基于深度学习的图像语义分割技术综述
2021-02-04
(广东技术师范大学计算机科学学院,广东广州 510000)
0 引言
近年来,图像在目标检测、图像分类、分割以及识别等方面的应用越来越广,其中图像分割技术是根据相似性原则将图像分成若干个不同特性区域的过程。图像分割方法大致可分为3 类:基于图论的方法、基于像素聚类的方法与语义分割方法,而图像语义分割是以像素共同点为分割依据,从像素级别处理图像[1]。语义分割是场景理解的基础性技术,对智能驾驶、机器人认知层面的自主导航、无人机着陆系统以及智慧安防监控等无人系统具有至关重要的作用。
1 传统语义分割方法
传统图像分割是根据灰度、彩色、空间纹理等特征将图像划分成若干个互不相交的区域,使得这些特征在同一个区域内表现出一致性或者相似性,而在不同的区域间表现出明显不同。其方法主要分为以下几类:基于阈值的分割方法、基于区域的分割方法、基于边缘的分割方法等。阈值分割方法是常用的分割技术之一,其实质是根据一定的标准自动确定最佳阈值,并根据灰度级使用这些像素以实现聚类。基于区域的分割方法是以直接寻找新区域为基础的分割技术,可分为区域生长和区域分裂合并两种基本提取方式。区域生长以单个像素点为基础,将具有相似特征的像素点聚合到一起形成区域,其计算简单,对于均匀分布的图像具有良好效果。区域分裂合并从整体图像出发,通过像素点之间的分裂得到各子区域,四叉树分解法就是其典型代表方法。基于边缘检测的分割方法通过检测不同区域边缘分割图片,最简单的边缘检测方法是并行微分算子法,它利用相邻区域的像素值不连续的性质,采用导数检测边缘点。传统方法多数通过提取图像的低级语义,如大小、纹理、颜色等。在复杂环境中,应对能力与精准度远没有达到要求。
2 深度学习与传统方法相结合的图像语义分割
