计量检定装置智能运维知识库的构建与应用研究
2021-01-11陈雅伦高铭泽赵兴旺
陈雅伦,凌 璐,高铭泽,赵兴旺
(南瑞集团(国网电力科学研究院)有限公司,南京210000)
近年来,在省级计量中心智能化建设的推进下,各省公司基本建成了计量自动化生产系统,有效支撑了计量器具和用电信息采集设备的集中检定工作[1]。目前主要运维方式是人工巡检,以人工方式开展、事后弥补手段为主,然而随着大量新型、先进自动化设备的广泛应用,系统规模大、专业性强、复杂度高,传统依靠人工处理故障的方式满足不了低成本高效率的要求,无法做到精益化科学管理[2]。因此,为了加快设备故障的处理速度,提升运维水平和运维质量,需要通过分析线下历史运维日志以及故障处理方法相关材料建立一个能够实现智能应答的知识库[3-8]。
国内现有的运维知识库检索方式主要采用知识检索匹配方式,通过基于文本分析计算词频(term frequency,TF)和逆文本频率指数(inverse document frequency,IDF) 确定文章关键词,TF-IDF 值越大表明单词在文章中的重要程度越高,就越可能是关键词。然而,考虑到搜索语句常常包含“一词多义”和“一义多词”的情况,现有的脱离语义的文本分析方法会造成检索结果不够精确[9-10],导致计量检定装置故障处理过程中出错风险增大,不利于智能运维工作的开展。
本文在历史运维数据的基础上构建智能运维知识库模型,输入查询数据时通过相似度计算,得到相似度排序,排序靠前的作为最优方案。同时根据用户反馈进行不断地完善,构建了能够智能推荐处理方法并能通过用户使用反馈进行自学习的智能运维知识库,帮助运维人员提升故障响应速度、运维水平和运维质量。
1 LDA 模型
1.1 模型理论
LDA 模型是基于语义分析的文档主题生成模型,它深入挖掘语义的方法为对每个文本提炼该文本的主题分布,即在文本(document,已知)和文本中词(word,已知)中间加入一个隐变量主题(topic,未知)。在LDA 模型中,给定文档dj,词wi出现的概率P(wi∣dj)是确定的,而P(wi∣dj)=ΣkP(wi∣tk)P(tk∣dj)中的P(wi∣tk)和P(tk∣dj)由于含有隐变量是需要学习的项。
对于LDA 模型来说一个文档的形成是先确定某个位置的主题,然后才选择这个主题下的某个词,即先确定主题后选词。图1 为LDA 模型结构流程,模型中出现的参数如表1 所示。
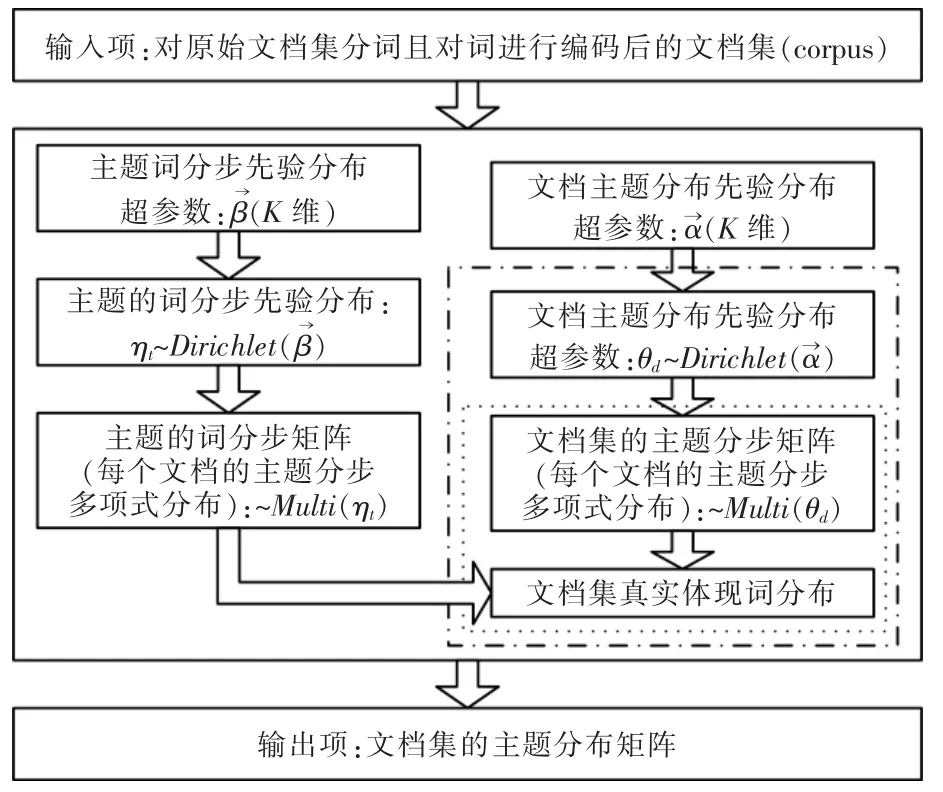
