支持差分隐私的图像数据挖掘方法研究
2021-02-04杨云鹿周亚建
杨云鹿,周亚建,宁 华
(1.中国信息通信研究院移动应用创新与治理技术工业和信息化部重点实验室,北京100191;2.北京邮电大学网络空间安全学院,北京100876)
引 言
随着大数据与计算机视觉技术的广泛应用,语义丰富的图像背后蕴藏的巨大价值得以挖掘,同时也带来了不容小觑的隐私泄漏问题[1]。若直接发布或使用语义丰富的图像,有可能会造成严重的隐私信息泄露。因此,如何在数据挖掘的应用中实现图像数据安全性与可用性之间的平衡日益成为重要的研究方向[2-3]。
近年来,深度学习在计算机视觉、图像处理、目标检测等领域成效卓然,备受国内外研究者的关注。深度学习是用于分析大规模数据集的代表性数据挖掘方法,通常需要大量的训练样本才能达到预期的效果。但是,在某些领域中,例如医疗、军事和旅游等,无法获得足量满足需求的样本数据。针对这个问题,Goodfellow 等[4]提出了一个通过对抗过程估计生成模型的深度学习框架,即生成对抗网络(Generative adversarial networks,GAN)。GAN 通过学习一组训练样本中的数据分布,可以从分布中进行采样并生成更多的具有同样分布的样本,以增加原始数据集的规模。在此基础上,GAN 及其变体结合了深度神经网络和博弈论的复杂性,生成了难以与原始数据区分的高质量“假”样本数据。
GAN 虽然拥有出色的性能,但它也同样存在着泄漏训练样本隐私信息的风险[4]。在深度神经网络中,对抗性的训练过程和高度复杂的模型结构共同作用生成了基于训练样本的数据分布。由于深度神经网络模型的高度复杂性,GAN 可以轻松地记住训练样本。如果对生成的数据分布进行反复采样,训练的原始样本有极大的概率可以被恢复。例如Hitaj 等[5]提出了一种主动推理攻击模型,该模型可以从生成的“假”样本中重建训练样本。因此,GAN 在隐私图像数据的应用不仅是通过使用高质量的“假”数据生成模型向公众或个人发布“假”数据,还应考虑使用隐私保护技术以减轻GAN 的隐私泄漏。
为了解决上述问题,研究者们提出了多种隐私保护模型及方法[6]。Papernot 等[7]提出了教师模型全体的隐私聚合(Private aggregation of teacher ensembles,PATE),该方法包含多个使用隐私数据训练的教师模型和一个基于GAN 模型的学生模型,教师模型结合差分隐私对GAN 评分以生成最优的学生模型。PATE 仅使用学生模型进行预测,不公布教师模型,从而保护训练数据集。但是,GAN 模型训练过程是不透明的,PATE 隐私保护机制的可控性较弱。Abadi 等[8]于2016 年提出了时刻统计(Moments accountant),该方法在随机梯度下降中引入差分隐私,可以在神经网络的训练中执行适当的隐私保护。在时刻统计的基础上,Zhang 等[9]提出了在数据训练阶段引入差分隐私的生成对抗网络模型(differential privacy-GAN,dp-GAN),通过将噪声注入神经网络的权重以缓解GAN 的信息泄漏。然而,该模型在训练中每次引入参数的“梯度”中的噪声大小都和隐私预算与训练时期的数量成正比。因此,在实际应用中,模型可能会消耗大部分不必要的隐私预算,以这种方式将差分隐私与GAN 结合会对训练GAN 模型的稳定性和可伸缩性产生重大影响。此外,由于数据的语义丰富,并且缺乏有关分析任务的先验知识,引入过多的噪声以确保隐私,导致了生成数据的可用性被大幅度减弱。因此,数据挖掘领域亟需一种既可以保护隐私信息又可以产生高质量图像的生成模型。
鉴于此,本文针对生成对抗网络隐私保护过程的不透明性以及隐私预算消耗量过大的问题,提出了一种支持图像数据差分隐私保护的生成对抗网络模型(Image differential privacy-GAN,IDP-GAN),采用在训练过程中引入差分隐私的方法,将拉普拉斯噪声合理地分配到判别器的放射变层和损失函数中,以提高GAN 的隐私性。更重要的是,不同于dp-GAN,IDP-GAN 在训练过程中仅单次引入噪声,有效减少了隐私预算的消耗,在实现差分隐私保护的同时,提高了生成图像的使用精度。
本文的主要贡献如下:
(1)结合差分隐私技术与生成对抗网络模型,提出一种更具普适性的支持图像隐私保护的数据挖掘模型。模型在保护原始数据隐私的同时,不仅可以产生高质量生成图像,而且具有较好的抗攻击能力。
(2)模型在判别器的仿射变换层和损失函数中均以单次引入拉普拉斯噪声的方式实现差分隐私,能够减少模型训练过程中隐私预算的消耗,显著提高了模型对于大规模图像数据集的可用性。
(3)不同于将模型训练过程视作黑盒的隐私保护机制,IDP-GAN 的隐私保护机制是透明且可控的,根据不同复杂度的数据集,合理分配隐私预算,可以生成更清晰、质量更好的图像。
1 相关技术概述
本节主要介绍差分隐私和生成对抗网络模型的背景知识,以及用于隐私预算分配的层级相关性传播方法。
1.1 差分隐私
差分隐私是由Dwork 等[10]提出的基于严格数学理论的隐私保护模型。差分隐私主要通过添加噪声来对原始数据的变换或统计结果进行扰动,从而达到保护隐私的效果,且不会影响整体数据的分析结果。差分隐私技术的主要优点在于其具有较高的普适性及可解释性。
1.1.1 差分隐私定义
定义1[11]存在两个相邻数据集D 和D′,两者的区别在于至多只有一条数据不同,用Range(M)表示随机算法M 的取值范围,用Pr[E]表示事件E 的泄露风险,若随机算法M 在数据集上的取值结果S∈Range(M),满足不等式

