基于改进梯形网络的半监督虚拟对抗训练模型
2021-01-22莫建文
莫建文, 贾 鹏
(桂林电子科技大学 信息与通信学院,广西 桂林 541004)
半监督分类是当前机器学习领域的一个重要研究方向。区别于传统的有监督分类算法,它能够基于标记样本,不依赖外界交互,自动地利用大量廉价的未标记样本提升学习性能。由于现实应用中利用未标记样本提升算法性能的巨大需求,半监督算法迅速成为了研究热点。
早期半监督学习算法中有较大影响力的是半监督自训练法和协同训练法。自训练法可看作是早期利用无标记样本的一种原始框架。先用少量标记样本初始化,然后分类大量无标记样本,选择可靠的伪标记样本扩充训练集,直到收敛。Li等[1]提出一种基于最优路径森林的自训练方法,其中所有样本作为最优路径森林的顶点相互连接,利用特征空间的结构和分布,帮助自训练法给未标记数据贴标签。Hyams等[2]基于自训练法,利用基于MC-dropout的置信区间作为置信度测量方法,得到改进的伪标记方法。Chen等[3]采用协同训练策略,并结合SVM算法进行分类器设计。该算法利用2个分类器对未标记样本进行分类,从而扩展标记样本,提高分类器性能。
随着深度学习在图像处理方面取得突破,半监督深度学习算法研究成为了自然的需求。许多学者通过优化网络结构构建的半监督分类学习框架都能取得不错的分类效果。如Springenberg[4]从损失函数的角度对网络优化,提出CAT-GAN,它改变了网络的训练误差,通过正则化信息最大化的框架提高了模型的鲁棒性。Salimans等[5]从判别器角度对网络优化,提出Improved-GAN,它在判别器后接一个分类器,训练网络得到一个分类判别器,可以直接将数据分为原始图像类别和生成图像假的类别,提高了生成样本质量和模型的稳定性。有学者将无监督深度学习网络与不同的有监督分类算法结合,也能得到较好的半监督分类模型。Rasmus等[6]利用去噪自编码构造梯形网络用于半监督分类任务,提高网络对更深层次图像特征的学习能力。付晓等[7]将生成对抗网络与编码器相结合,更好地提取特征。Larsen等[8]将变分自编码器和生成对抗网络结合,将生成对抗网络判别器学习到的特征表示用于变分自编码重构。Chen等[9]提出半监督记忆网络,第一次将记忆机制和半监督深度学习相结合,利用模型学习过程中产生的记忆信息,使预测结果更可靠。但是,半监督深层生成模型随着网络层数和参数的增多,会导致模型出现过拟合问题,并且半监督的方法未能充分利用大量未标记数据来辅助少量的有标记数据进行学习。
为了充分利用未标记样本,提高半监督深层生成模型的分类性能与泛化性能,在梯形网络框架的基础上,结合mix_up线性插值数据增强方法对训练数据进行预处理,并进一步讨论了虚拟对抗训练对模型鲁棒性的影响,提出一种基于改进梯形网络的半监督虚拟对抗训练模型(ILN-SS VAT)。本模型在梯形网络框架的基础上,引入虚拟对抗训练的正则化方法,结合mix_up线性插值法,完成数据增强操作,提高图像分类性能。首先,对训练数据进行凸融合,使用mix_up线性插值的方法得到新的扩充训练集;在梯形网络的输入层引入虚拟对抗噪声,并且保持编码器输出一致,对网络进行正则化;最后,模型以分类损失、重构损失和虚拟对抗损失相结合的方式调整参数,训练分类器。
1 ILN-SS VAT模型

ILN-SS VAT模型主要包括数据增强处理、虚拟对抗训练和训练分类器3个部分。梯形网络框架共有3个网络支路:有噪编码器、解码器和无噪编码器,其中编、解码器用VGG网络[10]或Π模型[11]。有噪编码器各层得到的特征变量通过跳跃连接(skip connection)映射到对应的解码器上,而无噪编码器则辅助解码器进行无监督训练,以达到对有噪数据的最佳映射效果。模型在训练时,先对训练数据做mix_up增强处理,使用线性插值的方法得到新的扩展数据输入网络。然后在梯形网络框架上计算对抗扰动,引入虚拟对抗损失构建平滑性正则化约束。最后,模型以分类损失、重构损失和虚拟对抗损失相结合的方式共同调整网络参数,训练得到分类器。
1.1 ILN-SS VAT模型数据预处理
为了解决半监督分类模型中有标记样本数不足的问题,在训练之前,模型采用mix_up数据增强方法进行数据预处理。mix_up[12]是一种运用在计算机视觉中的对图像进行混类增强的算法,它可以将不同类之间的图像进行混合,从而扩充训练数据集。

