基于改进R-FCN与语义分割相结合的人体姿态估计
2021-01-26马鸿玥朴燕鲁明阳
马鸿玥,朴燕,鲁明阳
(长春理工大学 电子信息工程学院,长春 130022)
人体姿态估计作为计算机视觉领域中的一个重要研究方向,被广泛应用于许多方面。例如,利用人体姿态可以进行摔倒检测或用于增强安保和监控[1];用于健身、体育和舞蹈等教学;训练机器人,让机器人“学会”移动自己的关节;电影特效制作或交互游戏中追踪人体的运动;通过追踪人体姿态的变化,实现虚拟人物与现实人物动作的融合与同步等。近年来,深度卷积神经网络不断应用于人体姿态估计中,使检测人体骨骼关键点变得不繁琐,并且精确度也得到了很大的提升。但在复杂的环境下,多人会出现遮挡、重叠的现象,使人体姿态估计面临着挑战。
基于深度学习的人体姿态估计方法,主要有两种思路:
(1)Bottom-up方法
第一步对整个图片进行每个人体关键点的检测,第二步根据检测到的关键点拼接成人形。近几年,此思路流行的方法有很多,例如Open⁃Pose[2],主要对编码人体四肢的位置和方向的关键点进行连接,并且学习身体部位的位置和联系的架构,并且用高效率、高质量的方法产生人体姿态检测的结果,该模型在标准测试集MPII中可以达到平均79.7 mAP。随着图像中人数的增加依然能保持准确率和实时性。但是,在OpenPose模型训练时存在着标签问题:由于采用CPM(Critical Path Method)[3]与 PAF(Part Affinity Field)[4]结合的方法,在训练时,一个 PAF 连接就是对已知的两个关键点进行连接,如果两个关键点中有一个不存在,则不生成PAF标签,即使模型预测出正确的PAF,训练时也会被惩罚,容易对模型的训练造成影响。
(2)Top-down方法
第一步利用目标检测算法检测出单个人,第二步对检测出的个人进行人体关键点检测。Top-down方法的性能通常依赖于人体检测器的精度,因为人体姿态估计是根据检测器得出的边界框中进行的。因此,错误的定位和重复的候选框会使姿态估计算法的性能降低。目前,代表性的方法是RMPE[5]:基于两步法框架的区域的多姿态估计算法,首先对目标进行检测,形成候选区域,然后根据候选区域进行姿态估计。针对候选区定位不准确的情况下也能正确的检测人体姿态。该算法在MPII数据集下可以达到平均76.7 mAP。但是,RMPE易受到检测框的影响,造成漏检和误检,从而影响检测结果。此外,Mask R-CNN[6]也可以应用到人体姿态估计中,该网络中的语义分割mask分支可以扩展到人体关键点检测。本文采用Top-down的方法,借鉴了Mask R-CNN中的语义分割mask网络分支,提出了一种基于改进R-FCN[7]和语义分割相结合的人体姿态估计模型。
目标检测作为姿态识别的一个子任务,本文将用于目标检测的R-FCN为基本框架,在此基础上加以改进,改进后的R-FCN框架具有人体姿态估计的能力,同时,保障运行速度的前提下提升检测精度。本文创新点如下:
(1)将R-FCN中原有的ResNet-101深度网络替换为ResNeXt-101[8]深度网络。其中R-esNeXt-101主要是结合了VGG堆叠和Incept-ion的分裂-转换-聚合原理,在相同参数情况下,解决了ResNet-101在训练时错误率较高的问题。通过使用相比ResNet-101更少的网络层数,从而提升准确率和运行速度。
(2)结合文献[9]中的方法,引用多尺度RPN,通过修改候选区域的比例和尺寸,从而提高对人体定位的准确性,解决多尺度下的人体姿态问题。
(3)在目标检测R-FCN框架上结合了Mask R-CNN中并行的语义分割mask网络分支,它与原始的分类与回归分支进行并联,使R-FCN具有语义分割的功能,从而实现人体姿态估计。
1 基础网络介绍
1.1 R-FCN网络介绍
R-FCN是用于目标检测的全卷积网络。与Fast/Faster R-CNN相比,在R-FCN的结构中,使用所有卷积层来构建共享卷积子网络,残差网络(ResNets)[10]作为基础网络。此外,针对图像分类中的平移不变性与目标检测中的平移方差之间的矛盾,R-FCN采用位置敏感的分数映射来解决。ResNets101作为R-FCN的骨干网络,在PASCAL VOC 2007数据集和PASCAL VOC 2012数据集上分别实现83.6% mAP和82.0% mAP,同时测试时间可以实现每图像运行170 ms的速度。
R-FCN是基于区域的二阶段框架,包括:(1)区域建议;(2)区域分类。其网络由共享的全卷积架构组成,使用ResNet-101为主体网络,采用区域建议网络(RPN)来提取候选区域(RoI),将RoI分为9个区域,分别代表人体的9个部位,构建一组位置敏感得分图,映射原图像的位置响应值,再经过RoI-Pooling层的平均池化操作,最后根据投票机制判断其类别或者背景。
将位置信息精确地映射到每个RoI中,划分每个RoI为k×k个bin的矩形网格,每个RoI网格的尺寸大小为w×h,每个bin的尺寸约为,在(i,j)位置的bin(0 ≤i,j≤k-1)中,定义一个位置敏感的RoI平均池化操作,该操作仅在(i,j)分值图上进行池化:

其中,rc(i,j)是在(i,j)区域基于C类别的池化响应;zi,j,c是K×K×(C+1)维的敏感得分图,C+1表示C类加上一个背景图;(x0,y0)代表9个区域的其中一个区域;n是在bin里的像素点个数;Θ表示网络的所有可学习的参数。(i,j)的范围为,并且
通过平均得分进行vote,为每个RoI生成一个(C+1)维向量:

然后计算不同类别的softmax响应:
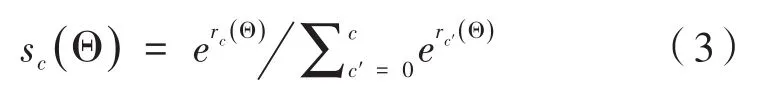
用于评估训练过程中的交叉熵损失。同时,使用类似的方法处理边界盒回归。
1.2 Mask R-CNN网络介绍
在实例分割领域,Mask R-CNN是一个概念简单、灵活、通用的框架。不仅可以有效地检测图像中的对象,而且针对每个实例都可以生成一个高质量的分割掩码。Mask R-CNN通过添加一个语义分割mask网络分支来扩展Faster RCNN[11],该分支与现有的用于边界框识别的分支并行地预测一个对象掩码。运行速度可以达到每秒5帧。此外,Mask R-CNN还可以用来检测人体关键点。在COCO 2016挑战赛中,实例分割、目标检测、人体关键点检测都达到了最好的结果。Mask RCNN的整体架构由Faster R-CNN、ROIAlign 和 FCN(Feature Pyramid Networks)[12]三个模块组成。其中,Faster R-CNN作为目标检测模块,FCN作为语义分割模块,ROIAlign策略解决了像素偏差问题,三个模块的结合使Mask RCNN达到了高速、高准确率的效果。
Mask R-CNN作为Faster R-CNN的扩展,主要表现在:
(1)在Faster R-CNN算法的基础上,增添了FCN网络以产生对应的语义分割mask网络分支,从而实现分割任务,并且分割任务与定位、分类任务是同时进行的。
(2)引入了RoIAlign,代替Faster R-CNN中的RoIPooling。因为在RoIPooling中会对像素值进行两次量化操作,进而会引入量化误差,造成像素偏差,对分割任务有很大的影响。而RoIAlign则是采用“双线性插值”算法来估计像素值[13],使原图中的像素和feature map中的像素完全对齐,这样不仅会提高检测的精度,同时也会有利于实例分割。
Mask R-CNN属于二阶段框架,第一阶段作用于RPN网络生产RoIs,第二阶段对RPN找到的每个RoI进行分类、定位和生成mask掩码。如图1所示,以FPN网络为骨干网络,整个架构分为上下两个分支,上分支经过7×7×256的卷积层以及两次1×1 024的全连接层分别实现分类和回归,mask语义分割网络作为下分支进行了4次14×14×256的卷积操作和一次 28×28×256的反卷积操作,最后输出为28×28×80的mask。
2 基于改进R-FCN与语义分割相结合的人体姿态估计方案
如图2所示,整体网络框架采用以区域为基础的、全卷积网络的两阶段框架。模型使用ResNeXt-101进行特征提取,生成特征图,将最后一层特征图经过多尺度RPN网络,输出为目标候选区域矩形框的集合。模型存在上下并行的两个分支,上分支利用mask网络实现语义分割,并且采用one-hot编码提取人体关键点。下分支利用特征图获得位置敏感得分图,同时在特征图上获得位置敏感得分映射,再经过池化和投票操作,最后采用softmax函数实现分类和回归。

