一种深度学习的网络安全态势评估方法
2021-01-29杨宏宇曾仁韵
杨宏宇,曾仁韵
(中国民航大学 计算机科学与技术学院,天津 300300)
近年来,随着互联网的快速发展,通过互联网进行的攻击问题越来越频繁,带来的危害也越来越严重。 我国互联网态势报告[1]中指出,在2019年上半年,我国网络遭受了大量的、多样的威胁攻击,并针对此情况开展了网络安全威胁治理工作;其中,采用的一个重要手段就是网络安全态势评估。网络安全态势评估是一种常用的、有效的解决方案。它综合了影响网络安全的指标,为网络管理人员提供决策意见,从最大程度上降低网络攻击威胁产生的危害[2]。
文献[3]提出了基于层次分析法和灰色关联分析的多维系统安全评价方法,以系统安全评价模型构建原则为指导,构建了环境安全、网络安全、脆弱性安全的多维系统安全评价模型。文献[4]将互联网受到的网络威胁作为态势评估的重要指标,利用模糊逻辑推理系统改进网络安全威胁评估模型。然而,上述方式在面对新型的网络威胁攻击时不能做出及时反应。
随着神经网络、机器学习等信息技术在许多领域的成功应用,在信息安全领域开始尝试将这些技术融入网络威胁态势评估。文献[5]引入动量因子,对搜索算法进行了优化,提出了一种改进反向传播神经网络的网络安全态势定量评估方法。文献[6]提出了结合朴素贝叶斯分类器的网络安全态势评估方法,从整体动态上展示网络当前安全状况。文献[7]结合支持向量机,并改良了布谷鸟算法预测网络安全态势,该方法在KDD数据集上的性能达到了较高的精度。上述方法可以动态评估网络安全态势,但是面对如今的大量网络威胁数据,已经不能满足实时、直观的评估需求。
在大数据背景下,结合深度神经网络的算法已经应用于海量威胁攻击数据检测。文献[8]通过实验表明,相对于传统的浅层网络方法,深层网络在检测网络威胁攻击方面更加准确和有效。文献[9]应用长短期记忆网络(Long-Short-Term Memory,LSTM)在CIDDS-001数据集上进行训练和测试。尽管实验结果取得较高的准确率,但是文中选择的测试集是训练集的一部分,因此没有表现出模型的泛化性。文献[10]将自我学习(Self-Taught Learning,STL)与稀疏自动编码器(Sparse Auto Encoder,SAE)相结合,对NSL-KDD数据集的检测准确率有很大的提升。然而,该方法在训练过程中抑制了某些神经元的传播而且易出现不同数量的样本检测结果不平衡的现象。
针对上述方法的不足,笔者提出了基于深度学习的网络安全态势评估方法。为了解决数据集中不同类型攻击的分类结果极度不平衡问题,提出一种欠过采样加权(Under-Over Sampling Weighted,UOSW)算法对数据集进行处理,结合深度自动编码器(Deep Auto Encoder,DAE)对网络攻击进行分类。在得到网络攻击分类后,对每种攻击类型进行影响评估,并对网络安全状况进行量化评估。通过实验,证明文中方法可实现对网络安全状况的实时评估,评估效果更加高效、直观,性能指标优于其他模型。
1 网络安全态势评估模型
笔者设计的网络安全态势评估模型包括态势获取、态势分析和态势评估3个部分。网络安全态势评估模型的结构如图1所示。

图1 网络安全态势评估模型
(1) 态势获取
在此阶段,获取网络中的流量数据。为了模拟网络处理海量流量数据的情况,选取上述NSL-KDD数据集作为网络流量。数据预处理后,输入深度自编码器进行训练。
(2) 态势分析
将测试 数据集输入训练后的模型,记录结果输出的二分类结果和多分类结果,用于计算网络安全态势量化值。
(3) 态势评估
根据测试的攻击分类结果,计算网络攻击概率和各种网络攻击的影响值。另外,计算网络安全态势值并对网络安全态势进行评估。详细计算方法见下文。
