基于自适应字典的小样本高光谱图像分类方法
2021-02-01虎晓红司海平
虎晓红 司海平
(河南农业大学信息与管理科学学院, 郑州 450046)
0 引言
高光谱图像的光谱分辨率高,不仅能辨识不同地物光谱间差异较大的地物类别,而且能辨识不同地物光谱间只存在细微差异的地物类别,在农业规划、环境监测和资源勘察等领域得到了广泛的应用[1-5]。对高光谱图像分类技术的研究可促进高光谱遥感的应用,近年来,高光谱图像分类已成为遥感、机器视觉和机器学习领域的研究热点,并取得了大量的研究成果。
高光谱图像分类研究主要包括高光谱图像的表达和分类器设计两方面。在高光谱图像的表达中,早期只采用光谱特征进行分类,由于缺乏空间信息,分类效果受到限制。为了更好地体现高光谱图像“图谱合一”的特点,空间信息在高光谱图像分类中得到了应用[6],空间滤波和区域分割等空间信息表达方法拓展了高光谱图像的应用领域[7-9],空谱融合方式的不断改进有效提高了高光谱图像的分类性能[10]。在高光谱图像分类的分类器设计方面,传统基于统计学习的支持向量机(Support vector machine, SVM)、融合空间信息的复合核支持向量机(Support vector machine with composite kernels, SVMCK)[11]取得了较好的分类效果;近年来,基于字典学习的稀疏分类器(Sparse representation based classification, SRC)[12]和协同分类器(Collaborative representation classification, CRC)[13]在高光谱图像分类中表现出良好的潜力,并得到广泛关注。文献[14]结合SRC和空间信息提出了高光谱图像的联合稀疏分类器(Joint sparse representation based classification, JSRC);文献[15]采用局部空间语义窗口平均特征,提出联合协同分类器(Joint collaborative representation based classification, JCRC),应用在高光谱图像分类中;文献[16]在JSRC中加入相关系数,提出了融合相关系数的联合稀疏表示(Correlation coefficient and joint sparse representation, CCJSR)。在空谱融合中相关系数的引入使基于字典的高光谱图像分类效果在联合空间信息的基础上得到了进一步改善[14-16]。
然而,高光谱图像分类仍然存在一些问题:其一,在实际应用中,标注工作通常需要实地采样,相比普通相机采集的图像,标注工作更加困难,且代价更高昂,因此可利用的训练样本数量非常有限,“小样本问题”极大地影响了高光谱图像的分类性能;其二,在基于字典学习的高光谱图像分类中,当构成字典的原子数目不足时,分类性能直接受到影响,若由大量的元素创建字典进行样本重构,构成字典的原子间又会因信息冗余、字典原子间的相互干扰和字典原子数量过多而导致分类时间过长和分类效果下降。因此,如何高效地协同高光谱图像的空谱信息来进一步提升分类性能,是高光谱图像分类及其应用中亟待解决的问题。
针对这些问题,本文提出基于自适应字典的小样本高光谱图像分类方法。通过对有限标记的训练样本空谱信息进行分析,采用伪标注方法扩展标记样本数量,并针对不同的测试样本构建其自适应字典,在自适应的空谱字典下协同重构样本,同时在协同表示中增加自适应空谱协同字典中的竞争关系,以期挖掘样本的本征,在小样本下提升高光谱图像的分类性能。
1 研究方法
1.1 高光谱图像超像素分割
