基于贝叶斯模式平均方法融合多源数据的水文模拟研究
2021-01-04尹家波郭生练曾青松刘汉武
尹家波,郭生练,王 俊,朱 青,曾青松,刘汉武
(1.武汉大学 水资源与水电工程科学国家重点实验室,湖北 武汉 430072;2.安徽省水利水电勘测设计院,安徽 合肥 233010;3.安徽省合肥水文水资源局,安徽 合肥 230022;4.安徽省巢湖气象局,安徽 合肥 238000)
1 研究背景
高质量的长系列降水和气温数据是灾害预警防控、农业生产管理、生态保护、流域水文模拟以及水利工程规划设计的重要基础资料[1]。传统的气象数据主要依赖于站点观测,但是气象站网通常密度较小且空间布设不均,难以准确反映气象变量的时空变化特性,不能满足高精度水文模拟等工程应用需要[2]。
近年来,卫星遥测技术和数据反演算法快速发展,基于卫星遥感反演的降水定量观测产品具有较宽的覆盖范围和更高的时空分辨率,有效弥补了气象站点布设不足的缺陷,并为无资料地区提供了新的数据参考[3]。目前已有一系列高精度卫星降水产品发布,如PERSIANN、CMORPH、GSMaP、TMPA 以及GPM 等降水数据集,并被广泛用于旱涝灾害和气候变化等领域的研究和应用[4-5];同时,随着人类观测手段和数据同化技术日渐成熟,学者们对多种来源(地面、船舶、无线电探空、测风气球、飞机、卫星等)的观测资料进行质量控制,提出利用数值天气预报的数据同化技术来重构长期历史气候过程,即所谓的再分析数据集[6],它同化了数值天气预报和大量的地面观测数据与卫星遥感信息,具有时空分辨率精度高、时间跨度长等优点,被很多学者作为接近真实观测的数据使用[7]。目前应用较为广泛的再分析数据集,包括欧洲中期天气预报中心(ECWMF)的ERA-Interim、美国国家环境预报中心的CFSR、美国航空航天局的MERRA 以及日本气象厅的JRA-55 等[8]。气温变量是再分析数据集的B 类产品(数据质量较为可信),已经在气候变率和变化、全球水循环和能量平衡以及大气模式评估等诸多研究领域得到应用[9]。但是,受限于遥感精度、反演算法、数值预报模式和同化方案等影响,卫星降水和再分析气温数据均具有较大的系统偏差,难以直接应用于流域水文模拟[10]。目前国内文献主要集中在评估反演数据集在我国不同气候区气象、农业和水文等领域的适用性[11-12],国外部分研究校正了降水气温数据集的系统偏差[13],但是不同的偏差校正方法存在一定差异,如何融合各方法的优势并评估其在流域水文模拟中的适用性有待探讨。
