基于IF-PGN模型的短文本摘要生成 ①
2021-01-15孙岩,李晶
孙 岩, 李 晶
(佳木斯大学信息电子技术学院,黑龙江 佳木斯 154007)
0 引 言
近年来,随着深度学习模型的发展以及在自然语言处理领域中的广泛应用,自动文本摘要技术受到了广泛的关注[1]。文本摘要技术主要分为两种类型:抽取式和生成式[2],抽取式摘要是通过给文档中的句子按照重要性打分,然后从文档中选取得分高的句子组成摘要,生成式摘要是通过对文档内容进行理解来概括出主要内容[3]。由于生成式摘要与人类撰写的摘要更为相似,越来愈多的学者正把注意力从抽取式摘要转移到生成式摘要上。
在摘要生成任务中,其中序列到序列模型是被应用最广泛的模型,并取得了较好的成果。该模型首次是被Bahdanau等[4]提出并应用于机器翻译。Nallapati等[5]将序列到序列模型应用于文本摘要任务中,在解码器阶段采用分层注意力机制和词表限制解决了在训练过程中出现罕见或不可见的单词的问题。See等[6]在Nallapati工作的基础上引入了指针网络,可以选择是从原文复制单词或者从词汇表中生成单词,解决了OOV(Out-Of-Vocabulary)词汇问题。
指针生成网络虽然提高了摘要的准确性和OOV单词的处理能力[7]。但是它不能完全利用好原文的信息,会受到许多无用信息的影响,导致复制概率不够准确,最终生成的摘要不够连贯且不能包含原文全部信息。本文提出一种信息过滤-指针生成网络(Information Filtering-Pointer Generation Network,IF-PGN)模型,以对输入文本信息进行筛选来避免冗余信息干扰问题,同时让指针网络的复制概率更加准确。
1 包含信息过滤网络的指针生成模型
本文在序列到序列模型的基础上提出了一种包含信息过滤网络的指针生成模型,该模型包括一个编码器一个信息过滤网络,一个带有注意力的解码器和一个指针生成网络,编码器使用双向门控单元来对文本进行编码,然后编码生成的向量由信息过滤单元进行过滤,同时使用注意力机制更好的获取文本的向量表示;解码器使用单向的GRU(Gated Recurrent Unit)逐词的生成摘要,同时在其上加入指针生成网络来提高摘要生成的质量,减少重复。详细架构如图1所示。
1.1 双向GRU编码器
对于输入长度为n的文本,X=(x1,x2,…,xi,…,xn)作为编码器的输入,将源文本输入双向GRU中得到词的隐藏向量表示hi。
(1)
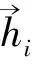
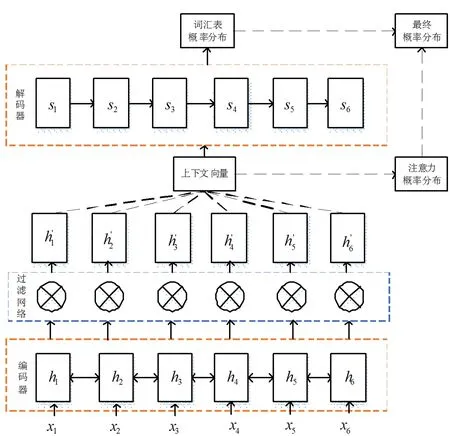
图1 IF-PGN模型图
1.2 信息过滤网络
文本摘要是一项特殊的自然语言生成任务,需要进行信息压缩。同时输入序列的许多词对生成摘要没有帮助,它需要去除源文本中不必要的信息,为了解决这个问题,本文在编码器解码器模型的基础上进行了扩展,在编码器之上添加一个信息过滤层,在摘要解码器生成摘要之前对源文本过滤。使用输入序列某个词的表示hi和句子表示s来计算出词的新向量表示hi′,如式(2)(3):
gi=σ(Wg[hi,s]+b)
(2)
hi=gi⊙hi′
(3)
其中Wg是权重矩阵,b表示偏移向量,gi是过滤网络阈值,gi的值越大表示词越关键,通过gi可以控制流向解码器的信息量。
