基于Mask RCNN的滤袋开口检测方法
2021-01-07王宪保朱啸咏姚明海
王宪保,朱啸咏,姚明海
(浙江工业大学 信息工程学院,杭州 310023)
0 引言
在滤袋的智能生产中,需要对滤袋进行卡扣的自动化安装,而实现这一过程的前提是获得滤袋开口的准确位置及滤袋所属的类别。伴随着滤袋制造工艺的提升以及需求的多样化,滤袋大小、纹理等变得更加丰富,这为滤袋开口检测问题带来了更为严峻的挑战。
本文的滤袋开口检测实际上是一种目标检测,它是一种包含目标定位与目标分类任务,使用图像处理、机器学习等方法,在图像中搜索感兴趣对象的计算机视觉技术[1]。一般先通过目标分类判断是否含有目标对象,再进行更细粒度的检测,并将搜索到的目标通过方框进行标注[2]。
计算机视觉处理中,图像一般以像素矩阵的形式存储,对其进行类别以及位置信息的相关特征提取方可实现目标检测[3]。传统目标检测算法在图像经过去噪、增强、裁剪等预处理之后,对图像采用滑动窗口遍历并生成候选区域,对每个候选区域采取特征提取,例如方向梯度直方图(HOG,histogram of oriented gradients)[4],尺度不变特征变换(SIFT,scale invariant feature transform)[5],(DPM,deformablepartsmodel)[6]等,最后通过AdaBoost[7],(SVM,support vector machine)[8]等机器学习算法对目标进行分类,然后依据类别对目标进行边框回归。由于上述目标检测模型对于不同的特征需要设计不同分类器,导致其泛用性差、鲁棒性不足。
2012年之后,计算机视觉技术在深度学习的带动下开始了迅猛的发展,以深度卷积神经网络为代表的方法替代了手工特征方法。在目标检测领域,(Fast RCNN,fast region-based convolutional neural network)[9]和(Faster RCNN,faster region-based convolutional neural network)[10]为基于深度学习的目标检测方法提供了新的方向。前者由于共享卷积操作降低了网络整体的计算消耗,后者在前者基础上融合全卷积网络[11]的思想,提出通过区域提议网络(RPN,region proposal networks)代替原先的Selective Search[12]以及Edge Boxes[13]算法。另一种基于回归的思路由2016年Redmon等[14]提出的(YOLO,you only look once)算法启发,这类算法精度不及Faster RCNN这类基于候选区域方法,但其检测速度却是前者的10倍,后续又提出了(SSD,single shot multi-box detector)[15]、(RefineNet,refinement neural network)[16]、(YOLOv2,you only look once v2)[17]以及(YOLOv3,you only look once v3)[18]等。
