Lucene的网络资源索引信息动态检索系统设计
2021-01-28贾晓霞神木职业技术学院公共课教学部陕西榆林719300
贾晓霞(神木职业技术学院 公共课教学部, 陕西 榆林 719300)
0 引言
大数据发展的时代下,网络中的数据信息量迅速增多,因此动态检索系统随之出现,为了推动海量数据信息动态检索系统的优化与发展,引入Lucene全文检索工具,其中网络资源索引信息的全文搜索是以数据库中的海量文献信息作为检索对象,通过设置的检索目标,实现对海量网络资源的检索[1]。Lucene全文检索工具不是一个完整的全文搜索引擎,而是一个引擎框架,根据该框架构建一个完整的检索引擎,还有许多工作要做。国外对于Lucene全文检索工具的应用较早,经调查,Lucene检索系统最早出现于1940年美国人口数据普查中,该系统面对海量的人口信息数据,利用识别技术改进Lucene的检索功能,实现对人口信息的检索。同时对比国内,对Lucene动态检索系统的研究与设计还处于探索阶段,但随着近些年来的不断探究与分析,我国Lucene动态检索系统的设计也取得了不错的成绩。当前阶段,文献[2]所提到的Lucene动态检索系统,通过分析Lucene的索引方法,设计该检索系统的动态检索程序,但随着大数据发展,该系统的应用已经存在检索漏洞,因此设计一个全新的Lucene的网络资源索引信息动态检索系统[2]是很有必要的。重新设计该系统的意义,就在于满足人们对网络资源的需求,通过更加完整的系统检索,得到与需求更加匹配的索引信息,所以设计一个稳定的、高效的和全面的检索系统势在必行。
1 Lucene的网络资源索引信息动态检索系统
Lucene作为一个全文检索引擎的架构,要想将其完全应用于网络资源索引信息动态检索系统中,需要开发者在Lucene的基础上进行二次开发,已知Lucene向检索系统提供了分析接口、索引引擎、存储管理和查询引擎。Lucene 的核心逻辑架构[3],如图1所示。
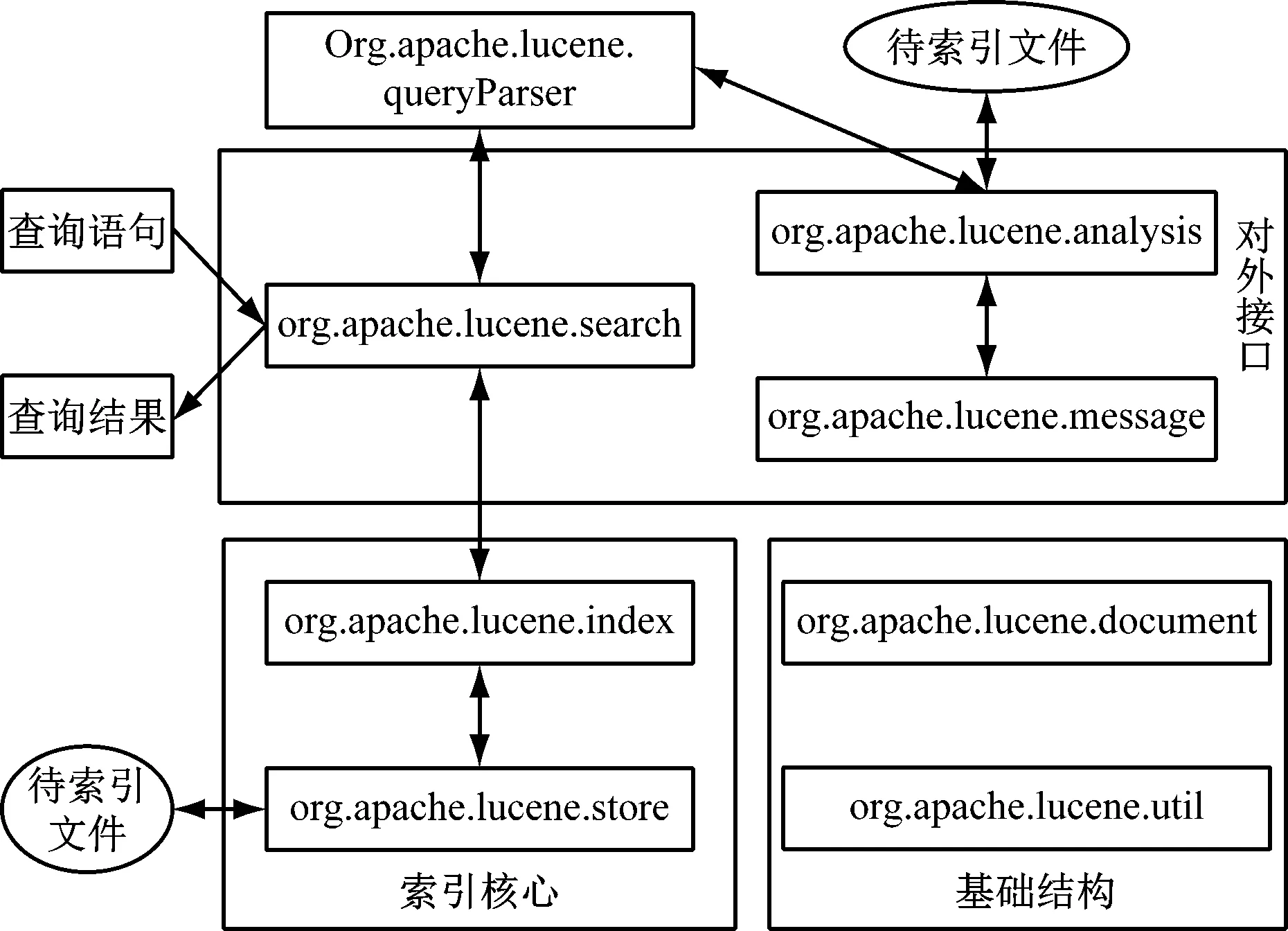
图1 Lucene核心逻辑架构
