基于深度强化学习的插电式柴电混合动力汽车多目标优化控制策略
2021-01-18隗寒冰贺少川
隗寒冰,贺少川
(重庆交通大学 机电与车辆工程学院,重庆 400074)
0 引 言
氮氧化物(NOx)是车用柴油机排放的主要污染物[1],为满足国家标准GB 17691—2018《重型柴油车污染物排放限值及测量方法(中国第六阶段)》中规定的NOx排放低于0.4 g/km限制要求,选择性催化还原(selective catalytic reduction,SCR)后处理技术被认为是进一步降低NOx排放的必要技术路线之一。插电式柴电混合动力汽车(plug-in hybrid electric vehicles,PHEV)工作模式切换过程中由于发动机频繁启停导致的发动机排气温度和进气流速波动较大,从而导致SCR催化器效率降低和排放恶劣,冷启动阶段这种性能下降更为明显。因此制定优化的整车控制策略在保证燃油经济性的条件下有效降低NOx排放,实现发动机油耗及后处理系统综合优化控制具有十分重要的意义。
整车控制策略作为插电式混合动力汽车关键技术之一,已经得到了广泛研究[2]。基于规则的控制策略因其算法简单、实时性好的优点在工程中被大量采用[3-4],然而策略制定需要大量实验和专家经验,无法适应工况变化,不能充分发挥插电式混合动力汽车的节能潜力。最优控制策略利用优化算法求解最小化目标函数,可以实现整车能量最佳分配[5-7],此类策略计算资源占用大,执行效率不高,实时应用受到限制。基于学习的控制策略利用历史或实时数据进行学习应用,可以根据不同的行驶工况对控制策略参数进行自调整,优化车辆运行以适应不同的驾驶工况[8-9],但仍依赖专家经验和精确的系统模型。近年来,作为人工智能、机器学习和自动控制领域研究热点之一的强化学习在混合动力控制策略中开始得到了应用[10],如:T. LIU等[11]提出马尔科夫概率转移矩阵在线更新方法,并结合Q-learning算法应用于混合动力汽车能量管理问题,其效果与动态规划接近;Y. HU等[12]使用Q-learning算法在线优化模糊控制器参数,对不同驾驶工况都表现出较好的实时性与燃油经济性;针对Q-learning算法采用二维查值表存储最优值时,面临高维度或连续状态导致“维度灾难”,且训练难以收敛等问题,J. D. WU等[13]采用深度强化学习利用神经网络拟合最优值函数。
笔者提出基于深度强化学习的油耗与排放多目标综合优化控制策略,采用深度Q网络(deep Q-learning network,DQN)算法通过学习和探索的方式获得最优控制策略,该策略以需求功率、蓄电池SOC和SCR温度为状态变量、以电机最优输出功率为输出变量,能实现从运行工况到电机执行端对端的学习与控制。最后将仿真测试结果与动态规划(dynamic programming,DP)策略进行对比分析,证明所提出控制策略的有效性。