2 深度自编码器
2.1 深度自编码器设计
2.1.1 模型结构
自动编码器(Auto Encoder,AE)由编码器和解码器组成,主要应用于数据降维和特征学习。输入数据通过编码器被映射到解码器,解码器可以用更精简的特征描述原始数据。深度自动编码器(Deep Auto Encoder,DAE)是一种改进的自动编码器模型。文献[11]深化了原有自动编码器的网络结构,生成了DAE网络。因为含有隐藏层更多,DAE的学习能力得到了提高,这使得它更有利于特征学习。
深度神经网络(Deep Neural Network,DNN)由于其准确性和高效性,在入侵检测中得到了广泛的应用。由于DNN包含了多个隐藏层,使得它的学习能力显著提高。与传统的机器学习分类器相比,DNN可以在更短的时间内获得更准确的分类结果,因此,选择DNN作为网络攻击数据的分类器,所提出的深度自编码器模型(Deep Auto Encoder Deep Neural Network,DAEDNN)如图2所示。

图2 DAEDNN模型
由图2可见,模型接收输入数据后,先通过DAE网络进行特征学习并记录学习结果,根据学习结果和DNN分类器,将输入数据进行分类,而后将其分类结果应用于后续的网络安全态势量化评估过程。
DAEDNN模型不仅可以进行二分类,也可以进行多分类。在进行二分类任务时,模型的激活函数为sigmoid函数,sigmoid函数将模型输出值映射到0和1区间,其中,数值越靠近1,则越容易被判定为异常流量。sigmoid函数(Fsgm)的计算公式如下,
Fsgm(x)=(1+e-x)-1。
(1)
当模型进行多分类任务时,模型的激活函数为softmax函数,softmax也是将输出映射到0和1区间,但是与sigmoid函数不同的是,各个类别的输出值相加的值等于1,模型选择输出值最大的类别为预测的类别。softmax函数(Fsfm)的计算公式如下,
(2)
其中,K表示输出可以被分为K个类,zi表示每一类所取得的值。
2.1.2 模型训练
在DAEDNN模型中,DAE模型进行特征学习。为了让DNN分类器充分学习DAE的特征提取结果和提高模型性能,减少模型过拟合的风险,应分次训练DAEDNN模型。
模型训练分为3个步骤:① 将训练数据输入至DAE网络,进行特征学习,记录训练完成的权重值。② DAE 模型训练结束后,组合DAE模型和DNN模型为DAEDNN模型,一起训练这两个网络。为了获取DAE模型的训练结果,将DAEDNN模型中的DAE网络的权重值设置为保留的权重值,并把DAE层的参数设置为不可训练,与DNN网络一起进行训练,此时网络只会更新DNN网络的参数。③ 将DAE层的参数设置为可训练,更新DAE网络和DNN网络的参数。训练过程中更新训练参数,不仅可以获取DAE层的特征学习结果,也提高了模型对数据的表征能力。
2.2 欠过采样加权数据重采样算法
2.2.1 数据集描述
选择网络安全领域相对权威的入侵检测数据集NSL-KDD作为评估的数据源。NSL-KDD数据集改良于KDD99数据集,它删除了重复的网络流量数据记录,这有助于分类器产生无偏差的结果[12]。NSL-KDD数据集包含41个特征和5种主要攻击类型。文中使用的数据集信息如表1所示。

表1 KDD-NSL数据集信息
2.2.2 数据预处理
为了更方便、准确地训练网络模型,需要将数据集中的分类特征转换为数字特征,并进行数值归一化。
(1) 特征数值化
NSL-KDD数据集有3个分类特征“protocol_type”、“service”和“flag”,分别包括3、64和10个类别。通过独热编码技术,将这3种分类特征转化为只表示0和1的数据。对这3个分类特征进行处理之后,数据集由41个特征维度变为116个特征维度。
