基于Doc2Vec和BiLSTM的老年患者疾病预测研究*
2021-01-05藏润强左美云郭鑫鑫
藏润强,左美云,郭鑫鑫
(中国人民大学信息学院智慧养老研究所,北京 100872)
1 引言
人体是一个各系统相互关联、协同运作的有机整体,疾病的侵入可以导致人体部分机能和生理体征发生复杂的关联变化,并且可能导致身体其他部位发生病变。老年人身体健康水平逐年降低,常常身患多种疾病。由于某些疾病的临床表现有着相似或相同的症状,导致医生确诊一种疾病后,忽视了相关疾病的识别。另一方面,疾病之间有一定的时序相关性,某些疾病随着时间的发展,可能会衍生出新的疾病。因此,研究疾病之间的关联性,可以在发现老年患者患有某种疾病时,预测可能引发其他疾病的风险,制定预防措施,以减少疾病风险对患者的影响[1]。
以前的许多疾病预测工作都是采用基于规则的方法,需要人工对疾病特征[2]进行诊断。后来,一些研究人员使用数据挖掘方法[3]自动地从临床记录中学习特征,为不同的疾病预测任务提供更好的结果。有些学者对冠心病、皮肤病、帕金森综合症和糖尿病等疾病的预测进行了基于数据挖掘和机器学习方法[4 - 6]的研究,达到了较好的预测精确度。
有的学者对多种疾病记录进行序列化处理,用于跟踪每位病人的个性化疾病预防方案。例如,Farhan等人[7]使用word2vec将疾病序列转换成语义向量,通过分析这些向量可以计算疾病之间的关联程度,成功估计了病人潜在的患病风险。可以用类似语义的向量说明疾病之间的关联关系,除了word2vec可以处理序列信息,还有传统的计算词语共现频数模型,如隐含狄利克雷分布LDA(Latent Dirichlet Allocation)和潜在语义分析LSA(Latent Semantic Analysis)等,但是这些模型忽略了词的顺序和词的语义问题。Baroni等人[8]证实word2vec模型优于传统的词语共现计数模型。Le等人[9]在word2vec基础上提出Doc2Vec模型,该模型在word2vec的基础上融入段落向量特征,实验证明该模型不仅优于传统的词语共现计数模型,而且还具有比word2vec更优秀的文本语义特征处理能力。
对于时间序列数据的处理还可以使用深度学习方法,Manashty等人[10]将疾病数据表示为一个适用于长短时记忆LSTM(Long Short-Term Memory)模型训练的固定长度时间序列,解决了无法处理变长稀疏的长时序序列问题。Tourille等人[11]利用双向长短时记忆BiLSTM(Bi-directional Long Short-Term Memory)模型抽取历史诊断记录的时序关系,实验结果表明该模型能够有效学习过去和将来的语义信息。
以前的研究多数是根据患者电子病历EMR(Electronic Medical Record)中的病状预测疾病(例如病人的病状为“微咳痰多,呼吸急促等”,根据该病状预测病人可能会患“寒哮证”疾病)[12],对疾病之间的相关性预测较少。因此,本文引入了一种新的电子病历表示法,该表示法考虑了医疗疾病的上下文感知信息,以Doc2Vec生成的词向量为基础,引入BiLSTM神经网络,提出一种基于Doc2Vec向量表示的BiLSTM疾病预测Doc2Vec-BiLSTM模型。该模型不仅能够提升疾病预测性能,还可以捕捉到疾病序列中更深层次的语义信息。首先,本文利用Doc2Vec在数据集上训练一个神经网络,将每个中心词及其上下文关系映射到一个矢量空间,进而提取每个医疗疾病的语义。通过计算语义相似性(通过嵌入向量空间中的余弦距离计算)可以反映上下文关联程度(例如,具有高度相似性的词语a和b倾向于出现在相同的上下文中)。其次,本文将BiLSTM模型中的每个神经元设置为双向LSTM,隐藏层的单元都会影响到相邻的隐藏单元,这种方法有助于模型更加准确地学习疾病的高级语义特征。最后在真实的医院数据集上评估本文模型,并对比多种数据挖掘模型[13]:逻辑回归LR(Logistics Regression)、决策树DT(Decision Tree)、K-近邻KNN(K-Nearest Neighbor)、卷积神经网络CNN(Convolutional Neural Networks)、随机森林RF(Random Forest)、支持向量机SVM(Support Vector Machine)和LSTM模型[14]。通过接收者操作特征曲线ROC(Receiver Operating Characteristic curve)对模型进行评估,对上述常用数据挖掘模型的疾病预测性能进行综合比较。
2 基于上下文和时间序列的疾病预测研究
本文在深入调查理解医疗数据的基础上,提出了针对老年人易发关联疾病的预测模型。该模型从老年患者的病历入手,将数据挖掘方法应用在病人的历史诊断记录上并做出疾病预测,并将预测结果与医生的实际诊断结果的对比作为预测性能的验证。预测模型框架如图1所示。