则算法M 满足ε-差分隐私。参数ε 表示隐私保护预算,其值越小隐私保护程度越高。
1.1.2 差分隐私实现机制
差分隐私的常用实现机制[11]包括拉普拉斯机制和指数机制。根据图像数据的特性,本文选取拉普拉斯机制在生成对抗网络模型上实现差分隐私。
(1)拉普拉斯机制
给定一个映射函数f:Dn→Rd,表示数据集D 到一个d 维空间的映射关系,并且ε >0。在函数f(D)上加入拉普拉斯噪声,得到输出函数A 为
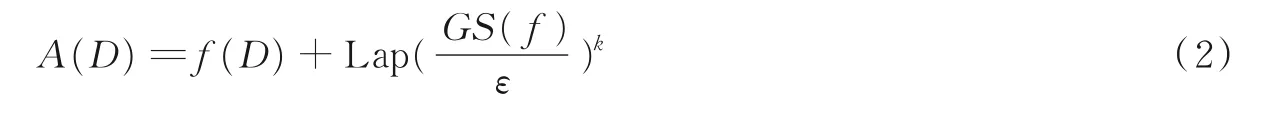
(2)敏感度
在拉普拉斯机制中,敏感度是影响隐私保护强度的一个重要因素,其定义如下。
定义2[10]若给定查询函数f,f(D)∈Range(f),f(D)表示查询函数f 在数据集D 上的查询结果,Range(f)表示f 的查询结果取值范围,则函数的敏感度值为

式中D,D′为类似于差分隐私定义中的相邻数据集。
(3)隐私预算与敏感度
差分隐私预算ε 与敏感度的关系定理如下。
定理1[12]给定函数集F,其敏感度为S(F),K 表示向F 的输出结果添加独立噪声的算法,若添加的噪声满足取值为S(F)/ ε 的拉普拉斯分布,则算法K 满足ε-差分隐私。
1.2 生成对抗网络
GAN[13]是一种无监督的深度学习算法,其体系结构通常包括两个模块:生成器G 和判别器D。G的目标是通过学习从一个潜在分布pz到真实数据分布pdata的映射,生成尽可能看似来自pdata的假样本来“欺骗”判别器D;而D 的目标是区分虚假样本和真实样本之间的区别。由于G 与D 两者的目标相反,故GAN 的训练可以看作是一个博弈过程。在博弈过程中,算法分别依次优化D 与G,直到两者收敛。因此,整体优化目标函数可写为

