基于注意力机制的农业文本命名实体识别
2021-02-01赵鹏飞赵春江吴华瑞
赵鹏飞 赵春江,2 吴华瑞 王 维
(1.山西农业大学工学院, 太谷 030801; 2.国家农业信息化工程技术研究中心, 北京 100097;3.北京农业信息技术研究中心, 北京 100097)
0 引言
随着农业信息化技术的快速发展,农户可通过农技服务平台进行在线问答咨询。面对海量的问题数据,快速而准确地定位关键词、挖掘深层的语义关系是农业智能问答系统亟需解决的问题[1]。农业命名实体识别作为一种智能化信息抽取方法,其主要任务是从非结构化的问答数据中识别不同类型的实体,如农作物病虫害、作物品种、农药名称等,这是构建智能问答系统的关键技术环节,是农业文本信息挖掘领域的热点研究方向。
在农业领域,许多研究者利用机器学习进行实体识别研究。文献[2]提出基于条件随机场的识别方法,通过添加词性、左右指界词等模板特征,对农作物、病虫害及农药3类实体进行识别。文献[3]采用BIO和BMES两种实体标注方式,基于CRF模型对数据集中农作物、家禽、病虫害等实体进行识别。文献[4]将农业本体概念作为子特征加入CRF模型中,对涉农商品名称进行抽取和类别标注。但是,传统的基于机器学习的方法依赖手工设计的特征模板,在提高模型性能的同时也导致整个模型的鲁棒性和泛化能力下降[5]。
农业实体构词复杂、种类众多,导致农业领域实体识别研究更具有挑战性,主要体现在:由于缺乏规范的农业词典,采用分词工具对农业语料进行分词出现分词错误的现象,影响了模型性能;同一实体在文本中所处位置不同,以单句为处理单元的识别方法无法聚焦全文语境,存在实体标注不一致问题。
随着深度学习算法的改进,网络模型能够自动学习到更深层次的特征信息,在很多领域实体识别任务取得了理想的效果[6-12]。
近年来,注意力机制在自然语言处理领域得到了广泛的应用[13-15]。文献[16]基于BiLSTM-CRF框架,通过添加注意力机制学习有效的字符特征向量。文献[17]提出基于双向注意机制的循环神经网络(Recurrent neural network,RNN)模型,该模型能更好地获取标签之间的关系。文献[18]提出了多注意力模型,在阿拉伯语实体识别任务中取得较好的结果。文献[19]利用卷积神经网络提取汉字分解后的特征信息,基于自注意力机制识别医学电子病历的相关实体。
上述基于深度学习的方法为农业领域开展命名实体识别研究提供了参考依据,但在农业文本向量化表示方面并未提出有效的方法来获取字符之间丰富的语义特征,并且相关模型在农业领域数据集上没有进行验证,不足以说明农业领域命名实体识别的相关问题。
本文在农业领域命名实体识别任务中,基于深度学习方法,在BiLSTM-CRF网络模型基础上,有针对性地引入大量无标注农业语料,通过预训练方式对农业实体字符分布式表示进行扩充,并引入文档级注意力机制重点关注实体关键字信息,通过余弦距离相似度得分获取文本中实体之间的相关系数,进一步对模型结构和训练参数进行优化和改进,构建基于注意力机制的Att-BiLSTM-CRF混合网络模型,以期实现农业文本命名实体的精准识别。
1 数据采集与预处理
1.1 数据采集
农业命名实体识别缺少公开的语料数据集,本文通过数据采集、数据预处理、数据标注3个步骤,建立农业领域实体识别语料库。本文的语料数据主要通过爬虫框架,抓取各大农业网站(中国农业信息网、中国农业知识网、中国作物种质资源信息网、国家农业科学数据中心等)关于农作物病虫害和农作物品种的文本语料。其中,标注语料库作为实验数据集,包含4 604篇农业文本,共33 096个句子;未标注语料库作为预训练数据集,包含26 025条语料,共300万个中文字符。
1.2 数据预处理
通过爬虫抓取的语料数据,包含大量的网站标签、链接、特殊字符等非文本的结构数据,不利于数据标注。通过Python正则表达式、字符格式规范化等操作,删除非文本数据,获取规范化的农业语料库。