Figure 1 Framework of disease prediction model图1 疾病预测模型框架
在学习阶段,首先从电子病历EMR数据集中学习疾病诊断的结果,按诊断时间顺序将病人所有不同的入院诊断结果拼接起来形成疾病序列。然后计算每种疾病在EMR中的频数。为了避免数据不平衡问题而导致预测出罕见疾病,本文筛选出频数排在前面的20种疾病(即图1中的疾病选择),并将它们用作样本的多标签分类,每个病人序列包含多个诊断标签。多标签分类的目的是验证模型的泛化能力,保证模型尽量多地预测多种疾病,而不是单一的疾病。
在预测阶段,使用Doc2Vec将训练阶段的疾病诊断结果转换成医疗疾病向量,并将老年患者的医疗诊断记录映射到相应的医疗疾病向量。本文通过拼接的方法生成患者的组合向量,这个向量代表患者所有疾病的结果。最后将学习阶段的疾病多标签分类结果和预测阶段的病人向量拼接起来,放入构建的各种疾病预测模型中,进而分析对比每个模型的性能。
2.1 模型框架
本文模型的总体框架如图2所示。(1)将每位病人的历史疾病信息按照时间顺序进行排列。(2)将所有疾病序列输入到Doc2Vec模型中,生成相对应的词向量(Word Embedding)。(3)使用BiLSTM处理词向量,输出每一种疾病的预测概率。

Figure 2 Framework of Doc2Vec-BiLSTM model图2 Doc2Vec-BiLSTM模型框架
2.2 疾病时间序列结构
疾病时间序列结构由所在历史记录中的疾病和疾病的上下文组成,这里“上下文”是针对老年患者的EMR中每个医疗疾病诊断结果定义的。医疗疾病A的上下文是指在老年患者EMR主体内发生在疾病A之前和之后的医疗诊断结果。对于每位老年患者,可以根据其病历记录中记载的时间顺序将其EMR中的所有医疗疾病串联起来。因此,时间轴中特定医疗疾病的上下文与自然语言文本中词语的上下文相似。按时间轴生成的疾病序列如图3所示。

Figure 3 Disease sequence based on time axis图3 基于时间轴的疾病序列
在图3中,以一位病人的所有历史诊断记录为例,将早期入院诊断的结果作为历史的疾病序列,这个序列作为训练集,近期入院的诊断结果用于预测窗口的测试集。
2.3 上下文嵌入
Doc2Vec是一种可以处理可变长度文本的模型,Doc2Vec包含段落向量的分布式存储模型PV-DM(Distributed Memory model of Paragraph Vectors)和段落向量的分布式词袋模型PV-DBOW(Distributed Bag Of Words version of Paragraph Vector)。因为本文的目的是通过历史疾病序列预测潜在疾病的风险,所以,本文选用PV-DM模型。如图4所示,该模型利用3层神经网络对段落(句子)进行建模,即利用段落和段落中词的上下文信息预测该词,其中,上下文信息是按照固定的滑动窗口在段落上逐步进行采样获得。