尽管GAN 结构简单,但是最初版本的GAN 既不稳定,训练效率也不高。在GAN 的后续研究工作中,新的训练机制和网络模型被提出,以不断地提高训练的稳定性和收敛速度。例如,Martin 等[14]提出的沃塞斯坦对抗性网络(Wasserstein GAN,WGAN)和改进的WGAN 训练机制解决了原始GAN 存在的训练效率低下与模式坍缩的问题。不同于原始GAN 的目标函数最小化真实分布与生成分布之间的JS-散度(Jensen-Shannon),WGAN 通过Wasserstein 距离来衡量两个分布之间的差异,并采用了一种梯度惩罚技术来限制判决器的Lipschitz 条件,使目标函数变为

若无特别声明,本文中使用的生成对抗网络模型均指改进的WGAN。
2 模型的设计与实现
本文设计的支持图像差分隐私保护的生成对抗网络模型(IDP-GAN)的重点在于生成对抗网络结构中噪声添加位置的选取和隐私预算的分配,下面阐述模型的设计思路和实现过程。
2.1 拉普拉斯噪声添加位置
本文选取GAN 结构中的判别器D 作为噪声机制添加的位置。因为在生成对抗网络中,只有判别器D 能够接触到真实的数据,对判别器D 扰动足以控制GAN 生成数据的隐私。此外,不同于生成器G的复杂网络结构,判别器D 仅需要较简单的网络结构和较少的参数,这样更容易计算隐私损失。更重要的是,根据差分隐私的后处理性,对判别器D 实现差分隐私,生成器G 的参数也同样满足差分隐私保护,且对差分隐私输出的任何计算不会增加隐私损失(计算是指对生成器参数的计算,输出指判别器输出的差分隐私保护参数)。
2.2 差分隐私生成对抗网络的构建
IDP-GAN 的设计核心在于构建差分隐私生成对抗网络,其关键步骤包括差分隐私神经网络的构建以及差分隐私损失函数的构造,均以单次引入噪声实现差分隐私,减少隐私损失。
2.2.1 差分隐私神经网络的构建
本文通过将拉普拉斯噪声加入输入特征,以构建差分隐私神经网络。这里的输入特征指的是生成对抗网络判别器中神经网络的仿射变换层的特征。
首先,生成对抗网络的判别器中神经网络的仿射变换层可表示为

式中:b 为静态偏差,W 为h 的参数。在经过L 批次训练后,仿射变换可表示为

得到单个神经元hL(W)的表示后,通过将隐私预算为ε1拉普拉斯噪声注入每个神经元hL(W) ∈h0的和输入特征xi和偏差b,来扰动仿射变换层h0。拉普拉斯噪声分布为扰动后的输入特征和偏差分别表示为给定随机训练批次L,扰动后的差分隐私仿射变换层记为其中每个隐藏神经元表示为
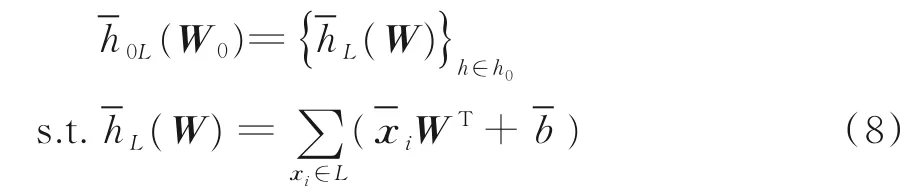
然后,将隐藏层{h1,…,hk}堆叠在差分隐私仿射变换层以构成差分隐私深度神经网络,如图1 所示。

图1 差分隐私神经网络的示例Fig.1 An instance of differentially private neural networks
2.2.2 差分隐私损失函数的构造
差分隐私神经网络的输出层产生预测标签Y。由于预测标签yi与原始数据集具有相同的隐私性,因此在输出层也需要实现差分隐私以保护标签yi。首先,基于泰勒展开(Taylor expansion)[15]对损失函数的多项式近似进行推导。然后,将拉普拉斯噪声注入损失函数FL(θ)的系数中,以在每个训练批次L上实现差分隐私。