1 插电式柴电混合动力系统建模
以ISG型单轴并联式插电式柴电混合动力汽车为研究对象,其整车动力系统结构如图1。动力系统主要由柴油机、动力电池、湿式离合器、ISG电机、换挡离合器、5档AMT自动变速器等部分组成,后处理系统采用SCR。电机安装采用P2构型,实现制动能量回收和高效率联合驱动等功能。整车通过CAN总线实现各控制器之间的数据通信与车辆状态监控,整车各部件相关参数如表1。
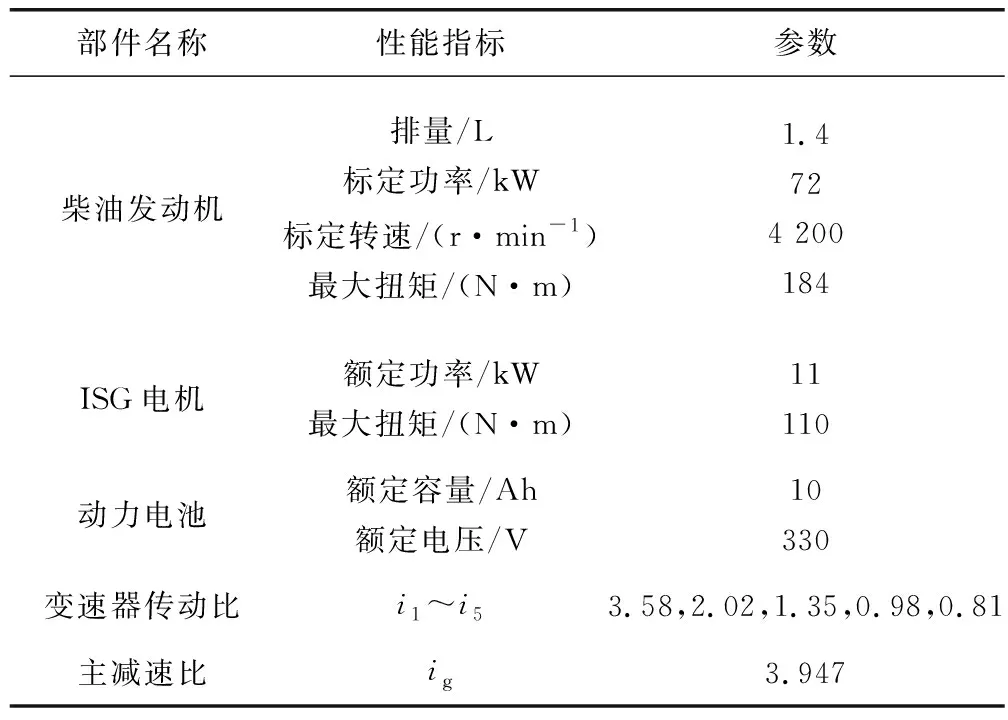
表1 整车各部件性能参数Table 1 Performance parameters of the vehicle’s components
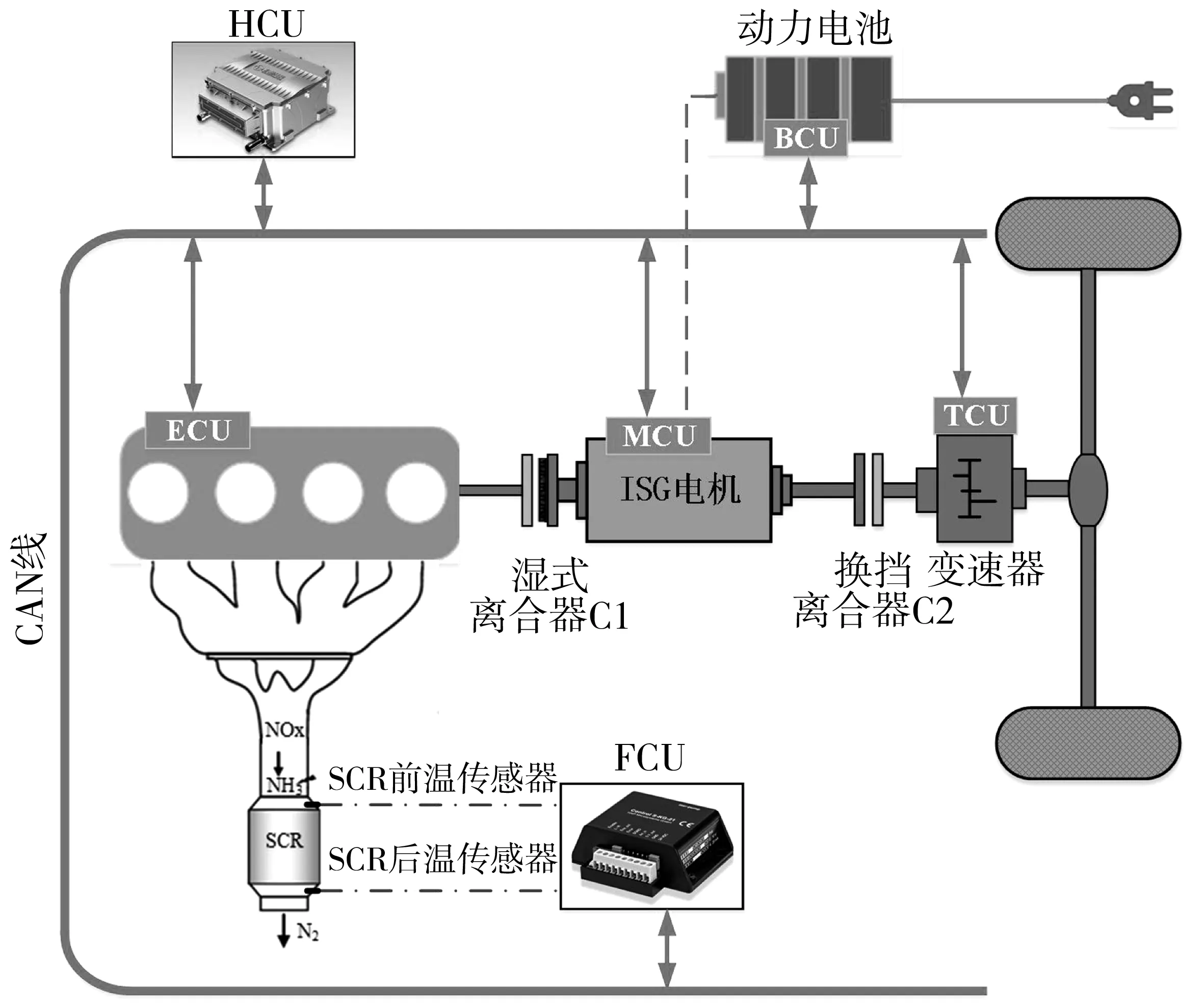
图1 PHEV整车动力系统Fig. 1 PHEV powertrain system
1.1 整车纵向动力学模型
忽略车辆横向动力学影响,假设整车质量集中作用在重心上,根据车辆行驶过程中受到的滚动阻力Ff、空气阻力Fw、坡度阻力Fi和加速阻力Fj,其驱动力平衡方程为:
(1)
式中:M为汽车质量;g为重力加速度;f为滚动阻力系数;α为道路坡度;CD为空阻系数;A为汽车迎风面积;v为车速;δ为汽车旋转质量换算系数。
不考虑坡度因素即α=0,在给定车速v下由车辆驱动力平衡方程计算出车辆需求功率和车轮转速分别为:
(2)
(3)
式中:r为车轮半径。
1.2 动力电池模型
动力电池工作时内部具有复杂的非线性变化过程,笔者忽略温度对电池特性的影响,建立一阶内阻电池模型,如图2。
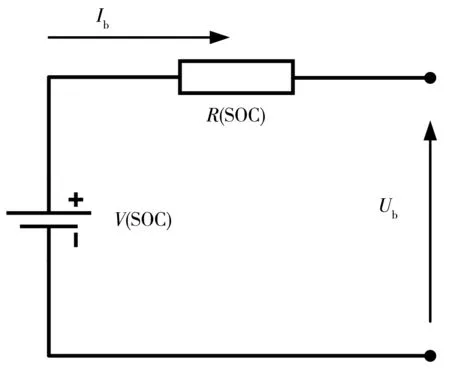
图2 电池内阻模型Fig. 2 Battery internal resistance model
电池电流I如式(4):
(4)
电池SOC如式(5):
(5)
式中:V为电池端电压;R为电池内阻。
1.3 发动机模型
在混合动力系统控制策略研究中,发动机模型不考虑复杂的燃烧过程和动态响应过程,只关心输入输出映射关系,能准确有效的反应发动机稳态特性即可。因此利用发动机油耗和排放台架实验得到发动机转矩、转速和燃油消耗量及NOx排放的关系,通过插值发动机台架试验稳态数据建立发动机油耗和NOx排放数值模型如图3、图4,其表达式为:
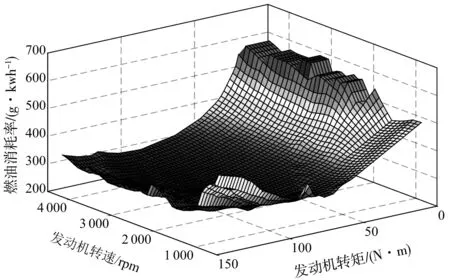
图3 发动机燃油消耗Fig. 3 Fuel consumption for engine