由图1可知,查询者通过查询语句搜索到查询结果,再把待索引文件进行索引,保存得到的结果;或者检查者直接对待索引文件进行分析,通过对外接口发送消息,其中基础结构包括文件和工具包,根据逻辑图我们可以看到,Lucene运行时,各个模块之间的调用关系,其中接口模块,通过语法分析器分析索引文本,并结合基础结构公共模块,将分析后的数据写入索引文件中,使用者进行查询时,通过接口模块将查询语句发送到索引核心模块,通过读取索引文件中的数据,得到检索结果,并执行反馈操作。
1.1 系统整体框架
Lucene的网络资源索引信息动态检索系统,其整体框架由三部分组成,页面层、控制层和数据库层,如图2所示[4]。

图2 系统整体框架
以中间控制层为核心,通过Lucene连接页面层和数据层,实现索引信息的全区域检索。
1.2 设计网络资源索引信息动态检索系统硬件
为了保证在海量信息中,可以无间断、高效、快速获取检索结果,需要设计网络资源索引信息动态检索系统硬件,通过改变原有检索系统中的部分硬件设备,提升检索系统的稳定性。而检索系统硬件的选择,自然想到了通过改变系统硬件的并行度,提高系统检索效率。已知检索系统会存在多个子系统并行检索信息的情况,根据这些被划分成多个子模块的检索任务,重新选取若干个功能更好的处理器与检索系统建立连接,该处理器共有64位,可以对同步进行的子任务执行加速操作。重新选择的处理器,与计算机连接后的实物图[5],如图3所示。

图3 处理器实物图
该处理器为每一子模块之间、子模块与索引信息之间的信息检索,提供高效的反应速度,同时在该处理器的连接下,保证系统其它硬件之间的数据传递,不会在信息传送途中遗漏关键信息,可以为检索系统的实时检索提供更加严谨的技术支持。
2 设计Lucene的网络资源索引信息动态检索系统软件
由于网络资源索引信息动态检索系统所需的支持硬件不多,因此只需将处理器改进即可。在此基础上,对网络资源索引信息动态检索系统软件展开设计。
2.1 设计网络资源分词方式
