基于移动趋势的轨迹隐私保护研究综述
2021-02-04
(曲阜师范大学 计算机学院,山东 日照 276826)
0 引言
随着移动设备的普及,基于位置的服务(Location-Based Service,LBS)广泛应用于人们日常生活[1]。通过定位设备获得位置信息,移动用户可享受位置服务提供商(Location Services Provider,LSP)的各类服务,如在社交网络中搜索附近的人,使用导航功能到达目的地等[2]。一般而言,用户可向LSP 发送快照查询和连续查询[3]。如“查找距离我最近的医院”这类查询就是快照查询,用户只需在当前位置提交一次查询请求便可获得所需服务。连续查询由同一用户在连续时间内提交多个快照查询组成,如在接下来的30 分钟内寻找距离我最近的医院。
然而在查询过程中,用户将位置和查询提交给LSP后,不知道LSP 如何处理自己的位置信息,这为个人敏感隐私泄露埋下隐患[4]。恶意攻击者可根据用户的位置信息窥探用户隐私。显然,在连续查询中,用户个人隐私泄露情况要比快照查询更严重。攻击者可跟踪用户的连续查询获得用户轨迹,而轨迹中的位置信息具有时间和空间相关性,有助于攻击者推断用户的日常行为特征,造成个人敏感信息泄露[5]。因此,连续查询中的隐私保护更为重要[6-7]。
为解决连续查询中的轨迹隐私保护问题,已研究出多种轨迹隐私保护技术,主要分为虚假轨迹法、轨迹抑制法和轨迹泛化法3 种[8-9]。这3 种技术各有优缺点,本文研究轨迹泛化法。首先介绍轨迹隐私概念及基于组的方法优缺点,然后归纳基于移动趋势方法,最后对未来工作进行展望。
1 轨迹隐私问题
1.1 基本概念
轨迹是指移动用户的位置按时间先后顺序连接起来形成的路线[10]。可将轨迹模型表示为三维空间中的折线。线段两端分别为用户在相邻时间的位置点pi=(xi,yi,ti),其中(xi,yi)是用户在地理空间中的坐标,ti表示时间戳。n个连续位置序列组成的轨迹可表示为T:p1→p2→…→pn。
隐私指个人不愿他人知道不想公开的信息。隐私具有较强的主观性,每个人对隐私的理解不同,定义标准也不同,所以不存在统一界定的隐私,但每个人都不想将一些私密的信息公开或被他人窃取,因此保护隐私不被泄露成为一个重要课题。然而,随着科技的不断发展,保护个人隐私变得越来越困难。用户会在不经意间公开大量个人信息,攻击者利用所获得的各类信息,通过数据挖掘技术分析用户敏感数据,从而获得利益。
轨迹隐私是由用户的轨迹暴露所引起的,攻击者可根据所获得的轨迹分析并推断轨迹中包含的敏感信息,如根据用户经常访问的位置以及访问过的敏感位置推断用户的兴趣爱好等。因此,保护轨迹隐私不被泄露十分重要[11]。
1.2 连续查询中的轨迹隐私保护
