基于交互效应Logistic回归模型的耕地质量评价方法研究
2021-01-28唐宗周悟杨颢谢晓瑜胡月明
唐宗,周悟,杨颢,谢晓瑜,胡月明*
1. 华南农业大学资源环境学院,广东 广州 510642;2. 广东省土地利用与整治重点实验室,广东 广州 510642;3. 广东省土地信息工程技术研究中心,广东 广州 510642;4. 自然资源部建设用地再开发重点实验室,广东 广州 510642
耕地与人类的生活息息相关,是农作物赖以生存的土地,直接决定了粮食的产量、质量和农业生产的可持续性(毛雪等,2019)。中国耕地质量问题日益突出,一方面,随着进入城市化、工业化和全球化快速发展的新阶段,大量耕地被占用、非农化和非粮化利用,中国1.2亿公顷耕地“安全底线”面临严峻考验;另一方面,工业废气废水排放、农业面源污染等加剧了耕地环境的恶化,导致土壤退化,作物生产能力下降,威胁粮食安全,并影响生物多样性(German et al.,2017)。在耕地数量和质量不断下降的背景下,积极开展耕地质量评价研究,成为中国未来耕地保护和粮食增产的优先选择和关键途径之一。
在耕地质量评价工作中,根据所选指标和分析目标的不同,评价方法也不尽相同,据目前研究来看,主要可以分为3种,第一种方法是基于样本信息,主要包括特尔菲法(明亮,2016)、经验判断指数和法(彭一平等,2019)、层次分析法(明亮,2016;汪雨琴等,2017)、灰色关联度分析法(叶青等,2008)、模糊评价法(兰民均等,2015)等,国土资源部开展农用地分等工作多采用这种方法,但是这种方法在对评价指标权重设定上以及相关信息的取舍上需要依靠专家经验来确定,主观性较强,影响评价结果准确性(林子聪等,2020)。第二种方法主要是利用GIS空间分析和RS快速监测技术,GIS为标准化耕地数据的衔接、时空分析提供了基础,RS技术用于耕地质量评价,能不断提供地表信息,对耕地进行动态监测,但第二种方法评价步骤较为繁琐,数据处理工作量大,人工成本高。第三种是利用数据挖掘技术,从数据挖掘的角度来看,耕地评价实质上属于分类预测问题,如应用关联规则(杨敬锋等,2008)、决策树模型(张孟容等,2016)、遗传算法、神经网络模型(吴利等,2019;叶云等,2018)等对耕地质量进行等级划分,这些方法在处理耕地质量各种指标综合作用的非线性关系时具有良好的适用性,其避免了设置指标权重,人为因素影响较小(叶云等,2018),借助于计算机技术的迅猛发展,拥有良好的评价效率。因此,探索基于数据挖掘技术的耕地质量评价方法已成为当前研究的热点。其中,Logistic回归模型是数据挖掘的一项重要技术,也是解决分类问题的常用方法。
在地学研究领域,对Logistic回归模型的研究多集中于利用二元Logistic回归模型的良好适用性(自变量可以是定性数据或是定量数据),进行土地利用变化模拟(周晨晴等,2018;林晓丹等,2017;田义超等,2019),对于多分类Logistic回归模型在耕地质量评价工作中的应用研究还少有报道。该模型同样适用于多个自变量与一个类别变量的非线性问题处理,通过对一组自变量和一个类别变量进行回归分析确定该类别变量发生的概率大小,该模型的计算量仅和变量特征的数目相关,因此较于其他数据挖掘模型有易于实现、训练高效等特点,在社会学(梁琪等,2014)和医学(刘立忠等,2017)等领域广泛应用。然而耕地质量系统是一个自然、经济、生态等因素相互作用相互影响的巨系统,各指标间并不是相互独立的,当某一指标(如耕地土壤pH值)对耕地质量的影响因第二个指标(如地形坡度)的不同而不同时,指标间就存在交互效应。目前大多数耕地质量评价方法中指标的选取都基于指标之间的独立性原则,未能考虑到耕地质量指标间的交互效应。因此,本文以从化区耕地为研究对象,在使用Logistic回归模型预测耕地质量等别时,考虑指标间的交互效应,将指标与指标间的交互效应同时纳入Logistic回归模型,对耕地质量进行评价,旨在解决现行耕地评价方法中受人为主观影响因素大的问题,探寻一种准确、高效的耕地质量评价方法。
1 研究区与数据
1.1 研究区域概况
从化区位于广东省中部(图 1),珠江三角洲北缘,是广州市最北部的一个市辖区,全区总面积1974.5 km2。其经纬度为 113°17′—114°04′E,23°22′—23°56′N。东与增城区、惠州市龙门县接壤,南与广州郊区白云区、黄浦区毗邻,西面和广州市花都区、清远市接壤,北面与清远市佛冈县、韶关市新丰县相连,以珍稀温泉闻名于世,素有“中国温泉之都”的美誉。该区地势自北向南倾斜,东北高,西南地,地形呈阶梯状,东北部以山地、丘陵为主,中南部以丘陵、谷地为主,西部以丘陵、台地为主。辖区有耕地1.36万公顷,主要利用方式为水田、水浇地和旱地。
1.2 数据准备
1.2.1 数据来源
本文采用 2015年广州市耕地质量评价指标数据库,数据主要来源于国民经济统计数据、第二次全国土壤调查数据以及实地测量结果。其中,广州市耕地质量评价指标数据库记录了包括从化区在内的广州市 11个下辖区耕地的地形状况、土壤条件、水资源状况、农田基础设施条件,包括耕地利用类型、地形坡度、田面坡度、地下水位、有效土层厚度、表层土壤质地、剖面构型、土壤有机质含量、土壤酸碱度、地表岩石露头、障碍层距地表深度、盐渍化程度、灌溉保证率、排水条件 14个指标,数据综合体现了广州市耕地质量现状及其影响因素的实际情况,是保证广州市耕地质量评价研究顺利开展工作的基础。本研究以从化区 2015年耕地质量评价数据库划定的 16664个耕地图斑为评价单元。

