胶囊神经网络研究现状与未来的浅析
2021-02-04贺文亮朱敏玲
贺文亮,朱敏玲
北京信息科技大学 计算机学院,北京100101
深度学习是机器学习的一部分,随着大数据时代的到来和GPU 技术的进步,深度学习广泛应用于图像识别、图像分类、图像分割、目标检测[1]、身份认证[2]、知识图谱[3]、自然语言处理、语音识别、文本分类[4]等各个领域。与传统的机器学习算法相比,深度学习的优越性在于其卓越的准确性。从图像分类到自然语言处理,深层神经网络正被应用于不同的领域。人们对人工神经网络进行了研究,开发了不同类型的神经网络,如卷积神经网络和循环神经网络,它们已经应用于不同的应用领域。卷积神经网络的引入是神经网络重新流行的原因之一。可是研究发现它存在一个根本性的问题,即无法考虑到底层目标特征之间的空间关系。由于在卷积神经网络中,上一层神经元传递到下一层神经元中的是标量,标量没有方向,无法表示出高层特征与低层特征之间的位姿关系。另外,它的池化层会丢失大量有价值的信息,因此卷积神经网络存在较大的局限性。2017年,Geoffrey Hinton 在神经网络架构中引入了一个新概念——胶囊网络。
胶囊网络是近年来为克服卷积神经网络存在的缺陷而引入的神经网络之一,它以向量的形式来表示部分与整体之间的关系,不仅能够以特征响应的强度来表示图像,还能够表征图像特征的方向、位置等信息。同时,胶囊网络采用囊间动态路由算法,取代传统卷积神经网络中的最大池化法,避免了图像因池化导致精确位置信息的丢失。因此,胶囊网络以其独特魅力迅速成为深度学习领域的一项热门技术,众多科研人员纷纷致力于对其进行深入研究。
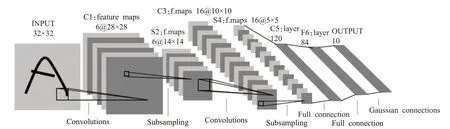
图1 LeNet-5神经网络结构图
1 卷积神经网络和胶囊网络
1.1 卷积神经网络
神经网络早期在图像分割、图像分类和识别等领域实现都非常困难。在神经网络实现过程中,它的隐藏层结构需要人为进行设计,同时计算成本非常高。因此,为了解决这些问题,LeCun 提出了卷积神经网络(Convolutional Neural Network,CNN)[5-6]。卷积神经网络成为神经网络研究热点之一,尤其是在图像分类领域,由于CNN 避免了图像的复杂预处理过程,并且可以直接输入使用原始图像,因此获得了广泛的关注[7-8]。
CNN 是一种深度神经网络,它的结构一般由输入层、卷积层、池化层、全连接层和输出层组成。卷积层以空间上下文感知的方式将多个低层特征编码为更具区分性的高级特征,再通过池化层降低图像的维数,最终由全连接层作为分类器对隐藏层的输出进行分类,输出结果。因网络结构是人为设计的,没有固定格式,因此网络结构过于复杂则会导致过拟合和梯度爆炸现象。
LeNet 是一类特殊的卷积神经网络,非常适合用于处理图像数据,但它只能处理高分辨率的灰度图像。比较经典的CNN 模型有LeNet-5、AlexNet、VGGNet、GoogLeNet、ResNet[9]以及DenseNet[10],以上均是LeNet的改进版模型[11]。下面对LeNet-5、AlexNet、VGGNet、GoogLeNet进行简单介绍。
(1)卷积神经网络LeNet-5[12]的结构如图1 所示,它由7层组成,每层均包含可训练的参数。其中,C为卷积层,S为池化层。
该网络输入大小为32×32的图片,各层的网络结构参数如表1所示。此网络结构是第一个成功用于MNIST手写数字识别的神经网络,在MNIST 数据集上准确率达到大约99.2%,由此CNN 迅速发展,出现了很多处理图像的优质网络结构。
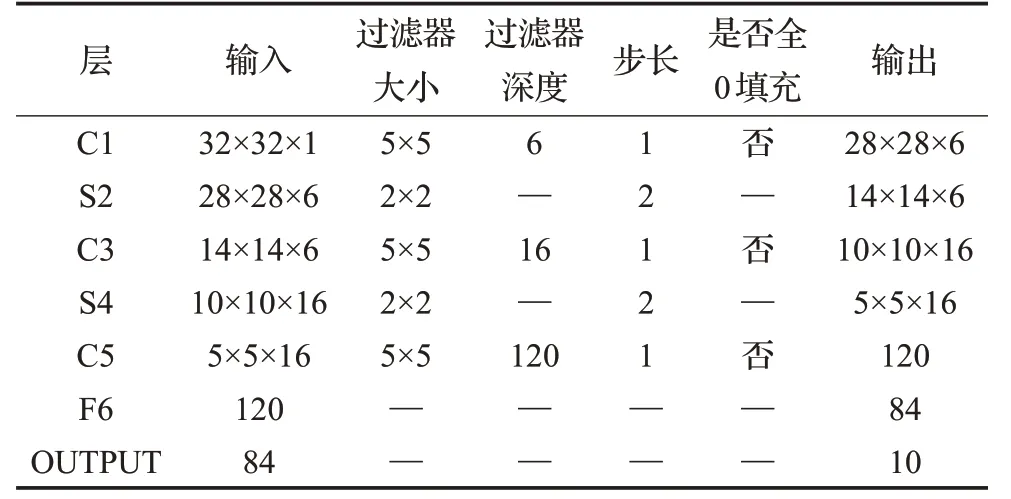
表1 LeNet-5的各层网络结构参数
(2)AlexNet[13]以图像数据集分类高准确率的优势名声大震。和现在的深度神经网络结构相比,AlexNet的结构非常简单,它由5 个卷积层、1 个最大池化层、dropout层[14]和3个全连接层组成,作者设计此网络结构用于1 000 个类别的分类。AlexNet 采用Relu[15]作为激活函数,同时利用数据增强技术扩充数据集,并且为了解决模型的过拟合问题,在结构中增加了dropout层。
