基于ISLI标准的科技文献和科学数据的关联
2021-01-05李欣怡姜恩波刘春江中国科学院成都文献情报中心中国科学院大学经济与管理学院
朱 江,李欣怡,姜恩波,刘春江,向 彬(.中国科学院成都文献情报中心;2.中国科学院大学经济与管理学院)
1 ISLI简介与应用现状
ISLI即国际标准关联标识符(International Standard Link Identifier),ISLI国际标准《ISO 17316:2015信息与文献——国际标准关联标识符(ISLI)》[1]于2015年5月15日正式发布,这是我国新闻出版界主导制定的第一部国际标准。与单一对象标识符不同,ISLI不以标识和识别单一对象为目的,而是主要用于标识两个实体之间的关联关系,并不改变实体的各种属性和标识,[2]其表现形式是一个带有关联信息(元数据)的标志码,以创建实体之间的关联,实现多个实体的关联、共同呈现等目的。这些实体可以是图文音像、数据、知识元等具有不同细粒度和表现形式的信息与文献领域内的所有具体实物,也可以是地理位置坐标、时间点等更为抽象的事物。[3]ISLI关联模型包括源、目标和两者之间的关联三个要素。[4]
关联关系是文献与信息领域不同类别、属性、细粒度实体之间尚待进一步挖掘与实现的宝贵资源,有着重要的现实意义。ISLI的提出、完备与推广对于定义相关实体间的关联关系有重要作用。①稳定可靠。在ISLI标准框架下,各实体就如同一个个 “零部件” ,通过ISLI编码实现彼此间共性主题的关联,同时各实体仍可保持其个体独立性,因为ISLI标准并不改变实体的独立形态及其原本功能。也就是说,依托ISLI标准构建的关联关系不会因为实体所处的仓储系统或其他客观环境的变化而失效。②原理简洁。不同于以识别和标识单一对象为目的的标识符,ISLI的关注点在于使用ISLI编码体系创建两个实体之间的关联关系,一旦编码标准的细节制定成熟完备,便可快速、低成本地盘活现存资源,以关联推进新的资源价值产生。③拓展灵活。在ISLI标准的编码方案中,关联字段所包含的数字编码的长度和结构均可由注册机构根据应用对象的分类和需要进行自定义,[4]ISLI标识符的编码结构采用了定长但不限长的十进制数字编码及相对自由的编码要素语法规则,因此,ISLI编码体系中的关联字段具有良好的可扩展性。
ISLI标准源自我国的多媒体印刷读物(Multimedia Print Reader,MPR)标准,[5]ISLI/MPR被视为ISLI标准最初的典型应用,并成功在国内外出版领域得到认可与推广。[6]随后,ISLI标准积极探索与更多领域的融合模式,并在知识关联服务(Knowledge Linking Service,KLS)、增强现实(Augmented Reality,AR)出版、插画等领域逐步形成ISLI/KLS[7]、ISLI/AR[8]、ISLI/WIS[9]等应用。国家新闻出版广电总局数字出版司于《新闻出版业 “十三五” 科技发展规划总体思路》规划中明确表示 “要大力推进ISLI标准在国内外的产业应用” 。[10]2018年5月,中国ISLI注册中心与中国科学院计算机网络信息中心就新闻出版与物联网标识的元数据共享开展合作,[11]这意味着ISLI的推广落地将在非新闻出版领域有所突破。