1.3 带有注意力机制的解码器
在文本编码层和信息过滤层上使用单向GRU作为解码器用来逐词的生成摘要。GRU通过上下文向量ct,前一步的解码器隐藏状态st-1,前一步生成的词向量表示yt-1来生成当前步t的隐藏状态。
st=GRU(st-1,yt-1,ct)
(4)
上下文向量是通过注意力机制进行计算,将当前解码器状态st与每个编码器隐藏状态hi′进行匹配,得到一个重要性评分。然后将重要性分数标准化,通过加权和计算出当前上下文向量ct。
et,i=vTtanh(Whhi′+Wsst)
(5)
(6)
(7)
然后根据当前上下文向量ct和解码器状态st,在词汇表上使用softmax层预测下一个单词yt的概率。如式(8):
pvocab(yt)=softmax(Wv(Wc[st,ct]+bc)+bv)
(8)
其中Wv,Wc,bv,bc是可学习的参数。
1.4 指针网络
为了解决摘要生成中OOV词的问题,本模型在解码端加入了指针生成网络,指针网络的生成概率pgen如式(9):
(9)
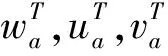
pcopy(yt)=∑i:xi=wαt,i
(10)
p(yt)=pgenpvocab(yt)+(1-pgen)pcopy(yt)
(11)
2 实 验
2.1 实验设置
本文使用在自动文本摘要任务中广泛使用的CNN/Ddily Mail[8]作为评测数据集。实验使用NVIDIA GeForce GTX1080Ti GPU进行,深度学习框架使用PyTorch[9]。
本文使用的词汇表大小为50000词,单词嵌入向量的维数是128,编码器和解码器的GRU隐藏单元维度256,解码器使用集束搜索beam search算法,束大小为5,batch_size(批尺寸)大小为64,编码器和解码器的GRU层数都为两层。
2.2 实验及结果
本文提出的模型生成的摘要如表1所示,所生成的摘要基本能包含原文重要信息且没有重复。同时本文选择以下模型与本文提出IF-PGN模型进行对比,评价标准使用ROUGE的F1值作为评价指标。

表1 生成摘要示例
words-1vt2k-temp-att[5]:用基本的seq2seq编解码器体系结构和注意机制来构建这个模型,这是其他许多工作的先驱。
PGNet[6]:在编码器解码器模型上进行了扩展,在解码端加入了指针网络。
ConvS2S[10]:创造性地利用卷积神经网络建立编码器解码器模型,实现了许多任务的高性能,包括抽象摘要。
RL+ML[11]:一种具有内注意力的神经网络模型,是一种新的抽象摘要训练方法。
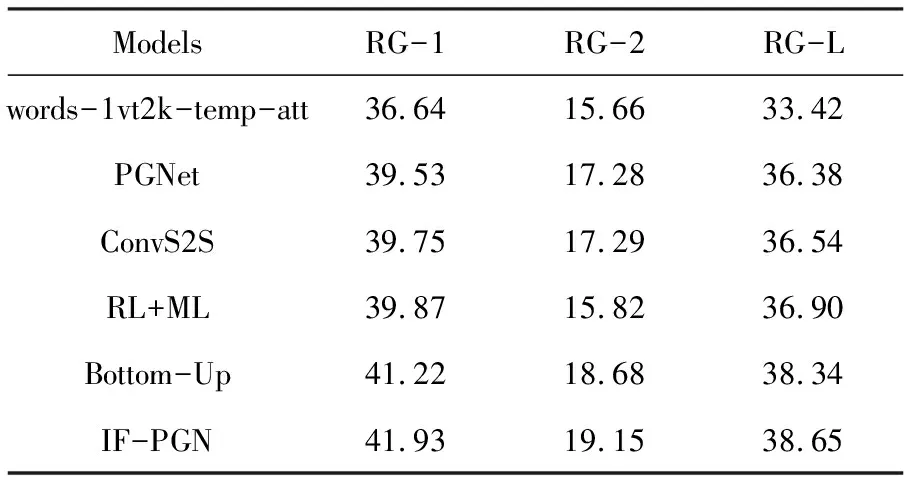
表2 对比实验结果
Bottom-Up[12]:一个由自底向上内容选择器扩展得来的序列到序列模型。
实验结果如表2所示,在CNN/Ddily Mail数据集上本文提出的IF-PGN模型较表现最好的Bottom-Up模型,RG-1,RG-2,RG-L指标分别提升0.71,0.47和0.31。
3 结 论
本文讨论了文本摘要过程中进行信息过滤的重要性,对信息过滤网络进行建模并且引入指针生成网络,对指针网络使用的注意分布进行优化,使指针网络能够更加准确捕获源文的重要信息。实验结果表明,本文提出的方法能够有效的生成信息丰富,且更加简洁的摘要。