(2) 数值归一化
数据集中某些特征的最小值与最大值之间存在显著差异。为了减少不同数值水平对模型的负面影响,文中采用对数标度法对特征值进行标度,使其归一化到同一区间。数值归一化的过程可以表示为
xnorm=(x-xmin)/(xmax-xmin) ,
(3)
其中,x表示特征原本的值,xmax和xmin为特征所取得的最大值和最小值。
2.2.3 欠过采样加权数据重采样算法
由表1可见,在训练数据集中,5类攻击的数据量非常不均匀,其中,数据量最大的nomal类有67 343 条数据,而DoS和U2R这两种类型只包含52和995条数据。在训练深度学习模型的过程中,若训练数据较少,则会导致模型无法充分学习数据的特征,而若训练数据过多,则又可能导致模型过拟合,即模型学习到了数据本身以外的特征。因此,极不平衡的数据会导致模型的学习效果不佳,导致数据量大的类别识别准确度较高,反之较小。
数据分析中的过采样和欠采样是用来调整数据集类分布的技术,也称为数据重采样。欠采样通常是删除数据量过大的类别的些许样本,而过采样增加了数据中少数样本的数据量,以达到数据平衡。为解决数据量分布不平衡的问题,提高模型检测少数类的精度,笔者提出一种过采样、欠采样和加权相结合的欠过采样加权(Under-Over Sampling Weighted,UOSW)算法。该算法步骤设计如下:
设原始数据集为S1,输出的数据集为S2,需要进行重采样处理的数据类型为typei,其原始数据集和样本数量为Si和xi。
步骤1 计算数据集中每种类型的权重wi。在网络训练中,当训练集中每个类别的数据量非常接近(达到平均值,以下用average代替)时,网络的识别准确率会很高。因此,文中计算每种类型的实际样本量与理想样本量之间的差值作为权重,以达到每种类型的均衡值。
(4)
其中,n表示数据集包含n种类别。
步骤2 数据欠采样。对于数据量过大的类型,进行数据欠采样,使处理后的数据样本接近平均值(average)。使用Python中sklearn库的“train_test_split”方法将数据集Si分为两个数据集Si-train,Si-remain。将Si-train作为训练集,并加入S2,其中,Si-train的数据量大小si=xi×wi;Si-remain用于接下来的数据过采样操作,将其加入数据集Sremain。
步骤 3 数据过采样。应用过采样算法SMOTE[13]处理数据量很少的类别的样本。SMOTE的核心是在现有少数类样本的基础上生成新的同类样本。由于SMOTE算法最初是针对二分类问题,而本文研究中存在多分类问题,因此对算法进行了以下改进:
(1) 合并其他类型数据。将步骤2中经过欠采样处理的数据集Sremain和原始数据集中的少量类型的数据集合并,表示为Sunion。
(2) 改变标签。经过(1),Sunion中包含与n种类别的数据。由于SMOTE算法只针对于二分类,因此要将需要进行过采样的类型与其他类型区分开来。将数据集Sunion的标签更改为同一类型,但不同于typei。
(3) 确定数据量大小。为了平衡数据集,需要对少数类样本进行扩展,设扩展后的数据量大小为si其中,si=xi×wi,wi是数据类型typei的权重。
(4) 数据过采样。使用Python中imblearn库的SMOTE方法,结合其他类型的数据生成所需的数据,将其加入S2。
重复(1)~(4),直到数据量少于平均值的类型全部完成过采样操作。
3 网络安全态势评估
3.1 网络攻击影响值
NSL-KDD数据集包括5种类型的网络数据:Normal、DoS、U2R、R2L和Probe。上述攻击的基本信息如表2所示。