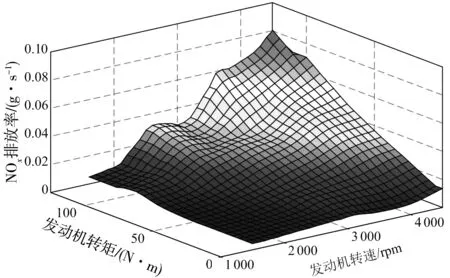
图4 发动机NOx排放Fig. 4 NOx emission for engine
(6)
(7)
式中:geng为发动机瞬时燃油消耗率;gNOx为发动机出口瞬时NOx排放率;Teng为发动机转矩;ωeng为发动机转速;mfuel为发动机燃油消耗质量;mNOx为发动机出口NOx排放质量。
1.4 后处理系统模型
SCR后处理系统常采用钒基或沸石基作为催化剂,在一定温度条件下SCR喷射NH3与尾气中的NOx发生催化还原反应生成N2。SCR催化器转化效率对温度十分敏感,插电式混合动力汽车工作模式切过程中由于发动机频繁启停引起的发动机排气温度和进气流速波动明显,从而导致SCR催化器催化效率降低和排放恶劣[14]。
遵循Eley-Rideal机理[15-16],假设SCR催化器中废气为不可压缩等熵流动,只考虑催化器与废气的对流换热以及与周围环境的辐射散热,建立SCR催化器反应温度模型为:
(8)
式中:TSCR为SCR催化器温度;Mexh为发动机出口废气流速;CSCR为催化层比热容;h为热传递系数;Tamb为发动机环境温度;Teng为发动机出口温度;Cexh为废气比热容。
2 基于DQN的多目标优化控制策略
2.1 强化学习基本原理
强化学习基本思想是智能体通过与环境之间的相互作用进行不断学习,从而实现一系列最优决策,以得到最大化累计奖励[17],基本原理如图5。
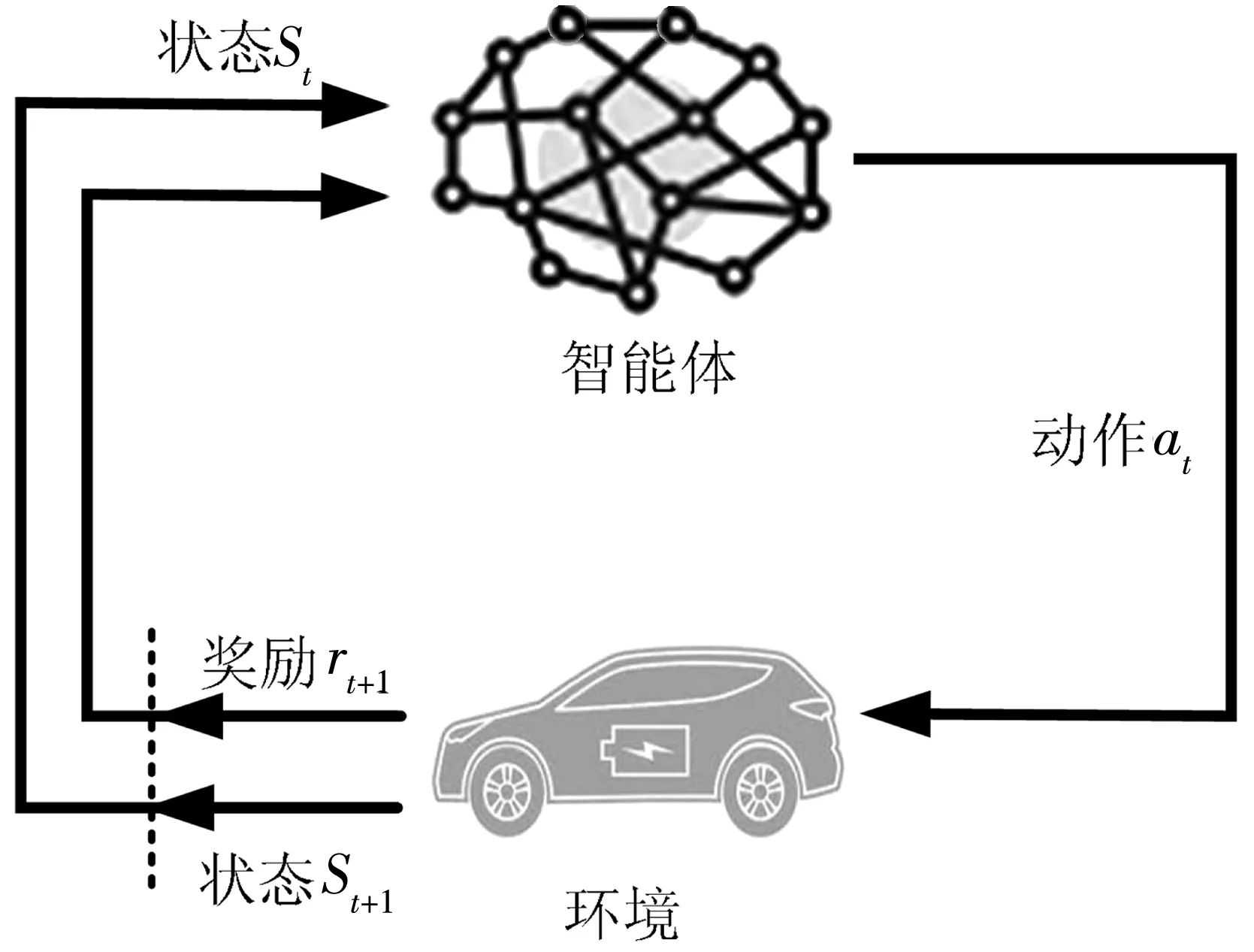
图5 强化学习示意Fig. 5 Schematic of reinforcement learning
学习者和决策者为智能体,在每个时间步长t(t=0,1,2,3…),智能体观测到环境的状态为st(st∈S),根据观测到的环境状态和当前策略做出决策,然后选择最优动作at(at∈A)。环境接收动作后进入新的状态st+1,并给出对应的奖励rt+1,智能体依据得到的奖励大小,不断学习改进其行为策略,以便获取最大累积奖励。整个过程为状态到行动的转换,如式(9):
Ht=s0,a0,s1,a1,…,st-1,at-1,st
(9)
定义从t时刻开始的累计奖励如式(10):
R(st,at)+γR(st+1,at+1)+γ2R(st+2,at+2)+…
(10)
式(10)简化如式(11):
Rt+γRt+1+γ2Rt+2+…
(11)
式中:γ为奖励衰减因子;Rt为奖励回报函数。
强化学习的目标是智能体通过完成一系列动作获得最大化期望回报,定义如式(12):
E[Rt+γRt+1+γ2Rt+2+…]
(12)
