基于难分样本挖掘的对抗自编码器推荐系统
2021-01-07孙静宇
魏 东,孙静宇,海 洋
(太原理工大学 软件学院,太原 030024)
0 引言
传统的推荐算法大致可分为3类:基于内容推荐、协同过滤推荐和混合推荐[1]。其中协同过滤算法因其在处理非结构化数据的优越性,在时下的推荐系统中得到广泛应用和关注。经过学术界和工业界多年的探索和研究,推荐算法经历了从传统的矩阵分解等方法到现今的与深度学习技术结合的发展历程。
深度学习旨在模拟、建立人脑进行分析学习活动的神经网络,其模型是一种深层非线性网络,可以获取比传统算法更深层次的数据本质特征。近些年,深度学习在图像处理[2]、语音识别[3]以及自然语言处理[4]等领域都取得了很多成果[5],成为了人工智能领域的一个研究热点,同时也为推荐系统的研究带来了新的机遇。基于深度学习的推荐系统通常将各类用户和项目相关的数据作为输入,利用深度学习网络进行学习和训练,最终自动为用户输出个性化的推荐结果[6]。
本文提出了一种结合难分样本挖掘(HEM,hard example mining)和对抗自编码器[7](AAE,adversarial autoencoder)的深度推荐模型(HEM-AAE)。难分样本挖掘采用三元损失算法对项目进行分类,以此来解决评分数据分布不平衡和稀疏性问题。将不同类别的项目输入对抗自编码器的训练过程,可以从两方面优化推荐模型。在此基础上通过训练好的模型预测目标用户的项目评分,使用TOP-N算法选择预测评分最高的项目推荐给用户。
1 难分样本挖掘
推荐系统研究中常用数据集数据分布不平衡,稀疏问题较严重,影响了推荐系统性能稳定性。虽然评分范围固定,但是用户评分基于个人主观认知,用户评分标准、偏好不同加剧了数据样本复杂性。所以用户偏好挖掘尤为重要,故本文引入均模型(Mean Model)对数据集做难分样本挖掘(Hard Negative Mining)预处理[10]。
1.1 均模型
由于推荐系统中的常用数据集稀疏性较高,对计算机资源消耗较大,故引入均模型[16]。均模型生成过程类似于排序二叉树,可以在保留数据统计学特征的情况下极大缓解数据稀疏性,如图1所示。

图1 均模型结构示意图
假设项目评分向量I={r1,r2,,rm},经过变换,得到此向量的均模型表示为:
IMM={t0,(t10,t11), (t20,t21,t22,t23), (t30,t31,),}
(1)
其中:t0为均模型的根节点,(t10,t11)为均模型第二层的第一和第二个元素,tlk表示第l层的第k-1个结点。结点生成过程如公式(2):
tlk=Tl(Il)
(2)
其中:Tl(*)为第l层的转换公式(3):
(3)
当k为奇数时,Il={ri∈I|ri>t(l-1)g};k为偶数时,Il={ri∈I|ri≤t(l-1)g},g的值为:g=|k/2|。在实际应用中,可以根据需求灵活调整均模型规模,一般只需三层即可。
1.2 三元损失算法