表2 5种攻击类型的基本情况
基于通用漏洞评分系统(CVSS)制定了攻击影响值评定表[14]。机密性(C)、完整性(I)和可用性(A)得分如表3所示。

表3 攻击影响值评定表
每种攻击类型的影响值(Ii)计算公式如下:
Ii=Ci+Ii+Ai。
(5)
3.2 网络安全态势量化
量化网络安全态势,可以更直观地分析网络整体状况。本文的网络安全态势量化评估过程主要包括4个部分:攻击分析、计算攻击的影响、计算网络安全态势值和网络安全态势定量评估。每个部分的处理过程设计如下:
(1) 攻击分析
从测试数据集中随机选取若干组数据,并将其输入到DAEDNN模型中,对其进行二进制和多分类,记二分类中检测到的攻击比例记为攻击概率(attack probability,p)。
(2) 计算攻击的影响值
结合表2、表3确定每一类攻击类型的C、I、A值,并根据式(5)确定综合的攻击影响值。
(3) 计算网络安全态势值
网络安全态势值综合考虑了网络受到的全部攻击和每种攻击会对网络造成的危害程度。设网络安全态势值为
(6)
其中,p为式(1)中所得出的攻击概率,n和N表示一共有n种类型的数据和N个样本,Ii表示每种攻击类型的影响值,ti表示每种攻击的出现次数,tn为normal类型出现的次数。由于normal类型是正常的网络数据流,对网络的机密性、完整性和可用性不会有影响,因此它的影响分数为0,只需要计算n-1种攻击类型的影响分值即可。
(4) 网络安全态势定量评估
参考《国家突发公共事件应急预案》[15]对网络安全形势进行分类。根据网络安全态势值0.00~0.20、0.21~0.40、0.41~0.60、0.61~0.80和0.81~1.00的5个区间,将网络安全态势严重程度划分为安全、低风险、中等风险、高风险和超风险等5个级别。
4 实验结果与分析
实验的硬件环境为:Intel(R) Xeon(R) Silver处理器,显卡为NVIDIA Quadro P2000,内存为32 GB。训练和测试实验均在Windows 64位操作系统上进行。使用的编程语言和机器学习库为Python3.5和TensorFlow2.0。模型的训练和测试均使用GPU加速。
4.1 评价指标
文中所用的评价指标如下所示:
真阳性(True Positive,TP):表示被模型预测为攻击样本而实际也是攻击样本的次数。
假阳性(False Positive,FP):表示被模型预测为正常样本而实际是攻击样本的次数。
真阴性(True Negative,TN):表示被模型预测为正常样本而实际也是正常样本的次数。
假阴性(False Negative,FN):表示被模型预测为攻击样本而实际是正常样本的次数。
下列公式中,PT,PF,NT和NF分别表示真阳性,假阳性,真阴性和假阴性。
准确率(Precision,P):表示模型预测正确的攻击样本频率。准确率越高,误报率越低。它可以表示为
P=PT/(PT+PF) 。
(7)
召回率(Recall,R):表示被模型正确分类的攻击样本与实际攻击样本的百分比。它可以表示为
R=PT/(PT+NF) 。
(8)
F1值(F1-score,F):表示综合考虑了模型的准确率和召回率。它可以表示为
F=2PR/(P+R) 。
(9)
4.2 模型二分类结果
在二分类任务时,选择ROC曲线和AUC面积来反映分类模型的性能。ROC曲线表示不同阈值设置下分类模型的性能;AUC面积为ROC曲线下的面积。面积越大,表示模型的性能越好;通过面积可以直观地对比各个模型。
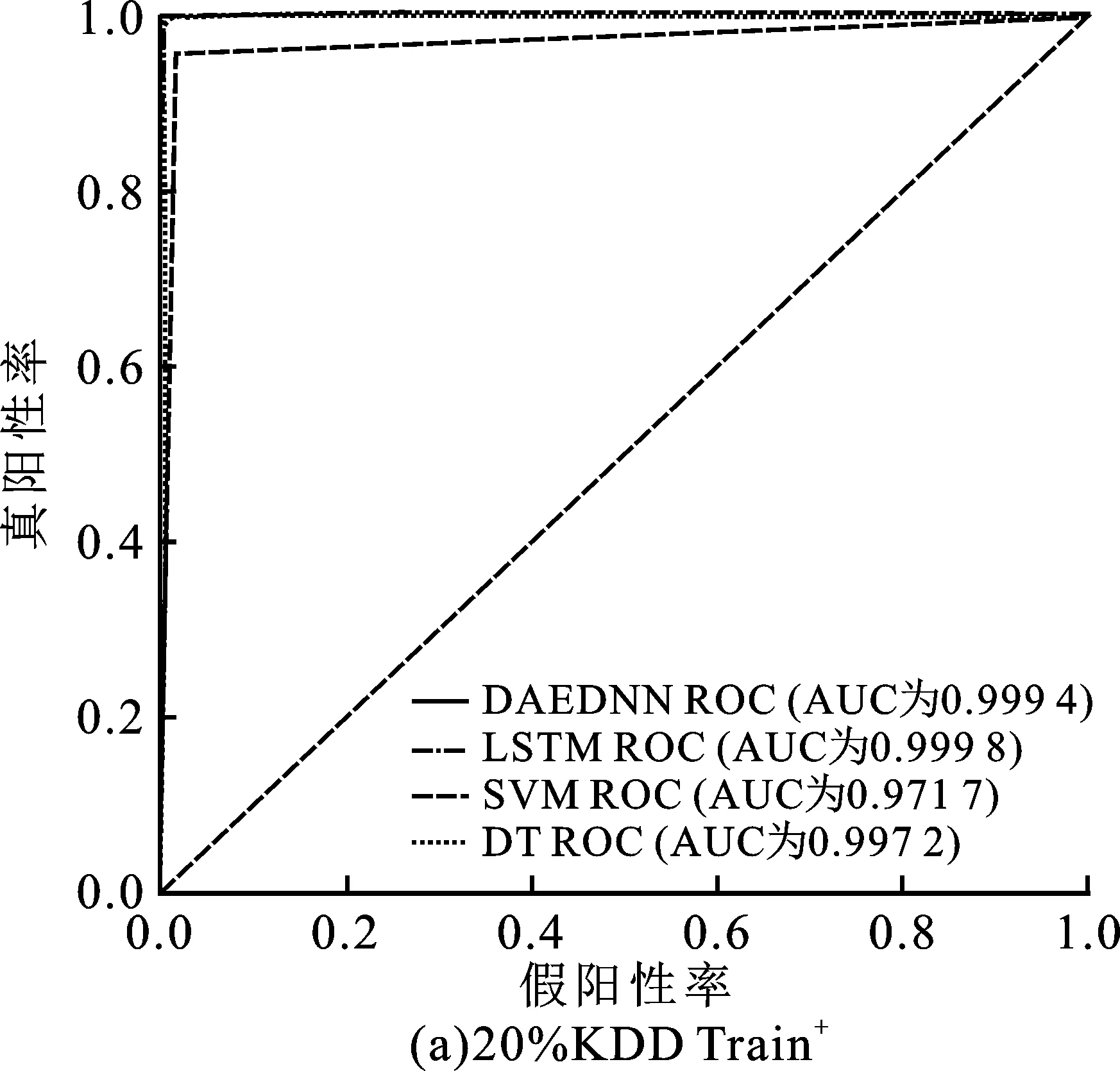
