基于深度学习的小麦抗寒性识别系统设计
2021-01-11来纯晓李艳翠金松林韩博闫思尧刘明久
来纯晓,李艳翠,金松林,韩博,闫思尧,刘明久
(1.河南科技学院信息工程学院,河南新乡453003;2.河南科技学院生命科技学院,河南新乡453003)
小麦作为世界上种植面积最大的粮食作物,也是我国重要的粮食作物和储备粮之一,占据国家储备粮的半数以上.小麦产量的稳定,对确保国家粮食安全,满足市场需求有重要的意义.我国作为全球最大的小麦生产国和消费国,约占全球年总产量的17%[1].其中,黄淮小麦产区作为中国小麦主产区,种植面积和总产量约占全国小麦种植总面积和总产量的58%和67%[2-3].全球气候变暖背景下,极端天气频发,北方小麦种植区在冬春时节的倒春寒、寒潮等极端低温天气发生的频率愈高,周期愈短.据统计,2004—2005年度,黄淮麦区和长江中下游麦区发生严重倒春寒,受灾面积达到4.07×106hm2,仅河南已经超过1.33×106hm2,绝收面积约达2.67×105hm2左右[4-5];2009 年黄淮麦区再次发生大规模倒春寒灾害,小麦严重减产;2013 年3—4 月,黄淮麦区气温的剧烈变化,导致正处于孕穗期的小麦又遭受了大范围的低温冻害.因此,黄淮麦区发生倒春寒的概率较大,在河北省南部、山东省中部和河南省西部等地区的发生频率可达30%,山东省中部泰山地区的发生频率甚至高达70%.
小麦的抗寒性能直接影响到小麦的产量,国内外专家从不同角度对小麦的抗寒性进行研究.赵瑞玲[6]研究了室内小麦抗寒性鉴定的最适低温胁迫温度,比较和分析不同低温胁迫条件下各指标的变化规律,结合田间抗寒性指标数据,找出一套重复性好、可操作性强、准确性高的室内小麦抗寒性鉴定评价方法.Chen[7]通过田间自然试验,探讨生物刺激剂对低温条件下抗冻性的影响,以及对冬油菜和冬小麦生长发育、越冬及产量的影响.欧行奇等[8]分析了黄淮南片麦区与小麦品种耐倒春寒能力强弱密切关联的冬春性、抽穗期等6 类性状,拟定了小麦耐倒春寒育种的基本方法.来纯晓等[9]利用获取小麦特征信息数据集,构建BP 神经网络实现了小麦抗寒性分类结果预测.
现有的抗寒性识别通常在特定的低温环境下测试,需要耗费大量人力、物力和财力.本文从自然语言处理的角度,利用Python 爬虫[10-11]爬取小麦文本数据,再使用Jieba 进行分词[12-13],并使用Word2vec 工具训练词向量.最后,利用深度学习的技术[14],构建小麦抗寒性识别模型,利用训练的模型对小麦的抗寒性进行识别,可以有效降低小麦抗寒性识别的时间消耗和工作复杂度.
1 系统需求分析
1.1 可行性分析
1.1.1 技术可行性 系统设计是基于Python 语言和Qt 开发框架结合深度学习相关知识实现的,相关技术已经在图像处理、自然语言处理以及数据分析等领域成功应用.系统设计采用Python 爬虫爬取中国种业大数据平台上的国审小麦品种信息;使用自然语言处理研究中的Jieba 和Word2vec 工具,对预处理后的特征信息分词和词向量训练;使用CNN、Bi_LSTM 以及Attention 机制等深度学习方法,构建小麦抗寒性识别模型;系统设计使用Qt 开发工具进行系统界面设计,实现人机交互操作.
1.1.2 操作可行性 系统设计的数据爬取、预处理以及模型训练等模块均被封,用户通过预测分析界面,按照特征名称键入具体的特征信息,经过系统分析会给为户反馈小麦抗寒性预测的结果.系统设计操作简单、可视化程度高.
1.1.3 经济可行性 降低成本、提高质量是所有项目设计永恒不变的主题之一.本研究系统设计主要通过Python 程序编写方式实现,研究所用数据为3 513 个小麦特征信息,不需要配置较高的软硬件设备.相对以往小麦抗寒性识别方式,系统设计不仅降低了抗寒性识别的人力、财力和物力消耗,也可以有效地提升识别的工作效率.
1.2 功能分析
系统设计主要由数据爬取、数据预处理、词向量训练、模型训练以及预测分析等5 部分组成.
