重庆话[n]、[l]分混的听感研究
2021-01-20孙旭
孙 旭
(贵州大学 文学与传媒学院,贵阳 550025)
一、概说
重庆方言大多数地区都属于西南官话片区下的成渝片,具有不分鼻音n和边音l、不分翘舌音和平舌音等特点,前辈学者的考察早有论断[1]。在现代汉语普通话中,[n]和[l]是两个独立的不同音位,它们分别来自古泥来母,[n]和[l]的发音方法相同点在于:气流都要流经口腔。但其区别也十分明显,[n]的发音气流必须流经鼻腔。学者们通过传统方言学的音位归纳指出:重庆人多将泥来母读为[l][2];而方言材料中却大都认为重庆人将泥来母读为[n][3]。这两种截然不同的结论至今没有得到很好的解答。
二、实验说明
(一)实验词
本次实验从现代汉语普通话中挑选实验词组成实验词对,词对除声母(n或l)外,韵母、声调均相同。
(二)实验程序
本次实验发音人为男性,老北京人,在安静的录音室中进行录音,录音软件为Cool Edit Pro 2.0,采样率为22 050 Hz,16位,单声道。后期用Adobe Audition CS6 对录音文件进行切割和合并,最后用E-Prime 1.0进行实验和数据收集,使用Excel对数据进行统计分析。实验均采用E-Prime 1.0来完成,每一实验正式开始前均有练习部分(不计入数据统计)。
实验的具体流程为:注视点→被试按空格键→播放提示音→显示选择画面→被试按键选择,之后选择界面消失→注视点再次出现。
(三)实验内容
被试听到的均为自然语音。实验共分4部分,分别为单字组、双字组、基本词汇/一般词汇、语流(其中单、双字组分为辨认实验和区分实验)。
在辨认实验中,单字组共212个刺激音,双字组共93个刺激音,实验每次播放1个刺激音,顺序随机,要求被试在测试界面上选出所听到的音。
在区分实验中,单字组共130对刺激音,双字组共122对刺激音,实验每次播放1对刺激音,顺序随机,要求被试判断听到的两个音是否相同。
在基本词汇/一般词汇的实验中,共178个刺激音,实验每次播放1个刺激音,顺序随机,要求被试选出包含所听到刺激音的词。
语流实验挑选在区分实验中出现的成对实验词进行造句,所造的句子必须包含该对实验词对。语流实验共37个刺激音,每次播放1个句子,顺序随机,被试需要选出他所听到的在句子中首先出现的词语。
(四)被试
本次实验共有20位被试,均为重庆人,20岁左右青年,无缺患。本实验的分类主要考虑被试受普通话影响程度,将20位被试分为三组。
