基于TransReID的智能寻人系统的应用
2021-01-14庞遵毅李丹
庞遵毅 李丹
摘 要:一般人流量密度大的场所容易发生行人走失的情况,如:车站、游乐园、广场。针对此类人流量大的密集场所中发生的行人走失情况,提出一种基于TransReID的智能寻人系统,结合跨镜技术在场所内对行人目标进行检测搜寻。TransReID在Transformer的基础上做了网络结构层的改进,提高了鲁棒特征提取效率。对比CNN网络结构有了很大的提升,TransReID在对行人目标重识别上也有着更好的综合性能。
关键词:目标检测;重识别;行人;TransReID
中图分类号:TP391.4 文献标识码:A文章编号:2096-4706(2021)14-0083-03
Abstract: Lost pedestrians are easy to happen in places with high pedestrian flow density, such as: station, amusement and square. In view of the lost pedestrians situation in such places with high pedestrian flow density, the intelligent human search system based on TransReID is proposed, it combined the cross-mirror technology to search pedestrians targets in the sites. TransReID has improved the network structure layer and the robust feature extraction efficiency on the basis of Transformer. Compared with CNN, the network structure has been greatly improved, TransReID also has better comprehensive performance in re-recognition of pedestrian targets.
Keywords: target detection; re-indentification; pedestrians; TransReID
0 引 言
隨着近年来人工智能的异军突起,AI技术在计算机行业快速发展,以前在科幻电影中才能见到的目标检测技术,现在也已经广泛应用在人们的日常生活之中。目标检测中非常重要的一环应用就是目标重识别的应用,而行人目标重识别也是目标重识别研究较多的领域。
目标重识别技术一直以来都被CNN神经网络方法所主导,CNN神经网络方法在目标重识别领域已经取得了巨大的成功,但依然有方法实现上的不足。CNN神经网络方法在处理目标图像时,由于一次只能处理一个局部领域,并且还会受到卷积和降采样操作在细节上造成信息损失的影响,TransReID方法由此被提出,成为实现更高精度和更高效率的目标重识别方法,这也是首个基于纯Transformer技术的目标重识别方法,也是Transformer方法在目标重识别领域上的首次应用。
TransReID将ViT应用到目标重识别任务上,并且以ViT为骨干构建了一个强大的基线ViT-BOT,其在目标重识别的几个基准上,其结果完全可以与CNN神经网络的框架相比。除此之外,因为考虑到ReID数据的特殊性,TransReID网络结构还设计了两个用于数据处理的模块,分别是JPM和SIE模块。JPM模块提高了网络的识别能力和更多样化的覆盖,SIE则是处理图像的非视觉信息以此减少特征对摄像机或者视图的偏差。以此设计的TransReID架构在实验结果上,在对行人目标重识别上,其性能对比CNN神经网络有显著的提升,这也是在行人目标重识别任务上一次突破性的探索,打破了一直被CNN神经网络架构所主导的局面。
1 TransReID概述
