基于Anaconda的婴儿用品数据爬取及可视化分析
2021-01-14谢美英

摘 要:随着国家对二胎、三胎政策的全面放开,新生儿出生数量有所增长,对婴儿用品的数量和质量需求也发生着改变。本文主要研究婴儿用品的商品评论相关信息的爬取,对目标网站的网页进行分析,采集数据。获取数据后,采用Python语言中的Pandas、Numpy等库进行数据预处理。然后,使用Matplotlib、Nltk、Jieba库对数据分析,去除重复评论,去除停用词,词频统计后制作词云图等可视化数据结果,挖掘出大数据背后的隐含信息。
关键词:Anaconda;婴儿用品;数据采集;数据分析;数据可视化
中图分类号:TP391 文献标识码:A文章编号:2096-4706(2021)14-0090-04
Abstract: With the full liberalization of the national policy on the second and third children, the number of newborns has increased, and the demand for the quantity and quality of baby products has also changed. This paper mainly studies the crawling of information related to commodity reviews of baby products, analyzes the web pages of the target website, and collects data. After obtaining the data, the paper uses pandas, numpy and other libraries in Python language to preproces data. Then, uses Matplotlib, Nltk and Jieba libraries to analyze the data, removes repeated comments, removes stop words, makes word cloud and other visual data results after word frequency statistics, and mines the hidden information behind the big data.
Keywords: Anaconda; baby care; data acquisition; data analysis; data visualization
0 引 言
三胎政策的全面实行,在未来,将会有不少行业迎来爆发式的增长,而母婴行业受益显而易见。若一个家庭准备生养小孩,必不可少的是准备母婴用品。小到奶嘴尿布,大到孕妇食品和儿童家具,这一系列的消费将随着新生儿数量的增长而迎来井喷式的发展高峰。尤其在网络购物方面,反映商品体验感和观点的评论词汇,成为消费者了解商品及其质量的重要渠道。大数据、人工智能的发展则对婴儿用品词汇数据的处理带来了更多便利。
构建婴儿用品消费的词汇数据,并进行有效分析和可视化处理,是各个地区商家经营母婴用品,对商品的种类、材质、规格、销量等参数进行有效控制的手段。同时,也对研究人口出生政策起到侧面的支撑作用。
1 婴儿用品数据采集
1.1 准备环境
Anaconda是一个基于Python语言的数据处理和科学计算平台,已经内置了许多非常有用的第三方库,装上Anaconda,相当于把Python和一些如Numpy、Pandas、Scrip、Matplotlib 等常用的库自动安装好,比常規Python安装更容易。