Figure 4 PV-DM model图4 PV-DM模型
在PV-DM模型训练过程中,将所有段落和段落中每个词初始化为独热One-Hot编码向量。对段落向量与该段落的每个词向量求和,并将其作为投影层输入。最后,输出层的神经元使用Softmax函数,使得输出结果是一些具有概率分布的浮点值。整个过程的段落向量和词向量由随机梯度下降方法共同进行训练,其中段落向量是唯一的,可以将段落向量视为一个单词,它可以记忆当前上下文中缺少的内容,而词向量是共享的。经过训练之后可以获得段落和词的最优向量。
以文本段落中序列“w1,w2,…,wT={高血压,下肢静脉曲张,行走困难,脑血管病,下肢肿胀,重度骨关节炎,…,胸痛}”为例,T为序列长度,在训练过程中,文本段落的ID保持不变,由段落矩阵D中的Db表示,该段落中的每个词共享同一个段落向量。而每个词语也被One-Hot编码映射为一个独立的向量,本文使用矩阵M中的Mi来表示,Mi代表着这个词在词典中的位置。对段落向量和上下文中的词向量求和得到一个矩阵,用来预测上下文中下一个词的词向量特征。PV-DM模型[10]的目标是在给定上下文(假设窗口距离k=1,以序列中wt为脑血管病为例,其上文对应wt-1行走困难,下文对应wt+1下肢肿胀)和段落向量的条件下预测中心词(脑血管病)最大平均似然估计:
(1)
本文模型的预测任务由Softmax函数完成:
(2)
其中,yi表示输出词i的非标准化对数概率,其计算如下所示:
y=a+Uh(wt-k,…,wt+kDb;M+D)
(3)
其中,U和a是Softmax的参数,h是由D中提取的段落向量和M中提取的词向量求和构造的。段落向量和词向量使用随机梯度下降方法训练,这个梯度由反向传播BP(Back Propagation)算法获得。每一步随机梯度下降获得上下文信息,都是从一个随机的段落里进行采样得到的,通过PV-DM模型计算梯度误差并且使用该梯度更新模型中的参数。经过训练之后,解决了序列中词序和词之间的关联问题,具有关联的词会被映射到向量空间中相似的位置上,这样就可以把这些特征向量直接用到数据挖掘算法中进行预测。
2.4 BiLSTM模型
LSTM是一种循环神经网络RNN(Recurrent Neural Networks),模型结构如图5所示,它是在RNN的基础上加入“门控”来处理信息的传递。符合规则的信息会被留下,不符合规则的信息会被遗忘,有效解决了RNN的梯度消失或梯度爆炸问题[15]。LSTM的优点是可以捕获序列数据中的长期依赖关系,适合用于处理与时间序列高度相关的问题。

Figure 5 LSTM model structure图5 LSTM模型结构
以2.3节中使用Doc2Vec生成的疾病向量序列X={x1,x2,x3,…,xn}中的元素作为输入,输出向量由H={h1,h2,h3,…,hn}中的元素表示,对应输入中每一步序列的一些信息。ct为LSTM的记忆细胞状态,记录着不同时刻记忆单元的值,LSTM通过3个门结构来控制信息的通过,包括去除或者增加信息到记忆细胞,从输入到输出的过程如式(4)~式(9)所示:
ft=σ(Wxfxt+Whfht-1+Wcfct-1+bf)
(4)
it=σ(Wxixt+Whiht-1+Wcict-1+bi)
(5)
(6)
(7)
ot=σ(Wxoxt+Whoht-1+Wcoct+bo)
(8)
ht=ot⊙tanh(ct)
(9)
其中,σ(·)表示通过Sigmoid函数生成[0,1]的数值,⊙表示2个矩阵对应元素各自相乘。W为初始化权重矩阵,b为偏差。ft、it和ot分别为LSTM的遗忘门、输入门和输出门。
遗忘门ft将xt和ht-1作为输入,经过Sigmoid函数后,输出值在0~1,对应着旧信息ct-1的通过率。

输出门ot控制着输出信息,该门通过xt和ht-1共同决定从当前状态中可以输出多少信息,记忆细胞状态ct通过tanh函数得到-1~1的值,该值乘以ot作为当前时刻的输出值ht。

(10)
(11)
(12)
3 实验和结果分析
3.1 数据集
从某三甲医院电子病历数据库中获得了2016年11月~2018年3月期间311 429名60岁以上老年患者脱敏后的相关诊断数据。该数据包括有关患者的详细信息,如人口基本信息、入院、诊断结果和交费等信息,一共1 024 712条数据。首先对数据进行去重和对接,然后删除大量仅有一种疾病的老年患者记录。为了探索疾病序列,最后留下患有2种以上疾病的患者40 999名,其中61%的老人患有2~6种疾病,平均每位老人患病8.9种,各年龄段的老人患病数量如图6所示。