TransReID网络架构是由阿里巴巴与浙江大学在Transformer与ReID上的一次突破性探索,也将ReID提升到了新的高度。在自然语言处理领域,为了处理序列数据提出了Transformer模型,许多研究显示了它在计算机视觉中的有效性。Transfomer模型最初用于处理由CNN模型为视频提取的序列特征。有研究者使用一种Transformer架构的变体来聚合视频中与特定人物相关的上下文线索[1]。目前Pure Transformer模型越来越受欢迎,ViT是最近提出的一种将Pure Transformer直接应用于图像序列配准的方法。然而,ViT需要一个大规模的数据集来进行预训练。为了克服这一缺点,Touvron等人进行了一系列的研究并提出了一个名为DeiT的框架,该框架引入了一种针对Transformer的teacher-student策略,以加速ViT训练,而不需要大规模的预训练数据。而TransReID则是将ViT做了一些调整过后扩展到ReID任务中,并证明了它的有效性。尽管ViT-BOT在ReID任务中可以实现比较好的性能,但是为了利用ReID数据中的特性,更好地挖掘side信息和fine-grained部分,TransReID的整体网络结构中还加入了JPM和SIE模块,以此来实现更高的ReID准确率。
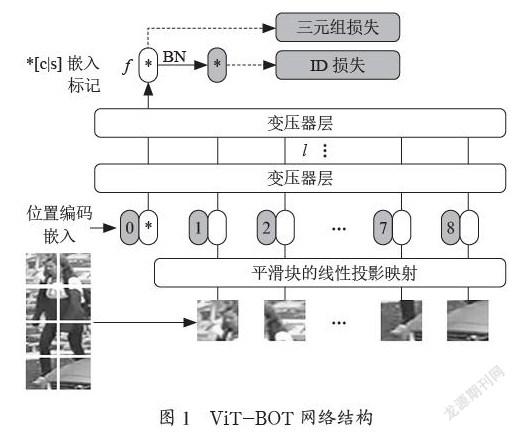
1.1 ViT-BOT
ViT-BOT的网络结构如图1所示,其遵循一般的强管道对象ReID,并且做了一定程度上的调整[2]。第一步作为预处理步骤,ViT将图像分割成N个不重叠的块,但是这就会导致块的局部近邻结构信息无法较好的保持;相反,如果采用滑动窗口形式生成重叠块,假设滑动窗口的步长为S像素,每个块的尺寸P=16,那么重叠部分的形状为(P-S)× P。如果输入图像的尺寸为H×W,那么所得到的图像块数量将如公式所示:。从公式可以看出,重叠区域越大,所提图像块数量越多,能带来更好的性能,但同时也会增加计算量。第二步进行位置信息的编码,利用ρi对第i个块的位置信息进行编码,它有助于Transformer的编码器编码空间信息,在对位置进行编码的同时,引入双线性插值,以帮助ViT-BOT处理任何给定的输入和大小形状[3]。第三步进行特征的学习,将图像分割成一系列的块,再将一个可学习的特征嵌入到上述块中,最后一个编码层的类标志作为图像的全局特征表示,假设最终的类标志表示为F,其他输出表示为P0={P1,P2,…PN},则其损失函数可表示为:LT=log[1=exp(‖Fa-Fp‖22-‖Fa-Fn‖22)]。
1.1.1 TransReID框架
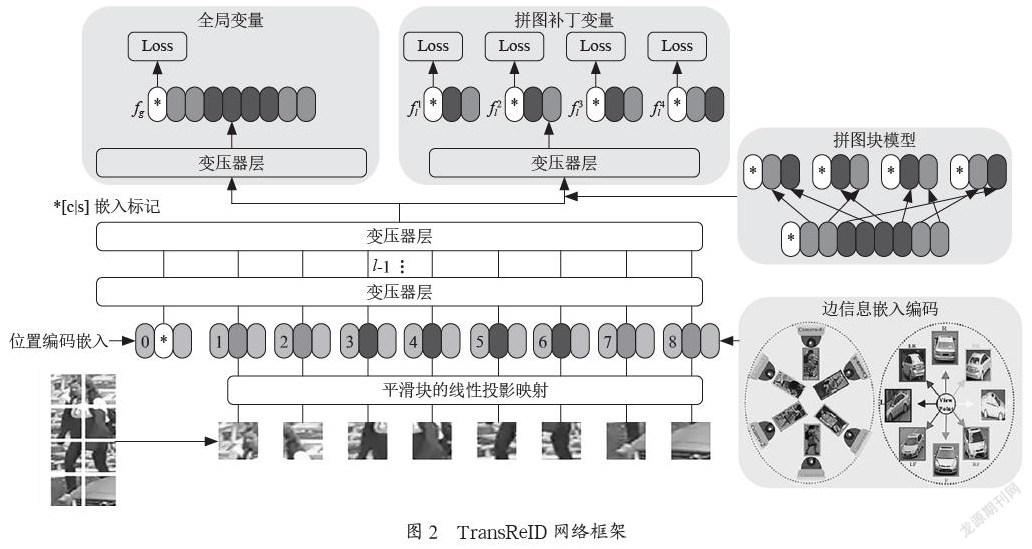
尽管上述ViT-BOT网络结构可以在ReID任务上取得较好的结果,但是它并未充分利用ReID数据的特性,所以提出将SIE和JPM模块融合到ViT-BOT网络结构之中,构成了最终的TransReID框架,其结构图如图2所示。
1.1.2 SIE模块
在目标重识别领域,一个极具挑战的问题就是:不同相机、视觉及其他因素导致的视觉偏差。Transformer则非常善于融合这类边界信息,因为类似于位置嵌入,它可以采用可学习层来编码这些边界信息。具体来说,如果一幅图像的摄像头记为C,则其摄像头Embedding可以记为S(C)。不同于Position Embedding在各patch之间的变化,摄像机EmbeddingS(C)对于一幅图像的所有patch都是相同的。另外,如果物体的视点是可用的,無论是通过视点估计算法还是人工标注,都可以将视点标签V编码为S(V),然后用于图像的所有patch。将摄像头ID和视角标签同时编码为S(C,V)。也就是说对于CN个摄像机IDs和VN个视角标签,S(C,V)总共有CN×VN个不同的值。最后,第i个patch的输入Embedding将遵循公式Ei=F(pi)+pi+λS(C,V)。
1.1.3 JPM模块
由于将强基线ViT-BOT的最后一层调整为并行分支结构,采用两个独立的Transformer层学习局部特征和全局特征[4]。假设倒数第二层的输出为:Zl-1=[Z0l-1,…Z1l-1,Z2l-1…ZNl-1]。局分支采用标准的transformer,得到Zl=[fg,…Z11,Z21…ZN1]。token embedding往往取决于其靠近的token,因此一组相近的patch进行embedding会把信息局限在有限的区域。JPM模块,其本质是随机分组,具体为:把前m个patch挪到后面,再进行patch打乱划分。这里的k组patch会输入到同一个transformer结构中,分别提取出一个局部特征。(并不是把一组的patch级联,形成k个大patch,输入一次transformer;而是每组输入一次transformer。)由此得到局部特征{f1l,f2l,…fkl}。。最后的损失函数计算为:L=LID(fg)+LT(fg)+∑(LID(fil)+LT(fil))。最后将全局特征和局部特征级联,得到最终的特征表示。