(4)
其中:α是一个常量,表示正负样本对训练的边界值。难分样本挖掘代价函数如公式(5)所示:
(5)
代价函数采用欧氏距离度量评分向量间距离,故公式(5)恒大于零,当[*]大于0时,规定其为损失函数的损失之;[*]小于0时,规定损失值为0。
2 基于难分样本挖掘的变分自编码器
HEM-AAE系统框架如图2所示。
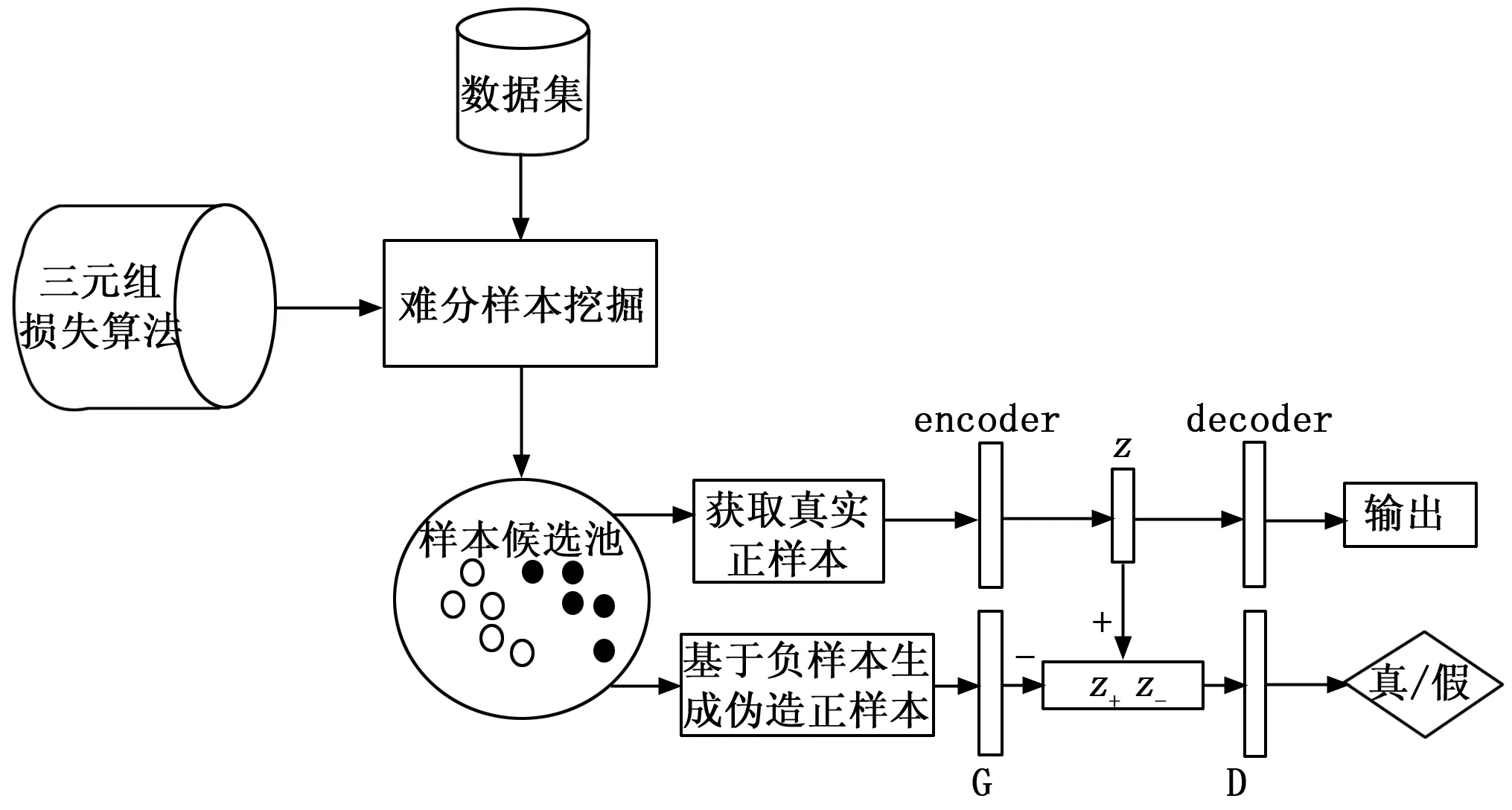
图2 基于HEM-AAE的推荐系统框架
其中AAE由自编码器[8](AE,autoencoder)和生成式对抗网络[9](GAN,generative adversarial networks)两部分组成。自编码器主要由编码模型encoder和解码模型decoder构成;对抗网络由生成模型G和判别模型D构成。首先,采用三元组损失算法对数据集进行难分样本挖掘,经过分类的正、负样本放入样本候选池;再将正样本和负样本分别作为自编码器encoder和对抗网络生成模型G的输入,分别产生正样本隐表示和伪造正样本隐表示;自编码器的decoder根据encoder生成的正样本隐表示重构用户评分;判别模型D辨别正样本隐表示和伪造正样本隐表示。
2.1 自编码器
自编码器是一种使用误差反向传播算法(BP,back propagation)进行训练的前馈神经网络,结构可简化为如图3所示[11]。
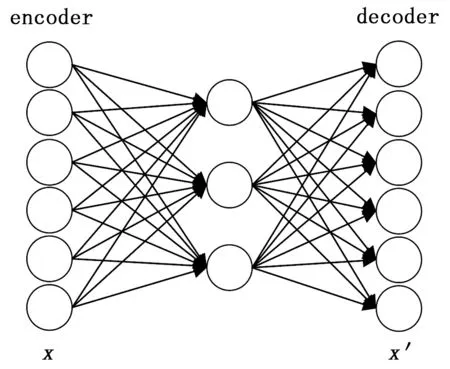
图3 自编码器结构图
自编码器神经网络由输入层encoder,隐藏层和输出层decoder构成。通常隐藏层的维度远小于输入层,输出层的作用是重构输入层,使用重构误差(x,x′)来表示重构的接近程度。其流程如图4所示。

