基于改进鸟群算法优化聚类的风电场等值建模
2021-01-15苏柯文张永明
苏柯文 张永明
(上海电机学院电气学院 上海 201306)
0 引 言
近年来风力发电技术发展迅猛,并网风电场的规模和数量也在不断增多。《2018全球风电研究报告》显示,截至2018年全球风电装机总容量已达592 GW,其中我国风电装机总容量已达221 GW。风能具有间歇性、随机性等特点,随着并网风电场的建设规模越来越大,风力发电场输出的不确定性及并网后各风力发电机间的相互影响对电网的影响问题越来越突出[1],因此对电力系统进行研究时,并网风电场的影响不容忽视。为减小计算规模,缩短仿真时间,对并网风电场进行建模时通常采用等值建模的方法。
风电场的等值建模目前主要有单机等值和多机等值两种方法,当风电场各风力发电机组型号相同,进入风速差异不大时,可以采用单机等值的方法。但是现实中每个风电场包含几十或者上百台风力发电机组,风力发电机组型号不尽相同,进入风速也有较大的差异,因此单机等值模型不再适用,此时需要使用多机等值法来对整个风力发电场进行等值。
在使用多台风力发电机对整个风力发电场进行等值之前,首先需要对风电场内的各风电机组进行分群聚类处理。在聚类方法的选取上,文献[2]提出基于分裂层次半监督谱聚类算法的风电场机群划分方法,但是这种方法容易导致聚类机群过多。文献[3]使用遗传算法对风电场进行机群划分,但是遗传算法迭代次数过多。文献[4]使用K-means算法对风电场进行机群聚合,但是此算法对K值的选取是最大的问题,而且聚类结果与初始聚类中心的选取有关,无法获得全局最优[5]。文献[6]结合粒子群算法,定义了一种不需要迭代的方法,对初始聚类中心优化。在聚类参数的选取上,文献[7]考虑了尾流效应、风速及风向的影响,但是考虑不够全面。文献[8]根据风电场中对风速-功率曲线的实测值对风电机组进行分群。为了使风力发电机组分群更加精确,也有学者充分研究了风速、滑移率、俯仰角和有功功率后,把它们作为分群指标[9-10],文献[11]对风力发电场进行戴维南等值建模,文献[12]就三种不同的风电场分布形式分别提出了等值建模方法。
本文针对K-means算法聚类中心选取困难的问题,提出一种基于改进自适应特性鸟群算法的K-means聚类方法。针对鸟群算法,首先通过利用混沌算法初始化种群,提高种群的多样性;其次通过引入惯性权重,对认知和社会系数的非线性调整来提高鸟类的本地和全局搜索能力;然后通过与K-means聚类算法相结合,寻找最佳聚类中心对风电机组进行聚类;最后在MATLAB/Simulink中进行仿真验证分析。
1 基于改进自适应特性鸟群的K-means聚类算法
1.1 基本鸟群算法
鸟群算法是2015年提出的一种生物启发式算法,源于鸟类觅食、警戒和自然界中的飞行行为。鸟群算法的目标是解决优化问题,以下是关于鸟群算法的一些理想化规则:
(1) 每只鸟可以在觅食行为和警戒行为中自由切换,其中鸟类觅食或保持警惕被建模为随机决策。
(2) 在觅食过程中,每只鸟都能及时记录和更新其先前的最佳觅食位置,同时会把这一信息分享给群体中的其他鸟类,然后记录下种群最佳觅食位置。
(3) 在警戒过程中,每只鸟都会有往种群中心移动的趋势,但是这一过程会受到其他鸟类的干扰,储备较高的鸟类比储备较低的鸟类更容易接近种群中心。
(4) 鸟类会定期飞往另一个地方。飞往另一个地方时,食物信息储量最高的鸟类是生产者,而储备量最低的鸟类则是掠夺者,其他保留在最高和最低储备之间的鸟将随机选择为生产者和掠夺者。
(5) 生产者积极寻找食物,掠夺者随机跟随一位生产者寻找食物。
鸟群的一系列行为可以理想化为以下数学模型:
(1) 觅食行为。每只鸟根据个人经验或者种群经验觅食,如果一个随机数均匀分布在(0,1)之间,那么这只鸟就会觅食,否则这只鸟仍然会保持警惕。
(1)
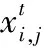
(2) 警戒行为。鸟类会试图移动到种群中心,它们将不可避免地发生竞争。它们的行为如下:
(2)
(3)
(4)
式中:k(k≠i)是正整数,且k
