基于款式变换和局部渲染相结合的虚拟试衣研究
2021-01-21普园媛赵征鹏钱文华阳秋霞
徐 俊,普园媛,b,徐 丹,赵征鹏,钱文华,吴 昊,阳秋霞
(云南大学 a.信息学院,b.云南省高校物联网技术及应用重点实验室,昆明 650504)
随着互联网技术的迅猛发展,越来越多的人喜欢在电商平台(如淘宝、蘑菇街、唯品会)购买衣服。但由于电商平台的特殊性,人们只能通过虚拟模特来观察服装效果,并不能直观地判断服装是否适合自己。针对如何让服装虚拟试穿到用户身上是目前试衣领域的研究热点,用户通过试衣结果体验自己穿着不同款式的服装,可以直观判断自己是否心仪某件衣服,从而帮助用户做出购买决策。
为了满足上述需求,学者们将GAN[1]应用于虚拟试衣任务,借助GAN将服装虚拟试穿到人物图像上,直观观察服装试穿效果。而虚拟试衣与图像生成[2-3]、图像翻译[4-6]以及图像编辑[7]等任务有着本质的不同。虚拟试衣时图像会产生几何形变,细节特征容易丢失,因此学者将传统的像素间损失(L1和L2损失)和感知损失[8]引入到GAN中,来保留图像信息。此外还引入了对抗损失[4],最大限度减小对抗损失,使得生成器生成的图像更接近原始图像,但是会遗漏关键的细节特征。在面临巨大的几何变化时,细节的保存能力较差,这就限制了GAN在虚拟试衣中的应用。
DONGGEUN et al[9]采用结合GAN和深度CNN的方式来完成图像生成任务,在没有考虑人物姿势的前提下,通过穿着服装的人物图像生成其上衣图像。LASSNER et al[10]提出了图像级穿着全身服装的人物生成模型,可以根据人物姿势形态进行服装调整,但服装是随机生成,并没有考虑如何控制服装项。WEI-LIN et al[11]训练了提升服装时尚感的模型,能自动度量时尚标准,对全身服装进行微小改变,可以将输入图像的服装调整为更加时尚的服装。NIKOLAY et al[12]采用GAN实现2D试衣,让模特试穿给定的服装,但是没有考虑人物的姿态,要求人物图像和服装图像高度对齐。WANG et al[13]提出了通过一个端到端的网络来聚合服装图像的多尺度特征,结合姿态和参考服装生成新人物图像,但参考服装的纹理形变程度过大,偏离了原始图像的纹理。YANG et al[14]在TPS形变的基础上,引入了二阶差分约束,使得参考服装的纹理不会发生较大形变,效果更加真实,但人物姿态较为复杂时,会出现无法正确试衣的情形。HAN et al[15]提出先生成粗糙试衣图像,再对参考服装的特征信息进行二次提取,来合成更加真实的试衣图像,但是依然会丢失服装和人物细节特征。WANG et al[16]在此基础上,提出了特征保留的试衣网络,更好地保留了参考服装图像的细节特征,但试衣后人物细节特征丢失,除服装区域变化外,人物手臂手部区域以及其它非试衣服装区域发生了不可控的变化,无法合成更加写实保真的图像。MINAR et al[17]在WANG et al[16]的基础上,提出了服装形状和纹理保留网络,虽然它优于目前的方法,但对于长袖款、纹理复杂的服装图像,以及姿态复杂的目标人物图像,它并不总是能生成满意的试衣效果。
针对上述问题,本文提出了款式变换和局部渲染相结合的虚拟试衣方法,保留参考服装细节信息的同时,需保持目标人物图像的手臂区域、手部脸部区域、头发区域以及非试衣区域等信息不变,然后将服装渲染到人物图像的目标区域来完成试衣(如图1所示)。其过程主要包括以下几个步骤:
首先,对人物图像进行像素级语义分割,寻找出具体的服装区域,为局部渲染的实施创造条件;其次,试衣时,如果仅对服装区域进行渲染,当目标服装图像和参考服装款式不同时,局部渲染策略则无法实现,因此需要应用款式变换模块将其转换为与参考服装相同的款式,从而实现不同服装款式间的换装。此外,提出的款式变换模块是可学习的,便于学习多种服装款式之间的转换;第三,为了让服装更好地符合试穿者身材,提出了可学习的TPS服装形变模块,将参考服装根据目标服装图像的身材姿态进行相对应的形变;最后,将形变过的服装无缝地渲染到目标图像上,采取局部渲染策略(仅对服装区域进行渲染),保留了人物原始的细节特征。

图1 款式变换和局部渲染相结合的虚拟试衣效果Fig.1 A virtual try-on effect that combines style transformation and local rendering
1 虚拟试衣网络
本文在上述基础上,为了更好地保留服装细节特征和人物细节特征,提出了款式变换和局部渲染相结合的虚拟试衣网络(如图2所示),主要包含4个部分:服装语义分析模块、服装款式变换模块、服装形变模块和服装渲染模块。


