结合XGBoost和条件随机场的城市场景机载LiDAR分类
2021-01-20刘翼王谱佐胡翔云修林冉
刘翼,王谱佐,胡翔云,修林冉
(1.中国石油西气东输管道公司 科技信息中心,武汉 430000;2.武汉大学 遥感信息工程学院,武汉 430079;3.中国石油西气东输管道公司 管道处,上海 200000)
0 引言
随着城市化的快速发展,如何在城市规划中有效管理资源成为决策者的难题,而掌握精确的土地覆盖数据能极大地帮助管理城市。由于机载激光雷达数据能够快速提供高精度三维信息,己成为一种重要的遥感数据源,在城市遥感、森林遥感、石油管理信息化等领域发挥着重要作用[1]。目前,将三维点云用于城市遥感信息提取任务己经成为热门研究。机器学习方法可利用提取出的数据特征组合[2],通过数学模型自动学习分类判别规则并有效分类城市复杂场景的不同地物。提取三维点云数据中的特征信息是区分不同地物的关键。Chehata等[3]总结了21种机载点云数据常见特征;Weinmann等[4]设计了一系列结合2D和3D的点云特征;Blomley等[5]使用了从不同邻域类型和多个尺度中提取的互补型几何特征。在机器学习模型的使用上,不同学者结合了不同的分类器方法[6-11]包括决策树、支持向量机(support vector machine,SVM)、随机森林等。极限梯度算法(eXtreme gradient boosting,XGBoost)分类模型[12]因为其优异的性能在数据挖掘中使用广泛。然而,这些分类器通常独立地使用局部特征标记每个点,通常会导致噪声结果。为此,一些学者提出了几种基于上下文特征的分类方法,这些方法可以考虑其相邻点之间的语义标签分布来改善分类结果[13-14]。本文提出了一种机载激光点云的自动分类方法,通过XGBoost训练从点云数据中抽取的特征信息,并结合全连接条件随机场优化初始分类模型,得到城市地区点云的精细分类结果。
1 激光点云分类
本文方法首先从机载激光点云中提取分类判别特征,考虑高度、形状和物理属性3个方面;然后采用XGBoost分类模型对激光点云数据进行分类,并使用网格搜索方法确定较优的模型超参数;最后利用全连接条件随机场语义标签平滑方法,加入点云颜色特征信息作为约束并结合初始分类标签信息,在后处理步骤中提高点云分类精度。实验数据选取了国际摄影测量和遥感学会(international society for photogrammetry and remote sensing,ISPRS)三维语义标注竞赛公开数据集[15]。
1.1 特征信息提取
从高度、形状特征、物理属性3个方面挖掘数据的特征信息,并针对不同的特征信息设计了不同的邻域大小选择方法。
1)高度特征。提取原始点云数据的归一化数字表面模型(normalized digital surface model,nDSM)作为一维高度特征,地表滤波过程使用了Zhang等[16]提出的布料模拟Lidar数据滤波算法。nDSM可以排除地形起伏的影响,获取地物真实的离地高度,其表达如式(1)所示。
nDSM=DSM-DEM
(1)
此外,使用一组计算单点与位于其所在邻域内其他点的高度关系而产生的高度特征。①单点与所在邻域内最低点的高程差Z-Zmin。②单点局部邻域内所有点的高程值标准差σ2。③单点与所在邻域内最高点的高程差Zmax-Z。④单点所在邻域内最高点与最低点的高程差Zmax-Zmin。

