一种基于特征编码技术的恶意代码检测方法
2021-01-19丁应,李琳
丁 应,李 琳
(武汉科技大学 计算机科学与技术学院,湖北 武汉 430065)
0 引 言
早期的恶意代码由于没有采用复杂的加密算法对其进行加密,因此可以通过交叉匹配部分代码的方式来检测恶意代码。但是随着多态和变态(混淆)等现象的出现,恶意代码每经过一轮迭代就进行一次相同密钥的加密算法进行加密(多态),有的甚至使用不同密钥的加密算法进行加密(变态),使恶意代码变得极难检测,恶意代码分析师往往需要花费至少一周甚至更久的时间才能分析一个新出现的病毒属于哪个家族。最近的一份安全报告显示,虽然攻击者对开发移动端的恶意代码的兴趣越来越高,但是Windows系统依然是黑客攻击的首要目标。2019年至今,几乎每周都有重大网络事件发生,给受害者造成了巨大的经济损失,更严重的甚至会危害受害者的生命安全。
传统的恶意代码检测技术可以分为静态分析和动态分析两种方法。静态分析[1]的优势是可以在代码执行之前对其进行分析[2],并且可以在确切的位置挖掘出代码的敏感信息,通过这些信息可以判断该代码属于哪种类型的恶意代码(木马,蠕虫,后门),动态分析方法很难做到这些;而在动态分析[3]中,代码在执行阶段会被实时监控[4](虚拟机,沙箱技术等),可以轻易地找到软件受感染的位置,但在静态分析中这是不可能的。
静态检测技术在对恶意代码进行分析时,需要借助恶意数据特征库。由于恶意数据特征库存在一段时间的更新周期,如果检测不及时,会存在漏检、误报等问题;并且静态检测技术对新型病毒也会显得心有余而力不足。
动态检测技术在对恶意代码进行分析时,需要借助虚拟机、虚拟镜像、沙箱等技术,这不仅会造成资源的浪费,而且一些病毒甚至能判断自身所处的环境,在虚拟环境下并不表现出自身的特点,导致动态检测误报。
无论是动态检测技术还是静态检测技术,在进行检测时还存在着其他的局限性,比如只能用于某些安全公司的“自产自销”。如今,互联网高度集成发达,如果不能将自身资源分享出去,也是一种资源的浪费。
针对上述传统的恶意代码检测技术的不足,深度学习算法凭借其强大的特征提取能力自然而然地被研究者用来对恶意代码进行检测和分类。T.Kim等人[5]将RGB编码技术和卷积神经网络结合起来对异常网络进行检测,通过将数据特征编码成彩色图像,然后使用卷积神经网络对生成的彩色图像进行分类,在三个不同的数据集上都取得了不错的准确率。韩晓光等人[6]通过把恶意代码映射为无压缩的灰度图片,然后对图片进行相应的处理,最后使用深度学习算法对其进行分类,准确率不高,而且过程过于复杂,单给研究者提供了思路。Baptista I[7]通过将恶意样本转换为灰度图像后,与无监督学习方法结合,对各种恶意文档或软件(pdf,txt,exe,doc等)的分类都能达到较高的准确率。
