分层强化学习综述
2021-02-04魏竞毅陈希亮
赖 俊,魏竞毅,陈希亮
陆军工程大学 指挥控制工程学院,南京210007
强化学习(Reinforcement Learning,RL)是机器学习的一个重要分支,它是智能体(Agent)根据自身状态(State)采取动作(Action)与环境进行交互获取奖励,最终完成一个最优策略使奖励最大化。2017 年最具影响力的AlphaGo大胜世界围棋冠军李世石和柯洁事件,其核心算法就是强化学习算法。但在传统强化学习中面临着维数灾难的问题,因为所有强化学习的方法都把状态动作空间视为一个巨大的、平坦的搜索空间,这也就意味着一旦环境较为复杂,状态动作空间过大,将会导致起始状态到目标状态的路径非常长,需要学习参数以及学习过程中的存储空间将会非常大,使得学习的难度成指数增加,并且强化学习效率以及效果不尽如人意。
之后随着深度学习的再次兴起,其强大的探索能力受到了广大科研人员的热捧,于是结合两者深度强化学习也就此应运而生,深度强化学习不仅具有强大的探索能力,对于复杂的环境状态都能够有一个良好的处理,但当智能体具有复杂动作空间时,其依旧不能取得良好的结果,使得强化学习的发展再次碰触到了瓶颈。为解决强化学习发展的瓶颈问题,研究者们将分层的思想加入强化学习中,提出分层深度强化学习(Hierarchical Deep Reinforcement Learning,HRL),HRL 的本质是通过将任务分解为不同抽象层次上的子任务,子任务的状态动作空间有限,对子任务能够有较快的求解速度,最终加快整体问题的求解[1]。经过分层深度强化学习在竞技对抗游戏中,人工智能不断发力,在例如DOTA2、星际争霸2 这类复杂的竞技对抗游戏中与游戏职业顶尖人员进行对抗并取得了胜利,甚至在与普通人对战时出现人类一败涂地的情况。
本文首先对MDP 和SMDP 进行简要描述,同时也回顾了一下三种分层强化学习方法:Sutton的option体系、Parr 和Russell 的HAM(Hierarchies of Abstract Machines)方法和Dietterich的MAXQ 框架,之后对几年来在分层深度强化学习上的创新进行了介绍,主要集中在分层的子策略共享、无监督的学习和多层的分层结构,最终讨论分层深度强化学习的发展前景与挑战。
1 强化学习理论基础
1.1 马尔科夫决策过程
强化学习是学习一种从情景到动作的映射,以此来使得标量奖励或强化信号最大[2]。强化学习的目标是给定一个马尔科夫决策过程(Markov Decision Process,MDP),寻找最优策略π。强化学习的学习过程是动态的,其数据通过在不断与环境进行交互来产生并不断更新,马尔科夫决策过程有元组(S,A,P,R,γ)描述,其中S为有限的状态集,A为有限的动作集,P为状态转移概率,R为回报函数,γ为折扣因子,用于计算累积回报。当一个智能体(agent)根据与环境的交互采取一个动作α后,它会获得一个即时收益reward,然后根据其状态转移概率P到达下一状态st+1,同时由于马尔科夫性,下一个状态st+1仅与当前状态st相关,所以每次做出决策时不用考虑历史状态,最终根据其累积奖励构成的状态值函数和状态-行为值函数,来学习到最优策略。
1.2 半马尔科夫决策过程