(3)VGGNet[16]是卷积神经网络的一种,为了表示信息的层次结构,它实现了一个深层网络结构。同时,它还使用Relu作为每个卷积层后的激活函数。它采用的3×3 大小的滤波器和AlexNet 的11×11 大小的滤波器有很大区别,3个卷积层得到1个7×7的有效感受野,其在图像分类以及定位的操作中都能得到不错的结果。
(4)GoogLeNet[17]使用batch normalization,image distortions 和优化算法rmsprop 等技术。为了减少参数数量,其结构设定为22层,使用过程中在内存和功耗等方面表现都很好。因为CNN 的图片是按顺序堆叠的,该网络设计时受到LeNet结构的启发,实现了一个名字为Inception 的网络模型。其整个网络结构中使用了9个模块,共100多层。网络结构中还使用一个平均池化层,将特征图大小从7×7×1 024变成1×1×1 024,此方法可减少大量参数,最后选取softmax 作为激活函数。GoogLeNet的主要特点就是提升了计算资源的利用率。CNN 的迅速发展,对于图像处理领域扩大了不小的影响力,正是这种优秀的图像处理能力,使众多学者纷纷投入对CNN的研究之中。但由此固化的网络结构所产生的问题日益凸显,经典的CNN 模型已经不能满足当前社会人工智能技术的需要。在医疗、金融、交通等领域,CNN 已经不能很好地解决一些复杂的图像处理的问题,如图像旋转、指静脉识别等。因此,为了解决CNN现有的问题,胶囊网络在此之上进行改进,通过新的算法和网络结构进一步提升模型的能力,增加应用场景,满足图像处理领域的需求。
1.2 胶囊网络
1.2.1 胶囊网络背景
上述介绍的所有卷积神经网络模型中,都存在一个根本性的缺点,即从上一层至下一层传递的是标量,导致CNN无法考虑到底层对象之间的空间关系。众所周知标量没有方向,因此不能表示低层特征和高层特征的关系,同时CNN的池化层会丢失非常多的有用信息,因此CNN 在识别具有空间关系的特征时存在很大局限性。于是,2017年Hinton等人提出了一种新型神经网络结构:胶囊网络(Capsule Network,CapsNet)[18],胶囊网络是当今图像识别领域最先进的技术之一,在CNN 的基础上能够达到更好的效果。
与CNN 不同的是,胶囊不再是以单个神经元的形式出现,而是一组神经元的集合,这个集合可以是向量也可以是矩阵[19],胶囊和神经元的差异如表2 所示。多个胶囊构成一个隐藏层,深浅两层隐藏层之间的关系则通过动态路由算法确定。与卷积神经网络隐藏层中的特征图不同,胶囊的组成形式非常灵活,动态路由算法没有固定的模版,并且是单独计算深浅两层隐藏层中每个胶囊之间的关系。动态路由的计算方式决定了深浅两层隐藏层之间是动态连接的关系,因此模型可以自动筛选更有效的胶囊,从而提高性能。CapsNet 解决了CNN对物体大幅度旋转之后识别能力低下及物体之间的空间辨识度差的两个缺陷。
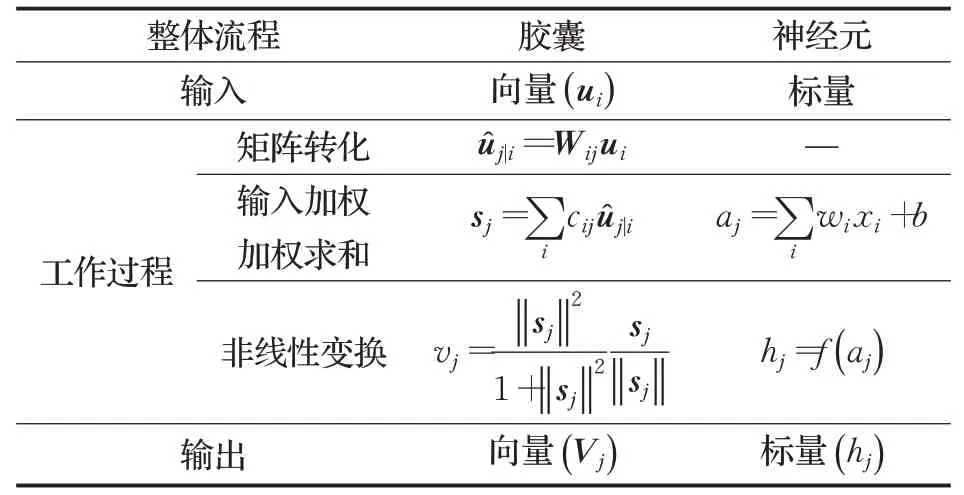
表2 胶囊和神经元的差异
1.2.2 胶囊网络结构
由Hinton等[18]提出的胶囊网络模型,又称向量胶囊网络。此胶囊网络结构较浅,由卷积层、PrimaryCaps(主胶囊)层、DigitCaps(数字胶囊)层构成,结构如图2所示[18]。输入部分为28×28的MNIST手写数字图片,输出部分是一个10维向量。其中,卷积层操作结束后,主胶囊层将卷积层提取出来的特征图转化成向量胶囊,随后通过动态路由算法将主胶囊层和数字胶囊层连接输出最终结果。第一层卷积层使用的卷积核大小为9×9,深度为256,步长为1,并且使用Relu激活函数。第二层主胶囊层采用8组大小为9×9,深度为32,步长为2的卷积核,对第一层卷积后得到的特征图进行8 次卷积操作,得到8组6×6×32的特征图,随后将特征图展平,最终得到向量神经元大小为1 152×8,即1 152 个胶囊,每个胶囊由一个8 维向量组成。第三层全连接层输出10 个16维向量的胶囊,由第二层主胶囊层经过卷积操作后得到的胶囊通过动态路由算法计算得出,图2 中Wij为动态路由的转化矩阵。
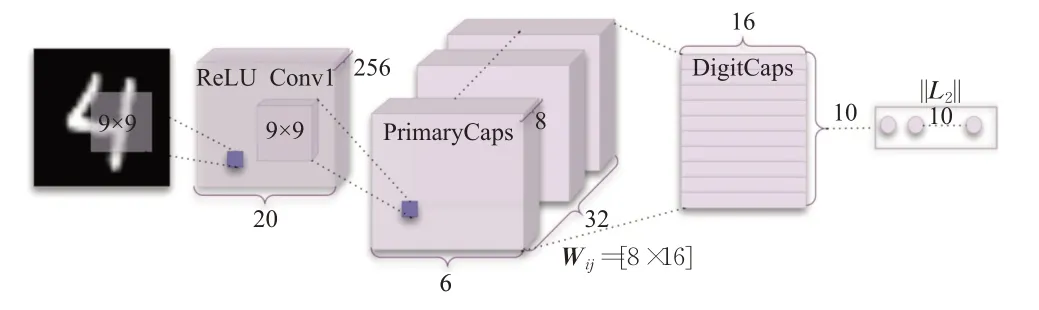
图2 胶囊网络编码器结构图
胶囊网络允许多个分类同时存在,因此不能再使用传统交叉熵损失函数,而是采用了间隔损失的方式作为损失函数,间隔损失如公式(1)所示:
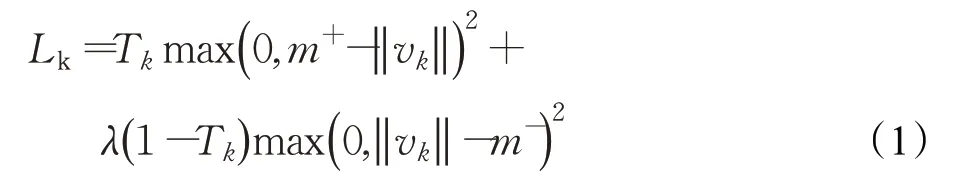
式中,Lk为经过计算得到的间隔损失;Tk为第k分类的存在值,若存在则取1,否则取0;m+、m-和λ分别取0.9、0.1、0.5。
CapsNet的解码器结构如图3所示[18],解码器用来重构图像,共有3个全连接层,接受DigitCaps层输出的10个16 维向量,也就是16×10 矩阵,重构出一幅和输入层大小28×28相同的图像。
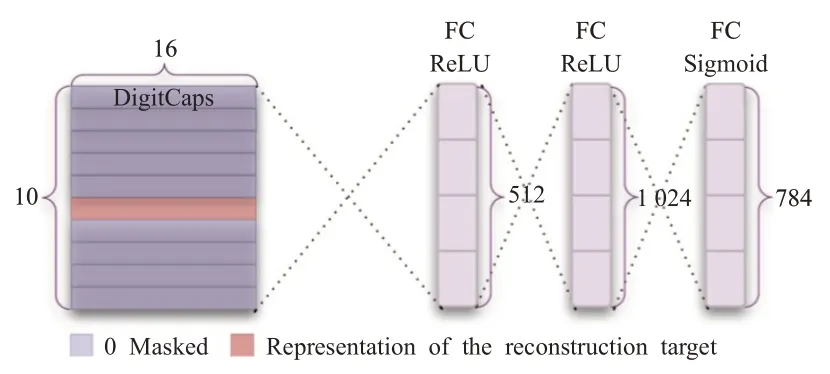
图3 胶囊网络解码器结构图
1.2.3 动态路由算法
上文已介绍过胶囊是一组神经元的集合,它的输出是一个多维向量,因此它可以用来表示实体的一些属性信息,其模长可以用来表示实体出现概率,模长值越大,表示该实体存在可能性越大。若实体的特征位置发生变化,胶囊输出的向量对应的模长不会变化,只改变其方向,实现同变性。
神经胶囊的工作原理如图4 所示[20],可以简单概括为4个步骤,即矩阵转化、输入加权、加权求和以及非线性变换。
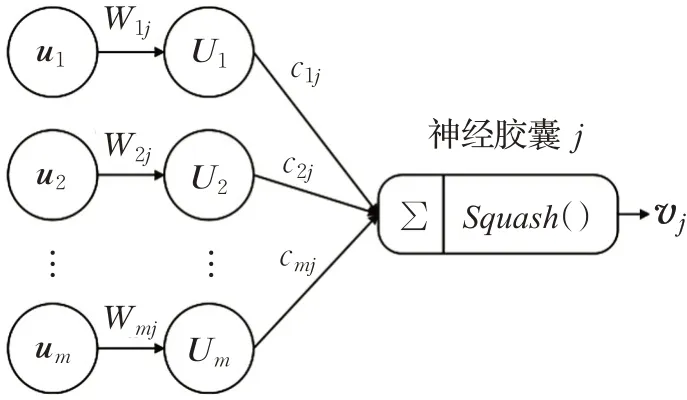
图4 神经胶囊工作过程图
图4 中ui为输入向量,第一步即将此向量与矩阵Wij相乘得到向量Uj,做矩阵转化。ui为输入层图片的低层特征,例如人脸的单个实体部分,比如嘴、鼻子、眼睛等。而Wij包含低层特征和高层特征的空间关系以及其他重要关系,通过矩阵转化操作得到向量Um,即高级特征。


式中,cij表示胶囊i连接至胶囊j的连接概率;bij表示胶囊i连接至胶囊j的先验概率。
cij是由softmax函数计算获得的,softmax函数的结果是非负数,且每个独立的cij相加总和为1,因此c表示概率,softmax函数计算方法如公式(3)所示。

式中,sj表示l层胶囊的总输入。

式中,vj表示l+1 层的胶囊输出。
第四步就是对sj进行非线性变换得到vj,采用激活函数如公式(5)所示,其中公式中第一部分的作用是压缩,如果sj很长,第一项约等于1,反之如果sj很短,第一项约等于0。第二部分的作用是将向量sj单位化,因此第二项的长度为1。此步骤的主要功能就是控制vj的长度不超过1,同时保持vj和sj同方向。经过此步骤,输出向量vj的长度在0~1之间,因此可通过vj的长度确定具有某个特征的概率。
在动态路由第一次迭代过程中,因bij都被初始化为0,耦合系数cij此时都相等,所以l层的胶囊i要传递给l+1 层中的哪个高级胶囊j的概率是平等的。经过这四个工作步骤,最终以的结果来更新bij,经过r次迭代后,输出vj。
动态路由算法伪代码如下:

动态路由算法作为胶囊网络的核心,对于整个胶囊网络的应用起到了决定性的作用。正是胶囊网络使用这种非模板化的算法,使得模型在对图像、文字等目标进行识别时,可以将目标姿态、形状、位置等关键信息进行学习,尽可能多地学习到目标的特征,同时保留重要特征,不轻易丢弃任何一个有用特征。因此,动态路由算法超越CNN 的固有卷积模式,胶囊网络成为当前人工智能领域最先进的技术之一。
2 胶囊网络的应用和优化
2.1 图像识别
计算机的图像识别过程通常分为两大步骤:图像特征提取和图像分类预测。首先对输入图片进行预处理,处理为适合特征提取的形式,然后再提取图像的特征,随后对特征图像进行分类预测,过程如图5所示[21]。

图5 图像识别过程
图像预处理操作的意义主要是为了增强目标图像信息,同时可以减少很多干扰,能够更好地进行图像特征提取。基于深度学习的图像分类方法和传统的图像分类方法相比的关键优势在于,其能通过深层架构自动学习更多深层含义的数据特征,无需人工干预即可找到特征,效果显著地增强了图像分类的效果。目前常用于图像分类的数据集如表3所示,由上至下在数据量和复杂程度上逐渐递增。
2.1.1 CNN和胶囊网络应用对比