由此可以看出,将深度学习算法与其他方法结合起来,然后应用于对恶意代码的检测和分类,其性能远远优于传统的恶意代码检测技术。但是上述文献中大多没有引入良性数据集,严格意义来讲,它们并不能算是对恶意代码的检测。因此,该文采用的数据集包含良性样本和恶意样本,然后将数据集上待检测的PE文件的特征进行双字节编码,转换为8×8的灰度图像,最后通过卷积神经网络提取图像特征并对测试集进行检测。实验结果表明,提出的双字节特征编码方法在Ember数据集上的准确率为92.82%,与传统的灰度编码技术相比,提高了11.42%。
1 相关工作
随着深度学习算法的不断发展,它们已经被广泛地应用于恶意代码的检测和分类当中。蒋晨等人[8]通过将深度神经网络应用于不同平台下恶意代码的分类,其结果表明该方法在Windows平台上的分类效果远高于安卓平台。A. I. Elkhawas等[9]通过将待检测的PE文件的特征转换成三元组的形式,然后通过SVM算法对其进行分类,在PE文件的分类上具有非常好的表现。A. Utku 等[10]采用的决策树算法在移动端恶意代码的分类上的准确率可以达到95%以上。其他的深度学习算法[11-15],在检测其他的恶意事件中也具有良好的表现。有趣的是,当生成对抗网络技术出现时,研究者发现可以通过生成技术在恶意代码某些特定的部分填充一些字节,在不改变该代码功能的前提下来逃避深度学习方法对可执行软件的检测,进而把恶意样本误判为良性样本。而Vineeth S. Bhaskara等人[16]通过生成技术在已知恶意软件行为的可逆分布RGB图像表示上训练GAN,编码API调用n-gram的序列和相应的项频率,生成的图像表示可以重新解码为底层API,通过调用序列信息可以合成恶意软件。Z. Li等人[17]提出了一种灰度编码方法,通过将入侵检测数据集的单个特征编码为10位二进制数(0b0000000000-0b1111111111),然后转换为灰度图像,并用深度学习算法对其进行分类,最终的准确率为82%。由此可知,将各种特征处理方法与深度学习算法相结合,在恶意代码的检测和分类上的表现都优于传统方法。
EMBER数据集是Endgame公司在2018年四月份发布的一个大型开源数据集。该数据集可以用于训练机器学习模型来检测静态Windows便携式可执行文件。它总共有110万条数据,其中训练集有90万条,恶意样本、良性样本以及未标注样本各30万条;测试集有20万条,恶意样本和良性样本各10万条。该数据集用jsonlines格式保存,并详细解释了各数据的含义。其父特征有8类,部分父特征又可以分解成子类特征,总共构成了56个特征(父特征和子类特征的集合);这些特征又可以分成数值特征和非数值特征。