本文以应用最广的交叉熵损失函数[16]为例进行多项式推导,也可以选取均方误差等其他损失函数。整个神经网络模型的交叉熵损失函数的计算过程如下。

基于泰勒展开,FL(θ)的多项式近似可表示为

式中:∀l ∈[1,M]:f1l(z) =yillog(1+e-z),且f2l(z)= (1-yil)log(1+ez)。
为了实现差分隐私保护,本文对泰勒展式的每项系数插入拉普拉斯噪声,从而达到扰动损失函数的目的。因此,将yil对应的泰勒展式系数定义为给定隐私预算为ε2,则加入的拉普拉斯噪声为然后,将扰动后的系数和损失函数分别表示为和这样扰动后的损失函数就无法直接接触原始的预测标签。
2.2.3 隐私损失的计算
在IDP-GAN 的差分隐私实现机制中,在访问原始数据的每个计算任务中都会执行差分隐私保护。但是,拉普拉斯噪声仅需要被单次注入到IDP-GAN 模型中,作为预处理步骤在放射变换层和损失函数中实现差分隐私。此后,训练阶段将不再访问原始数据,隐私预算消耗不会在每个训练步骤中累积。因此,隐私预算消耗与训练时期的数量无关,总隐私预算ε=ε1+ε2。
2.3 模型的实现
根据上文的支持图数据差分隐私保护的生成对抗网络模型(IDP-GAN)设计思想及流程分析,本节给出IDP-GAN 模型的伪代码(如算法1 所示)。在介绍具体实现过程之前,先介绍在IDP-GAN 模型构造中用到的符号表示。模型的损失函数记为F(θ),这里的θ 表示参数。模型随机训练T 批次,每次训练批次L,批次L 是D 中具有预定批次大小|L|的训练样本的随机集合。最后使用Adam 算法优化损失函数。
算法1IDP-GAN
输入:图数据集D;隐藏层H;损失函数F(θ) ;隐私预算ε1和ε2;Adam 超参数α, β1和β2;判别器的训练迭代次数T;随机训练批次大小|L|;学习率ηt;随机噪声分布pz。
输出:差分隐私生成器G。
(1) 初始化θ0
(2) For t∈|T|, l ∈|L| do,xi~D, z~pz
(12) ε ←ε1+ε2//计算隐私损失
(13) Return 差分隐私生成器G
3 实验结果及分析
通过实验对比及统计的实验数据,从不同角度分析了支持图数据差分隐私保护的生成对抗网络模型(IDP-GAN)的有效性。
3.1 实验环境及数据集介绍
本文在两个标准数据集(MNIST 数据集[17]和CelebA 数据集[18])上进行了大量的实验,通过评估IDP-GAN 生成数据的质量和隐私级别,验证的IDP-GAN 性能。
MNIST 数据集由大小为28 像素×28 像素的手写数字图像组成,分为60 KB 和10 KB 测试样本;CelebA 数据集包含20 万名人的脸部图像大小为48 像素×48 像素,每个图像有40 个属性注释。
本文分别将MNIST 和CelebA 数据集的训练数据(如果不考虑标签信息,则训练数据为整个数据集)按照2∶98 的比例分为公有数据集Dpub和隐私数据集Dpri。
实验环境为Ubuntu 16.04.5 LTS 操作系统,GTX 1080 Ti 和NVIDIA TESLA K40C 两块显卡,实验利用TensorFlow 版本1.9.0 和Keras 版本2.2.0的框架,以及Python 版本3.6.5 实现。
本文使用Leaky ReLUs 作为鉴别器上的激活函数,并使用ReLU 作为生成器上的激活函数,因此激活函数导数的界限Bσ′≤1。在生成器和判别器的权重上加入L2-regularization,以在学习过程中降低模型复杂度和不稳定程度,IDP-GAN 超参数设置如表1 所示。