图4 自编码器神经网络流程图
其中encoder将输入INPUT进行压缩表示,decoder再将压缩表示进行还原。其数学表达式如式(5),φ和ε分别表示encoder和decoder。
φ,ε=argminφ,εL(X,ε(φ(X)))
(5)
数据降维和特征提取被认为是自编码器的两个主要实际应用。使用适当的维度和稀疏性约束,自编码器可以得到比主成分分析或其他类似技术更好的数据投影。
2.2 对抗自编码器
如果只通过最小化重构误差来训练模型,自编码器极有可能学习到一个恒等函数[1],因此本文引入对抗自编码器进行“对抗”训练。如图1所示,对抗自编码器模型由自编码器和对抗网络两部分组成。训练过程分为也可划分为两阶段:重构阶段和正则化阶段。本文中,对抗网络的生成器G与自编码器的编码模型encoder使用同一个网络。在重构阶段,自编码器更新编码模型encoder和解码模型decoder以最小化重构误差。在正则化阶段,判别器D辨别正样本隐表示z+和生成器G生成的的负样本隐表示z-,根据判别结果,交替更新生成器G和判别器D。对抗自编码器的训练有两个目标:最小化重构误差和达到对抗网络的相对平衡,其损失函数如式(6):
LAAE=ReonstructionLoss+AdversarialTraining
(6)
自编码器的重构输出[12]如式(7)所示:
h(r;θ)=f(W·g(Vr+μ)+b)
(7)
其中:g(*)使隐藏层的激活函数,f(*)是输出层的激活函,θ={W,V,μ,b},权重W∈Rm×k,V∈Rk×m,偏置μ∈Rk,b∈Rm。输出层对应位置元素被认为是预测值,即:
(8)
损失函数如公式(9):
(9)
生成模型G使用负样本作为输入产生伪造正样本,对判别器D进行反向激励,使得判别器可以更好地识别正样本;经过优化的判别器同时有利于优化生成器,生成更好的伪造正样本。对抗网络的训练采用交替优化方法,即固定G的参数以更新D的参数,然后固定D的参数去更新G的参数。Goodfellow等[9]指出,将生成器G固定,可求得唯一的最优判别器:
固定判别器D,在pg=pdata时,D*=0.5,此时生成器G达到最优,即判别器无法区分真实样本和伪造样本[17]。损失函数如公式(10):
Ed~pφ(m|un)[ln(1-D(m|un))])
(10)
其中:m为训练集样本,U表示用户集合,un表示第n个用户,φ和δ分别表示生成器G和判别器D的参数。首先更新判别器,使其最大化正确判别正样本隐向量和伪造正样本隐向量,如式(11)所示:
Em+~ptrue,mg~Gφ(mg|un)[ln(1-Dδ(mg,m-|un))])
(11)
其中:m+,m-分别代表正样本和负样本,mg代表由G生成的伪造正样本。与判别器D相反,生成器G最小化判别器D的正确判别概率。故生成模型G的优化函数如式(12),M表示样本集合。
(12)
在HEM-AAE中,对抗网络和自编码器均使用Adam优化算法[13],即自适应时刻估计方法进行优化训练。Adam优化算法是一种一阶优化算法。与随机梯度下降法等优化方法最大的区别在于:通过计算梯度的一阶和二阶矩估计,Adam算法为每个参数设计了独立的学习率。更新过程如式(13)~(17):
mt=β1*mt-1+(1-μ)*gt
(13)
(14)
(15)
(16)
(17)
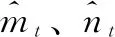
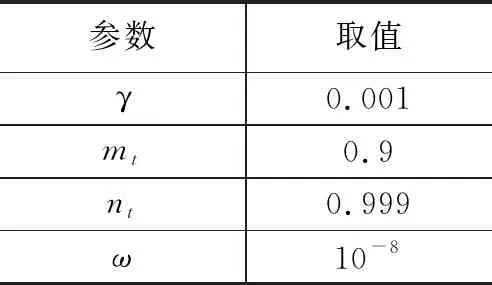
表1 Adam算法参数的选取
3 实验结果与分析
3.1 实验设计与数据集
HEM-AAE的encoder、decoder、生成器G和判别器D均采用单层神经网络,隐藏层神经元个数视不同数据集而不同(详见3.2节),所有神经网络都使用Sigmoid激活函数。运用Python编程语言,通过深度学习框架Tensorflow进行神经网络的搭建;实验中的操作系统为Ubuntu 18.04 Lts,在NVIDIA GTX 1060 6G显卡上运行。
本文采用GroupLens公开数据集MovieLens-100K、MovieLens-1M[18]来评估HEM-AAE的性能。只使用用户ID,电影ID和评分信息,其中的每个用户都有20个以上的评分记录。两个数据集的统计信息如表2所示。实验共进行5次,每次随机选取数据集中的80%作为训练集,20%作为测试集,综合5次实验结果的平均值得出结论。

表2 MovieLens数据集统计信息
3.2 隐藏层规模对算法的影响
本节通过设置不同个数的隐藏层神经单元来研究推荐准确度受隐藏层规模对于HEM-AAE模型性能的影响,神经元个数分别为[10, 50, 100, 150, 200, 250, 300, 350, 400, 450, 500, 550, 600],测试结果如图5所示。