马尔科夫决策过程根据当前状态st选择一个动作后,会根据状态转移概率P和策略π 跳转至下一状态st+1,而且根据马尔科夫性其下一状态st+1仅与当前状态st有关。但由于在一些情况下,多个动作在多个时间步骤完成后才能体现出其真正的价值,对于这类情况MDP 无法进行较好的优化处理,所以研究人员引入半马尔科夫决策过程SMDP(Semi-Markov Decision Process)[3],SMDP是依赖历史状态的策略,两者的状态变化如图1。Sutton提出对于任何MDP,以及在该MDP上定义任何一组option,仅在这些option 中进行选择并执行每个option以终止决策的过程就是SMDP。SMDP包括一组状态、一组动作,对于每对状态与动作都有一个累积折扣收益,同时与下一个状态和transit time有一个明确的联合分布[4]。
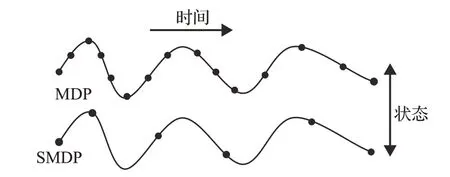
图1 MDP与SMDP状态比较
在SMDP 中,两个决策之间的时间间隔为τ,τ既可以是实数也可以是整数。当为实数时,SMDP建模连续时间离散事件系统(continuous-time discrete-event systems)[5],在离散时间(discrete-time)SMDP[5]中,只能在底层时间步的整数倍的时间上做决策,离散时间SMDP是大多数分层强化学习算法的基础,同时也可以推广到连续时间上。在SMDP中,在某一状态s采取动作后,经过τ时间后才会以某一概率转移至下一状态s′,此时是状态s和时间τ的联合概率写作预期奖励为状态值函数和状态-行为值函数的贝尔曼方程为:
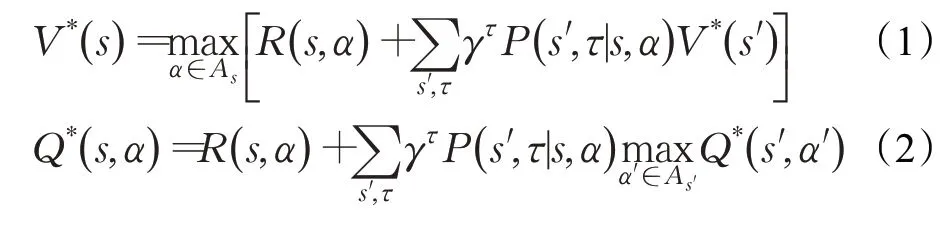
2 经典分层强化学习方法
分层强化学习本质是将较为复杂的强化学习问题进行分解,将大问题分解为一系列子问题,之后给出子问题的解决策略,从而得出解决整体问题的最优化策略。在分层强化学习中,抽象的思想贯穿始终,其通常对于子任务进行抽象,将其多个动作进行封装抽象为一个策略动作,在MDP 系统中下一状态仅与当前状态有关,而与之前状态无关,所以在底层策略中采用MDP,但在高层策略中,其虽然将子任务抽象成一个策略动作,近似看作一个动作,但其内在存在一系列动作,在高层策略选择子策略后,经过子策略一段执行时间后,高层状态才会转至下一状态,在此是采用SMDP的处理方式。分层强化学习的经典学习算法主要包含Option、HAMs、MAXQ,虽然这三种方法是相对独立开发的,但是其具有相同的点,都是依据SMDP来提供理论基础。
2.1 Option
Sutton[6]提出SMDP本质上是具有固定Options选项集的MDP,Options 是具有一定意义的时间序列决策过程,也可以理解为一段持续时间内的动作。Options 包含三部分:策略π表示option 中的策略,终止条件β表示状态s有概率结束当前option;初始集I表示option的初始状态集合。
在一个任务正在进行时,只有状态s⊆I时,Options才是有效的。当选择了option,就会根据当前的策略π 选择动作,直到option 根据终止条件β终止,之后智能体开始选择下一option。一个option 在st开始,终止于st+k。在每一个中间时间,MDP 仅取决于sτ,而SMDP可能取决于前面的整个序列。同时可以将SMDP 用在Q-learning 中,在每一步option 终止后更新,更新公式为:
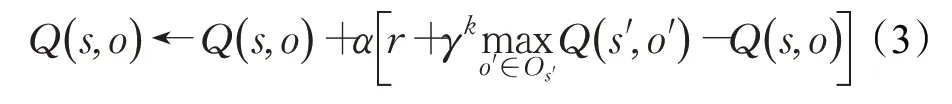