第一组:没有受过普通话训练,在发音时分不清声母l和n,在听觉上也分不清,共11人,其中6位男性,5位女性。
第二组:没有受过普通话训练,在发音时分不清声母l和n,但在听觉上可以分清,共5人,其中2位女性,3位男性。
第三组:受过普通话训练,在发音时能分清声母l和n,在听觉上也可以分清,共4人,其中2位男性,2位女性。
(五)实验参数
本次实验统计被试在不同条件下的选择正确率:即被试选择的结果和其听到的刺激音一致。计算公式为:
正确率=选择正确数/总数
在辨认实验中,“正确率”即为“辨认率”;在区分实验中,“正确率”即为“区分率”。
三、实验结果分析
(一)辨认单双字组
1.辨认单字组
表1为三组被试[l]、[n]的总体辨认率。

表1 三组被试单字组总体辨认率
由表1看出,第一组[l]的辨认率为57.98%,[n]的辨认率为62.95%;第二组[l]的辨认率为61.89%,[n]的辨认率为72.64%;第三组[l]的总体辨认率为76.42%,[n]的总体辨认率为88.44%。第一组[l]、[n]的混淆情况最严重,其次是第二组,第三组较前两组来说最不易混淆。但是,第三组的辨认率最高的也仅仅为88.44%,同时,[l]的辨认率明显低于[n]的辨认率,在听感上,三组的被试选择均倾向于[n],[l]和[n]的辨认率是第三组>第二组>第一组,整体上来说n的辨认率高于l的辨认率。
表2为三组被试在单字组不同韵母条件下[l]、[n]的辨认率。
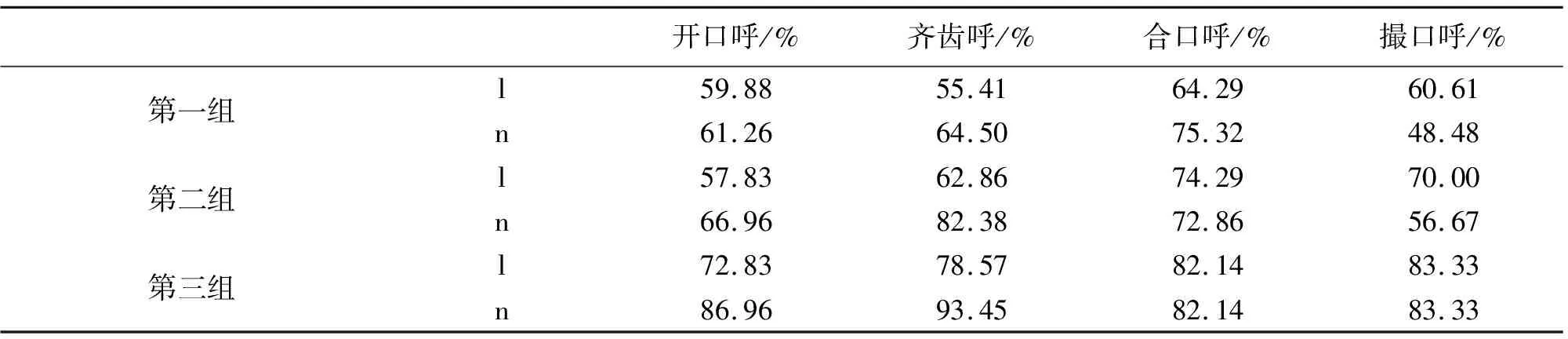
表2 三组被试单字组不同韵母条件下[l]、[n]的辨认率
由表2可以看出,第一组[l]的辨认率是合口呼>撮口呼>开口呼>齐齿呼,[n]的辨认率是合口呼>齐齿呼>开口呼>撮口呼;第二组[l]的辨认率是合口呼>撮口呼>齐齿呼>开口呼,[n]的辨认率是齐齿呼>合口呼>开口呼>撮口呼;第三组[l]的辨认率是撮口呼>合口呼>齐齿呼>开口呼,[n]的辨认率是齐齿呼>开口呼>撮口呼>合口呼。
第一组中除了撮口呼外,其他三呼的辨认率均是[n]的辨认率大于[l]的辨认率,被试在声母条件下的选择倾向于[n];第二组中,开口呼、齐齿呼的辨认率情况是[n]的辨认率大于[l]的辨认率,合口呼和撮口呼的辨认率情况是[l]的辨认率大于[n]的辨认率,被试在声母条件下的选择没有明显的倾向;第三组与前两组相同之处在于,开口呼、齐齿呼的辨认率情况是[n]的辨认率大于[l]的辨认率,被试的选择总体上更倾向于[n]。