1.3 数据标注
本文采用人工标注的方式进行语料库的标注,语料库包含实体共26 309个,其中,病害名称4 129个,虫害名称4 275个、农药名称11 952个、农作物品种名称5 953个,不同类型实体统计如表1所示。使用BIEO标记方案表示命名实体,B表示实体名称的开始,I和E分别表示实体的内部和实体的结束标记,O表示语料中的非实体。语料库注释示例如图1所示。为更好地识别实体所属类别,将类别信息添加在实体标签上,实体类型描述如下:病害名称实体-Disease、虫害名称实体-Pest、农药名称实体-Pesticide、农作物品种名称实体-Crop。其中,B-Disease和B-Crop分别表示病害和农作物品种的命名实体的开始。
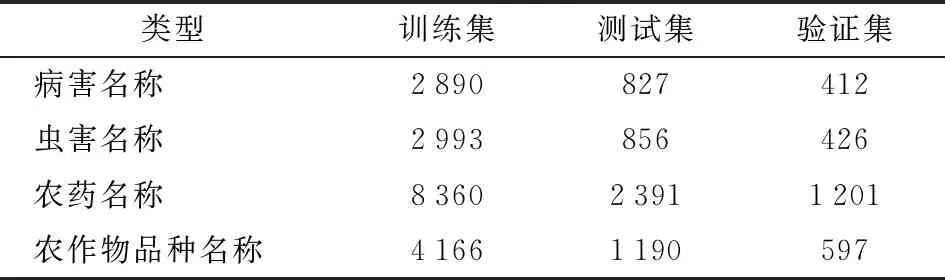
表1 语料库统计信息Tab.1 Corpus statistics
2 模型框架
本文模型包含字嵌入层、BiLSTM层、Attention层和CRF层4部分,模型结构如图2所示。
2.1 字嵌入层
2.1.1预处理
在英文NER任务中,由于每个单词被空格分隔,很多研究将词向量与字符向量拼接作为模型输入,提高模型的性能。与英文单词不同,中文词语之间没有明显的分隔标记,而且词语具有较强的领域性。因此,为更好地处理中文实体识别任务,多数方法都将分词作为语料处理的基本步骤。但是,现有分词技术不能准确地进行切分,会产生各种各样的错误[20]。
例如,病害实体“水稻细菌性褐条病”分词结果为“水稻/细菌性/褐/条/病”,农作物品种实体“两优培九”分词结果为“两/优/培九”。这些实体被错误地拆分,从而导致模型不能正确获取实体的特征表示,基于字的实体识别可以有效地避免这类问题。
本文使用字向量作为模型初始输入,采用预训练方式,以字为单位进行切割,获取特征表示,缓解分词准确度对性能的影响。
2.1.2字向量表示
农业文本数据需进行文本向量化,将相应字符映射为一定维度的实数向量,才能被计算机处理。本文采用Word2vec的CBOW模型[21-22],在模型架构基础上,针对字向量维度,进一步优化和验证,通过对这些无标注的语料进行无监督训练,得到相应的分布式表示,最终生成特定维度的字向量,构建字向量表。CBOW模型的框架如图3所示,主要有输入层、映射层和输出层3层。
在CBOW模型中,目标字由上下文推测得到,已知当前字wm,利用周围2n(n为窗口尺寸)个字wm-n、wm-n+1、…、wm+n-1、wm+n预测wm当前字出现的概率。以病害实体“小麦霜霉病”为例,通过字“霜”的上下文“小”、“麦”、“霉”、“病”4个字,来预测所有字出现的概率,其中目标字“霜”出现的概率最大。
在预训练过程中,CBOW模型字级窗口设置为2,构建字向量表,每个字对应唯一的向量表示。本文验证了不同维度字向量对模型性能造成的影响,维度设置为50、100、150和200,经过实验对比发现,字向量维度设置为100时模型的性能最优。因此,通过预训练方式,获取农业文本100维度的字向量特征表示,适用于农业领域命名实体识别。
2.2 BiLSTM层
LSTM是一种特殊的循环网络模型,克服了RNN模型在训练过程存在的梯度爆炸问题[23]。农业实体的构词方式复杂多样,针对目标实体的识别,需要考虑实体不同位置的上下文信息,来获取更深层次的特征表示。LSTM是单向的循环神经网络,只能获取目标词过去的文本信息。例如,病害实体“玉米根腐病”,LSTM只能访问“腐”的前一个字“根”的特征信息,不能预测下一个字“病”的出现。目标词的上下文信息对实体识别具有不同程度的影响,为了准确识别出农业命名实体,构建了双向LSTM(BiLSTM)网络模型,进行正向和反向2个不同方向的文本表示,充分获取目标词过去和将来的特征信息。
LSTM网络的主要结构可以形式化地表示为
it=σ(Wiht-1+Uixt+bi)
(1)
ft=σ(Wfht-1+Ufxt+bf)
