Teaching English in the Context of Data-driven Learning
2021-01-11
School of English,Jilin International Studies University,Changchun,China Email:565216168@qq.com
[Abstract]For decades,the application of corpora to language pedagogy and research has roused extensive attention.The computer-assisted language learning is experiencing dramatic change,from assistance to dominance.This paper aims at generalizing the paradigm of the application of corpora to language learning.In order to achieve this purpose,a teaching experiment is conducted for a whole semester in teaching vocabulary,grammar,public speech and writing.Through the questionnaire carried out among participants after the experiment,it is found that learners’feedback towards the data-driven approach is generally positive,yet also with some issues to resolve in future.
[Keywords]corpus;data-driven approach;COCA;concordance line
Introduction
For decades,most EFL classroom materials are selected or extracted only to serve for specific purposes.As a result,the linguistic rules that learners learn in class are different from the language in real life and so the enhancement of communicative competence is rather hard to achieve.Therefore,language study based on the corpora of native data has been widely accepted and hence a new branch of linguistics — corpus linguistics.DDL,data-driven learning,closely connected with corpus linguistics,(Johns,1991),was coined by Tim Johns.DDL aims to provide learners with large amounts of authentic language and encourage them to discover language rules by themselves by means of concordance tools.By presenting to learners native linguistic expressions,this inductive-learning technique can be helpful for improving ESL learners’proficiency.In class teaching,the students can undertake full exploration and effective collection,collation and analysis of the data explored(Hu,2014).In the meantime,DDL highlights the participation of students,promotes learning autonomy,and also entails a shift in the role of teachers and students(Talai,2012).This,therefore,requires a brand new teaching method and learning mode.
Literature Review of Data-driven Learning
Within a constructivist framework,data-driven learning was first coined by Tim Johns in 1990.He defined data-driven learning(DDL)as“the attempt to cut out the middleman as far as possible and to give the learner direct access to the data”.Instead of directly passing knowledge to learners,DDL is a process-based approach(O’Sullivan,2007).Johns remarked the advantages of DDL:helping students to become better language learners outside the classroom by encouraging noticing and consciousness-raising,leading to greater autonomy and better language learning skills in the long term.In 2002,Tim Johns gave a brief outline of the development of data-driven learning,outlined some of the responses to the challenges,and pointed to alternative approaches.Professor O’Sullivan(2007)provided an impressive list of cognitive skills that DDL may be supposed to promote:observing,reasoning,reflecting,etc.However,there is some controversy over the appropriateness of DDL for the level of learners.Johns(1986)said that DDL is appropriate for the learners who are adults,and have enough motivation,but some investigations present evidence for the efficiency of this type of learning for the students at lower levels(Sealey,& Thompson,2007).The study derived from corpora was later distinguished between“corpus-based”and“corpus-driven”.The former is described as expounding or exemplifying existing theories not always based on corpus evidence.In corpus-driven research,theoretical statements are a product of the evidence from the corpus(Bonelli,2002).
Due to the plus side of corpora,scholars have conducted empirical studies applying DDL approach to different aspects of language teaching for many years,covering writing,grammar and vocabulary teaching etc.It was Johns(1990)who first applied DDL to grammar and vocabulary teaching of overseas postgraduate students and at the same time put forward some future possibilities for enquiry:the different types of observational tasks and concordance exercise.Aluthman(2017)proved the effectiveness of directed instruction with corpus-based activities in enhancing ESL writers’general proficiency through an empirical study.Research is also conducted in some new fields of interest like dictionary compilation.McGee(2012)analyzed what contribution four English monolingual collocation dictionaries might make to‘soft’DDL inductive learning activities in the classroom and provided a description and comparison of the dictionaries,and examines and compares the data provided by concordance lines for a series of DDL questions,with data from the collocation dictionaries.Some scholars even expanded the sense of“corpora”,from machine-readable texts to web-page-plus-search-engine corpus(Sha,2010).
The pedagogical research related to DDL is abundant for now and has indeed enhanced language learning and teaching.However,there’s still no standardized teaching paradigm of DDL and the study of EFL students’feedback and experience is still open for discussion.
Application of Corpora to Language Teaching
Corpora nowadays are widely used as a useful tool for language teachers.Getting access to corpora can be regarded as something difficult for young learners,but many scholars have conducted research by making corpora directly accessible to learners.However,in the process,language teachers undertake a significant place in giving students directions,which requires the teachers to first command relevant skills in dealing with corpora.Since the data in the native corpora are produced and collected from native speakers,the learners can definitely learn more from the authentic materials by analyzing and reasoning by themselves.Here is the general paradigm in a typical data-driven learning class.