表3为三组被试在单字组不同声调条件下[l]、[n]的辨认率。
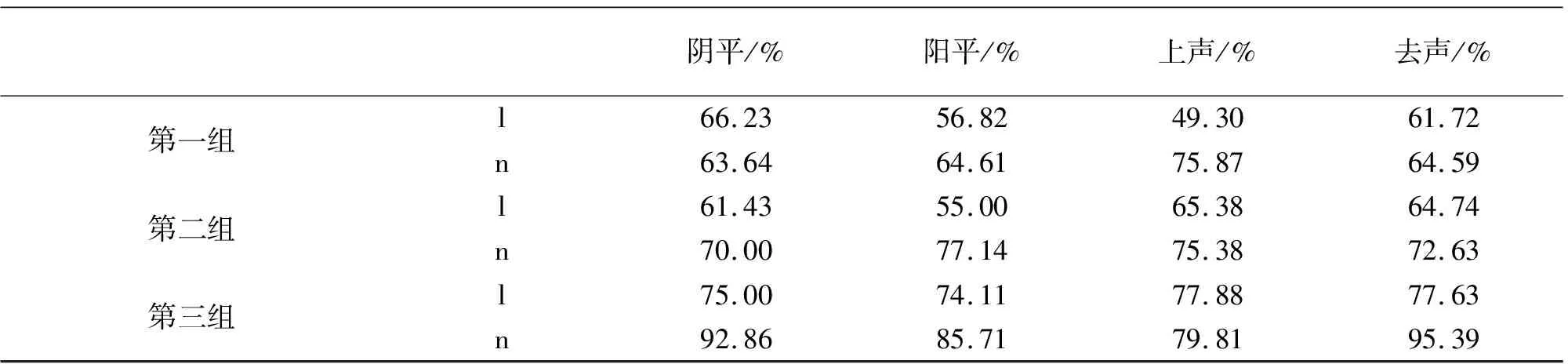
表3 三组被试不同声调条件下[l]、[n]的辨认率
第一组中,阴平条件下[l]的辨认率大于[n]的辨认率,阳平、上声和去声均是[n]的辨认率大于[l]的辨认率;第二组和第三组中,四呼条件下均是[n]的辨认率大于[l]的辨认率,在声调条件下,被试的选择倾向于[n]。
2.辨认双字组
表4是三组被试双字组[l]、[n]的总体辨认率,前字组是对比字在前,后字组是对比字在后。
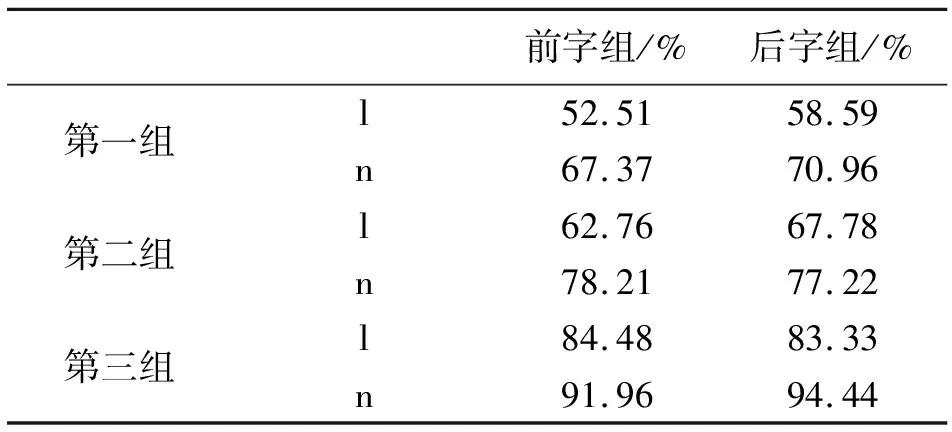
表4 三组被试双字组前、后字组辨认率
由表4可知:第一组[l]的辨认率是后字组(58.59%)>前字组(52.51%),[n]的辨认率是后字组(70.96%)>前字组(67.37%);第二组[l]的辨认率是后字组(67.78%)>前字组(62.76%),[n]的辨认率是后字组(77.22%)<前字组(78.21%);第三组[l]的辨认率是后字组(83.33%)<前字组(84.48%),[n]的辨认率是后字组(94.44%)>前字组(91.96%),除了第二组的[n]和第三组的[l],均是后字组的辨认率大于前字组的辨认率。同时,在前字组条件下,第一组的辨认率情况是[n](67.37%)>[l](52.51%),第二组的辨认率情况是[n](78.21%)>[l](62.76%),第三组的辨认率情况是[n](91.96%)>[l](84.48%);在后字组条件下,第一组的辨认率情况是[n](70.96%)>[l](58.59%),第二组的辨认率情况是[n](77.22%)>[l](67.78%),第三组的辨认率情况是[n](94.44%)>[l](83.33%)。
3.小结
从上述实验结果分析可以看出:总体上来说,三组被试的辨认率情况是[n]的辨认率大于[l]的辨认率,被试在进行听辨的选择时,倾向于选择[n],且辨认率情况是第三组>第二组>第一组。值得注意的情况是,被试对泥来母与撮口呼相结合的音节更为敏感,辨认率最高。
(二)区分单双字组
1.区分单字组
表5是三组被试的单字组总体区分率。