Bacon 在option 基础上将其与Actor-Critic 者结合,提出了一种Option-Critic框架[7],这一框架与经典AC框架相似,但其使用option 的分层强化学习方法,并使用策略梯度方法对一系列option的参数进行更新,实现了端到端算法,其不需要设置内在奖励,就能够自动学习出option的策略和自动切换option。其在四房间任务中,当目标任务发生变化时,相较于AC 方法,使用Option-Critic 框架的智能体能更快的适应,同时在Arcade 学习环境中,在多个游戏中表现出超越DQN的性能收益。
2.2 HAMs
Parr和Russell提出一种分层结构的MDP策略称为分层抽象机HAMs(Hierarchies of Abstract Machines)[8]。HAMs也是在SMDP的理论基础上提出的,但与Options不同的是,HAMs是通过限制可实现策略的类别来简化复杂的MDP。HAM是一个程序,当智能体在环境中执行时,它约束着每个可以执行的操作,例如在迷宫之中,一个简单的机器可能会命令反复选择向右或向下,排除所有向上向左的策略,HAMs以这种简单约束表达来给出了一种层次约束思想。
HAMs是通过一组状态、一个转换函数和一个确定机器的初始状态的启动函数来定义一个HAM是一个三元组,μ是机器状态的有限集,I是从环境状态到机器状态的确定初始状态的随机函数,δ是机器状态和环境状态对下一机器状态的随机下一状态函数映射,I和δ通常是是描述环境状态的一些状态变量的函数[9]。
对任意的MDP(M)和任意的HAM(H)都存在一个SMDP,表示为H◦M,其解是一个最优的选择函数choose(s,m),使得在M中执行H的智能体获得的期望和收益最大。同时对任意的MDP(M)和任意的HAM(H)都还存在一个reduced SMDP,表示为等同于H◦M,其最优策略相同,但是包含的状态不超过H在M上的选择的状态的动作是H◦M的选择点上的选择动作。将Q学习应用于HAMs 中称为HAMQ-learning[9],它持续追踪以下参数:t当前环境状态;n当前机器状态;sc和mc上一选择点的环境状态和机器状态;α上一选择点做的选择;rc和βc上一个选择点以来累积的奖励和折扣总额。HAM Q-learning智能体更新:在每一个选择点的转换,智能体Q学习更新公式:
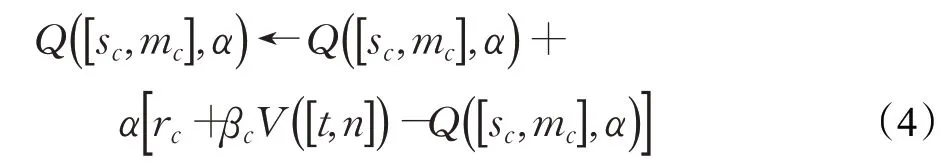
PHAM[10]是David 在HAM 上提出的新的改进,在PHAM中引入了两种额外的状态类型,分别是表述执行内部操作的内部状态和便于计算但不产生直接影响的空状态,通过这两种状态在HAM 中添加了几个结构化的编程结构,PHAM 具有相比HAM 更多的11 个参数,同时PHAM具有中断中止特性,其可以在调用子例程中指定中止条件。在执行巡逻环境中,PHAM仅需9台机器即可,而HAM则需要63台,具有更好的表现力。
2.3 MAXQ
Dietterich提出一种新的分层强化学习方法MAXQ值函数分解(MAXQ value function decomposition),简称为MAXQ[11]。该方法将目标MDP 分解为较小的MDP的值函数的组合,这种分解称为MAXQ分解,将给定的M分解为一组子任务,将M0作为根子任务,解决M0也就解决了M,如图2 所示是一种出租车任务简要分解的情况。每一个子任务是一个三元组定义为一个终止断言(termination predicate),它将S划分为一组活动状态Si和一组终止状态Ti,子任务Mi的策略只有在当前状态是活动状态时才可以执行。Ai是实现Mi任务的一系列动作,这些动作可以是原始动作集合A中的动作,也可以是其他子任务。是一个伪奖励函数,它规定了每个从活动状态到终止状态的转变的伪奖励,这个奖励说明了终止状态对这一子任务的期望程度,它通常被用来给目标终端状态一个0的伪奖励,而给任何非目标终止状态一个负奖励。策略π定义为一个包含问题中每个子任务的策略的集合是子任务Mi的解决策略。