本文融合有限的地面气象观测数据、国际上较新的长系列高精度MSWEP-V2 卫星集成降水数据集和欧洲中期天气预报中心的ERA5 气温数据,首先通过基于分位数映射的日偏差校正(DBC)、基于月尺度的回归校正(LRBC)和等率校正(RBC)等3种偏差校正方法,对遥测栅格降水和再分析气温日系列进行校正,再采用季节性贝叶斯模式平均(Bayesian Model Averaging,BMA)方法求解各偏差校正系列的后验分布优选相应权重,得到融合多种偏差校正模式的日降水、气温系列,最后驱动新安江、GR4J和HMETS 水文模型评估其流域水文模拟的适用性及精度。
2 研究区域与数据来源
2.1 研究区域巢湖流域位于安徽省中部,属长江下游左岸水系,发源于大别山余脉和江淮分水岭,主要支流杭埠河、南淝河、派河、十五里河、白石天河、柘皋河和兆河等河流呈放射状注入巢湖,流域控制面积13 486 km2,覆盖范围为东经108°35′—111°35′,北纬29°33′—30°50′。巢湖是我国五大淡水湖和“三河三湖”之一,具有防洪、灌溉、供水、航运、水产等多种功能,也是“引江济淮”工程的重要输水区。长系列气象水文数据是开展巢湖流域水旱灾害治理、蓝藻水华防控、水生态修复和引江济淮工程优化调度的重要依据,但是目前巢湖入湖39 条河道仅有2个系列不完整的水量监测断面,制约了巢湖流域规划和水资源综合管理,亟需依托气象资料开展流域的长系列径流回溯模拟工作。
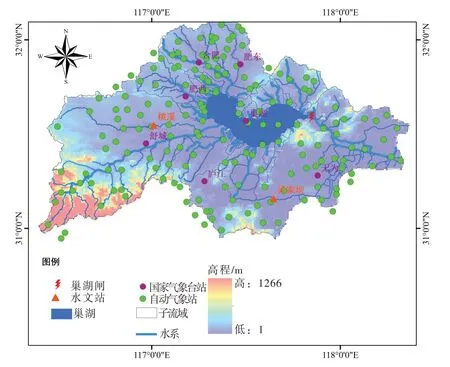
图1 巢湖流域气象水文站点分布
2.2 数据
2.2.1 地面观测数据 巢湖流域设有7个国家基本气象台站,涵盖1955—2019年的日降水量(Pday)、日平均气温(Tmean)、日最高气温(Tmax)和日最低气温(Tmin)资料;流域内近年来设立了174个自动气象观测站,包括2015—2019年的日气象系列;本文为评估水文模拟的适用性,搜集到巢湖最大支流杭埠河的桃溪水文站1955—2017年日流量过程,以及西河的梁家坝水文站2005—2014年日流量过程,流域内气象水文站点分布如图1所示。
2.2.2 MSWEP-V2 卫星集成降水数据集 Multi-Source Weighted-Ensemble Precipitation Version 2(MSWEP-V2)数据集是Beck 等[14]生成的一套1979—2017年具有0.1°空间分辨率和3 h时间尺度的全球栅格化降水产品,该产品集成多个卫星反演数据源(包括CMORPH,GridSat,GSMaP和TMPA 3B42RT 等)、76 747个全球地面站点观测资料(包括WorldClim,GHCND,GSOD和GPCC 等观测数据源)和再分析数据源(ERA-Interim和JRA-55),采用全球13 762个径流站的实测数据基于水量平衡对陆地降水过程进行了偏差校正。