耦合内容相似度信息的贝叶斯隐式反馈推荐∗
2021-01-19
(空军预警学院 武汉 430019)
1 引言
战场态势具有数据海量、特征复杂、种类繁多等特点,导致作战用户在使用态势信息系统时存在着这样的问题:战场态势数量呈爆炸式增长,由于作战人员认知能力的局限性,无法在任何情况下都能够及时地明确自己的态势需求,自然也难以从海量的战场态势挑选出合适的态势产品提供给用户。因此智能推送运用而生,通过核心技术—推荐算法来帮助作战用户获取到自己感兴趣的态势,解决“态势泛滥”和“态势缺乏”的矛盾问题[1]。
显式反馈推荐算法一般采用评分预测的方式进行推荐。在实际运用过程中,评分数据往往是非常稀疏的,即只有用户只对很小一部分的项目进行评分,此时用户偏好难以准确表达,而隐式反馈推荐能够充分利用到用户的隐式反馈行为,如用户检索、定制、浏览等行为,而这些数据往往是大量存在的,并且随着用户与推荐系统的交互越多,推荐效果越佳。针对隐式反馈推荐算法,国内外学者展开了广泛的研究。隐式反馈推荐算法可以分为三类:基于单类协同过滤的推荐、引入辅助信息的推荐和基于排序的推荐[2]。基于单类协同过滤的推荐是基于正反馈数据和通过分布假设负反馈数据来实现推荐[3];引入辅助信息的推荐主要是将用户或项目特征信息引入到传统推荐算法[4];基于排序的推荐是将任意两个项目的偏好顺序进行优化,从而将推荐问题转化成二分类问题[5]。基于单类协同过滤的推荐利用权重或采样的方式将负样本集成到算法中去,使得模型不易过拟合,解释性强,但算法复杂度增加,训练结果集成方式复杂;引入辅助信息的推荐利用用户画像、用户情绪、项目属性信息、相似度信息、项目语义关联等额外信息一定程度上,但特征提取相对困难,容易引入不必要的杂音;基于排序的推荐采用逐点或逐对的方式进行排序,使得样本复杂度降低,偏好刻画更为准确。因此,本文以贝叶斯隐式反馈推荐算法为基础,利用作战用户历史定制信息作为隐式反馈训练数据,构建一种能够同时利用到用户历史行为信息、用户和态势本身具备的属性信息的推荐模型,以期能够对作战用户提供个性化、智能化的态势信息推送服务。
2 贝叶斯隐式反馈推荐算法