在高光谱图像分类中,图像局部空间子块信息得到了广泛的采用[11,14-16],但无论是预处理中采用的均值滤波,还是像素级高光谱图像分类后,在固定窗口尺寸上进行的空间信息融合,通常无法有效地保持高光谱图像目标区域的边界。而超像素[17]作为在一幅图像中有意义的不规则区域,通过将相似的相邻像素合并而产生,能更好地保持高光谱图像的局部细节。同时,熵率超像素分割[18]有利于形成结构均匀、紧凑和尺寸基本一致的超像素区域,据此,本文采用熵率方法对高光谱图像进行超像素分割,分割流程如图1所示。
设高光谱图像X=[x1,x2,…,xn]∈Rd×n,d为波段数,n为图像像素数,图像尺寸为M×N,在对X进行熵率超像素分割前,对X进行主成分分析,提取高光谱图像X的第一主成分Γ,由Γ的像素点构建图G=(V,E),其中V为Γ的像素点构成的顶点集,E为描述图G中顶点相似性的边集,从而将图像分割转换为图的划分问题,优化目标为
(1)
H(·)——随机游走熵率
B(·)——平衡项
μ——平衡系数
由贪心算法[18]求解式(1),可得到高光谱图像的第一主成分Γ被分割为
(2)
式中Ti、Tj——Γ中的第i、j个超像素
p——Γ中的超像素数目
由此,可得到高光谱图像X的超像素分割。
1.2 自适应字典构建
高光谱图像在像素的局部空间上,满足较好的局部一致性,属于相同类标的概率大[19-23];依据像素局部空间的类别关联性,可增加标记样本数量,缓解分类中的小样本问题。设高光谱图像中的标记样本XL={x1,x2,…,xm},标记为{l1,l2,…,lm},li∈{1,2,…,c},1≤i≤m,c为类别数目。既在xi的超像素区域中的像素,又在xi的光谱近邻的像素,定义为
Z(xi)={x|x∈Ω(xi)∩x∈Ψ(xi)}
(3)
式中Z(·)——空间近邻和光谱近邻交集
Ω(·)——所在的超像素空间近邻
Ψ(·)——X中的前q个光谱近邻
虽然X的超像素区域多为类别一致性区域,但对xi的不规则超像素区域Ω(xi), 由于受到背景点、噪声和超像素分割算法的影响,导致Ω(xi)中的一些像素不具备和xi相同的类标,即这些xi的空间近邻对xi类别的代表性相对较弱。因此,本文在扩展超像素局部空间像素点至标记样本集时,通过增加光谱近邻Ψ(xi)来过滤掉背景点、噪声点和分割算法的影响,将Z(xi)中的像素点添加至标记样本集,其标记为xi的标记,形成新的标记样本集L,满足
L=Z(xi)∪XL(1≤i≤m)
(4)
(5)
对X中的每个测试样本点xj分别在L上筛选出xj的超像素空间近邻Ω(xj)和光谱近邻L(xj),形成自适应字典为自适字典中的第k个原子。
1.3 空谱信息的协同竞争重构

(6)
λ——正则化参数

(7)
(8)
λ1——竞争参数
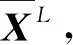
(9)
式中I——t阶单位矩阵
1.4 标记判别

(10)
xj的类别标记lj计算式为
(11)
1.5 算法流程
本文算法步骤如图2所示:①对高光谱图像进行熵率超像素分割。②对带标记的小样本在高光谱图像中计算光谱近邻,并结合超像素分割结果通过式(4)扩展标记样本,形成新的标记样本集。③计算测试样本在扩展标记样本上的光谱近邻,同时结合扩展样本和超像素分割结果根据式(5)生成测试样本的自适应样本集并构建自适应字典。④采用式(9)计算测试样本在自适应字典上的协同竞争表示。⑤依据协同竞争表示系数和自适应字典的类别标记,通过式(10)计算测试样本的类别残差。⑥通过式(11)计算最小类别残差得到高光谱图像的分类结果。
2 实验数据集
本文采用印地安农林和帕维亚大学2个高光谱数据集进行实验,图3和图4分别为这2个数据集的假彩色图像和实际地物图。
印地安农林是由机载可见光/红外成像光谱仪(AVIRIS型)采集的一片农田区域高光谱影像,采集时间为1992年6月,空间分辨率20 m,影像尺寸为145像素×145像素,波长范围为400~2 450 nm,光谱分辨率为10 nm,波段数为220,去除受噪声或水气吸收影响的第104~108波段和第150~163波段以及第220波段,余下的200波段用于实验,共包含16 类不同的农业对象。该影像种类分布不均匀并且存在样本稀少类别,混合了种植作物、林地、草地等,同时影像中种植作物尚处于生长阶段,裸露的土壤与种植作物残渣增加了分类的难度。