在二值分类任务中,模型只需要区分数据是攻击数据还是正常数据。为了检验文中模型的有效性,将笔者提出的DAEDNN与决策树(Decision Tree,DT)[8]、支持向量机(Support Vector Machine,SVM)[8]和长短期记忆网络(Long Short-Term Memory,LSTM)[9]等模型进行了比较。为了验证文中模型的泛化性,使用KDDTrain+的80%数据进行训练,分别对剩下的20%和KDDTest+进行测试。4种模型的二分类结果如图3所示。
从图3(a)可以看出,在使用20% KDDTrain+对4种模型进行测试时,4种模型均表现出较好的准确性和泛化能力。这是由于训练集和测试集来源于同一集合,模型学习到的特征可以完全应用于测试数据集,所以能得到理想的结果。然而,从图3(b)可见,如果使用KDDTest+数据集作为测试数据集,4个模型的准确性则会降低。这是因为测试训练集中存在一些与训练数据集数据格式不同的样本,这种情况与真实的网络情况一致,即模型面临众多未知攻击类型。从图3(b)可见,在使用KDDTest+数据集进行模型测试的情况下,DAEDNN模型的准确率明显优于其他3个模型,分别比DT、SVM和LSTM高出近13.35%、16.17%和2.72%,说明DAEDNN模型的学习能力更强,具有较好的泛化性。
4.3 模型五分类结果
使用KDDTest+数据集对DT、SVM、LSTM、DAEDNN和应用UOSW算法的DAENDD这5种模型进行检验,并选取准确率、召回率和F1值作为评价指标,对各种模型进行比较分析。不同模型的指标得分如图4所示,图中的纵坐标表示评价指标的百分数,数值越高,模型性能越好。

图4 不同模型的各类指标得分
从图4可见,DAEDNN(UOSW)模型在准确率、召回率和F1值等方面都优于其他4种模型。实验结果表明,DAEDNN(UOSW)提高了少数训练数据样本的攻击类型的召回率和准确率,而对拥有大量训练样本的攻击检测性能并没有降低。
值得注意的是,结合文中的UOSW算法后,DAEDNN的准确率和召回率更高,泛化能力更强。与DT、SVM和LSTM模型相比,DAEDNN(UOSW)的F1值分别提高了约2.77%、10.5%和5.2%。
4.4 网络安全态势量化评估
从测试数据集中随机选取相同数量的测试样本,对网络安全状况进行了量化评估,并对于分别用不同的模型计算网络安全态势值,其中20组测试的网络安全态势值如图5所示。

图5 20组测试的网络安全态势值
由图5可见,基于DAEDNN模型计算出的网络安全态势值最贴合样本的实际安全态势值,相比于SVM和DT这两类传统的机器学习模型,DAEDNN和LSTM这两类深度学习的方法更能表示数据的真实情况。其他3种模型的态势值与实际态势值相差较大的原因是,训练样本中存在样本量极少的攻击类型,导致模型无法充分学习到这类攻击的特征。而DAEDNN模型应用了UOSW算法,提高了模型检测少样本攻击类型的准确率。所提出模型计算出的态势值与实际态势值之间存在些许差异,但大多数态势值都落在了相同的区域内,根据3.2节定义的网络安全态势严重程度和实际情况相符。
5 结束语
笔者针对传统网络安全态势评估方法在处理大量网络数据时效率低的缺点,提出一种深度学习的网络安全态势评估方法。该方法首先结合了自动编码器和深度神经网络组成DAEDNN模型,用于对网络攻击进行识别。根据识别的结果,计算攻击概率和攻击影响值,从而得出网络安全态势量化值。通过安全态势量化值,可以更直观地反映网络安全态势。实验结果表明,笔者提出的模型在二分类和多分类的攻击检测方面优于其他模型。此外,在进行多种攻击类型检测时,结合所提出的UOSW算法,可以提高模型对拥有少量训练样本的攻击的检测准确率,从而可以更准确地评估网络安全态势。
