面向序贯决策中异常情景下交互问题处理方法
2021-01-14安敬民李冠宇张冬青
安敬民,李冠宇,张冬青,蒋 伟
(1.大连东软信息学院 计算机与软件学院,辽宁 大连 116023;2.大连海事大学 网络信息中心,辽宁 大连 116026)
0 引言
近年来,随着智能决策和服务推荐的兴起,对多智能体系统(Multi-Agent System, MAS)决策技术的研究成为了人工智能领域的热点和重点问题[1],但因MAS难以解决的维数灾难的问题,使其发展遭遇到了瓶颈。目前,基于个体控制的智能体群集决策求解方法[2]是缓解多智能体决策求解维度过高问题的主要策略,其以机器学习(Machine Learning, ML)作为解决MAS序贯决策的主要方法,并已得到了国内外众多学者的应用。具有代表性的从单智能体的角度研究多智能体交互决策问题的相关研究主要包括基于分散式部分可观测的Markov逻辑网络决策处理方法(Decentralized Partially Observable Markov Decision Process, DEC-POMDP)[3-5]和交互式动态影响图[6-9](Interactive Dynamic Impact Diagram, I-DID)两种方法。Seo等[4]和Grady等[5]提出分散式部分可观测Markov决策过程,将基于Markov逻辑推理的单智能体部分可观测决策扩展到MAS当中,提高了智能体的决策能力,同时由于其全局建模的方式导致存在求解困难的问题;文献[2]提出了基于个体控制的多Agent决策,国内李波等[6]提出I-DID模型精确解法基于BE(behaviorally equivalent)的精确最小模型集合法;文献[7-11]就I-DID的建模和求解提出其近似解法(区别模型更新算法(Discrimative Model Update,DMU)和ε-BE-I);Wu等[12]则利用信息论中的交互信息理论(information-theoretic method—mutual information)提出一种I-DID求解方式MPMI(model pruning using mutual information),通过模型间交互的信息衡量其相关度,并删除弱关系的候选模型,进一步压缩了模型空间和消耗时间,BE、DMU、-BE-I以及MPMI在保证决策效果的同时,降低了计算复杂度(降低了维数),且MPMI具有更高的求解效率。在此基础之上,潘颖慧[13]提出了最优K模型算法,随着K值增大效果更接近精确的DMU方法,为求解I-DID问题提供了一个新思路。
而在序贯决策求解方法的应用方面,由于各方法的优势不同,应用领域也各有不同。具有代表性的有:国内的张晓迎等[14]和刘海涛等[15]分别将DEC-POPMDP用于网络频谱接入和经典的老虎问题。相应地,国外的Marecki[16]和Velagapudi[17]则对MAS中部分智能体间的通信和协作进行功能优化,以提高DEC-POPMDP的决策能力,但该方法更多依赖于主观因素,很难拓展到更多的应用领域。能源分配优化[18]等多智能体合作协同任务[19]领域问题大多采用Jennings方法。曾一锋等[10-11]则考虑到在多智能体交互过程中合作与竞争共存,将提出的I-DID建模和求解策略应用于机器人和无人机追踪等问题,证实了在处理动态决策方面的问题具有一定优势;而潘颖慧[13]则在对攻游戏领域验证了I-DID模型的有效性。