(3) 飞行行为。为了躲避天敌和觅食或者由于一些其他的原因,鸟群会从一个地方迁移到另一个地方,在新的地点鸟群会重新开始寻找食物。一些作为生产者的鸟类会开始觅食,另一些作为掠夺者的鸟类会跟随生产者寻找食物。根据规则(4),生产者和掠夺者可以从种群中分离,它们的行为模拟表示为:
(5)
(6)
式中:randn(0,1)表示高斯分布的随机数为0,标准差为1;k∈[1,N],且k≠i,FL∈[0,2]表示掠夺者跟随生产者寻找食物。假设飞行频率为FQ∈Z+,FQ的实际意义为鸟群算法中两种不同搜索算子的切换频率。
1.2 鸟群算法的改进
混沌优化初始化种群:鸟群算法以随机的方式生成初始种群,因此不能保证群体的多样性,从而影响算法的性能,所以可以采用混沌优化算法[13]来初始化种群。本文采用这种方法在搜索空间中均匀分布个体,提高鸟群算法的优化能力。
引入自适应惯性权重:惯性权重的概念最初由Shi和Eberhart提出,用于解决粒子爆炸问题,文献[14]提出了基于惯性权重W的线性递减粒子群优化算法,该算法对惯性权重的研究具有深远影响。
本文将惯性权重W加入到式(1)中,通过调整W的值来实现全局搜索和局部搜索之间的平衡,该方法可以加速收敛并提高算法的性能。
(7)
式中:Wmax=0.9;Wmin=0.4;t是当前迭代次数;tmax是最大迭代次数。
学习系数的非线性调整:鸟群算法中的C和S分别代表认知和社会加速系数,这种方法适应性地调整自己的认知和社会经验。C和S在觅食早期是相同的,这表明“个体”和“群体”对粒子搜索过程具有相同的影响。在觅食后期,C取一个较小的值,S取一个较大的值,这使得本地搜索能力加强。非线性调整学习系数的更新公式如下:
(8)
(9)
因此,改进的觅食公式为:
(10)
式(10)右边第一部分为第i只鸟的先前位置,用来保证算法的收敛性;第二部分为引起鸟类位置变化的认知因素;第三部分为引起鸟类位置变化的社会因素,使算法具有局部搜索能力。所以,惯性权重W起到了平衡全局搜索能力和局部搜索能力的作用,如果W较大,则有利于全局搜索,此时虽然收敛速度快,但是得不到精确解;如果W较小,则全局搜索能力弱,局部搜索能力强,此时得到的解更加精确,但是收敛速度慢,有时会陷入局部最优。
关于生产者位置增加干扰问题,式(6)是位置更新的公式,由于掠夺者只跟随生产者搜寻食物,一旦生产者陷入局部最优化,那么掠夺者也将陷入局部最优。为了解决这一问题,将干扰项增加到生产者的位置式(5)中,可以增强其获得全局最优的能力而有效地避免局部最优化。改进的生产者位置更新公式如下:
(11)
1.3 基于改进鸟群算法的K-means聚类
K-means聚类算法的目的是找到聚类中心,每个类别中所有对象之间的距离和最小。K-means算法依赖于聚类中心,容易达不到全局最优。因此,改进鸟群算法在本文中的目的是找到最优的聚类中心,从而实现最佳的聚类效果。设定分群聚类后每一类中所有数据到该类中聚类中心的距离和为目标函数:
(12)
式中:yi为第i类聚类中心;K为聚类数;xi,j为第i类对象;f为目标函数的适应值;d(xi,j,yi)表示xi,j和yi的全导数。
基于改进鸟群算法的K-means聚类算法步骤如下:
步骤1初始化每个参数,将N设置为总人口,设置a1、a2和FQ的初始值,定义鸟群搜索的空间维度为2。
步骤2设置外部循环的最大迭代次数为tmax。
步骤3设置变量i=1,进入内循环,并根据式(2)、式(9)、式(11)和式(6)更新觅食行为中鸟群的位置信息。
步骤4设t=t+1,确认当前迭代次数是否达到FQ。如果达到当前迭代次数,则这些鸟儿将会被分成两组:掠夺者和生产者,并且根据式(6)和式(11)分别更新鸟群位置;否则跳过式(6)处理,继续迭代。
步骤5达到最大迭代次数或者在多次迭代中未更新鸟的位置,则停止计算并获得最佳参考值。
步骤6步骤5获得的最佳聚类中心用作K-means的初始聚类中心,数据被分配为K类。
步骤7重新计算聚类中心直到不再变化,迭代结束然后输出聚类结果。
IBSA-K-means聚类算法流程如图1所示。