由于当前动作执行时,未来动作和状况不可知,因此引入状态-动作值函数估计在已知当前状态s下,按照某种策略ε行动产生的预计未来回报。基于策略ε的状态-动作值函数定义为:
Q(s,a)=Eε[Rt+γRt+1+γ2Rt+2+…|st=s,at=a]
(13)
简化为:
Q(s,a)=Eε[Rt+γQ(st+1,at+1)|st=s,at=a]
(14)
Q(s,a)表示每个状态下的预计未来回报,基于状态-动作值函数定义则将强化学习目标最大化期望回报转化为最优策略ε*,使每一个状态的价值最大化:
ε*=argmaxεQ(s,a),∀s,a
(15)
2.2 基于强化学习的控制策略问题建模
控制策略本质是求解带约束的优化问题,即在满足循环工况下驾驶员需求功率、动力总成各部件物理约束情况下,求出最优策略使得整车油耗和排放的综合指标最小化。
基于2.1节强化学习理论基础,选取电机输出功率Pm为控制变量,需求功率、电池SOC和SCR温度为状态变量,将目标函数定义为带折扣的累计回报:
(16)
式中:γ为奖励衰减因子,以保证性能指标函数的收敛,γ∈[0,1];R(t)为每个时间步长t内由控制变量引起的奖励回报函数,由油耗、排放和SOC惩罚项的加权和组成,定义如式(17)~式(19):
R(t)=ω1Rfuel(t)+ω2Remis(t)+ω3(SOC-0.4)
(17)
(18)
(19)
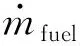
系统控制变量表示为:
U(t)=Pmot(t)
(20)
系统状态变量表示为:
S(t)=[Preq(t),SOC(t),TSCR(t)]
(21)
系统满足的物理约束条件为:
式中:SOCmax和SOCmin为电池SOC限值;TSCR,max和TSCR,min为催化器温度安全限值;Pmot,max和Pmot,min为ISG电机功率限值;Peng,max和Peng,min为发动机功率限值;Tmot,max和Tmot,min为ISG电机转矩限值;Teng,max和Teng,min为发动机转矩限值。
系统边界条件为:
基于强化学习理论将整车油耗和排放量的综合指标最小化问题转化为寻找最优控制策略ε*对应的控制动作序列。因此定义最优状态-动作值函数Q*(s,a):
Q*(s,a)=maxεE[Jt|st=s,at=a]
(22)
式中:ε是将状态映射到动作的策略,可进一步简化为:
Q*(s,a)=maxεE[Rt+γQ*(st+1,at+1)|st=s,
at=a]
(23)
最优状态-动作值函数Q*(s,a)对应的控制量为最优控制动作U*。由式(23)可以看出,最优状态-动作值函数遵循贝尔曼最优性原理,因此可以采用动态规划算法求解以上问题。
2.3 基于DQN算法的控制策略问题求解