在连续查询中,轨迹数据是动态变化的。在可信的中心服务器架构中,匿名服务器需要以较高的速率处理大量实时位置。虽然连续查询由多个连续的快照查询组成,但由于轨迹所具有的时间和空间关联性,不能直接将快照查询隐私保护技术用于连续查询。如图1 所示,用户A 在不同时刻ti和ti+1分别形成2 个不同的匿名集{A,B,C,D}和{A,E,F,G}。对于每个快照,攻击者只能以1/4 的概率识别查询提出者,位置隐私得到保护。但将两个匿名集关联使2 个匿名集取交集,就可清楚看到用户A 为查询提出者。更严重的是,将匿名区域连接起来便可获得A 的大致轨迹。同时,如果每次位置更新时都重新为用户构建匿名集,将加重匿名服务器计算开销,使匿名服务器成为系统瓶颈,为此需开发很多新技术用于保护连续查询中的轨迹隐私。
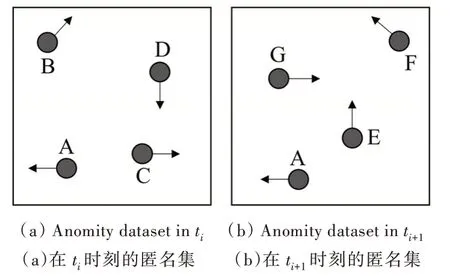
Fig.1 K-anomity图1 位置k-匿名
基于组的方法属于一种轨迹泛化法,可在连续查询中保护用户轨迹隐私。该方法根据用户隐私需求k,将查询用户与附近的k-1 个用户划分在一个组,使分组中的用户共享匿名区域,并且在连续快照中k 个用户始终保持在相同的分组内[12]。如图2 所示,在连续查询中用户A 满足4-匿名。将ti作为用户提交初始查询的时刻,匿名服务器将从用户A 附近选择3 个用户形成一个组{A,B,C,D}。在后续查询ti+1中,匿名服务器只需根据组{A,B,C,D}中用户更新的位置数据重新计算匿名区域,不需要重新为A 寻找新的组。
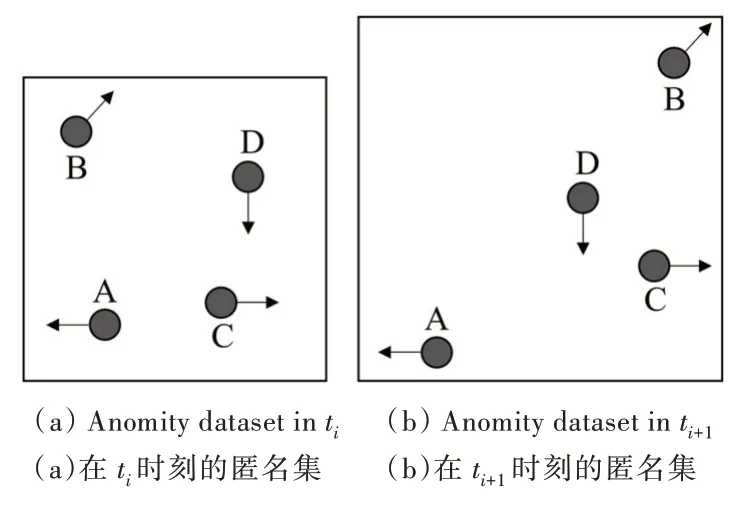
Fig.2 Method based on group图2 基于组的方法
这种方法可以抵抗连续查询攻击和采样攻击,在连续查询中有效保护用户的轨迹隐私,甚至可以在用户位置泄露的情况下保护用户的查询不被泄露。但是,正如图2(b)所示,由于用户的查询方向不一致,在一段时间后,组内用户覆盖的匿名区域会变得非常大。虽然匿名区域越大包含的用户数越多,攻击者识别查询用户的概率越低,但也会增加LSP 的计算开销,产生许多额外的候选结果,这将增加网络传输负担及匿名服务器对候选结果求精的计算开销,使服务质量变差。因此,如何在泛化方法中寻找隐私与服务质量的平衡点具有重要的现实意义。
2 轨迹隐私保护方法
为解决基于组的方法带来的弊端,研究者将用户的移动趋势引入到轨迹隐私保护方法中。基于移动趋势的方法分为基于移动方向和基于位置预测的轨迹隐私保护技术。
2.1 基于移动方向的轨迹隐私保护技术
在基于组的方法中,由于匿名集中用户移动方向不同,在后续连续查询中,用户的匿名区域会逐渐变大,这降低了LBS 的服务质量。因此,构建K-匿名集时有必要考虑用户的移动方向。