图2 人体姿态识别框架
分类和回归分别执行位置敏感的RoI平均池化操作。每个RoI上定义的损失函数视为分类损失、回归损失及语义分割损失之和:

其中,c*表示RoI的ground-truth标签(c*=0表示为背景);t表示ground-truth框。[c*>0]是一个指示符,如果参数为真,则该指示符等于1,否则等于0。并且设置平衡量λ=1。
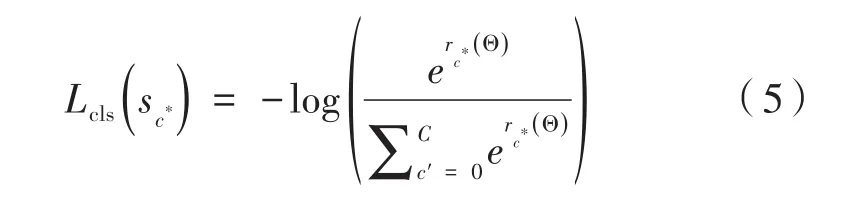
公式(5)为分类的交叉熵损失,Lreg(t,t*)为边界框回归损失。mask分支的平均二值交叉熵损失如下:
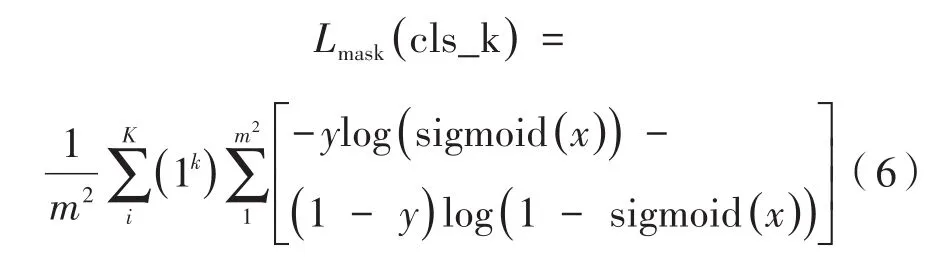
其中,1k表示当第k个通道对应目标的真实类别时为1,否则为0;y表示当前位置的mask的label值,为0或1;x表示当前位置的输出值,sigmoid(x)表示输出x经过sigmoid函数变换后的结果。Mask R-CNN中最后输出的mask的尺寸为m×m×K(28×28×80)。计算Lmask时,仅使用RoI的真实类别的通道损失。
2.1 以ResNeXt-101为基础网络的人体姿态估计模型
ResNeXt网络作为ResNet网络的一个扩展网络。主要思想是VGG堆叠网络与分裂-转换-聚合原理的结合。其中采用深度、宽度和基数作为衡量指标。如图3所示,图3(a)为ResNet网络模块,输入通道为 256,依次进行 1×1、3×3、1×1的卷积。输出通道为256。图3(b)为ResNeXt网络模块,与ResNet网络模块相比,ResNeXt网络模块共分为32个卷积路径,输出与ResNet网络模块的输出相同,且两个网络模块的复杂度相近。