贝叶斯隐式反馈推荐算法是由Rendle等提出,是一种基于排序学习的个性化隐式反馈推荐框架与准则,贝叶斯隐式反馈推荐算法的原理在于预测需求度未知项中所有项的需求度排序关系,然后根据预测结果,将排序高的态势推送给作战用户[6]。该方法基于这样的一个假设:当输入作战任务时,作战用户u向态势定制系统输入自己的态势需求,态势定制系统根据用户发出的态势需求,通过从态势数据库筛选出符合用户需求的态势将态势i和态势j并展示给用户u。用户u定制了态势i,却没有定制态势j,则可以假设用户u对某态势i的需求度高于态势j的需求度,记为(u,i)≻(u,j)。
贝叶斯隐式反馈推荐算法是以矩阵分解为训练模型,通过最大化态势排序的后验概率来获取态势的正确排序,从而为目标用户提供推送结果。假设不同用户之间的态势需求情况相互独立,同一用户对不同态势之间的需求情况也相互独立,则基于态势需求度排序的后验概率可表示为
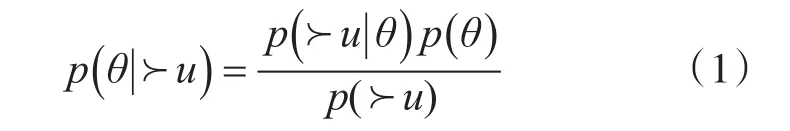
其中θ为矩阵分解模型要学习的参数,θ=(U,V),≻u为单个用户对所有态势的成对排序关系,p(θ)表示为矩阵分解模型的先验概率,p(≻u|θ)表示为所有态势成对排序的似然概率,p(θ|≻u)为所有态势成对排序的后验概率。
因为已经假设了不同用户之间的态势需求情况相互独立,因此式(1)可以进一步变形为
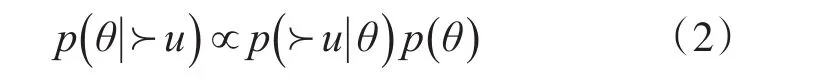
要得到最合适的模型参数θ,即优化似然概率与先验概率的乘积。假设每个用户之间的态势需求相互独立,用户对所有态势的需求独立,则根据态势排序的独立性、传递性和反对称性,则最大化态势成对排序的似然概率为
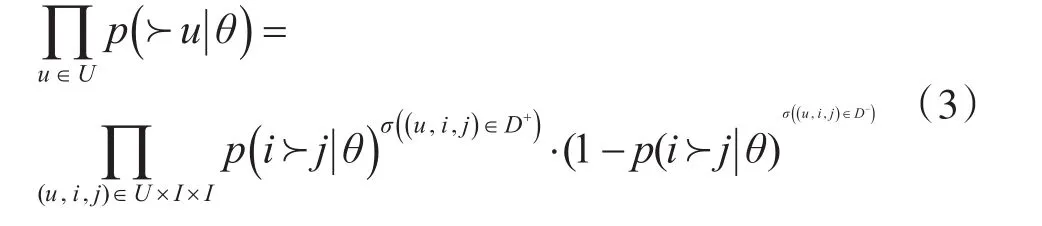
其中U、I分别为用户集合和态势集合,D+、D-分别表示为用户与态势有定制历史行为和用户与态势无定制历史行为的态势集合,p(i≻j|θ)即为(u,i,j),表示态势i的排名高于j的概率。要使态势i的排名高于j,则可以通过使p(i≻j|θ)出现的概率越大。则态势成对排序的似然概率可以进一步表示为
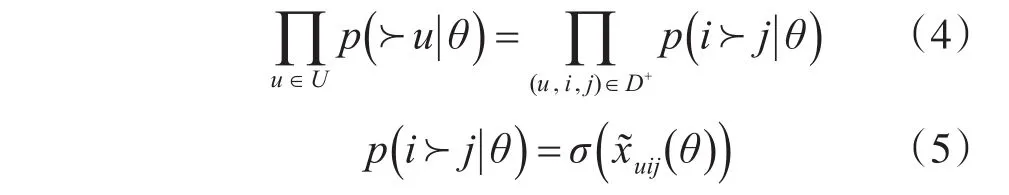
其中σ()为sigmoid函数[7],满足δ(x)=1/(1 +e-x),用于将用户u对态势i的需求度与用户u对态势j的需求度差值映射到区间[0 ,1] ,表示底层模型的评估函数,且满足。贝叶斯隐式反馈推荐算法进一步假设先验分布服从正态分布,即:
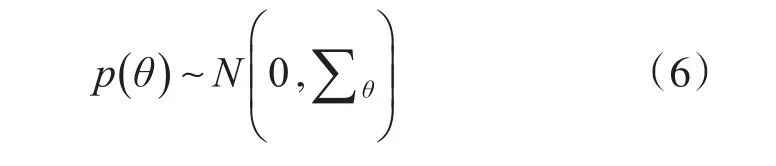