MSWEP系列数据集是目前国际上时空精度最高的降水数据源之一,已经在对地观测、气候系统演化分析、气象灾害预报预警等领域得到广泛应用[15]。基于MSWEP-V2降水数据集,将3 h 降水过程进行累积获得巢湖流域1979—2017年的栅格化日降水系列。
2.2.3 ERA5 数据集 欧洲中期天气预报中心(ECMWF)的第五代再分析气候数据集ERA5 提供了自1979年以来的逐小时再分析资料,并实时更新。该产品采用四维变分分析(4D-Var),结合改进的大气湿度分析和卫星反演偏差校正等技术显著提高了数据质量和时空分辨率。ERA5 数据集逐小时分析场的水平分辨率为31 km,垂直分层137层,顶层达到0.01 hPa 高度(约80 km);采用了综合预报系统的Cycle31r2模型版本,以光谱谐波分辨率T255为基础,通过双线性插值技术将简化的高斯网格(N128)数据插值到0.25°至2.5°等多种不同分辨率栅格,ERA5 气候数据集是目前时空分辨率最高的全球再分析数据之一。基于ERA5 数据集的0.25°×0.25°逐小时气温系列,得到巢湖流域内各栅格1979—2019年的日平均气温、日最高气温和日最低气温系列。
3 遥测栅格气象数据偏差校正方法及流域水文模拟技术
3.1 偏差校正方法MSWEP-V2和ERA5 数据集结合了多个全球数据产品,但考虑的气象站点数据主要为月尺度,例如MSWEP-V2 基于全球GPCC的月降水进行校正;同时,这两个数据集所采用的实测站点在中国分布较少,其中GPCC 仅包含中国194个气象站[16],难以满足中小流域水文模拟的实际要求,故需要开展偏差校正研究[15-16]。分别采用基于分位数映射的日偏差校正(DBC)、基于月尺度的回归校正(LRBC)、等率校正(RBC)和季节性BMA 等4种方法,校正巢湖流域MSWEP-V2 降水和ERA5 气温数据集的系统偏差。
3.1.1 基于分位数映射的日偏差校正(DBC)方法 DBC方法常用于校正全球气候模式(GCM)输出数据的系统偏差,它假定历史期和未来时期气候变量在各分位数具有相同的模拟误差,通过结合LOCI(Local intensity scaling)和分位数映射两种方法,依次校正日降水系列的发生频率和量级。本文将DBC方法引入卫星集成及再分析数据集的偏差校正领域,将地面站点的观测阶段当作GCM的历史期,将需要回溯反演的时段作为GCM的未来时期。