以上方法在序贯决策计算求解方面均具有突破性的进展,但都是从不确定的环境或者情景(context)角度看待问题和解决问题的,而在处理异常情景(perturbation context)下多Agent的交互决策问题时,仍显不足。主要原因是在传统的序贯决策中,Agent交互的实现是基于Agent(或实体)间(推理)关系的(静态)属性或外在影响因素的剖析,且只以机器学习为主要手段进行研究,并不断完善推理规则,提高在不确定情景下交互决策的准确性。未考虑Agent(或实体)本身具备的(动态的)属性给关系推理所带来的影响;同时在应用实现方面未拓展到有关现实生活或者工作的智能家居领域。本文针对该问题提出一种全新的方法:
(1)以语义推理与机器学习相结合的方式对异常情景进行监测。基于改进的情景本体,实现Agent对所观察的实体物(O)的位置变化的计算分析,推理获取该实体物O此刻的“时—空”维度上下文。
(2)结合元认知环,实现智能体Agent的自省与反馈功能。利用当前实体物O的“时—空”上下文与规则中某一时刻的上下文进行对比与语义推理,以判断当前情景是否发生异常情况,并给出Agent在序贯决策中的下一决策。
最后,将该方法分别融合到上文提及到的DMU、ε-BE-I、最优K模型(Top-K)以及MPMI几种决策处理方法中,在模拟的智能家居环境下实现,取得了较好的实验效果。优化了I-DID求解方法,实现了应用领域的拓展,体现了本文方法的价值所在。
1 异常情景的监督
解决多Agent的序贯决策问题主要基于机器学习方法,通过概率的计算生成推理规则模型。但情景中具有复杂和多变的特点,Agent在执行交互动作的过程中,难免会遇到一些先前无法预知的情况,是偶然事件(accident),且在已有的规则库中没有对应的处理策略,本文称这种情况为异常情景,本文主要讨论如下两方面内容:
(1)某一固定规则事件(E)在其规则发生时间范围外发生(例如:规则库中某事件E通常发生在上午的某个时段,但偶然间在深夜某个时间点触发了该事件E)。如定义1所示。
定义1关于Oi的固定规则事件E(Oi)∈Rules(Oi),若有某被触发时间不在规则时间内t(E(Oi))∉T(E(Oi)),T(E(Oi))⊂Rules(Oi),则为Oi触发时间异常。
(2)某一被监测物体O发生位移,与规则中记录的位置有较大偏差(例如:包含在某规则事件E中的O在某次事件触发时,其位置与原位置状态不同)。如定义2所示。
定义2关于Oi的固定规则事件E(Oi)∈Rules(Oi),若有Oi发生位移,即l(E(Oi))∉L(E(Oi)),L(E(Oi))⊂Rules(Oi),则为Oi位置状态异常。
如上述两种异常情况均发生在已训练规则之外,而传统的机器学习机制是严格按照规则进行决策[1,4,10-11],无法对此异常情景进行有效的处理。本文引入本体语义技术,提出了改进的情景本体,实现对情景中被观察实体的“时—空”状态的监督与检测,以实现对异常情景的判断。
1.1 改进的情景本体
本文设计的情景本体(C-Onto)主要结合传感器的感知,从以时序(T)上传的上下文(Ctx)中计算获得实体物O的位置(L)信息,并采用与O所对应的智能体Agent(A)判断当前O是否处于异常情景中,执行符合情景的动作。因此,本文给出C-Onto形式化五元组:C-Onto=(O,A,T,L,SRT)。其中:T指TimeInterval,包括StartTime和EndTime两个时间点;SRT指Spatial Relation,即不同的O在T时间的L间关系。