2 双字节特征编码与深度学习
在使用深度学习算法对恶意代码进行检测之前,首先需要将非数值特征转化为数值特征,然后将数值特征转换成二进制数,接着通过双字节特征编码技术将其转成灰度图片,最后使用深度学习算法对其进行检测。本章主要介绍了该文使用的EMBER数据集的特征、提出的双字节特征编码技术以及所使用的深度学习算法。
2.1 相关特征介绍
根据EndGame公司对EMBER数据集特征的描述筛选出如图1中的特征用来编码,包含4个父特征和35个子类特征。具体描述如下:
label:标签,值为1代表恶意样本,0为良性样本,-1表示未标记,可用作半监督学习。
general:常规文件信息,主要包括的特征有文件大小、从PE头获得的基本信息、文件的虚拟大小、导入函数和导出函数、文件是否具有调试部分、线程本地存储、资源、重定位、签名以及符号数。
header:在coff标头中,主要包括目标主机(字符串)和图像特征列表(字符串列表);在optional标头中,特征有目标子系统(字符串)、DLL特性(字符串列表)、magic字符串(例如“PE32”)、主要和次要映像版本、链接器版本、系统版本和子系统版本、代码、标头以及提交大小。
strings:字符串中的特征包括简单的统计信息,至少五个可打印字符长度的可打印字符串(由0x20到0x7f范围内的字符组成)、字符串的数量、字符串的平均长度、所有可打印字符串中字符的熵;此外,字符串特征还包括以C:(不区分大小写)开头的可能表示路径的字符串数,以及http://或https://(不区分大小写)的出现次数、它们表示路径URL、还有表示注册表项的HKEY_的出现次数以及可能提供Windows PE删除程序或捆绑的可执行文件的短字符串MZ的出现次数。该数据集提供的是字符串的简单统计摘要而不是原始字符串的列表,可以尽量不泄露某些良性文件可能存在的隐私问题。

图1 单个PE文件的部分原始特征
图1和2.1节详细地描述了单个PE文件的部分原始特征以及特征的含义。
2.2 特征编码技术
本节主要介绍该文对数值特征采用的数据预处理技术以及提出的双字节特征编码方法,并将该方法相较于传统灰度编码方法的优点进行了简单的描述。
2.2.1 数据预处理
由图1可知数据集的子类特征包含两种,一种是非数值特征,比如subsystem和dll_characteristics等特征;另一种是数值特征,比如numstrings和entropy等特征。对于非数值特征,如果该特征中的子类特征的数目不超过16,那么就可以使用独热编码的方式对其进行编码,例如subsystem的子类特征数目为12,所以其编码方式为(0b000000000001,0b100000000000),即12个位置上每一个位置只有一位为1,其余为0。对于子类特征数目超过16的情况(如图1中的dll_characteristics),直接对其进行类别编码并转换为数值特征。