首先,基于LOCI方法校正降水的发生概率,以0.1 mm 作为实测降水的发生阈值,依据实测的日降水在不同月份的发生频率确定模拟系列各月份的降水阈值,当日降水量高于此阈值时判定为有雨天,反之则为无雨天,由此使实测和模拟系列的降水发生频率一致;然后,计算实测的日降水(气温)和历史期模拟系列在各月份频率分布函数的系统偏差,并推求各分位数对应的校正系数,最后将该系数用于校正模拟的长系列气象数据,具体计算公式如下:
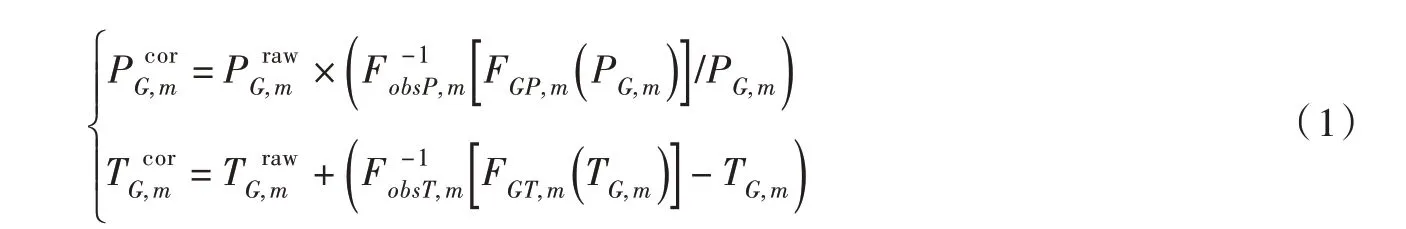
3.1.2 基于月尺度的回归校正(LRBC)方法 Aghakouchak 等[17]提出附加误差校正模型(additive error adjustment model)用于建立地面观测降水和卫星反演降水系列的回归关系,其本质是采用线性回归(Linear Regression Bias Correction,LRBC)方法对降水量级进行校正。考虑到栅格气象数据产品在不同月份的气候描述能力可能存在差异,故对各月份气象站点的实测日降水(气温)和MSWEP-V2 栅格日降水(ERA5 气温)建立回归关系(即建立12个LRBC模型),如下:

式中: Pobs,m和Tobs,m分别为第m月的实测日降水和日气温;PG,m和TG,m分别为同一时期的模拟降水和气温系列;aP,m和bP,m(aT,m和bT,m)分别为降水(气温)系列的回归系数,采用最小二乘法估计;ε 表征模型残差,一般可假定其服从标准正态分布。
3.1.3 基于月尺度的等率校正(RBC)方法 等率校正(Ratio Bias Correction,RBC)方法假设卫星反演降水(或再分析气温数据)和地面观测系列的月偏差在不同时期具有一致性,首先基于地面观测信息计算各月份的校正因子,再将该因子应用于同一月份的长系列模拟数据集。该方法易于操作且效果较好,近年来广泛应用于卫星反演降水产品校正领域[18]。本文对气象站点的每一个月份,分别基于观测资料和模拟系列计算该月份的偏差比率(降水)或绝对偏差(气温),获得相应的校正因子后利用下式校正卫星降水和再分析气温系列:
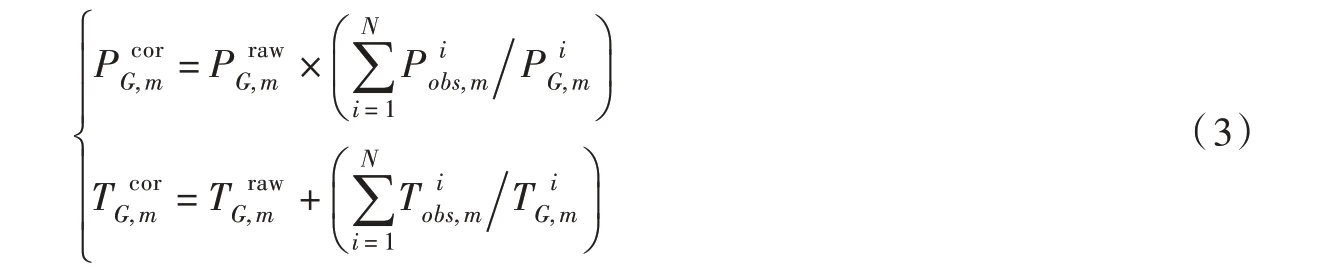
式中:N为站点第m月的总观测日数;i为日降水或气温系列时序。
3.1.4 季节性贝叶斯模式平均(BMA)方法 BMA是一种统计后处理方法,在水文领域最早应用于水文气象预报及其不确定性评估,它依赖所有集合预报成员,而不是单一的“最优”预报模式,通过考虑多成员内部的不确定性从而改进预报结果。本文使用季节性BMA方法融合DBC、LRBC和RBC 三种偏差校正方法,得到的长系列气象资料过程,以期提高气象变量的校正精度。
