和D2,则其信息增益为:
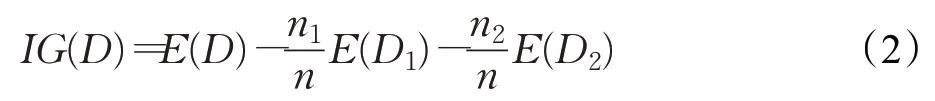
其中,n、n1和n2分别表示数据集D、D1和D2的大小。E(D)表示D的熵,计算如下:

式中,pc是集合D中类标号为c的序列的概率。
定义5(shapelet)[12]定义分裂点为一个二元组<S,δ>,由子序列S和距离阈值δ组成的,根据S与数据集中每一条时间序列之间的距离是否大于δ将时间序列数据集D分为DL和DR,当信息增益最大时的即为shapelet,此时的距离阈值δ=dosp即:

图1 展示的是Gun/NoGun 问题中的两条质量最好的shapelet,从形状上来看,shapelets 就是形状独特、足以区分不同类别的子序列。

图1 Gun/NoGun问题中的shapelets
定义6(局部敏感哈希)[21]对于哈希家族H,如果任意两个对象x、y满足如下两个条件,则认为H是敏感的。
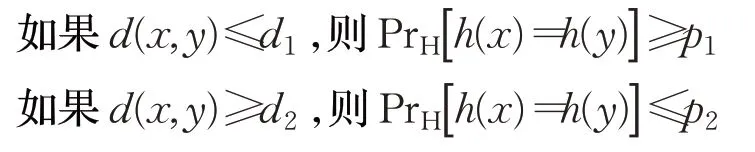
其中,d1>d2,p1>p2,d(x,y)表示x与y之间的距离,分别表示对x和y进行哈希变换。
局部敏感哈希函数在降维的同时能有效保持两个高维数据之间的距离,第一个条件保证了两个距离相近的向量会以很高的概率映射为同一个Hash 值,第二个条件则表明两个距离较远的向量映射为同一个Hash值的概率会很低。
定义7(LSH 函数族)本文中采用欧氏距离度量下的Hash函数[22]:

其中,ω是窗口长度参数(文献[23]推荐用ω=4),ai是一个d维向量,每一维的值都满足标准正态分布,bi满足的均匀分布。
2 基于LSH的shapelets转换算法(LSHST)
本文是基于Lines 等人[17]提出shapelets 变换算法(简称ST)的改进,该算法首先通过单次扫描训练集,找到最佳的k个shapelets,然后通过5 折交叉验证方法得到参数k的最优值,用top-kshapelets得到一个新的数据集,其中新数据集中每一条时间序列有k个特征,每条数据的k个特征都代表了时间序列与shapelets 之间的距离。最后将不同的分类器与新数据集结合使用进行时间序列分类。