3)物理特征。点云数据的物理特性与点云自身所表示的地物特性有关。直接使用点云数据内包含的强度数据,并针对少数点强度值远大于其他点的现象,通过直方图均衡方法,减少异常数据的影响。另一方面,通过激光点云数据与对应区域的遥感影像数据相结合,计算单点在影像中的对应像素,通过影像提供的光谱信息辅助点云进行信息提取。
4)邻域选择。不同的邻域类型由提取特征的需求所决定。在抽取高度特征时,需要考虑一点在高程值Z上的空间分布,因此圆柱体形的邻域类型适应于高度特征的提取,并考虑了3种不同的邻域大小(2.0 m、4.0 m、6.0 m),对高度特征进行了多尺度提取。而在计算点云表面特征时,需要关注该点与在一定距离内点云的空间关系并获取几何形态,本文选择聚集于单点的球面邻域(2.0 m)。
1.2 XGBoost分类
XGBoost属于提升式系列的分类器,在梯度提升树(gradient boosting decision tree,GBDT)的基础上做了一些改进,得到了一个更高效准确的机器学习模型,因此在数据挖掘应用中得到广泛使用。其主要特点有:在模型中加入了正则项,用于控制模型的复杂度;对代价损失函数进行了二阶泰勒展开,同时用到了一阶和二阶导数;收缩和列取样,可增大迭代生成的树模型的影响,并在一定程度上防止过拟合;在树模型分割点的特征值上实行并行,大幅度提高运行效率;对决策树最佳分裂点的改进。
本文在使用XGBoost分类器的过程中,为了使模型更适应于点云数据的分类工作,采用了超参数设计方法对模型参数进行调优,另外使用了网格搜索的功能,逐步搜索确定最佳参数值。
1.3 全连接条件随机场优化
针对机器学习方法在特征空间中单独标记每个点的标签而造成的分类结果不连续性的问题,使用全连接条件随机场融入了点云之间的语义信息[17]。应用在点云模型中,每2个点间的边是由高斯核在任意特征空间的线性组合定义的,而算法基于条件随机场分布的平均场近似,通过聚合来自所有其他变量的信息进行迭代优化。
(2)
式中:i和j表示从1到N的每个点;Øu(xi)是一元项能量函数,用于约束优化结果与初始结果的差异,定义为Øu(xi)=-log(p(xi));Øp(xi,xj)是二元项能量函数,用于提取点云的邻域信息,如式(3)所示。

(3)
式中:Wθ1表示为标准差为θ1的高斯函数。核函数中的参数采用训练的方式,通过L-BFGS方法优化得到。一个简单的标签兼容性函数μ由Potts模型给出:
μ(xi,xj)=[xi≠xj]
(4)
具体实施参考了Wang等[18]对点云分类优化的处理,利用XGBoost得到的初始分类概率作为Øu,用于保证优化结果位于初始分类概率的一定区间内;将Øp设置为点云与影像匹配生成的颜色信息与强度信息,考虑到颜色与强度特征在同一类别中一般是连续的,这样更符合平滑分类结果的要求。通过能量函数的最小化求解,得到优化后的分类结果。
2 实验与分析
2.1 实验数据
本文选用了ISPRS三维语义标注比赛提供的公开数据集作为激光点云分类的基准。激光点云数

表1 数据类别分布
据集包含使用Leica ALS50系统获得的ALS数据,点密度在4~7点/m2。此外,激光雷达的多次回波信号和强度值被记录下来。数据集一共包含9类地物,包括电力线、低矮植被、不透水面、汽车、栅栏、建筑屋顶、建筑立面、灌木和树木。整个区域都位于建筑物密集的城市中心。相对应的遥感影像包含整个地区范围,地面采样距离为8 cm,为假彩色合成影像。

图1 实验数据集
2.2 实验过程
特征提取过程中,基于圆柱形的邻域采用了规则格网的方法进行简化,而基于最近邻的邻域采用了KD树建立索引。XGBoost的超参数选择中通过网格搜索功能,逐步搜索每个超参数在一定范围内的最优值。本文对模型最大树深度、子节点最小权重和、最小损失下降值、样本采样比例和分裂列采样比例进行了区域最优搜索,通过设置一定范围内的典型值,获取更优模型。本文采用的精度评价指标包括混淆矩阵、总精度和F1分数。
2.3 结果分析
图2(a)为分类结果,用不同颜色表示。图2(b)中绿色表示正确分类,蓝色表示错误分类。