采用观测期各季节的站点实测气象系列和各偏差校正方法模拟系列,率定相应的季节性BMA模型,令S为校正变量(日降水或气温),R=[D,O]表征模型输入数据(其中D为训练期各方法的校正系列,O为实测系列),为K个不同校正模式(本文取K=3)的输出结果,由贝叶斯全概率公式可得S的概率密度函数如下[19]:

BMA方法可以通过各模式偏差校正效果的相对贡献来优选相应权重,最终输出的校正系列是各模式校正系列的加权平均结果,当校正变量服从正态分布时,可基于正态线性分布假设推导BMA方法的校正公式如下:
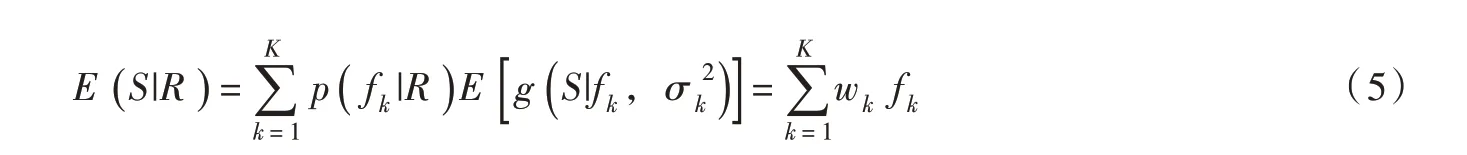

BMA模型代求的参数设为首先通过Box-Cox 函数将气象站点观测系列和各校正方法得到的模拟系列进行正态转换,再将θ似然函数的对数形式表示如下:
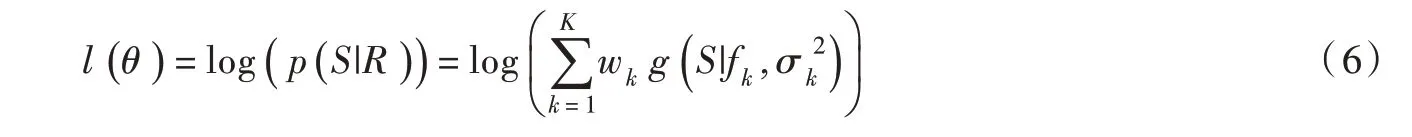
式(6)难以直接得到解析解,可采用期望最大化(EM)算法[19]得到收敛的极大似然值,从而求得的数值解。在EM 算法中,首先定义隐藏变量,具体迭代步骤如下。
(1)初始化(设迭代次数Iter=0),给定各模式的初始权重和方差:
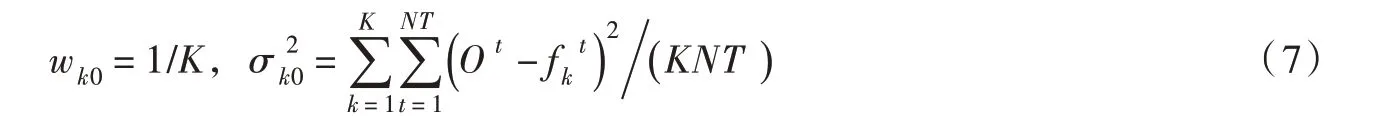
式中:NT为训练期的系列长度;Yt和分别为t时刻的实测数据和第k个模式的校正值。
(2)计算初始参数的似然值:
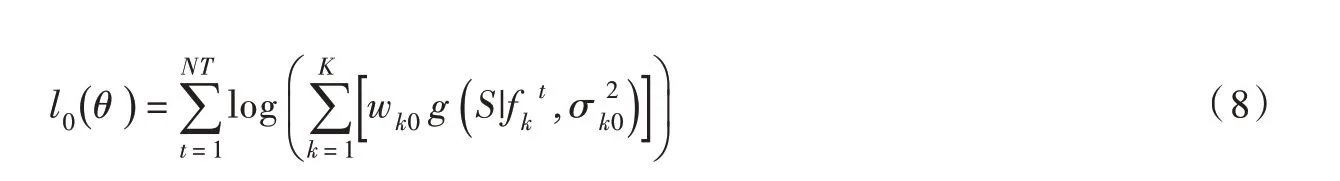
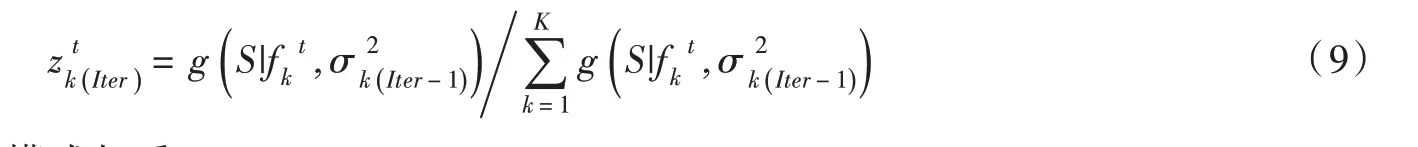
(4)依据隐藏变量计算各模式权重:

(5)重新计算各模式的偏差:
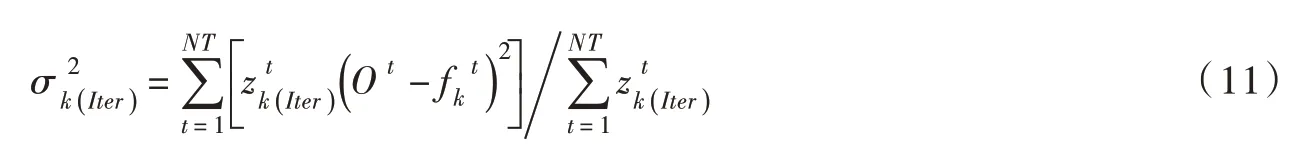
(6)计算第Iter 次迭代状态下参数的似然值:
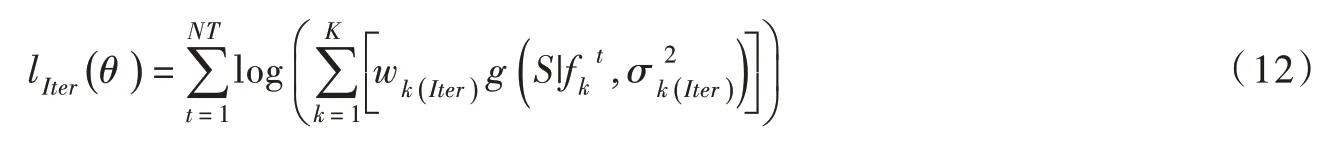
3.2 水文模型及参数率定方法为了评估校正后的MSWEP-V2降水和ERA5 气温数据集在流域水文模拟中的适用性,采用BMA模型校正的长系列气象数据分别驱动新安江、GR4J和HMETS模型,其中HMETS是近年来应用较多的是概念性集总式水文模型,包含渗流区以及饱水带两个相连的水库模块串联;涉及蒸散发计算、渗流、融雪积雪以及河道汇流过程[16]。采用复合型混合演化(SCE-UA)算法优选水文模型参数,该算法是一种全局优化算法,它集成了随机搜索算法、单纯形法、聚类分析及生物竞争演化等方法的优点,能有效处理目标函数反映面的不敏感和不凸起等问题,且不受局部最优点的干扰[20]。