图2 本文虚拟试衣网络框架Fig.2 Virtual try-on network in this paper
此外,由于款式转换需要两幅服装图像在相同域下进行转换,因此无法直接实现目标图像I1和参考服装图像R之间的转换,这也是引入参考图像I2的原因,此外参考图像I2可以是与参考服装图像R款式相同的任意图像。
1.1 服装语义分析模块
对服装I1、I2进行语义分割,提取出具体的服装区域,是款式变换的前期工作。主要包括3个步骤:1) 利用马尔科夫随机场作为基础网络模型,寻找出相邻像素点,确定具体的服装区域;2) 为了能让计算机自动辨别服装区域的标签Ii,选定标签过的服装区域作为正样本,其他外部区域作为负样本,训练分类器C;3) 采取滑动窗遍历整幅图像,通过分类器寻找出指定标签的服装区域,进而提取该区域掩膜M.
1.2 服装款式变换模块
款式变换模块包含生成器Gst和判别器Dst.生成器输出生成的图像,由6层卷积网络和3层残差块组成。判别器Dst对生成器Gst产生的图像I*进行真假样本的判定,由3层卷积层组成。卷积层作为特征提取,残差块级联邻层特征,作为特征优化。
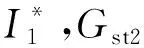
Lcyc=‖Gst2(Gst1(I1,M1))-(I1,M1)‖1+
‖Gst1(Gst2(I2,M2))-(I2,M2)‖1.
(1)
Lidt=‖Gst1(I2,M2)-(I2,M2)‖1+
‖Gst2(I1,M1)-(I1,M1))‖1.
(2)
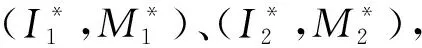
(3)

L1sgan=(Dst(I1,M1)-1)2+Dst(Gst(I2,M2))2.
(4)
款式变换模块的整体损失Lst:
Lst=L1sgan+λcycLcyc+λidtLidt+λctxLctx.
(5)
1.3 服装形变模块
服装形变模块由2个特征提取网络、1个特征连接网络、1个回归网络和1个TPS转换网络组成。

Lwarp(θ)=‖R*-Rgt‖1.
(6)
式中:Rgt为目标人物服装的Ground-truth图像。
1.4 服装渲染模块
服装渲染模块由6层卷积网络和3层Unet网络组成。卷积层作特征提取,Unet层采用3个跳连接,将低层和高层特征进行拼接,更好地保留原始特征。
Lrender=λL1‖It0-Igt‖1+λvggLVGG(It0,Igt) .
(7)
式中:Igt为ground-truth图像,LVGG为VGG感知损失函数。
2 实验
2.1 数据集
实验部分使用HAN et al[15]提出的数据集,约16 000对图像,每对图像包括参考服装图像、目标人物图像、语义分割图、人物姿态图以及mask图像,服装人物图像主要是纯色背景的女性上装图像,随机选取14 221对,2 032对作为训练集和测试集。选取该数据集中两种不同款式的服装图片若干张,作为款式变换模块的训练,例如在训练长短袖转换时,选取120张长袖图片和120张短袖图片进行训练。此外,为了更好地验证款式变换的效果,还使用了LIANG et al[21]提供的CCP数据集,该数据集包含约2 000张背景复杂的人物服装图片。
2.2 实现细节
语义分析、款式变换、服装形变和服装渲染4个模块均在pytorch平台下完成,输入和输出图片分辨率均为256×192.其中,款式变换模块初始学习率为0.000 2,选取Adam优化器,批量大小为1,单GPU训练约60 h;服装形变和服装渲染模块初始学习率为0.000 1,选取Adam优化器,批量大小为4,单GPU训练耗时约25 h.本文基于分辨率256×192的图像来计算PSNR、SSIM和MSE值,以此作为定量评价指标。
3 结果与讨论
WANG et al[16]提出的虚拟试衣网络CP-VTON是目前该虚拟试衣领域较新、效果较好的方法,因此,本文后续实验都是基于CP-VTON的方法进行相关比较。
3.1 验证模型性能
为了验证模型的有效性,且便于与Ground-Truth进行比较,用本文提出的方法与CP-VTON方法测试了训练集中所有图片(14 221张),随机选取了部分结果,如图3所示。

图3 两种方法验证训练集结果比较Fig.3 Results of the two methods in training dataset
从图3可以看出,CP-VTON和本文方法都能完成试衣。但CP-VTON会丢失人物一些细节特征,例如人的手臂、手部等细节特征,此外,试衣后的人物下装发生了不可控的变化。对于这些问题,本文提出的方法实现了较好的效果。
3.2 定性比较
在测试集进行了相关测试,该部分测试主要包括不同款式的试衣测试、人物手臂姿势简单的试衣测试和人物手臂姿势复杂的测试。
3.2.1不同服装款式的试衣测试
当参考服装图像和目标人物图像的款式不同时,应用款式变换模块将目标图像变换为与参考图像相对应的款式,例如图4中参考图像为短袖、目标图像为长袖,应用款式变换将目标图像变换为短袖款式,然后再结合参考图像进行试衣。