其中∑θ为方差,结合上述公式,则贝叶斯隐式反馈推荐算法的目标函数为
λθ为模型正则化参数,用于防止模型过拟合。在得到目标函数后,利用随机梯度下降法[8]对目标函数进行参数优化,当模型收敛时,根据优化结果将最合适的态势推荐给目标用户。
3 耦合相似度信息的贝叶斯隐式反馈推荐算法
贝叶斯隐式反馈推荐算法是利用用户—态势需求度矩阵来确定未知项的排序关系,某种意义来说是根据相似的用户有着相似的历史行为,态势需求情况也会相似,他们需求态势之间的排序关系才会相似,是一种集体智慧的结晶[9]。该算法的缺点在没有充分利用用户之间或态势之间的关系,如用户与用户之间存在相似类别、指挥层级、区域、年龄段、受教育程度等属性信息,如态势与态势之间存在相似种类、主题、来源等属性信息,这些属性信息的融入将能有效提升推送质量,并且在用户之间没有相似行为记录的条件下,可以充分利用用户或态势的相似属性来为目标用户寻找相似用户来实现推送,有效缓解数据稀疏性问题。相似度信息融入到贝叶斯隐式反馈推荐算法主要包括两个步骤:相似度计算和相似度信息正则化。
新三板等多层次资本市场是近几年发展起来的股权交易平台,是国家推进中小企业发展的重要举措。但从成立至今,这些平台总体来说由于市场活跃度不高,平台给企业融资方面带来的益处相对较少。国家可以适当考虑降低这些平台股权交易的门槛,增加市场活跃度,让平台上企业的股权能够得到更多投资者的青睐,使企业的股权价值更加公允,方便企业利用股权质押或者股权增发获得融资。
3.1 相似度计算
态势推送主要存在两个关键节点:用户和态势,因此相似度信息是指用户之间或态势之间的相似性。计算不同用户或态势的相似度一般采用余弦相似度方法[10],则用户之间的相似度如下公式所示:

式(9)的含义与式(8)含义类似,不同之处是用户变成了态势。在得到相似度值后,可以得到所有用户、态势的相似度矩阵,矩阵中每一项表示用户之间、态势之间的相似度值。
对于算法模型而言,以用户之间的相似度为例,则只需寻找与目标用户最相似的一组用户即可,因为低相似性的用户的引入反而会使得模型引入噪声,导致推荐效果效果下降[11]。相似用户的选取采用k近邻法,即只选取相似度最高的t个用户,则sim(uk,uk')可以表示成以下公式:
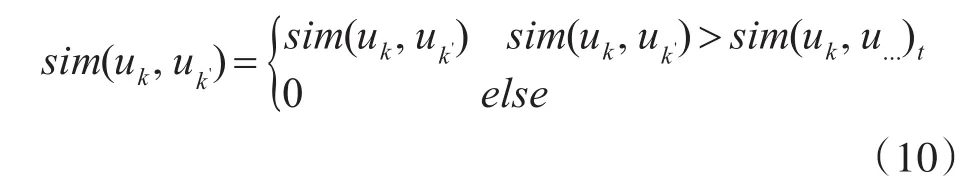
其中sim(uk,u...)t表示与用户uk最相似的t个用户。同理也可以对相似态势做同样的处理。