实际车辆系统呈现高维连续特征,采用动态规划求解需要进行离散化,当问题规模较大时动态规划算法将带来维度灾难。深度强化学习将深度学习和强化学习相结合形成深度Q-learning网络,深度学习提供学习机制,强化学习为深度学习提供学习目标,使得深度强化学习具备解决复杂控制问题的能力[19],因此可应用于插电式混合动力汽车能量管理问题中。笔者提出的基于深度强化学习的插电式混合动力汽车多目标优化控制策略原理如图6。
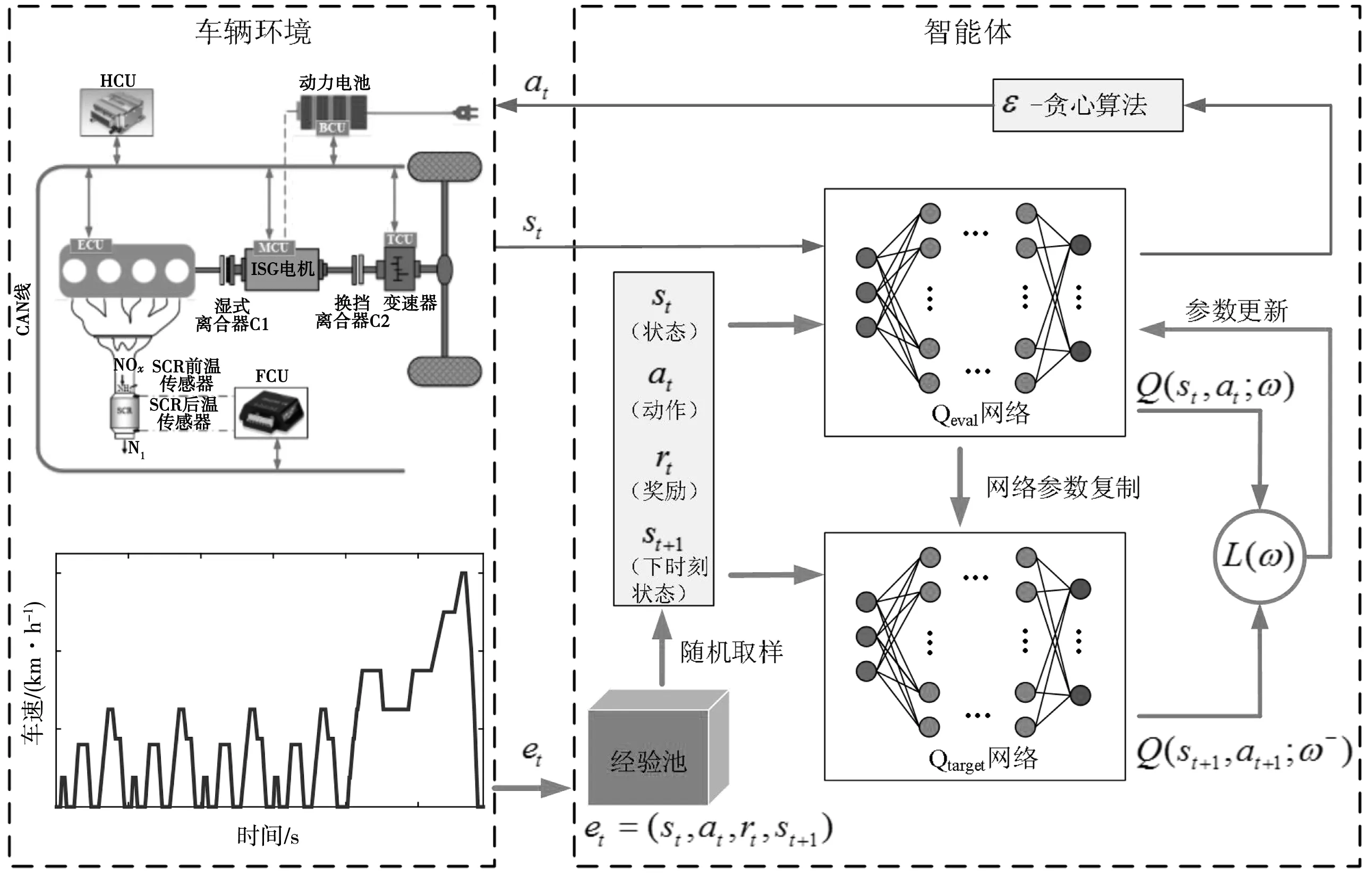
图6 控制策略原理Fig. 6 Principle of control strategy
基于深度强化学习的控制策略采用深度神经网络来拟合最优状态-动作值函数Q*(s,a),即:
Q(s,a,ω)≈Q*(s,a)
(24)
式中:ω为神经网络的参数。
为使DQN算法在训练过程中进行充分学习到更加优化的策略,利用ε贪心算法以概率ε选取最优Q值对应的控制动作,以1-ε的概率随机选取控制动作。然后采用经验回放方法将每个时间步长t内智能体探索环境得到的经验数据,即对应的状态-动作序列存储到经验池Dt={e1,e2,…,et}中,如式(25)。最后从经验池中随机抽取样本训练深度神经网络,这样不仅消除时间数据序列之间的相关性, 也使得网络更新更有效率。
et=(st,at,rt,st+1)
(25)
式中:st为当前状态;at为智能体根据当前状态采取的动作;rt为执行动作后的奖励;st+1为下一时刻的状态。
DQN算法使用两个结构完全相同参数不同的神经网络进行策略的学习与改进,其中Qtarget网络用于计算目标Q值,网络参数不需要迭代更新;Qeval网络用于估计当前状态下最优Q值并产生最优的控制动作,且拥有最新的网络参数。每隔一定步长,将Qeval网络参数复制给Qtarget网络,即采用延时更新减少目标Q值和当前估计Q值的相关性,增加算法稳定性。
DQN算法通过最小化损失函数来进行迭代更新。损失函数定义为目标Q值与最优估计Q值之差的平方:
Q(st,at,ω)]2}
(26)
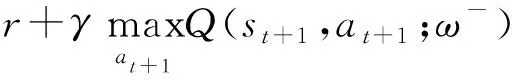
搭建的Q网络采用5层全连接神经网络如图7,其包含3个隐含层,神经元个数分别为20、50、100,并使用ReLU(rectified linear unit)激活函数;输入层神经元个数为3,主要取决于定义的状态变量数;输出层使用线性激活函数,每个输出代表一个控制动作,共45个控制动作,使用梯度下降优化函数来最小化损失函数。
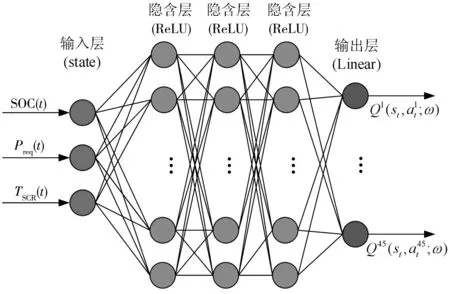
图7 神经网络架构Fig. 7 Neural network architecture