随着深度学习技术的发展,深度学习模型开始与传统语义分割方法相结合,即在利用传统方法分割出目标区域的基础上,进一步采用卷积神经网络等方法学习目标特征并训练分类器,对目标区域进行分类,从而实现目标区域的语义标注[2]。卷积神经网络模型的提出,为图像语义分割与深度学习的结合奠定了基础,使得图像语义分割技术应用于多个应用领域。卷积神经网络使用卷积层—激活函数—池化层—全连接层的运行结构,输入图像经卷积层聚拢不同局部区域特征,通过激活函数(Sigmoid、Relu、Tanh 等)部分激活,部分抑制从而强化特征。池化层在不改变目标对象的基础上,使输入图片变小,减少训练参数,最后使用全连接层神经元的前向传播与反向传导损失计算函数最优点,使输入图像的分类、分割等更加高效。训练研究人员以卷积神经网络为基础提出AlexNet、VGGNet、GoogleNet、ResNet 等图像分类网络模型[3-6],其中AlexNet网络为2012 年ILSVRC 大赛冠军,GoogleNet 网络、VGG⁃Net 网络分别为2014 年ILSVRC 大赛中的冠亚军,ResNet网络为2015 年ILSVRC 大赛冠军,其特点如表1 所示。
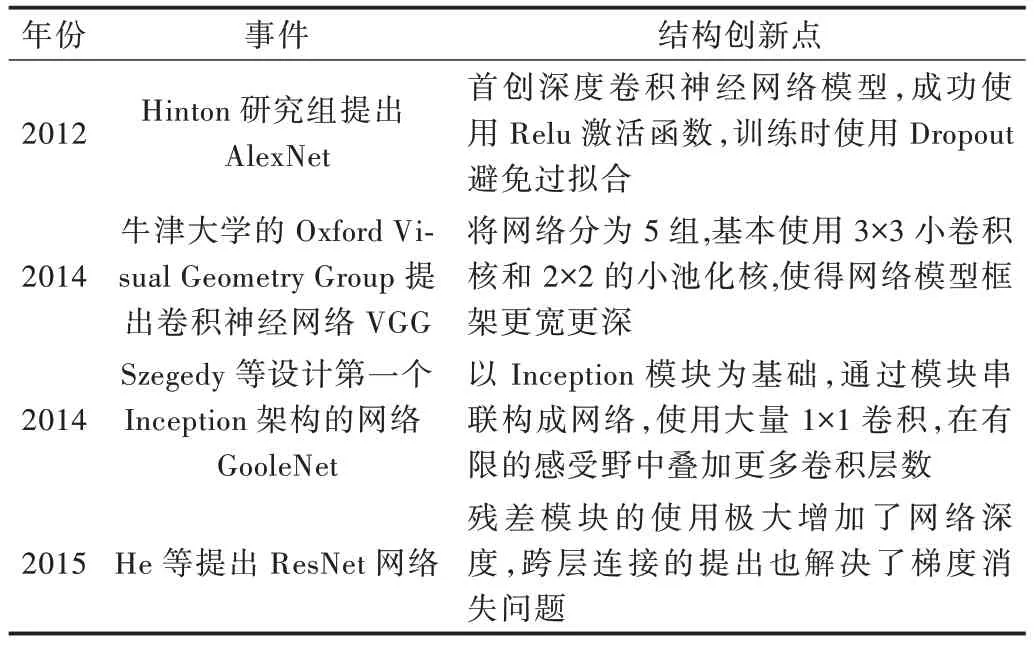
Table 1 Image semantic segmentation methods combined with deep learning and traditional methods表1 深度学习与传统方法相结合的图像语义分割方法
3 基于深度学习的语义分割方法
随着全卷积神经网络的提出,图像语义分割技术进入新时期,计算机在视觉领域通过深度学习网络进行全卷积后能够极大提高图像分类效率与识别准度,网络框架与语义分割问题进入深度结合快速扩展的时代。全卷积网络通过扩展普通卷积网络模型,使其具有更多的参数特征和更好的空间层次。其结构可以分为全卷积和反卷积两部分,全卷积借鉴卷积神经网络模型,输入图像在参数减少与特征强化后,采用反卷积层对最后卷积层的特征图进行上采样,通过转置卷积恢复输入图像尺寸,从而针对每个像素都产生一个预测,使输入图像达到语义级分割。