ST 方法的主要优点在于将shapelets选择过程单独分离出来,可结合不同分类器灵活使用。然而该算法在运行时间上消耗巨大,其中寻找top-kshapelets是最为耗时的部分:首先获取数据集的所有子序列,其次对子序列计算其到每一条时间序列的距离用以衡量shapelets的质量,最后去除来自同一序列且有重叠的冗余序列后,选择质量最好的k个shapelets。假设在数据集D中有长度为m的时间序列n条,那么这个数据集一共有nm2条子序列,ST 算法中的shapelets 提取的时间复杂度为O(n2m4),但最终从nm2条子序列中只选择几条到几十条作为shapelets,由此可见,ST 算法的shapelets 提取过程中对大量相似冗余序列进行了重复计算,导致时间消耗过大。
针对以上所提问题,本文提出一种shapelets提取的加速策略,引入局部敏感哈希函数(LSH)先过滤掉大量形状上相似的候选序列,再计算剩余序列质量,精简计算量,加快shapelets的提取过程。
2.1 用于shapelets过滤的改进LSH算法
局部敏感哈希最早在1998 年由Indyk 提出[21],基本思想是利用哈希函数值使得相似的数据以很高的概率发生冲突从而能够被检测到。欧氏局部敏感哈希(Exact Euclidean Locality Sensitive Hashing,E2LSH)是LSH 在欧氏空间的一种随机化实现方法,由Datar 等人在文献[22]中提出,利用基于p-stable分布的位置敏感函数对高维数据进行降维映射,使原始空间中距离很近的两个序列经映射操作后依然很近。
LSH 算法的提出用来解决海量高维数据的最近邻问题:首先将原始高维数据点经过LSH函数,根据不同函数值映射到一张哈希表中的不同位置(哈希桶),每一个哈希桶中的点大概率相似,待到查找最近邻时,将待查找的点经过同样的哈希函数映射到同一个哈希表的某一个桶中,最后直接对该桶中的数据进行查找,大大提升了查找效率。