图1 从化区地理位置Fig. 1 Geographical location map of Conghua District
1.2.2 样本选取
为保证数据挖掘的样本数据具有代表性,采用分层抽样法,依据数据库内用因素法划定的耕地质量等别在从化区依比例随机选取不同等级的耕地作为样本,同时考虑样本属性,总共选取6000个训练样本,训练样本用于交互效应的发现与Logistic回归模型的构建,测试样本采用全部的耕地评价单元,即16664个评价单元。
2 研究方法
2.1 评价因素量化
为方便对数据进行交互效应Logistic回归建模,首先进行评价指标分级量化,对从化区耕地质量评价数据库中的数据进行分级。该数据库中所采用的指标大部分来源于《农用地质量分等规程 GBT 28407—2012》(以下简称规程)中的指标体系,其中包括有效土层厚度、表层土壤质地、剖面构型、盐渍化程度、土壤有机质含量、土壤pH值、障碍层距地表深度、排水条件、地形坡度、灌溉保证率和地表岩石露土,其因子级别临界值和等级划分标准参考规程。地下水位与田面坡度为区域性指标,其标准划分参考《广东省县级耕地质量等别更新评价技术规范》(以下简称规范)(2012)。一般来说,耕地利用类型不影响耕地质量,因此将其作为一个分类变量,不进行分级。部分指标的说明如下:
地表岩石露土:是指基岩出露地面之间的间距,规程根据露头之间的间距来进行等级划分,其间距越高表明对耕作的干扰程度越低,规程将其分为3个等别。
盐渍化程度:该指标一般根据土壤中易溶盐的盐分含量和其与作物生长的关系划分,1级表示土壤无盐化,作物没有因为盐渍化引起缺苗断垄现象,表层土壤盐含量根据土壤易溶盐类型分别为苏打、氯化物、硫酸盐,标准分别为:小于0.1%、小于0.2%、小于0.3%。其他等级规程依照其含量划分为轻度盐化、中度盐化和重度盐化。
障碍层距地表深度:土壤障碍层指在耕层以下出现的阻碍根系伸展或影响水分渗透的层次,其距地表距离越远,则对耕作影响越小,规程根据其距地表的距离分为3个等别。
灌溉保证率:指预期灌溉用水量在多年灌溉中能得到充分满足的年数出现的几率。规程将其分为4个等级,1级表示可随时灌溉的耕地,2级为在关键需水生长季节有灌溉保证的耕地,3级表示有灌溉系统,但在大旱年不能保证灌溉的耕地,4级属于无灌溉条件的耕地,为恶劣范围。
排水条件:耕地受地形、排水体系两者共同影响下地表积水状况,很多农作物在雨水充足时也会减产甚至绝收,因此该项指标也很重要。依据规程划分为4个级别,一级表示有健全的干、支、斗、农排水沟道,无洪涝灾害;2级表示丰水年暴雨后有短期洪涝发生(田面积水1—2 d);3级表示丰水年大雨后有洪涝发生(田面积水2—3 d);4级表示一般年份在大雨后发生洪涝(田面积水≥3 d)。
地下水位:是指地下含水层中水面的高程,该项指标是一个正向指标。依据规范划分为3个等别,1级属于优质水位,2级属于及格水位,3级属于危险水位。
其余指标等级划分情况如表1所示。
2.2 交互效应的生成与评价模型的构建
2.2.1 交互效应的定义
目前学术界对交互效应有多种定义方法,使用最广泛的一种方法是将交互效应置于因变量、自变量和调节变量(Moderator variable)的框架中进行讨论(Lewis et al.,2014)。其中,因变量是结果变量,由自变量决定或者受到自变量的影响。自变量被认为是因变量的原因,当自变量对因变量的影响因为第三个变量的取值不同而不同时(第三个变量称之为“调节变量”),认为两者间存在交互效应。
2.2.2 寻找交互效应
Logistic回归中的交互效应分析一般采用多层次完全(Hierarchically Well-Formulated,HWF)模型,该模型包含了最高阶交互项的所有低阶组成部分(Kleinbaum,2011)。例如,我们要研究X和Z两个自变量的交互效应,多层次完全模型就包含了X、Z和XZ。如果X包含虚拟变量X1和X2,那么多层次完全模型就包括了X1、X2、X1Z、X2Z。由此可见,耕地质量影响因素包含15项指标,随着主要效应的增长,此时若利用常规的多层次完全模型,最后将得到包含 15个主效应以及所有阶数交互效应在内的32767个变量,这不仅加大了计算机的运算量,而且得出的Logistic回归结果无法进行判读和解释,因此,利用多层次完全模型无法分析耕地质量的交互效应。
Changpetch et al.(2013)提出利用数据挖掘中的关联规则分析帮助从大量可能性中选择变量之间潜在交互效应的方法,其对 MONK数据集的验证表明关联规则能有效发现主效应间的潜在交互效应,将关联规则应用到耕地评价中,可有效提高耕地评价知识的可解释性(杨敬锋等,2008)。因此,本研究采用关联规则方法挖掘耕地质量影响因素间的潜在交互效应。