本文将(Mask RCNN,mask region based convolutional neural network)[19]作为基本框架,并针对具体目标对象进行改进,建立了一种用于滤袋的有效检测方法。本文的主要工作有:首先,针对固定卷积中感受野形状固定,不能灵活地覆盖目标对象,降低了特征提取效果这一问题,采用可变形卷积网络(DCN,deformable convolutional networks)[20-21]改进固定卷积,通过引入额外的偏移来提升空间采样能力。其次,提出一种改进的(Soft-NMS,soft non-maximum suppression)方法,对Mask RCNN的RPN网络输出增加一次筛选,提升候选区域的质量,减少候选区域的数量。最后,利用本文提出的目标检测器在滤袋数据集上进行实验,结果证明可以有效检测滤袋开口,相较于基准方法高了2.4个百分点。
本文的组织结构如下:首先在第一节对基础框架等技术进行介绍;第二节对本文提出的检测器进行详细介绍;第三节通过实验,验证了本文提出的检测器在滤袋开口检测中的有效性,并通过与基准检测器的对比,展现了本文检测器的性能优势;第四节对全文工作进行总结与展望。
1 相关工作
1.1 Mask RCNN
Mask RCNN模型建立在Faster RCNN的基础上,将Faster RCNN中(ROI Pooling,region of interest pooling)替换为(ROI Align,region of interest align),消除了二次量化的误差,并在头部网络中增加掩码分支用于实现实例分割,提升了对象的检测精度。
1.1.1 网络结构
Mask RCNN的结构如图1所示。模型包含用于特征提取的主干网络、候选区域生成的RPN、ROI Align以及头部网络。主干网络的选择主要有(VGG,visual geometry group)[22]、(ResNet,deep residual network)[23]等,其将一系列卷积进行堆叠,逐层提取图像中的语义信息,形成特征映射图。
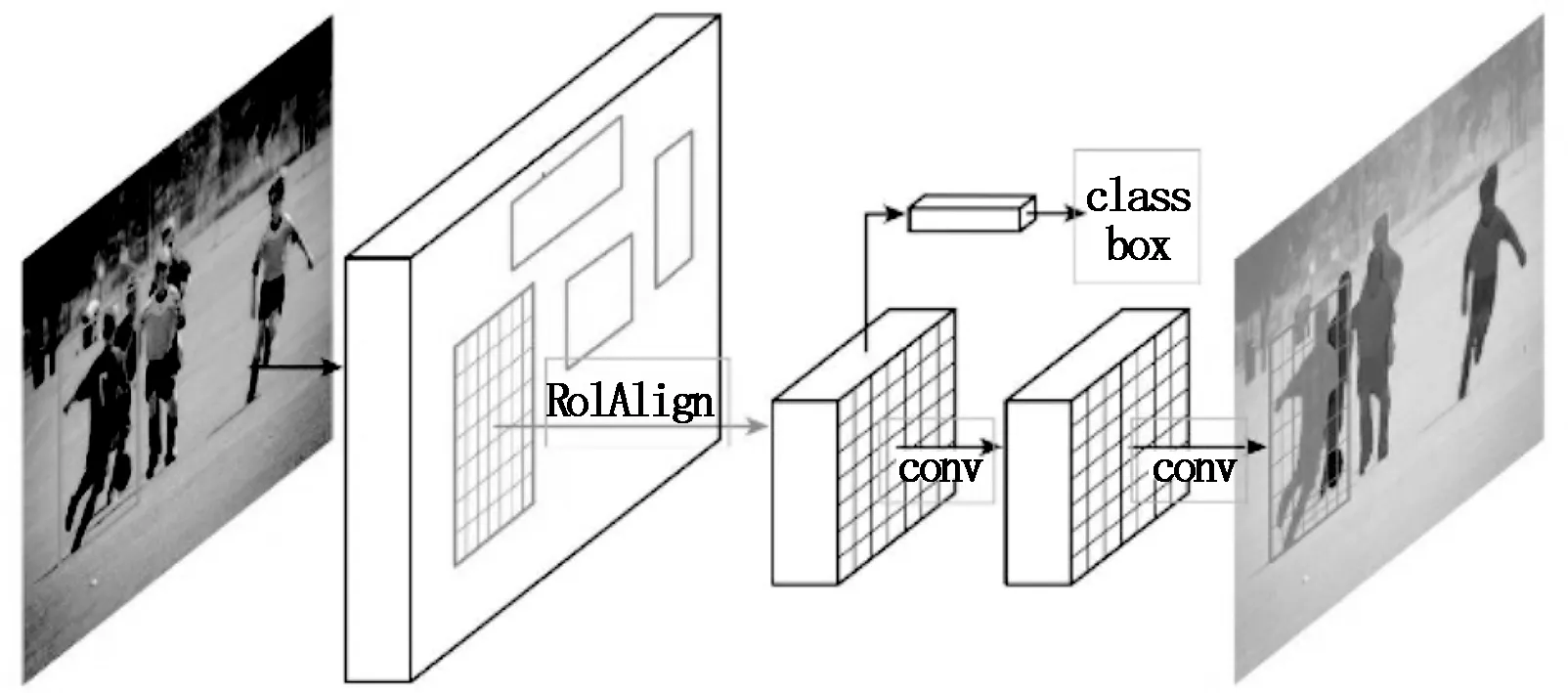
图1 Mask RCNN的网络结构[10]
1.1.2 RPN
RPN将任意大小的输入图像转换为一组含有分数的矩形框作为regionproposals,并同后续网络共享特征提取图中的特征信息,在输入的每个空间位置采样k个不同尺度的anchors。通过后续二分类网络对这些anchors进行评估,挑选出可能含有对象的anchors,并对其进行边界框的精修,作为目标候选区域。
与目标对象交并比(IOU,intersection over union)最大的anchors以及和至少一个对象的IOU不小于预设阈值的anchors将被作为proposal层中的正样本,其余作为负样本用以后续训练。
根据式(1)对RPN进行训练:
(1)

(2)
1.1.3 ROI Align