图1 LDA 模型流程Fig.1 Flow chart of LDA model

表1 LDA 模型符号说明Tab.1 Description of LDA model symbol
LDA 模型将变量分为3 个层级:α→,β→为文档集层级变量(corpus-level),一个模型内部文档集层级变量一样;θ→d为文档层级变量(document-level),一个文档内部文档层级变量一样;wd,n为文档d的第n词,zd,n为文档d第n词的主题类型,它们均为词层级变量(word-level),词层级变量随着位置的不同而不同。
通过极大似然估计最大化概率,似然函数如式(1)所示:
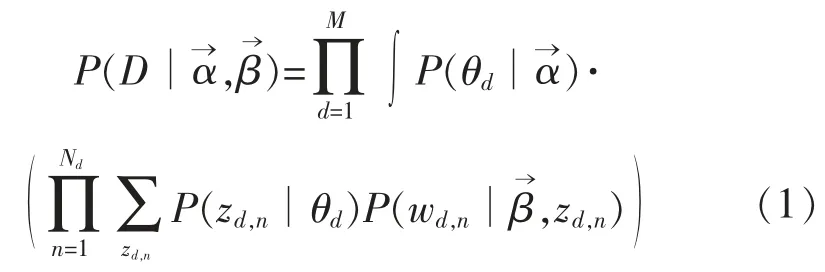
根据给定的限制条件为Σn zd,n=1,Σn wd,n=1,Σθd=1。参数估计(zd,n,wd,n)极大化似然函数。
采用最大期望(expectation-maximum algorithm,EM) 算法进行迭代求解,EM 算法是适用于带有隐变量的参数估计的求解方法。每次迭代求解分为两步,期望步(E-step)和极大步(M-step),在E-step 中求解隐变量的期望,在M-step 中使用隐变量的期望代替隐变量的值,求解模型参数。每次E-step 输入,计算似然函数。M-step 最大化该似然函数,算出不断迭代直到收敛。
1.2 模型评价标准
困惑度(perplexity)是评价语言模型好坏的方法,其基本思想是:给测试集的句子赋予较高概率值的语言模型,当语言模型训练完之后,测试集中的句子都是正常的句子,那么训练好的模型就是在测试集上的概率越高越好。
困惑度表达式如式(2)所示:
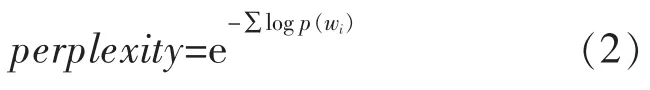
式中:P(w)=ΣΣP(d)P(z∣d)P(w∣z)。其中困惑度越小代表模型效果越好。
本文首先利用Python 程序代码块对几种常用模型进行困惑度评价。表2 列出各个模型所能达到的最小困惑度,从表2 可知经过数据预处理后的LDA模型困惑度最小,模型表现效果较好。因此本文通过分析线下运维日志以及故障处理方法相关材料,基于自然语言预处理技术和LDA 模型构建主题分布矩阵,从而构成知识库模型。

表2 不同模型困惑度比较Tab.2 Model perplexity
2 知识库构建
2.1 数据预处理
2.1.1 文本清洗
根据运维得到的历史数据,采用文本清洗方法排除噪声词汇对文本相似度的影响。由于本身报警描述中的语言较为规整,不存在错别字、习惯用语等,文本清洗主要从以下两步入手:
1)去除标点符号
由于标点符号本身并不带有文本的特征信息,去除标点符号有利于减小模型输入的维数、及其带来的对文本相似度的干扰。
2)去除逆文本频率指数较低的词汇
逆向文件频率(inverse document frequency,IDF)是一个词语普遍重要性的度量,第i个词汇wi逆文本频率指数表示如式(3)所示:
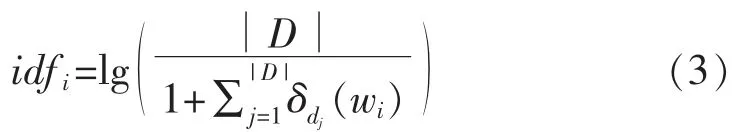
式中:∣D∣为文本个数。若wi∈dj则δdj(wi)=1,若wi∉dj则δdj(wi)=0。
逆文档频率指数较低,意味着该词汇在较多的文档中出现,因此判断该词汇为常用词汇即不能反映文本的特征。通过该方法去除非特征词汇不仅能降低维度,还能提升文本匹配算法的准确度。
2.1.2 文本分词
对去除非特征词汇的文本使用JIEBA 分词工具,基于不同的算法,通过大量的语料训练,实现中文分词。图2 给出了分词过程示例。
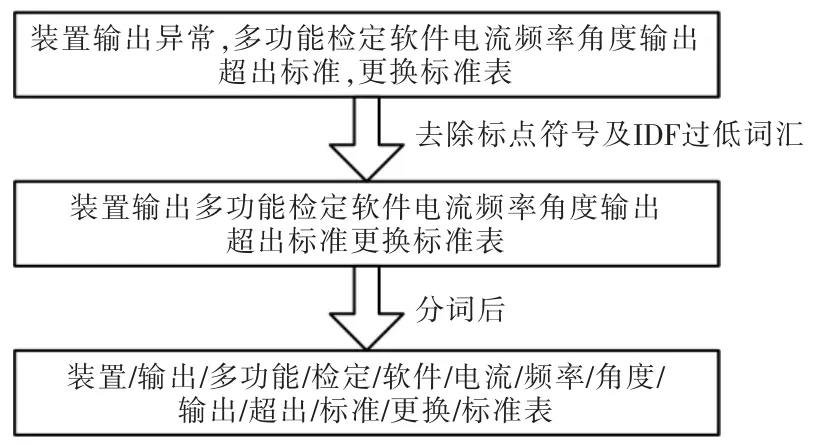
图2 分词过程示例Fig.2 Example diagram of word segmentation process
2.1.3 文本向量化
分词后形成文档集的“词袋”并对“词袋”中的词汇进行编码。通过计算每篇文档的词频将文本向量化,得到文档集的词频矩阵,作为构建知识库模型的输入。图3 给出了将分词结果向量化过程示例。
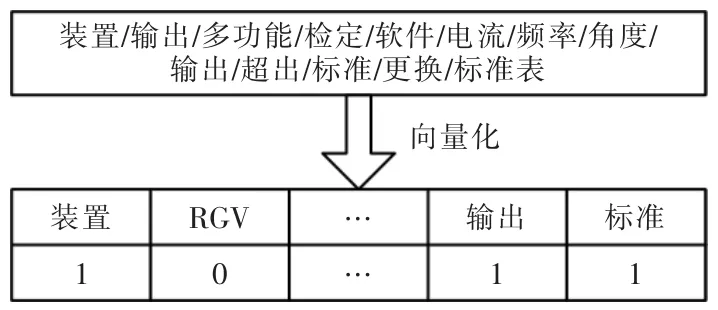
图3 向量化示例图Fig.3 Example diagram of vectorization
2.2 主题分布矩阵
对训练的LDA 模型,将Topic-word 分布文档转换成字典,方便查询概率,即计算困惑度perplexity中的P(w),其中P(z∣d)表示一篇文档中每个主题出现的概率,P(w∣z)是词典中的每个单词在某个主题下出现的概率。对于不同的主题数量的模型,计算困惑度,画出折线图,确定每篇文章的主题向量维数。根据原始文本预处理后形成的词频矩阵,对于不同主题所训练出来的模型,计算它的困惑度,最小困惑度所对应的就是最优的主题数。
2.3 相似度计算
LDA 模型最终输出每个文档的主题分布矩阵,构成知识库模型。假设有K个主题,M篇文章,主题矩阵为M×K维矩阵ti,j[ ]M×K,其中Σti,j=1,ti,j[ ]为第i篇文章的主题分布。通过计算关键词在文章中出现的词频,计算词频向量并计算余弦相似度,使用选择出来的关键词,计算这些关键词的词频。计算两个词频向量的文本匹配度,通过余弦相似度,越接近1 的就表明相似度越高。