网络资源是面向普罗大众的,虽然其知识专业性不强,但由于涵盖的知识范围广,知识点数据量大因此检索不易。对于设计网络资源索引信息动态检索系统软件,应该设计网络资源分词方式[6]。中文分词是Lucene全文检索中核心的处理步骤,当对网络资源进行索引和搜索时,都会需要进行中文分词。设计的分词方式,通过分析用户输入的关键词,得出检索目标。设K=k1,k2,…,kn为待切分的网络资源字符串,其中ki(n=1,2,…,n)为字符串中的单个汉字字符,假设{k1k2}、{k2…kj}是待检索数据库中的字串,存在约束条件n≥j≥4,利用最大匹配法进行第一次切分,如式(1)。
(1)
式中,K2为数据库中相似的网络资源字符串[7]。此时最长的词{k2…kj}并没有被单独切分,假设待切分网络资源字符串的长度为n,数据库中的字符串,其中最长句段的长度为i,利用归左原则进行切分,提取网络资源字段中的前i个字,将它与检索数据库中的词条分别进行匹配,当没有语句与当前的字符串匹配时,则取第2个到第i+1个字符重复上述步骤[8]。当出现匹配成功字样时,将成功的字符串从一个句子中,单独切分出去,将其作为一个独立的检索目标,同时将原句中,除了该词之外的语句组成新的句式结构,继续进行匹配。若匹配i长度字串均失败,则对匹配长度为i-1的词,重复此步骤,直到网络资源的整个句子被完全切分[9-10]。下面所示部分的代码,为设计网络资源分词方式的关键步骤代码。
Dispart( K[0], K[n-1] ) {
for(int j=maxlength; j>=1; j--)
{
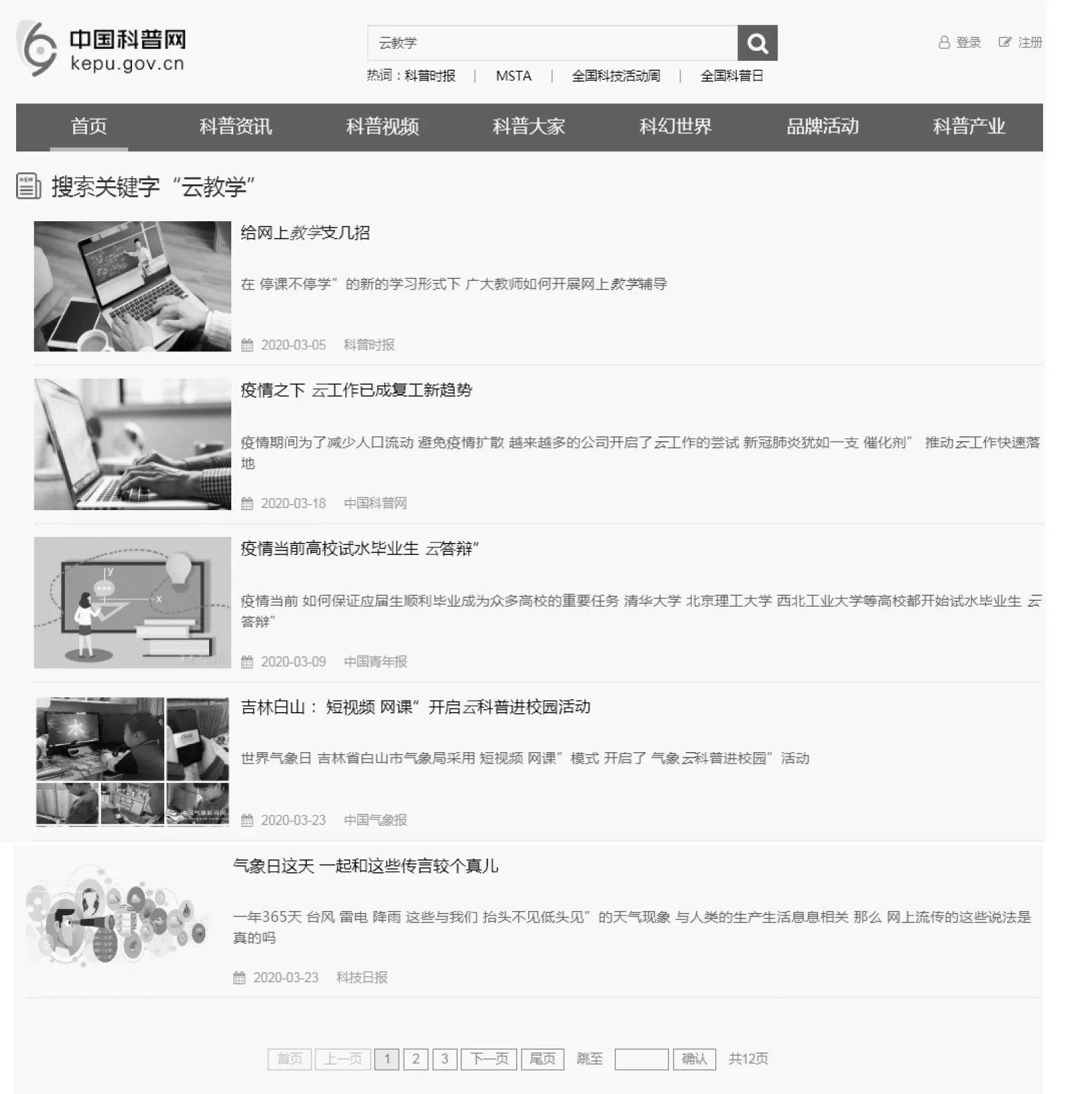
for(int i=0; i { if(match( K[i], j)) { stringDispart(K[i], j); if(i>0) Dispart( K[0], K[i-1] ); else if(i+j Dispart( K[i+j+1], K[n-1] ); } 根据上述代码,设计网络资源在进行动态检索之前,对于语句的分词方式,为检索数据库中的海量网络资源的动态检索,提供目标。 影响检索速度的两个关键信息,一个是检索目标的确认,另一个是对同类网络资源索引信息的合并优化,因此利用Lucene设计索引信息的动态检索。首先对与检索目标的位置确认优化设计,要确定检索数据库中检索目标在标题处位置权重[11-12],如式(2)。 