图3 模块示意图
ResNeXt网络的一个残差模块被视为分裂-转换-聚合的过程,如图4所示。ResNeXt网络相当于在卷积层增加了“新”维度,由此一个模块的总维度数被称为基数,分裂-转换-聚合如下:

其中,Ti(x)可以是任意函数;D是要聚合的基数大小。根据式(7)可以得出残差方程:
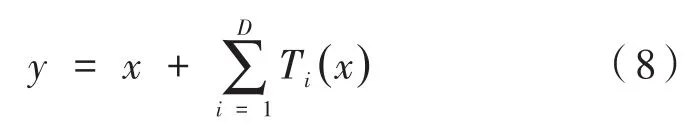
其中,y是输出。

图4 分裂-转换-聚合原理
所有的Ti都具有相同的拓扑结构,如图5所示,每个Ti中的第一个1×1层产生低维嵌入,本文在ResNeXt-101网络的基础上将原始的基数32改为64。采用的结构如表1所示,使用ResNeXt网络作为基础网络,可以减少超参数的数量,同时提高模型的准确率。

图5 本文采用ResNeXt-101网络模块

表1 ResNeXt101网络结构
2.2 多尺度RPN结构
在多目标检测中会出现多尺度的目标检测问题。考虑到目标尺寸之间相差较大,仅用单一的尺寸会影响网络对多尺度目标的检测能力[14]。如图6所示,图像中目标的尺寸存在差别。例如每张图像中人所占的比例不同。从图6(a)、图 6(b)、图 6(c)可以看出目标所占的区域依次减小。所以,由于信息位置的差异,实现恰当的卷积就比较困难。信息分布更全局性的图像倾向较大的卷积核,信息分布比较局部的信息倾向较小的卷积核。

图6 实例图片
由此,本文结合文献[9],借鉴了多尺度RPN结构。通过在同一层上并联不同尺寸的滤波器解决多尺度问题。如图7所示,在最后一层特征图上使用3种不同大小的滤波器来生成候选区域,分别通过 1×1、3×3、5×5卷积实现。经过卷积之后每一个像素点映射原始图片对应的坐标点,此坐标点作为中心生成3种比例1:1/1:1.5/1:2、3种尺度64/256/512、共9种不同大小的粗粒度的候选区域,如图8所示。
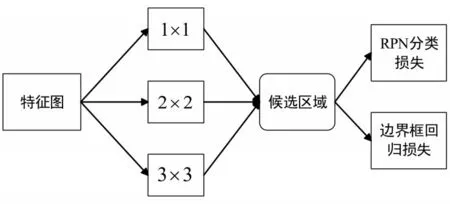
图7 多尺度RPN结构

图8 三种比例、三种尺寸的候选区域框
对多尺度RPN进行RoI-pooling操作,利用反向传播对网络进行优化,RoI-pooling的反向传播公式如下:

其中,xi代表池化前特征图上的像素点;yr,j代表池化后的第r个候选区域的第j个点;i*(r,j)代表点yr,j像素值的来源(平均池化时选出的平均像素值所在点的坐标)。由上式可以看出,只有当池化后某一个点的像素值在池化过程中采用了当前点xi的像素值(即满足i=i*(r,j),才在xi处回传梯度。
2.3 语义分割mask分支
本文在R-FCN网络上添加一个语义分割mask网络分支,与分类分支和回归分支并行,添加的mask网络分支使用全卷积网络以像素点对应像素点的方式预测分割mask,以RoI分类器选择的人体区域作为输入,将人体区域标定15个关键点类型,如图9所示,将人体15个关键点一一对应一个mask,并将关键点的位置建模为一个one-hot mask。关键点坐标的表示方式为:在图片中关键点的绝对坐标值为i∈(i,…,k),其中表示第i个关键点的坐标值(xi,yi),然后对其进行归一化处理。设人体的边缘框坐标表示为b=(bc,bw,bh),其中bc=(cx,cy)表示边缘框的中心点,边缘框坐标可以通过关键点的绝对坐标值计算出来。则归一化的关键点坐标(相对坐标)表示为:
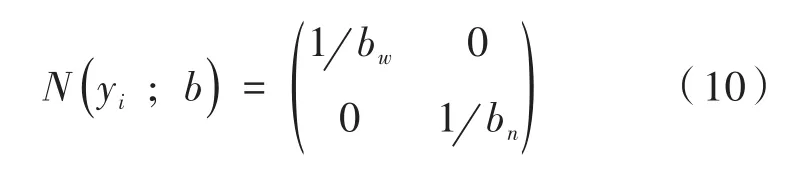
其中采用关键点坐标归一化处理的目的是:解决人体相对于图片的尺寸过大而造成关键点坐标值的差距过大的问题,对尺寸的变化具有更好的鲁棒性,同时降低回归的值的范围及网络的训练的难度。由公式(11)可以得出网络预测的人体区域骨骼关键点坐标相对于图片的绝对位置表示为:
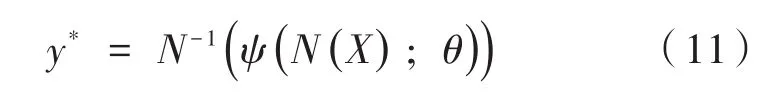
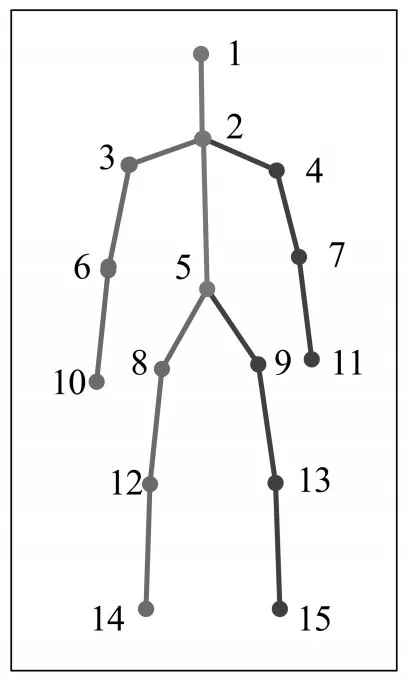
图9 15个关键点标注
如图10为mask网络结构,通过多尺度RPN网络,RoI分类器选择的正区域分辨率为14×14×256,经过 3×3卷积、2×2卷积、1×1卷积操作,输出为 28×28×80的 mask,经过 one-hot编码,最终得到的是每个关键点输出的二值掩码,其中被标记的关键点像素为前景,其余像素均为背景。
3 实验结果与分析
本文在两个标准数据集上对多人姿态进行评估:(1)MPII数据集[15]和(2)MS COCO 数据集[16],这两个数据集在不同的场景中收集图像,其中的场景包含生活中的许多现象,如拥挤、尺度变化、遮挡和接触现象等。

图10 mask网络结构
3.1 评估数据集
(1)MPII数据集
MPII数据集由3 844个训练组和1 756个测试组组成,此外,还包含了28 000多个用于单人姿态估计的训练样本。本文使用单人数据集中的所有训练样本和80%的多人训练样本进行训练,20%用于验证。
(2)MS COCO数据集
MS COCO数据集包括105 698项训练样本和大约80 000项人类实例测试。训练集包含超过100万个标记的关键点。
3.2 模型训练
本文使用的编程语言是python3.7,采用caffe深度学习框架,程序运行平台为Anaco-nda3(64bits),操作系统为Windows10(bits),运行环境为GPU显卡型号为NVIDIA-GTX1080ti-12G。首先对ResNeXt-101网络进行预训练,然后用预训练网络来初始化特征提取网络卷积层的权重。设置学习率为0.005,mome-ntum为0.9,weight_decay为0.000 5。网络经过的迭代共8万次。
3.3 在MPII数据集上的实验结果与分析
本文在MPII测试集上进行了评估。在MPII测试集中,完整的测试数据集包括人体的头部、肩部、肘部、腕关节、臀部、膝盖、脚踝部分。如表2所示,通过与DeeperCut、OpenPose以及文献[18]进行对比,本文模型可以达到的平均精确度是最高的。在估计腕关节、肘部、脚踝和膝盖等困难关节方面的平均准确率达到了81%,比之前的最新结果高出0.9%。本文最终得到了手腕的精度为77.6%,膝盖的精度为80.3%。实验结果表明,基于改进R-FCN与语义分割相结合的人体姿态估计模型可以提高精确度。在图11中展示了一些实验结果图。实验证明,本文模型能够准确地对多人姿态、单人姿态、目标接触以及目标遮挡姿态进行估计。