表1 从化区耕地质量评价因子级别指标值Table 1 Grade index value of cultivated land quality evaluation factors in Guangzhou
关联规则分析中,参数的阈值对于关联规则结果尤为重要。由于影响耕地质量的变量较多,须通过不断调整参数,即关联规则的最小支持度和置信度来获取满意的挖掘结果(Pradhan et al.,2017)。关联规则是形如X→Y的蕴含式,其反映X中的项目出现时,Y中的项目也跟着出现的规律。支持度(support)指的是同时包含X和Y的事务集数与所有事务集数之比;置信度是包含X和Y的事务集数与所有包含X的事务集数之比,其反映了包含X的事务中,出现Y的条件概率。
通过对数据进行统计分析发现,从化区耕地盐渍化程度、地表岩石露土度均为等级 1,障碍层距地表深度为等级3,因此不将这3个影响因素纳入分析。本研究中,将耕地质量等别(Y)作为后项,各项评价指标作为前项,通过MATLAB实现FP-G(Frequent Pattern-Growth)算法挖掘关联规则,该算法通过构造一个树结构来压缩数据记录,使得挖掘关联关系只需要扫描两次数据记录,且不需要生成候选集合,对于属性较多的耕地质量数据较于以往的关联规则算法有更高的处理效率,由于该算法已十分成熟,读者可参考相关文献(邱小倩等,2020;Lin et al.,2011),此处不再赘述。本研究以最小置信度为 95%时,逐渐降低最小支持度并观察其结果。结果发现当最小支持度分别设置为0.05、0.03、0.01时,挖掘出关联规则数分别为8、35、78条,涉及到的交互效应个数分别为6、32、75个。由于文章篇幅有限,仅列出在最小支持度为0.05的情况下,挖掘出的8条关联规则,如表2所示。
根据强关联规则表,第1、3条规则表示表层土壤质地、土壤酸碱度与耕地质量存在强关联关系,提示表层土壤质地与土壤酸碱度之间可能存在某些潜在交互效应,同理,第4、8条规则分别提示耕地利用方式与土壤酸碱度、有效土层厚度与土壤酸碱度之间可能存在某些交互效应,与檀满枝等(2007)基于信息熵原理得出的土壤酸碱度影响因素的结论类似,因而针对这3项交互效应,分别将表层土壤质地、耕地利用方式、有效土层厚度作为调整变量。第2、6条规则提示地形坡度与土壤有机质含量之间可能存在某些潜在交互效应,与周一鹏等(2019)对土壤有机质空间变异性及其驱动因素间交互效应的研究结论类似,因此将地形坡度作为该交互效应的调整变量。第5条规则提示耕地排水条件与灌溉保证率之间可能存在潜在交互效应,通过对广州市耕地实地走访调查发现,从化区耕地的灌溉系统与排水系统是密切配合的,在布置灌渠时,就同时布置了排水系统,因此将灌溉保证率作为该交互效应的调整变量。此外,第7条规则提示,表层土壤质地、土壤酸碱度、地形坡度三者之间存在三阶交互效应,将表层土壤质地与地形坡度作为该三阶交互的调整变量。