综上所述,乡村振兴体现了历史与现实的统一。我国有着悠久的历史,乡村在国家中占有着重要地位,乡村的富庶是我国盛世历史的标志,也留下了数不清优美田园浪漫诗篇。新中国成立后,城乡关系曾历经分离、对立、统筹、一体化,终回归于融合。[10]9推进乡村振兴,要以习近平总书记“三农”思想为根本遵循,借鉴国内外先进经验,对标最高最优最好,既要有“坐不住、等不起、慢不得”的紧迫感,更要有久久为功的韧性,驰而不息的坚守,紧紧围绕乡村振兴总要求扎实推进。

表5 三组被试单字组总体区分率
由表5可知:第一组[n]和[l]的区分率为54.97%;第二组[n]和[l]的区分率为63.21%;第三组[n]和[l]的区分率为79.72%;三组被试的区分率情况是第三组>第二组>第一组,三组被试对[n]和[l]均表现出一定程度的混淆,并且这种混淆随着普通话的影响而逐渐减轻。
表6是三组被试在单字组不同韵母条件下[n]、[l]的区分率。
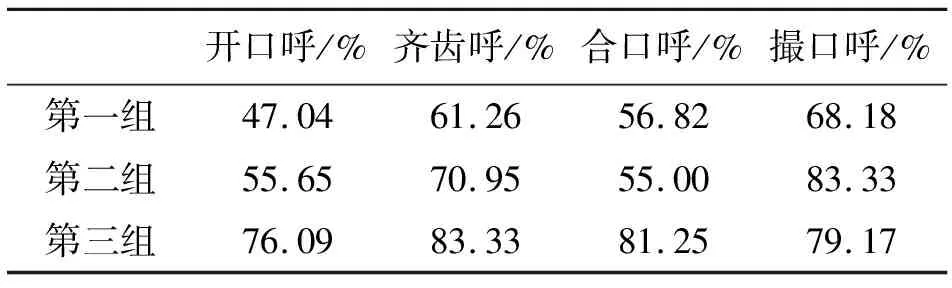
表6 三组被试单字组不同韵母条件下[n]、[l]的区分率
由表6可知:第一组[n]、[l]的区分率从高到低为撮口呼>齐齿呼>合口呼>开口呼,其中,开口呼的区分率最低,撮口呼的区分率最高;第二组[n]、[l]的区分率从高到低为撮口呼>齐齿呼>开口呼>合口呼,其中,合口呼的区分率最低(开口呼的区分率55.65%只比合口呼的区分率55.00%高0.65%,十分相近),撮口呼的区分率最高;第三组的区分率从高到低为齐齿呼>合口呼>撮口呼>开口呼,其中,齐齿呼的区分率最高,开口呼的区分率最低;除了第二组撮口呼的区分率比第三组撮口呼的区分率高外,三组被试的区分率仍然是第三组>第二组>第一组,撮口呼的区分率在四呼中较高。
表7是三组被试在单字组不同声调条件下[n]、[l]的区分率。

表7 三组被试单字组不同声调条件下[n]、[l]的区分率
由表7可知:第一组[n]、[l]的区分率从高到低为去声>阴平>阳平>上声,其中去声的区分率最高,上声的区分率最低;第二组[n]、[l]的区分率从高到低为去声>上声>阴平=阳平,其中去声的区分率最高,阴平、阳平的区分率最低;第三组[n]、[l]的区分率从高到低为去声>上声>阴平>阳平,其中去声的区分率最高,阳平的区分率最低;除了第一组的阴平区分率略大于第二组的阴平区分率外,均是第三组>第二组>第一组,且三组中,均是去声的区分率最高。
2.区分双字组
表8是三组被试双字组总体区分率。

表8 三组被试双字组总体区分率