3.3 校正精度及水文模拟评价指标为了综合评价卫星集成和再分析气象数据校正前后对极端和均态气象事件的模拟能力,采用表1列出的37个指标作为气象变量校正精度的评价指标。表中所涉指标分为3 类,第一类主要评价模拟数据集对年均值和各月均值的观测能力,第二类用于评价年标准差和各月标准差,第三类主要表征11个不同分位数的气象事件。采用Kling-Gupta efficiency(KGE)、纳西效率系数(NSE)、模拟径流量与实测径流量序列的相关系数(CC)、平均绝对误差(MAE)和相对偏差(RB)作为水文模型径流模拟精度的评价指标,各指标计算方法如下[16,21]:
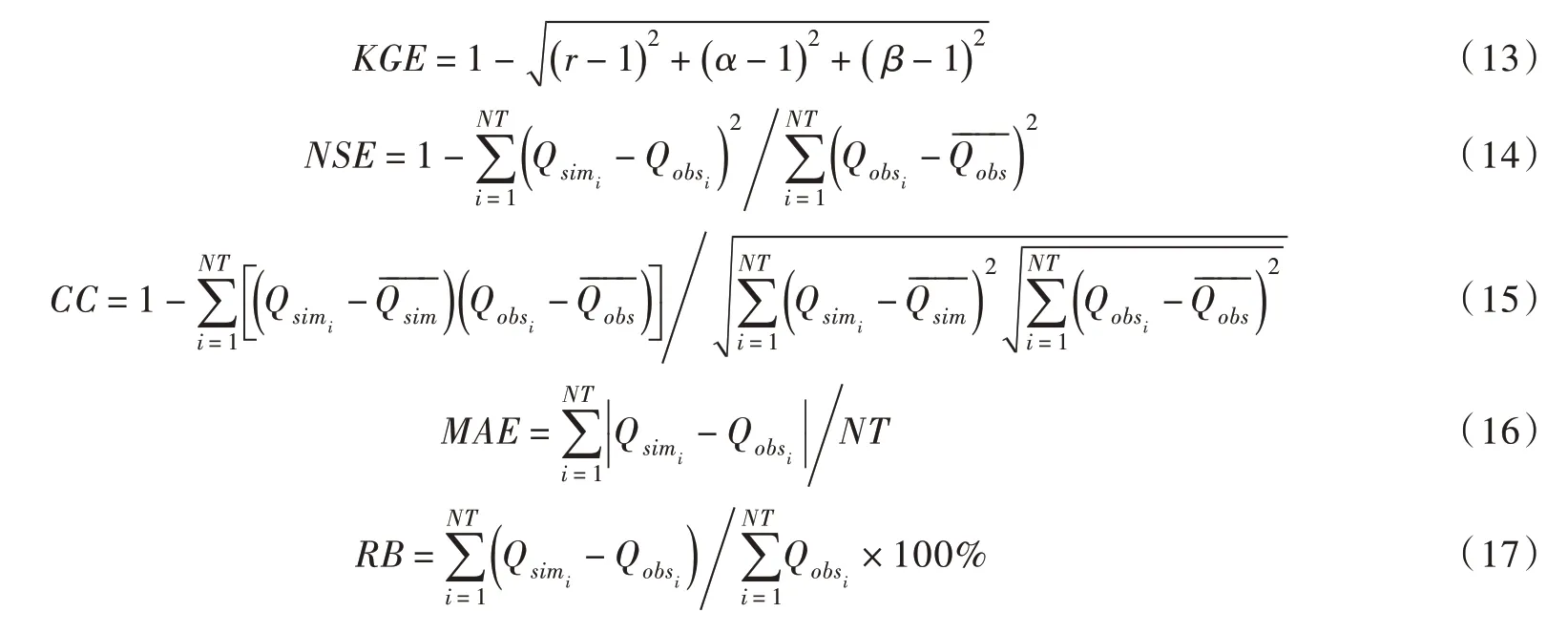
式中:r为皮尔逊线性相关系数;α为实测流量与模拟流量标准差的比率;β为实测流量与模拟流量均值的比率;Qsimi和分别为模拟径流序列及其均值;Qobsi和分别为实测径流序列和其均值;N为径流系列长度。KGE、NSE和CC 越接近1,则表明模拟效果越好;MAE和RB 则越小越好。
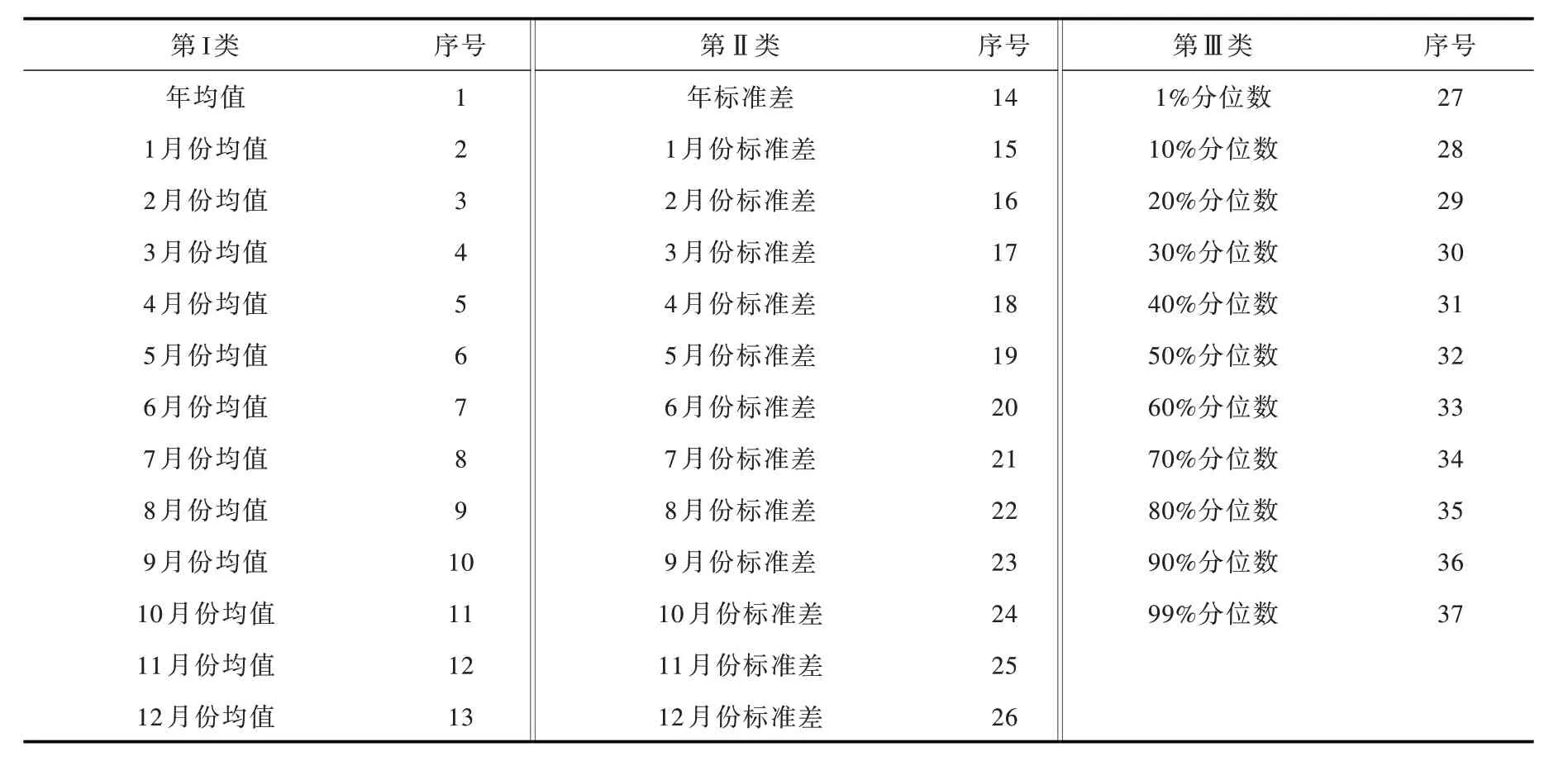
表1 气象系列偏差校正精度的评价指标
4 结果分析
4.1 季节性BMA模型参数估计由于巢湖流域174个自动气象站仅有2015—2019年的观测系列,故采用该时间段作为各偏差校正模型的训练期,率定得到各校正模式的参数后,再用其反演1979—2014年的日降水和气温系列。首先基于DBC、LRBC和RBC 偏差校正方法获得各月份的校正因子及相应的气象输出系列,再通过季节性BMA模型优选各校正方法所占权重,最终得到融合多种偏差校正模式的系列日降水和气温过程。本文考虑校正的气象变量包括日降水量(Pday)、日平均气温(Tmean)、日最高气温(Tmax)和日最低气温(Tmin)。图2以Pday变量为例展示了巢湖流域气象站季节性BMA模型的模拟结果,图中站点编号1—174 表征自动气象站,编号175—181代表流域内7个具有较长观测系列的国家基本气象台站。从图2可以看出不同站点BMA模型的权重具有较大差异,同时4个季节BMA模型的权重也显著不同,这说明考虑巢湖流域的季节性特征,率定BMA模型是有必要的;从图中还可以看出在大多数站点DBC方法所占权重最大,而LRBC和RBC方法所占权重较为接近,一定程度上说明DBC 校正方法对日降水量的偏差校正能力相对较优。