为了提升LSH 算法的准确性,使得p1更大,p2更小,文献[21]提出了增强LSH算法:定义了函数组g(·),由同一个哈希函数族中独立随机地选择k个哈希函数组成,即,只有k个hi()全部对应相等时,才映射为同一个Hash值,该操作降低了false negtive rate(本身相似的序列被判断为不相似),但这样增加了false positive rate(本来不相似的两条序列被判断为是相似的),所以采用L个函数g1(·),g2(·),…,gL(·),对长度为l的全部子序列分别进行L次哈希计算,建立L个哈希表,两个序列只要在任意一个哈希表中被映射为同一个Hash值,就认为这两条序列是相似的。假设两条等长的序列v1和v2,经过相同LSH哈希函数hi()的映射计算的值相等的概率为P,即,那么,经过上述增强LSH算法,这两条数据被认为是近邻的概率为。
本文所提LSHST算法就是利用LSH哈希表的每一个哈希桶中数据大概率相似、不同哈希桶的数据大概率不相似的特点对候选集进行过滤,希望经过LSH哈希后得到形状上互不相似几条序列。但是上述增强LSH 算法对于每一长度的序列都需要建立L个哈希表,造成大量的空间消耗,同时在本文算法中,只关心经哈希函数映射后互不相似的序列,而相似的序列是将要抛弃的部分,所以提出了逐级过滤LSH,具体算法如下:
(1)同样生成L个函数g1(·),g2(·),…,gL(·),先对长度为l的子序列通过函数g1(·)进行第一次LSH 映射,建立第一个哈希表T1。
(2)遍历哈希表T1,从每一个哈希桶中挑选u条序列作为代表通过函数g2(·)进行第二次映射,建立第二个哈希表T2,同时删除第一个哈希表T1,释放内存。
(3)遍历T2,从T2的每个桶中选择u条序列进行第三次映射,建立T3,删除T2。这样重复至第L次结束,哈希表TL中的所有序列即为逐级过滤的最终结果,该过程如图2所示。
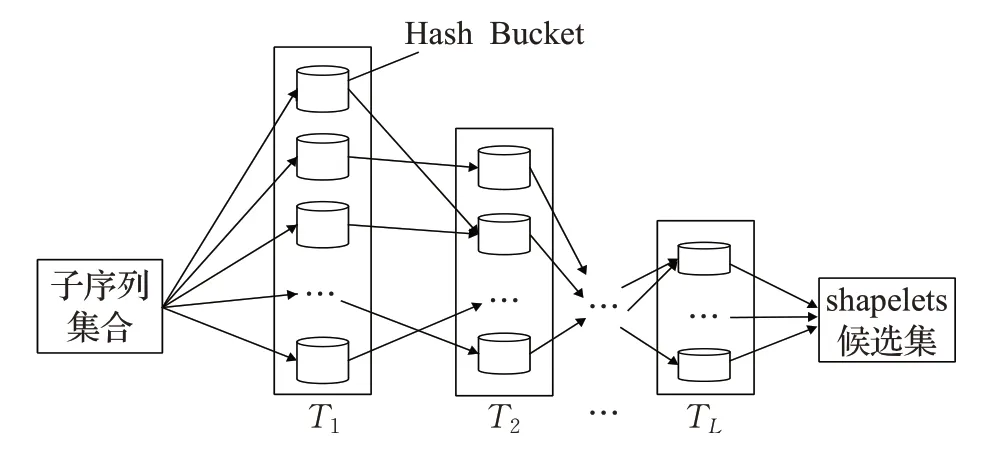
图2 LSH逐级过滤过程示意图
逐级过滤LSH在两个方面做了提升:减少了空间开销同时减少了计算量。既然只要两条序列同时被映射在任意一个哈希表的同一个桶中,这两条序列就相似,就可以提前对相似序列作剪枝操作,抛弃掉大量已经被证明是相似的序列,这样并不会影响TL最终留下的序列之间不相似的概率,节省了下一次映射过程中对这些无用序列的计算,大幅度提升运算效率。