为了探究经典CNN模型和胶囊网络识别精度的差异性,Anuradha 等[26]比较了4 种模型AlexNet、VGGNet和GoogleNet 与CapsNet 在扩展MNIST 数据集上的应用,同时展示了胶囊网络在目标检测中的最高精度,并证明胶囊网络只需要少量的数据就可以提供更好的性能。其使用的数据集是扩展MNIST(EMNIST)[27],EMNIST 是一组手写字符数字,从NIST 专用数据库19中提取,并转换为28×28像素的图像格式。此数据集中提供了6 种不同的拆分,它们是ByClass、ByMerge、Balanced、字母、数字和MNIST,EMNIST 语料库的示例如图6 所示[26]。实验中使用了EMNIST Balanced数据集,EMNIST Balanced数据集包含一组字符,每个类具有相同数量的样本。它包含47 个类,131 600 个图像分为112 800个训练图像和18 800个测试图像。
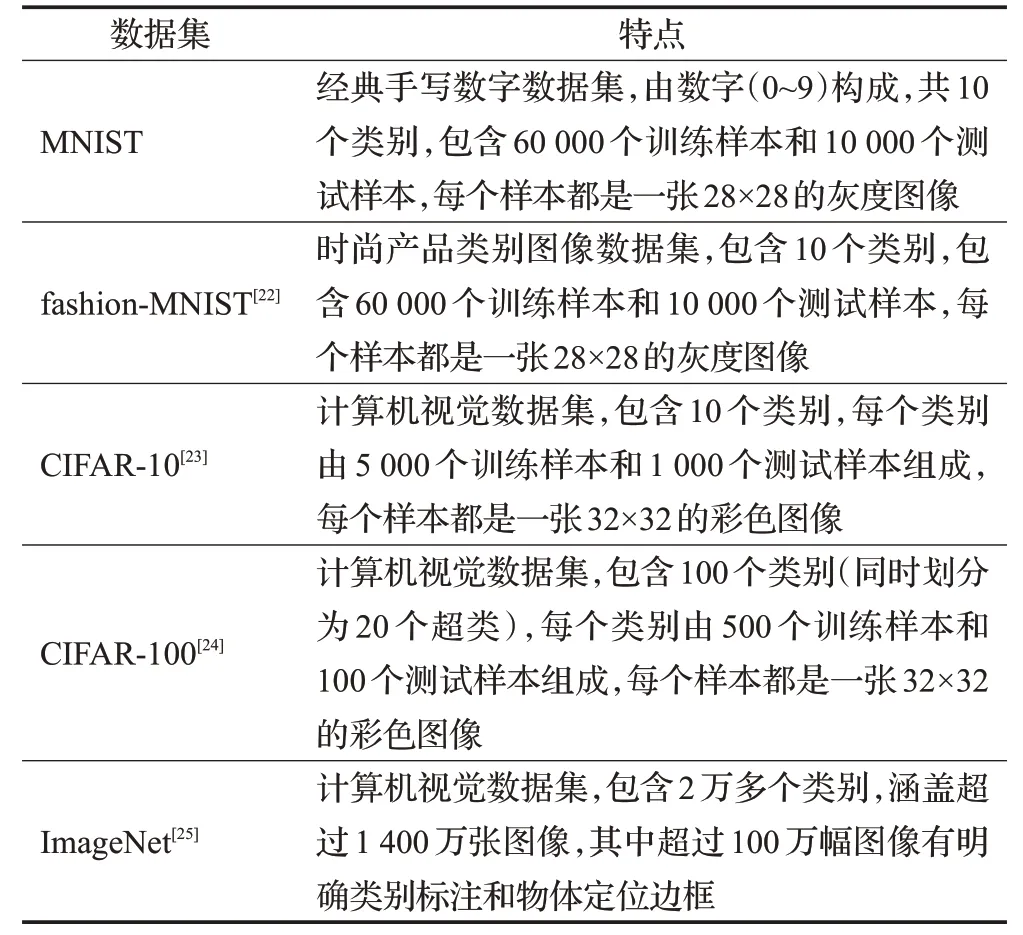
表3 不同数据集的特点

图6 EMNIST语料库
此研究将Balanced EMNIST数据集分为50%、75%和100%分别进行测试,CapsNet在测试结果中的精度分别为95.7%、98.9%、99.7%。研究表明,CapsNet 带来了总体上最好的性能,其准确率超过其他所有模型,在识别图像中得到了较好的效果。
2.1.2 CNN结合胶囊层的应用
通过将现有CNN模型与胶囊网络结构的结合方式可以提升识别精度,Hollósi等[28]选取了VGG、ResNet和DenseNet三种鲁棒性很强的神经网络,通过增加胶囊层的方式来提升神经网络的精度,与未增加胶囊层的原始网络进行精度对比。每个神经网络模型中均使用包含两层胶囊层的相同胶囊块,胶囊块第一层包括256个卷积核,第二层包含10 个胶囊,输出向量为16 维,采用动态路由算法,共有3 条路由。分别使用CIFAR-10 和MNIST 数据集进行测试,两个数据集均进行了一些修改,将图像旋转24°、48°、72°、96°、120°、144°、168°、192°、216°、240°、264°、288°、312°和336°,同时随机翻转图像水平和垂直方向。测试时采用不同的数据集大小,分别为(1 250,250),(2 500,500),(5 000,1 000),(10 000,2 000),(20 000,4 000)和(50 000,10 000),第一个值为训练集的大小,第二个值为测试集大小。经过测试,其中增加了胶囊层的DenseNet网络在CIFAR-10数据集采用的(50 000,10 000)和(20 000,4 000)两种大小方案中,分别由45.27%和36.88%提升至64.02%和59.98%。同时增加了胶囊层的DenseNet网络在MNIST数据集中采用的(20 000,4 000)方案中精度提升最为明显,由58.75%提升至95.35%。实验结果表明,使用修改后的数据集降低了神经网络原本的精度,使用胶囊块可提升精度,采用胶囊单元的网络普遍比传统方法精度更高。采用胶囊层的神经网络,训练速度比原始神经网络快,同时胶囊网络识别旋转物体相比传统CNN 模型更具优势。
2.1.3 小规模数据集应用
以深度学习为代表的人工智能技术正在蓬勃发展,并已应用于很多领域。然而深度学习也有一些局限性:它更适合于大量的数据,与小规模的数据集没有特别的相关性。由此引出的一个问题即深度学习是否适用于小数据训练一直是一个有争议的话题。有学者提出,当数据相对较少时,深度学习的表现并不优于其他传统方法,相反,有时效果甚至比传统方法差。某种程度上,这种说法是正确的:深度学习需要从数据中自动学习特征,通常只有在大量训练数据的情况下才有可能,尤其是对于一些输入样本高维的情况,例如图像。
神经网络使用数据扩充技术可以起到提升准确率的作用,Zhang 等[29]以Kaggle 中的2 000 张“猫vs 狗”比赛的图片作为训练数据集,同时额外选取400张进行测试,根据数据集的特点,对数据集采用了几种预处理技术,包括最大最小范数、调整大小和数据扩充等。使用数据扩充技术后,模型不会发现任何两幅完全相同的图像,这将有助于抑制过度拟合,使模型更具普遍性。最后采用CNN 和CapsNet 对使用了数据扩充技术和未使用数据扩充技术的两种情况分别测试,测试结果如表4所示。不使用数据扩充技术时,CNN 的精度为68%,CapsNet为73%,使用了数据扩充技术时,CNN为76.5%,CapsNet 为81.5%。实验结果表明,CapsNets 在小规模数据集上的性能优于传统的CNN。此外,当不使用扩充技术的训练数据时,CapsNet 的性能明显优于CNN,这个情况表明CapsNet 在数据量相对较小的情况下和CNN 相比具有更好的泛化能力,能够较好地抵抗过拟合,正是胶囊具有同变性的特性,才可以更好地探索特征属性直接的关系,因此这是一个非常重要的优势。