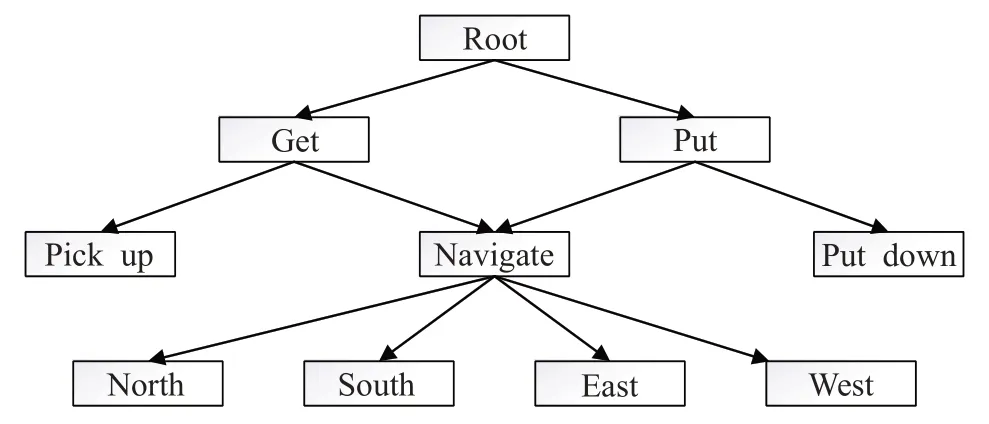
图2 使用MAXQ的出租车接客任务分解
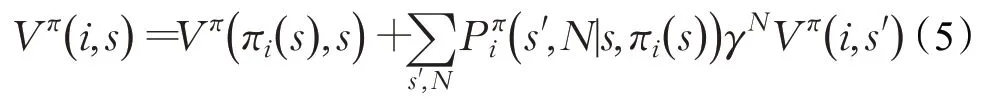
状态-行为值函数定义为:
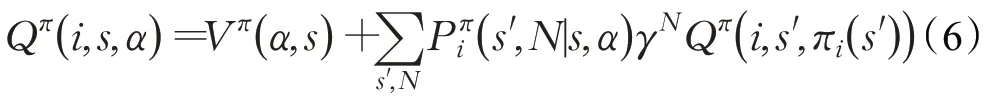
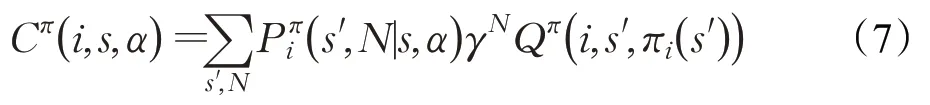
因此可以递归的表达Q函数为:
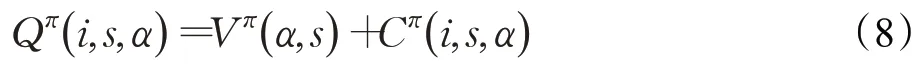
在MAXQ 的 基 础 上,Nicholas 将R-MAX 算 法 与MAXQ 框架相结合提出一种更新的算法R-MAXQ[12],它继承了R-MAX 算法基于模型的探索和MAXQ 的分层抽象思想,R-MAXQ 与MAXQ 不同于其使用模型分解来计算分层的值函数,而不是使用标准MDP 模型来计算整体值函数,同时它的层次结构允许它通过减少不必要的探索性操作来约束智能体的策略,并提高其累积回报,在出租车任务中R-MAXQ 算法相对R-MAX 和MAXQ-Q算法总是获得更大的收益。
Mehta 提出了一种从模型和演示中自动归纳算法HI-MAT(Hierarchy Induction via Models and trajectories)[13],HI-MAT 将动态贝叶斯网络(DBN)模型应用于源问题中的单个成功轨迹,以构建因果注释轨迹(CAT)。HI-MAT以CAT中动作之间的因果和时间关联为指导,递归地对其进行解析,并根据发现的CAT 分区定义MAXQ子任务,其与VISA[14]相同都使用了DBN,但不同于VISA 引入option 架构,而HI-MAT 引入的是MXAQ架构,同时使用了在源MDP中得到的成功轨迹,最终其实验表明学习的层次结构更加紧凑。
但同时HI-MAT 使用DBN 对于复杂环境模型的自动构造能力较差,同时如果成功轨迹如果存在缺陷,则其无法自动发现子任务,于是Wang 提出了一种新的机制来发现MAXQ子任务,称为HI-CS(Hierarchy-Instruction via Clustering States)[15],HI-CS通过使用受动作影响的状态变量来自动获取任务层次结构,并基于状态变量,生成状态抽象。然后,HI-CS分析了动作对系统状态的影响,将子任务聚类成层次结构。
3 最新分层深度强化学习研究
当今HRL 算法通常采用两层结构,一层结构作为顶层结构,每隔一段时间进行调用,根据当前观测到的环境和智能体状态产生高层策略输出子任务,这个子任务可以是一个目标点也可以是一个任务,第二层作为底层结构,根据当前目标状态和子任务产生动作,以解决子任务问题。这种结构高层产生子任务并不十分复杂,而在底层策略上产生的动作会影响最终目标完成的效率,同时由于子任务产生所获得的收益回报往往较为稀薄,所以如何更好地学习以及产生更有效的任务是重点。
3.1 基础算法的改进