ωa∈q,title=μσa∈q,title (2) 式中,a表示检索目标;q表示检索数据库中,所有网络资源索引信息;ωa∈q,title表示检索目标在查询标题中的位置权重;μ表示检索目标在标题中的出现频次;σa∈q,title表示检索目标的词量数目。其次还要确定检索目标在正文位置中的出现权重[13-14],如式(3)。 (3) 式中,m表示检索目标在正文中的出现频次;ωa∈q,text表示检索目标在正文中的位置权重;σa∈q,text表示检索目标的词量数目;|f|表示待检索数据库中的特征词总数。根据上述公式所获结果,设计海量数据信息下,Lucene对索引信息的全文动态检索,如图4所示。 图4 Lucene对索引信息的动态检索方案 由图4可知,对待索引数据进行信息提取,得到数据字符串,将字符串进行分词写入索引文件,再读取索引,通过搜索索引确定是否合并,如果是,进行相关性排序,得到检索结果;对于科普文献索引信息,先进行分词,再搜索索引,确定是否合并,如果是,则重复上述操作。按照检索目标在标题处的位置权重、以及在正文位置中出现的权重,完成对检索目标的加载设置;同时利用Lucene进行数据检测,根据得到的子类数据,自动执行同类网络资源索引信息合并,至此Lucene的网络资源索引信息动态检索系统设计完毕[15-16]。 搭建实验测试环境,检测此次设计的检索系统,和文献[2]所设计的系统的检索差异。已知实验测试环境的选择,会直接影响所设计系统的功能和效率,因此需要注意实验测试环境中的硬件选择,保证实验测试环境中的测试硬件与两个系统可以兼容。 由于网络资源数量庞大,特选取其中的科普文献作为参照。选取一个科普文献查询网站Z,将其作为实验测试对象来源网站,对其中的6种网络资源进行动态检索。该网站的初始登录页面,如图5所示。 图5 网络资源中科普类网站登录界面 为保证实验测试结果的可靠性,计算该网站中每一类科普文献在一年内的平均检索率,如表1所示。 表1 科普文献信息 由表1可知,在该科普类网络资源检索网站中,同样的科普信息数据在两次检测下,其平均检索率较为接近,因此可知选取的科普类文献在该网站中被活跃使用,可以将这几项数据作为实验测试对象。