图2 分类结果
混淆矩阵表示不同类别的相互错分情况,每一行代表真实数据的归属类别分布。从表2可以看出,在点云数量较多的低矮植被、不透水面、建筑屋顶和树木4大类别中,该分类器取得了较好的分类效果;而对于一些小型地物的分类效果不佳,特别是对于栅栏这一类地物,召回率很低,这与点云数据集中栅栏的数量较少有关。另外,在数据集中栅栏这类地物本身就由植被组成,并在城市中通常位于其他植被附近,因此出现了较严重的错分现象。
为评价该模型的有效性,本文将分类结果与该实验数据集竞赛中的其他方法做了比较。从表3可以看出,本文方法在总体精度上有较大的优势,在几个点数多的大类上取得了较好的分类精度。对比4种机器学习模型,LUH方法在F1分数上表现较好,在多个类别上取得了最佳的效果。文本方法在低矮植被和不透水面的类别精度上取得了最好的结果,在电力线、汽车和建筑屋顶3类地物中取得了和最佳值相近的效果。
另外,与数据竞赛上一些基于深度学习方法相比,本文方法与其中一些相比具有优势,但与其中2个最佳的分类精度模型相比,文本方法在F1分数和总体精度均有劣势。其中,WhuY4方法平均F1=69.2%,总体精度=84.9%;NANJ2方法(将点云插值图像并通过多尺度卷积神经网络(MCNN)模型分类)平均F1=69.3%,总体精度=85.2%。考虑到深度学习在处理三维点云所需的高性能计算显卡,经典机器学习模型只需要CPU就能运行,本文方法在一定程度上不受计算机性能的约束。

表2 分类混淆矩阵 %
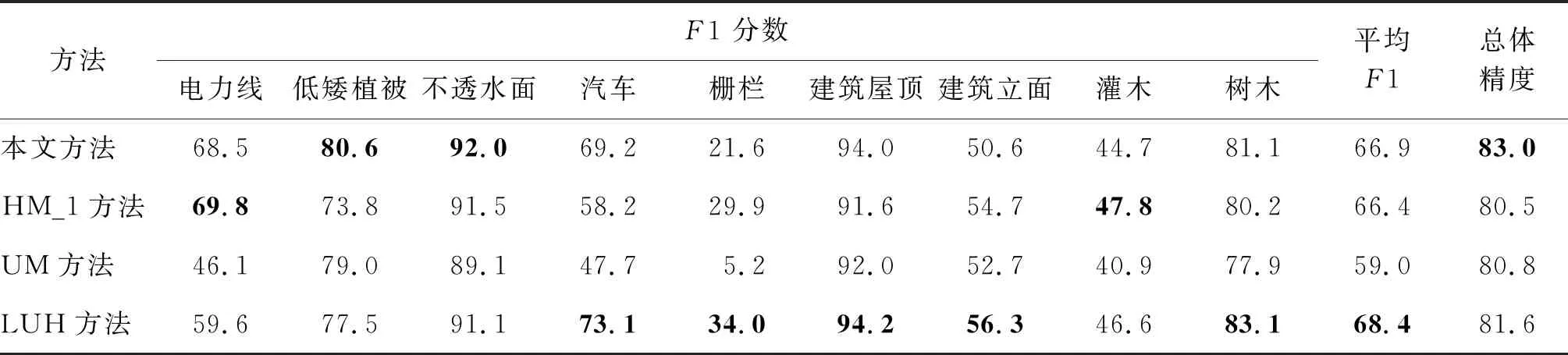
表3 不同方法比较 %
3 结束语
本文总结了一些高效的机载激光点云特征描述方法,并结合机器学习XGBoost分类模型和全连接条件随机场后处理优化方法,提出了一套机载激光点云分类方法。在未来的工作中,对于复杂的城市场景,需要采用更多新的特征提取方法,从多层次、多尺度来深度挖掘点云信息。另外,需要结合特征选择的功能,通过分析特征之间的关系抽取有效的特征信息。