表1 IDP-GAN 模型的超参数设置Table 1 Hyperparameter of IDP-GAN
3.2 性能指标
3.2.1 Inception score
Salimans 等[19]提出了用Inception score 来衡量GAN 生成数据的质量。理论上,生成器G 的Inception score 定义为
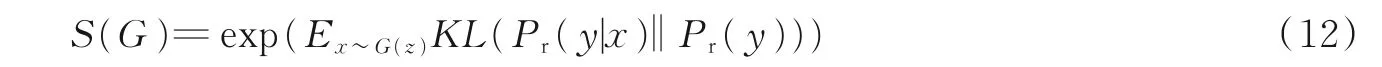
式中:x 为由G 生成的样本,而Pr(y | x)为预先训练的分类器的条件分布,用于预测x 的标签y。如果x与真实样本相似,则期望Pr(y |x)的熵很小。Pr(y)是y 的边缘分布。如果G 能够生成一组不同的样本,则期望Pr(y)的熵很大。因此,通过测量两个分布的KL-散度(KL-divergence),S(G)可以评估生产数据的质量和多样性。对于MNIST 和CelebA 数据集,使用完整的训练集来训练基线分类器以估算Pr(y |x),调整分类器以在验证集上评估性能。简而言之,Inception score 的值越大,表示生成模型生成图像的质量和多样性就越高。
3.2.2 推理攻击的精度
为评估IDP-GAN 的隐私级别,本文通过成员推理攻击[20]来衡量将生成图像用于训练模型会造成的成员泄露风险。当攻击者获得某项记录并且该记录已用于训练特定模型,则表明该模型存在信息泄漏的风险,且推理攻击的精度越低,隐私的级别越高。
3.3 相关实验及结果分析
在本文的实验中,以在随机梯度下降的计算中添加相同噪声的dp-GAN[9]作为对比模型进行IDPGAN 模型的性能测试。
3.3.1 隐私级别与生成图像质量的关系
为验证隐私级别与IDP-GAN 的输出图像质量之间的关系,在MNIST 和CelebA 数据集上进行了大量的实验。在这些实验中,根据dp-GAN 中隐私预算的选择,在实验中选择一些相对较大隐私预算的(范围从0.3 到11)来评估IDP-GAN 的性能,对应于3 个不同的ε 值,IDP-GAN 生成的图像分别如图2 和图3 所示。

图2 基于MNIST 的3 种不同ε 的生成图像样例Fig.2 Synthetic samples with three different ε on MNIST dataset