(1)数据爬取模块:通过使用Python 网络爬虫,爬取小麦的文本特征信息.
(2)数据预处理模块:通过数据清洗将数据规整化并使用Jieba 分词,得到每个文本特征的分词信息.
(3)词向量训练模块:将预处理得到的分词结果,采用Word2vec 训练词向量,获得特征词的高维向量表示.
(4)模型训练模块:通过深度学习中的卷积神经网络和双向长短期记忆网络训练小麦抗寒性鉴定的模型.
(5)预测分析模块:通过交互式的界面设计,让用户通过输入小麦文本特性信息,对输入小麦的抗寒性做鉴定.
2 系统设计
系统设计的整体结构由数据爬取、数据预处理、词向量训练、模型训练以及预测等5 部分组成,如图1 所示.
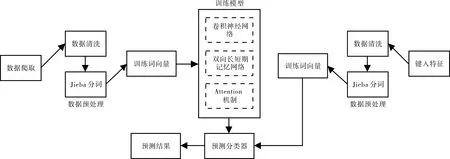
图1 系统设计总图Fig. 1 General drawing of system design
2.1 数据爬取模块
Python 网络爬虫具有强大的Scrapy 框架,能够在数据挖掘、存储历史数据以及信息处理方面体现出重要的作用.数据爬取模块由数据采集、处理、储存3 个部分组成.在采集过程中,网络爬虫向中国种业大数据平台发出请求,生成待爬取网页的种子URL,然后将生成的种子URL 放入待抓取URL 任务队列.在处理过程中,通过首先读取URL 和解析DNS,完成网页下载;再通过网页解析提取小麦特征特性中包含的信息.在储存部分,将解析出来的小麦特征文本信息,采用UTF-8 格式编码以文本形式储存.Python 网络爬虫的工作过程如图2 所示.
利用Python 网络爬虫,爬取1978—2018 年间农业农村部种业管理司的中国种业大数据平台的国审小麦品种信息,共得到3 513 个小麦品种的熟性、生育期、苗性和容质量等37 个特征.爬取后数据如图3 所示.

图3 爬取数据Fig. 3 Graph of crawling data
2.2 数据预处理模块
该模块实现对爬取数据的预处理,本研究系统设计的数据预处理主要分为数据清洗和分词2 个部分.
2.2.1 数据清洗 通过相关小麦资料的查询,结合小麦育种专家的建议[15-16],采用人工结合自动的方式清洗数据,剔除空值属性较多的无效记录,共保留3 049 条特征较为完整的小麦数据.为了构建抗寒性识别系统,选择出小麦的抗寒性作为数据标签,将数据标签标记为抗寒和不抗寒2 种类型.
由于网络文本数据的不规整,爬取到的小麦特征信息中会存在着指代信息不明、错别字、数据特征稀疏等不规整现象,需要对不规整数据进行处理,不规整数据处理如表1 所示.

表1 不规整数据处理Tab. 1 Irregular data processing
2.2.2 特征文本分词 分词是自然语言处理(NLP)中最基本的问题,它将连续的字序列,按照一定的规范重新组合成新得词序列.中文分词是指将汉字序列切分为多个汉语词语,Jieba 分词是从事汉语计算语言学研究常用的中文分词工具,可用于中文分词、词性标注和关键词抽取等任务.Jieba 分词的工作原理是将待分词的内容与已经存在的中文分词词库进行比对,通过图结构和动态规划方法,找到最大概率的词组.Jieba 分词工具采用“最大匹配”规则,返回挑选基于词典的候选词和最终结果.基于词典的模型[17]可以用式(1)表示.式(1)中:GEN(X)表示利用词典搜索到的被测试文本产生的候选词的结果集合.

Jieba 分词工具不仅可以通过添加自定义词表,实现未登录词的识别,而且还提供了精确模式、全模式和搜索引擎模式等3 种模式的分词.
(1)精确模式.把输入的汉语句子做最精确切分,适用于文本分析任务.
>>>jieba.lcut(" 小麦的抗寒性能直接影响到小麦的产量")
[' 小麦',的',抗寒性',能',直接',影响',到',小麦',的',产量']
(2)全模式.把输入的汉语句子中所有可切分成词的词语都切分出来,但会存在冗余词,不能解决歧义.
>>>jieba.lcut(" 小麦的抗寒性能直接影响到小麦的产量", cut_all=True)
[' 小麦',' 的',' 抗寒',' 抗寒性',' 性能',' 直接',' 影响',' 到',' 小麦',' 的',' 产量']
(3)搜索引擎模式.在精确模式的基础上,对较长词再次切分,提高召回率,用于搜索引擎分词.