ROI Align是对ROI Pooling的优化。ROI Pooling利用空间金字塔池化[24],将RPN的输出作为输入,输出一组固定大小的特征张量作为后续处理的输入。但是ROI Pooling引入了两次量化操作,带来了量化误差,降低了ROI和其对应特征之间的一致性。针对此问题,ROI Align通过双线性插值法解决,对每个ROI先进行分割,之后在分割得到的每个子区域中采样K(K一般取4)个点,对每个点进行双线性插值得到其像素值,之后将最大的像素值作为该子区域的像素值。这种方式避免了引入量化操作带来的量化误差,实现了ROI与特征的一致,提升了后续分类以及回归框的精度。
1.1.4 头部网络
由于引入了特征金字塔生成不同尺度的特征图,所以需要根据ROI尺度选择特定层级的金字塔输出作为后续处理的输入,具体选择如公式(3):
(3)
式中,k0=5,w,h表示对应ROI区域的宽和高,224对应特征金字塔第五层的尺度。
经过ROI Align输出固定大小的特征张量,经过两层全连接网络之后分别传送给分类器和回归器,以实现目标对象的分类和边界框的回归。掩码分支的输入也由ROI Align产生,但其尺寸大小与分类和回归不同。
网络训练采用多任务损失函数,通过学习不断下降的损失函数的值,直至获得最优解。损失函数的公式由式(4)给出。其中包含了3项,分别对应分类损失,边框回归损失以及掩码分割损失。
L=Lcls+Lbbox+Lmask
(4)
Mask RCNN中使用固定卷积,这类卷积在空间采样上不够灵活,容易引入对象周边的噪声信息,干扰后续的识别与分类。针对此问题,本文引入可变形卷积来改进主干网络中的部分固定卷积,以实现更加灵活的空间采样。针对RPN网络产生的候选区域提出一种改进的Soft-NMS方法进行进一步筛选与整合,在降低候选框冗余的同时提升候选框的质量,从而达到提升目标检测性能的目的。
2 融合可变形卷积的Mask RCNN
本文将可变形卷积加入Mask RCNN中,从而得到更好的空间采样结果,并用改进的Soft-NMS进一步整合候选区域降低其冗余程度,最终实现对滤袋开口的有效、精确检测。图2给出了本文目标检测模型的总体结构。整个模型分为4部分,第一部分为主干网络,实现图像特征的提取工作;第二部分是RPN,用于候选目标的生成;第三部分是ROI Align,它将候选区域对应的特征映射池化输出为固定大小的特征张量,为后续处理做准备;第四部分是头部网络,由三个分支构成,分别实现目标类别的识别、目标边界框的修正以及目标掩码信息的生成。最后将掩码信息与边界框信息整合得到更为精确的定位。
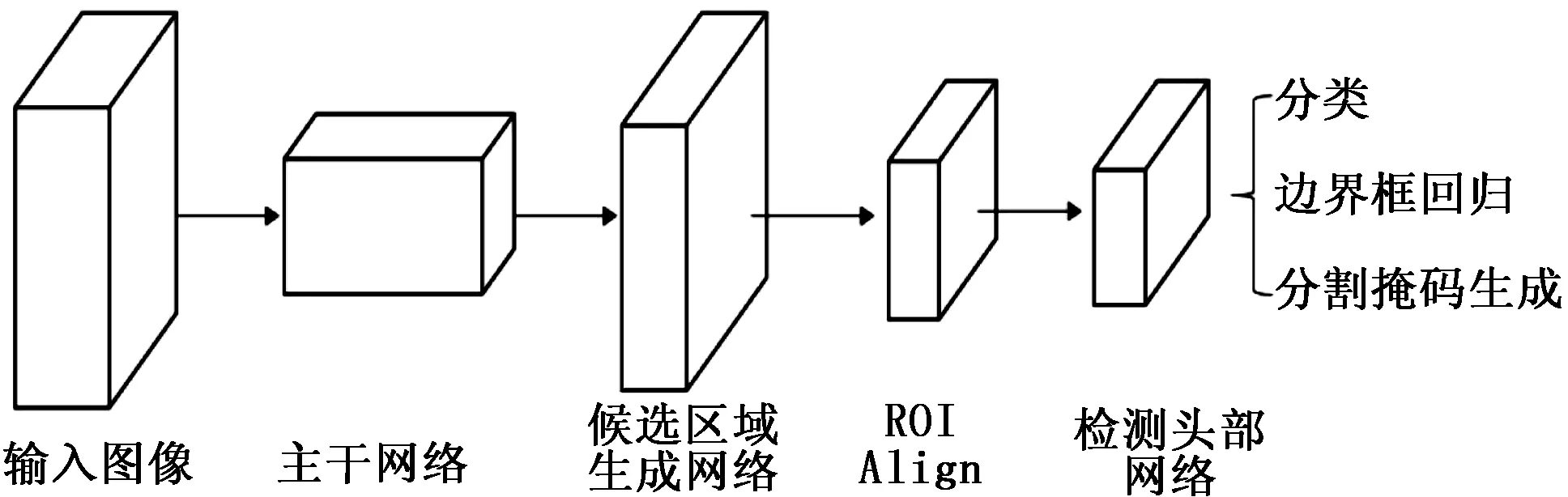
图2 融合可变形卷积的Mask RCNN网络结构
2.1 主干网络
本文选取残差网络作为提取特征的主干网络。残差网络利用跳接(skipconnect)形成残差块,通过堆叠残差块的方式构建残差网络。残差块可以用公式(5)表示:
y=F(x,{Wi})+x
(5)
其中:y表示残差块的输出,x为残差块的输入,F(x,{Wi})表示待学习的残差映射。
残差网络通过跳接结构,降低了随着模型深度的增加产生过拟合的可能性,为构建更深的模型提供了基础。