DQN 算法是在强化学习中经典的算法,其通过神经网络来近似值函数,但是DQN 算法在奖励稀疏问题上效果较差的,针对这一情况Kulkarni提出了一种分层强化学习算法h-DQN[16],其建立双层网络结构如图3,其双层结构都是采用DQN 网络。第一层叫做metacontroller,负责先定一个能达到的小目标,第二层是低级别controller,根据meta给出的目标进行action,小目标达到或者到达规定时间后,重复制定新的目标。metacontroller 通过外在奖励来生成子目标,同时给予controller 内在奖励,使controller 能够根据奖励实现小目标。最终其在Atari 游戏蒙特祖玛的复仇中相较DQN取得了更好的效果,提高了其在稀疏奖励问题上的处理能力,但如果在连续状态空间上中,meta-controller需要无数个子目标,同时其需要外部奖励,这显然无法做到,所以其也具有局限性。
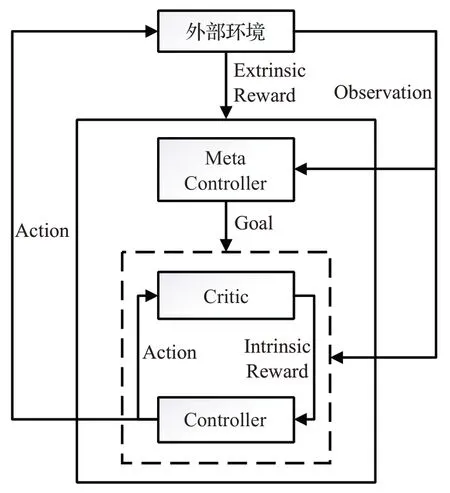
图3 h-DQN分层结构图
3.2 子策略共享分层方法
在分层结构中,子策略是用于解决其子任务的一系列具体动作,环境和智能体处于在不同状态下所采产生的子任务必然不同,同时其采用的一系列动作也有所区别,但是在一些环境下,其虽然任务不同但是所采取的动作与策略存在共通性,只要把这些子策略再次进行细分,就可以使其在不同任务中实现共享,而不用每次提出子任务就需要一次学习训练,这样也就可以提高训练效率,使其更快更好地完成任务。
Florensa 提出了一种基于skill-based 的随机神经网络SNN4HRL(Stochastic Neural Networks for Hierarchical Reinforcement Learning)[17],在整体框架下其首先建立了一个预训练环境,在预训练环境中学习技能,之后在利用所学习到的技能,使智能体在实际环境中的高层策略中根据环境状态来学习调用这些技能,提高其解决问题的效率。在高层策略中其使用SNN(Stochastic Neural Networks)来灵活调用这些技能,并采用双线性融合将观测值和隐变量做外积,发现这种方式可以产生更广泛的技能,同时文中通过使用基于互信息的正则项,以保证其学习到的技能更多样更能适用多种情况。但如果由于预训练环境与实际环境的奖励并不完全相同,在实际中可能会产生不能良好解决整体任务的情况。
由于人对不同的环境任务能够有一个明确的解决策略,那么人工对子任务和子策略提出更强的一些约束也就可以减少智能体学习训练时间,Andreas 就提出了一种以策略草图(policy sketches)为指导的多任务深度强化学习框架[18],建立一种模型将每个子任务与一个模块化的子策略相结合,其子策略训练时采用AC(Actor-Critic)方法,并通过在共享子策略之间绑定参数,来使整个任务特定策略的收益最大化。因为将子策略与子任务人工进行关联,所以在学习过程中可以提高学习效率,减少了自我学习,但同时由于人工定义了每个任务所需要的子任务数目,所以其泛化性能不足,对于不同环境下的问题需要重新进行人工定义。
此前的分层结构更多的都是研究人员根据任务人工进行设定,OpenAI实验室的Frans提出了一个端到端的算法(Meta-Learning Shared Hierarchies[19],MLSH),其通过与环境互动来实现自动的分层结构,无需进行过多的人工设定,能够在未知任务上快速学习子策略。MLSH在子策略问题上也是共享的,同时通过不断训练新的主策略,使其可以自动地找到适合主策略的子策略,这一算法突破了人工设定的局限性,使得其能够自主进行学习。
3.3 无监督分层方法
无监督在缺乏足够先验知识的情况下依旧能够自动实现良好的分类,其不需要人工进行标注这也就使其具有更好的泛化性能,由于很多分层强化学习算法适用的环境相对较为单一,在不同的环境下都需要人工进行不同的设定,将无监督应用于分层强化学习中就可以增强其鲁棒性,使其在放到更为复杂的环境下,也能够产生更好的效果。