假设不同来源的用户相似度矩阵表示为和,总的用户、态势相似度矩阵分别为SU和SV,wp、wq用于表示不同来源(即沿着不同的元路径)的用户相似度矩阵的权重,ns、ms分别表示用户、态势路径数量。则总的用户相似度矩阵公式如下:
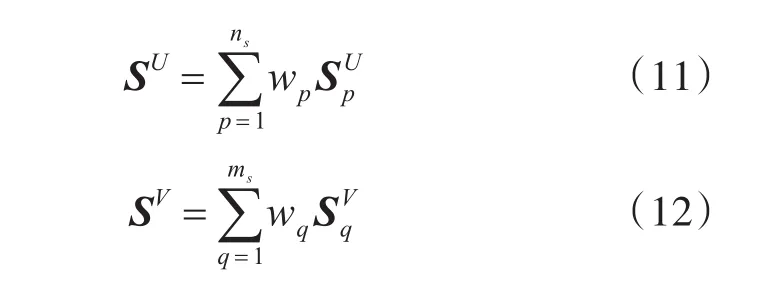
权重具体值需要从数据中推断出来,假设参数λc表示总的相似度信息的置信度,则置信度与不同来源的用户、态势相似度矩阵的权重满足以下等式:
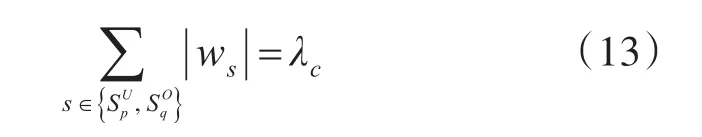
3.2 相似度信息正则化
将相似度信息融入到贝叶斯排序推荐模型,其核心思想是在于具备相似属性的用户,他们对态势的需求情况应当是相似的,同时同一用户对具备相似属性的态势,他的需求情况应当也是相似的。此时应当确保属性信息相似用户的特征向量与目标用户特征向量尽可能相似,同理属性信息相似态势的特征向量应与待推送特征向量尽可能相似。在此条件下,属性信息相似用户对应的需求态势排序情况才会相似。因而,因而可以直接对贝叶斯排序推荐模型添加正则化项,用以表示用户相似度信息、态势相似度信息对于用户特征向量、态势特征向量的影响程度。记Fsim表示相似度信息的正则化项,正则化主要包括三个部分:用户之间的相似度,排序靠前的态势之间的相似度和排序靠后的态势之间的相似度。公式如下:
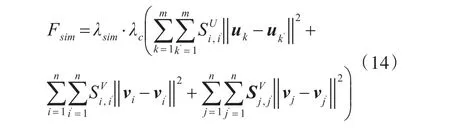
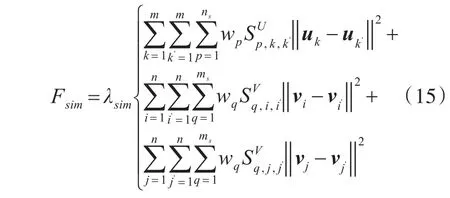
则此时耦合相似度信息的贝叶斯隐式反馈推荐算法,目标函数可表示为
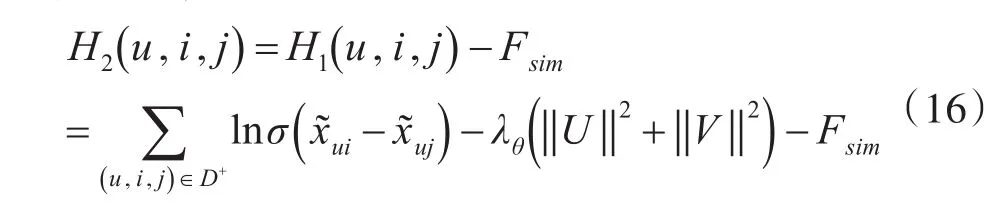
Fsim指用户、态势相似度信息的正则化项,H1(u,i,j)表示贝叶斯隐式反馈推荐算法的目标函数。
来自不同信息源的信息量不同,对于推荐结果有一定的影响,因此需要给予权重设置。为防止权重过拟合,因此还需对权重进行正则化,主要用于惩罚ws与w0的差异,即w0是指所有相似度矩阵均匀加权,即,则此时相似度信息的正则化项还需加上权重正则化项,公式如下:
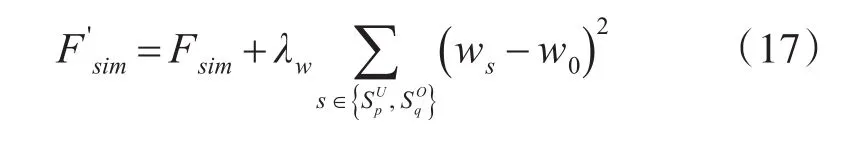
结合式(7)、(16)、(17),则考虑权重正则化的基于内容相似度和贝叶斯排序的组合推荐算法的目标函数为