首先,进入官网,点击下载对应安装包,下载完成后,按照提示步骤,逐一点击安装。选择安装其他地址的,可以单独新建一个文件夹来存放跟Anaconda相关数据,点击结束后安装完毕。然后,需要配置环境变量。找到安装Anaconda的路径,包含一个scripts文件,复制该路径,通过右键“我的电脑”,选择“属性”,高级系统设置,环境变量,点击环境变量,在系统变量中找到path,选中path,编辑好复制的路径,粘贴在分号后面,点击确定,保存后关闭就可以启动Anaconda。
1.2 数据采集
1.2.1 分析网站页面
爬取电商平台的婴儿用品数据之前,为更有效编写代码的逻辑,需要对该网站的域名结构和层次划分清楚。本文以淘宝网为例,进入首页,搜索输入“奶瓶”,进入展示页面,点击第一个产品,进入“comotomo可么多么原装进口硅胶奶瓶新生儿套装韩国官方正品”的销售页面,该页面包含了“累计评价”数据,其中,本次有效处理提取的数据是商品的评论内容、评论时间和商品分类类型。
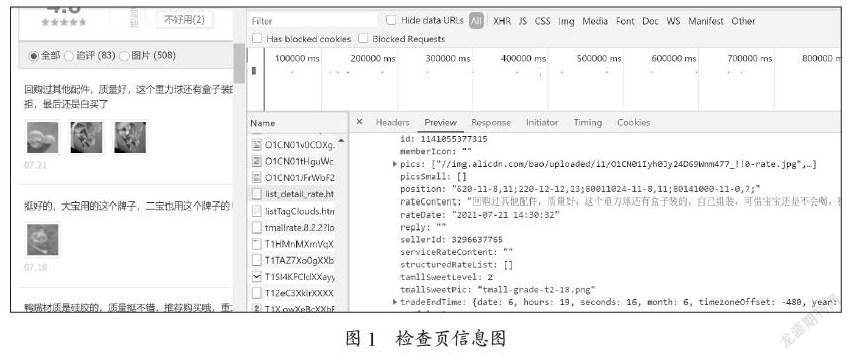
爬取数据前,登录淘宝网,查看可么多么原装进口硅胶奶瓶的评论,建议选择谷歌浏览器,选择开发者工具或者按快捷键F12,找到Network选项,打开源代码页查找,发现源代码页没有任何关于商品评论的信息,再去检查页进行查找,查找以“list_detail_rate.htm?”开头的文件,在检查页的json数据里找到,然后需要向这些数据发送请求。该页面的检查页信息和评论信息如图1所示。
1.2.2 编写代码爬取数据
(1)导入需要用到的包,代码如以下所示:
import requests # 导入第三方模块requests库
import csv
import re # 导入正则表达式库
import numpy as np # 导入科学计算库
import pandas as pd # 導入数据分析库
import time
import random
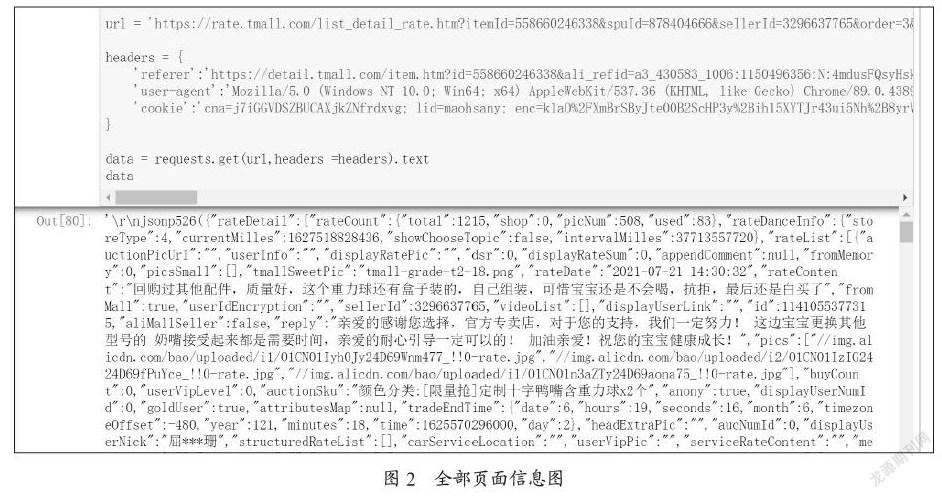
(2)根据上面的网页结构分析,找到真正的需要爬取的页面URL和Headers头部信息,包括referer、user-agent和cookie。评论页面的地址很长,但是可以分析出规律,比如其中itemId是商品id,sellerid是卖家id,currentPage是页面号,reply是评论回复等等。编写的代码以及运行结果是全部的页面信息,如图2所示。
(3)利用正则表达式对全部页面信息进行提取,得到该款婴儿用品的评论内容、评论时间和产品类型。多观察分析几个URL后,发现只有currentPage部分不同,表示评论页码。因为全部评论内容包含59页多,需要用到循环结构实现。循环之前,先定义3个初始为空的列表,分别表示评论内容、评论时间和商品类型。编写的关键代码为:
for i in range(1,60):
url2 = ‘https://rate.tmall.com/list_detail_rate.htm?itemId=558660246338&spuId=878404666&sellerId=3296637765&order=3¤tPage=’+str(i)+’&append=0&content=1…’(说明:该url很长,此处省略了后面一部分。)
time.sleep(random.randint(3,9))
data = requests.get(url2,headers = headers).text
pat_content = re.compile(‘”rateContent”:”(.*?)”,”fromMall”’)
pat_time = re.compile(‘”rateDate”:”(.*?)”,”rateContent”’)
pat_type = re.compile(‘”auctionSku”:”(.*?)”,”anony”’)