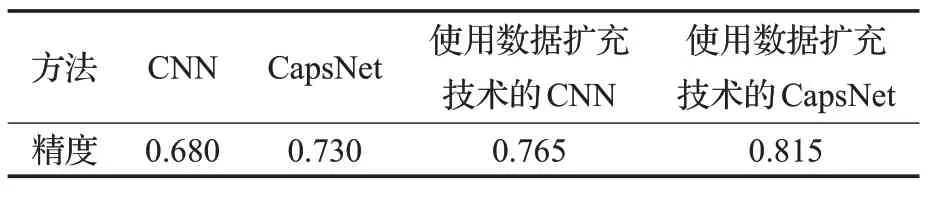
表4 分类精度比较
2.1.4 不同仿射变换的应用
胶囊网络在识别空间位置信息上具有优势,付家慧等[30]从可视化角度研究了胶囊网络在平移、旋转等仿射变换的特征。实验结果的准确性通过三种仿射变换的损失值来表示。最终发现经过600次epoch也没有真正达到收敛,但每个batch 中的100 张图片的总损失函数值能够降低至10 以下,最后得到的生成图像非常接近目标图像。研究表明:在胶囊网络的内部,每个胶囊模块都能够学习到一种姿态,这种姿态适用于大多数的手写数字,同时每个胶囊模块得到的特征姿态均对最终结果存在一定贡献。与卷积神经网络不同的地方在于,胶囊网络在搭建模型时就考虑到位置信息,最终生成结果得到的模块特征输出是从初始位置信息转化而成的,胶囊网络最后确实学到了手写数字图像经过变换的图像信息。因此,胶囊网络对于实体姿态、位置和方向等信息的处理明显优于卷积神经网络。
2.1.5 指静脉识别应用
指静脉识别技术在现代应用中随处可见,CNN 在指静脉识别过程中存在信息丢失的问题,余成波等[31]提出了一种基于胶囊网络的指静脉识别算法。胶囊网络以向量的形式封装指静脉的多维特征,这些特征会被保存在网络中,而不是丢失后再进行恢复。实验采用60 000张图片作为训练集,10 000张图片作为测试集,同时进行图像增强与裁减操作。经过测试,如表5 所示,CapsNets的识别率逐渐增加,在训练次数为30 000时精度达到99.7%,loss值为0.010 7。经过对比,CapsNets展现出了令人惊讶的准确率,在准确率上相比VGG 增加了13.6%,同时loss 值最终收敛到0.01。当CapsNets 迭代到2 000 次的时候,就开始逼近90%的准确率,同时loss值降低至0.2,最终收敛于98.6%的准确率。而VGG迭代比较平稳,迭代200 次时网络精度趋近84%,后期并无太大提升,最终精度为85%,loss值为0.21。
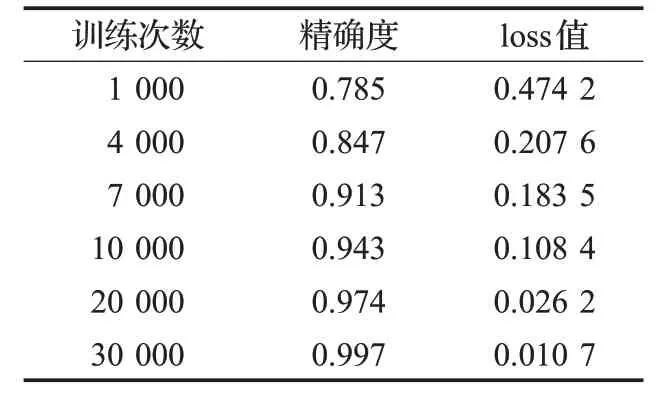
表5 CapsNets训练的识别率和loss值
研究表明CapsNets比CNN更加适合进行指静脉识别,二者对比如表6 所示。胶囊网络结构简单,网络深度远小于VGG,且训练速度非常快,只用了VGG 网络训练时间的1/8,同时其空间特性将静脉的特征保留完整,能够得到非常好的结果。
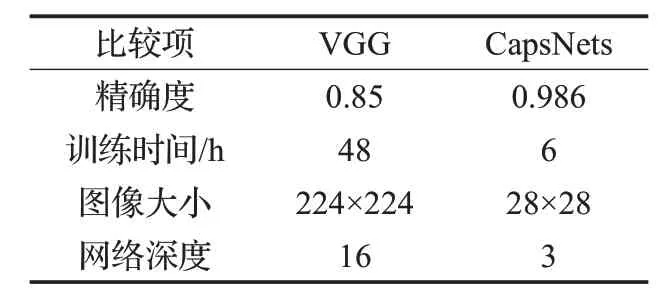
表6 CapsNets与VGG对比
2.1.6 胶囊网络优化方法
为了提高胶囊网络的效率和泛化能力,Zou 等[32]提出了一种新的胶囊网络激活函数exping,同时在损失函数中加入了最小重量损失Wloss。实验采用MNIST 数据集对原始压缩激活函数、exping激活函数和exping加Wloss 进行测试,测试中使用相同的参数。表7 展示了不同方法对手写数字集MNIST 的识别精度,原始压缩激活函数的准确率为99.71%,使用exping 激活函数的准确率为99.72%,使用exping 加Wloss 的准确率为99.75%。此研究表明,经过改进的胶囊网络提高了网络收敛速度,提高了网络泛化能力,提高了网络效率,因此具有很大的使用价值。

表7 不同方法对MINST测试集的识别精度
除了改变激活函数和损失函数的方式,还可以通过改变胶囊层的架构来提升网络的精度。Xiong等[33]通过引入卷积胶囊层(Conv-Caps-Layer),借助现有CNN 深层架构可以提取高维特征的思想,加深了CapsNet的结构,大大提高了性能。同时提出了一种新的池操作——胶囊池(CapsPool),用来减少参数的数量,还能保留功能。实验使用CIFAR-10数据集测试,如表8所示,此研究提出的DeeperCaps模型训练准确率达到96.88%,测试准确率达到81.29%。在MNIST数据集上测试,Deeper-Caps 模型测试准确率达到99.84%。通过添加胶囊池,训练精度和测试精度只降低了1%,但能够显著减少50%的参数数量,大幅节省训练资源。此研究提出的DeeperCaps模型在数据集Cifar10上得到了迄今为止最强的CapsNet结果,Caps池在保持性能的同时减少了层间参数的一半,将CapsNet推向了最先进的CNN架构。