2.2 LSHST算法描述
本节具体描述基于LSH 的shapelets 转换算法(LSHST)。整体思路是首先扫描数据集提取所有子序列,对数据集子序列集合进行筛选过滤,得到形状上具有代表性的shapelets候选集;其次计算候选集中每一条序列的质量,从中挑选最终的shapelets;最后进行shapelets转换。下面具体展开阐述。
第一步过滤是利用2.1 节所提出的逐级过滤LSH算法去除shapelets候选集中在形状上的相似冗余序列,留下形状上互不相同的部分序列。在逐级过滤的过程中,怎样从上一个哈希表的桶中选择u条序列进行下一次映射是需要考虑的问题。由于映射到同一桶中的子序列具有很高的相似程度,在后续计算质量时几乎差距不大,为了避免序列之间耗时的比较计算,所以在选择代表序列时采用随机选取的方式。以长度l为10的全部子序列为例,图3 展示的是从哈希表T1中随机挑选的两个哈希桶中的全部序列,可以看出,每一个桶中的序列形状上高度相似,选择哪一条作为代表序列区别并不大,其中加粗的序列为随机挑选的代表序列(u=1 时)。

图3 不同哈希桶中序列示意图
经过逐级过滤后得到无冗余序列的候选集,接下来计算每一条序列的质量,本文使用信息增益作为衡量shapelets质量的方法,然后采用文献[20]所提的shapeles覆盖方法根据质量进一步筛选确定最终的shapelets。表1为5个数据集在过滤过程中候选集中子序列数量的变化,表中第三列为经过LSH逐级过滤后的候选集中序列的数量,可以看出,该步骤过滤掉大量相似序列,只需计算几十或者几百条序列的质量便能得到shapelets,节省了时间。
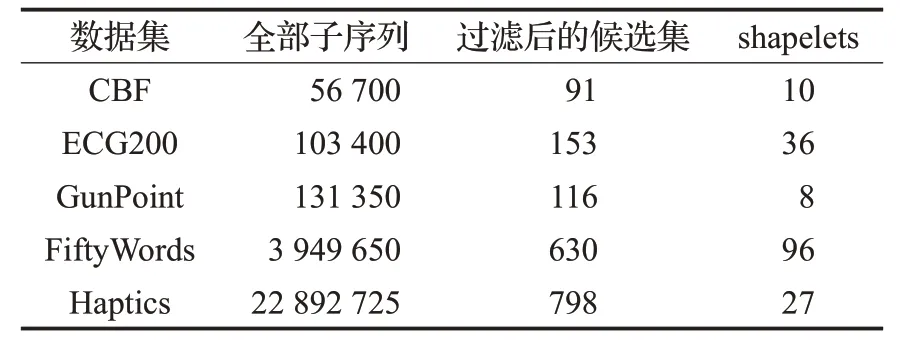
表1 LSHST算法在过滤过程中序列数量变化表
2.3 LSHST算法实现
LSHST算法伪代码见算法1。
算法1LSHST(data,L,u,minLength,maxLength)
输入:数据集data,LSH哈希映射循环次数L,每个桶中随机选取的子序列条数u,shapelets长度最大值和最小值