图1 IBSA-K-means聚类算法流程
2 风电场等值建模
2.1 聚类指标的选取
本文所用聚类方法把双馈风力发电机的12个状态变量作为风电机组的聚类指标,主要有风速v、转差率s、桨距角β、风电机转矩TM、机械转矩TT、电磁转矩Te、定子d轴电流Ids、定子q轴电流Iqs、转子d轴电流Idr、转子q轴电流Iqr、转子d轴电压Udr、转子q轴电压Uqr。以上参数在知道风力发电机的功率因数及运行曲线的情况下,通过获取风力发电机的进入风速可以很容易计算得到。
2.2 等值参数的计算
假设风力发电场分群后第K群中有n台双馈风力发电机组,把它们等值为一台风力发电机,则各部分参数计算如下:
(1) 发电机参数计算:
(13)
式中:S为风力发电机的容量;P为风力发电机组有功功率;Q为风力发电机组无功功率;Xm为励磁电抗;Rs为定子电阻;Rr为转子电阻;Xs为定子电抗;Xr为转子电抗;下标i为第i台风力发电机参数;下标eq为等值后的风力发电机组参数;下标req和seq分别表示等值后转子和定子参数。
(2) 轴系参数计算:
(14)
式中:H为惯性时间常数;K为轴系刚度系数;D为轴系阻尼系数;Di表示第i台风力发电机的阻尼系数。
(3) 集电系统参数计算:
(15)
式中:n为风电机组的总数量;Zi为第i台风电机组的线路阻抗;Pi为流过阻抗Zi的总功率;Zeq为等值后的阻抗。
(4) 等值模型误差分析。为了对风力发电场等值模型的误差进行分析,以风电场详细模型输出电气参数为标准,采用均方差定义风电场等值模型的有功功率和无功功率误差评价指标E为:
(16)
式中:z为详细模型输出电气参数;zi为等值模型输出电气参数;n为采样点数。
3 算例分析
针对本文所提等值建模方法的仿真验证,在MATLAB中搭建包含24台双馈风电机的风力发电场模型,其中每台风力发电机组的容量为1.5 MW,风电场系统连接方式如图2所示。每台风力发电机通过变压器升压至35 kV,风电场内每6台风电机组通过架空线路连接,然后汇入PCC处,通过35 kV/220 kV变电所与电网相连。
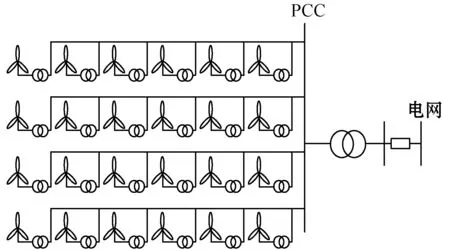
图2 风电场系统单线图
对本文所提12个状态变量使用基于改进自适应特性鸟群的K-means聚类算法对这12个状态变量进行聚类,把风电场中的24台风力发电机组分为4类,如表1所示,图3为等值后的风电场接线图。