λ=Beta(α,β);
(1)
(2)
(3)
(4)
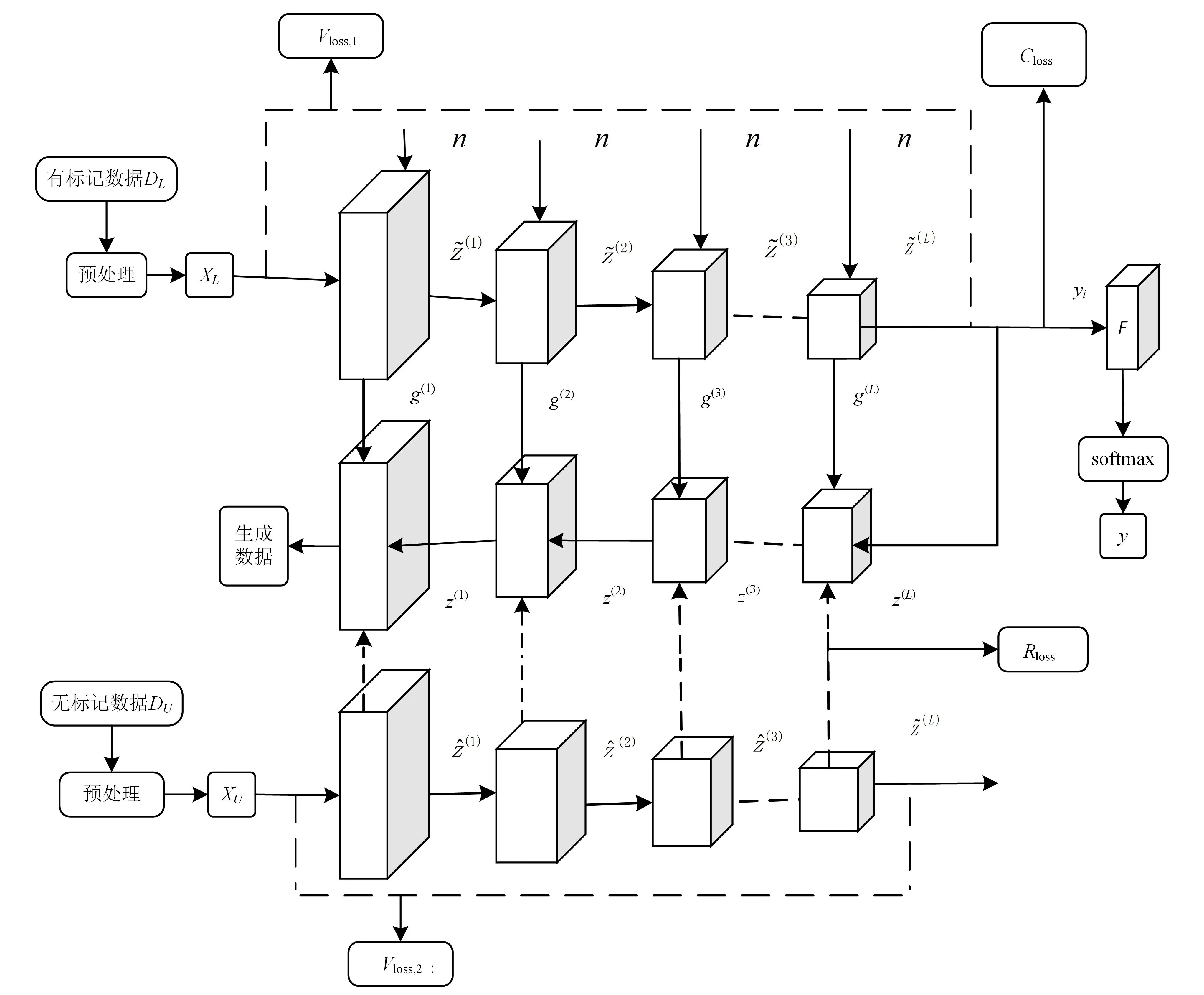
图1 ILN-SS VAT模型结构
mix_up是邻域风险最小化的一种形式,它令模型在处理样本之间的区域时表现为线性,相比于其他数据增强方法,这种线性建模减少了预测训练样本以外数据的不适应性,提高了邻域内的平滑性。此外,扩充训练数据集有助于消除对错误标签的记忆、网络的敏感性以及对抗训练的不稳定性,提高模型泛化能力。
1.2 ILN-SS VAT模型训练
ILN-SS VAT模型利用mix_up数据增强和虚拟对抗训练的优势,在梯形网络框架的基础上,以有监督分类损失、无监督重构损失和虚拟对抗损失相结合的方式共同调整网络参数,训练得到分类器,综合增强模型泛化能力,并且提高图像分类精度。
1.2.1 虚拟对抗损失
虚拟对抗训练是一种有效的正则化技术[13]。通过在实际数据点上应用小的随机扰动来生成人工数据点,鼓励模型为真实和扰动的数据点提供类似的输出。从分布散度的意义上,在虚拟对抗方向上的扰动能够极大地改变输出分布,虚拟对抗方向定义在未标记训练数据点上,使得当前的模型输出分布极大地偏离当前状态。