(2)
(3)
(4)
ot=σ(Woht-1+Uoxt+bo)
(5)
ht=ot⊙tanh(ct)
(6)
式中σ——sigmod激活函数
tanh——双曲正切激活函数
it、ft、ot、ct——在t时刻的输入门、忘记门、输出门、记忆细胞
Ui、Uf、Uc、Uo、Wi、Wf、Wo、Wc——不同控制门对应的权重矩阵
bi、bf、bo、bc——偏置向量
xt——t时刻的输入向量
ht——t时刻的输出结果
⊙——点乘运算符
字嵌入层的向量x,将作为t时刻BiLSTM层的输入,通过正向LSTM输出特征序列和反向输出序列,得到隐藏层拼接的向量,经过tanh激活函数进行加权得到最终的输出结果ht,将作为Attention层的输入。
2.3 Attention层
在命名实体识别任务中,由于中文构词方式灵活多变,同一实体具有多种表述方式,实体在文本不同位置可能多次出现。以单句为训练单元的识别模型,关注实体在该句的上下文表示,忽略全文的语境信息,容易造成同一文本实体标注不一致的问题。
例如,水稻稻瘟病的描述如下:水稻又见“【火烧瘟】”,早稻警惕【稻瘟病】流行,一定要早做预防。当前江西早稻,……禾苗都可以点火烧了,名符其实的“【火烧瘟】”。【水稻稻瘟病】又称【稻热病】、【火烧瘟】,症状表现为中央呈灰白色病斑,边缘呈显著褐色,且发病部位在潮湿的环境下会产生灰色的霉状物。
文本中,水稻稻瘟病又称火烧瘟,火烧瘟作为病害实体,在文本中不同句子的不同位置多次出现。以句子为处理单元的模型,在脱离上下文语境的情况下,对【火烧瘟】病害实体出现错标或者漏标的现象。为解决实体标注不一致的问题,通常采用基于规则制定的方法,但是特定领域的规则制定较为复杂,需要较强的领域知识,不同的领域规则不具有通用性。
针对农业文本中实体命名方式多样化、实体分布不均匀的特点,在注意力模型基本架构上进行扩展,引入文档级全局信息,并增加余弦距离得分的相似性评估,对处于不同位置的同一实体重点关注。基于注意力的学习模型,能够忽略文本中无关的信息,关注实体关键信息,模型以整篇文本作为训练单元,考虑实体上下文的语境信息,缓解实体标注不一致问题。
本文用D=(S1,S2,…,Sd)表示文档包含d个句子,每个句子S=(w1,w2,…,wm)包含m个字,文档中包含字的总数是N。对于文档中的实体,通过注意矩阵A处理BiLSTM层输出的特征序列,来计算当前目标字与文档中所有字之间的相关性,获取目标字wi基于文档层面的全局特征表示gi,计算公式为
(7)
其中
(8)
(9)
式中Ai,j——当前字wi与文档中字wj注意力权重
hj——BiLSTM层输出
score(wi,wj)——采用余弦距离判定的字wi与字wj相似性得分
Wa——训练过程中学习到的参数
最后,目标字wi在文档级注意力层的输出为ci,通过tanh函数来获取置信度ei,计算公式为
ci=tanh(Wg[gi,hi])
(10)
ei=tanh(Weci)
(11)
式中Wg、We——训练时学习到的参数矩阵
2.4 CRF层
在CRF层,采用状态转换矩阵来预测当前标签,获得全局最优的标记序列[24]。设定P为Attention层的输出矩阵,维度为m×k,m表示输入句子包含字的数量,k表示标签集合的元素数。对于输入文档D,对应的输出标签序列y=(y1,y2,…,yn) 的概率为
(12)
式中X——输入的文本序列
Ayi,yi+1——从标签yi转移到标签yi+1的分数,Ayi,yi+1的值越大表示标签i转移到标签j的可能性越大
Pi,yi——第i个字被预测为第yi个标签的分数
然后,利用Softmax函数,得到序列y的条件概率。最后,使用Viterbi[25]算法将得分最高的序列y*作为模型最终的标注结果。
2.5 模型参数配置及评价