Selection of Corpora before Class
There are two main kinds of corpora in use:native language corpora and learner language corpora.The corpora for use in teaching are mainly native language corpora as they serve as a reference and direction for EFL learners.The data selected for the author’s study are COCA(corpus of contemporary American English)and TED parallel corpus(founded by the author herself for bilingual comparative study).COCA is the only large,genre-balanced corpus of American English.COCA is probably the most widely-used corpus of English,containing more than 600 million words of text and it is equally divided among spoken,fiction,popular magazines,newspapers,and academic texts.TED parallel corpus contains the speeches from TED in three languages:English,Chinese and French.TED is a nonpartisan nonprofit devoted to spreading ideas,usually in the form of short,powerful talks.TED began in 1984 as a conference where Technology,Entertainment and Design converged,and today covers almost all topics — from science to business to global issues — in more than 110 languages.Apart from these two corpora,two other corpora are also applied in the study.

Table 1:Corpora Applied in the Study
Learners can get the data via two ways:direct access to data by themselves and indirect access,i.e.the acquisition of data from the teacher.Either way,teachers or students need to do concordance.Concordance lines,as an intense and highlighted collection of target language,serve as evidence for analysis.Under proper instruction,most learners are able to use concordances by themselves.The pro side of giving students direct access to data is that they get to see abundant real native expressions and the con side is that students are likely to be confused by such a flood of linguistic data.There is another way,proposed by professor Liang(2009),making mini-texts.Mini-texts are just a certain collection of concordance lines,but the teacher,as material provider,can preview the materials and select,edit and then present the data to the learners.The good point is that students are less likely to feel frustrated by the massive and unfamiliar data,but the negative point lies in that students lose the opportunity to challenge themselves in finding new useful language information by analyzing,processing and differentiating by themselves.Besides,there are some other advantages of this mini-text:authentic language,definite goal,easily hand-on,high flexibility,and clear highlight(Liang,2009).The author recommends the usage of mini-texts in class because learners get to save time in looking over repetitive linguistic phenomena and can avoid getting frustrated in face of countless novel expressions online.
Data-driven Tasks in Class
Many DDL tasks in class are based on the concordance lines or the edited concordance lines.In teaching fixed word chunks,the concordance lines can be adjusted and re-designed as blank-filling exercise,collocation matching exercise etc.Learners need to work together and finish these tasks with the data from the corpora.Second,by analyzing and generalizing rules in the data,learners can summarize by themselves the different English grammatical knowledge.Observance of the different use of,for example,“-ing”,can facilitate the understanding of the usage of English present participle and gerund.Third,on the level of the passage,different sample essays can be searched and presented on a given topic.For the sake of writing an essay or making a public speech,these materials are quite handy.When teaching writing,different essays of the same topic can be sorted out and organized as a whole to serve as supplementary materials.By engaging in such tasks as writing thematic statements,eliciting evidence or examples,statistics and ordering the different paragraphs of an article,learners are able to collect sufficient materials for writing.Possible corpus-based tasks/activities in class are listed in detail as below:
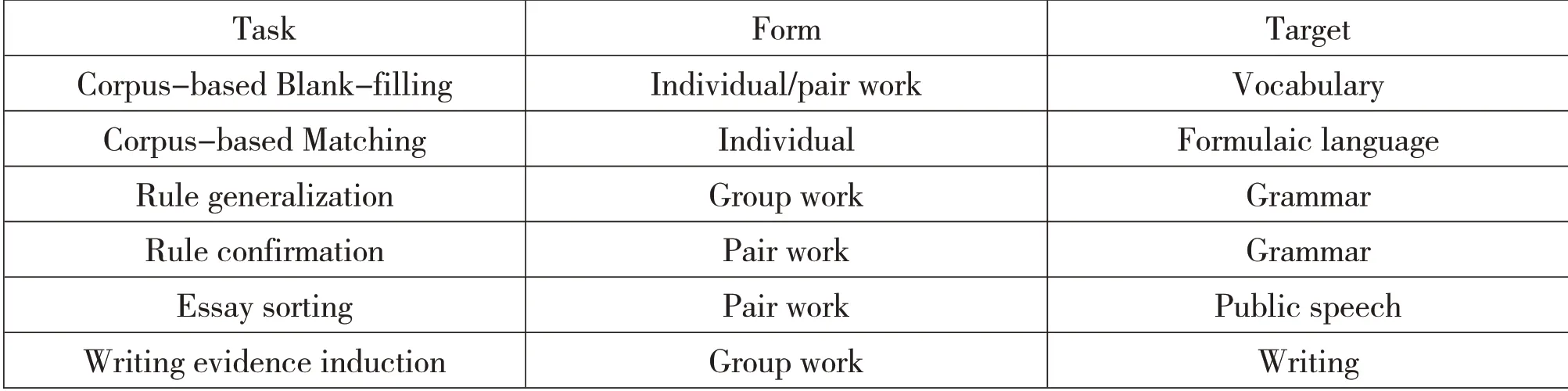
Table 2:Corpus-based Tasks in Class
Data-driven Tests after Class
After a certain period of DDL teaching,the teacher should design corresponding tests to examine the efficiency.These tests are better related to the in-class tasks.The principle of designing tests after class is flexibility and openness.Learners should have the freedom to get access to the corpus,offline or online.And the results of these tests shall be discussed in the next class.