输出:转换后的数据集

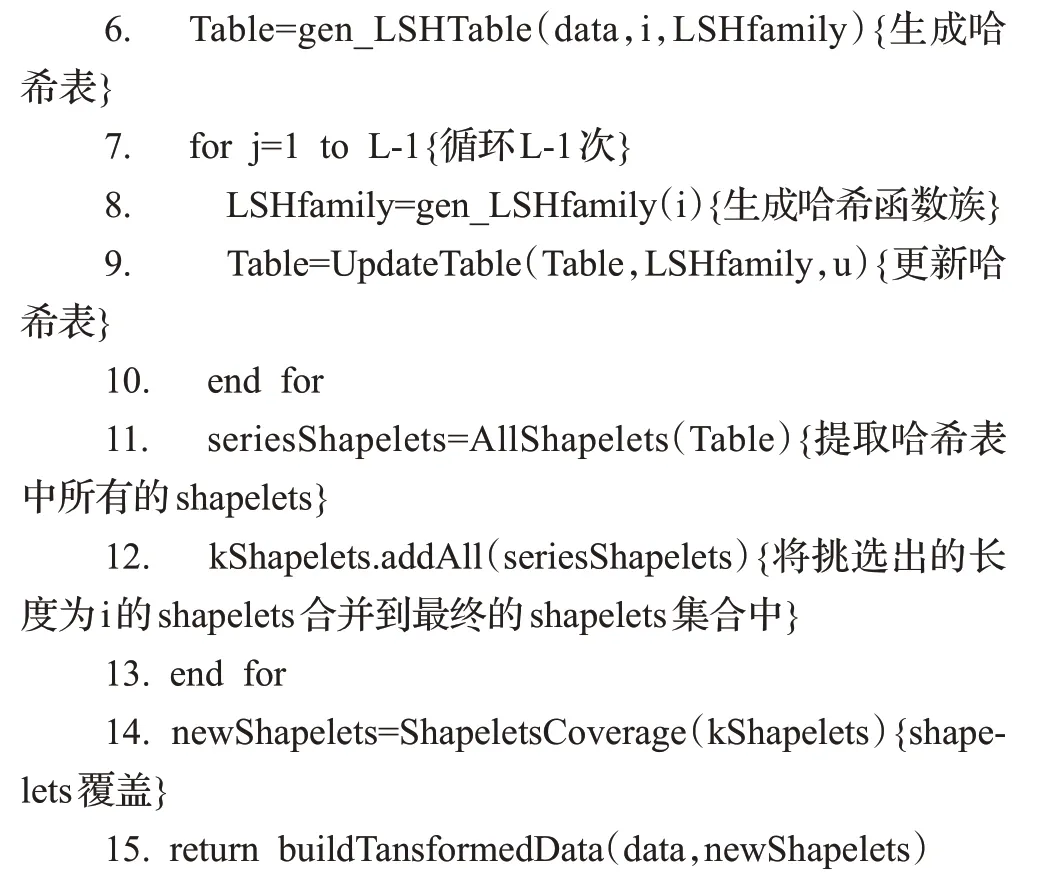
算法1描述了基于LSH的shapelets转换过程,对长度从minLength 到maxLength 的子序列分别进行过滤(第4行~第13行),首先生成Hash函数族(第5行),所有子序列依次进行LSH映射,存储到哈希表Table中(第6行);其次循环L-1 次更新哈希表Table(第7 行~第10行),每次更新都重新生成不同的Hash函数族(第8行);接着将每一个长度挑选出来的shapelets 候选序列合并到一个数据集中(第10行);最终集合kShapelets就是过滤后的shapelets 候选集合。上述过滤过程无需计算shapelets候选序列的质量,每次循环序列的数量均会减少很多,相应地节省了大量的计算。过滤完成后进一步进行Shapeles 覆盖[20]选择shapelets,此时的候选序列仅有几十或几百条,大大缩短了运行时间。最后返回转换后的数据集(第13行)。其中哈希表更新算法见算法2。
算法2UpdateTable(Table,LSHfamily,u)
输入:待更新哈希表Table,Hash 函数族LSHfamily,每个桶中随机选择子序列数量u
输出:更新过后的哈希表newTable

算法2中首先初始化一个新的哈希表newTable(第1 行),其次遍历待更新的哈希表Table(第2 行~第10行),依次提取出每一个哈希桶bucket 中的子序列集合seriesLists(第6 行),从该集合中随机选择u条序列uLists(第9行),将其插入到新的哈希表newTable中,遍历结束返回newTable。
由于在哈希表更新过程中每个桶中只选择u条序列进行新一轮映射,所以新建的哈希表规模远远小于原哈希表,并且在提取出每个哈希表中的序列后,就会释放掉该哈希表所占用的空间,由此可见对长度为i的所有子序列的逐级过滤过程中,所占用的最大空间即为第一次建立哈希表所占的空间。而紧接着对长度为i+1的子序列进行过滤时,长度为i的子序列哈希表也同样被释放,所以LSHST算法最终的空间复杂度为O(nm),可见该算法大大节省了空间消耗。
