流式文档排版效果自动化测试方法
2021-01-22田英爱
左 阔,李 宁,田英爱,侯 霞
1.北京信息科技大学 网络文化与数字文化传播重点实验室,北京100101
2.北京信息科技大学 计算机学院,北京100101
流式文档主要描述文档的逻辑内容,同时支持编辑和浏览[1]。流式文档最终的排版效果是借助排版引擎对文档内容进行灌排生成的,而不同厂商对排版格式的理解和算法精度的设定存在差异,导致同一流式文档在不同办公软件中呈现的排版效果并不完全一致。在办公软件的开发和测试过程中,分析并指出流式文档的排版效果在何种程度上存在差异,对于办公软件标准符合性和兼容性测试,以及提高办公软件的质量具有重要意义。
在文档处理领域,兼容性测试指文档处理软件在其他软硬件环境中的兼容能力,以及一种文档格式在不同的软硬件环境中的一致性,标准符合性测试主要是检查被测产品能否满足标准的要求[1]。由于流式文档格式复杂,且排版元素数量较多,一个办公软件格式规范中含有的排版格式功能点多达上千个。目前还没有成熟的可用于排版效果自动化测试的测试方法,测试工作主要通过人工测试完成。
在人工测试中,测试人员主要从文档的显现效果上对文档的排版元素类型及其排版格式进行分析,这种方法不仅费时费力,对于一些细小的排版差异或者排版元素类型也很难给出准确的测试结果。此外,在现有测试方法中,所有排版格式功能点的重要程度是一致的,未能考虑排版格式功能点使用频度的差异。显然,如果一款办公软件可以很好地支持大部分不常用的排版功能,而不能很好地支持个别常用的排版功能,那么从实用性的角度来说,这个办公软件的符合性和兼容性并不好。因此,如何针对流式文档本身特点,设计并实现一种客观、准确的流式文档排版效果自动化测试方法变得尤为重要,本文试图在这方面进行研究。
目前尚未见到与本文相同的研究内容,但是仍有一些相关的成果可以借鉴。例如,网页中也存在布局或排版的问题,并且网页信息的存储方式与流式文档相似。因此,与网页布局相关的自动化测试[2-3]研究可为本文提供参考。
在HTML页面分析中,很多方法都是通过分析DOM结构实现的。文献[4]提出了一种针对HTML期刊文章内容提取的版面分析算法,首先生成DOM树,然后根据标签内容和结构对网页进行分割,识别各部分段落内容。文献[5-7]通过比较HTML DOM结构来查找HTML元素的差异,但这些方法无法发现显现效果上的实际布局差异。
此外,还有一些方法是借助图像分析实现的。文献[8]将不同浏览器中呈现的测试网页的图像进行比较,以查找网页布局的不一致。文献[9]通过调用网页的API来获取HTML元素位置,并将测试图像和标准图像进行比对,找出存在差异的像素点及其位置,从而定位出现布局错误的HTML元素。
文献[10]对集合内的元素按照出错的可能性进行了排序,以查找最可能发生布局变化的元素。文献[11]在文献[10]研究的基础上创建了贝叶斯概率模型,将布局差异通过概率模型计算,从而得到最有可能导致这种差异出现的原因。
综上,在HTML 布局分析中,现有方法只对发生布局变化的元素进行了定位,并未给出HTML元素的布局变化程度,对于实现标准符合性和兼容性测试还是不够的。为弥补以往方法的不足,本文面向XML 的流式文档,提出了一种排版效果自动化测试方法,以实现对文档格式标准符合性和兼容性的自动化测试,技术路线如图1所示。
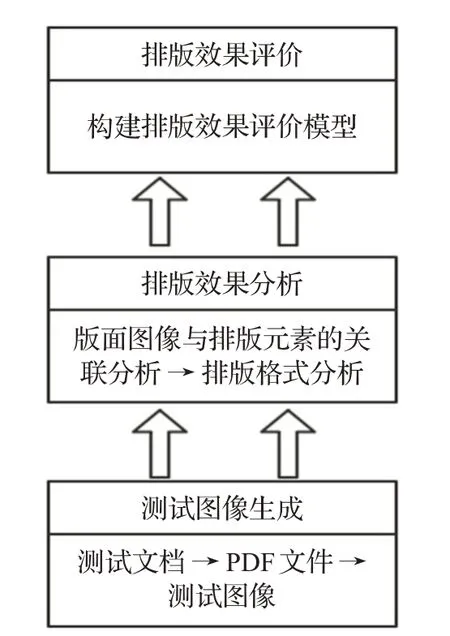
图1 总体技术路线
针对文档格式标准符合性和兼容性的测试需求,借鉴相关成果的研究方法,排版效果自动化测试将通过图像分析来实现,主要包括排版效果分析和排版效果评价两部分。其中,排版效果分析的研究目标是实现排版元素类型识别及其排版格式分析,排版效果评价的研究目标是针对上述分析结果给出客观、准确、量化的评价结果,为最终的测试结果提供评价依据。因此,本文的关键技术包括:(1)基于流式文档特点实现版面对象到排版元素的逆向关联分析,确定排版元素类型及其所在区域。(2)结合图像特征对排版元素进行排版格式分析。(3)结合统计方法和层次分析法构建排版效果评价模型。
1 排版效果分析
1.1 版面对象到排版元素的逆向关联