传统的卷积结构空间采样不够灵活,无法有效处理目标形变。本文引入可变形卷积对原始残差网络进行改进,替换掉其高层中的固定卷积层,从而更有效地实现对目标的特征提取,提升检测效果。
传统的卷积从数学形式上可以用式(6)表示,其中pn代表卷积核中每个点对应中心点的空间偏移,R表示卷积核对应的各个空间位置偏移。
(6)
相较于传统的卷积,可变形卷积引入了一个空间偏移Δpn,该偏移参数可以通过学习的方式获得。可变形卷积的表示如公式(7):
(7)
由于增加的Δpn一般是小数,并没有与之对应的输入,所以通过双线性插值的办法来获得这一位置对应的输入。
随着卷积网络的加深,顶层感受野的大小增加,高层语义信息变得更多,更适合分类,但同时也损失底层信息,这对小目标的检测会造成较大影响。因此本文构建特征金字塔(FPN,feature pyramid network)[25]来融合高低层级的语义信息,实现对各个层级卷积输出的捕获,提升对小目标的检测效果。将残差网络中conv2,conv3,conv4,conv5的输出分别用C2,C3,C4,C5表示。FPN在C5的输出上通过一个1×1的卷积,将其通道数由原先的2048降为256,获得特征映射图CP5。之后对CP5进行上采样,同时对C4的输出经过一个1×1的卷积将其通道数下降为256,使用特征图相加的方式将两者结合得到CP4。通过上述方式依次得到CP3,CP2,之后对CP2,CP3,CP4,CP5分别使用一个3×3的卷积以降低上采样带来的混叠现象,得到P2,P3,P4,P5,构成了特征金字塔。
2.2 区域提议生成
候选目标区域的质量与数目直接影响到目标检测的效果与速度。本文通过RPN方法利用anchor机制获得原始的候选区域,同时依据所用数据集中目标的尺度对anchor的大小做出了调整,调整后的参数为(32,64,128,256),长宽比为(1,0.5,2)。
RPN生成的原始提议框数目众多,在这些候选框中有些包含背景图像,为减少这类样本,提升候选框的质量,一般采用非极大值抑制对候选框进行筛选。由于PRN分类结果与候选框位置之间没有明确的线性关系,所以传统NMS方法会导致很多虽然重叠但是包含目标不一样的候选框被直接删除。为此,本文提出一种改进的Soft-NMS方法,Algorithm1给出了改进后的伪代码。
Algorithm 1: 改进的Soft-NMS方法
Input:B={b1,,bN},S={s1,,sN},Gt,其中B是一系列候选框,S是其对应的得分,Gt为IOU阈值
Output:O={o1,,om},S={s1,,sm},O为输出框,S为其对应的得分
Begin:
O←Ø
WhileB≠Ø do:
k←argmax{S}
K←bk
L←K
B←B-K
For biin B:
If IOU(K,bi)>Gt
L←L∪bi
End if
si←sif(IOU(K,bi))
End for
K′←f2(L)
O←O∪K’
End while
上述算法中,计算得分的公式由式(8)给出,最佳候选框位置调整的方法由式(9)给出:
(8)