2 科技文献和科学数据的关联
科技文献是学者向社会展现其科研成果的重要途径之一,而科研过程中产生的科学数据实则与科研结果保持着同等重要的位置,其如同 “证据” 一般详实地记录着科研结果的推导过程,一些科学数据也已成为科研成果的重要表现形式之一。科技文献与科研数据间关系可谓紧密。随着认识的提高和技术的突破,人类进入了大数据时代,科学研究不可避免地也有了新的延伸方向:数据在科研中的地位逐渐重要,数据密集型科学作为科学探索的新的第四范式随之产生。[12]加之开放获取浪潮的不断推动,人们对于科技文献中相关科学数据的可获取性呼声日益高涨,诸如GBIF、DataStaR、OTA之类的数据仓储平台应运而生。目前,有学者基于数字对象唯一标识符(DOI)、元数据等角度对科学数据和科技文献的关联展开了研究。[13,14]ISLI标准的出现为实现科技文献和科学数据的标准化关联提供了新的解决方案,同时也有利于提升两者间关联关系的稳定性和复用性。
以科学数据原创性和独立性为标准,可将科学数据分为科技文献内科学数据和科技文献外科学数据。[15]前者指在某项科研过程中具体产生的原始科研数据,与科技文献内容完全整合在一起,通常以表格、数字、图像等格式呈现,此类科研数据并未被单独存储,而是依附于科技文献,文献本身即为此类科研数据的天然载体,对这一类科研数据通常以文献引用代替数据引用;后者是指与科技文献分离、独立存在的科学数据,通常来自于特定数据仓储平台的科学数据集和数据记录。目前,还出现了以刊载和发行规范化科学数据为主要目标的数据出版物,如数据期刊和数据论文,这种类型的科学数据可作为直接引用源。
科技文献、科学数据的关联形式多样、类型复杂,主要的关联形式有以下三种。[16]①硬关联。一篇科技文献与它在特定数据仓储平台提交的科学数据集之间的关联,呈现一对一或一对多的关系。这种关联是有意识的、人为的关联,主要实现科学数据与其来源科技文献形式上的关联。②软关联。一篇科技文献与它引用的科学数据集或主题、内容相关的科学数据集之间的关联,大多数情况下是一对多的关系。这种类型的关联是从某一特定内容出发,将与该内容相关的多方科技文献和科学数据进行集成,可为用户参考提供便利。但这种关联尚不成熟,准确性有待考证。③其他关联。一篇科技文献与在出版、传播过程中由编辑或同行科技工作者添加的其他科学数据集或解析工具之间的关联等。上述关联均可利用ISLI模型实现。
科技文献和科学数据并非最小的关联单位,可将其解构成细粒度更小的知识单元。如果把独立的单篇科技文献和独立的单个科学数据集看作 “资源” ,把科技文献和科学数据集中更小的知识单元看作 “知识” ,则可将科技文献、科学数据集之间的关联划分为四种类型(见表1)。根据上述关联类型,可在ISLI标准元数据集的基础上对关联类型元数据项、关联对象及取值范围进行扩展,同时对ISLI关联编码体系进行定义。