2 实验及结果
2.1 数据集
本文使用的原始数据集是Market-1501数据集,它包含了1 501个行人对象,由6个不同的摄像头捕捉,每个行人对象在每个视点平均有3.6张图像。其中750个行人对象用于训练集,751个行人对象用于测试集。
2.2 模型训练
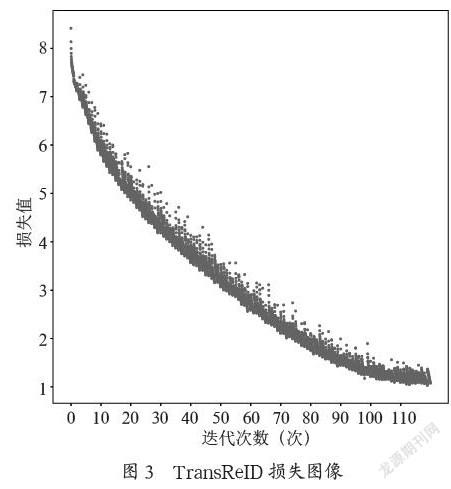
本文算法基于Cglab平台实施,迭代次数为120,GPU为TeslaT4。在训练模型时,将所有图片大小调整为256×256。训练图像通过随机水平翻转、填充、随机裁剪、随机擦除进行图像增强。Batch=8,采用SGD优化算法,动量为0.9,权值衰减为1e-4。学习率初始化为0.008。如图3所示。
3 智能寻人系统
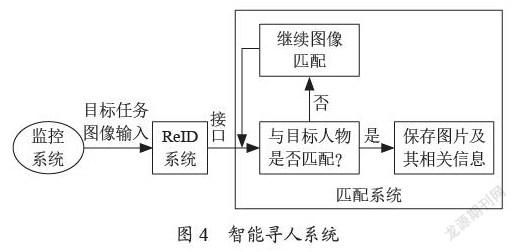
随着科技的发展,电子设备通信成为人与人沟通的主要方式,但如果脱离了电子设备,尤其是在一些人口密集的场所,单纯依靠人力寻找目标如同大海捞针[5]。现在的科技寻人方式,基本还停留在依靠人力去查阅监控视频、寻找行人轨迹的方式,进而再组织寻找,这样的方式需要耗费大量人力,但是ReID技术就能很好地应用并解决这一问题,只需要输入一张目标人物的照片进入ReID的系统,实时地在场所内所有监控摄像头寻找目标任务,通过ReID的跨镜技术,实现区域内监控设备的多镜结合查找,并且ReID技术在针对目标图像不同姿态、不同角度、不同分辨率时,通过多粒度网络结构与边信息融合处理,结果上都有很好地识别效果,进一步提升人脸识别的精准度,尤其是在针对视频质量低、部分遮挡等复杂场景时,通过视频连续帧的处理,延长行人在摄像头连续跟踪的时空延续性,可以快速反应并且找到目标的最近落脚点,实现真正的监控技术智能化,结合现在城市发达的监控网络,就能高效实现在人口密集场所寻人的功能。图4所示。
4 结 论
本文所实现的是利用监控网络,在人口密集场所利用ReID的跨摄像头技术进行寻人的功能,从而帮助人们在走失时能够快速团聚。TransReID以Transformer技术为基础,通过构建其ViT-BOT强基线与其SIE和JPM模块的结合,在ReID性能上对比CNN网络有着更高效率的表现,并且通过其对图像边信息的处理,能够进一步降低不同相机的视点引起的负面偏差,弥补CNN网络在这方面的不足,在ReID几个主流基准上达到更高的准确率。将其应用于智能寻人系统,只要在监控网络覆盖范围内,都必将实现更高的查找效率,对于日后社会的和谐,民生的安康都有着非常巨大的帮助。
参考文献:
[1] BEAL J,KIM E,TZENG E,et al. Toward Transformer-Based Object Detection [J/OL].arXiv:2012.09958 [cs.CV].(2020-12-17).https://arxiv.org/abs/2012.09958v1.
[2] HE S T,LUO H,WANG P C,et al. TransReID:Transformer-based Object Re-Identification [J/OL].arXiv:2102.04378 [cs.CV].(2021-02-08). https://arxiv.org/abs/2102.04378v1.
[3] MENG D C,LI L,LIU X J,et al. Parsing-Based View-Aware Embedding Network for Vehicle Re-Identification [C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition(CVPR),Seattle:IEEE,2020:7101-7110.
[4] LUO H,GU Y Z,LIAO X Y,et al. Bag of tricks and a strong baseline for deep person re-identifification [J/OL].arXiv:1903.07071 [cs.CV].(2019-05-19).https://arxiv.org/abs/1903.07071v3.
[5] 郝翠翠.基于人脸识别的寻人系统设计与实现 [D].大连:大连理工大学,2015.
作者简介:庞遵毅(2000.02—),男,汉族,四川内江人,本科在读,研究方向:人工智能。