帕维亚大学高光谱图像是由机载成像光谱仪(ROSIS型)采集的大学周围影像,采集时间为2002年7月,空间分辨率为1.3 m,影像尺寸为610像素×340像素,波长范围为430~860 nm,共115个波段,去除12个受噪声影响严重的波段,余下103个波段用于实验,共包含9种地物类别。
3 实验结果及分析
3.1 实验设计及评价指标
在印地安农林和帕维亚大学高光谱图像中,为了获取足够的样本信息进行分类,传统训练样本数量取值通常为印地安农林图像中每类10%采样,不足10个训练样本的类别选取10个训练样本,余下样本作测试,帕维亚大学图像每类5%采样,剩余为测试样本。为了减少采样训练样本的数量,在印地安农林图像上按照每类2%随机选取标签训练样本,不足10个训练样本的类别选取10个训练样本,剩余约98%数据作为测试集;在帕维亚大学图像上按照每类1%随机采样,余下99%的数据为测试样本。在Intel i7-8550U CPU,主频为1.8 GHz,内存为8 GB的硬件环境,Matlab2015b软件平台下进行10次实验,取10次实验结果的平均值作为实验结果。
为了验证本文所提方法的有效性,将本文方法与K近邻(K-nearest neighbor,KNN)、SVM、SVMCK[11]、SRC[12]、CRC[13]、JSRC[14]、JCRC[15]、CCJSR[16]方法进行对比,选取生产者精度(Producer’s accuracy,PA)、生产者精度均值(Average accuracy,AA)、总体分类精度(Overall accuracy,OA)和Kappa系数(Kc)作为评价准则。
3.2 参数对分类精度的影响
在本文所提出的算法中,有4个参数需要分析,自适应协同竞争表示中的正则化参数λ、竞争参数λ1、超像素分割区域数p以及光谱近邻数q。图5a为印地安农林图像在分割区域数p为80,光谱近邻数为290,λ1、λ分别在{10-3,10-2,10-1,1,10,102,103}上进行取值所对应OA的影响结果,图5b为帕维亚大学图像在分割区域数p为30,光谱近邻数为5,λ和λ1所对应的OA结果。由图5可见,2幅高光谱图像均在图的最右边(λ=103,λ1=10-3),即在取值区间λ取最大值,λ1取最小值时, OA值最小;然后,随着λ的降低和λ1的增大,OA值在2幅图中均快速提升,随即达到较宽泛平稳的OA最高值。λ1较小时,分类结果不能体现自适应样本间的竞争性,不足以表达样本本征,导致OA在不同的λ取值上波动较大,λ1的引入,协同样本的竞争信息增加,能有效改善分类结果受传统协同表示参数λ的大幅度波动,减少分类结果对参数的敏感性。
为了探究超像素分割区域数p对高光谱遥感图像分类的影响,在印地安农林和帕维亚大学2幅图像中分别对分割区域数[10,200]间隔为10进行实验参数取值,其中λ1为0.1,λ为0.01,光谱近邻数q分别为290和5,图6为区域数p对OA的影响。从图中可见,印地安农林图像和帕维亚大学图像分别在[10,80]和[10,30]超像素分割数目区间随着分割区域数p的增加,可运用的空间信息逐步丰富,OA迅速提升;然后印地安农林图像和帕维亚大学图像在OA达到各自的最大值后随着分割区域数p的继续增加,过多的空间信息对分类精度形成干扰,OA缓慢下降。