图3 基于CelebA 的3 种不同ε 的生成图像样例Fig.3 Synthetic samples with three different ε on CelebA dataset
实验结果表明,IDP-GAN 可以生成视觉上清晰的图像,图像的失真是由注入的噪声造成的而不是因为训练图像的质量问题。将生成的图像与其相邻图像进行对比,可以明显地看到,IDP-GAN 不仅是为了学习训练样本,而且还能够生成具有独特细节的图像。更重要的是,图2 和图3 中生成的图像显示,当所有其他条件都相同时,噪声的方差越大,生成图像的模糊性就越大。在IDP-GAN 中,任何获得合成图像的使用者几乎都无法知道训练过程中是否涉及某个数据,在这种情况下无法重建训练图像,因此可以保护原始数据的隐私。尽管噪声减小会提高生成图像的质量,但模型的安全性通常也会减小。因此,选择一个合理的ε(添加更少的噪声),能够避免对生成的数据造成太大影响。这也表明IDPGAN 成功解决了前文提到的隐私问题,并且在较大范围内调整隐私级别ε 可以确保生成图像的高质量。
3.3.2 生成图像的质量评估
下面通过实验,根据Inception score 将生成数据与真实数据进行比较,对IDP-GAN 生成图像的质量进行评估,使用完整的训练集来训练基线分类器以估算Pr(y | x),调整分类器以在验证集上评估性能。Inception score 的值越大,表示生成模型具有生成更高质量且具备多样性的图像的能力。
为了评估IDP-GAN 生成图像的质量,通过在MNIST 和CelebA 数据集上进行实验并与dp-GAN 和无隐私保护的WGAN 进行对比。图4 比较了具有不同隐私预算条件下3 种生成模型的生成图像和真实图像的Inception score。根据Inception score 的统计特性,从图4 可以看出,IDP-GAN 生成图像的质量优于dp-GAN。
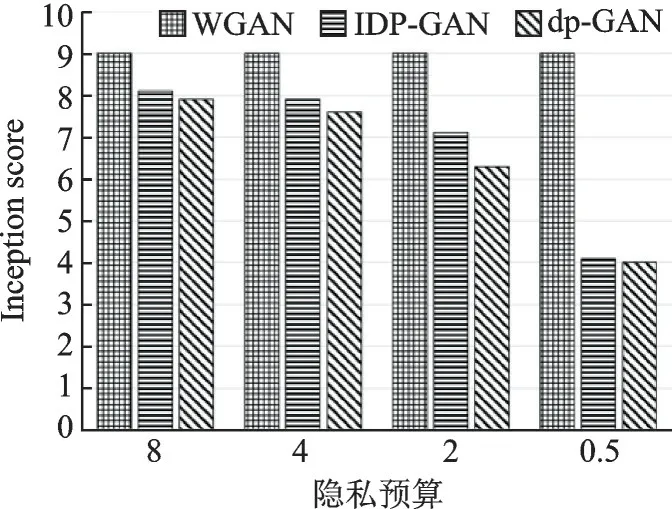
图4 3 种生成模型的Inception score 对比Fig.4 Inception scores comparison of three generative models
3.3.3 隐私级别的评估
为评估IDP-GAN 的隐私级别,通过成员推理攻击来衡量将生成图像用于训练模型会造成的成员泄露风险。当攻击者获得某项记录并且该记录已用于训练特定模型时,则表明该模型存在隐私泄漏的风险。在攻击实验中,使用CelebA 数据集验证隐私预算对攻击准确性的影响。图5 显示了在IDPGAN 中使用不同隐私预算和不同规模的数据集训练时,实现成员推理攻击的精度。
从图5 可以看出,数据集的大小和隐私预算的大小均与攻击精度成正相关。隐私预算越小,攻击精度就越低。在差分隐私理论中,隐私预算反映了隐私保护的程度,值越小说明隐私保护程度越高,当隐私预算设2 时,即使有大规模的数据集,攻击精度最高也仅为0.52。因此在隐私预算较小时,攻击者无法准确地推断出目标模型的分布,从而证明IDP-GAN 可以缓解生成模型的信息泄漏。
为进一步评估IDP-GAN 的隐私性,本文将IDP-GAN 与dp-GAN 和WGAN(无隐私保护)这两种现有解决方案下CelebA 数据集实现成员推理攻击的精度进行比较。图6 显示了在不同解决方案下CelebA 数据集实现成员推理攻击的精度。从图6 可以观察到,IDP-GAN 抵御成员推理攻击的能力优于dp-GAN 和WGAN。

图5 基于不同大小的CelebA 数据集在不同的隐私预算下实现推理攻击的精度Fig.5 Precision of the inference attack for CelebA dataset with different sizes of datasets

图6 不同解决方案下CelebA 数据集实现推理攻击的精度Fig.6 Precision of the inference attack for CelebA dataset under different solutions
4 结束语
本文立足于研究数据挖掘过程中隐私保护强度与数据可用性之间的平衡问题,针对现有的隐私保护和数据挖掘结合的方法展开深入研究,提出了一种支持图像差分隐私保护的生成对抗网络模型(IDPGAN)。IDP-GAN 将拉普拉斯噪声合理地分配到判别器以提高生成对抗网络的隐私性。更重要的是,不同于在“梯度”中引入相同噪声量的隐私保护机制会造成隐私预算冗余,IDP-GAN 仅在判别器的仿射变换层和损失函数的多项式近似系数中单次加入拉普拉斯噪声,减少了隐私预算的消耗,大幅提升了差分隐私生成对抗网络生成图像的精度。
如何在数据挖掘模型训练过程中保护隐私信息的研究将具有广阔的研究前景和实用价值。本文聚焦于图像数据集实现了支持图数据差分隐私保护的生成对抗网络,然而差分隐私与其他类型的语义丰富数据(如文本、音频等模型)生成模型的结合也是值得深入研究的。