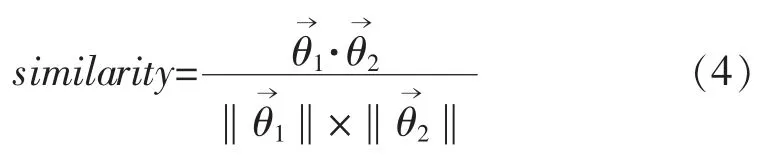
将知识库中故障原因的主题分布矩阵与用户输入的主题分布向量进行相似度计算,得到要匹配的内容与知识库原有文章的相似度排序,选择排序靠前的故障原因及相应的处理方法提供给用户。
2.4 迭代调优
知识库应用过程中,根据用户反馈进行不断完善使得知识库和智能应答功能可根据多变的现实情况不断调整,进行深度自学习,从而实现知识库的迭代优化,如图4 所示。
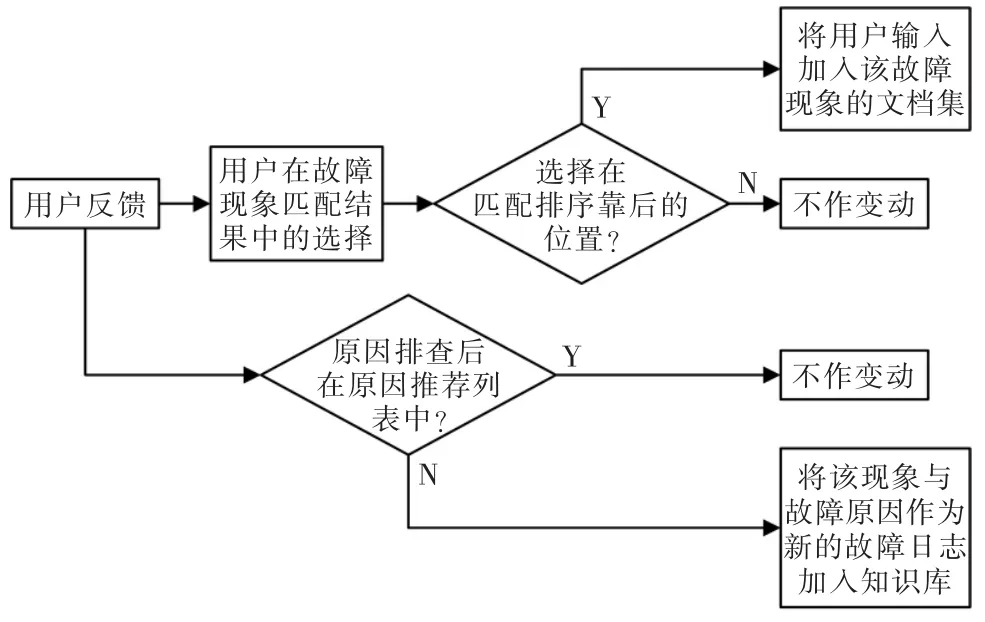
图4 迭代调优流程Fig.4 Iterative optimization flow chart
用户反馈来源于两个方面:一是用户在故障现象匹配结果中的选择;二是原因排查后用户反馈原因是否在推荐列表中。第一部分的反馈所体现的是文本匹配的精准度。最终的匹配结果是以用户输入的故障现象和知识库中故障现象的相似度排序后的列表,用户自主选择列表中的故障现象以查看解决方法。如果用户选择的故障现象在排序列表中较后的位置说明对于此次匹配来说精确度较差,应通过将本次输入加入到对应知识库故障现象的描述中调整模型内部主题词分布的方式完善模型。第二部分的反馈所体现的是知识库解决方法的完善度。若用户原因排查后发现解决方法不在知识库中,应添加进知识库中方便下次故障解决。图5 为知识库构建流程。
3 应用实例
3.1 关键技术验证
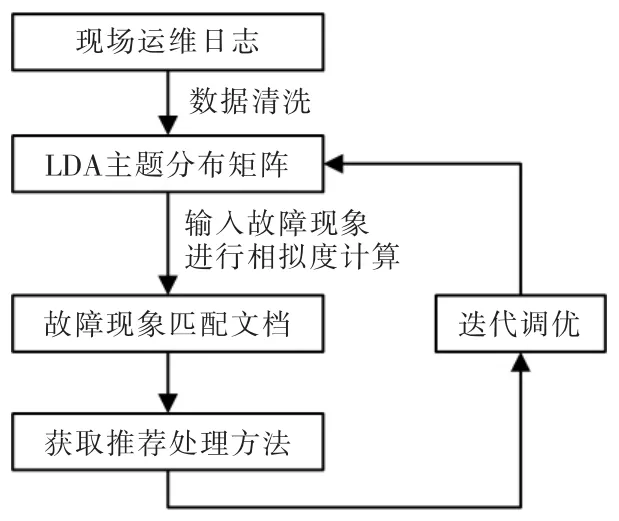
图5 知识库构建流程Fig.5 Knowledge base construction flow chart
原始数据来自于由线下运维日志整理成的处理方法编码表,主要数据是报警原因描述以及处理方法描述。在实际应用中,选取2015年至2019年的某省级计量中心单相一号线运维日志,通过文字识别技术扫描并形成线下运维档案,部分日志记录如图6 所示。
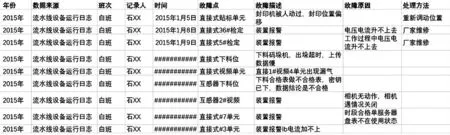
图6 单相一号线运维日志记录图Fig.6 Operation and maintenance log record of single-phase line one