表2 耕地质量影响因素的强关联规则Table 2 Strong association rules of influencing factors of cultivated land quality
2.2.3 交互效应Logistic评价模型
耕地质量等别是一个多分类变量,耕地质量评价的目的就是依据耕地质量的好坏进行有序分类。因此研究采用有序多分类 Logistic回归模型对耕地质量进行评价。
对于有序多分类Logistic回归,模型首先定义了因变量的某一个水平为参照水平(SPSS软件默认最后一项为参照水平),其他水平均与其相比,建立水平数-1个广义Logit模型。
基于广州市耕地划分为6个等别,即反应变量有6个水平,分别取值为1、2、3、4、5、6,以等别6的耕地单元为参考类别,相应概率为P1、P2、P3、P4、P5、P6,对n个自变量拟合成5个模型。

式中,Gi为解释变量X1,X2, …,Xn的线性函数。

式中,βi1,βi2…,βin为耕地质量等别为i时,各个解释变量的回归系数,αi为截距。
对Pi进行Logit变换,则有:

最后,运用极大似然估计法可求得各个等级模型的参数估计系数αi,βi1,βi2,…,βin(Zhang et al.,2010;Del Hoyo et al.,2011)。
在分析交互效应时,我们需要有清晰的理论假设来界定何为调节表量,以及何为关键自变量(focal independent variable),即对因变量的作用受到调节变量影响的自变量。根据关联分析所得到的结果,此处以地形坡度和土壤有机质含量之间的交互效应为例,说明如何在Logistic回归中加入交互效应。
在Logistic回归中加入交互效应最常见的方法就是加入一个乘积项(James,2014)。以下是耕地质量等别为1的全局Logistic回归模型(不包含交互项),其中X1表示土壤有机质含量,X2表示地形坡度,已知二者存在交互效应,其中X2是调节变量,X1对结果变量的影响因X2取值不同而不同。