改进的情景本体机理图如图1所示,本体分为3层结构,从上至下依次为Agent或Multi-Agent决策层、被观察的Object组成的物理层,以及对于情景的检测和监督的异常情景判断层。如引言部分介绍,本文重点研究异常情景的监测和判断,并将其应用于Agent或Multi-Agent的决策过程中,以补充现有研究的不足。

1.2 情景本体工作机理
本文以观察Object的“时—空”状态为主,因此被观察体Oi应具备动态属性Temporal Context和Spatial Context以及本体赋予其的可计算属性Mathematical Context(本文未列出Oi本身具备的物理属性)。通过传感器感知规则事件E的触发情况以及触发时间TimeInterval,并将事件序列发生过程中产生的Ctx数据分别用于定位当前Oi的位置和通过基于语义分析的旋转矩阵RotationMatrix[20]计算发生事件E(A交互)的位置关系SRT(如:Oi在Ok的上、下或内部等),且实现二者的语义表示。其中,Ei=Acti(Ctxi)=Ctxi+1,即Ctxi→Acti→Ctxi+1。Ctxi=Objecti·State=Val(Oi,Li,Ti),A=(O,Act)。Acti表示在事件Ei中Agent或者实体执行的动作。
1.3 “时—空”关系的语义表示及推理
上下文Ctx中的数据信息在本体中以资源描述框架(Resource Description Framework, RDF)的形式进行知识表示。本文提出的本体主要是将传感器感知的Ctx通过本体语义解析得到Oi在同一规则事件序列的活动时间(点)和其所在的位置以及与Oj的位置关系。
传感器感知Oi在事件Event中被触发,可表示为rdf(“Oi”,“SensorPerceving”,“Event”)(①);传感器感知被触发的位置L,可表示为rdf(“Locationi”,“SensorPerceving”,“Oi”)(②);传感器感知Oi在事件Event中被触发的时间T,可表示为rdf(“StartTime”,“SensorPerceving”,“TimeInterval”)(③)。
结合①和②及③,多个实体物O被触发或交互的事件Event发生位置L间的关系表示为rdf(“SRT”,“SensorPerceving”,“RotationMatrix”)(④)。
以第1章中的异常情景定义给出如下实例:
(1)规则事件中Oi被触发时间异常 事件E中的Oi被触发时间点不在已有规则内(生成规则关于被触发的Oi的Ctx中的时间要素用Pre_StartPerceving和Pre_TimeInterval表示),具体监测机理如图2和算法1所示。

算法1触发时间的监测与语义匹配算法。
输入:Ctx;
输出:触发时间匹配结果the Matching of Triggered Timepoint(MoTTp)。
1.Begin
2.while true do
3.For对于Ctxi∈Eq do
将上下文生成RDF描述的本体语言:
RDFi←Ctxiin C-Onto
4.抽取出RDF中的时间属性T:StartTimeiRDFi
5.If 规则库不空
For (j=1;j≤n;j++)
Return(Complete Matching)
Else Return(Incomplete Matching)
Else Break;
6.End