排版效果分析的首要任务是从图像中识别出版面对象类型,并将其与流式文档中的排版元素对应,即实现版面对象与排版元素的关联。因为一般的渲染过程是将排版元素映射到版面图像中,而自动化分析过程是从图像角度对版面对象类型进行分析,与渲染过程相反。因此,实现版面对象到排版元素逆向关联分析的最终目的是完成流式文档排版元素类型的识别。为方便表述,首先进行如下定义:
集合O={o1,o2,…,on} 表示待测图像的版面对象集合。
R 表示待测图像的版面区域,将R 划分成一组非空子区域{R1,R2,…,Rn} ,使(i ≠j),Ri(i=1,2,…,n)表示oi(oi∈O,i=1,2,…,n)所在区域。
集合E={e1,e2,…,en}表示待测文档的排版元素集合。
A 表示待测文档的页面区域,将A 划分成一组非 空子区域{A1,A2,…,An} ,使(i ≠j),Ai(i=1,2,…,n)表示ei(ei∈E,i=1,2,…,n)所在区域。
版面对象到排版元素的逆向关联可以定义为:如果区域Ri中有且仅有一个版面对象oi,且区域Ai中有且仅有一个排版元素ei,其中Ai与Ri存在一一映射的关系,则版面对象oi与排版元素ei存在关联关系。
因此,为了分析关联关系,需要将版面区域划分得足够小,使其与排版元素有一一对应的关系。
目前可参考的版面区域分割方法主要有三种:(1)自顶向下法,其主要思想是不断将版面划分成更小的部分[12]。(2)自底向上法,其主要思想是将较小的子区域进行合并,使其逐渐增大[13-17]。(3)混合型方法,其主要思想是将自顶向下法和自顶向上法两种方法进行结合,充分发挥两者的优势,使系统进行版面分析时更加准确、快速[18]。但是,版面分割方法多数都是基于连通区域实现的,而流式文档中段落的间隔区域大小基本相同,无法基于连通区域进行划分。因此,在流式文档版面对象的区域划分中,现有版面分割方法并不完全适用。
为避免版面分割方法的缺陷,本文借助流式文档可编辑这一特性设计了几种关联方法,如表1所示。
通过分析发现,为被测元素增加颜色标识不会影响文档中的排版元素个数,对版面效果影响较少。因此,本文设计了一种自动化的文档元素颜色标注方法,用于建立版面对象与排版元素的逆向关联关系,具体实现过程如下:
记存储流式文档排版元素信息的XML 文件为F,根据F 的元素标签可以得到文档元素集合E={e1,e2,…,en}。
记集合E 中的元素类型集合C ,按照排版元素类型所对应的标记颜色,依次修改文件F 中排版元素所对应的颜色值:ei.color=ci.color ,经过颜色标记后的文档记为F′。
设D 为经过颜色标记的流式文档,P 为D 生成的PDF文档,I 为P 打印生成的待测图像。打印图像的获取过程可表示为:F′→D →P →I 。
通过颜色标识可知,版面对象oi(oi∈O)的颜色值为color(oi),其所在区域为Roi。因此,根据排版元素ei所对应的标记颜色值color(ei),即可将待测图像中版面对象oi与待测文档中排版元素的元素ei(ei∈E)对应,即:color(ei)==color(oi)⇒class(ei)==class(oi)⇒R(ei)==R(oi)其中,R(ei)表示排版元素ei所在区域,class(ei)和class(oi)分别表示ei和oi的类型。
这种方法虽然能够准确地识别出排版元素类型并且划分出元素所在区域,但在测试过程中需要解决待测图像与原始图像发生色彩冲突的问题。针对这一问题,本文为每种排版元素设定多种备选颜色,机器将首先选择原图中未出现过的颜色作为标记颜色,从而避免了待测图像与原图像发生色彩冲突。
1.2 排版格式分析
1.1 节中通过分析版面对象与排版元素的关联关系,实现了排版元素的定位。排版效果分析的第二步是实现排版元素的排版格式分析,本节将对其分析方法进行讨论。
排版格式分析主要是从图像上对其功能点的属性值进行计算,判断图像上的测量值与预期值是否一致,从而实现对排版效果的分析。由于排版格式功能点数量较多,本文仅列举几种常用功能点的测量内容及其计算方法,具体如下:
(1)字号
字号的测量值为当前段落中最大的文字高度。
对当前段落中的每行文字分别做水平方向投影,每行文字的投影宽度记为pi(i ∈1,2,…,n),最终得到当前段落的投影宽度集合P={p1,p2,…,pn},文字高度H的计算方法如公式(1)所示:

(2)行距
行距的测量值为当前段落中相邻两行文字底部间距离的最大值。
记当前段落每行文字结束位置的纵坐标集合为Y={y1,y2,…,yn},行距D 的计算方法如公式(2)所示:
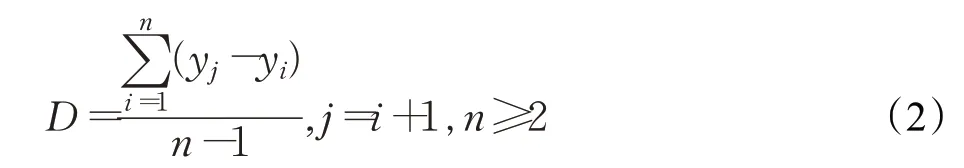
(3)首行缩进
首行缩进的测量值为当前段落的第一行文字起始横坐标与第二行文字起始横坐标的差值。
对前两行文字分别做垂直投影,投影的起始横坐标分别记为x1、x2,首行缩进F 的计算方法如公式(3)所示:

(4)对齐方式
对齐方式的判断内容包括左对齐、居中对齐、右对齐、两端对齐,以及分散对齐。
记图像宽度为w,对当前段落中的每行文字分别做垂直方向投影,每行文字的起始横坐标记为si(i ∈1,2,…,n),结束横坐标记为ei(i ∈1,2,…,n),最终得到起始横坐标集合S={s1,s2,…,sn},结束横坐标集合E={e1,e2,…,en}。记第一行中相邻两文字的起始横坐标之差记为xi,最终得到集合X={x1,x2,…,xn-1}。按照公式(4)至公式(8)的顺序依次进行判断,如果满足当前公式的成立条件,即为当前公式所对应的对齐方式。