3 实验与结论
本章所涉及所有算法均在Weka框架下使用Java代码实现,为了全面衡量算法效果,根据数据集的规模,从UCR数据集中分别选择6个较小和6个较大(见表2)的数据集,作为本章实验的数据集对前文所述算法进行测试和评估。

表2 数据集
3.1 参数选择
在建立子序列过滤的过程中,为了提高每一个桶中序列相似的概率,本文引入了哈希映射的次数L和随机选取子序列的数量u,这两个参数会决定shapelets的数量和质量,进而影响分类效果和转换时间。为分析参数u和L的变化对分进行了测试,结果如图4所示,可以看出算法的分类准确率的影响,分别对参数在不同组合情况下算法准确性基本稳定,不会因参数L和u的变化产生明显的趋势变化。
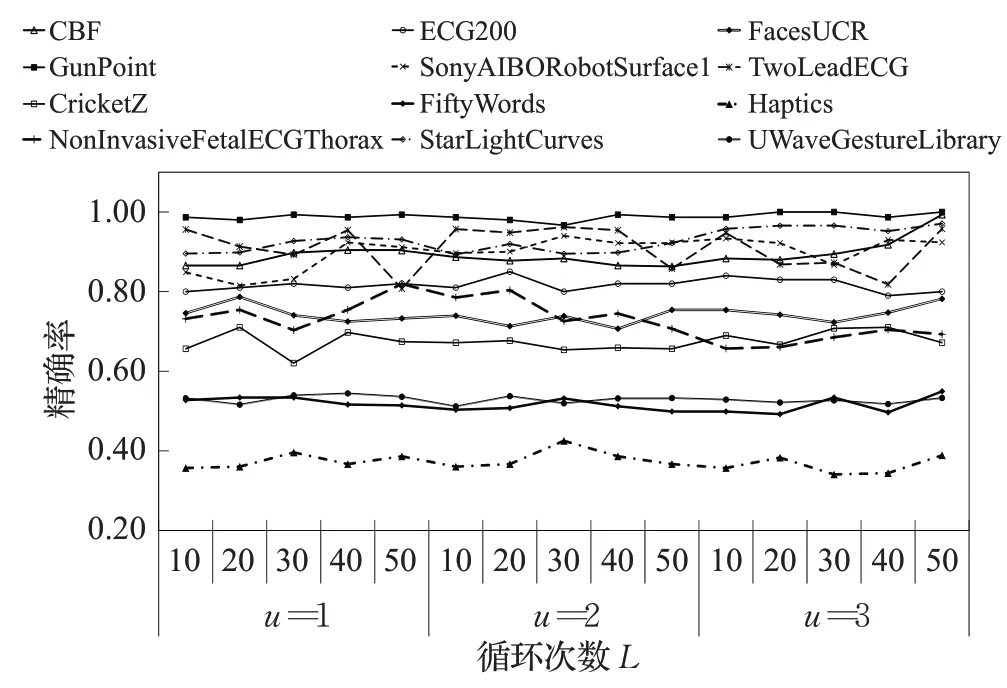
图4 LSHST算法精度随L和u的变化曲线
为分析参数变化对计算耗时的影响,本文首先对参数L不同取值情况下计算耗时情况进行了测试,结果如图5所示,实验结果表明参数L的变化对时间有明显的影响。在u=1 的情况下,分别对两组数据集进行了实验。从图5(a)可看出在规模较小的数据集上,所用时间消耗随着L的增大总体呈减小趋势,但L=45 变化趋于平缓,L=55 后会有一定程度的上升。图5(b)所示在规模较大的数据集上,耗时曲线持续下降,L=50 时大部分数据集变化基本平缓。
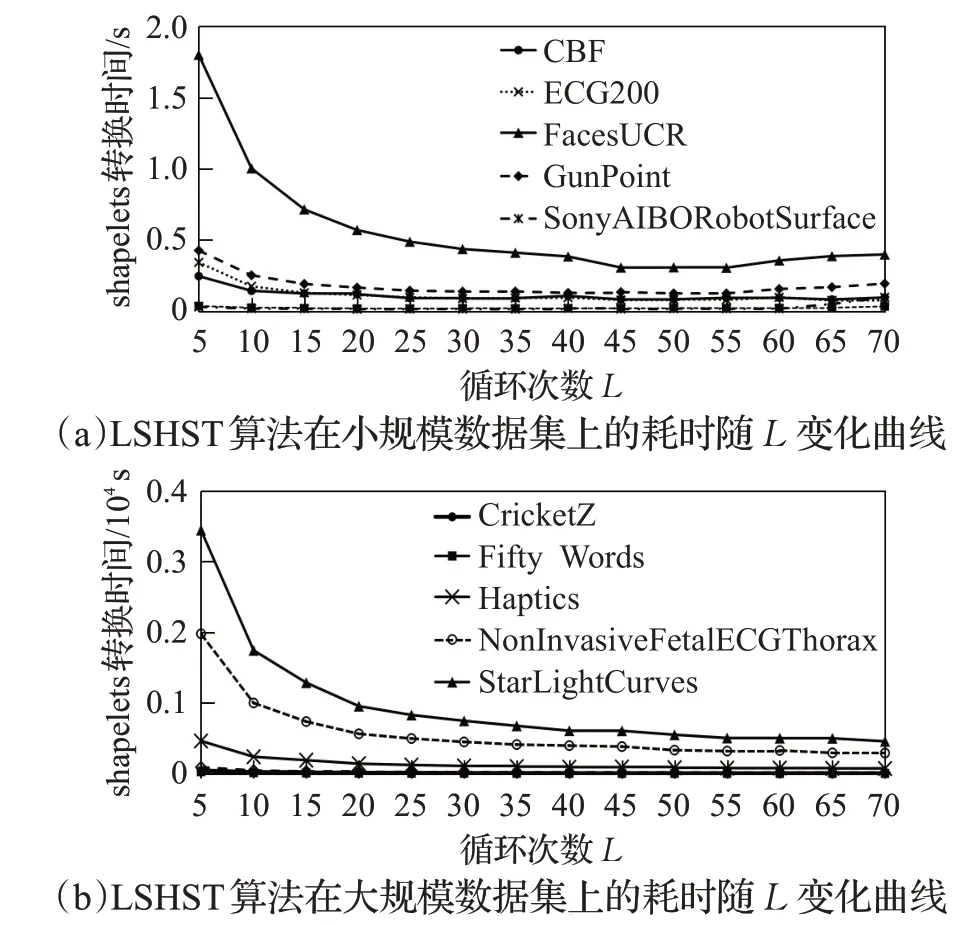
图5 LSHST算法时间消耗随L 的变化曲线
为整体观察u和L对时间消耗的影响,本文同时也对u和L不同组合情况下的计算耗时做了对比实验,其中取u={1,2,3},L={20,30,40,50},实验结果如表3,其中表现最好的参数组合为u=1,L=50。

表3 LSHST算法在参数L 和u 的不同组合情况下的耗时 s
3.2 算法评估
为综合评价LSHST 算法的性能,设计了两组对比实验,其一是与shapelets 转换算法作对比,另一个是与其他经典分类算法作对比,在前一实验所确定的最佳参数组合u=1 和L=50 基础上将LSHST 算法与多种分类器组合,进行分类准确率和算法耗时的测试。