算法1主要通过1.1节和1.2节提出的情景本体C-Onto将给定的上下文Ctx等价转换为本体描述语言RDF三元组,进而抽取出其触发事件的时间属性。结合式(1)判断触发时间与习惯性(规则库中)触发时间是否吻合或相近:
(1)


(2)
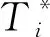
(2)规则事件中被触发的Oi位置状态异常 事件E中Oi与Oj的位置关系LocationiRLocationj(以下简称RLi,Lj)发生改变,即传感器监测发现Oi位于Locationi,Oj位于Locationj,且Locationi和Locationj在C-Onto中的位置关系[23](如表1)与已有规则中的不同。具体位置关系推理机理如图3和算法2所示。

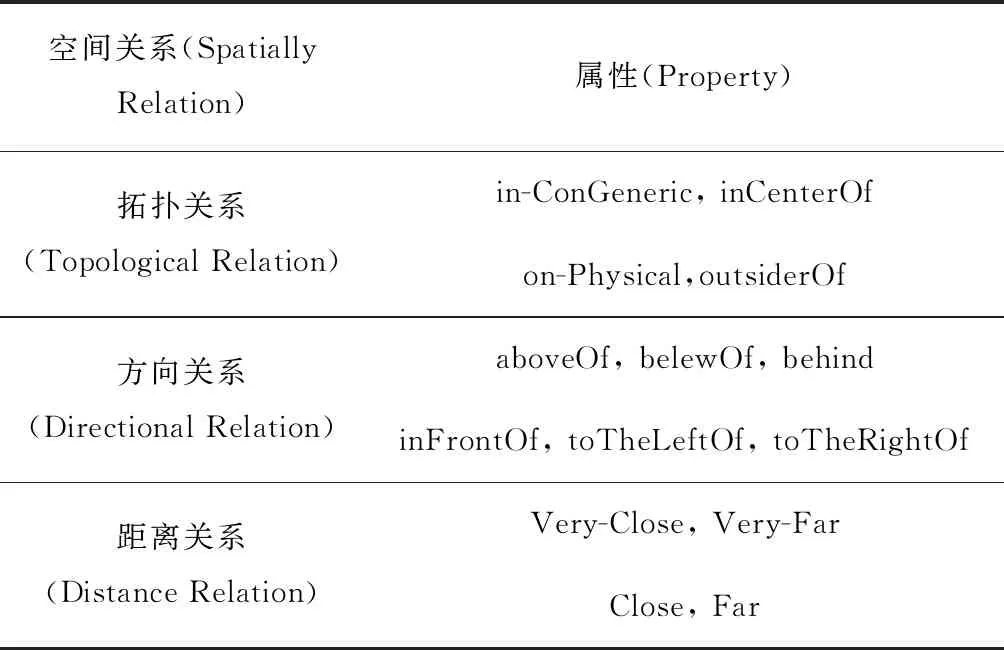
表1 空间关系属性分类
算法2物体间空间位置关系的监测与计算算法。
输入:Ctx;
输出:Oi和Oj空间位置关系RLi,Lj。
1.Begin
2.对每个输入的Ctx利用C-Onto生成RDF:
For对于Ctxi,Ctxj∈Ekdo
RDFi←Ctxiin C-Onto; RDFj←Ctxjin C-Onto;
3.从RDFi和RDFj中分别抽取出Oi和Oj当前的位置:
Locationi←RDFi;Locationj←RDFj;
4.基于C-Onto,利用3D_旋转矩阵计算推理出Locationi和Locationj的位置关系RLi,Lj:
RLi,Lj←3_D Rotation Matrix(Locationi, Locationj) in C-Onto
5. Return(RLi,Lj)
6.End(For)
算法2主要借助3_D旋转矩阵3_D Rotation Matrix[20]对从由Ctx转化而来的RDF中抽取出位置信息Locationi和Locationj进行关系计算,得到如表1所示的某个对应关系。
2 异常情景的检测
上文阐述了“时—空”两种动态属性的监督方法,即判断Oi当前(被)触发时间是否与习惯性触发时间相吻合(近似),计算(被)触发的Oi与Oj当前的位置关系。利用监督结果,并结合语义推理技术,实现Agent的自省与反馈功能,最终达到判断当前情景是否异常和做出符合情景的反应动作。
序贯决策中,Agent在一系列动作Acti,Actj,…,Actn中逐次发生之后,结合已有学习得来的规则,推出下一步将要执行的动作Actk。但在某种特殊情况下,即异常情景下,原则上的期望动作未必是最佳或者最合适的选择,而Agent应能结合实际情况实现自我规则的修正,以提供最能满足当前用户需求的服务。基于元认知环[24]的Agent自省与反馈机制如图4所示。
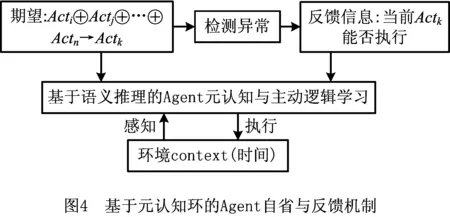
通过感知不同情景下的Ctx,抽取出其中“时—空”属性信息进行计算与判断,利用结果实现Agent的本体语义推理,且对异常情景做出反馈处理,并将处理过程与结果形成Agent学习的新规则,如算法3所示。
算法3基于语义推理的情景识别与Agent决策算法。
输入:Ctx,MoTTp,RLi,Lj;
输出:语义推理结果与Agent的动作反馈。
1.Begin
while true do
2.If: MoTTp is Complete Matching
Goto loop;
Else:
{结合C-Onto进行语义分析,从T-q时刻上传的Ctx中抽取出Oi状态:
For(i=1;i≤n;i++)
对当前情景下的每一个实体进行状态匹配:
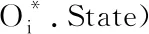
If:Complete Matching
Goto loop;
Else:
{Return(context is perturbation state);
ActkAgent;
break;}}}
3.loop:
{Return(context is not perturbation state);
Actk←Agent;}
Else:{结合C-Onto进行语义分析,并从知识库中抽取出Oi与Oj自身具备(已标记)的功能属性:
Oi.Function←C-Onto;Oj.Function←C-Onto;
判断当前RLi,Lj是否满足二者功能需求:
SemanticMatching(RLi,Lj,Oi.Function,Oj.Function) in C-Onto;
If: Complete Matching
{Return(context is not perturbation state);
Actk←Agent;}
Else:
{Return(context is perturbation state) ;
ActkAgent;}}
4.End

步骤3是基于算法2对于Oi与Oj当前的位置关系RLi,Lj的进一步语义分析,判断当前二者位置是否影响规则中的决策逻辑。根据当前位置关系RLi,Lj与原相对应决策规则中记录的位置关系RLi,Lj是否相同,判断当前位置是否异常,若相同则关于情景中触发位置无异常;反之,进一步将RLi,Lj结合Oi与Oj自身具备的使用功能属性Oi.Function和Oj.Function进行语义匹配分析,并最终判断关于情景中触发位置的异常判断结果。
3 实验与分析
3.1 实验环境与数据
本文实验在Microsoft.Net Framework 和SQL Server 2012 database所搭建的环境下进行,运行在3.80 GHz,4 GB内存,Windows 10 64位操作系统的台式机上。
为体现序贯决策在现实应用的效果,本文选择智能家居中某几个场景作为本次实验的数据来源(因为该环境下的场景更具有不确定性、随机性和异常状态)。本文将智能家居场景分为4种区域(状态),包括厨房、客厅、卧室以及浴室;每个实体(Agent)有3种动作,即启动、关闭和等待;4个观测值(周围其他实体的数目),具体数据集如表2所示。表3中是部分实验数据Ctx的实例,主要包括实体物O、动作Act类型、位置L和时间T要素,以及对每个要素的物理意义解释。
近年来,I-DID成为了解决复杂序贯决策的最为重要和有效的方法,其解决策略主要包括4种:DMU、ε-BE-I、最优K模型及MPMI,因此本文以这4种方法为基准,设计了两部分实验,以证实本文方法的有效性和意义所在。实验1对比了上述4种方法在结合了本文算法前后的性能;实验2分析了在使用了本文算法时,4种方法在求解决策结果耗时方面的影响。
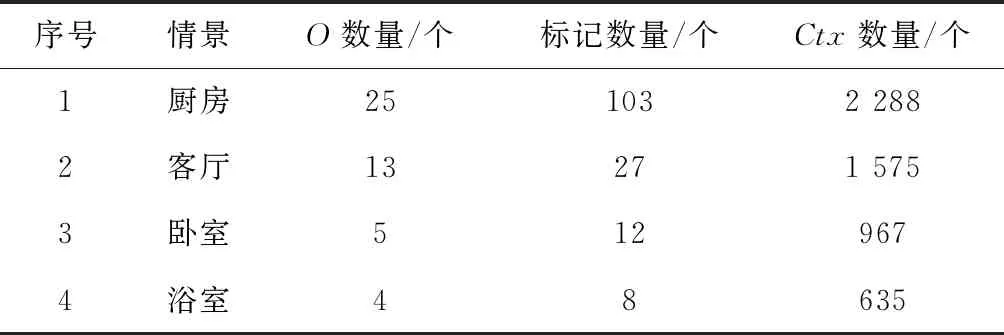
表2 实验数据集表

表3 数据Ctx实例
通过表2中80%数据训练获得I-DID节点模型,剩余的20%数据被用于验证本文方法在求解I-DID模型的性能(决策准确性)和求解速度(响应时间)方面的性能。
3.2 实验结果与分析