Figure 6 Number of diseases in elderly people at different ages图6 不同年龄的老人患病数量
3.2 基线
为了确定哪个数据挖掘模型预测效果更好,本文将Doc2Vec-BiLSTM模型与其他多种数据挖掘模型进行对比分析,如LR、DT、RF、KNN、SVM、CNN和LSTM模型。首先,将医疗疾病转换为One-Hot表示向量;然后,将疾病向量作为输入特征,输出为多标签分类;最后对20种常见疾病使用8种模型进行对比分析。
实验将Doc2Vec与8种模型分别组合进行预测,其中Doc2Vec采用以下参数:根据图6所示,平均每位老人患病8.9种,疾病序列较短,所以滑动窗口不宜设置过大,窗口过大容易导致无法关注序列的局部信息,窗口过小无法学习序列的全局信息,经实验验证,滑动窗口大小设为5,词向量维度为100最为适宜,8种模型的参数均为默认参数。
3.3 评价标准
为了评价模型的好坏,需要使用评估函数。本文采用通用的评价标准对实验结果进行评估:准确率Acc(Accuracy)[17]、ROC和ROC曲线下的面积AUC(Area Under Curve)[18]、F1值(F1 Score)[19]和p值(p-value)。准确率指所有预测正确的样本(包括正类和负类)占总体样本的比重;ROC是反映敏感性和特异性连续变量的综合指标;ROC曲线下的面积为AUC值,其值越大表示分类器性能越好;F1值准确率和召回率的调和均值;p值衡量模型之间的性能差异程度,当p值小于0.05时,表明模型与模型之间的性能有显著性差异,当p值小于0.01时,表明模型与模型之间的性能有极其显著的差异。
3.4 性能比较
实验包括对老年患者的20种常见疾病的预测,本文构建了一个多标签分类问题。在这个问题中,每位患者序列都可以标记多个诊断。只有当某个特定的诊断在医院确诊时(即预测窗口),患者才会被贴上标签。8种模型在对20种常见疾病的平均预测性能如表1所示,表1中训练时间和测试时间分为在GPU和CPU上的运行结果,括号前数字为模型在CPU上的运行时间,括号内数字为模型在GPU上的运行时间。

Table 1 Performance comparison of different models表1 不同模型的性能比较
从表1可以看出,BiLSTM性能比单向 LSTM 更优。虽然BiLSTM比LSTM多了一个反向传播的隐藏层处理过程,但是模型的训练和测试时间相比LSTM增加不多,而且BiLSTM可以考虑更多的上下文关系,而不是仅仅递进的前向关系。另外,在检验水平α=0.05下,BiLSTM与其他模型做差异性检验,得出p值均小于0.05,可知,BiLSTM模型的预测性能相对于其他模型具有明显优势。由此可知,Doc2Vec和BiLSTM的组合在所有组合中性能最好。
图7所示为BiLSTM模型在前8种疾病预测上的ROC曲线。其中,最高的AUC是重度骨关节炎,为0.96,最低的AUC是高血压,为0.86,不同疾病之间的AUC波动较小且ROC曲线都远离横纵轴对角线,说明BiLSTM模型的准确率高。