通过版面对象到排版元素的逆向关联分析以及排版效果分析,可以从图像上进行排版元素类型的识别,并计算出各排版元素的实测属性值,为后续排版效果评价提供基础。
2 排版效果评价
2.1 排版格式功能点权重分析
排版效果测试的最终目标是得到被测文档排版效果与预期效果的一致性程度,而排版效果分析结果只是得到了被测文档的排版元素类型及其排版格式信息,量化的测试结果则需要通过排版效果评价模型分析得到。构建排版效果评价模型的第一步是为排版格式功能点设定合理的权重,文献[19]根据用户需求和实现难易程度等,对功能点进行了三个级别的划分,而在实际应用中,同一级别功能点的使用频度并不完全一致。
为确保每个功能点被赋予的权重更加客观准确,本文计算了每个格式功能点的使用频度。对100篇OOXML文档进行了解析,对打包文件内word目录下的document.xml文件的功能点路径进行了提取和统计,并采用层次分析法对用到的功能点的权重进行设定。表2 是对句属性中部分功能点使用情况的统计。

表2 句属性中部分功能点的使用情况
通过分析发现,文献[19]对功能点的级别划分较为宽泛,其中定义的一些基础级功能点在实际应用中的使用频率并不高。从表2 可以看出,在统计的100 篇文档中,基础级功能点下划线的使用次数仅为4 次,远低于字体、字号的使用次数。因此,本文认为采用层次分析法确定的权重更加客观合理。
由于统计文档中段落、表格和文本框的个数不平衡,本文将对三种排版元素功能点的权重分别进行分析,具体功能点及其所属排版元素类别如表3所示。
下面对权重的计算方法进行说明:
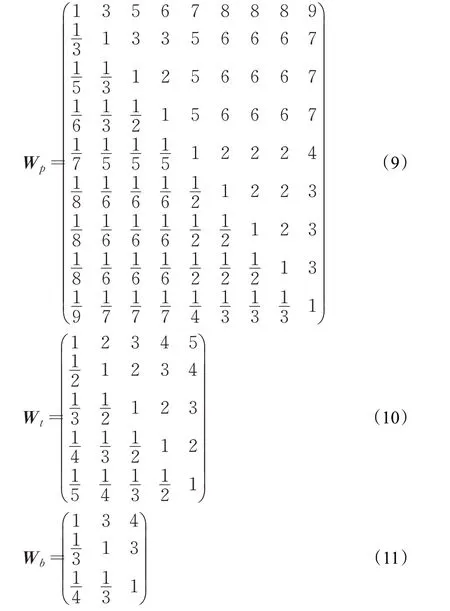
根据功能点的使用频率,构建各排版元素功能点的判断矩阵W,W 中元素wij为功能点i 相对于功能点j的重要程度,数值越大重要程度越高。显然,wji=经统计,段落功能点权重的判断矩阵Wp,表格功能点权重的判断矩阵Wt,以及文本框功能点权重的判断矩阵Wb,分别如公式(9)、(10)和(11)所示:

表3 进行权重分析的排版元素功能点
分别求出公式(9)、(10)、(11)中判断矩阵的最大特征值λmax,并带入公式(12)求得一致性指标CI 。

根据公式(13)求得矩阵一致性比例CR。

其中随机一致性指标RI 所对应的取值如表4所示。

表4 随机一致性指标表
经计算,公式(9)、(10)、(11)所对应的矩阵一致性比例CR 分别为0.094、0.017和0.063,均小于0.01,因此三个判断矩阵均通过一致性检验,判断构造矩阵合理,可继续进行权重求解。
对公式(9)、(10)、(11)中的判断矩阵进行归一化,然后采用算术平均法求得各个功能点的权重。其中,段落功能点的权重αT=(α1,α2,α3,α4,α5,α6,α7,α8,α9),表格功能点的权重βT=(β1,β2,β3,β4,β5),文本框功能点的权重γT=(γ1,γ2,γ3),最终得到各功能点的权重如表5所示。