Analysis of EFL Students’Data-driven Learning Experience
At the end of the experiment,all participants were asked to finish a survey to collect the data of their satisfaction of data-driven learning approach.The questions are set with a five-point Likert scale:(i.e.very dissatisfied,dissatisfied,satisfied,quite satisfied and very satisfied)on the following topics:language knowledge,analytical and critical abilities,teacher’s guidance,mastery of data processing,overall satisfaction.The questionnaire was given to a sample of students(n=120)classified on the basis of the different teaching contents and academic year,i.e.,vocabulary,grammar,English speech and writing.With respect to the students’academic year,three groups were established.They corresponded to three different years:first-year students(n=28,23.3%of the sample,vocabulary),second-year students(n=31,25.8%of the sample,grammar),,third-year students(n=30,25%of the sample,public speech)and fourth-year students(n=31,25.08%of the sample,writing).
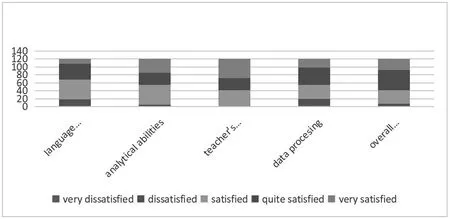
Figure 1:Learners’Satisfaction with DDL Approach
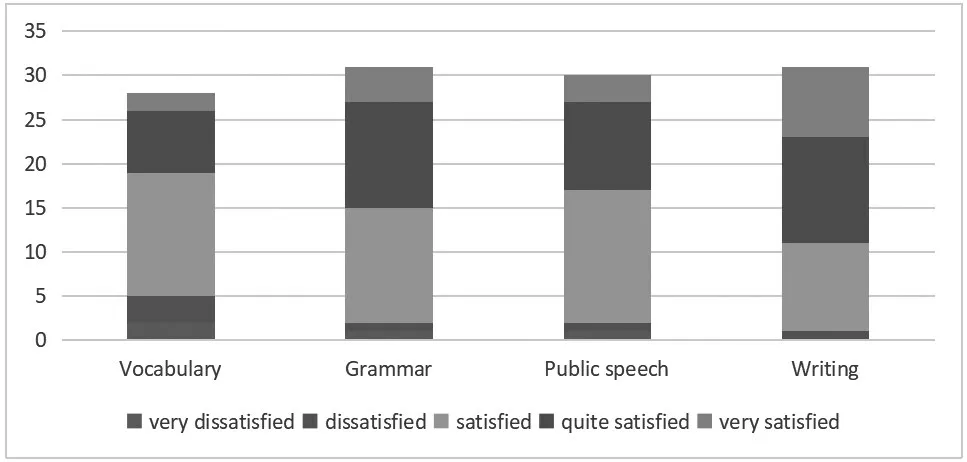
Figure 2:Learners’Satisfaction with the Different Teaching Contents
As is shown in figure 1,the percentage of dissatisfaction with language knowledge is the highest among the four.Students are most satisfied with the guidance from the teacher.Besides,a majority of the students believe their analytical ability got improved a lot.As for the different teaching contents,students of the higher grades have a higher degree of satisfaction.However,grammar learners,especially vocabulary learners,are more dissatisfied.They are the freshmen and sophomore students.Thus,it can be roughly concluded that students of higher grades can handle the corpus better and are more acceptable with the self-learning approach.
The commonality is that the subjects in the data-driven learning experiments mostly experience a rising motivation in learning English,whether it is formulaic language,grammar or the analysis of a whole passage.In the process of analyzing data with other students,learners are able to discover the rules of language by themselves.It is quite likely that some rules they find might be improper or not general,but even the mistakes they make in this process are still helpful for learning a language.It is the process that matters.
Conclusion
In a typical DDL class,adequate instruction should be given to students and teachers should design data-based classroom activities of a proper level of difficulty.As most of the data-driven activities are organized as group work,learners are actively engaged in these tasks.This is the major benefit of having a data-driven class,learners spending a majority of the time making discoveries by themselves.In the meantime,proper time allocation should be done to control the length of different tasks.This inductive learning method is better combined with instruction from the teacher.A proper blend of teacher summary and learners’practice can clear the learners’head.There might be some problems with DDL,but there is no denial that big data will always be a major trend in language teaching.
Acknowledgements
This work was supported by Jilin Association for Higher Education(No.JGJX2018D530,2018,05/28).
杂志排行

Proceedings of Northeast Asia International Symposium on Linguistics,Literature and Teaching的其它文章
- Language Assessment Literacy and the Influential Factors:Evidence from a Survey of Middle School English Teachers in Chongqing
- Case Study:Interviewing,Assessing,and Analyzing a Second Language Learner
- A Comparative Study on the Effects of Two Modes of Internet-based Feedback in EFL Writing Settings
- A Corpus-based Study on Conceptual Metaphor in T.S.Eliot’s Four Quartets
- Exploration of the SPOC-based Blended Teaching Model:Case Study of Business English Course
- The Study on CET-4 Writing and Writing Teaching Strategies Based on the Survey of CET-4 Writing Marking Teachers