Shin 等[13]在匿名过程中引入用户移动方向,选择移动方向与用户查询方向相同的k个用户以确保k-匿名。然而该方法要求过于严格,具有相同方向的k个用户可能导致过大的匿名区域。后来作者放宽限制,匿名集中的用户只要满足P(Q=ui|D=r⋅d)≤1/k即可。也就是说,找到后验概率分布小于或等于的一组用户,这样攻击者就无法从匿名集中识别出实际的查询请求者了。其中,Q=ui表示查询的请求者为ui,D=r⋅d表示查询请求r的移动方向为d。然而,该方法仅考虑用户初始查询时的方向,忽视了后续连续快照的匿名区域大小,无法使服务质量达到全局最优。
为使用户在查询生命周期中匿名区域面积达到最优,Pan 等[14]提出一种贪心匿名算法。该方法首先根据匿名集中用户的移动方向、速度以及查询时间,预测出连续查询中每个快照的匿名区域;然后根据预测的匿名区域,利用位置扭曲度确定最终的匿名集。如图3 所示,R1 包含3 个用户的匿名区域,假设这3 个用户维持原来方向前进,那么t2时刻,用户的匿名区域将为R2。对每个区域R,位置扭曲度可以表示为:
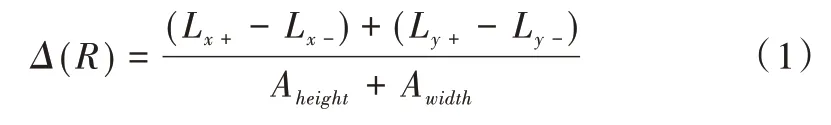
其中,(Lx-,Ly-)和(Lx+,Ly+)分别为匿名区域R在t时刻的左下角和右上角坐标,Aheight和Awidth为整个空间的宽和高。用户在查询有效期内的总位置扭曲度可表示为:
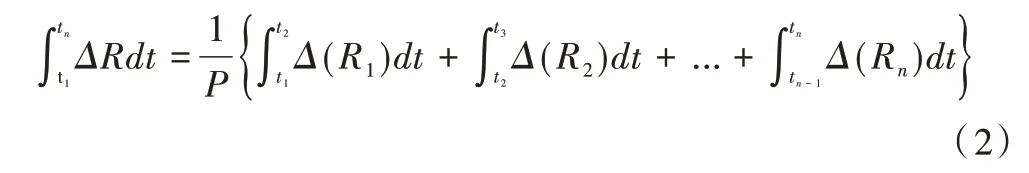
其中,P=Aheight+Awidth。匿名集在查询中的总扭曲度表示为:。当匿名查询到达时,匿名算法会将查询用户与其它k-1 个未匿名的用户组成一个匿名集,使匿名集中的位置扭曲度达到最小。但该方法忽略了现实的运动环境,移动方向会实时变化,使用移动方向判断未来匿名区域的大小误差很大。
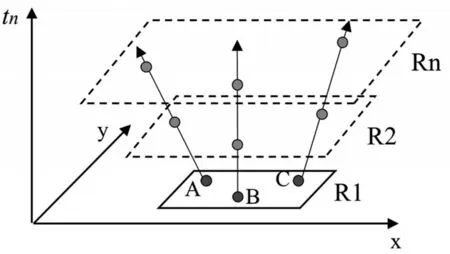
Fig.3 Greedy anonymous method图3 贪心匿名法
Gustav 等[15]提出方向速度动态匿名算法,该算法选择具有相似方向、相似速度和相同传输模式的用户实现轨迹k-匿名。令两个用户位置分别为l(xi,yi)和l(xj,yj),相对于原始位置l(x0,y0),两个用户查询角度可表示为θi和θj。根据定义的角度方向相似性simθ可计算如下:
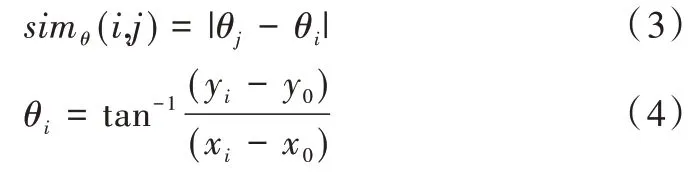
在匿名过程中,匿名集中用户要满足simθ(q,q')≤θ,q和q'表示查询,θ为AS 根据历史数据确定的阈值。该方法虽然考虑到用户交通方式的不同,但同样忽视了移动方向及速度变化的可能性,对处理用户动态改变路线情况不够灵活,无法解决突发事件影响。
2.2 基于位置预测的轨迹隐私保护技术