基于DQN的多目标优化控制策略算法流程如下:
步骤1:初始化。经验池可存储状态-动作对数量N、Qeval网络权重参数ω、Qtarget网络权重参数ω-=ω。
步骤2:For episode=1:M do
步骤3:获取初始状态Preq(0),SOC(0),TSCR(0)。
步骤4:Fort=1:T do
步骤5:以概率ε选取最优Q值对应的控制动作at,否则随机选取控制动作at。
步骤6:执行at得到立即奖励rt,并观测系统下一时刻状态st+1。
步骤7:将经验数据et=(st,at,rt,st+1)存储到经验池D中。
步骤8:从经验池中随机抽取n个样本(st,at,rt,st+1)。
步骤9:if当前状态为终止状态si+1:
yi=ri
else:
步骤10:梯度下降法更新Qeval网络权重,损失函数为[yi-Q(si,ai;ω)]2。
步骤11:隔C步将Qeval网络参数复制给Qtarget网络。
步骤12:End for。
步骤13:End for。
为了加快网络训练速度,将输入数据进行归一化处理,通过式(27)、式(28),将Preq和TSCR范围压缩到[0,1]:
(27)
(28)
3 仿真分析
笔者将DQN算法应用于插电式柴电混合动力汽车的能量管理控制策略问题,进行油耗与排放多目标综合优化。为了验证控制策略的有效性,选取NEDC工况对DQN算法进行离线训练和在线仿真测试,并将仿真结果与DP算法进行对比分析。动态规划算法不依赖近似计算求极值,能够得到全局最优解,故被广泛用于混合动力汽车控制策略算法评价。DQN算法的相关参数设置如表2。
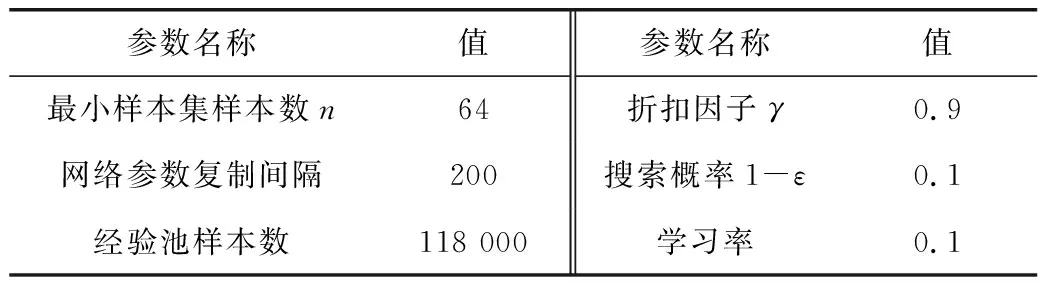
表2 DQN算法参数Table 2 DQN algorithm parameters
图8为DQN算法在离线训练过程中的平均损失曲线,在迭代开始时刻损失值快速下降,随着训练不断进行,平均损失逐渐减小,说明了算法能迅速收敛。图9 为平均累积Q值变化曲线,其反应了每个状态下智能体获得的累计折扣回报,能够稳定的反映算法性能[20]。可以看出随着迭代次数的增加,网络不断调整对Q值的过高或过低估计,最终逐渐趋于稳定并收敛。
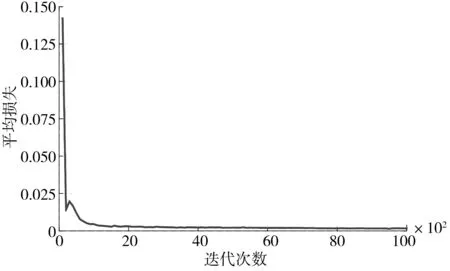
图8 训练平均误差损失Fig. 8 Average training error loss
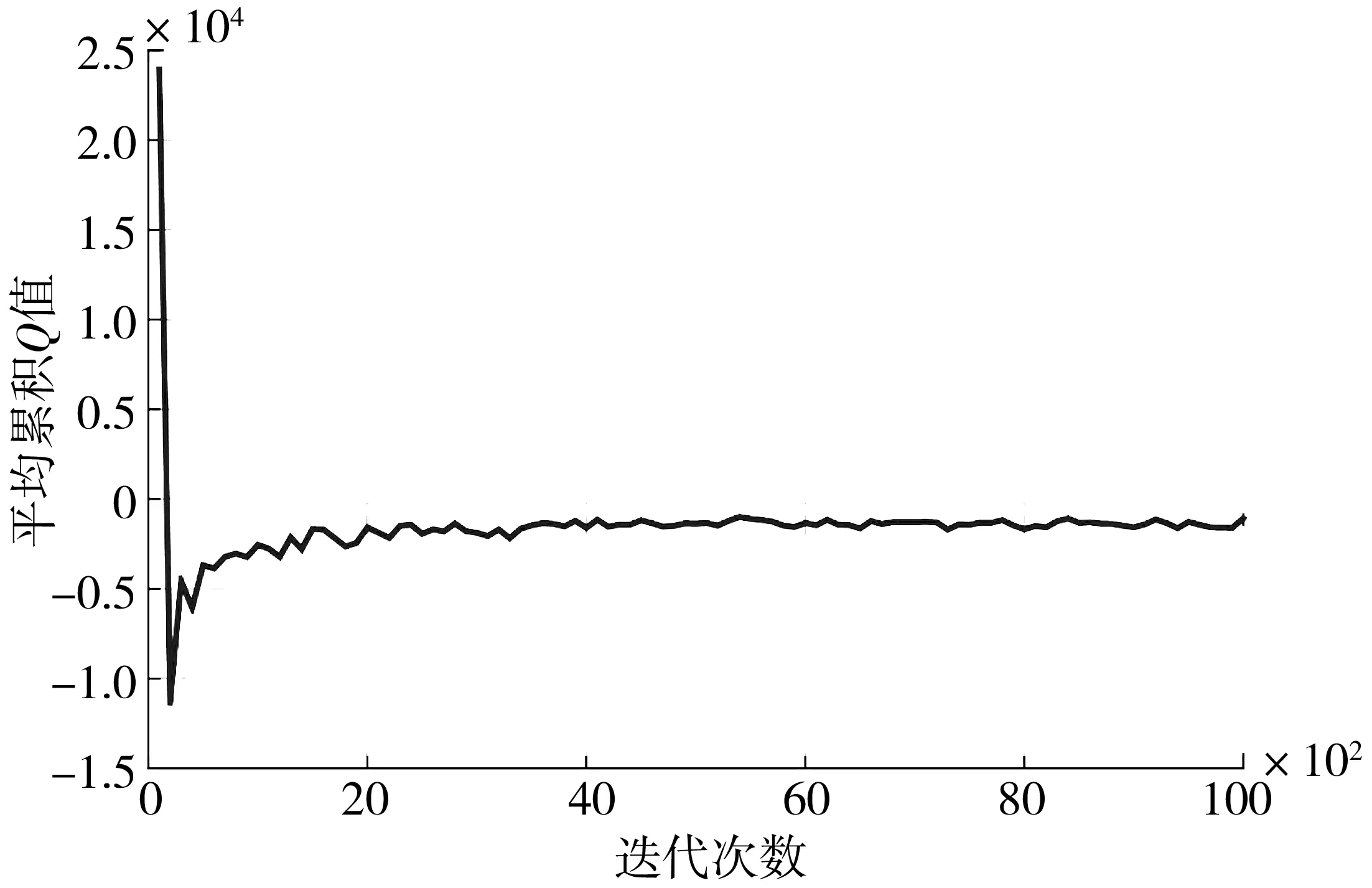
图9 平均累积Q值Fig. 9 Average cumulative Q-value