由表8可知:第一组双字组的总体区分率是63.04%;第二组双字组的总体区分率是71.30%;第三组双字组的总体区分率是71.30%;三组被试双字组的总体区分率由高到低是第三组=第二组>第一组;受过普通话训练的第三组被试的双字组区分率和没受过普通话训练的第二组被试双字组区分率相同,第三组和第二组的双字组总体区分率均大于第一组。
表9为三组被试双字组在前后字组条件下的区分率。
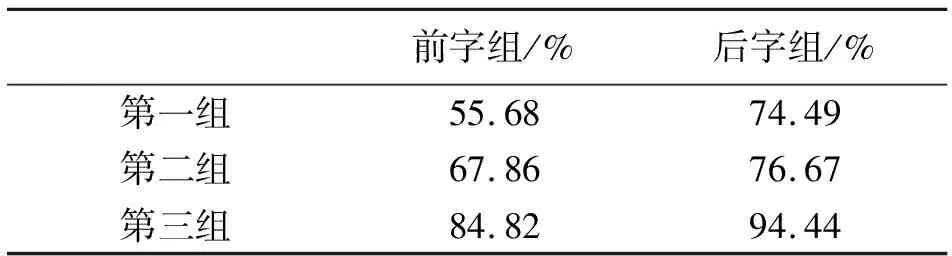
表9 三组被试双字组前、后字组区分率
由表9可知:第一组的前字组区分率为55.68%,后字组的区分率为74.49%;第二组前字组区分率为67.86%,后字组的区分率为76.67%;第三组的前字组区分率为84.82%,后字组的区分率为84.82%;前字组和后字组区分率情况均是第三组>第二组>第一组,每一组的区分率情况均是后字组>前字组,被试在后字组条件下更容易区分。
3.小结
从上述区分单双字组的实验结果分析来看,被试的区分率仍然是第三组>第二组>第一组,而且在区分单字组中,被试对韵母中的撮口呼以及声调中的去声有更高的区分度。
重庆话大都属于湖广话,是明洪武及清前期移民的结果[4],湖广话泥来母一二等字相混,三四等字区分是整体趋势[5],虽然重庆人泥来母全混,但仍不可避免地受到湖广话整体的影响,撮口呼开口度极小,因此被试能较好地区分撮口呼音节。重庆方言的声调里,阳平与上声都是降调,这与普通话去声的调型相同,因此被试能更好地辨认去声条件下的泥来母音节。
(三)基本词汇和一般词汇
基本词汇的主要特点是全民常用的,包括语言中具有悠久历史,至今仍在日常交际中独立使用的词,具有稳固性,构词能力较强;一般词汇的主要特点是不是全民常用的,是词汇中除了基本词汇之外的词构成的,不稳固,构词能力弱。本实验所选的基本词汇均是生活或学习中常用的,一般词汇均是专有名词或者专业术语。
表10是三组被试在基本词汇和一般词汇条件下的区分率。
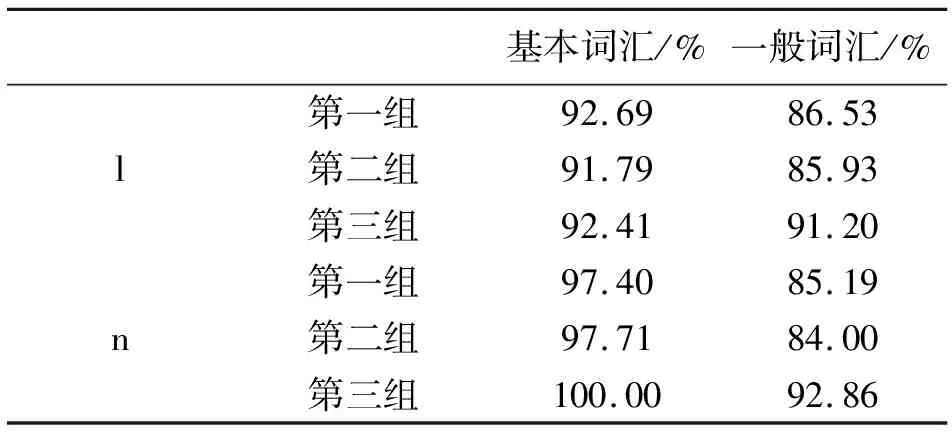
表10 三组被试声母[l]、[n]基本词汇与一般词汇区分率
由表10可知:[l]中,第一组的基本词汇的区分率是92.69%、一般词汇的区分率是86.53%,第二组基本词汇的区分率是91.79%、一般词汇的区分率是85.93%,第三组的基本词汇的区分率是92.41%、一般词汇的区分率是91.20%;[n]中,第一组的基本词汇的区分率是97.40%、一般词汇的区分率是85.19%,第二组的基本词汇的区分率是97.71%、一般词汇的区分率是84.00%,第三组的基本词汇的区分率是100.00%、一般词汇的区分率是92.86%;不论是在[n]中还是在[l]中,基本词汇的区分率均高于一般词汇的区分率。