图5 隐藏层规模对HEM-AAE性能的影响
基于测试结果可以发现:数据、神经网络规模越大,最佳神经元值也越大。随着神经元个数的增加,平均绝对误差迅速减小,但当其超过某个值后,误差又开始增大。对于不同的数据集,神经元个数需要经过调试找到最佳值。规模越大的网络过拟合的风险也越大,所以并不是越大越好。基于测试结果,分别为数据集MovieLens-100K、MovieLens-1M选定的隐层神经元个数为100和400。
3.3 性能评价指标
本文预测的是目标用户对待定预测产品的明确的评分,选用平均绝对误差(MAE,mean absolute error)、准确率(precision)和NDCG(normalized discounted cumulative gain)。
检测预测准确度,MAE越小,说明算法的预测准确度越高。定义如下:
(18)

准确率表示推荐算法的准确性,值越高说明推荐的准确性越高,对于用户u在生成的推荐的准确率公式为:
(19)
其中:R(u)是训练完毕后为用户u做出的推荐结果,T(u)是用户u在测试集上的真实结果。
NDCG是一种衡量推荐算法产生的推荐结果的排序质量的评价指标,该指标考虑到元素之间的相关性,值越高说明推荐结果的排序质量越好。对于推荐结果中的第i个结果qi,其NDCG值为:
(20)

本文选择对比的算法有包括:
1)PMF[14]:概率矩阵分解是将用户物品评价矩阵分解为用户因子和物品因子,其中假设用户和物品的隐向量服从高斯分布。正则化参数λu,λv设置为0.01和0.002时,PMF推荐性能最好。
2)PCMM[15],使用据模型将整体用户集聚类成多个用户子集,然后在整体上和局部上计算相似度,利用整合后的相似度预测评分。
3)IRGAN[16],信息检索生成对抗网络是首个基于生成对抗学习模型的推荐系统。
4)DeepFM[11],由深度神经网络和因子分解机组成,可以同时提取到低阶组合特征与高阶组合特征。
3.4 结果比较与分析
具体实验结果如表3、表4和表5所示,由表中实验数据可知,HEM-AAE在各项数据上都相较于PMF、PCMM和IRGAN都有明显提升。

表3 各算法/模型在不同数据集上的MAE
如表3所示,在评分预测平均绝对误差方面,在两个数据集中的测试中HEM-AAE的推荐质量都有很大提高。表4实验结果和表5实验结果类似,分别是各算法/模型在MovieLens-100K和MovieLens-1M数据集上的准确率和NDCG指标,可以看出HEM-AAE各项推荐性能指标显著提升,各算法/模型推荐性能降序序列:HEM-AAE> IRGAN> PCMM> PMF。

表4 各算法/模型推荐性能比较(MovieLens-100K)
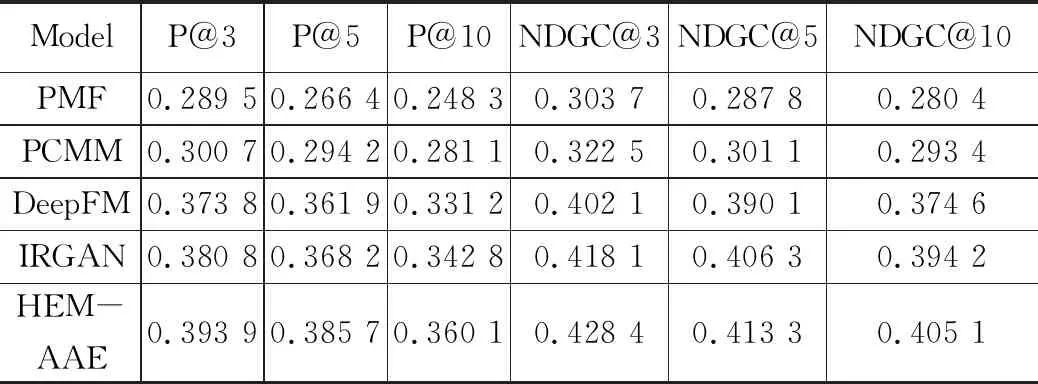
表5 各算法/模型推荐性能比较(MovieLens-100K)
4 结束语
从实验结果来看,本文提出的HEM-AAE推荐模型有效提高了推荐精度。但是对于新用户在没有任何行为记录时,无法进行推荐,冷启动问题依然存在。其次由于神经网络是一个黑盒子过程,无法合理解释在反向传播的过程中的具体细节,所以此算法缺乏一定的可解释性。本文使用的为单层神经网络,对计算性能要求相对较小,而在工业界实际操作中,数据体量远远大于本文实验数据,所以后期要在分布式集群上进行数据运算,这样也可以获得更准确的结果。