对于数值特征,使用MIN-MAX归一化的方法对其进行处理,转换成[0,1]范围的值,公式如下:
(1)
其中,xnorm为归一化后的数字,x为原始数字,xmin和xmax分别为该特征的最小值和最大值。
2.2.2 双字节特征编码方法
该文提出了一种双字节特征编码方法,是将单个的数值特征都编码为相等数量的字节(每个数值特征编码为两个字节),非数值特征根据子类特征数目分别进行独热编码或类别编码。而数值特征的编码规则如式(2):
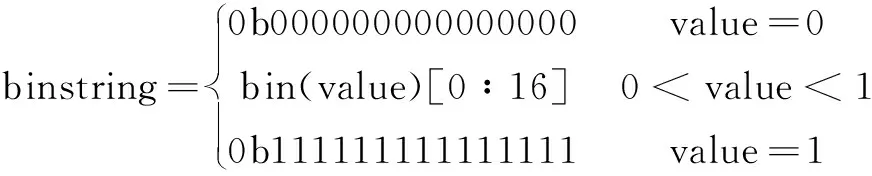
(2)
由式(2)可知,对于数值特征的子类特征,如果该值为0.0或1.0,就将其编码为0x0000(值为“0”)或0xffff(值为“1”);如果该值在0.0到1.0之间,那么就将十进制小数转换为二进制小数并取前十六位,即每个特征代表两个字节。非数值特征的处理方式在2.2.1节中已作详细介绍。
将待检测的PE文件特征通过该文提出的双字节特征编码方法进行编码后,得到的字节的数量是确定的。假设N为数值特征,M为非数值特征中子特征数大于16的特征,K为非数值特征中子特征数小于16的所有特征经过独热编码后相加的数量。则该文提出的编码方法的字节数量为((M+N)×16+K)/8,最后得到的字节数目是64,刚好可以转换为8×8的灰度图像。而传统的灰度编码方法经过相同处理后,最终得到的大小为42.5的字节,需要填充6.5个都为0的字节才能转换为7×7的灰度图像。图2为任意四个待检测的PE文件的特征值经过双字节特征编码后生成的图片(经过1 228%放大后)。

图2 待检测PE文件的特征编码图片
该文提出的特征编码与灰度编码相比,有以下优点:
在编码时将每个数值特征以及子类特征中类别超过16的都编码为2个字节,而灰度编码只是将特征编码为1.25个字节。灰度编码在转换为图像的时候会造成特征分裂,降低准确率。
在精度方面,灰度编码的损失远远大于特征编码。比如灰度编码将特征值0.400 1和0.499 9都编码为0b0001000000,损失值为0.098。而双字节特征编码则分别将其编码为0b0110011001101100和0b0111111111111001,是完全两个不同的值, 且损失值
小于2-16,与灰度编码方法相比,损失值可以忽略不计。
2.3 深度学习算法