3.2.1 LSHST与其他shapelets转换算法的比较
为了说明本文所提算法在基于shapelet 转换的算法中处于领先水平,对比了LSHST 和ShapaletSelection(ST)[17]、ClusterShapelet(CST)[18]以 及Fast Shapelet Selection(FSS)[19]这三种shapelets 转换算法,分别结合1-NN、C4.5、Naive Bayes(NB)、Support Vector Machines with Linear(SVML)、random forest(with 500 trees)(RandF)、Rotation Forest(with 50 trees)(RotF)这6 个分类器以计算平均分类精度,结果如表4,LSHST 算法在12个数据集中的7个数据集上表现优于其他方法,在SonyAIBORobotSurface 数据集上相比FSS、ST、CST 分别提升了5.08、12.94和19.95个百分点,在TwoLeadECG数据集上分别提升了16.52、14.1和4.71个百分点,可以看出LSHST在分类精度上表现良好。
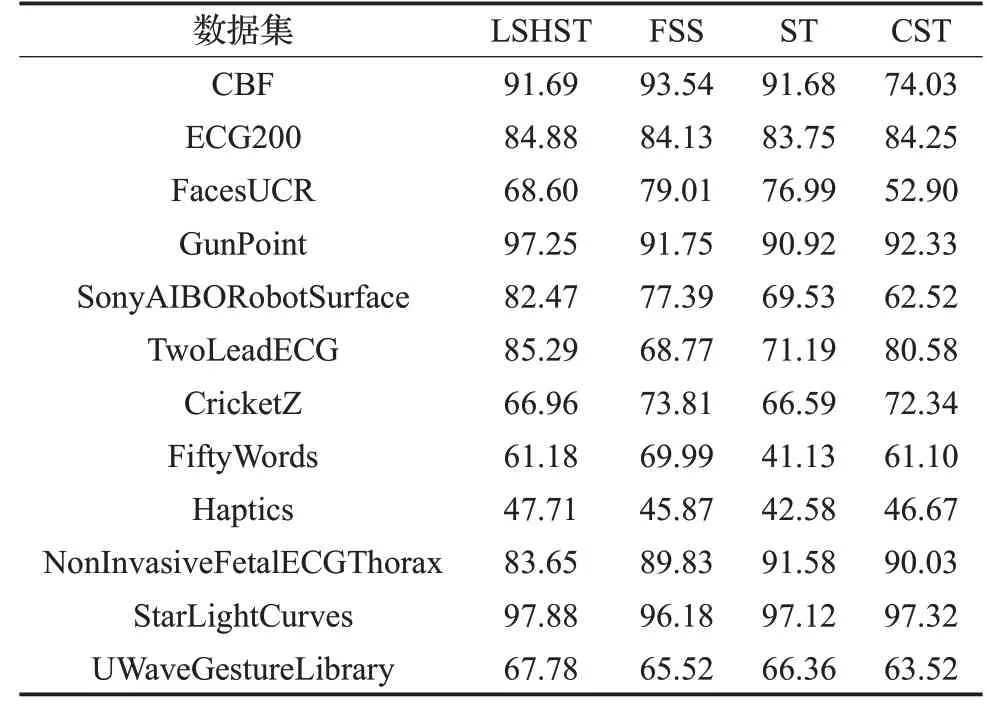
表4 LSHST、FSS、ST、CST算法的平均分类精度%
同时比较了这4 种方法的shapelets 转换时间,如表5 所示,ST 和CST 随着数据集规模的增长,时间消耗也巨幅增长,而LSHST 算法在时间消耗上比ST 提升了10~8 000 倍,CST 的时间消耗最长达到两天以上,在FiftyWords数据集上耗时是LSHST的16 000多倍。FSS是目前shapelets 转换方法中最快的,从表5 中可得LSHST与FSS在规模较小的数据集上耗时相当,但是在规模较大的数据集上,LSHST可以将耗时减少至FSS的一半以上,尤其在NonInvasiveFetalECGThorax 和Fifty-Words 数据集上FSS 的耗时分别是LSHST 的4.8 和8.5倍,这表明LSHST在大规模数据上具有较高的适用性,在保证有较好分类精度的前提下耗时最短。