(5)
(6)
(7)
其中:p(y|x,θ)为模型输出分布;q(y|x)为输出标签的真实分布;D[p,q]为KL散度,用于评估p、q之间的距离。式(6)表示在r的L1范数小于某个值的情况下,找到使式(5)最大的radv,即为扰动方向,最小化两输出之间的KL散度即得到对抗损失Vloss,1。
虚拟对抗损失定义为模型的后验分布与每个输入点周围局部扰动的鲁棒性,相对于对抗训练的优点是,不需要标签信息就可以定义对抗方向,因此适用于半监督学习。
由于未标记数据的输出标签真实分布是未知的,当标记样本个数很大时,可用当前的模型输出近似代替未知的真实标签,并基于虚拟标签计算对抗方向。
(8)
(9)

(10)
将式(8)、(10)结合,得到总的损失:
(11)
虚拟对抗损失反映了当前模型在每个输入数据点的局部平滑度,当其减小时,会使得模型在每个数据点处更加平滑。相比于其它正则化约束,ILN-SS VAT模型针对对抗方向的扰动进行输出平滑,可提高模型对噪声的鲁棒性,防止过拟合。
1.2.2 重构损失
梯形网络框架中编码器的每层都有一个跳跃连接(skip connection)到解码层,有利于恢复编码器丢弃的信息,减轻编码器最高层特征表示的压力,也可以避免梯度消失的问题,这使得梯形网络框架能够与有监督算法兼容。
向有噪编码器的每层施加随机高斯噪声nl(l=0,1,2,…),得到有噪声输入为(x′l为未添加噪声数据)
(12)

(13)

(14)
有噪编码各层的特征变量通过跳跃连接映射到对应的解码层,将无噪编码器每层的特征变量作为目标值,通过无监督训练尽可能多地恢复出未添加噪声数据的信息特征。按照有噪编码器的思路,对解码器的每层都进行批归一化处理,不同的是在此之前需要进行降噪。根据Pezeshki等[14]的研究成果,已知有噪数据的特征变量μ和无噪数据的先验分布ε,可得到最优降噪函数
g(l)(x)=εx+(1-ε)μ=(x-μ)ε+μ。
(15)
解码器每层的特征变量表示为
(16)
同样的,对无噪编码的每层进行批归一化处理:
(17)

(18)
其中,λl超参数是第l层占的比重。通过最小化重构损失函数,使输出的重构样本尽可能多的恢复原有数据信息。
1.2.3 分类损失
ILN-SS VAT模型中的分类器采用Softmax来构建有监督分类损失。将有标记样本输入有噪编码器得到标签预测值,计算预测值与真实标签之间的交叉熵,得到有监督分类损失:
(19)
根据式(11)、(18)和(19),可得训练分类器总的损失函数:
L=Vloss+Rloss+Closs。
(20)
虚拟对抗损失、有监督损失和无监督损失都可以通过梯度下降法达到最小化,因此,采用将其结合的方式共同调整网络参数,通过虚拟对抗训练的方式进一步提高模型的泛化性。
2 实验仿真及结果分析
通过在MNIST数据集、SVHN上对ILN-SS VAT模型的学习特征能力和分类性能进行评估。
2.1 数据集及实验配置
MNSIT手写字符数据集:MNIST有10个类别,包括60 000个训练样本,10 000个测试样本。图像均为单通道黑白图像,大小为28×28的手写字符。参考文献[4-6,13],从训练样本中分别选取N1=100、N2=1 000个有标记数据作有监督训练,其余为无标记数据。
SVHN街牌号数据集:SVHN包括73 257个训练样本和26 032个测试样本。图像为彩色图像,大小为32×32,每张图片上有一个或多个数字,且图像类别以识别的正中数据为准。参考文献[4-6,13],从训练样本中分别选取N1=100、N2=1 000个有标记数据作有监督训练,其余为无标记数据。
实验硬件采用Intel Xeon E5-2687 W CPU、32 GiB内存和GTX 1080 GPU平台;软件采用Windows系统、Python语言、Tensorflow深度学习框架。
ILN-SS VAT模型,对较简单的MNIST数据集,网络结构采用Π模型,主要由9个卷积层、3个池化层和1个全连接层组成。对较复杂的SVHN,网络结构采用VGG-19,由16个卷积层、5个池化层和3个全连接层组成。模型为减少梯度对参数大小的依懒性,对每层编、解码结构都采用了批归一化处理,且设置批次大小为64。另外,实验中将遍历次数设置为总样本数除以批次大小,以增加多样性。为保证模型的收敛速度,采用指数衰减的方式更新学习率,并且定义初始学习率为0.02(MNIST)、0.003(SVHN)。实验设置迭代150个epoch(MNIST),180个epoch(SVHN)。
2.2 各个模块对模型分类性能的影响
为了进一步分析ILN-SS VAT模型中2个模块的有效性,以梯形网络框架为基准,提出2种混合方案。方案A不使用mix_up数据增强;方案B不使用虚拟对抗训练。实验结果如表1所示。
表1显示,ILN-SS VAT模型显著提高了数据集的分类精度。由此可发现,mix_up数据增强和虚拟对抗训练都是提升模型性能的重要因素。对MNIST数据集分别采样100和1 000个有标记样本,mix_up的改进率分别为0.32%和0.02%,虚拟对抗训练的改进率分别为0.63%和0.07%,通过结合这2个模块,改进率分别为0.67%和0.15%。结果显示,利用mix_up数据增强和虚拟对抗损失相结合的模式,使得梯形网络具备更强的学习能力,同时,也表明模型更具有效性。