(9)
式(9)中,k代表了同当前最高得分的候选框之间IOU大于阈值的候选框的总数,之后根据得分进行加权修正。
2.3 网络的联合训练
本文采取端到端的训练方式,将RPN网络的训练任务同主干网络以及头部检测网络的检测任务结合起来,通过构建一个多任务损失函数,训练整体结构。损失函数由式(10)给出:
Ltotal=Lcls+Lbbox+Lmask+Lrpn
(10)
主干网络部分采用在ImageNet上训练的ResNet50+DCN模型进行初始化,RPN以及检测头采用在COCO数据集上训练的参数进行初始化。本文采用梯度下降法进行神经元参数的迭代调整。
3 实验结果与分析
本文使用本实验室构建的滤袋数据集。为增加训练样本个数,通过旋转、裁剪以及翻转等数据增强方式对数据集进行了增广。使用labelImg工具对数据集进行标注。得到数据集1和数据集2,两个数据集共有样本1 000张。数据集1中包含8类不同圆形开口的滤袋,每类均有100张图像,按8:2的比例分为训练集和测试集。数据集2中含有2类不同椭圆形开口的滤袋,每类均有100张图像,同样以8:2的比例分为训练集和测试集。表1和表2分别给出了数据集1和数据集2的具体信息。图3和图4展示了数据集对应的部分图像。

表1 数据集1中每一类包含的图片数目

表2 数据集2中每一类包含的图片数目

图3 数据集1图片示例

图4 数据集2图片示例
3.1 评价标准
本文的评价指标为各类平均精度(mAP,mean average precision),中心偏移距离以及检测速度。本文对比的模型为Faster RCNN以及Mask RCNN两种主流的两阶段目标检测模型。
boxgt为真实值标签用(y1gt,x1gt,y2gt,x2gt)表示,预测框boxpred用(y1pred,x1pred,y2pred,x2pred)表示。两者之间的距离记作d=dis(boxgt,boxpred),可以根据公式(11)计算:
d=dis(boxgt,boxpred)=
(11)
其中:ygt=(y1gt+y2gt)/2,xgt=(x1gt+x2gt)/2,ypred=(y1pred+y2pred)/2,xpred=(x1pred+x2pred)/2。
本文的模型在数据集1与数据集2上进行评估。
3.2 参数设置
实验的硬件环境为Intel Corei5-9400 CPU,NVIDIA GTX 1080 GPU。软件环境为Tensorflow架构,实验语言为Python。训练时设置学习率为0.001,权重衰减系数为0.000 1,采用带动量的(SGD,stochastic gradient descent)优化器迭代训练,动量设置为0.9,训练迭代20 000次,batch-size设置为2。实验主要由以下几部分组成:第一个实验将对比本文算法与基准算法之间的性能差异;第二个实验为消融实验将验证提出的改进Soft-NMS方法的有效性;第三个实验将数据集1和数据集2合并,检验算法在输入类别增加情况下的鲁棒性。
3.3 算法比较