图7为2幅高光谱图像中不同光谱近邻数q对OA的影响,其中2幅图像的λ1为0.1,λ为0.01,印地安农林和帕维亚大学2幅图像的分割区域数p分别为80和30。从图7a可知,印地安农林图像在q取值[5,130]区间,可运用的光谱信息逐步增多,OA增加相对较快;在q达到130之后,随着光谱近邻数的进一步增加,OA持续缓慢增加。从图7b可知,帕维亚大学图像对光谱近邻参数q不敏感,变化相对平稳。q在[5,105]区间,随着光谱近邻数的增加,更多光谱信息的引入,OA增加非常缓慢,几近不变;但尺寸为610像素×340像素的帕维亚大学图像,像素数目超过20万,随着更多光谱近邻像素点的引入,在空谱协同时的运行时间势必加长;在q为5时的运行时间为391 s,在q为40时运行时间为2 283 s,在q超过75后,运行时间超过3 600 s。面对对q不敏感的OA增长,在OA和运行时间之间进行平衡,本文对帕维亚大学图像取相对较小的q值5。对比图7a和图7b可见,帕维亚大学图像超像素中的样本较为丰富,反映出其地物分布更密集,因此具有更高的空间特征利用率。
3.3 对比实验结果及分析
表1和表2为不同方法分别在印地安农林和帕维亚大学高光谱图像的PA、AA、OA、Kc和运行时间的结果对比。由表1和表2可知,本文方法在2个数据集上的总体分类精度分别为91.45%和95.54%,相较于其他方法,本文方法在2幅高光谱图像中均有最高的AA、OA和Kc,在印地安农林图像上OA高出其他方法3.48~39.52个百分点,在帕维亚大学数据集上OA高出其他方法2.45~21.63个百分点;同时,在大部分地物中具有较高的分类精度。尤其对印地安农林图像的“草地/牧草”和“建筑-草-树”2类,其训练样本数偏少,仅为10个样本,本文方法相比于其他方法中的最高地物分类精度分别提高了9.33、9.50个百分点;对帕维亚大学图像的砂砾、裸土和地砖3类图像,本文方法相比于其他方法中的最高地物分类精度分别提高了17.70、7.60、7.79个百分点。

表1 不同方法在印地安农林高光谱图像的分类效果对比Tab.1 Classification results with different methods on Indian Pines HSI

表2 不同方法在帕维亚大学高光谱图像的分类效果对比Tab.2 Classification results with different methods on Pavia University HSI
图8和图9分别为实验中印地安农林和帕维亚大学高光谱图像一次随机抽样的训练样本图、测试样本的真实地物类别图以及采用不同方法进行分类后的地物分类效果。从图8和图9可见,在2幅高光谱图像上,和仅用光谱信息的KNN、SVM、SRC、CRC相比,加入空间信息的SVMCK、JSRC、CCJSR、JCRC和本文方法分类效果明显更为光滑,错分点相对较少。由图8可知,在印地安农林图像上,虽然本文分类效果图仍存在点状噪声,但块状噪声相对较少。为了进行对比,在4个方法(JSRC、CCJSR、JCRC和本文方法)的效果图上绘制了3个白色矩形框,这3个矩形框中的地物样本较少,地物周围种类较为复杂,在测试样本受局部空间多类别样本干扰时,本文方法尤其显示出了更好的分类效果,错分率明显低于其他3种方法。由图9可见,在帕维亚大学高光谱图像上, JSRC、CCJSR、JCRC由于固定的块状空间滤波,均呈现出大量大块的噪声点,而本文超像素分割更贴近地物细节,地物分类结果图中噪声点相对较少。
4 结论
(1)针对小样本下提高高光谱图像分类性能问题,提出了高光谱图像分类的自适应字典分类方法。通过协同扩展小样本构建的自适应字典原子,可以缓解小样本问题,在小样本下印地安农林图像数据集总体分类精度为91.45%,比其他方法提高3.48~39.52个百分点,在帕维亚大学数据集上总体分类精度达到95.54%,比其他方法提高2.45~21.63个百分点。
(2)与固定窗口尺寸的空间信息表达相比,在高光谱图像分类中运用超像素表示局部空间信息,能在分类结果中更好地保持图像的局部细节,降低分类中的块状噪声。
(3)在高光谱图像分类中,过多的超像素分割数对分类形成干扰,导致分类精度下降,光谱近邻数的增加影响分类时间,空谱自适应字典原子间竞争性的表达可以弥补协同表示在高光谱图像分类中的不足。