CNN(convolutional neural network)模型的灵感来源于动物视觉皮层组织,该组织负责小范围内的光检测[18]。通常,CNN由两种类型的层组成,分别称为提取特征的卷积层和用于特征映射的池化层,可以很好地提取特征,通过该特征可以轻易地识别出图像之间的区别,因此CNN在图像分类上具有卓越效果。在2014年,ImageNet大规模视觉识别挑战赛(ILSVRC)竞赛的获胜者也是以CNN模型为架构的[19],在比赛中,它的错误率仅为6.67%,与人类水平的性能几乎相同。由2.1节可知,该文的输入是8×8大小的灰度图片,而输出分别为0(良性)或者1(恶意),属于二分类问题。因此,适合用CNN模型来对待检测的PE文件进行检测。
在TensorFlow框架的基础上,把输入大小为8×8的灰度图片,经过一次3×3的卷积之后,得到6×6大小的灰度图片,通过使用ReLU激活函数可以有效防止梯度消失问题,并且计算量也比较小,然后使用2×2的最大池化层来减少参数误差造成的均值偏移,最后输出的图片大小为5×5。由于此时的分类效果并不理想,因此在此基础上重复做了一次3×3的卷积和2×2的最大池化,得到输出为2×2大小的灰度图片。为了避免出现梯度消失和过拟合等问题,分别使用带有ReLU激活函数和dropout的全连层,最后使用softmax对数据集进行分类。图3为该文采用的CNN网络架构。

图3 CNN网络架构
3 实验结果分析
由于大部分开源数据集都只有恶性样本而没有良性样本(例如:BigData2015),因此该文选择EndGame公司在2018年四月份公布的包含两种样本的EMBER数据集;并通过准确率、查全率、查准率三种具有代表性的度量性能比较该文提出的双字节特征编码以及传统的灰度编码技术。
本节主要介绍了实验过程中使用到的数据集以及对实验结果的具体分析。
3.1 数据集
在EMBER数据集的基础上分别随机选取30万条良性样本和恶意样本,以形成60万条样本的新数据集。然后将该数据集以9∶1的大小随机划分为训练集和测试集,表1详细描述了该数据集训练集和测试集的大小。
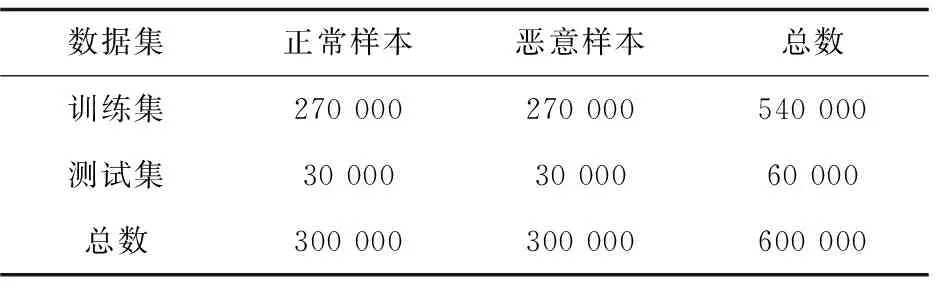
表1 数据集分布
3.2 实验结果
通过采用如图3所示的卷积神经网络架构,对3.1节中划分的数据集进行实验,并且采用准确率(accuracy)、查全率(precision)、查准率(recall)和F1值度量两种方法的性能,以比较双字节特征编码方法与灰度编码方法的优劣性。其中查准率P、查全率R和F1值分别定义为:
(3)
(4)
(5)
其中,TP表示真正例,FP表示假正例,FN表示假反例。图4为双字节特征编码和灰度编码在CNN上的准确率曲线。