(四)语流
表11是三组被试语流的区分率。
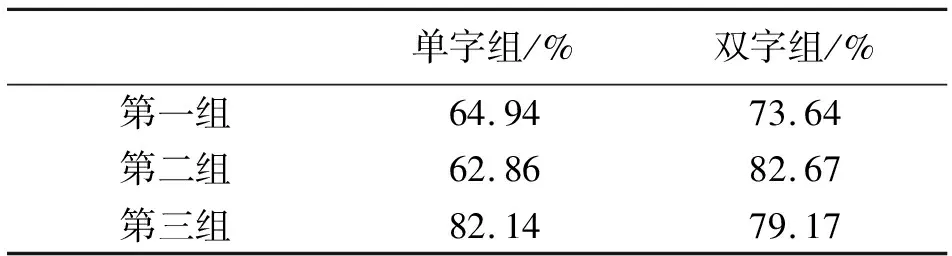
表11 三组被试语流实验单、双字组区分率
由表11可知:在语流实验听辨的第一组实验数据中,单字组的区分率为64.94%,双字组的区分率为73.64%;第二组实验数据中,单字组的区分率为62.86%,双字组的区分率为82.67%;第三组实验数据中,单字组的区分率为82.14%,双字组的区分率为79.17%。
总 结
本文通过语音听辨的实验方法采集了重庆人对[n]、[l]的辨别与区分数据,由上述数据统计结果得出以下初步推论:
(1)辨认单双字组中,三组的实验辨认正确率为第三组>第二组>第一组,通过第一组和第二组比较,可以发现同样未曾受过普通话训练的被试中,在北方方言区学习的被试,[n]和[l]的辨认率比未在北方方言区学习的被试的辨认率高,被试受普通话影响越大,其实验辨认率越高。
(2)区分单双字组中,撮口呼和去声的区分率明显较高。从声调上可以很明显地看出重庆话与普通话声调的不同,重庆方言阳平和上声的调值分别是21和42,两个声调都与普通话四声类似,由此推测:重庆方言使用者更容易区分降调条件下的[n]和[l]。
(3)泥来母与开口度最高或最低的由舌面前元音为主要元音的韵母组成音节时,被试更容易区分泥来母。
(4)在基本词汇和一般词汇中,被试基本词汇的区分率明显高于一般词汇,也就是说,越常用的词被试的区分程度越高,语义提示对泥来母分混有重要的作用。
(5)在语流中,只有第三组是双字组的区分率小于单字组的区分率,除此外,第一组和第二组均是双字组的区分率大于单字组的区分率。
(6)在重庆话泥来母的辨认、区分实验中,第三组对[n]、[l]的辨认以及区分程度都比第二组、第一组高,普通话的训练与否以及普通话对被试的影响程度会影响到被试的辨识率,被试泥来母的辨识率与普通话水平呈正相关。
不能否认的是,被试在严格意义上都经历了不同的语音矫正。教育和媒体的发展、国家政策的推行以及经济交流,使得重庆话受到普通话的影响逐渐加深,被试对于泥来母的区分程度也参差不齐。在实验过程中,我们通过观察发现,当[n]、[l]和/i/、/a/以及[-ng]类韵母相结合时,被试的辨认率、区分率更高,但这点还有待于进一步通过实验研究分析去证明。