由于在复杂环境中用户的移动方向不停地改变,移动方向不再适合作为用户的移动趋势,所以研究者提出基于位置预测的方法,通过挖掘历史数据中的运动规律预测用户未来可能到达的位置。Monreale 等[16]考虑移动用户群体模式,提出基于轨迹模式的位置预测方法,但是该方法忽略用户间的相似性,预测精度不高;李雯等[17]提出基于运动趋势的移动对象预测算法,根据历史轨迹建立马尔可夫模型预测用户的移动位置,并采用用户运动趋势进一步完善预测结果,但该方法没有考虑多个移动用户的局部相似性。目前已有多种预测模型应用于位置预测中,如神经网络、贝叶斯网络、马尔可夫模型等,但是还没有最优的解决方法,需要根据不同情况选择不同的预测模型;Liu 等[18]通过融合多种预测模型以增强预测结果的准确度;张少波等[19]将马尔可夫模型预测的位置应用于轨迹隐私保护,使用预测的位置形成匿名区域。
在道路网络中,Wang 等[20]提出一种基于Snet 层级结构的隐私保护方法。该方法预先将道路网络抽象为加权有向图G=(V,E);然后根据历史记录计算的转移概率构建Snet 层次结构,每一个Snet 单元都可作为用户的匿名单元;为确保匿名集中的用户可以长期处于同一个Snet 中,该方法根据用户移动趋势、速度及到边界点的距离选择匿名用户。其中,用户的移动趋势使用当前Snet 及相邻Snet的马尔科夫链进行建模。如图4 所示,将道路构建为4 层的Snet 层次结构,其中点集V={v1,v2,...,v7}代表路口,边为两个路口之间的线段,每一条边都代表一个Snet 单元。例如snetS12由 边(v3,v5)和(v4,v5)构成,其中,(v3,v5)为SnetS03,(v4,v5)为SnetS04。其转移矩阵表示用户的移动趋势。转移矩阵中第一行为边(v3,v5)到S11及S13的转移概率,第二行为边(v4,v5)到S11及S13的转移概率。在构建匿名集时,用户的移动趋势将作为一个重要因素选择合格的匿名者。但上述方法没有给出概率预测失误后的解决方案,并忽视了现实交通环境,如交通状况及十字路口对移动用户的影响。
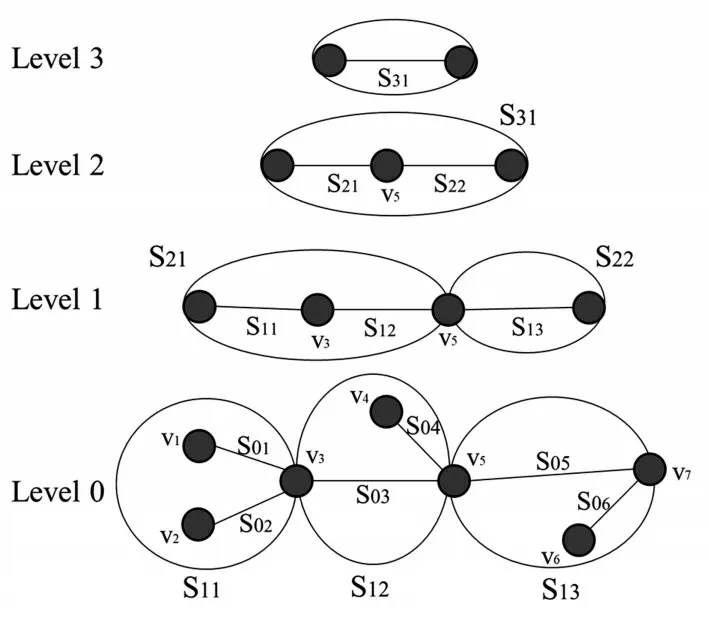
Fig.4 Snet hierarchy图4 Snet 层次结构
3 展望
基于移动趋势的轨迹隐私保护方法可有效减少泛化法带来的匿名区域过大问题。现实交通环境较为复杂,用户的速度变化、交通拥堵程度以及无意间的行驶错误都可能导致用户匿名区域变大,从而降低用户服务质量。如何将这些因素考虑到移动趋势中,使用户临近未来位置,是基于移动趋势的轨迹隐私保护方法重要的研究方向。此外,现在的方法往往将全部用户作为研究对象,但用户的运动规律通常与移动对象种类相关,这就导致预测模型可能对某个种类的用户移动趋势预测不准确。因此,需将移动用户进行分类分析,增强不同模型对个体运动的适应性。
4 结语
本文对基于移动趋势的轨迹隐私保护技术进行了综述。首先介绍了轨迹和轨迹隐私概念,指出连续查询中基于组的轨迹隐私保护优缺点,介绍了基于移动趋势的轨迹隐私保护方法,然后分别对基于移动方向和位置预测的轨迹隐私保护技术进行了归纳总结,展望了未来的研究方向。