content.extend(pat_content.findall(data))
content_time.extend(pat_time.findall(data))
type.extend(pat_type.findall(data))
data
dict = {
'评论':content,
'时间':content_time,
'类型':type
}
new_frame = pd.DataFrame(dict)
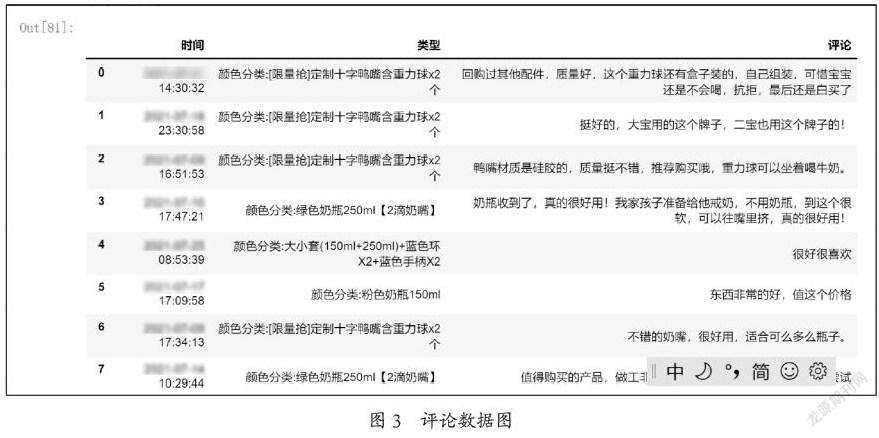
运行结果得到需要的评论数据,如图3所示。
(4)存储数据到csv文件,得到“婴儿用品评论信息.csv”。Python提供了多种格式的数据存储形式,由于本实验数据量不大,选择了csv文件格式。以可么多么原装进口硅胶奶瓶为对象商品评论表,包含1210条原始评论数据。
2 婴儿用品数据预处理
(1)导入相关包和婴儿用品评论信息文件内容:
import nltk # 导入自然语言工具包
import nltk.book
file_path = open(‘D:/Python/婴儿用品评论信息.csv’)
file_data = pd.read_csv(file_path)
(2)原始评论数据中有些是重复的,比如“此用户没有填写评论!”,需要进行去重复处理。去掉重复评论剩余1086条数据。去除重复评论代码为:
file_data = file_data.drop_duplicates()
(3)为了方便后期分别对评论内容进行词频统计,对商品的类型评论条数进行展示,将文档分解成评论内容和产品类型两个csv文件。
3 婴儿用品数据分析及可视化
(1)对文本内容的评论分析需要导入Python中的自然语言工具包ntlk,利用jieba库进行中文分词。导入代码为:
import jieba#导入jieba库
from nltk.book import *
cut_words = jieba.lcut(str(file_data[‘评论’].values),cut_all=False)
(2)加载停用词列表,对中文分词去除停用词,比如评论中的“你”“他”“的”“地”“得”等词语,删除停用词后,从输出的结果中可以大致看出评价的特征信息,不过后期还需要统计词语出现的次数,才能进一步知晓用户对该款婴儿用品的喜恶。部分代码为:
with open(‘D:/Python/停用词表.txt’,encoding=’ utf-8’) as f:
stop_words = f.read()
new_data = []
for word in cut_words:
if word not in stop_words:
new_data.append(word)
(3)词频统计和产品分类评价统计。部分代码如下:
import matplotlib.pyplot as plt # 导入模块
import numpy as np
%matplotlib inline
%config InlineBackend.figure_format = ‘svg’
freq_list = FreqDist(new_data)
most_common_words = freq_list.most_common()
most_common_words
plt.figure(“分类统计”,figsize=(10,7))
plt.rcParams[‘font.sans-serif’] = [‘SimHei’]
plt.rcParams[‘axes.unicode_minus’] = False
new_x = np.linspace(0,9,12)
plt.xticks(new_x)
plt.ylim(0,30)