为了表示这种关系,我们可以将β11(反映了X1对结果变量的影响)写成一个关于X2的线性函数:

这个公式表示,X2每变化一个单位,β11就变化β1(n+1)个单位。将公式代入原方程并整理转换得到含交互项的方程:
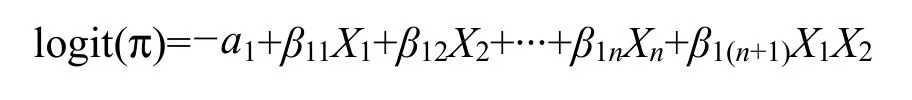
最后,运用极大似然估计法求得包含交互效应的Logistic回归模型的参数估计系数。
对于一个交互项是否有必要纳入模型,通过比较两个模型——包含该交互项和不包含该交互项的模型拟合优度即可,对于本实验,我们使用赤池信息准则(Akaike Information Criterion,AIC)和决定系数R2来衡量一个模型的拟合优度,AIC值越小,R2越接近于1,表示损失的信息越少,模型拟合程度越好。如果两个模型的拟合优度有显著差别,就说明交互项是有意义的;如果差别不大,就没有必要加入交互项。通过直接检验交互项的Logistic系数的统计显著性,如果该系数在统计上不显著,就说明该交互效应在统计上不显著。
2.2.4 模型验证
Logistic回归模型对测试样本的分类结果可通过混淆矩阵(confusion matrix)反映。本研究涉及到的耕地分类等别较多,应用模型划分需要注意多个类别是否混淆,因此需要对该算法的分类结果做出总结。混淆矩阵也称错误矩阵,是精度评价的一种标准格式,其应用特殊的矩阵来呈现Logistic模型的精度,主要用于比较分类结果和实际测得的值,每一列代表Logistic模型的预测值,每一行代表等别数据库中运用因素法划定的实际等别,模型分类精度可直观地反映于该矩阵。
ROC(Receiver Operating Characteristic Curve)即受试者工作特征曲线,该曲线的横坐标为特异性指标假阳性率(False Positive Rate,FDR),纵坐标为其敏感性指标真阳性率(True Positive Rate,TDR)绘制而成的曲线,本文根据 ROC曲线计算出的假阳性率和真阳性率,可求得约登指数,约登指数=假阳性率+真阳性率-1,进而计算出各个耕地质量等别的最佳临界值(cut-off值)。以1等地的ROC曲线为例,如果某块评价单元其1等地模型预测概率P1大于该临界值,则模型判别该块耕地为1等地,小于该值则认为该块耕地不是1等地。此外,通过这条曲线可以反映多分类Logistic模型和因素法两者的关系,可直观看出受试工作的准确性情况。该曲线越靠近左上角,ROC曲线下方面积大小即(Area Under ROC Curve,AUC)越接近于1,受试者工作越准确,说明该模型性能越好,一般AUC的值超过0.9时说明该模型具有较高的准确性。
3 结果与分析
3.1 模型选取
图2为模型性能曲线,即纳入不同交互效应个数的模型性能对比图。其赤池信息准则与决定系数的变化情况如图2所示,将关联规则筛选得到的75个耕地质量交互效应逐个加入Logistic模型,在加入前5个交互效应时,R2上升趋势明显,AIC值不断下降,模型拟合度变化明显,在第5个交互效应时,R2超越了 0.95,达到了 0.998,模型拟合度良好。当加入第6个交互效应时,模型拟合度开始下降,但总体变化不大,此外,拥有5个交互效应的Logistic回归模型,交互效应系数的显著性水平都满足P≤0.05,分别为0.00、0.00、0.00、0.01、0.00,因此得出从化区耕地质量评价指标间交互效应有 5个,分别是:表层土壤质地与土壤酸碱度、耕地利用方式与土壤酸碱度、有效土层厚度与土壤酸碱度、地形坡度与土壤有机质含量、排水条件与灌溉保证率之间的交互效应。