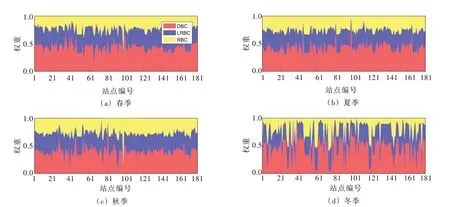
图2 巢湖流域气象站日降水量(Pday)季节性BMA模型的权重
4.2 自动气象站校正精度评估采用表1中37个指标计算得到了巢湖流域174个自动气象站4种偏差校正方法在模型训练期(2015—2019年)对观测数据的模拟效果,为了便于比较也给出了校正前的评价指标。
图3给出了各站点气温变量的平均指标结果,图中纵坐标分别代表不同偏差校正模式日平均气温(Tmean)、日最高(Tmax)和最低气温(Tmin)的统计结果,从图中可以看出ERA5 校正前的Tmax和Tmin普遍比Tmean显示出更大的系统偏差,尤其是对月平均气温和极值的模拟能力较差。经过偏差校正后,4种方法均可得到较低的模拟偏差,其中DBC方法对气温极值的模拟能力最优,BMA方法次之;对于均值气温,DBC、RBC和BMA方法均能得到优良的校正效果,校正后各月平均温与实测系列的差异一般在0.5℃以内。图4给出了巢湖流域174个自动站日降水量校正前后与实测系列的相对偏差,可以看出日降水相较于日气温模拟数据的系统误差偏大,这一现象与国内外学者的发现一致,即降水过程通常比气温更难观测和模拟;LRBC方法对日降水的校正能力相对较差,尤其是对各月降水方差的模拟误差接近10%;BMA、DBC和RBC方法均取得较好的模拟效果,这3种校正模式下大多数评价指标的相对偏差低于5%。
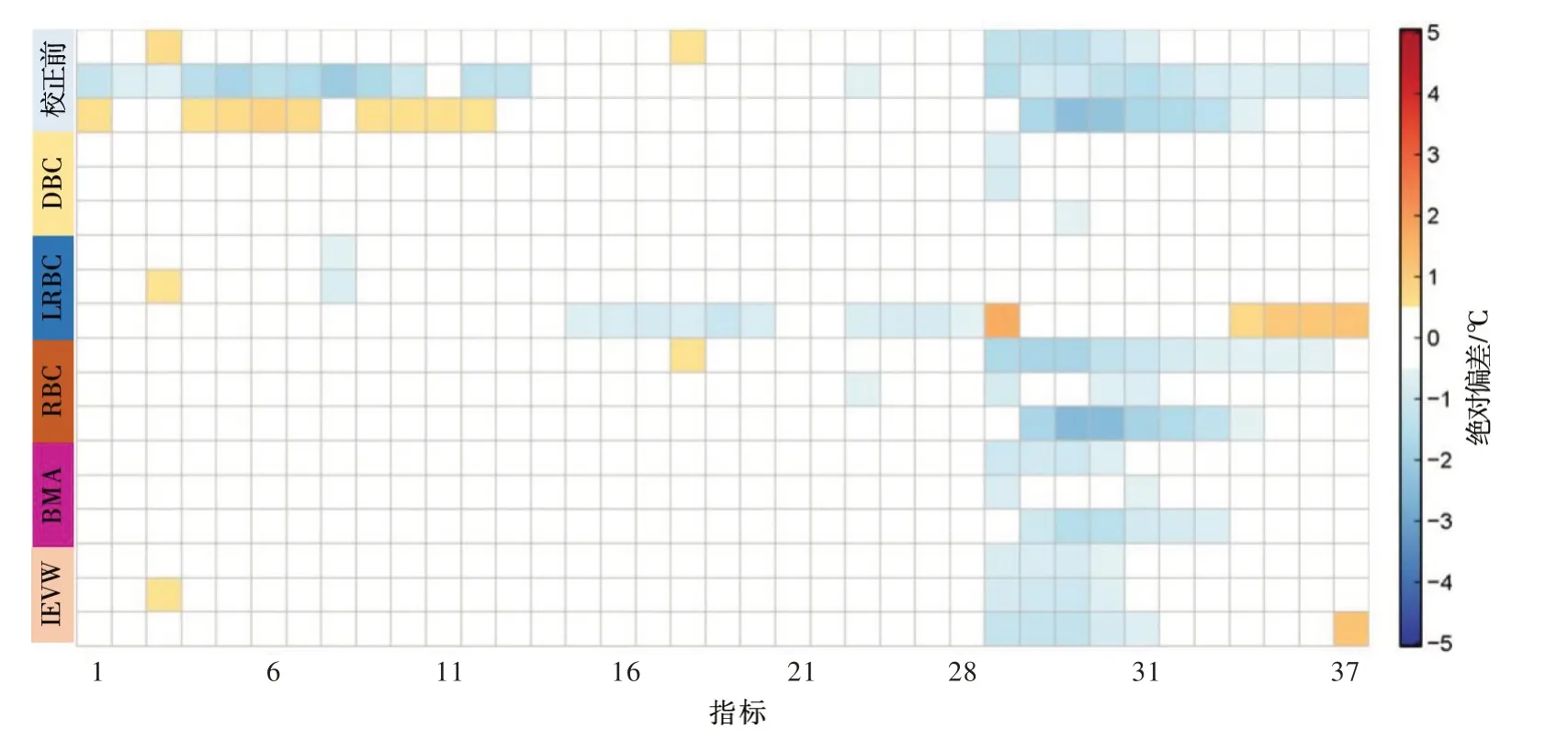
图3 巢湖流域174个自动气象站气温变量校正前后评价的平均指标结果
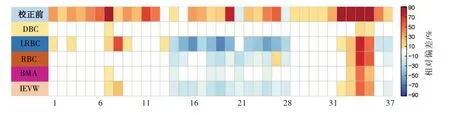
图4 巢湖流域174个自动气象站日降水量校正前后评价的平均指标结果
4.3 国家基本气象台站校正精度检验巢湖流域7个国家基本气象台站具有1955—2019年的系列观测数据,依据该资料可以通过独立验证法对各偏差校正方法的适用性开展进一步评估。首先,为了与自动气象站的模型率定期一致,仍采用2015—2019年实测系列率定各偏差校正模型,首先评估率定期的偏差校正效果,为节省篇幅本文仅给出Tmean、Tmax和Tmin的偏差校正结果(如图5所示),可以看出气温变量经各方法校正后大多数评价指标的绝对偏差低于0.5℃。将1979—2014年设定为模型检验期,采用该时段国家基本气象台站的观测系列对卫星观测数据及其偏差校正方法进行评估,图6 给出了气象台站1979—2014年期间各变量校正前后的泰勒图,它能够较为全面地反映多个方法的偏差校正能力,其中校正后的点据越靠近实测点,则表明该模式的校正精度越高,从图中可以看出BMA方法优于其他模式,其中日气温的相关性系数均超过0.9,日降水则接近0.8。