>>>jieba.cut_for_search(" 小麦的抗寒性能直接影响到小麦的产量")
[' 小麦',' 的',' 抗寒',' 抗寒性',' 能',' 直接',' 影响',' 到',' 小麦',' 的',' 产量']
本文采用Jieba 分词中的精准模式进行分词,把输入的汉语句子做最精确切分,词与词之间用“/”分割.分词示例如表2 所示.
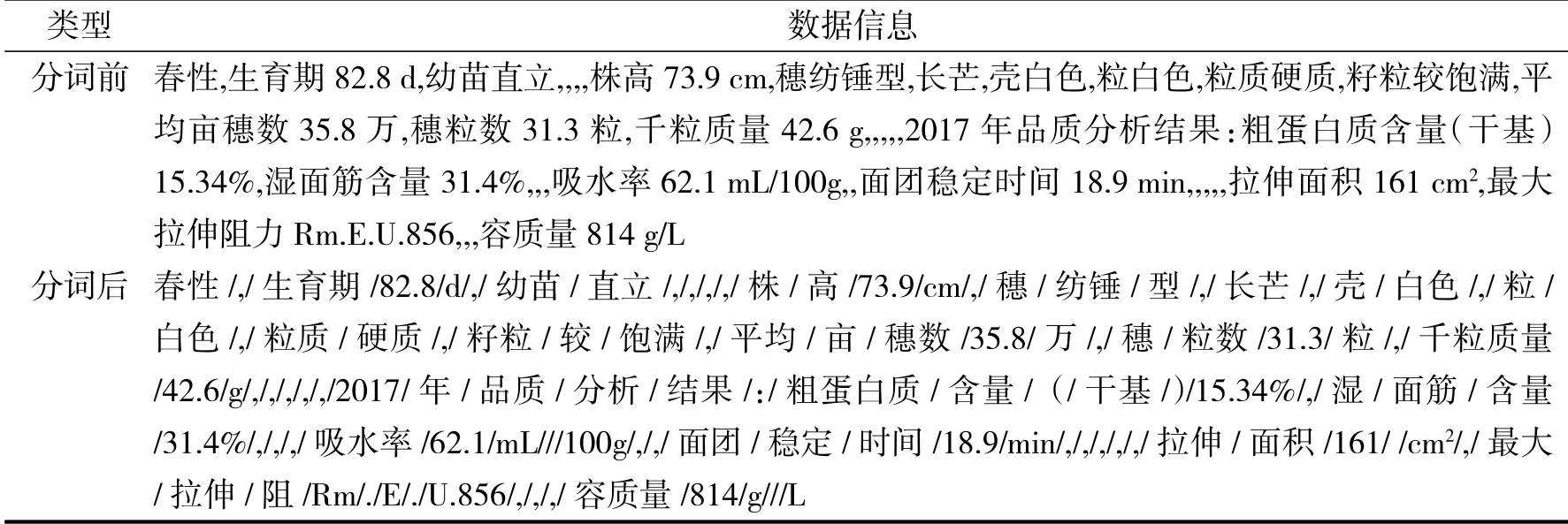
表2 分词示例Tab. 2 Examples of participle
2.3 词向量训练模块
词向量是一组语言建模和特征学习技术的统称,他可以将生成词汇表的单词或短语映射为实数值的向量.Mikolov 等[18]在2013 年公布了词向量的计算工具Word2vec,经过Word2vec 工具训练得到的词向量能够表示词汇在空间上的意义,空间中的每个点代表一个单词,在空间中的词向量之间的距离能够表示两个词在语义和语法上的相似性.Word2vec 输出的词向量常用于近义词识别、词性分析等研究领域.
Word2vec 由连续词袋模型(Continuous Bag-of-Words Model,CBOW)和Skip-gram 模型两个部分组成.CBOW 模型通过上下文来预测当前词语的概率,Skip-Gram 模型通过当前词语来预测上下文的概率.两者共同依据上下文语境来预测当前词语发生的概率.Word2vec 模型结构如图4 所示.

图4 Word2vec 模型结构Fig. 4 Word2vec model structure
对分词后的词表采用Word2vec 训练词向量,分词后的数据集中,单个样本的特征词个数分布主要集中在(135~155)之间,本研究设定样本特征长度为150,用0 补齐特征词个数不足的样本,截断特征词个数超出的样本,确保样本输入长度的一致.设定词向量的维度为100.例如“半冬性”经过训练后,词向量表示如图5 所示.