由图4可以看出,在同等情况下,当经过100个epoch之后,灰度编码方法的准确率仅为81.4%,而该文提出的双字节特征编码方法的准确率达到92.82%,比灰度编码提高了11.42%。
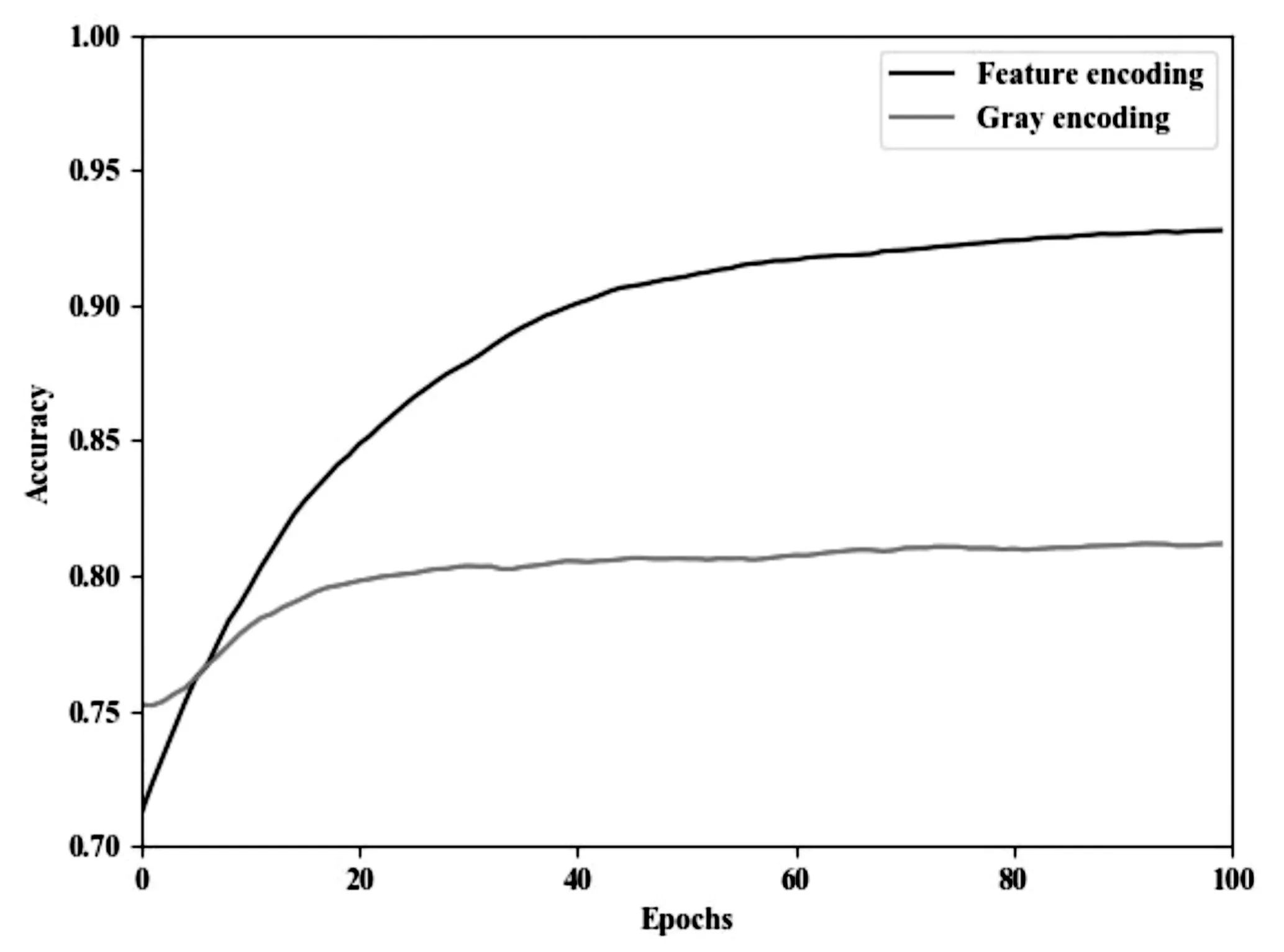
图4 特征编码和灰度编码的准确率曲线
由表2可知,特征编码方法在查准率P、查全率R和F1值上的表现都优于灰度编码;双字节特征编码在正常样本和恶意样本上的查全率分别为93.14%和93.16%,而灰度编码分别为81.39%和81.41%;双字节特征编码在正常样本和恶意样本上的查准率分别为93.17%和93.14%,而灰度编码分别为81.42%和81.38%;双字节特征编码在正常样本和恶意样本上的F1值为93.15%,而灰度编码分别为81.4%和81.39%。由此可知,该文提出的双字节特征编码的性能远优于传统的灰度编码方法。
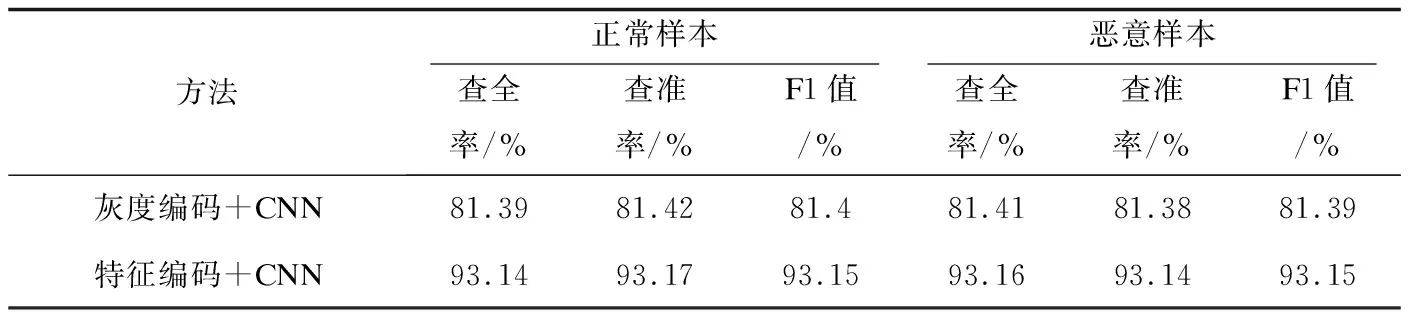
表2 度量性能
4 结束语
针对传统的恶意代码检测技术存在漏报、误报以及资源浪费等的不足,结合卷积神经网络技术在图像分类上的优异表现,提出了一种新的双字节特征编码方法。该方法通过将待检测的PE文件的单个数值特征和非数值特征中子特征数目超过16的编码为2个字节,并将编码后的所有字节转换为灰度图像,然后使用卷积神经网络对其进行特征提取并检测。在带有标签的EMBER数据集中的数据上进行了实验,实验数据为60万条,其中良性样本和恶意样本数各30万条。实验结果表明,提出的双字节特征编码方法通过与卷积神经网络算法结合,在6万条测试集上的准确率accuracy、查全率P、查准率R和F1值的表现都优于传统的灰度编码方法。由此可知,提出的双字节特征编码方法比灰度编码方法更加有效。
提出的双字节特征编码与传统的灰度编码相比具有以下两个优点:
(1)由于提出的双字节编码是将特征编码为两个字节,因此在生成灰度图像时,不会造成特征分裂,保存了特征的完整性。
(2)在精度方面,提出的双字节编码方法的损失值仅为2-16,远低于灰度编码的2-10,因此在分类性能上大大提升。
提出的双字节特征编码方法存在三点不足:
(1)在对一些非数值特征里面的相关子类特征进行处理时,并没有根据该特征的特点进行对应编码。
(2)没有考虑父特征和子类特征的关联性,没有将父特征与其对应的子类特征进行结合编码。
(3)在深度学习算法方面,CNN网络结构上的优化也存在不足,并且只使用了一种网络架构。
未来的工作可能会采用新的编码方法对非数值特征里的子类特征进行编码,根据其特点进行对应编码;并且将父特征和子类特征进行结合编码,体现其关联性;并使用更加成熟的网络结构进行训练(例如:VGG-16,Inception-v4等)。