Figure 7 ROC curve of BiLSTM model图7 BiLSTM模型的ROC曲线
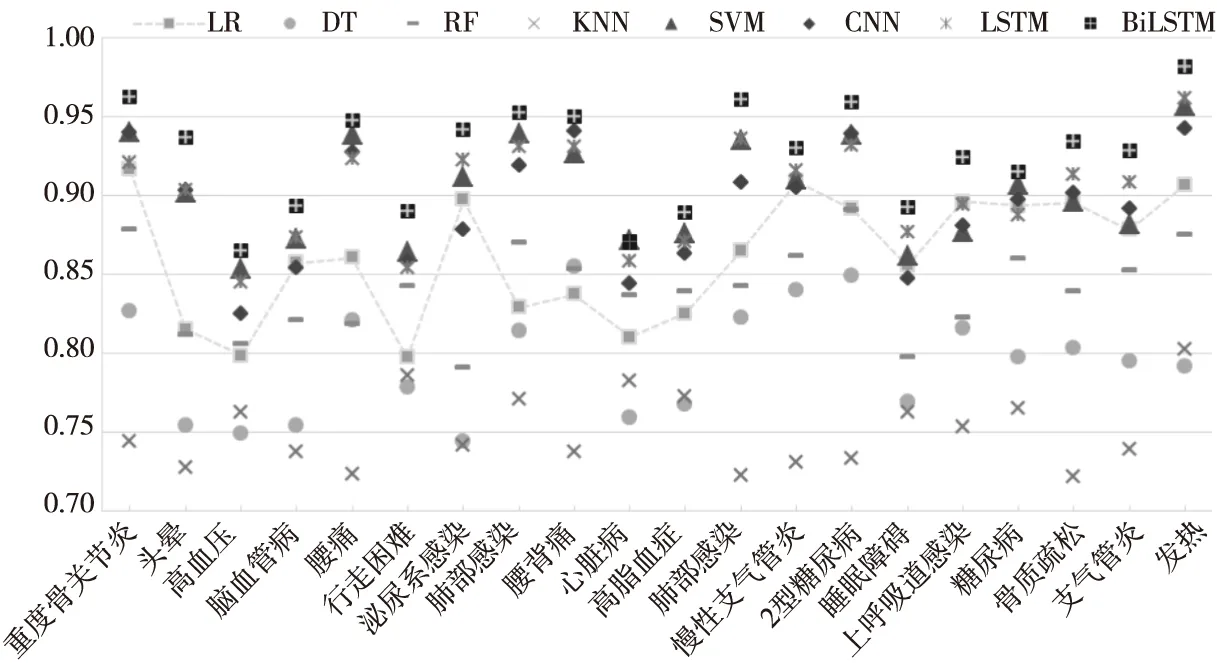
Figure 8 Prediction performance of 20 common diseases in elderly patients(AUC)图8 老年患者常见的20种疾病预测性能(AUC)
如表1所示,SVM具有较好的预测性能(AUC=0.91,Acc=86.49%,F1=80.42%),与除BiLSTM外的其他方法相比具有更高的准确率、AUC值和F1值。但是,SVM模型的训练时间和测试时间均比其他模型时间更长,其对一种疾病进行预测大约需要8 s,无法适用于处理实时数据的任务,而耗时最少的逻辑回归模型LR只需要0.02 s,但是其F1值比BiLSTM的低很多。
CNN的AUC为0.89,模型的预测性能接近SVM,比除SVM外的其他传统机器学习方法好很多,这样的结果可能得益于深度学习方法更适合处理具有时序性的数据。随机森林由多棵决策树构成,利用多棵决策树的平均结果进行预测,这样可以降低采样造成的偏差,所以其AUC值、准确率和F1值都要比决策树好(随机森林的AUC为0.84,决策树的AUC为0.80)。但是,决策树的优点是可以用层级树状图展示出疾病之间的关系。然而,树的深度越深,解释起来就越困难,过度拟合的风险也随之增加。
逻辑回归模型作为传统的统计学方法,具有模型简单且可以解释变量的优点,因此作为本文实验的基准线,在本文实验的整体评估结果中表现良好(其平均AUC值为0.86)。KNN模型的预测效果相对于其他模型表现较差(AUC=0.74,Acc=82.17%和F1=45.57%),模型测试时间为238.3 s。而当把模型参数n_jobs设置为-1时,KNN开始在多核CPU上运行,测试时间为46.84 s,速度快了近5倍,不过耗时仍然较长。8种模型对20种疾病预测的AUC值如图8所示。
由图8可知,在大多数情况下,无论采用哪种预测模型,AUC值都达到了0.72以上。可见使用Doc2Vec提取的特征向量包含丰富的文本语义信息,原因在于:从数据角度,本文研究的是老年病人患病的情况,每条数据内容较短,故本文利用字级别的文本向量表示方法可以提取到疾病之间更加细粒度的关联信息;从技术角度,Doc2Vec不是计算频繁出现或共同出现词的频数去度量疾病之间的关联程度,而是通过逐步采样上下文信息来度量词与词之间的关联,而且还考虑了词语之间的排列顺序对语义分析的影响。
4 结束语
人体疾病通常是有关联的。本文利用Doc2Vec模型提取出老年人前期疾病的语义信息作为特征向量,并结合BiLSTM建立后续疾病的预测模型,最后通过实验验证了Doc2Vec-BiLSTM模型在疾病预测中的有效性,同时分析对比了不同的数据挖掘算法在疾病预测方面的性能。
本文是自然语言处理在智慧医疗方面的一个重要应用,今后将进一步考虑融入更多的老年人特征来提升预测准确率,准确地判断哪些老年病会关联在一起,为医生诊治疾病提供决策支持,同时也为老人疾病预警提供有效的帮助。