图4 两种不同款式换装结果比较Fig.4 Comparison of two different styles
由图4可以看出,本文方法更好地保留人物的细节特征,但也产生了微弱的失真。由于不同款式间的换装,本文方法需要经过款式变换模块,该模块在服装渲染前需要进行款式之间的转换(如图4中目标图像由长袖款变为短袖款),经款式变换后的图像会产生一定程度的失真,该失真同样影响着最终的试衣结果。
3.2.2人物姿势简单类的试衣测试
当目标人物手臂姿势较为简单时,本文方法和CP-VTON方法的实现效果较好。由图5可知,当目标图像手臂姿势较简单时,两种方法都达到了令人满意的效果,但本文方法在人物细节特征保持方面优于CP-VTON.

图5 姿势简单类的测试结果Fig.5 Test results of easy poses
3.2.3人物姿势复杂类的试衣测试
当目标人物手臂姿势较为复杂时,先前工作试衣失败或者效果不佳。如图6可以看出,CP-VTON进行试衣渲染时,会出现手臂和手部细节丢失、位置错误以及下装随机改变等情况。
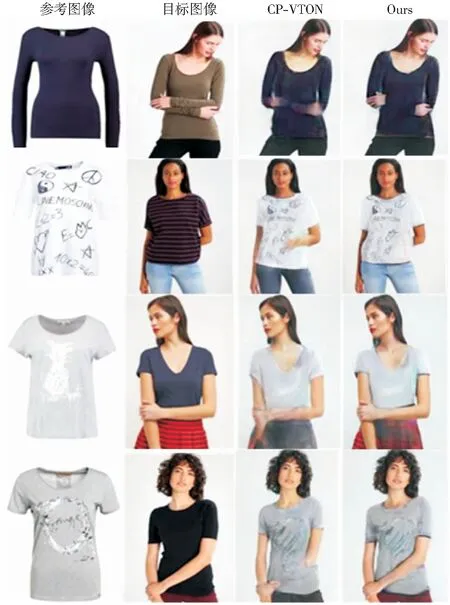
图6 姿势复杂类的测试结果Fig.6 Test results of complicated poses
从图4-图6的整体结果比较可以看出,本文提出的款式变换和局部渲染相结合的试衣方法效果更加显著。该方法摒弃了传统的全局渲染的试衣方法,采用先进行服装语义分割,确定具体的服装区域后,仅对服装区域进行渲染的策略,不再对人物图像整体进行渲染,很好地保证了除试穿的服装区域外,其他非试衣区域的特征信息不会丢失,同时也保证试穿上装时,下装不会发生变化。尤其在保持人物手臂、手部细节以及下装不变等方面效果较好,证实了算法设计的有效性。
3.3 定量比较
上述定性比较是基于视觉层面上的结果对比,该部分为了更好地比较两种方法的效果,采取定量比较的方式,选取了3个评价指标对生成结果进行评测,其中PSNR、SSIM、MSE分别表示两幅图像间的峰值信噪比、结构相似性以及均方误差,评测结果如表1和表2所示。

表1 随机选取50组实验结果Table 1 50 groups of test results selected randomly

表2 全部测试结果Table 2 All test results
表1是随机选取50组实验结果的数据,表2是全部测试结果(共14 221组)的数据。从表中可以看出,本文方法的PSNR值略高于CP-VTON方法,表明了本文方法试衣后的图像质量更好。SSIM值基本一致,表明两种方法在图像结构性保留方面都有着较好的效果。此外,本文方法的MSE值小于CP-VTON方法,说明了本文方法的图像失真较小,更好地保留了原始图像的结构特征,试衣后图像更加保真。
4 结束语
图像级的虚拟试衣是一项复杂的研究任务,先前方法在试衣时,人物图像手臂、手部等细节特征容易丢失,此外,在试穿上装时,下装发生不可控的变化。针对上述问题,本文提出了款式变换和局部渲染相结合的虚拟试衣网络:先对人物图像进行像素级语义分割,寻找出具体的服装区域,为服装的局部渲染提供前提条件。为了实现不同服装款式间的试衣,构造可学习的款式变换模块;此外,为了让服装更好地符合试穿者身材姿态,使用了可学习的TPS服装形变模块,从而使试衣后图像更加保真写实。除试衣的服装区域外,保留了原始图像的其他细节特征。
在未来的研究中,虚拟试衣有着广阔的研究前景。但是还有一些问题需要继续展开深入研究:1) 在实现图像保真的前提下,试衣时应考虑参考服装图像的款式,不仅仅是基于目标图像进行试衣。目前该方法实现起来难度较大,不仅是简单地将形变后的参考服装图像试穿到目标图像上,还要结合参考服装图像的款式,进行试衣;2) 首次将InstaGAN应用于服装款式转换,由于服装款式的多样性,实现难度较大,效果还有待提升,后续还需要进行相关改进,增强款式转换后图像的真实感。
