一种图像形状的编码表达方法及其应用
2021-01-15许少武卿来云乔元华邹柏贤
苗 军,许少武,卿来云,乔元华,邹柏贤
(1.北京信息科技大学 计算机学院,网络文化与数字传播北京市重点实验室,北京 100101;2.中国科学院大学 计算机科学与技术学院,北京 100049;3.北京工业大学 数理学院,北京 100124;4.北京联合大学 应用文理学院,北京 100191)
0 引言
卷积神经网络(convolutional neural network,CNN)是LeCun[1]提出的一种特殊的神经网络。自Krizhevsky等[2]提出的AlexNet首次在ILSVRC比赛取胜以来,许多研究者开始投入到对CNN的研究中。如今CNN除了在图像方面[3-6],还在音频[7-9]、视频[10]和语义识别方面[11-14]表现出优秀的应用效果。
但是,CNN仍未能够完美地模拟人类视觉。Szegedy等[15]向一组曾被CNN正确识别的图片中混入了噪声数据得到一组新的图片,新的图片在人眼看来与原始图片极为相似,但是使用由原图片进行训练得到的CNN模型对新的图片进行分类却有不同的结果,即在人眼看来高度相似的两张图片会被CNN识别为不同的对象。Nguyen等[16]使用进化算法将一组图片进行了变换,变换得到的新的图片在人眼看来与原图片毫无相似之处,然而CNN却会将新的图片识别为与原图相同的对象。Nguyen等[16]认为,CNN之所以会存在这样的缺陷,究其原因在于CNN在训练时只学到了中低层的特征,而没有获得描述全局图像结构的高级语义特征。
为了解决卷积结构无法直接提取图像的高级语义特征的问题,本文提出了形状编码方法。形状是能够描述全局图像结构的高层特征之一,形状编码的作用是提取原图像中的形状特征,并以特征图的形式进行表示。通过形状编码获得表征原图像形状特征的特征图后,将特征图作为学习对象交予CNN进行学习,可以使CNN直接学习到图像的形状特征而非单纯的边缘、纹理等低层特征。
1 形状编码方法
1.1 形状编码
形状编码的核心思想是对图像中的显著点对的空间位置关系进行统计,并将统计的结果以图像的形式表示。因此形状编码需要由两个步骤组成:第一步是将原图像转换为由显著点和非显著点组成的二值特征图,第二步则是对二值特征图进行编码。
1.1.1 原图像转换为二值特征图像
将原图像转换为二值特征图像的过程包含两个阶段。第一个阶段即提取原图像的显著特征,该操作通过卷积来实现。使用中央周边差算子作为卷积核对原图像进行卷积,根据卷积的算法,这一运算所得结果为包含原图像显著特征的特征图像。图1为第一阶段运算的示意图;图1(a)代表一个5×5的原始图像,每一小方格代表图像的一个像素点,小方格中的数值即对应位置像素点的值;图1(b)是3×3的中央周边差算子;图1(c)为使用中央周边差算子为卷积核对原始图像做卷积得到的特征图像。
第二阶段即令前一阶段所得的特征图像二值化。如图2所示,图2(a)为前一阶段运算所得的特征图像,对图像的每一个像素点的值进行判断,若小于0则将该像素点的值置为0,即得到如图2(b)所示的二值特征图像。
图3是将一张28×28的手写数字图像通过上述步骤转换为二值特征图像的示例,图3(a)为原始图像,图3(b)则是通过上述方法进行变换后得到的二值图像。
从图3(b)可以看出,经过上述方法转换得到的图片保留了原本的手写数字的边缘轮廓特征,并且由于像素点二值化的操作,该边缘轮廓特征相对明显。但是这样的特征图像仍然只具有原图像的低层特征,为了能够获得图像的高层特征即形状特征,还需要进行下一步的变换。
1.1.2 对二值特征图像进行编码