模型的参数配置如表2所示,参数通过反复实验确定的,字向量维度设置为100。模型使用双向的LSTM网络,隐藏层维度设置为128。为减轻模型过拟合问题,引入Dropout机制[26],Dropout的值直接影响到模型性能,设置为0.5。选取ADAM[27]优化算法,学习率为0.002。模型训练批处理参数为16,迭代次数设置为50。

表2 参数配置Tab.2 Parameter setting
与其他实体识别方法相似,采用准确率P、召回率R、F值作为实验的评价指标[28]。
3 实验结果
在不依赖人工设计特征的情况下,通过调整不同的模型参数,在1.3节构建的标注数据集上验证模型的识别性能。语料库中训练集、测试集、验证集按7∶2∶1的比例进行分配,数据集之间无重叠,因此测试数据集的实验结果可作为实体识别效果的评价指标。
3.1 不同嵌入向量性能比较
本文分别以词向量和字向量作为Att-BiLSTM-CRF模型的初始输入,验证不同嵌入向量对模型性能的影响,对比结果如表3所示。将字向量作为模型的输入,模型识别准确率P为93.48%,相较于词向量作为模型输入,准确率提升了2.96个百分点。分析结果得知,基于词向量的输入,实体被错误拆分,导致这些复杂的实体没有被正确识别,例如,水稻品种“广8优郁香”被错误地拆分为“广/8/优郁/香/”。接着,验证了不同字向量维度对模型性能的影响。字向量维度设置为50、100、150、200,模型准确率P分别为91.19%、93.48%、92.15%、91.83%;召回率R分别为89.5%、90.6%、90.08%、90.21%;F值分别为90.29%、92.01%、91.04%、91.00%。从实验结果看出,适当增加字向量维度,可以获取质量更好的字级分布式表示,字向量维度为100时,模型性能达到最高。随着维度越来越大,训练成本越来越高,模型性能很难得到提升,甚至下降。针对农业实体,字向量维度不是越大越好,在一定范围内存在局部最优值。

表3 不同嵌入向量实验结果对比Tab.3 Results of different embedding %
3.2 不同注意力机制的性能比较
采用字向量维度100,并在BiLSTM-CRF模型框架上增加句子级和文档级的注意层,并对模型性能进行了评估。结果如表4所示。句子级的方法,模型的准确率P为91.23%,召回率R为89.24%,F值为90.23%。分析结果发现,同一文本中,部分农药实体“农抗120/Pesticide”,被错误标记为农作物品种实体“农抗120/Crop”。这种标记不一致的现象,是由于“农抗120”与大多数农作物品种实体构词方式相似,都是“词+数字”的方式,在识别过程中,虽然句子级注意力获取了该实体在句中特征信息,但是并没有考虑全文的语境,从而导致上述错误的判断。

表4 不同Attention机制实验结果对比
与基于句子级的方法相比,文档级方法模型的准确率P、召回率R、F值分别提高了2.25、1.36、1.78个百分点。结果表明,文档级方法通过获取文档中字之间的相关信息,通过余弦函数计算文档中目标字与其他字的相似度,调整目标字的权重,在缓解上述讨论的标记不一致问题的同时,有效地提高了模型性能。
3.3 不同模型性能比较
为了验证本文提出的基于Att-BiLSTM-CRF在农业语料上的识别性能,在不同的模型上进行对比实验,模型包括:LSTM[29]、LSTM-CRF[30]、BiLSTM-CRF[31]以及本文提出的基于文档级的Att-BiLSTM-CRF,实验结果如表5所示。在准确率P、F值两方面,对比了各模型针对4类实体的识别性能,结果如图4所示。
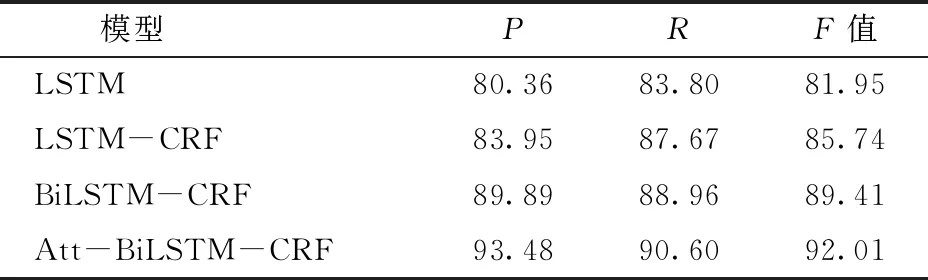
表5 不同模型的实验结果对比
由表5可知,LSTM模型通过隐藏层获取过去的序列信息,结构比较单一,模型准确率为80.36%。LSTM-CRF模型相比于LSTM模型,通过添加CRF层,利用实体间相邻的标签动态规划最优的序列标注,模型准确率为83.95%。为了获得输入序列丰富的上下文信息,基于BiLSTM-CRF模型框架,模型准确率为89.89%,与LSTM-CRF模型相比,提升了5.94个百分点。基于文档级注意力的Att-BiLSTM-CRF模型,通过添加注意力层,获取文本中实体间的相似系数,与其他3个模型相比,准确率P和F值最高,分别为93.48%和92.01%。