表8 DeeperCaps与Caps-Pool的精度对比%
为了探究影响胶囊网络识别效率的因素,郭宏远等[34]采用了三种优化措施:使用衰变学习率代替恒定学习率、使用Google 提出的Swish 激活函数代替relu 激活函数,以及使用较低的batch size。衰变学习率相较于恒定学习率,其后期收敛效果更好。Swish 激活函数是谷歌提出的一种新型激活函数,其虽与Relu函数类似,但最终性能更加突出。更小的batch size有利于卷积层对于局部特征的捕捉。衰变学习率设置为0.9,batch size采用32 来替代常规的128。实验使用Fashion-MNIST与MNIST 两个数据集进行对比。进行优化前CapsNet在MNIST上测试的错误率为0.36%,而优化后的错误率为0.30%。优化前CapsNet 在Fashion-MNIST 上的错误率为9.40%,优化后的错误率为8.56%。实验结果证明了更小的batch size同样对于胶囊神经网络中的胶囊层具有增强局部特征捕捉能力的效果。
2.2 文本分类
近年来,随着互联网中文本数据的显著增长,文本分类则越来越被人们关注。文本分类是自然语言处理中的一个基本问题,它的目标是自动将文本文档分类到一个或多个预定义类别中,使用户更容易找到所需的信息。因此文本分类在信息抽取、问答、情感分类和语言推理等众多应用中起着至关重要的作用。受深度神经网络在计算机视觉和自然语言处理领域巨大进步的推动,深度学习算法如卷积神经网络和长短时记忆网络已成为主流文本分类方法。以往的文本分类方法在提供大量标注训练数据的情况下能够取得显著的效果,然而这种性能依赖于训练数据和测试数据来自同一数据分布的假设很难将学习到的文本分类模型推广到新的领域并应用。在推理过程中,人类视觉系统会智能地将部分分配给整体,而不必硬编码与透视相关的模式[35]。因此,胶囊网络具备捕捉局部和整体之间的内在空间关系的特性可以构成视点不变的知识,并自动推广到新的视点。这种部分和整体的关系在自然语言中称为语义合成,词组和句子意义的分析是基于语义组合原则的。胶囊可以是一组神经元,其活动向量代表特定语义特征的实例化参数,因此胶囊网络可以用于文本分类。
2.2.1 静态路由和动态路由的应用
Kim等[36]提出一种简单的路由方法,称之为静态路由,使用这种方式成功降低了动态路由计算复杂度,同时提高了分类精度。通过7种基准数据集对5种不同的网络结构进行测试,使用静态路由方式的精度普遍高于动态路由0.1%~6%不等。同时,他们提出使用ELU 门传递信息,无论在哪种路由情况下,精度都是最高的。在文本分类方面,CapsNet 优于CNN,能够达到更好的效果。
Yang 等[37]研究了用于文本分类的动态路由胶囊网络,提出了三种策略来减少噪音胶囊的干扰。他们使用一个主要由N-gram 卷积层、初级胶囊层、卷积胶囊层和全连接胶囊层组成的模型。通过6 个不同的分类基准数据集对11种网络结构进行测试,胶囊网络在6个数据集中的其中4 个达到了所有网络结构中的最好效果。同时,在其余两个数据集中,胶囊网络的结果处于中上等水平。通过对比,胶囊网络在文本分类时明显优于CNN,在将单标签文本分类转换为多标签文本分类时,也具备显著的优势。
2.2.2 评论识别和情绪分析的应用
在当今时代,网络中具有攻击性和负面的评论非常常见。Srivastava 等[38]提出了一种单模型胶囊网络用来在评论中识别具有攻击性的评论,他们的模型分为4层:文字嵌入层、特征提取层、胶囊层和卷积胶囊层,同时使用焦点损失代替标准的交叉熵损失函数。胶囊网络可利用动态路由的过程来减轻一些噪声胶囊干扰,焦点损失可以防止在训练中大量简单的负样本对检测器造成的严重影响。通过3 种数据集对11 种神经网络模型测试,这种单模型胶囊网络在每个数据集中的表现都是最优的,达到了这些模型中最高的精度,特别在ROCAUC 数据集的测试结果中,他们的模型用于文本分类的准确率高达98.46%。胶囊网络以其独有的特性在评论识别中达到了非常好的效果。