已知01科普文献的类别为健康类;02为教育类;03是自然科学类;04是天文类;05为环保类;06为农业类,不同的科普文献保证了系统功能测试的不唯一性。将两个检索系统与该网站之间建立连接,保证运行顺畅后考试实验。 实验将此次设计的系统运行测试结果作为实验组,将文献[2]设计的系统运行测试结果作为对照组,在表1中,选择科普类网络资源中Z-02类的科普文献作为测试对象,两组页面,为不同检索系统对同一科普文献索引的动态检索结果,如图6所示。 a 实验组检索页面 根据上述两组动态检索结果可知,此次设计的动态检索系统,利用Lucene全文检索工具,将网站Z中的以“云教学”为关键词的科普文献Z-02,全部检索出来;而文献[2]的系统,由于只计算了关键词在标题处的位置权重,因此只得到1页检索结果。为了保证测试结果的可靠性,将Z-05作为实验测试对象,以“农村景观保护”为科普文献索引信息关键词,分别利用两个系统对其进行信息检索,为两个实验测试组的检索结果,如图7所示。 a 实验组检索页面 根据图中的检索页面可知,在同样的关键词之下,实验组检索得到的网络资源中的科普文献共有29页,而对照组中的检索页面,只有一页,同时该页面内的科普文献数量也只有4个。综合上述两组实验测试结果可知,此次设计的检索系统的性能更好,可以针对不同的索引信息位置,获取数量更多、范围更广的网络资源中的科普文献。 此次设计的检索系统,充分发挥了Lucene工具检索特点,通过计算多个角度的索引信息权重,保证系统对海量网络资源的逐一筛选。该检索系统在获取索引信息、合并同类数据上,得到了极大提升,通过逐层筛选,保证检索结果的匹配性和准确性。但此次设计的系统仍然存在一些不足,第一是没有将题目相关与内容相关进行区分;第二是没有根据文献年份进行排序,这两个不足之处会影响使用者对网络资源重要性的判断,因此在今后的检索系统优化设计中需要加以改进。2.2 基于Lucene设计索引信息的动态检索
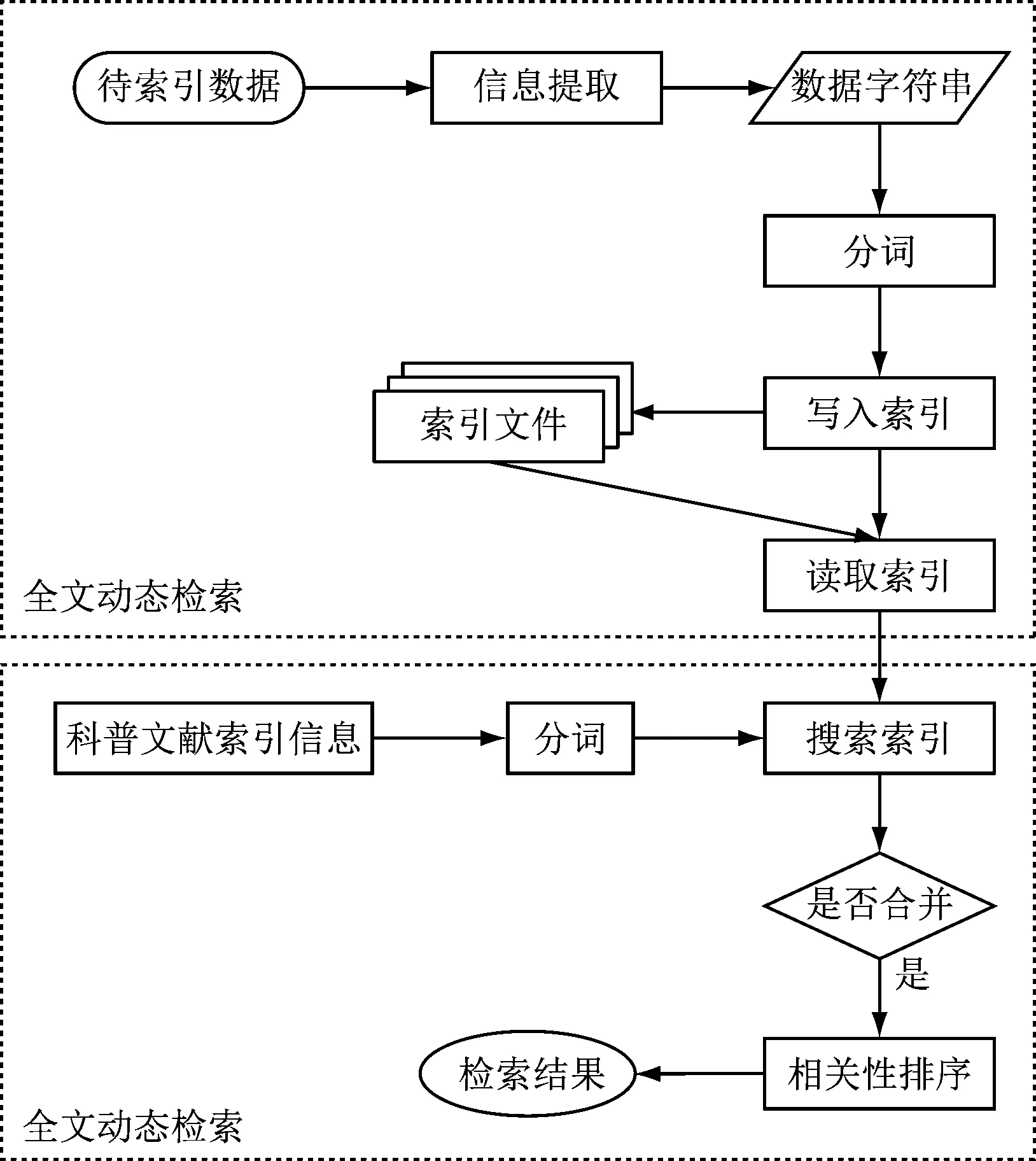
3 实验与分析
3.1 准备阶段

3.2 结果与分析
4 总结