全卷积网络将卷积神经网络对于图像的识别精度从图像级识别提升为全卷积神经网络中像素级的识别。但是使用全卷积网络的图像分割仍存在分割结果不够精准、输出图像模糊等问题。全卷积网络为语义分割的未来发展指明了方向,研究人员以全卷积神经为基础提出U-Net、SegNet、PSPNet、RefineNet、DeepLab、BiSeNet、Panoptic FPN[7-13]等图像分割网络结构模型。其特点如表2 所示。
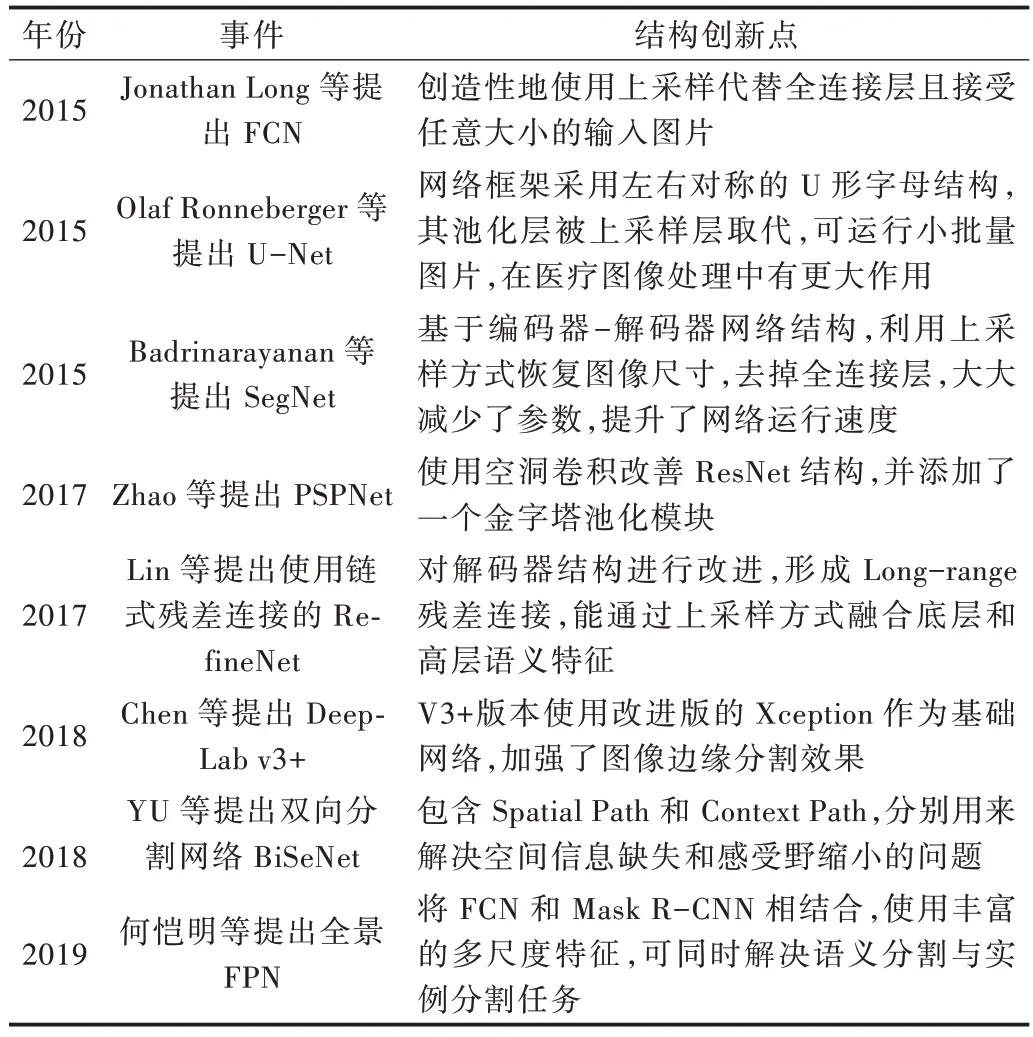
Table 2 Semantic segmentation methods based on deep learning表2 基于深度学习的语义分割方法
4 图像语义分割分析与比较
评估基于深度学习的图像语义分割算法性能的主要指标可归纳为:精确度、执行时间及内存占用等。处理速度或运行时间是重要的衡量指标,因为数据集一般较大,受到计算机硬件设施限制,更少的执行时间意味着更多的应用可能。内存是语义分割的另一个重要因素,不过内存在多数场景下是可以扩充的。精确度是最关键指标,图像分割中通常依据许多标准衡量算法精度。这些标准通常是像素精度及图像交并比衍变产生,如像素精度(Pixel Ac⁃curacy,PA=)、均像素精度(Mean Pixel Accuracy,MPA=)、均交并比(Mean Intersection over Union,MIOU=)等。像素精度是最简单的度量,用以标记正确像素占总像素的比例。均像素精度是类别内像素正确分类概率的平均值。均交并比是公认的算法评估标准,其计算两个集合的交集和并集之比,在语义分割领域中,真实值和预测值就是两个集合的体现。FCN 网络的提出打破了传统分割方法,使用Caffe网络框架,在PASCAL VOC 数据集上的分割精度(MIOU%)为62.2%。