图2 交互效应Logistic模型性能曲线Fig. 2 Performance curve of logistic model based on interaction effect
为验证基于交互效应Logistic模型的适用性与准确性,将未加入交互效应的全局Logistic模型与基于5个交互效应的Logistic模型进行对比,结果见表3。

表3 模型参数结果对比Table 3 Comparison of model parameters
PE为模型对训练样本中耕地单元等别预测误差。关联是预测等别与因素法划分等别之间的斯皮尔曼关联(Spearman’s correlation),其值越高,说明预测等别越接近常规法划分的等别,模型效果就越好。赤池信息准则通过考虑模型的自由度,对比不同模型的差异性(张金牡等,2010),其值越小则模型拟合度越高(梁慧玲等,2017),损失的信息越少。
由表3可知,交互效应Logistic模型的R2优于全局Logistic模型,即模型的拟合优度较高。更小的预测误差和更大的相关性表明该模型能更好地解释自变量和因变量间的关系,模型的精度更高。由于考虑了耕地质量评价指标间的交互效应,所以模型的AIC值明显下降。从模型的综合表现看,该模型比全局Logistic模型更能反映耕地质量指标与耕地质量之间相互作用相互影响的关系,用于耕地质量评价损失的信息更少,从而更加准确地对耕地质量进行评价。
因此,选取加入前5个交互效应的Logistic回归模型作为本次耕地质量评价最优模型,进行耕地质量等别划分。
3.2 模型精度
对基于5个交互效应的Logistic回归模型进行精度评价。

图3 等别划分混淆矩阵Fig. 3 Confusion matrix of gradation
如图 3,对角线上的值是各类别应用基于最优Logistic回归模型方法分类正确的数量占比。各等别划分正确率均达到了95%以上,其中1等耕地和3等耕地划分准确率为100%,而2等地、4等地、5等地和6等地划分正确率分别为97%、98%、97%、99%。
从图 4a—f可以看出 ROC曲线趋势均向左上偏,1、2、3、4、5、6等耕地的 AUC值分别为1.00、0.990、1.00、0.9985、0.9983、0.9999。说明包含5个交互效应的Logistic回归模型性能良好,得到的结果精度高。
3.3 耕地评价结果
将 16664个测试样本耕地单元输入到所建立的交互效应Logistic回归模型中,进行耕地质量等别计算。经过等别的计算,统计应用因素法和应用交互效应 Logistic模型的耕地质量等别一致性数量。该模型对16664个耕地评价单元的评价准确率为92.2%。虽然该模型在区分不同等别耕地区分上仍然存在一些问题,但总体来看,耕地质量等别的划分结果准确度较高。