Rafati[20]提出了一种新的无模型的子目标发现的分层强化学习方法,其使用了增量无监督学习,根据智能体最近产生的轨迹来产生合适的子目标集合,利用无监督学习方法可以用来从状态集合中识别出好的子目标集合,分层结构使用的是H-DQN。Rafati使用异常点检测和K-means聚类方法来识别出潜在的子目标,状态特征发生较大变化也可以当做异常点(也就是新奇的状态),其在“蒙特祖玛的复仇”这一环境较为复杂的游戏中也取得了较好的结果。
为了使智能体能够自主地不断进步并对环境进行探索,Sukhbaatar和Kostrikov提出了一种以无监督探索环境的方式[21],其设立一个智能体,但是存在Alice 和Bob 两个策略制定者,Alice 首先执行若干动作,之后将这个序列作为目标任务让Bob去做,如果Bob完成任务则获得较多奖励,而Alice获得较少奖励,相反如果Bob未完成则Alice 获得较大奖励,以此来使Bob 能够更快地了解环境,而Alice也能不断提高任务难度,两者形成一种循序渐进的探索。在此基础上Sukhbaatar 再次将分层的思想加入其中,提出一个基于非对称自我扮演的无监督学习方案[22],其模型为HSP(Hierarchical Self-Play)模型如图4,添加了高层策略chalice,让chalice 利用外部奖励来学习如何提出目标让Bob进行完成,使得其能够不断自我优化,不仅有较好的环境探索能力,同时也能够通过增加外部奖励来促进其实现任务目标。
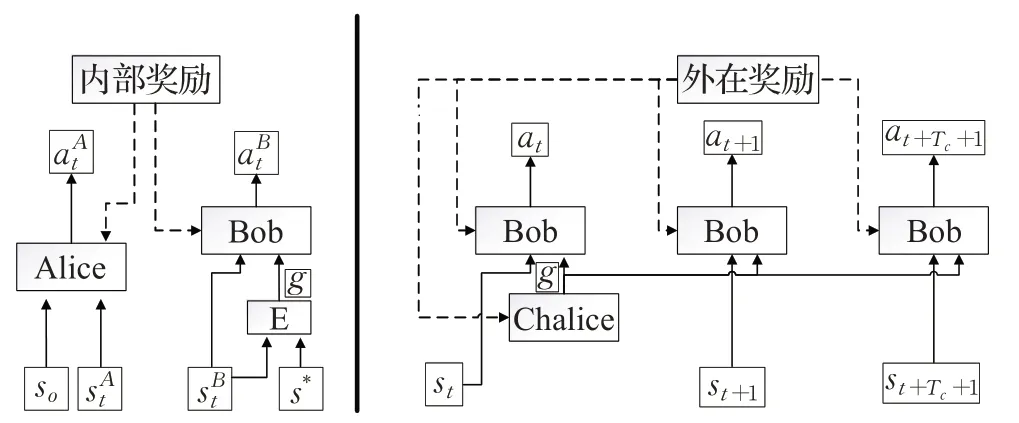
图4 HSP分层结构框图
3.4 多层结构分层方法
两层的分层结构是当前大多数分层强化学习算法的主结构,因为分层算法本身就具有不稳定性,同时由于有些环境下奖励更为稀疏,所以分层结构一旦分更多层,其稳定性更为难以保证。Levy 提出了一种三层的层次强化学习框架,层次角色批评HAC(Hierarchical Actor-Critic)[23]。在这一层次框架中其克服了智能体在联合多个层次的稳定性问题,同时也是第一个成功在具有连续状态和动作空间的任务中并行学习三级层次结构的框架。其在三层结构中采用一种嵌套的方式来构建智能体如图5,当前状态输入每层策略,首先由顶层策略产生subgoal1,之后再由子策略产生subgoal2,直到底层策略产生动作与环境进行交互。Levy认为分层强化学习分层策略的产生不稳定性的原因主要有两点,第一点是顶层的转移函数是依赖于下一层的策略的,顶层每隔n个时间步会提出一个子目标,然后交由底层策略执行,但n个时间步后智能体处于什么状态是由底层策略决定的,所以顶层策略提出目标,智能体却可能到达不同的状态,第二点由于底层策略是不断探索的,这也就造成顶层策略的转移函数会随之不断变化,这并造成多层策略的不稳定性。为了解决这一问题,文中使用了HER(Hindsight Experience Reply)[24],解决其稳定性问题,并通过使用hindsight action和hindsight goal transitions 让智能体能够并行学习多个策略,但HAC 的三层结构相比其他两层结构所具有的优势并没有真正体现出来,仍有继续进步的空间。
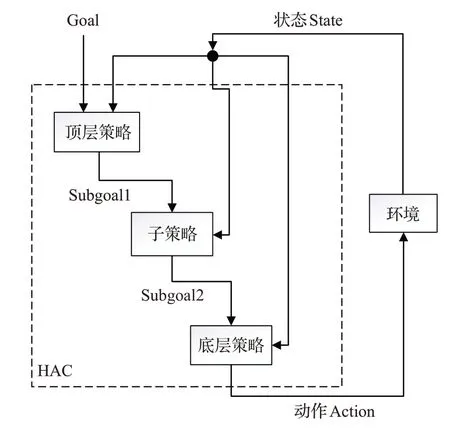
图5 HAC多层结构示意图