3 科技文献和科学数据关联的ISLI元数据集扩展
3.1 ISLI标准元数据集的扩展
(1)关联类型的扩展。在ISLI标准元数据集的基础上,对科技文献和科学数据集的关联类型元数据项进行扩展,划分为上述的四种类型,并预留进一步扩展的空间。
(2)关联对象的扩展和规范。科技文献具有诸如论文、图书、研究报告等多样的表现形式,而科学数据分为原始性基础数据与按照不同需求加工后的数据集和相关信息。不同的科技文献和科学数据之间的关联位置、层级、程度不可能千篇一律。因而对于关联对象而言,其取值范围、取值标准和校验方法亟需得以扩展与规范,以便区分与囊括不同类型和细粒度的关联对象,打破载体和介质的屏障,直接进入内容资源层建立一套具有统一规则的、完整的关联关系。
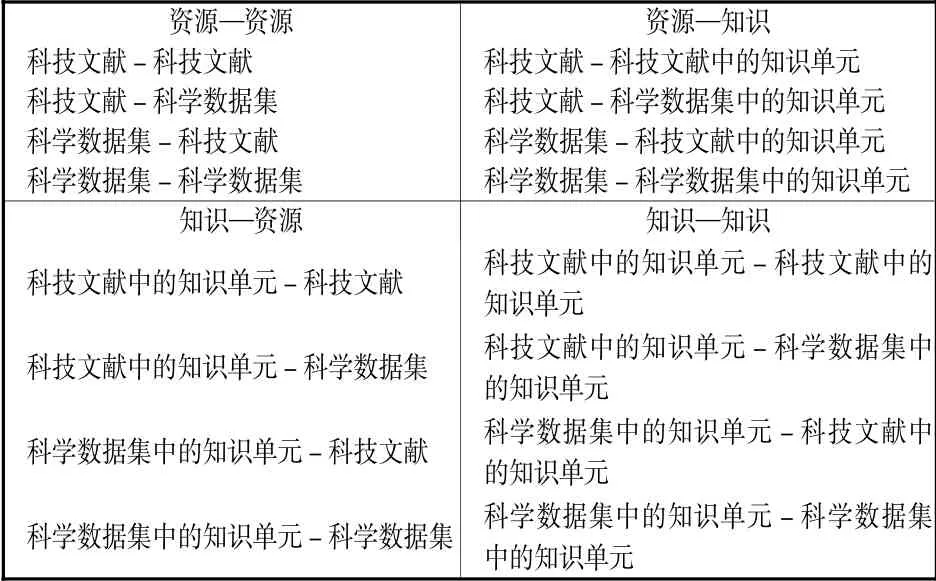
表1 科技文献与科学数据集的关联类型
(3)关联行为元数据项的扩展和作用。实体间存在目的不同的关联行为,可参照Subject-Action-Object(SAO)的语义表达结构理念,在ISLI关联的 “源” 和 “目标” 中间增加一个关联行为元数据项,其作用相当于SAO中的 “A” ,以便对庞大的关联编码进行聚类。关联行为元数据项的取值可根据实际应用不断扩展,以适应不断创新、变化的关联行为。
3.2 命名实体的抽取及KOI标识的建立
出于对海量实体及实体种类 “身份” 管理的需求,需要对 “有意义” 的实体进行唯一性标识,并通过识别、抽取命名实体和创建实体唯一标识符实现对实体的准确性、系统性管理。①明确命名实体的命名规则及组织、保存和更新规则,以便对不同类别的实体进行有效归类、检索,明确实体边界,便于机器学习,实现对命名实体的自动抽取、命名、保存和更新。②建立KOI(知识对象标识符)标识。ISLI关联的是 “源” 和 “目标” 两个实体,虽然ISLI标准规定 “源” 实体一般是确定的, “目标” 实体可以是确定的也可以事后确定或建立,但 “源” 和 “目标” 作为实体,除了实体名称外,一般还应建立一个唯一标识符。独立的单篇科技文献和独立的单个科学数据集可被视为粒度较粗的 “资源” 层面,该层面现已存在数字对象标识符(DOI)作为唯一标识符。但对于科技文献和科学数据集中的知识实体(或知识单元)还尚未建立统一且被广泛使用的唯一标识符体系,在此可借助KOI[7]对系统内抽取出来的知识实体(或知识单元)进行标识和存储。由于KOI尚无公认的标准,因而只能在一定范围内解析使用。
4 科技文献和科学数据关联的ISLI编码体系设计
ISLI编码由十进制数字构成,分为服务字段、关联字段和校验字段。参照相关文件,[4]一个ISLI编码的形式如图1—图3所示(连字符 “-” 及 “ISLI” 并不构成标识符的组成部分,只为便于阅读)。服务字段的编码一般为6位,由ISLI注册中心(ISLI RA)分配;关联字段的编码长度可变,具体长度、结构由ISLI RA根据应用需求进行定义,如果分段,一般可细分为前置编码和后置编码两部分;校验字段的数值(校验码)由ISLI系统依据规则自动计算。[4]