通过分析得知,2015~2019年期间,有效报警原因描述共1525 条。根据数据预处理的4 个步骤对文本进行处理,如图7 所示。由于故障描述中出现了较多的专有名词,在梳理文本过程中,将设备专有名词,如:RGV,RFID,PLC,主控等,加入词典,通过设置用户自定义词典提高分词的准确率。
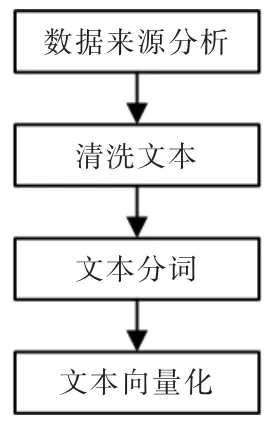
图7 数据预处理流程Fig.7 Flow chart of data pre-processing
根据文本预处理后形成的词频矩阵,设置不同的文本主题个数进行训练,训练得到的困惑度曲线如图8 所示,横坐标表示不同的主题个数,纵坐标表示对应的困惑度值。
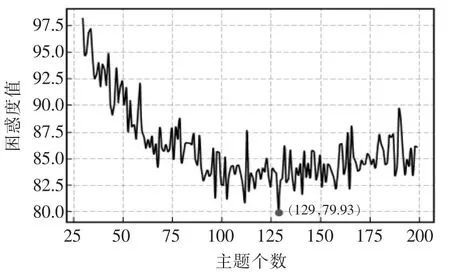
图8 模型困惑度曲线Fig.8 Confusion curve of model
根据图8 所示,当主题数K=129 时困惑度达到最低值79.93,因此确定了LDA 模型的输出,从而确定了运维知识库的主题分布矩阵。当某个设备发生故障后,输入故障现象为“机器人抓表异常”,推荐解决措施经过余弦相似度计算,筛选得到的结果,列出值最接近于1 的前三条数据,如表3 所示。

表3 余弦相似度计算结果表Tab.3 Result of cosine similarity calculation
根据现场情况,选择适合的文档内容,查看建议的故障处理方法,进行故障处理。由此可见,当输入相应故障现象时,可以根据余弦相似度在已构建的知识库中检索出相似文本,推荐合适的处理方法。
3.2 系统应用成效
系统利用运维过程积累的大量数据,实现计量平台知识库的搭建,对日常运维工作给予智能计算和指导。以某省电力公司计量中心现场室内检定室应用情况为例,针对单相电能表、三相电能表、采集终端、低压电流互感器的检定生产和设备的运维工作,对智能运维知识库部署以来的2019年10月~12月每个月运维数据进行了统计,设备发生故障后由知识库推荐的故障处理方法,能够极大程度上解决问题,使设备恢复正常运行。根据统计,计量检定装置知识库应用后,在检定能力不变的情况下,平均故障处理时间下降了50%以上,极大地提升了故障处理速度,应用效果良好。
4 结语
本文构建了以计量检定运维场景为载体的知识库体系,方便了运维故障处理的知识存储与检索,通过知识推理、智慧推荐知识的方式,自动匹配故障描述来提供故障解决措施,从而解决问题。且知识库本身具有“自学习”能力,可不断扩充、完善和提炼。经验证,通过智能知识库的运用,能够提升计量检定装置运维工作中的效率、 节省人工成本、增强知识传递。