实验一:在本实验中,通过将Faster RCNN、Mask RCNN以及本文的融合可变形卷积Mask RCNN在滤袋数据集1上训练和测试,得到如表3展示的结果。图6给出了部分检测结果。

图6 在数据集1上检测的结果(示例)

BackbonemAP中心偏移距离FpsFaster RCNNVGG1688.124.341.12Faster RCNNResNet5090.620.621.23Mask RCNNResNet5093.213.720.95OursResNet50+DCN95.611.760.93
在表3中可以看到,本文的算法在中心偏移距离这一指标上优于对比算法,相较于Faster RCNN提升了11.58个像素。Soft-NMS过程对候选框的重整提高了这一指标。
本文构建的特征金字塔实现了特征的融合,提升了对小目标的检测精度,使得模型的漏报率下降,提升了模型的召回率。藉此,总体的mAP相较于没有特征金字塔结构的Faster RCNN也得到了提升。同时,可变形卷积带来了更加灵活的空间采样,引入改进Soft-NMS的区域提议生成网络提供了更高质量的候选框,给本文方法在mAP上带来了高于对比算法的性能,相较于Mask RCNN提升了2.4个百分点。
在检测速度方面,由于本文模型基于Mask RCNN构建,其增加了掩码分支且本文在模型中加入金字塔结构以及可变形卷积,在一定程度上提升了模型的复杂度,致使本文算法相较于Faster RCNN的推理速度有所下降,但是和Mask RCNN相当。
实验2:为了验证改进Soft-NMS的有效性在实验数据集1上进行消融实验。实验结果如表4所示。对比采用的是NMS方法,本文使用的是改进的Soft-NMS方法,其余部分两者相同皆为融合可变形卷积的Mask RCNN。可以看到本文提出的Soft-NMS方法相较于传统NMS在数据集1上mAP指标实现了1.2个百分点的提升,同时中心偏移距离提升了0.36个像素,验证了本文提出的改进Soft-NMS方法的有效性,经过重整的候选框质量确实优于原始候选框。
实验3:为了验证算法的泛化性能,本文用数据集1和数据集2对算法进行验证,结果如表5所示。可以看到引入可变形卷积并使用改进Soft-NMS方法后,本文模型性能依旧高于其他对比算法,证明了本文方法在增加对象类别之后仍然可以具有较好性能。为了进一步检验其性能,将来自不同数据集的对象放在同一环境采集,继续测试,结果如图7所示。实验结果证明本文模型可以有效地检测不同滤袋开口,具有良好的鲁棒性。

表4 改进Soft-NMS方法的有效性
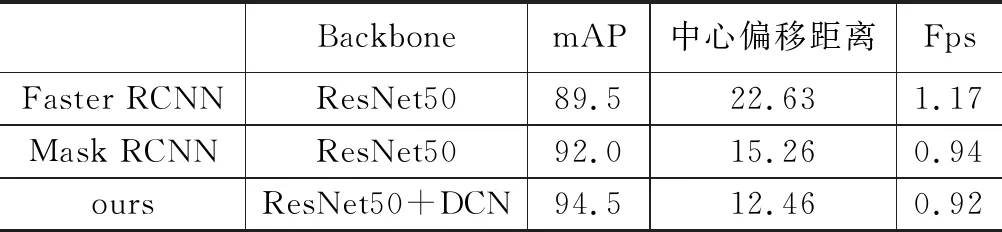
表5 在数据集1+2上的检测结果

图7 在同一图片中两种不同尘袋的检测效果
4 结束语
本文提出了一种基于深度学习的滤袋开口检测算法,实验结果表明,本文算法在滤袋开口检测问题上比传统基于深度学习的目标检测方法表现得更好,且检测速度较快。由于本文构建的数据集规模较小,后续工作中将尝试建立种类更为全面的大型数据集供滤袋开口检测算法的训练和测试,并且进一步通过剪枝算法压缩模型体积,提升运算速度。