编码过程需要统计二值特征图像中任意一对显著点的出现频度。如图4(a)所示,设有一个包含9个像素点的3×3的图像,其中有2个像素点是显著点(黑点),其余7个点为非显著点。以位于图像第一行第一列的像素点为坐标原点建立直角坐标系,则在此直角坐标系中,两个显著点在x轴和y轴方向上的距离分别为-1和2,即Δx=-1,Δy=2。然后在一个新的图像中统计这样的显著点对,新图像的宽度与原图像相等,长度则为2倍的原图像长度减1。以新图像第一行中间列的像素点为原点建立直角坐标系,令坐标系横轴为Δx,纵轴为Δy,在该坐标系中对应横轴坐标为-1、纵轴坐标为2处统计在原图像中相互之间距离为Δx=-1、Δy=2的显著点对的数量,如图4(b)所示。
在形状编码的过程中,只取二值特征图像中在y轴方向上距离为正数(即Δy>0)的显著点对。这是因为在统计显著点对的过程中,需要对二值特征图像中的每一个显著点进行遍历,统计其与其他所有显著点所构成的点对,而点对本身则是一个无向图。如图4(a)中的两个显著点,它们既是距离为Δx=-1、Δy=2的点对,也是Δx=1、Δy=-2的点对,因此为了在形状编码时减少冗余特征、避免数据维度无意义地扩大,在统计时只将在y轴方向上距离为正数(即Δy>0)的显著点对纳入计算。根据该方法进行形状编码所得的图像即为形状编码图(shape coding map,SCM)。图5是依照上述流程对图2中的二值特征图像进行形状编码的示意图。
图6(b)是对图3中的二值图像进行形状编码得到的新图像,该图像中颜色越明亮(如图像中部)表示对应的显著点对的频度越高,相对地,颜色越暗淡(如图像右下角处)则表示对应的显著点对的频度越低。
1.2 基于动态阈值的形状编码
在1.1所述的形状编码方法中,首先使用了中央周边差算子对图像进行卷积,卷积的结果是与原图大小相同的特征图。在原图像中明显属于非显著性特征的像素点在特征图中对应位置的像素点的值为0或负值;相对地,在特征图中数值为正值的像素点,由计算过程可知,其在原图像中对应位置的像素点的值要大于该点周边的8个像素点的值之和,我们将具有这种特性的像素点视为可能属于显著性特征的像素点。而二值化时将所有小于0的像素点的值都置为0的计算过程,其实质是将0作为阈值对上一步中得到的可能属于显著性特征的像素点做进一步筛选,将所有数值在阈值以上的像素点视为显著点,将所有数值在阈值以下的像素点视为非显著点,同时令所有非显著点的值为0,将其与显著点做明显区分。像这样将一个恒定的值用以区分整个特征图中的点是否显著的做法,又可称为使用绝对阈值的形状编码。
考虑到对于某些图像而言,属于同一图像、但却位于图像上不同区域(如手写数字图像中笔划较重的部分与较轻的部分之间)的显著点的数值可能会存在较大差距,这时使用绝对阈值将特征图中的所有特征点进行区分可能会导致误分,即将一些理应作为显著点的像素点视为非显著点。对此,我们提出使用动态阈值的形状编码(shape coding using dynamic threshold),不使用绝对阈值甄别显著点与非显著点,而是将待定像素点周边的像素点的值也纳入计算,即基于像素点所在局部区域的特征,动态地获得阈值用以对待定像素点进行划分,然后再依照基于动态阈值而获得的二值特征图进行形状编码,所得结果即为基于动态阈值的形状编码图(shape coding map based on dynamic threshold,SCMDT)。
基于动态阈值的显著点提取方法计算方式如下:
设IM×N表示大小为M×N的原图像,OM×N表示使用中央周边差算子对原图像进行卷积后得到的大小相同的特征图,用IM×N(i,j)和OM×N(i,j)分别表示位于两图中第i行第j列的像素点的值,使用rS(i,j)表示位于第i行第j列的像素点所在3×3小区域的所有像素点的值之和,即:
(1)
其中,因为i和j分别代表像素点的行列坐标,所以有1≤i≤M,1≤j≤N。
对位于(i,j)处的像素点,与其相对应的动态阈值可通过如下公式计算得到:
(2)
其中α为给定的动态阈值系数。若令OM×N中的所有像素点分别与其对应的动态阈值相减,所得结果为基于动态阈值的特征图像O′M×N:
O′M×N(i,j)=OM×N(i,j)-TH(i,j)
(3)
将O′M×N送入ReLU函数进行二值化之后,依据本文1.1.2所述的对二值图像进行编码的方式对该基于动态阈值获得的二值特征图进行编码,就完成了基于动态阈值进行形状编码的计算。
1.3 分块形状编码
本文提出的形状编码方法是一种基于图像中显著点对的统计的编码方法,最后所有类型的显著点对的统计结果都被汇总到同一矩阵中,将该矩阵以图像的形式表示出来即为类似于如图6(b)所示的形状编码图。一个形状编码图中同时包含了图像中一些大部件如数字整体轮廓的编码,即那些两点间距较长的点对,以及图像中的一些相对小的部件如数字字体结构中的拐角,即那些间距较短的点对。这种情况下,同一图像中不同部件之间的空间结构关系会被忽略。
人类视觉系统对图像的识别存在空间选择性注意,对于视野范围内的信息识别存在左右视野间或是上下视野间的转移过程,在视野转移的过程中人的大脑会认知到视野内目标的空间位置关系,为大脑对目标的识别工作提供线索[17-19]。参考这一点,本文提出分块形状编码方法,以期弥补在形状编码图中同一图像中不同部件间的空间位置关系丢失的问题。
图7所示为对手写数字图像进行形状编码的示意图。图7(a)为原始图像,首先使用中央周边差算子对原始图像进行卷积,然后将卷积的结果二值化,得到如图7(b)所示的由数值为正的显著点和数值为0的非显著点组成的二值特征图。将二值特征图分成4个部分,即依照如图7(b)用虚线标示的方位对该图像进行切割,然后将4个部分分别进行形状编码后,再依据原先所在的位置将4个形状编码图进行拼接,最后得到如图7(c)所示的图像,即为分块形状编码图(partitioning SCM,PSCM)。分块的形状编码不仅适用于使用绝对阈值的情况,同样可以用于基于动态阈值的形状编码,获得的特征图即为分块的基于动态阈值的形状编码图(partitioning SCMDT,PSCMDT)。
2 实验与分析
为了验证新的图像表示方法的效果,设置了一个对照实验:分别将原始数据和经过形状编码后的数据作为样本数据导入同一个CNN中进行训练和测试,然后对比所得的训练准确率和测试准确率。
2.1 数据集介绍
MNIST手写字符数据集共有70 000张手写数字图像,包含由60 000张图像组成的训练数据集和10 000张图像组成的测试数据集,是图像识别领域常用的数据集。这70 000张手写数字图像可分为10个类别,分别对应0到9共10个数字。该数据集的图像取材于真实场景,由250个不同的人分别写下然后被转换为电子图片,因此在该数据集中存在一些数字图像其外形与标准数字结构不同。MNIST数据集中每张图像的大小为28×28,该数据集经过形状编码后,得到的每张形状编码图大小为28×55。
如图8所示为以伪彩色显示的MNIST数据集示例图,其中第1列和第3列为原始图像,第2列和第4列为其左侧图像所对应的全局形状编码图。
2.2 卷积网络
形状编码图强调原图像的形状特征而隐性地忽略了原图像中的其余特征类型,如果只让网络对形状编码图进行学习,可能会导致网络学习到的特征不够全面而影响其识别性能。因此,本文使用如图9所示的网络进行实验,网络结构可以看做由4个部分构成:3路卷积网络以及1个将3路卷积的结果合并处理的全连接网络。
3路卷积网络具有相同的结构:2个有着64个3×3大小卷积核的卷积层,以及2个按2×2的块进行最大池化的池化层,2个池化层分别连接在2个卷积层之后。网络的输出层之前是2个全连接层,分别有128和64个神经元。其中,与3路卷积直接相连的是具有128个神经元的全连接层,在训练时以0.5的比率隐藏该全连接层的神经元。
在这种网络结构下,3路卷积网络可以分别送入不同类型的图像数据。如图9所示即为将原图像、形状编码图以及分块形状编码图分别送入了3路卷积,最后的全连接层所接收到的是3路卷积网络各自计算所得的特征图像,全连接层将这3类特征图像进行融合,输出层的输出结果是依据融合的特征所得到的分类结果。