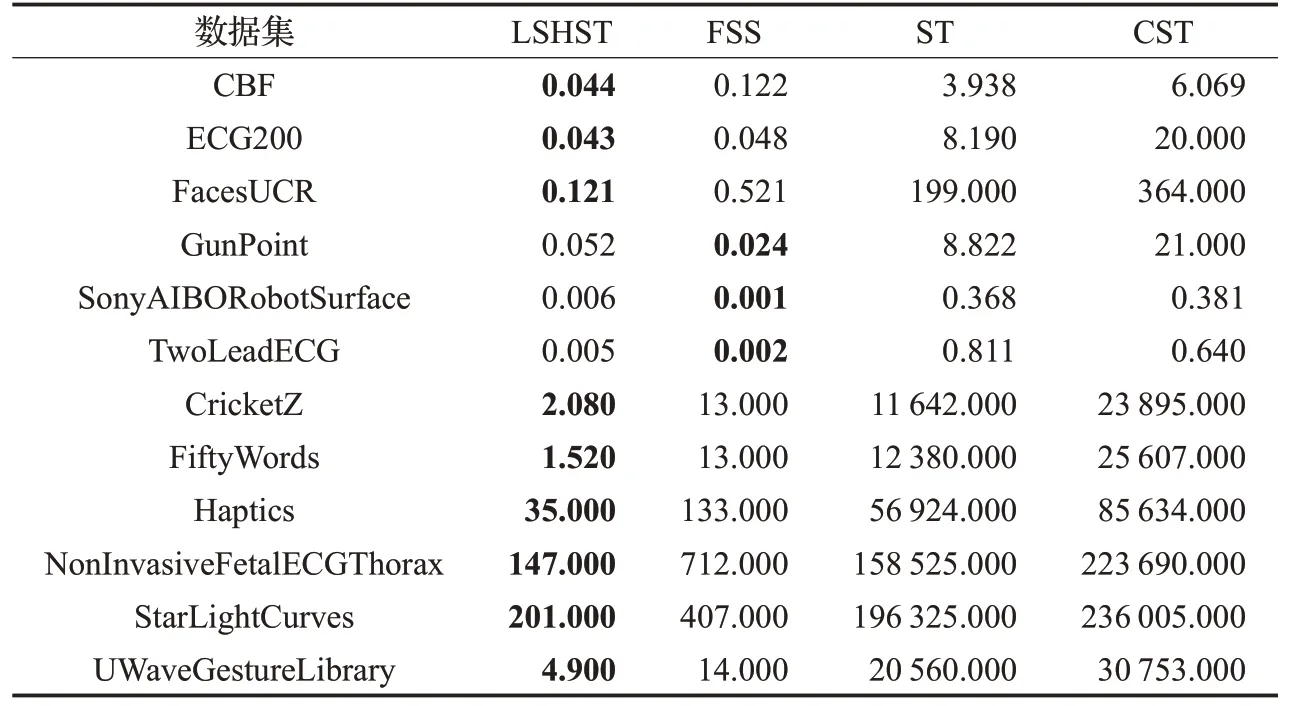
表5 LSHST、FSS、ST、CST算法的shapelets转换时间 s
3.2.2 LSHST与其他经典分类算法的比较
为了说明LSHST 在时间序列分类方面的先进性,对比了几种经典的分类方法,其中包括基于欧氏距离的最近邻算法(DTW_1NN)、基于shapelets 学习的LS 算法[15]、基于SAX的shapelets发现算法(FS)[14]和集成算法(COTE)[13]。在实验中,LSHST 使用Random Forest 分类器。从实验结果可知,这5 种方法的分类精度(表6所示,下标括号中为精度排名)平均排名分别是2.4(LSHST)、3.25(DTW_1NN)、2.5(LS)、4.25(FS)、2.67(COTE),其中LSHST排名第一,结合表7可以得出,FS算法在分类精度上表现不如其他算法,而LS 和COTE虽然具有较高的分类精度,但算法耗时巨大,特别是在数据规模较大的数据集StarLightCurves和NonInvasive-FetalECGThorax 上,分类时间均超过72 h(259 200 s)。DTW_1NN表现出对数据规模的敏感,在小规模的数据集上表现更好。而本文所提LSHST在保证分类精度的同时,大量缩减分类时间的消耗,特别是在大规模数据集上具有明显优势。
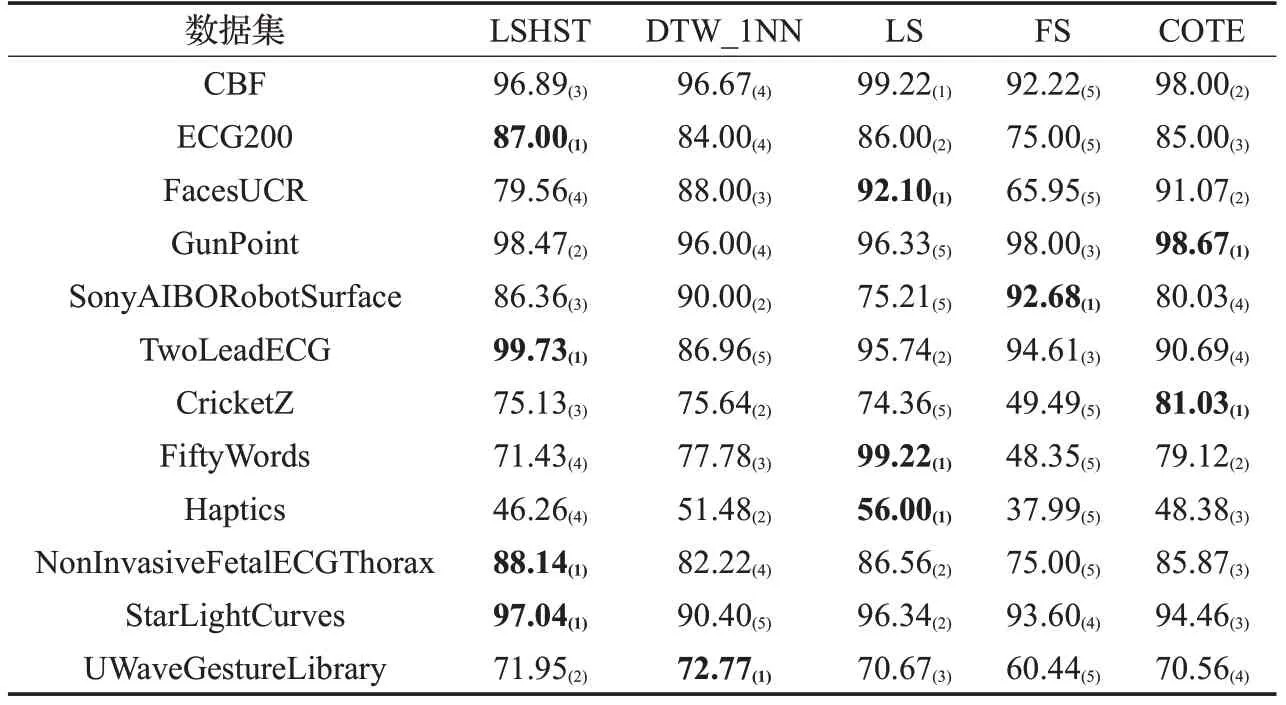
表6 LSHST与其他经典分类器分类精度对比%
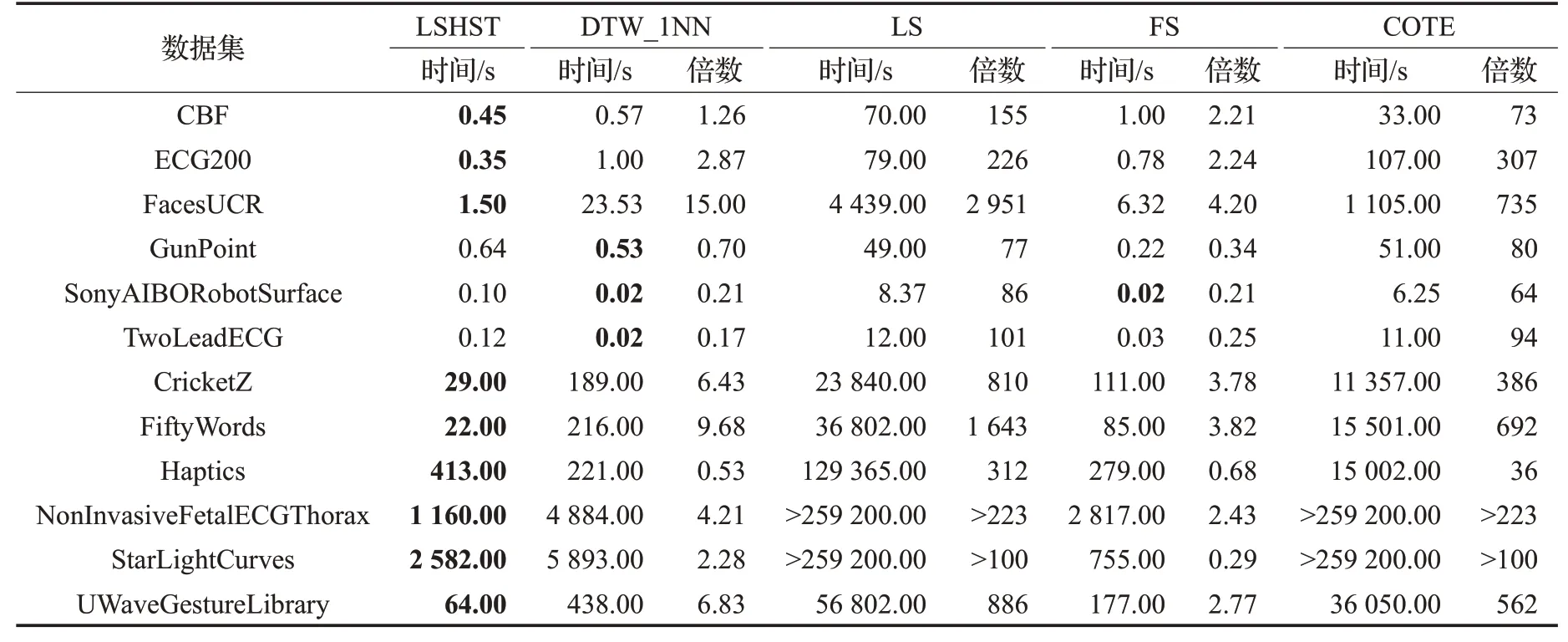
表7 LSHST与其他经典分类器的分类时间对比
4 结束语
介绍了一种基于LSH 的shapelets 转换方法,利用LSH快速将相似的序列聚集在一个桶中的特性,对子序列候选集中大量相似序列进行过滤筛选,再用覆盖方法从其中选择出shapelets 作进一步转换。该方法在保证分类精度不降低的前提下大幅缩减了分类时间,尤其在大规模时间序列的分类问题上具有很高的应用前景。