为解决FCN 分割精度不高等问题,SegNet 算法被提出,其使用Caffe 网络框架,在CamVid 数据集上的分割精度为60.1%。随后RefineNet 出现,使用Pytorch 网络框架,在PASCAL VOC 数据集上的分割精度为83.4%。PSPNet 提出金字塔模块,使用TensorFlow 网络框架,在PASCAL VOC 数据集上的分割精度为85.4%。BiSeNet 和全景FCN 的提出使语义分割算法更加完善,它们在Cityscapes 数据集上的分割精度分别达68.4% 和79%。上述数据集汇总如表3 所示,网络框架汇总如表4 所示。
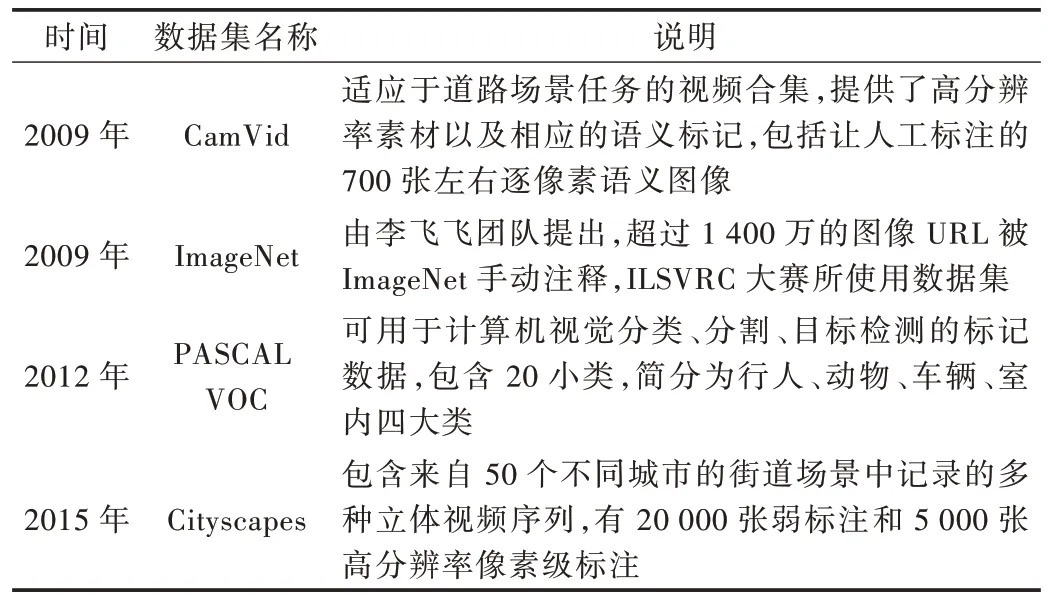
Table 3 Summary of data sets表3 数据集汇总
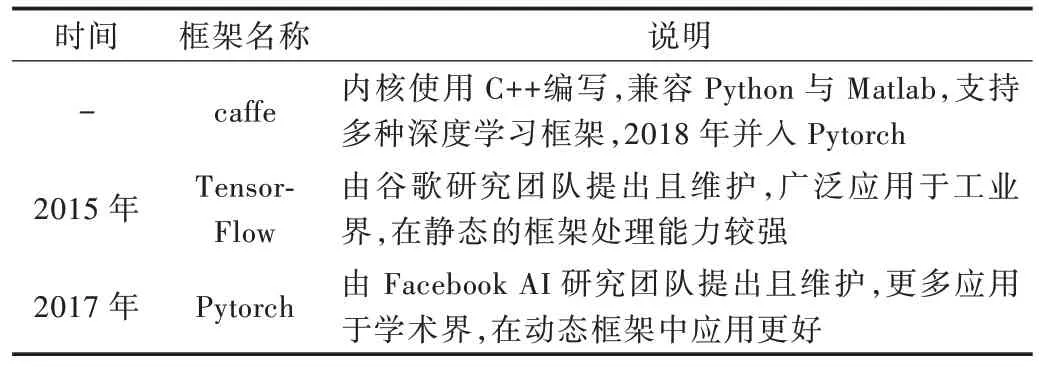
Table 4 Network frameworks表4 网络框架汇总
5 结语
基于深度学习的图像语义分割技术虽然取得了良好分割效果,但是其网络训练需要大量数据集,像素级别的图像质量难以保证,原因是大量使用基于强监督的分割方法,依赖于人工数据标记,且对未知场景适应能力差。2014 年,DeepLab v1 结合深度卷积神经网络和概率图模型,形成完整端对端网络模型,但是其空间分辨率低,存储空间需求量大;2017 年,DeepLab v2 空洞金字塔的提出,提高了模型优化能力,但图像细节模糊处理能力下降;同年,DeepLab v3 改进金字塔结构被提出,其使用1×1 小卷积核,但输出图效果不佳;2018 年,DeepLab v3+被提出,其使用编码器解码器结构,使用改进版的Xception 作为基础网络,弥补了之前版本网络的缺陷性,但仍需继续提高模型运行速度与性能,如随着DeepLab 算法的发展,深度学习具有更新太快、周期较长、完善缺陷困难等问题。目前,还没有一种通用算法适用于所有领域,基于深度学习的图像语义分割尚有巨大发展潜力。