一篇关于情绪分析的研究文章[39]将递归神经网络与胶囊式网络结合进行情绪分析。研究者为一个特定的情绪类别设计了一个胶囊,例如“积极”和“消极”。胶囊由状态、属性和3 个模块(表示、概率、重构)组成,表示模块通过注意机制构建胶囊表示,模型中使用的胶囊结构能够模拟情绪,并且无需任何语言知识模型即可输出情感倾向。通过基准数据集Movie Review and Stanford Sentiment Treebank,以及专有数据集Hospital Feedback对12种神经网络模型进行测试,他们提出的RNN-Capsule模型在众多网络模型中脱颖而出,达到了非常理想的效果,尤其在情感分类方面高达91.6%的准确率,达到了目前为止最先进的性能。
2.2.3 动态路由和压缩函数的优化
为了更好地保留文本特征,增加特征多样性,验证动态路由迭代次数和压缩函数对模型的影响,沈炜域等[40]构建包含多尺寸多层卷积的胶囊网络和自注意力网络的CapSA模型验证模型效果。实验使用Headlines和Review Sentiment数据集测试,结果如表9所示,仅限制迭代轮数为5 轮时,CapSA 模型在第2 轮路由迭代能够得到较好的分类效果,后续增加的迭代次数并没有使得效果提升。模型如果达到理想的收敛状态,需要更多的路由迭代次数,亦需要非常多的数据迭代才能达成,会造成更大的计算代价。
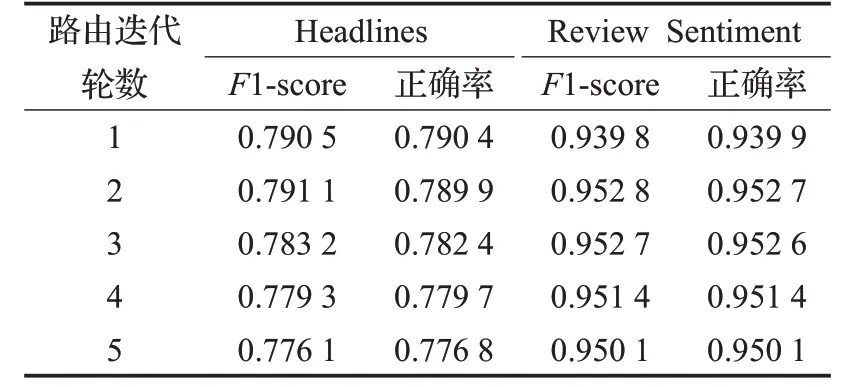
表9 CapSA在两种数据集上不同迭代轮数的F1与正确率
CapSA 模型上还尝试了4 种不同的压缩方案。方案1是,方案2是方案3 是,方案4 是在路由迭代中使用,进行最后一轮迭代输出时使用。对比4 种方案的训练损失变化,结果为方案2的损失下降速度是最快的,其收敛效果也达到最好。研究表明不同的动态路由迭代轮数对模型的收敛效果非常敏感,适当的向量压缩方案同样会影响效果。
2.3 小结
胶囊网络有很多优势,朱应钊等[20]提出胶囊网络具有3个优势特性。第一点即所需训练数据量较少,神经胶囊的引入,能够保留输入对象的详细属性信息。其中属性信息中包含了输入对象的姿态、位置、大小、旋转等信息,胶囊网络能够将学习到的东西推广到新场景中。因此,对发生平移、旋转、缩放等操作的同一对象依然可以识别正确,同时还能从不同角度进行识别。所需要的训练数据量少的优势,使得胶囊网络更接近人脑。第二点即不易受多类别重叠的干扰,胶囊网络有能力处理对象重叠的复杂场景,通过每一个特定部分的属性和存在预测高级对象的属性和存在,同时对比预测结果之间的一致性,若达成一致则增加路由权重,不一致则减少路由权重。因此,一个胶囊的输出只需路由到下一层对应的胶囊中,即下一层的胶囊能获取更清晰的输入信号,将多类别重叠的模糊性进行转换,从而实现对重叠对象的识别和预测。第三个优势即胶囊网络抵御白盒对抗性攻击能力较强。因深度学习的各种网络模型在各个领域广泛使用,其防御对抗性攻击的能力备受大家关注。经过研究,发现胶囊网络有着较强的抵御能力,尤其是对于白盒的对抗性攻击,相比卷积神经网络,胶囊网络则在这一方面更加出色。一种典型的白盒对抗性攻击的方法FGSM发挥作用时,卷积神经网络的准确率会断崖式下降至20%以下,与此同时胶囊网络却能够持续保持70%以上的准确率。胶囊网络的优势突出、应用广泛,本文主要列举图像识别和文本分类两大方面的应用和优化,如表10、表11所示。
3 结束语
胶囊网络在很多领域的应用都展现出其独特的鲁棒性,无论是图像识别领域还是文本分类领域,不管是直接使用胶囊网络结构还是改变现有结构的网络将胶囊层加入其中,都呈现出了令人惊讶的效果。在现有CNN结构中加入胶囊层提升精度的同时还能够提升训练速度,对于小数据集的应用,胶囊网络的泛化能力非常强。胶囊网络在处理空间信息中具有明显的优势,能够将空间特征保留完整,善于处理实体位置、姿态以及方向信息,且网络结构浅、训练速度快、空间特征保留完整。即使网络迭代前期能够达到一个不错的准确率,但是网络迭代后期仍然能够平稳提升准确率并降低loss值,达到更好的效果。不同的激活函数能够提升胶囊网络的泛化能力、收敛速度,改变胶囊层架构、batch size、学习率等也能优化胶囊网络的效果。动态路由迭代次数也是影响准确率的因素之一,适当的迭代次数能够使得网络性能达到最理想的状态。胶囊网络有能力处理对象重叠的复杂场景,这也是其在众多神经网络模型中脱颖而出的其中一个原因。同时,胶囊网络对于白盒的对抗性攻击还有着较强的抵御能力,这种抵御能力远超卷积神经网络。因此,胶囊网络具有很大的潜力,还需要进行探索。