图1 图书、音像制品ISLI编码字段结构
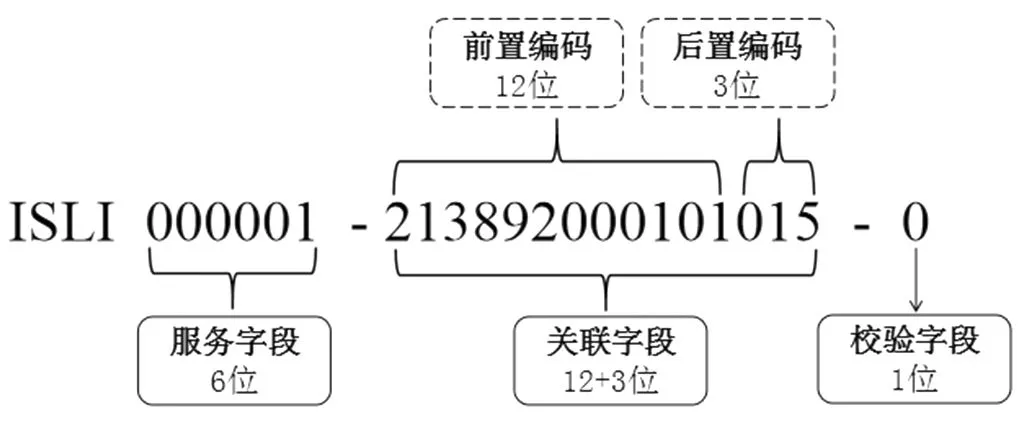
图2 连续出版物ISLI编码字段结构

图3 以互联网传播的音频内容产品ISLI编码字段结构
在科技文献和科学数据关联服务中,假设服务字段为 “200000” ,关联字段的前置编码为10位数字,容有100亿个码段,可在不扩容情况下供100亿个独立的科技文献或科学数据集使用;后置编码为5位数字,容有10万个无重复的编码,除去用于标识1个科学文献或科学数据集和它的元数据之间关联的 “00000” 这个特定的ISLI标准标志码外,还有99,999个ISLI标准编码可用于标记该实体与该实体内部的知识单元、外部其他实体(包括外部其他科技文献、科学数据集及其包含的知识单元)的各种关联,并使用经过扩展的ISLI标准元数据集来表示各种复杂的关联。
如 “10+5” 的关联编码字段容量不足,还有根据实际需要增加关联编码字段的长度,变成 “10+6” 或 “12+6” 等形式,以容纳更多的关联编码。
为了更加具体地说明科技文献和科学数据的关联是如何基于ISLI标准来实现的,特举例如下。论文A根据 “2018年成都市日降水量观测记录表” 汇总了一张 “2018年成都市月降水量统计表” KOI(a),并与已获得DOI(B)的论文B中的 “2018年武汉市月降水量统计表” KOI(b)进行了比较。论文A发表后获得DOI(A), “2018年成都市日降水量观测记录表” 按要求提交到数据仓储平台,获得DOI(a);将DOI(A)的ISLI关联编码的前置编码定为 “1000000001” ,DOI(a)的ISLI关联编码的前置编码定为 “1000000002” ,而后置编码按一定的编码段或流水号顺序分配的话,则可形成最基本的关联和ISLI关联编码(见表2)。相应地,对于DOI(B)、KOI(b)来说,也可以采取类似的方法,将它与科技文献及其他科学数据集的关联标识出来。
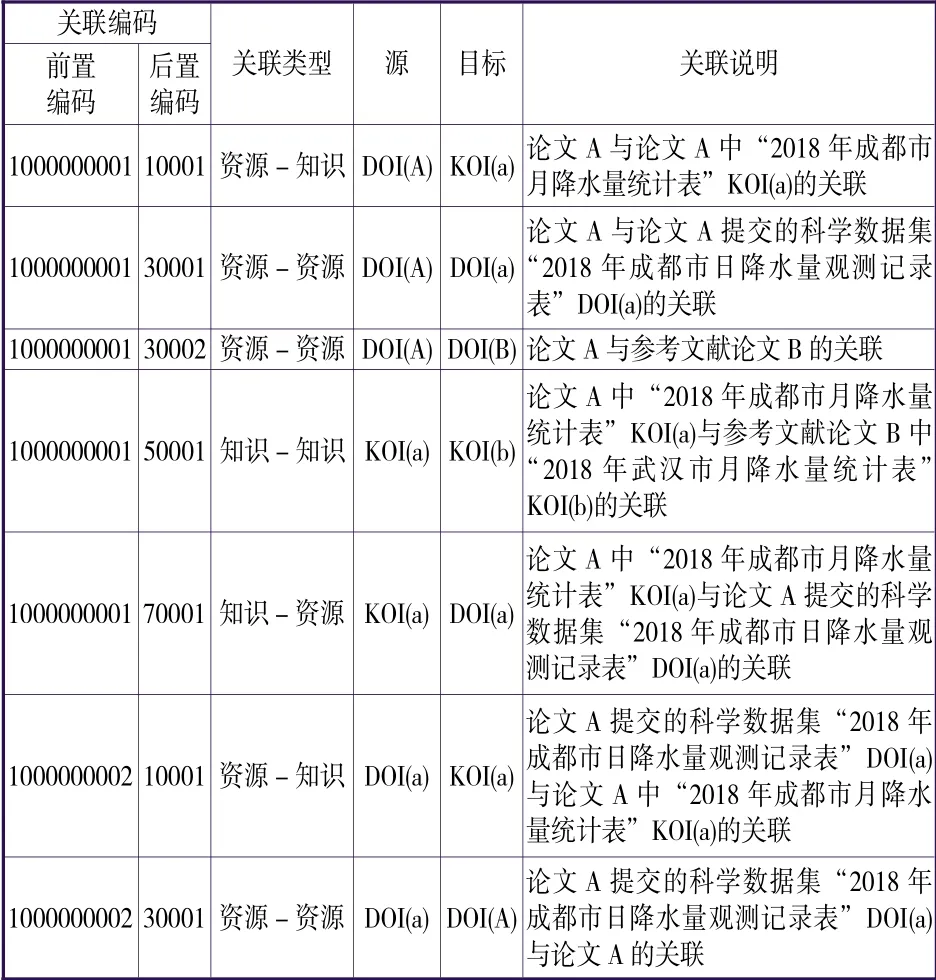
表2 基于ISLI标准的科技文献与科学数据集的关联
将上述ISLI编码及其元数据存储到科技文献和科学数据关联服务系统中,并提交给ISLI注册服务中心,即可在ISLI服务系统的支持下实现ISLI编码的解析和服务。
5 结论
对于科技文献和科学数据关联中存在的 “源” 和 “目标” 细粒度不同、关联类型多样等问题,ISLI标准以其稳定可靠、原理简洁、可拓展性强等较为独特的优点提供了一种角度新颖的解决途径。在科技文献和科学数据关联的具体实践中,以标识符定义被关联对象之间的关联关系,有利于快速发现并精准定位到所需的高品质内容,同时也使得科技文献和科学数据之间的引用与考证变得更加容易。应全面总结科技文献和科学数据关联的类型,并借鉴ISLI标准的其他典型应用案例,完善基于ISLI标准的科技文献和科学数据关联标准,以充分展现科技文献和科学数据的关联。