本文在进行实验时所用的优化算法为Adam算法,初始学习率为0.000 1。使用数据集进行训练时分批送入数据集,批大小为600。总训练次数为2 000,并在训练次数分别到达1 000次和1 500次时令学习率缩减到原来的10%。
2.3 实验结果
本文使用3路卷积网络对由原图像与不同类型的形状编码图所组成的多种的特征组合进行识别,并同仅使用原图像,即分别送入3路卷积的数据都为原图而没有与任何形状编码图组合的情况进行对比。在实验中用于与原图进行特征融合的形状编码图有4种类型,分别为:基于绝对阈值的形状编码图,基于动态阈值的形状编码图,分块的基于绝对阈值的形状编码图以及分块的基于动态阈值的形状编码图。其中,在对原图像进行基于动态阈值的形状编码时,使用的动态阈值系数α的值为1.5。
对于每种特征组合在使用同样的超参数的情况下分别进行5次识别实验,将每种特征组合在5次实验中所得的识别准确率的均值进行汇总,如表1所示。表1的前3列对应3路卷积网络各自的输入图像数据类型,表1的第4列给出了使用不同的输入图像组合各自能取得的识别准确率均值,表1第5列是整个3路卷积网络所包含的可训练参数数目,表1末列则是使用不同的输入图像组合分别所需的计算量。
从表1中可以看出,相比于只使用原图进行识别的情况,将原图与合适的形状编码图组合进行识别时可以达到更高的识别准确率。特别地,3路卷积网络在学习由原图像与形状编码图与基于动态阈值的形状编码图这3类图像的融合特征时,对手写数字图像的识别准确率是最高的。同时,当3路卷积网络所学习的融合特征是原图像与分块的形状编码图与分块的基于动态阈值的形状编码图的组合时,取得的准确率在所有统计结果中是次高的。这表明,基于绝对阈值的形状编码图和基于动态阈值的形状编码图所对应的是原图像的两种不同侧面的特征,3路卷积网络在同时学习包括原图在内的这3种图像时,相比于只学习原图像的情况,可以获得更多的信息量。
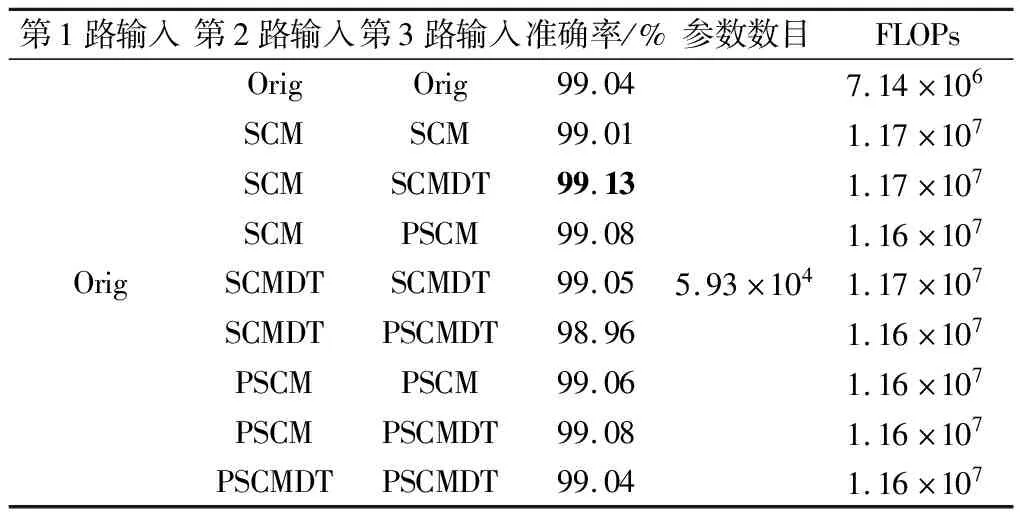
表1 3路卷积网络基于不同特征组合对手写数字图像的识别能力对比
此外,从整体来看,3路卷积网络对于原图和分块与不分块的形状编码图的融合特征的学习情况相对较差。推测的原因是,分块的形状编码图的特点在于将图像整体进行分割从而实现特征的局部化,但并非所有数字都存在突出的局部特征。譬如数字0和数字1就是全局特征与局部特征高度重合的数字,对于这类数字进行分块化可能会导致不必要的冗余信息的产生,而在3路卷积网络将该分块图与原图和不分块的形状编码图进行特征融合时,这些冗余信息可能会对网络的学习产生负面影响。同时,从表1中也能看出,由于相比于原图像,形状编码图的大小有所增加,因此导致使用形状编码图进行学习时训练网络所需的计算量也随之提高。
3 结束语
本文针对一般卷积结构无法直接提取图像的高级语义特征的问题,提出了形状编码方法,可以通过编码的方式获取形状这一图像全局结构特征,并以特征图的形式进行表示。形状编码的编码对象是图像中的显著点对,编码的依据是显著点对间的位置关系,在实现时需要先将原图像转换为仅包含显著点和非显著点的二值特征图,然后再对二值特征图进行编码。原始形状编码方法在转换为二值特征图时使用的是与局部像素点无关的恒定阈值,因此也可称为使用绝对阈值的形状编码。本文基于动态阈值的形状编码方法,以及分块形状编码方法,这两种改进形状编码更强调局部形状信息。
本文通过实验验证了可以通过让CNN学习手写数字原图像与形状编码图的融合特征而非仅学习原始图像特征的方式,提高CNN对手写数字图像的识别准确率。但是,实验中使用的网络结构相对简单,在未来的工作中,我们还需要研究如何在更加深层和复杂的网络中,更高效地将原图像特征与形状编码特征结合,从而提高网络对图像的识别性能。