表1 ILN-SS VAT模型及混合方案在MNIST数据集上的分类精度 %

图2 ILN-SS VAT模型生成图片与MNIST原始数据图片对比
2.3 实验分析及对比试验
梯形网络架构中,由于解码器是编码器逆运算的一个过程,也可通过观察解码后的图片质量评估模型的收敛程度。图2和图3分别显示了ILN-SS VAT模型趋于收敛时,生成图片与原始输入图片的对比情况。图2对MNIST数据集选取1 000个有标记数据,迭代训练150次趋于收敛,可以看出,已基本恢复出原始输入图片的信息,生成图片质量较高。图3对SVHN数据集选取1 000个有标记数据,迭代训练180次趋于收敛,生成的图片能够识别出正中的数字,基本能够与部分原始输入图片相匹配。观察图2、3可以发现,ILN-SS VAT模型对数据学习能力较强,并且在处理不同复杂程度的数据集时,都有很好的鲁棒性。

图3 ILN-SS VAT模型生成图片与SVHN原始数据图片对比
为了验证提出的ILN-SS VAT模型的优势,按照提出的实验配置和采样不同有标记样本数目,以分类精度为评价标准,与当前主要半监督深层生成模型进行对比,实验结果如表2、3所示。

表2 MNIST数据集上的分类精度 %

表3 SVHN数据集上的分类精度 %
实验结果显示,ILN-SS VAT模型具有更高的分类精度,证明了在半监督学习中处理对抗扰动的重要性,同时也证明了数据增强对模型分类性能提升的有效性。通过训练不同复杂程度的数据集,ILN-SS VAT模型仍具有较强的学习能力,表明其有很强的泛化能力。
为验证ILN-SS VAT模型的泛化性,对SVHN数据集选取1 000个有标记数据进行训练,并以基础梯形网络框架(VGG+Softmax)为基准实验,对模型趋于收敛时的测试集的损失作对比试验分析,如图4所示。

图4 模型趋于收敛时测试损失对比
从图4可看出,基础梯形网络框架在训练时,测试集损失开始会随着迭代进行慢慢下降,随着训练次数的增多,损失渐渐增大,相比而言,提出的ILN-SS VAT模型,随着训练的进行,测试集损失趋于稳定。这表明,ILN-SS VAT模型结合mix_up数据增强和虚拟对抗训练的模式能有效改善过拟合的问题。
3 结束语
为了进一步提高半监督深层生成模型的分类精度,减少过拟合,在梯形网络框架基础上,结合mix_up数据增强和虚拟对抗训练,提出了一种基于改进梯形网络的半监督虚拟对抗训练模型(ILN-SS VAT)。ILN-SS VAT模型相对其他方法有以下几点优势:1)用mix_up对训练数据做增强处理得到新的扩展数据,解决了半监督分类模型有标记样本较少的问题;2)对梯形网络框架施加虚拟对抗噪声,通过构建平滑性正则化约束,可有效增强模型的泛化能力;3)利用梯形网络的优势,通过对有监督分类损失、无监督重构函数和虚拟对抗损失总和的梯度下降来达到最小化,优化网络参数,得到分类性能更好的分类器。实验结果表明,针对不同复杂程度的图像数据集,ILN-SS VAT模型可利用少量的有标记数据训练得到更好的分类精度。同时,该模型也有一定的不足,训练时存在参数过多的问题,并且采用数据增强扩充训练数据导致训练较为耗时,在之后的工作中将继续研究如何能够保证分类精度,同时又能有效减少模型训练时间。