图4 不同等别耕地的ROC曲线图Fig. 4 Receiver operating characteristic curve of cultivated land of different grades
分类情况如表 4,对于 1等地、4等地、5等地、6等地这四类耕地单元较多的样本来说,其分类正确率均达到了90%以上,4等耕地的划分正确率最高,达到了97.26%。根据划分错误情况,其中1等地错划为2等地和3等地,4等地错划分为3等地和5等地,5等地错划分为4等地和6等地,6等地部分被划入5等地,由此可见,大多数等别划分误差都集中在1等别,跨级误差占比极小。但对于2等地和3等地这两类耕地单元较少的样本,正确率分别只有66.63%和76.63%,跨级误差也较大,分类精度不理想。因此,样本数量的不均衡将影响模型的分类精度。
4 结论与讨论
4.1 讨论
耕地质量评价工作中指标体系的构建是重点难点。耕地质量评价指标体系构建已由偏重于自然属性向较为全面考虑自然与生态环境、社会经济等众多方面完善(沈仁芳等,2012)。然而,由于耕地质量的影响因素较多,各因素之间也会相互产生影响,耕地质量所呈现的实际上是各种驱动因素作用共同叠加的结果。
本研究通过关联规则分析与Logistic回归模型得知耕地表层土壤质地与土壤 pH、耕地利用方式与土壤pH、有效土层厚度与土壤pH、地形坡度与土壤有机质含量之间存在交互效应,这与近年来有些学者针对耕地质量中的几个主要驱动因素的交互效应研究结论类似。如黄平等(2009)通过DEM模型图与土壤有机质空间分布图进行空间叠置分析以探讨坡度、坡向对耕地土壤有机质空间变异的影响,结果表明坡度对土壤有机质含量的影响比坡向更明显,部分地区存在坡度与坡向交互影响显著的情况。王亚男等(2018)利用ArcGIS软件和地统计学方法对耕地土壤pH的空间分布特征进行半变异函数分析,结果表明土层厚度和土壤类型对耕地土壤pH影响较大,坡度对耕地土壤pH的影响呈弱相关。檀满枝等(2007)基于信息熵原理对土壤pH与母质、地形和土地利用方式之间的空间相关性进行定量分析,结果表明其相关性顺序为土地利用方式>地形>母质。因此,关联规则与Logistic回归模型对于耕地质量评价指标间交互效应的发现是一种行之有效的方法,该方法针对传统多层次完全模型在寻找交互效应时自变量数量较多时的局限性,通过关联规则分析找到了耕地质量指标间的交互效应,将其作为Logistic回归分析的待选解释变量,这样既克服了全局Logistic回归分析无法发现变量间交互效应的问题,也解决了关联规则无法给出模型和参数估计值的缺陷。当然,可用于检测耕地质量指标间(低阶和高阶)交互效应的其他方法也可以在这里使用,关于和其他交互效应发现的方法比较有待下一步的讨论分析。
耕地质量评价结果的可靠性高低依赖于评价方法的优劣。在耕地质量工作中,虽早有学者针对耕地质量相关影响因素间的交互效应开展研究,但未见将交互效应理论应用于实际耕地质量评价工作,其根本原因在于传统的耕地质量评价方法难以对耕地质量与耕地质量影响因素间的交互效应进行有效表达,数据挖掘方法为其交互效应的表达提供了可能性。本文采用基于纳入具有统计学意义的5个交互效应的多分类Logistic回归模型对耕地质量等别进行划分,该模型在对耕地质量数据的拟合优度和预测准确率上均优于全局 Logistic回归模型,用于耕地质量评价准确度更高。但该模型在对个别等别的耕地质量识别准确率较其他等别偏低,原因在于训练样本的选择上,对于训练样本较小的耕地质量评价单元的精度不理想,本文仅采用分层抽样法选择样本,因此下一步可讨论不同方式的样本选择方法进行深入对比分析。

表4 多分类Logistic回归模型划分耕地质量等别分布表Table 4 Classification of cultivated land quality by multi-classification Logistic regression model
4.2 结论
耕地质量的影响因素众多,要保证耕地质量等别的科学划分,就必须对各类因素给予客观评价。传统的耕地质量评价方法大多采用特尔菲法、层次分析法、指数和法、灰色关联度分析法和GIS方法等,这类方法在评价过程中主观性大,易受人为因素干扰,且工作量大。据此,本研究引入一种基于交互效应的Logistic回归模型评价方法,将其应用到耕地质量评价中,得到以下主要结论:
(1)通过构建基于交互效应的耕地质量评价指标体系,将关联规则技术与Logistic模型结合,既可快速挖掘耕地质量影响因素间的交互效应,又可通过Logistic回归模型验证交互效应是否具有统计学意义,从而得到从化区耕地质量评价指标的交互效应:表层土壤质地与土壤酸碱度、耕地利用方式与土壤酸碱度、有效土层厚度与土壤酸碱度、地形坡度与土壤有机质含量、排水条件与灌溉保证率之间的交互效应。
(2)对于耕地质量这一综合系统而言,基于交互效应的Logistic回归模型比全局Logistic回归模型拥有更好的模型拟合优度。将该模型应用到耕地质量评价领域,最终选取具有 5个交互效应的Logistic回归模型,应用此模型进行耕地质量等别划分,评价结果精度为92.2%,达到了较高的精度等级,可满足实际应用需求。