表1 聚类结果

图3 等值风电场单线图
通过选择相同的聚类指标,把本文聚类算法与其他算法进行对比,如表2所示,所有算法设置最大迭代次数为500,本文中IBSA算法的参数设置为N=30,FQ=3,P=1。本文进行了50次独立实验,并进行记录,然后把各类算法的最大值、最小值、平均值、标准差和达优率进行对比,不同算法的对比结果如表2所示。图4和图5分别给出了K-means算法和IBSA-K-means算法聚类轮廓值,轮廓值是对聚类效果好坏的一种评价方式,轮廓值处于-1~1之间,值越大说明聚类效果越好。
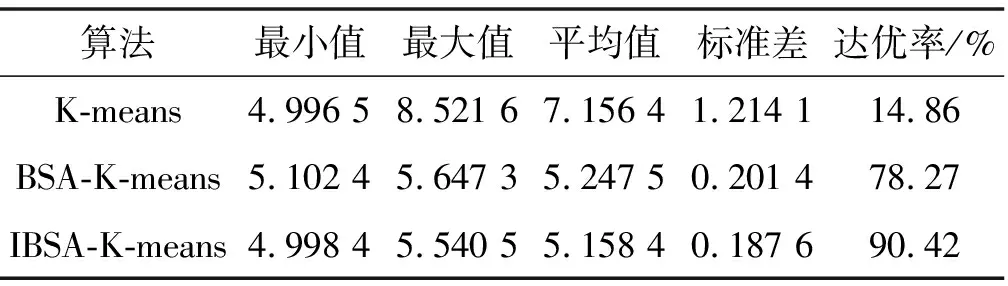
表2 不同算法实验结果对比

图4 K-means算法聚类轮廓值

图5 IBSA-K-means算法聚类轮廓值
由表2可以看出,K-means算法的收敛效应最差,BSA-K-means算法与K-means相比有较大的优势,可以满足很多领域的要求,而本文对鸟群算法改进后的IBSA-K-means算法与其他三种相比具有较大的优势,虽然收敛速度与K-means算法相比较慢,但是其稳定性和达优率都有较大的改观。从图4和图5中可以看出,IBSA-K-means算法聚类轮廓值都处于0.8以上,有些轮廓值已经很接近1,反观K-means算法聚类轮廓值参差不齐,有些轮廓值在0.1附近,显示出了聚类的不合理性,由此可见本文改进的IBSA-K-means聚类算法在实际应用中要优于传统的K-means算法。
为进一步证实本文所用聚类算法的优越性,在相同的聚类指标下,对比不同的聚类算法的优劣,分别在风速扰动和故障情况下从有功功率、无功功率两个方面来分析。
三种不同的聚合模型分别用于再现风速扰动和故障扰动下的风电场动态响应,三种不同的聚类算法PCC处有功功率和无功功率的动态响应对比如图6-图9所示。表3和表4为在风速扰动和故障扰动下基于不同聚类算法的等值模型通过式(16)方法计算的等值误差,从图6至图9、表3和表4中可以看出,与基于K-means聚类算法的等值模型相比,本文提出的基于改进BSA的K-means聚类算法的等值模型与详细模型的功率出力曲线相似度更高,误差更小,能准确地对双馈风力发电机进行分群处理,可以适用于大规模风力发电场的等值建模。