图5 词向量表示Fig. 5 Word vector diagram
2.4 模型训练模块
模型训练采用深度学习的方式,是本研究系统设计的核心模块.深度学习可以自动地对数据进行筛选,自动地提取数据高维特征,通过组合低层特征,抽象出更加高层表示属性类别的信息,从而提升分类或预测的准确性.深度学习的发展,特别是卷积神经网络(Convolutional Neural Networks, CNN)[19]、循环神经网络(Recurrent Neural Network, RNN)、以及改进的双向长短期记忆网络(Bidirectional Long Short-Term Memory,Bi_LSTM)的发展,深度学习在农业图像处理和农业文本分类等领域得到了广泛的应用[20-25].
2.4.1 卷积神经网络 卷积神经网络可以从原始数据中自动提取特征,通过多层网络结构自动学习到输入数据的局部特征信息.卷积神经网络由卷积和池化两种特殊的神经元层组成,卷积层输入的每个神经元与前一层经过局部相连,实现对局部特征进行提取,获取更能代表输入的深层信息;池化层通过下采样操作进行二次特征提取,获取最能表达输入数据的特征信息.卷积神经网络结构不仅减少网络参数数量,而且降低了训练的时间复杂度.卷积神经网络工作如图6 所示.
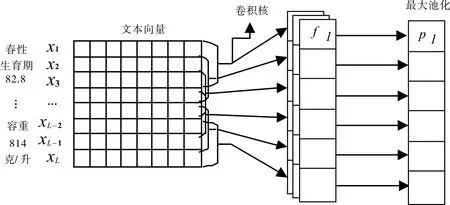
图6 卷积神经网络工作图Fig. 6 Working graph of convolutional neural network
从 图6 可 知, 卷 积 层 输 入 文 本 序 列“ 春 性、生 育 期、82.8、…、容 质 量、814、g/L”表 示 为:,向量的每行代表一个特征维度d=100 为的特征词向量;卷积操作所采用的卷积核向量为,卷积核的窗口大小为3,卷积步长为1,卷积后f1表示特征词序列“春性、生育期、82.5”中捕获的局部特征信息,表示进行卷积计算;池化层采用最大池化操作进行二次特征提取,此时表示最大池化.
2.4.2 双向长短期记忆网络 长短期记忆网络(LSTM)模型最早由Hochreiter 等[26]提出,是对循环神经网络的改进.LSTM 不仅能捕获到输入信息中的长时序依赖关系,而且可以从整体上把握输入信息的关系.Bi_LSTM 包含两个方向相反的LSTM,可以同时得到前向和后向的语义特征信息,从而充分的捕获特征词文本的上下文信息.Bi_LSTM 工作如图7 所示.
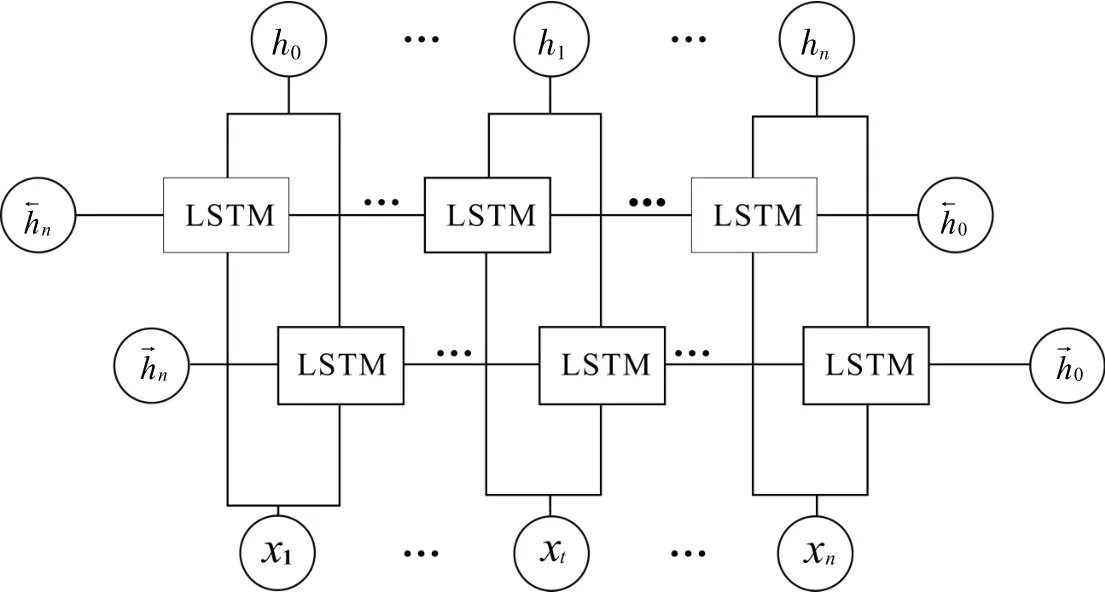
图7 Bi_LSTM 工作图Fig. 7 Work graph of Bi_LSTM
在图7 中,在任意一个时刻t 会同时有两个方向相反的LSTM 控制机制.xt为模型在t 时刻的输入,表示t 时刻LSTM 在正方向上的输出,计算见式(2),表示t 时刻LSTM 在反方向上的输出,见式(3),整个网络的输出计算见式(4)

式(4)中:Wt和Vt分别表示前向方向和后向方向上输出的权重矩阵;bt表示的是偏置值.经过Bi_LSTM 编码提取的特征信息,同时考虑当前输入小麦特征词前后两个方向上的序列语义信息.