表5 功能点权重对照表
2.2 排版效果评价模型
本节将结合排版效果分析结果,以及评价指标权重,构建排版效果评价模型,针对流式文档的实际排版效果与预期排版效果的一致性程度给出量化的评价结果,为最终的测试工作提供评价依据。下面讨论排版效果评价模型的构建。
设E={e1,e2,…,en}为排版元素功能点的预期值集合,T={t1,t2,…,tn}为排版元素功能点的实际测量值集合,D={d1,d2,…,dn}为排版元素功能点的实际测量值与预期值的一致程度集合,n 为当前排版元素的功能点个数。功能点一致程度di(i=1,2,…,n)的度量方法如公式(14)所示,如果功能点测量值为非数值型数据,则1表示一致,0表示不一致。

排版效果的总体评价需要考虑功能点使用的频度,按功能点的重要性加权进行评价。因此排版元素的排版效果评价模型如公式(15)所示:

其中,矩阵D 表示各功能点测试值与预期值的一致程度,矩阵W 表示D 中各功能点所对应的权重值,参见2.1节。
最终,求得整篇文档中所有排版元素的平均排版效果评价得分P,如公式(16)所示:

其中,Ei为某一排版元素的排版效果评价值,n 为待测文档中的排版元素个数和。
3 实验与分析
由于目前尚未见到可与本文的研究方法进行对比分析的相关成果,本文将通过实际案例说明本文提出方法的准确性及实用性。
图2 为原始OOXML 文档的预期排版效果,一般跟随测试案例给出;图3为从某个排版软件得到的同样文档的排版效果,将之作为待测文档。

图2 预期文档排版效果

图3 待测文档排版效果
应用本文方法,首先对待测文档进行自动化颜色标记,以从图像中确定排版元素类型。然后按照排版元素类型及其位置,进行排版格式分析以及排版效果评价,最终得到的结果如表6所示。
从图像中可以看出,图3 中段落2 与段落1 的间距明显小于图2。另外,在格式转换过程中,图3 中段落3的首行缩进丢失。对比表6 中的分析结果也可以得出这些结论,但是人工分析并不能从图像中看出这些差异的具体值。此外,从表6中可以看出,段落1中“字号”的实际结果和预期结果的差值仅为1个像素点,这些差异在人工测试中是很难得到的。
通过2.2 节构造的排版效果评价模型,对文档的排版效果进行定量分析。从表6中的评价结果可以看出,段落2只有段前距与预期结果存在差异,因此整体评分较高;而段落3 中丢失了首行缩进这一格式信息,且段后距和右缩进也与实际值存在差异,因此评分较低。
上述结果表明,相比人工测试,本文提出的评价方法自动化程度高,且更加准确。

表6 排版效果评价结果
4 结束语
本文面向XML的流式文档提出了一种排版效果自动化测试方法,包括排版效果分析和排版效果评价两部分。在排版效果分析阶段,设计了一种逆向关联方法从图像中定位并识别出排版元素类型,并采用图像分析方法测得不同元素的实际排版结果。在排版效果评价阶段,采用层次分析法根据功能点的使用频度确定功能点权重,构建了排版效果评价模型,以此给出文档排版效果的量化评价结果,从而完成排版效果的自动化测试工作。
本文提出的方法与传统的人工测试方法相比,提高了自动化程度和准确率,可以大幅提升各类文档格式的标准符合性和兼容性测试效率。本文方法还可以辅助定位出现差异的元素和属性,便于缺陷追踪和系统调试,提高文档处理软件的质量。此外,本文得到的量化评价结果还可以为文档格式标准制定以及文档互操作性度量提供参考依据,因此具有广阔的应用前景。
目前,本文主要对流式文档中的段落、列表、表格和文本框四类排版元素进行了排版效果分析。今后可以进一步增加图像、公式等排版元素的排版效果分析,使测试内容更加全面。