图11 姿态估计效果图
3.4 在MS COCO数据集上的实验结果与分析
为了进一步验证本文方法的有效性,在MS COCO数据集上进行了多组对比实验,分别对OpenPose、RMPE、Mask-RCNN、以 ResNet101和RPN为基础R-FCN与mask结合、以及Our模型进行实验。
MS COCO评估指标中,对象关键点相似性(Object Keypoint Similarity,OKS)定义如下:

其中,p为地面实况中人的id;i表示关键点的id;dpi表示地面实况中每个人关键点与预测关键点的欧氏距离;Sp表示当前人的尺度因子即此人在地面实况中所占面积的平方根;σi表示第i个关键点的归一化因子;vpi代表第P个人的第i个关键点是否可见;δ用于将可见点选出来进行计算的函数。AP即所有10个OKS阈值的平均精确率,AP50即IoU阈值等于0.5时的平均精确度,AP75即IoU阈值等于0.75时的平均精确度,APM即测量面积在322和962之间的平均精确度,APL即测量面积大于962平均精确度。
由表3可知,本文模型精度优于前三组实验,OpenPose中存在标签问题,很容易对模型的训练造成影响。在目标有缺陷的情况下,Mask-RCNN无法精确的判断是否为缺陷。由于RMPE容易受到检测框的影响,造成漏检和误检,从而影响检测结果。实验表明,以ResNeXt101和多尺度RPN组合为基础的R-FCN与mask结合实现的效果最好,精度率达到74.3%。以ResNeXt101为基础框架的R-FCN能够更好的对目标进行检测,结合多尺度RPN结构可以有效的解决目标的不同尺度问题。

表2 各姿态估计模型在MPII数据集上的精确度对比

表3 各姿态估计模型在MS COCO数据集上的性能对比

图12 不同模型结果对比图
在图 12中,图 12(a)为 Mask R-CNN 模型姿态估计结果,图12(b)为OpenPose模型姿态估计结果,图12(c)为本文提出的模型姿态估计结果。在肢体遮挡和人体复杂姿态场景下,图12(a)只检测到两个目标姿态,图12(b)中遗漏了第三个目标的腿部关键点,由于中间目标遮挡了右边目标,导致无法对腿部遮挡的部分进行估计。实验表明,当前流行的两种姿态估计模型处理效果有待提高。本文提出的模型可以成功实现姿态估计,各个关键点检测效果明显优于另外两种模型。
4 结论
本文以深度学习为基础,进行了人体姿态估计算法的研究,并提出了一种基于改进R-FCN与语义分割相结合的人体姿态估计模型。该模型以目标检测R-FCN框架加以改进,并添加了Mask R-CNN中mask语义分割网络,从而提高人体姿态估计算法的性能。同时,为了减少参数复杂度以提高准确率,本文采用ResNeXt-101作为基础网络应用于R-FCN网络结构;并且引用多尺度RPN结构代替传统的RPN结构,处理候选区域中出现的多尺度问题。通过实验证明,本文提出的模型可以快速准确的对人体姿态进行估计,并且与其他模型相比,有较高的准确率。