DMU,ε-BE-I,最优K模型和MPMI方法在求解I-DID模型的性能和求解速度的对比在文献[13]和文献[12]中已给出,本文则主要突出本文方法对上述每一种方法的影响。
实验1将智能家居中4种状态场景的测试数据进行4次模拟实验(每次8个时间片),以智能体执行正确的动作数作为回报值,具体如图5~图8所示。
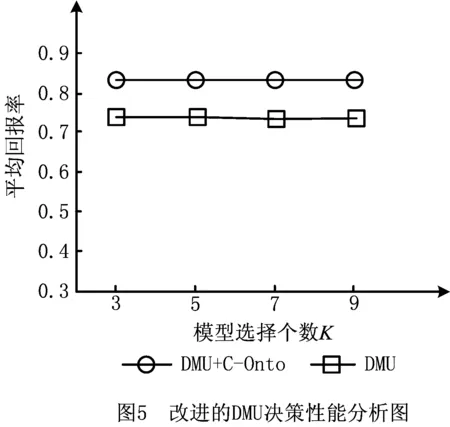



通过上述4组实验结果分析可知,DMU,ε-BE-I,最优K模型和MPMI方法在处理序贯决策的回报率方面低于文献[13]和文献[12]中的结果,因为其采取的实验环境是规则性较强的游戏场景,而本文采用随机性和不确定性更强的真实生活场景,且伴有异常情况的发生,故I-DID在应用领域的可拓展性仍然受限。当4种方法在结合本文提出的C-Onto方法时,从整体上看,在回报率上均有提高;逐个分析发现,改进后的精确DMU、MPMI和ε-BE-I的回报提升率分别是12.3%、11.4%以及8.3%,前者的效果要优于后者。而改进的Top-K方法的回报提升率随着K值的增加而不断提高,最后接近12%,是因为当K值在增大的同时,Top-K模型方法性能不断接近于精确DMU和MPMI方法。
综上可得,本文方法对于依赖机器学习所生成的决策规则具有一定的优化效果,且对于(接近)精确型的决策求解方法所呈现的优化效果更加突出。
实验2本文所提方法是对现有求解序贯决策问题方法的一种有效优化和应用领域的拓展,同时在求解过程中增加了异常检测机制,故对于求解速度,即响应时间这一指标具有一定影响。表4中给出C-Onto方法对DMU,ε-BE-I,最优K模型和MPMI在求解速度方面的定量分析。

表4 决策求解速度对比
本文首次将I-DID用于智能家居环境中的序贯决策问题,整体决策响应时间高于已有的游戏环境[12-13]等的实验结果,且改进后的4种方法较原方法仍有稍许提高。如表4所示,4种方法进行7次实验,响应时间的同比增长率在4%~6%范围内。因为本文实验环境相对更加复杂,客观性更强,同时改进的方法增加了语义推理机制,在求解过程中势必会延长计算时间,且结果仍在可接受范围内。
综合实验1和实验2,虽然C-Onto在决策响应时间方面对原有方法造成了一定影响(平均小于5%),但是考虑到在决策回报率上的提高(平均高于10%),以及可以将I-DID拓展到更加实用的现实生活场景的应用上,证明了C-Onto方法的可行性和创新性。
4 结束语
本文针对序贯决策中I-DID等方法尚不能较好地处理异常场景多智能体交互决策问题进行了补充,提出了基于C-Onto的I-DID求解决策方法,为当前对该问题的研究提供了一个重要且有意义的思路。
本文在该问题上的贡献和创新点主要有两点:
(1)对I-DID求解方法DMU,ε-BE-I,最优K模型和MPMI进行优化改进,保证了其在异常情景下仍具有较高的性能。并以此说明了基于C-Onto的异常检测方法具有普遍适用性,而非针对具体某一种方法。
(2)当前I-DID模型对于较复杂、随机性更大的环境的应用仍然受限,主要是因为其中伴随着异常情况的发生和计算性能等问题,本文考虑了实体或Agent的时间和空间异常因素的处理,将I-DID应用拓展到了现实生活或工作的智能家居环境中,为其进一步应用研究打下了基础。
基于文中的研究,未来将从以下方面进一步研究:
(1)考虑更多可能在多智能体交互过程中产生动态异常变化的因素,综合分析以进一步提高决策性能。
(2)优化I-DID建模方法和计算求解方法,使其可以在更多应用领域实现较高的性能和求解速度。