而Song 提出了一种多样性驱动的分层强化学习算法DEHRL(Diversity-driven Extensible Hierarchical Reinforcement Learning)[25],在该框架中,构建并学习了一个可扩展框架如图6,实现了多层次的HRL,但与HAC结构并不相同,DEHRL是上层策略调用下层策略与MLSH类似,在每一层中其包含三个部分policy、predictor 和estimator,每一层都会将环境状态和上一层的动作作为输入,policy负责产生每一层的动作,predictor对未来的状况进行预测,预测一段时间后的外部状态和外部奖励,并将其传给下层的estimator,estimator 将上层的预测作为输入,得到本层的奖励并根据结果训练本层的policy,同时DEHRL 是无需人为设计外部奖励的端到端的算法,避免了过多的人为因素。
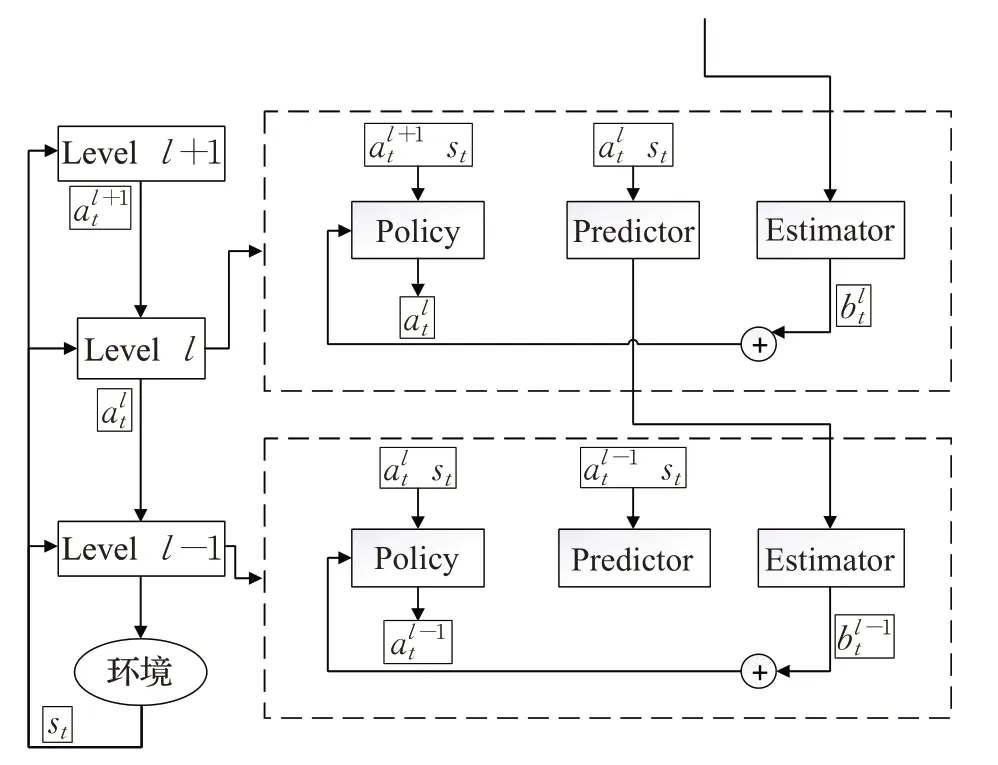
图6 DEHRL分层结构框图
4 方法分析和对比
上述分层强化算法都有其针对性优化的方面,各自具有其优缺点,其对比情况如表1。子策略共享的分层方法相对更易实现,其所依赖更多的是人工进行子策略的设计,当设计的子策略越好,其训练出来的效果也就越好,同时其收敛速度也会更快,但其也会因为人工设计的缺陷,可能产生无法良好解决任务的情况。无监督分层方法更多的优化体现在其对环境的探索上,其对于探索新奇点产生的奖励更高,这在复杂环境下能够更好地使其产生出更多的动作,同时其不会受限于单一环境,在新环境下也能够不断进行探索发现,训练结果能够不断进行优化,但也是因为会对更多地方不断探索,所以需要更多的训练时间。多层结构分层方法主要对分层的稳定性方面有了更好的体现,分层结构本身就具有不稳定性,同时层数越多结构的稳定性也就更差,训练结果也更不容易收敛,所以多层结构对稳定性的解决有了很好的表现,但是多层的分层结构具体对整体性能的优化体现的并不明显,这点仍有研究的空间。同时在2.3节中介绍了两种自动分层算法HI-MAT和HI-CS,自动分层算法能够根据动作和状态变化,来进行子任务的识别,并通过聚类或者DBN来实现自动的分层,自动分层的结构更为紧凑,同时减少了人工,使得智能体能够具有更好的自主学习能力,其整体效果相较基础的Qlearning和MAXQ-Q方法有更好的表现,但是整体环境较为简单,所以仍有较大的进步空间。
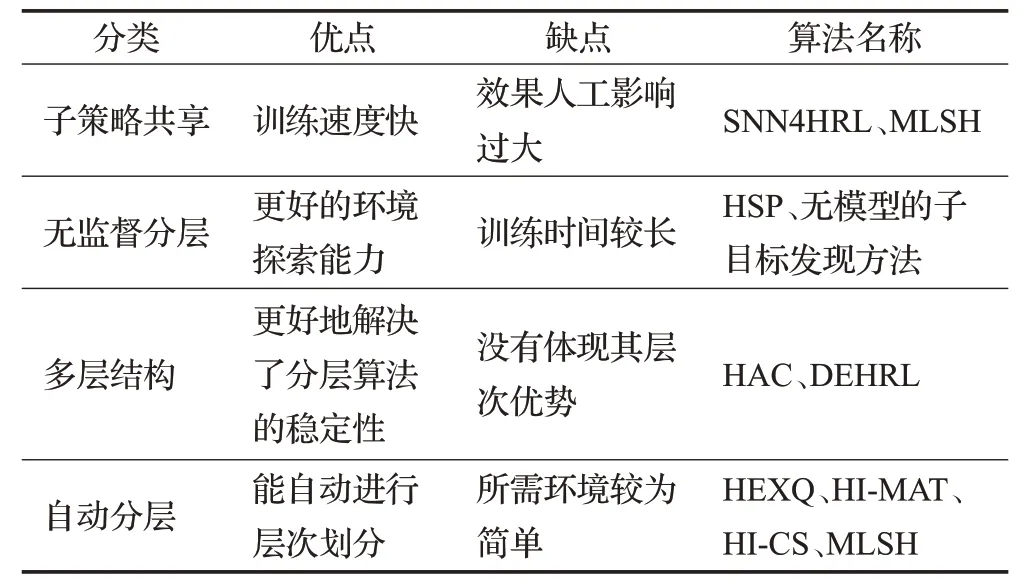
表1 分层深度强化学习算法汇总
除了上述几种方法,依旧有以下几种不同创新的分层强化方法。例如为了应对skill-based HRL 方法在预训练环境中的代理奖励和任务可能不一样,而导致预训练的技能不能良好解决底层任务的情况,Li开发了一种新的基于优势的辅助奖励的HRL 方法(HRL approach with Advantage-based Auxiliary Rewards HAAR)[26],HAAR基于高层策略的优势函数,在不使用特定领域信息的情况下,为低层次技能学习指定了辅助奖励。通过优化其辅助奖励,来整体提高累计的奖励来实现整体效果的提升。Nachum 则提出了一种采用off-policy 的分层强化学习算法HIRO[27],因为off-policy 具有更好的样本效率,最终实现在Ant-Gather、Ant-Maze 等较为复杂环境中的较好效果。Dilokthanakul[28]针对可视域中发现子目标提出了一种具有广泛适用性的方法,其采用两种方法来对子目标进行发现,分别是采用像素控制和特征控制,在像素控制过程中采用卷积处理,并将其处理后的连续两个的像素块的平方差来作为内在奖励,在特征控制上其引入特征选择性的概念,将其作为一个内在奖励,最终其塑造的奖励函数不仅包含内在奖励还设立有外部奖励,通过奖励来对智能体的行为可以进行细微的调节。