movie_name = [‘十字嘴’,’丫字嘴’,’粉色’,’蓝色’,’250ml+150ml大小套’,’250ml’,’150ml’,’含重力球’,’不含重力球’]
y = [11.92,12.97,13.42,12.07,3.45,19.96,1.48,20.14,4.58]
plt.xticks(range(0,9),movie_name,)
plt.xticks(rotation=45)
index = np.arange(9)
plt.bar(index,y,0.5,color=[“r”,”g”,”b”],align=”center”)
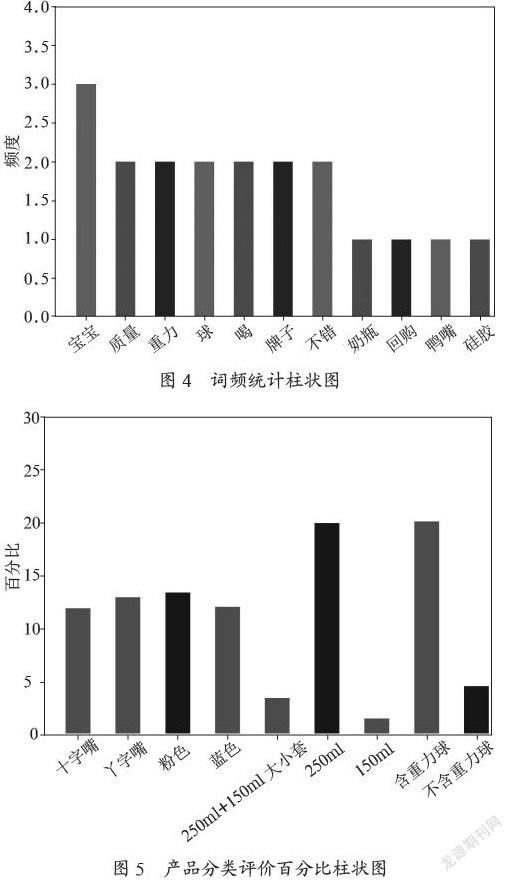
通过调用nltk库中的FreqDist类,对评论内容中每个词语出现的次数进行词频统计,再把主要词语的次数以柱状图展示出来。同时,对评论数据中类型字段进行分类统计,如十字嘴和丫字嘴的类型评论次数相差不大,但是,有重力球和不含重力球、250 ml和150 ml的商品類型评论次数相差明显。词频统计柱状图和商品分类评价百分比柱状图如图4、图5所示。
(4)制作词云图。根据上一步中用户评价的特征信息,使用wordcloud模块进行词云展示。将出现频率高的评价词汇进行放大显示,频率较低的词语缩小显示。代码为:
from wordcloud import WordCloud
from matplotlib import pyplot as plt
wc=WordCloud(font_path=’D:/simhei.ttf’,background_color=’white’,width=1000,height = 800).generate(“ “.join(new_data))
plt.imshow(wc)
plt.axis(“off”)
plt.show()
从词云图中可以直观地看出,“宝宝”“质量”“喝”“牌子”和“不错”等词语最为突出,表明用户对该款婴儿用品的质量和品牌总体感觉不错,以宝宝是否爱喝作为重要的评判点。运行得到的词云图如图6所示。
4 结 论
首先,通过本文研究发现:该款婴儿用品销售量,在不同的产品参数方面有所不同,用户对宝宝是否爱喝、商品质量、是否有重力球和品牌等方面有较强的体验感。合理运用Python在Anaconda环境下的科学计算库、文本分析库以及数据可视化等库,可以高效便捷地完成简单数据的采集,并且对原始数据进行预处理和可视化展示,对婴儿用品商家提供销售数据支持,也从侧面反映二胎、三胎政策影响下的婴儿用品需求变化。
然后,为了完善婴儿用品词汇资源库,后续研究尚需要对其他商品的评论数据进行补充,对评论内容的文本情感分析和相似度分析进行思考和探索。
参考文献:
[1] 吕云翔,李伊琳,王肇一,等.Python数据分析实战 [M].北京:清华大学出版社,2018.
[2] 陈红波,刘顺祥.数据分析从入门到进阶 [M].北京:机械工业出版社,2019.
[3] 李培.基于Python的网络爬虫与反爬虫技术研究 [J].计算机与数字工程,2019,47(6):1415-1420+1496.
[4] 章蓬伟,贾钰峰,邵小青,等.基于文本情感分析的电商产品评论数据研究 [J].微处理机,2020,41(6):58-62.
[5] 聂晶.Python在大数据挖掘和分析中的应用优势 [J].广西民族大学学报(自然科学版),2018,24(1):76-79.
[6] 郑晶晶.融入Python应用的学生考勤数据管理分析 [J].数字技术与应用,2021,39(2):83-84+89.
[7] 郝海妍,潘萍.Python技术在数据分析中的应用 [J].电子技术与软件工程,2020(12):179-181.
作者简介:谢美英(1984—),女,汉族,湖南涟源人,讲师,硕士研究生,研究方向:软件技术、数据挖掘。