尽管研究者在深度学习的交叉领域已取得了诸多胶囊网络的相关成果,但是胶囊网络的发展并不完善,在某些方面仍然受到现有技术制约,存在很多问题需要研究者去解决。因此,未来可以在以下方面增强胶囊网络的识别能力,从而提升胶囊网络的性能。
(1)提高识别速度
现代深度学习模型的识别速度很大程度上影响模型的整体性能,在胶囊网络的动态路由算法中,对于目标特征的每个位置都被准确地以向量形式封装在胶囊里。因此动态路由算法内部的迭代耗时长,迭代次数多,大大降低识别效率。尽管准确率比诸多深度学习模型都要优异,但识别速度还有很大的提升空间。胶囊网络不光可以采用向量形式表示,也可以采用矩阵进行表示。矩阵可减少大量的参数,同时降低计算量,提高计算速度。此表示方式在以后的研究中可作为一个重点突破的方向,其对胶囊网络提高识别速度具有重大意义。同时,GPU集群技术使用的越来越普遍,虽然一定程度上提升了计算能力,但仍然不足以满足胶囊网络需要的强大大计算能力。因此,未来的研究方向可以着手于降低网络参数、提升GPU计算能力、提升动态路由算法效率等方向来提升胶囊网络的识别速度。
(2)优化网络结构
胶囊网络在识别MNIST手写数据集上表现极其优异,精度趋近于100%,但由于手写数字为28×28的灰度图像,规模较小,内容较简单,特征较明显,因此胶囊网络在小规模的图像处理中几乎具有最好的性能,但是在大规模的图像处理过程上仍然有待提高。目前胶囊网络的网络结构很浅,和众多典型CNN 网络结构构成了鲜明的对比。未来可以通过适当加深网络结构,探索适合识别大规模图像的网络结构进行研究,以此打造一个可以识别不同规模大小的网络结构,进一步优化网络处理过程,获得更出色的效果。

表10 胶囊网络的应用总结
(3)优化压缩函数
压缩函数在胶囊网络结构中发挥非常重要的作用,不同的压缩方案效果不同。在胶囊网络原始的压缩函数中,参数中常数值的改变对损失值、精度能够造成很大的影响。因此,未来在提升胶囊网络性能时,可探索其他不同的压缩函数,试验每种压缩函数的效果,寻求一个能够提升现有性能的压缩函数,同时搭配合适的网络结构以及优化过的路由算法。探究更加合适的压缩函数将会对胶囊网络的性能带来突破,同时对胶囊网络的发展也具有重大意义,如何界定一个合适的压缩方案将成为一个很重要的研究内容,将作为日后胶囊网络的研究重点。
(4)优化损失函数
胶囊网络采用了间隔损失的方式作为损失函数,因其可对多个目标进行分类,所以不再采用传统交叉熵函数的方式。适当的损失函数可减少负面信息对模型的不良影响,能够尽快地将预测结果与真实结果靠近,达到训练模型的预期目的。损失函数对模型的性能具备一定程度上的影响,目前可以将损失函数作为胶囊网络的主要改变方向,损失函数不光对胶囊网络具有重要意义,也对整个神经网络的改进与优化存在非常重要的作用。
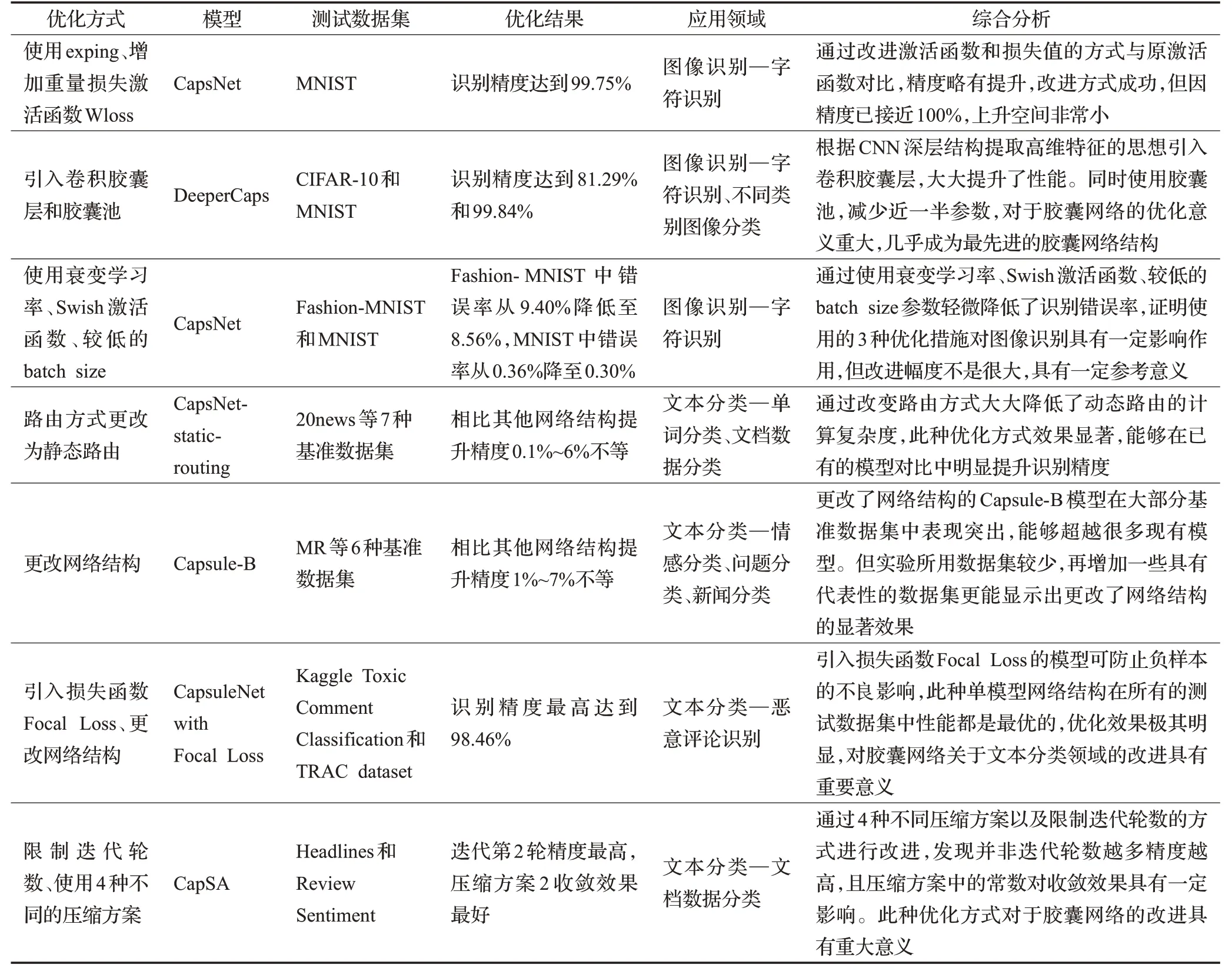
表11 胶囊网络的优化总结
当前人工神经网络应用广泛,未来在信息处理、模式识别、医学影像、生物信号、市场价格预测、风险评估、交通模式分析、车辆检测与分类、教育,甚至心理学等领域都可以有显著进步。目前的应用处于人工神经网络的应用初始阶段,较为简单,经过探索已经有很多成熟的经典模型用于社会发展中。但正是人工神经网络模拟人脑的特点,给科学发展带来了无限可能。经过发展,未来的人工神经网络会应用在生活的方方面面,人们的生活会更便捷,例如无人驾驶汽车的普及、公安系统对公民信息的查询以及录入,公司内部的员工打卡系统,甚至商场里每一个商家手里的门店钥匙,都会迎来质的飞跃,变成不一样的形式伴随着社会发展。根据现已应用的模型进行改进,融合胶囊网络的优势,能够在目前的研究中实现更进一步的发展。因此,探索胶囊网络应用的优势领域是一个有待发展的研究课题,通过探索不断完善胶囊网络的性能,能够极大推进人工智能技术进步。当前对胶囊网络的探索研究仍然具有广阔的发展空间,仍然需要更进一步地探索胶囊网络更深层的意义。