在电子竞技方面,南京大学团队就发现将分层强化学习用在星际争霸2游戏中训练AI算法[29],也表现出良好的性能,通过实验发现分层的结构相较于未分层结构,在与高难度电脑对战的情况下有更好的胜率,而在低难度情况下差别不明显,但其在作战网络是由人工进行整体的设定,输出结果是都是整体的行动,但在玩家对战时存在着编队的行为,所以其作战策略仍可以进行优化。同时OpenAI 实验室开发出了名为OpenAI five的人工智能系统[30]在dota2游戏中表现出了极为优越的性能,OpenAI five 采用的GPU 数量峰值时有1 536 个,同时其采用了一个超过1.5 亿个参数的模型,神经网络具有4 096 个单元的LSTM,并经过将近10 个月的训练时间,最终在与游戏职业选手的对战中取得了胜利。
5 分层深度强化学习未来展望
科研人员认为人和动物的行为是具有层次结构的,分层强化学习在一定程度上符合人解决任务的思想历程。分层强化学习的优势从根本上在于:拥有在更快的学习、减少维数灾难和解决大的状态-动作空间问题的强大能力,同时拥有多层次的时间抽象能力和更好的泛化能力,其利用分层的方式减少了问题的复杂性,但同时其依旧面临着多层次产生的策略不稳定性、额外的超参数以及样本效率问题等诸多挑战,总体来看以下几个方面将是HRL的重要研究方向:
(1)更加强大的自动分层能力。当前的分层强化学习,其高层策略尤其是在相对复杂的环境下,通常是由人工进行层次划分以及任务的设定,这可以减少其子任务空间状态与动作的复杂性,但同时结果的好坏更多的会有人设定来决定,这也就要求其有特定领域的知识和技巧,来更好促进其强化学习的效果,虽然有HI-MAT、HI-CS、MLSH自动学习层次结构方法,但其对解决任务的能力并没有较好的提升,所以在此方面仍有较大的进步空间。
(2)大规模深度强化学习的应用。深度学习的发展就是计算机算力在不断的发展,大规模深度强化学习对于计算机算力需求更是强烈,其通过大规模的CPUGPU来进行获得训练数据以实现神经网络的训练,而分层强化学习在大规模问题上的应用依旧很少,如果能将分层应用于大规模深度强化学习上,使得学习效率更快,这也是一种挑战。
(3)评价标准的确立。现在的研究环境下存在一个观点认为,认为当前缺乏一个有效的标准与工具来评价HRL甚至整个强化学习的领域的进展,这也在一定程度上阻碍着强化学习的进步,所以如何确立一个明确的评价标准也是一个重要的研究方向。
6 结语
本文对于分层强化学习进行了回望,按照由浅入深的次序对分层强化学习进行了分析,介绍了HRL 的概念理论、经典算法、深度学习算法和发展展望等。本文在引言部分对分层强化学习的背景知识进行了介绍,之后对强化学习的基本理论进行了简要介绍,同时对经典的分层强化学习进行梳理,接着对加入深度学习后的分层强化学习按照对基础算法的改进、子策略共享分层方法、无监督分层方法、多层结构分层方法进行分类对比分析,最后对分层强化学习的未来展望进行简要分析。通过本文可以看到分层强化学习是一个有着极大发展潜力、能够解决复杂动作问题的新兴领域,其不仅在科研领域在工程领域也有着诸多的应用场景,相信随着科研人员的不断钻研,这一领域必会不断克服困难解决更多更复杂的问题,在未来实现人类的美好智能生活。