图6 风速扰动下有功功率的动态响应
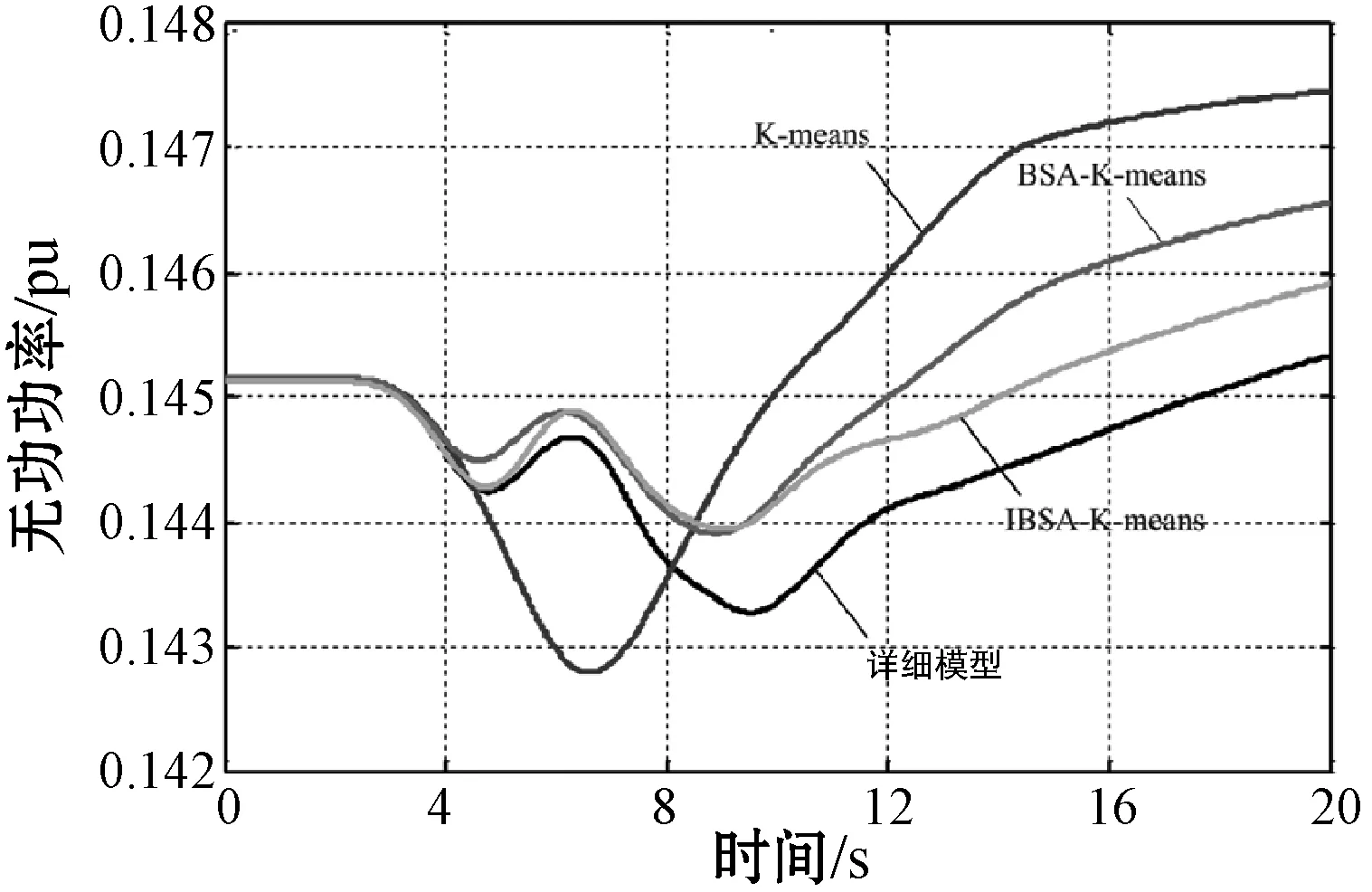
图7 风速扰动下无功功率的动态响应

图8 故障扰动下有功功率的动态响应

图9 故障扰动下无功功率的动态响应
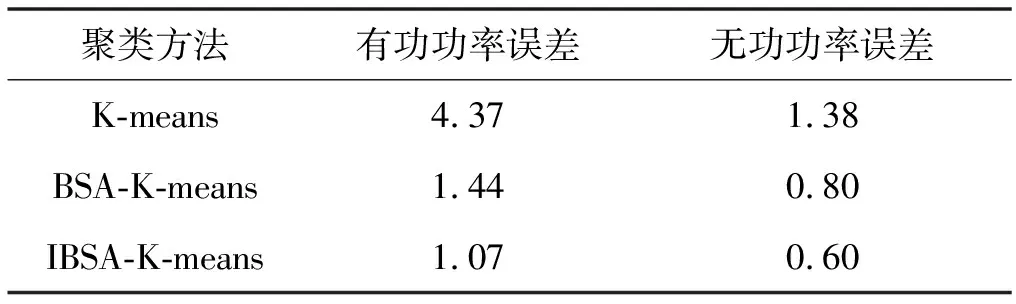
表3 风速扰动下等值模型误差 %

表4 故障扰动下等值模型误差 %
4 结 语
针对目前风力发电场聚类等值建模精度不高的情况,本文提出一种基于改进自适应特性鸟群的K-means聚类算法。该算法采用风力发电机组的12个状态变量作为分群指标对风电机组进行分群,然后分别对每个群组内的风力发电机进行等值。在相同的分群指标下,把仿真结果通过与传统聚类方法和详细模型对比,证实了本文方法的精确性。在扰动及故障情况下,都能很好地表征风力发电场的对外特性,为风力发电场的等值建模提供了一个很好的聚类方法。