图10为DQN和DP两种控制策略对应的SOC曲线变化情况,初值SOC均为0.8。可见两种策略下SOC下降曲线轨迹基本一致,说明DQN能够得到DP全局最优解的近似解。前800 s为ECE工况车辆需求功率较低,电机主要提供辅助动力,SOC下降趋势平缓,800 s后随车辆需求功率变大,电机工作时间变长,SOC快速下降,工况结束时刻均维持在0.42左右。DP控制策略下SOC曲线偏低,主要由采用离散化的状态,每个工况点强迫SOC落在定义好的状态网格上的误差导致。
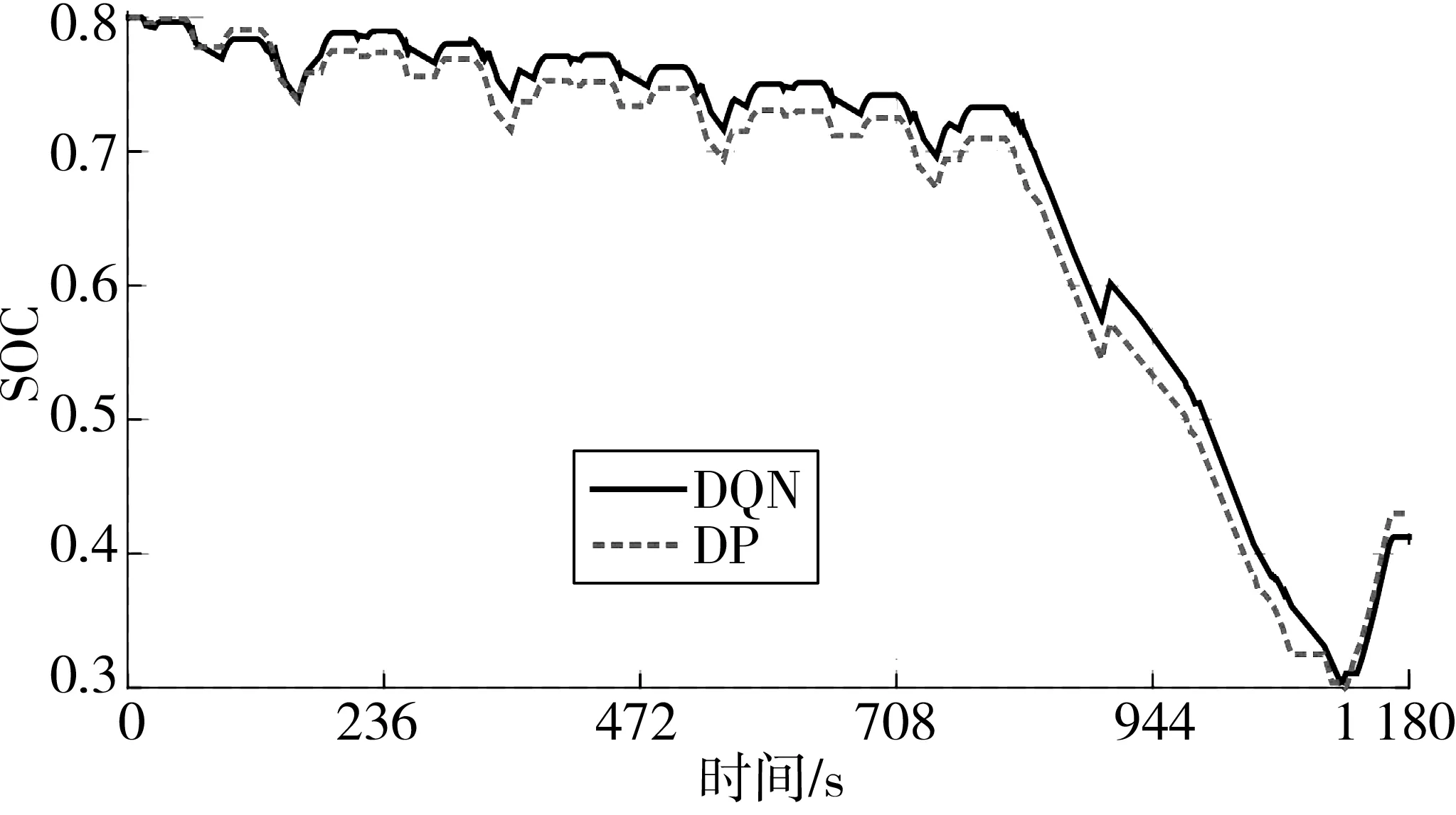
图10 DQN和DP控制策略的SOC曲线Fig. 10 SOC curve of DQN and DP control strategy
图11和图12为电机功率分配和电机工作效率MAP图。由于训练数据样本本身存在不稳定性,造成训练得到控制策略具有波动性,引起DQN控制策略下的电机功率输出在部分地方出现较大的跳动。从电机工作效率MAP图可以看出,DQN控制策略下对应的电机工作点分布相对较为分散,但总体效率与DP控制策略基本相当,进一步说明DQN算法通过训练能够获得优化的控制策略。
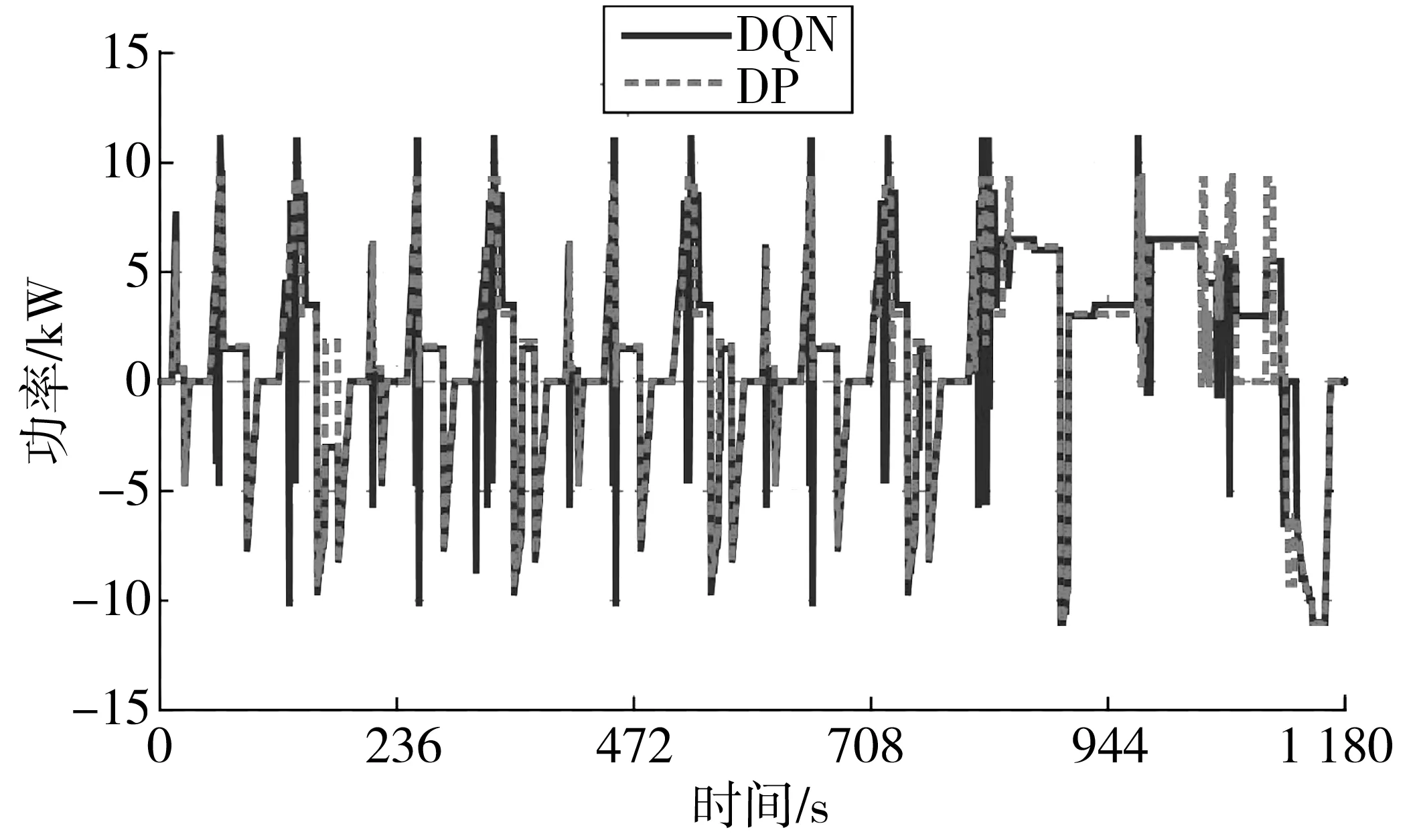
图11 电机功率分配Fig. 11 Motor power distribution
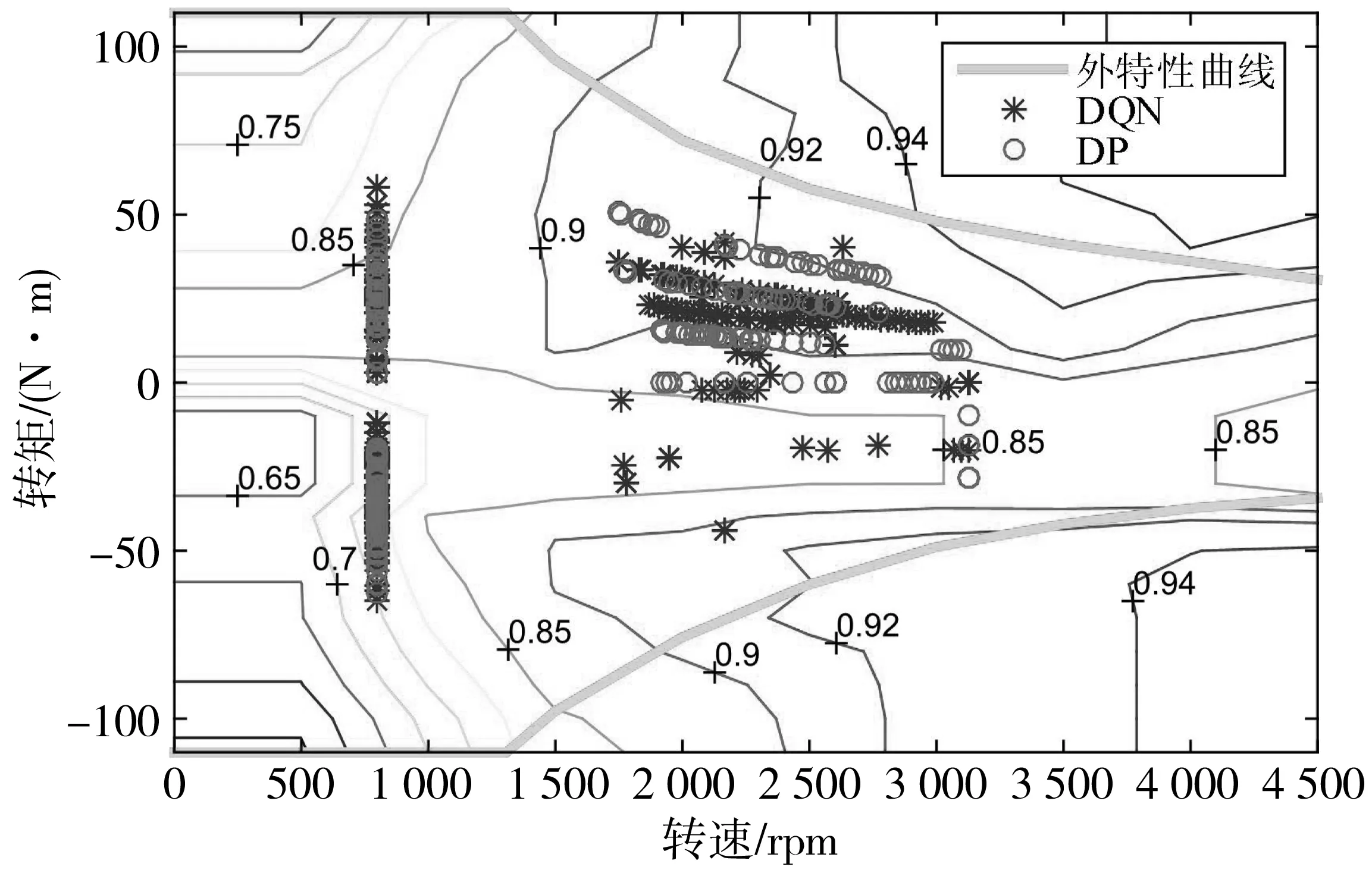
图12 电机工作点在效率MAP图分布Fig. 12 Distribution of motor load in the efficiency MAP
图13和图14为SCR催化器温度变化曲线和转化效率曲线。由图13可知,SCR催化器温度变化分为快速升温和温度保持两个阶段。在快速升温阶段,SCR催化器温度快速升高以提高转化效率,降低SCR催化器出口NOx排放量,DP控制策略下在221 s 内达到起燃温度,DQN控制策略下的起燃时间为248 s,起燃速度与DP控制策略接近;进入温度保持阶段,SCR催化器在最佳工作温度350 ℃附近上下波动,此时转化效率高达93%,在900 s时由于高需求功率导致SCR催化器温度不断升高,转化效率下降13%,但在两种策略控制作用下又逐渐回归稳定,在此阶段DP和DQN控制策略下的SCR催化器温度变化基本一致。
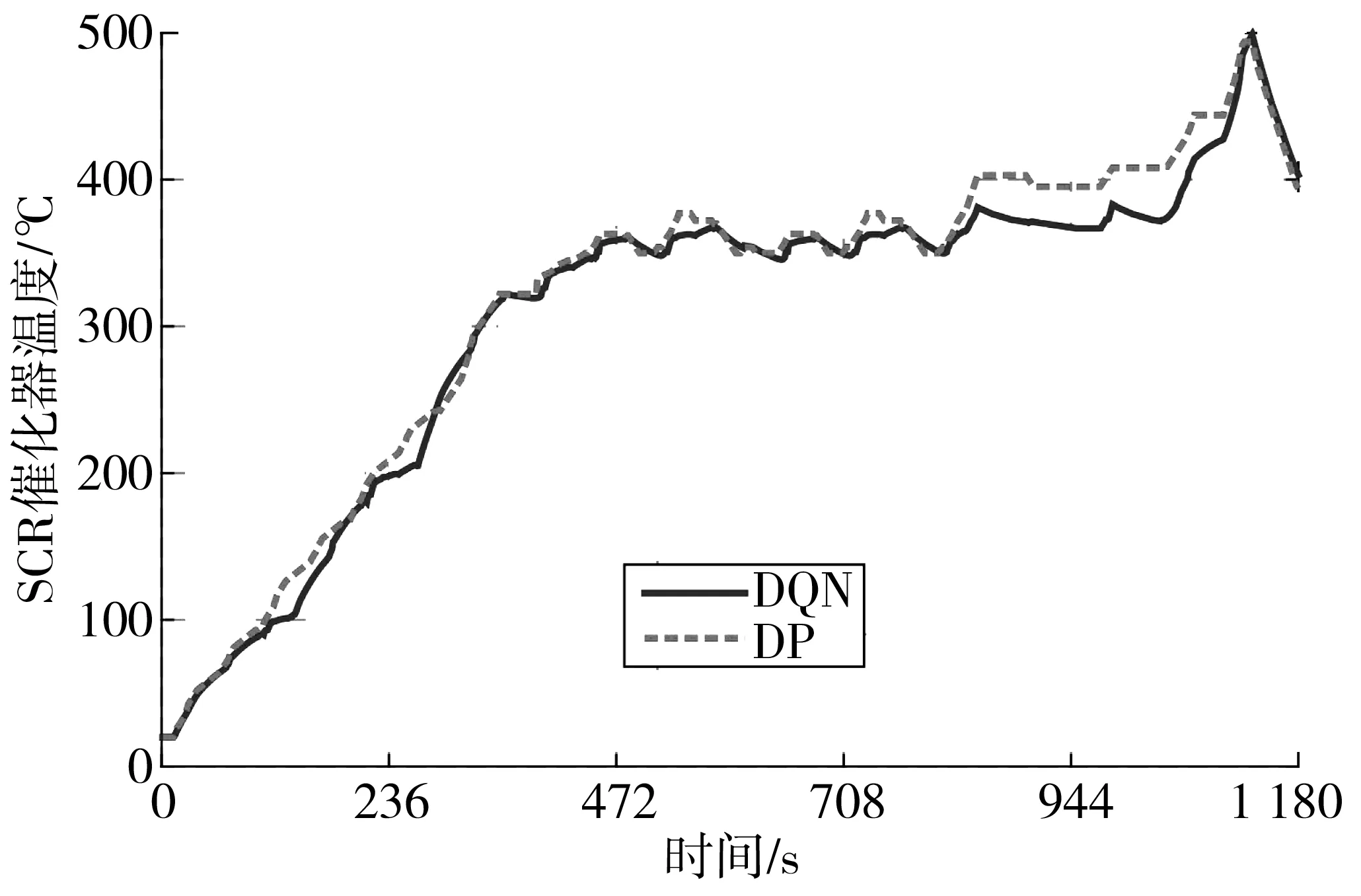
图13 SCR温度变化对比Fig. 13 Comparison of SCR temperature variation
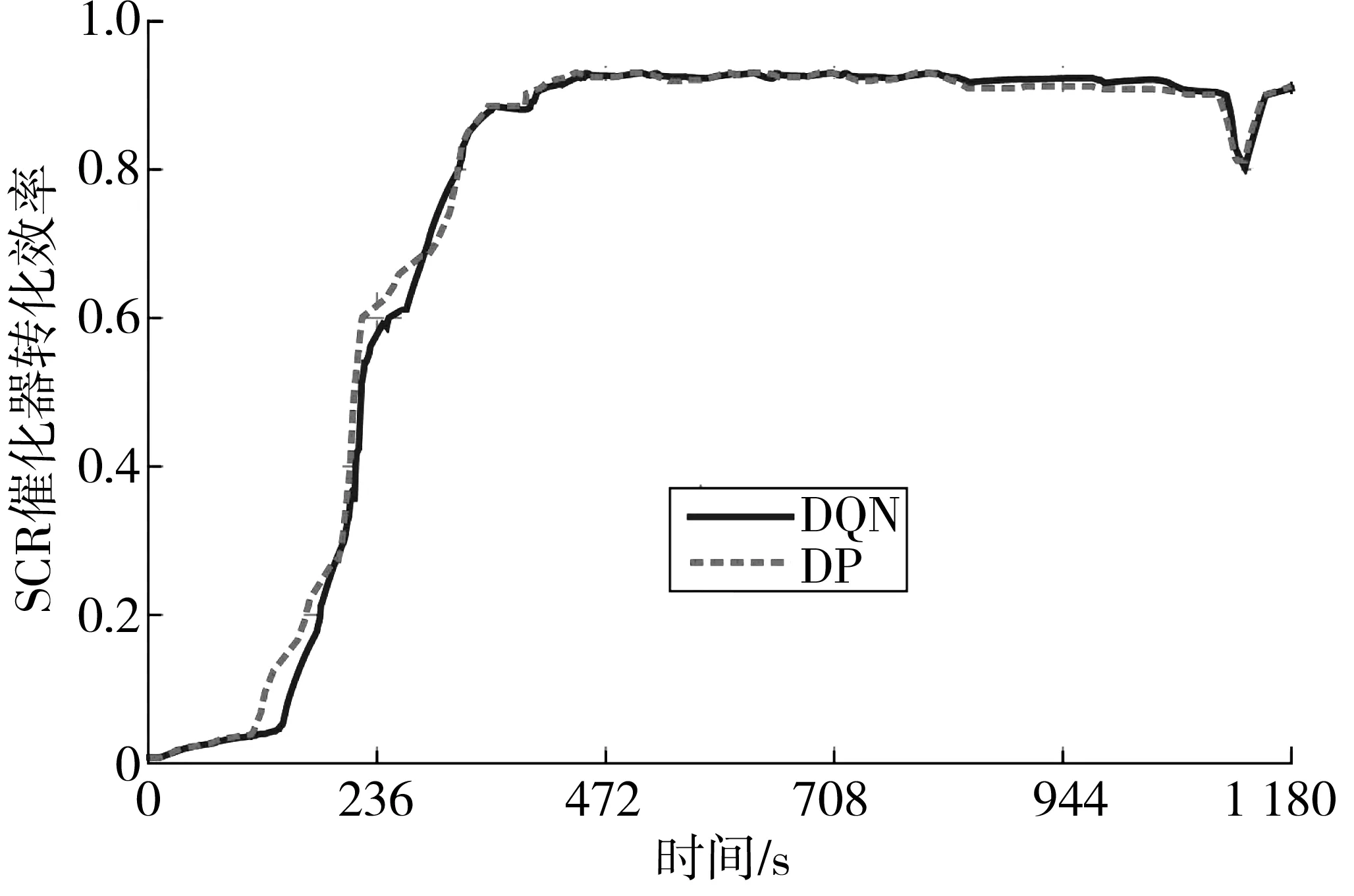
图14 SCR催化器转化效率Fig. 14 Conversion efficiency of SCR catalytic converter