2.4.3 Attention 机制Attention 机制用于对CNN 和Bi_LSTM 捕获的信息进行特征重要性计算,利用计算得到的权重矩阵,依据特征重要性程度为网络模型的特征进行权重再分配,提高模型对重要特性信息的关注程度.引入注意力机制后,模型会为重要的特征分配较高的权重值,不重要的特征会分配较小的权重甚至被忽略.
2.4.4 训练模型性能 构建的基于深度学习的小麦抗寒性识别模型,首先通过卷积池化捕获最能代表小麦文本向量的局部特征信息,然后将捕获的局部信息由Bi_LSTM 处理,进一步挖掘特征在前后两个方向语义的序列信息,最后通过引入Attention 机制,提高模型对重要特性信息的关注程度,提升模型的抗寒性识别能力.实验结果表明:在预测性能上要高于朴素贝叶斯(Bays)、支持向量机(SVM)、BP 神经网络(BP)[7]、卷积神经网络(CNN)和双向长短期记忆网络(Bi_LSTM)的方法,与其他模型对比的结果如表3 所示.

表3 模型性能对比Tab. 3 Comparison of model performance
从表3 可知,本文构建的模型利用小麦的输入特征信息,对小麦的抗寒性识别准确率为0.904 8,对小麦育种工作者判断小麦的抗寒性具有一定的指导作用.
2.5 预测分析模块
预测分析模块主要通过人机交互界面实现,采用Qt开发工具设计系统界面.小麦抗寒性识别系统预测工作界面如图8 所示.

图8 小麦抗寒性识别系统Fig. 8 Wheat cold resistance recognition system
由图8 可知,系统设计可以实现对小麦抗寒性的识别,用户输入的特征信息为“半冬性品种/ 平均226.2 d/ 幼苗半匍匐/ 叶色浅绿/ 分蘖力强/ 株型适中/ 株高70~75 cm 左右/ 纺锤型穗/ 长芒/ 白壳/白粒/ 籽粒饱满/ 亩穗数40~45 万/ 穗粒数35 粒上下/ 千粒质量48~52 g/ 抗旱性一般/ 湿面筋含量31.4%/’吸水量61.7 mL/100 g’/ 稳定时间2.5 min/ 延伸性136 mm/ 拉伸面积34.8 m2/ 最大拉伸阻力180 U.E/’容质量842 g/L’”时,然后点击“点此预测”按钮,系统会将输入信息自动提交到后台,在经过预处理、训练词向量后,特征信息由卷积神经网络与双向长短记忆网络混合的网络模型预测,结果显示输入品种抗寒性为中等.使用该系统,用户只需按照特征名输入特征信息,系统会自动进行抗寒性识别.
3 小结
从自然语言处理的角度出发,结合深度学习中的方法,挖掘小麦文本数据的深层特征信息,构建小麦抗寒性识别系统,可以实现对小麦抗寒性的识别.该系统可以减少育种工作者的田间和营造室内低温环境的试验,从而节省大量人力、物力和财力.小麦抗寒性识别是实践性较强的学科,抗寒性识别系统必须与育种实践结果结合,在实践结果中逐步完善,才能更好地满足育种工作者的实际需要.此外,深度学习在处理海量数据上优势更明显,后续的工作需要不断的扩充小麦数据,进一步提高系统的识别能力.