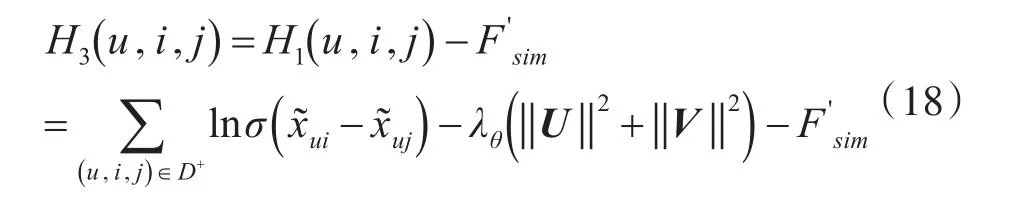
为方便后续实验算法性能进行比较,将贝叶斯隐式反馈推荐算法记为BPR,耦合相似度信息的贝叶斯隐式反馈推荐算法记为SBPR,考虑权重正则化的耦合相似度信息的贝叶斯隐式反馈推荐算法记为WSBPR。
在得到各算法的目标函数后,利用随机梯度下降法进行参数优化,则可以得到态势的相对需求度,将排序高的态势推送给目标用户。
4 实验结果及分析
实验数据采用雷达航迹仿真得到各类情报750000条,其中用户定制过的情报为1500条,数据稀疏性为99.8%,其中该数据还包括用户的类别、任务区域、指挥层级等信息,情报的类别、主题、来源等信息。根据用户定制历史记录,需求度取值采用二元制刻度,即用户—态势需求度矩阵中的项取值1和0,值为1代表用户定制过情报,值为0代表用户没有定制情报。对用户特征和情报特征属性进行相似度处理,如用户种类相同,则对应相似度矩阵中的项记为1,反之记为0,情报处理方法类似。
为验证推荐算法效果,数据处理过程中,将数据划分为训练集和测试集,采用随机梯度下降法对算法进行训练。在衡量推荐算法的性能效果时,本文采用排序推荐领域广泛使用的两个评价指标:NDCG(normalized discounted cumulative gain)[12]和AUC(area under the curve)[13]。为便于各算法进行比较,对实验数据总共模拟了三种情景,通过对情报数据中随机剔除50%、75%和90%数据用以创建数据稀疏性情景,保证实验的客观性,实验重复训练5次,对实验结果取平均值。算法参数设置:相似度用户和态势的数量t为10,隐因子数f为10,学习率为0.1,λθ=λw=0.01,λsim=0.05,迭代次数为{5,10,15,20,25,30}。为评估本章提出的算法的推送效能,设计了以下对比实验。
实验一:迭代次数取15次,其他参数条件不变,分析数据稀疏性对各算法性能的影响。
各算法实验结果如表1所示。
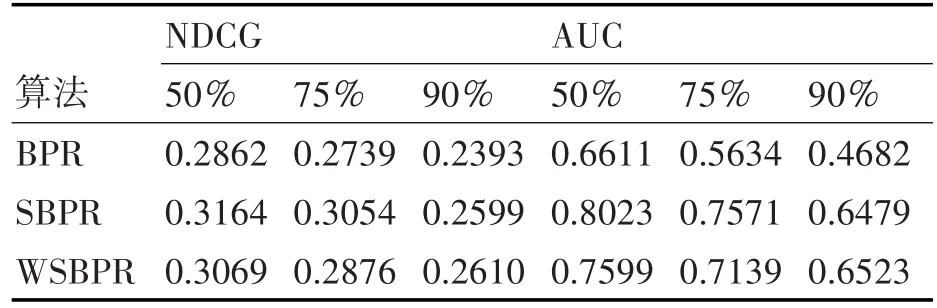
表1 不同算法在数据稀疏性情景下NDCG、AUC测量结果