图15和图16为两种策略下的发动机工作点在油耗MAP图和NOx排放MAP图上的分布情况。为了平衡最优燃油经济性与最低NOx排放之间的trade-off关系,以牺牲部分油耗为代价,减少发动机出口NOx排放量,因此两种策略下发动机均未完全在最优的经济区域内工作。在此情况下,DP控制策略得到的燃油消耗量为2.331 L/100 km,DQN控制策略燃油消耗量为2.615 L/100 km,为对应DP控制策略油耗的87.82%。在NOx排放方面,DP控制策略下的NOx排放量为0.181 g/km,DQN控制策略下的NOx排放量为0.2275 g/km,为对应 DP控制策略NOx排放量的74.31%。
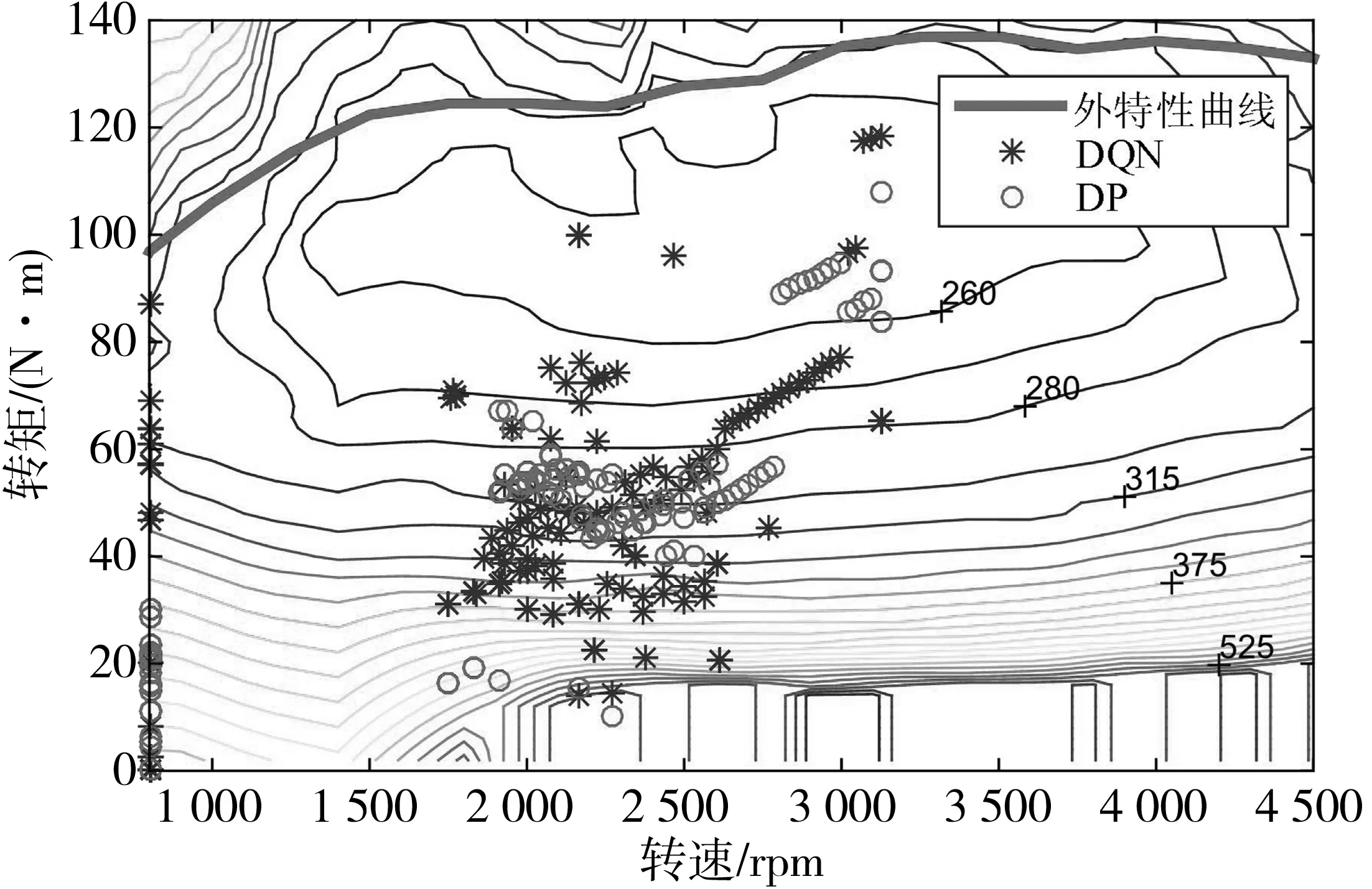
图15 发动机工作点在油耗MAP图分布Fig. 15 Distribution of engine load in the fuel consumption MAP
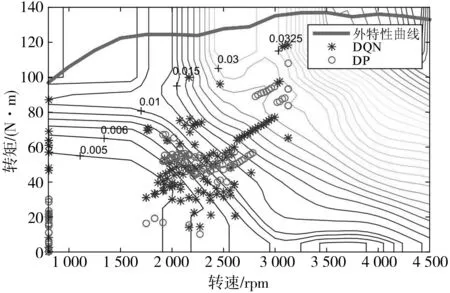
图16 发动机工作点在NOx排放MAP图分布Fig. 16 Distribution of engine load in the NOx emission MAP
DP控制策略和DQN控制策略对比结果如表3。由表3可以看出,笔者提出的基于深度强化学习的多目标优化控制策略可以实现较好的控制效果,两种控制策略下的SCR起燃时间只相差27 s。整车燃油经济性方面,DQN控制策略的油耗为2.623 L/100 km,为DP控制策略对应油耗的89.82%;NOx排放方面,DQN控制策略下的SCR出口NOx排放量为0.2275 g/km,为DP控制策略对应NOx排放的74.31%,结果证明了笔者所提控制策略的有效性。

表3 两种控制策略下仿真结果对比Table 3 Comparison of simulation results of two control strategies
4 结 论
1)为实现插电式柴电混合动力汽车油耗与排放的多目标综合优化,基于强化学习理论给出了多目标函数定义,并提出了基于DQN算法的多目标优化控制策略;
2)在NEDC工况下进行离线训练得到最优的电机功率分配序列,实现了以需求功率、SOC和SCR温度为状态变量,以电机最优功率为输出变量的控制策略;
3)仿真结果表明,基于深度强化学习的多目标优化控制策略取得了较好效果,燃油消耗为2.623 L/100 km,SCR催化器出口NOx排放为0.227 5 g/km,与DP控制策略相比,分别下降10.12%和25.69%,具有实时在线应用的潜力。