图4展示了4种模型对于农药、虫害、农作物品种以及病害4类实体的识别率P和F值,4种模型对病害和农药实体识别准确率较高,虫害和农作物品种较低。LSTM模型结构单一,对于复杂的虫害和农作物品种实体,模型不能获取丰富的特征信息,识别率为65.92%和71.64%,F值为71.33%和72.48%。LSTM-CRF模型对虫害实体识别率为73.18%,农作物品种实体识别率为76.59%,相较于LSTM模型分别提高了7.26、4.95个百分点。
分析得出,病害和农药具有较规则的后缀组成词,例如,病害的“病”、农药的“乳油”等,这些明显的字特征信息提高了这类实体识别的准确率。而虫害和农作物的构词比较复杂,例如“数字+词”、“数字+字母”等方式,因此这类实体需要提升模型的复杂性,来获取更丰富的特征信息。
BiLSTM-CRF模型对农药和病害实体识别率相对较高,为94.35%、92.70%,对虫害和农作物两类实体识别率为83.66%、85.47%,相较于LSTM-CRF模型,分别提升了10.48、8.88个百分点。模型通过双向LSTM隐藏层提取过去和未来的序列信息,对复杂、长度较大的实体识别率有较大提升。但是,模型依然存在实体标签不一致的现象。
本文Att-BiLSTM-CRF模型对农药实体识别率达到97.58%,虫害实体识别率为91.15%,对于构词更复杂的农作物品种实体识别率达到最高的87.26%,F值为84.92%。进一步验证了添加文档级的注意力机制,结合实体所在文本的语境信息,获取实体关注度能够提高农业实体的识别效果。
实验结果表明,本文提出的Att-BiLSTM-CRF模型不使用任何字典或外部注解资源,在训练过程中动态地获取实体间的相似关系,能够有效地识别农业复杂实体,F值达到92.01%。
3.4 不同模型识别效率比较
为了验证语料集的规模对模型性能的影响,本文新增了3个语料库,包含实体数量分别为9 906、15 020、20 618,新增的语料库同样按照7∶2∶1的比例进行分配,数据集之间无重叠,实验结果如下:LSTM模型由于结构比较单一,在4种规模语料库准确率较低,分别为64.52%、72.85%、83.93%、85.11%。LSTM-CRF模型通过添加CRF层,获取标签转移的最优概率,与LSTM相比,模型准确率分别提高了1.40、2.03、0.43、1.57个百分点。BiLSTM-CRF和Att-BiLSTM-CRF在语料集较小的情况下,模型达到较好的识别效果。随着语料集规模的扩大,融入注意力机制的Att-BiLSTM-CRF模型,在4种规模语料库识别准确率均达到最高,分别为85.11%、86.68%、90.29%、93.48%。
最后,本文通过中国农技推广信息平台,在农技问答板块,抽取了相应的农户问答文本数据,应用Att-BiLSTM-CRF模型对文本数据进行了实体识别,结果如表6所示。

表6 问答数据识别结果示例Tab.6 Examples of Q&A data recognition results
4 结论
(1)针对农业领域命名实体识别中实体识别类别众多、实体类型组成复杂,造成分词不准确等问题,提出基于注意力机制的Att-BiLSTM-CRF神经网络模型方法,提升了识别性能,F值为92.01%。
(2)通过预训练的方法获取农业实体字级的分布式表示,缓解分词错误造成的性能影响。通过多种向量维度的实验,证明基于字向量的识别方法适用于农业领域NER任务,字向量维度设置为100,模型准确率P达到93.48%,召回率为90.60%。
(3)基于文档级的注意力机制获取实体间的相似度,可确保农业实体标签的一致性,避免错标或者漏标的情况,提高了模型识别性能。