由表1各算法实验结果可以看出:1)随着情报数据剔除的比率越高,BPR、SBPR、WSBPR三种算法NDCG、AUC两个指标均随着下降,说明数据越稀疏,算法性能越差,原因在于此时有定制历史的态势数量变小,占总的态势数量比例变小,使得用户—态势需求度矩阵变得更加稀疏,而三种算法都需要利用到需求度矩阵,此时利用更少的具有明确需求度的项来预测未知项,会使得预测准确性下降。2)同时也可以看出,在相同的数据稀疏性情境下,与基准算法(BPR)相比,SBPR、WSBPR算法性能要好于基准算法,SBPR、WSBPR两者算法性能较为接近,说明相似度信息的融入能够有效缓解数据稀疏性问题,提升算法性能。3)情报数据剔除的比率为50%、75%时,由NDCG、AUC两个指标值可以看出,SBPR算法性能好于WSBPR算法,而当情报数据剔除的比率为90%时,SBPR算法性要WSBPR算法要差,这说明数据比较稀疏的条件下,对不同来源的用户、态势的相似度信息设置权重并正则化,能够防止算法过拟合,使得此时算法训练结果最大可能逼近最优值。
实验二,情报数据剔除的比例为90%,其他参数不变,分析迭代次数对各算法推荐性能的影响。实验结果如图1所示。
由图1(a)、(b)可知,1)各算法随着迭代次数的增加,NDCG、AUC两个指标值也相应的增加,基准算法(BPR)相比,SBPR、WSBPR算法的推荐性能要更好一些,说明相似度信息的融入确实能够提升推荐效果。2)SBPR、WSBPR算法两者算法相比较,在一开始迭代次数较小的情况下,WSBPR算法性能不如SBPR,但随着迭代一定次数时,WSBPR算法性能要好于SBPR,说明对不同信息源的相似度信息考虑权重正则化,能够在一定程度上防止算法过拟合,提升算法性能。3)随着迭代次数的增加,BPR、SBPR、WSBPR三者算法性能提升速率逐渐变慢,说明算法迭代次数增加到程度后,算法训练变得过拟合,此时算法推荐性能随迭代次数增加并不会显著提升。
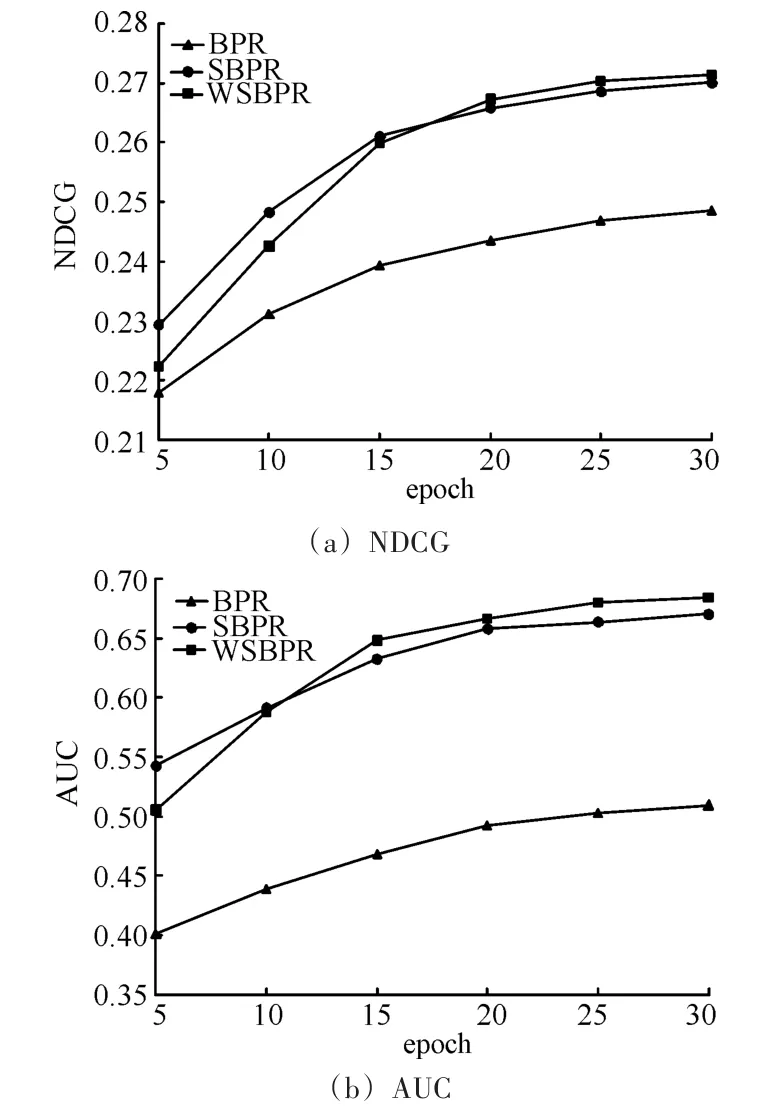
图1 各算法随迭代次数变化,NDCG、AUC指标变化情况
5 结语
本文提出了一种耦合相似度信息的贝叶斯隐式反馈推荐算法,该方法通过相似度算法将不同来源用户、态势的相似度信息,以相似度矩阵的形式融入到贝叶斯隐式反馈推荐算法,有效填充了用户需求特征,使得用户需求信息刻画更为准确,算法的应用场景更为广泛。同时也设计了实验仿真,探究了不同数据稀疏性背景、不同参数设置条件下对于推荐算法性能的影响,实验结果证明本文算法在稀疏性背景下,与贝叶斯隐式反馈推荐算法相比,本文算法具有一定的性能优势。