为了分析卫星集成降水在旬、月尺度对实测过程的模拟能力,图7 以合肥气象台站为例,展示了1979—2014年实测系列与偏差校正后降水量的对比图,可以看到各模式的月降水普遍比旬降水更接近实测系列;LRBC方法的校正效果相对较差,BMA方法最优,月降水量的相关系数超过0.94;各方法对降水极大值的模拟效果略有下降,这是由于极端降水往往受剧烈的大气对流活动影响,现有的卫星遥测手段难以较好观测[16]。
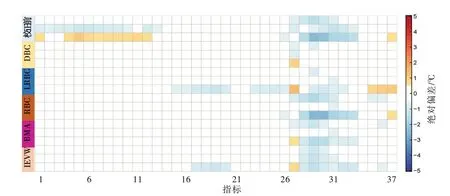
图5 巢湖流域7个国家基本气象台站气温变量校正前后评价指标的平均结果
4.4 IEVW方法对比及校正精度独立验证倒误差方差加权(Inverse Error Variance Weighting,IEVW)方法,近年来在卫星降水校正和融合领域得到较广泛的应用[18],采用IEVW方法计算权重并与季节性BMA方法的校正结果进行对比,从图3—6可以看出,季节性BMA 普遍比IEVW方法显示更优的校正效果。基于交叉验证思想,随机将巢湖流域的181个气象站划分为率定站点和验证站点,首先通过率定站点2015—2017年的日资料率定季节性BMA模型,再通过普通克里金插值方法[21]将所得权重插值到验证站点,对权重归一化处理后即可推求验证站点的估计降水量,该交叉验证方法被广泛应用于卫星降水校正领域[18,21]。本文设置4种不同的验证站点比例,每种方案下随机抽取100 次,并通过集合方案下的均方根误差(RMSE)、MAE、探测率(POD)和RB 等4个指标度量降水的校正效果,从表2可以看出季节性BMA模型得到的日降水,比原始数据集具有更低的估计偏差;同时可以看出,随着设置的验证站点比例提高,季节性BMA模型得到的估计结果逐渐接近原始数据效果,这是由于率定站点数量过小会影响模型权重的空间异质性,不利于刻画降水量的时空特性,所以在工程应用中应尽量选择较多的可靠站点资料。
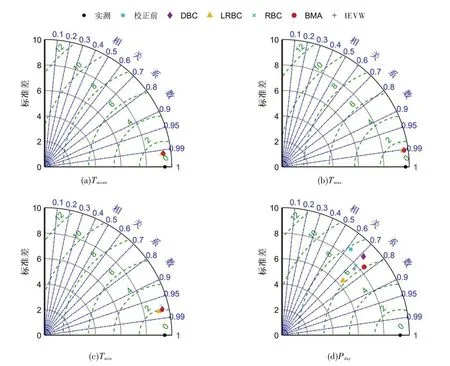
图6 巢湖流域7个国家基本气象台站1979—2014年期间各变量校正前后的泰勒图

图7 巢湖流域合肥气象台站偏差校正后的降水量与实测系列的对比图
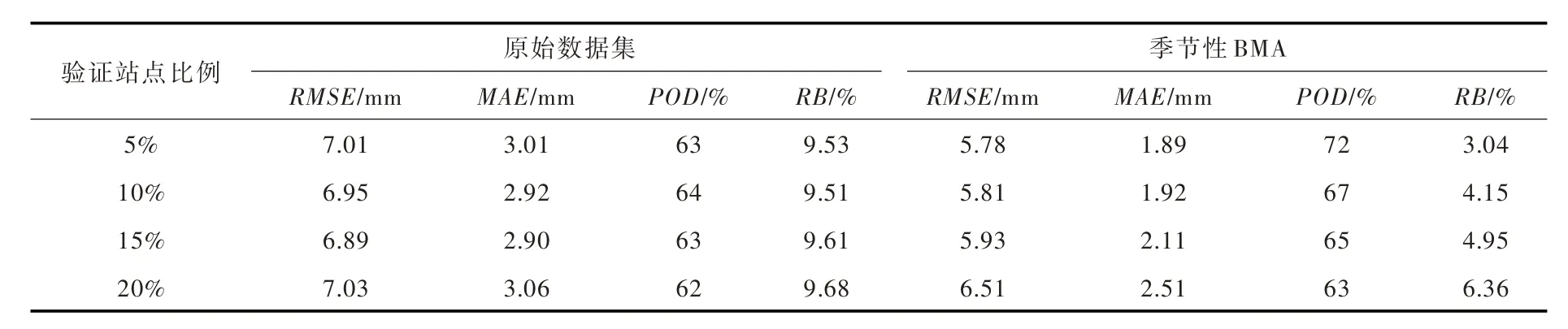
表2 巢湖流域不同比例验证站点方案下的日降水评价指标结果
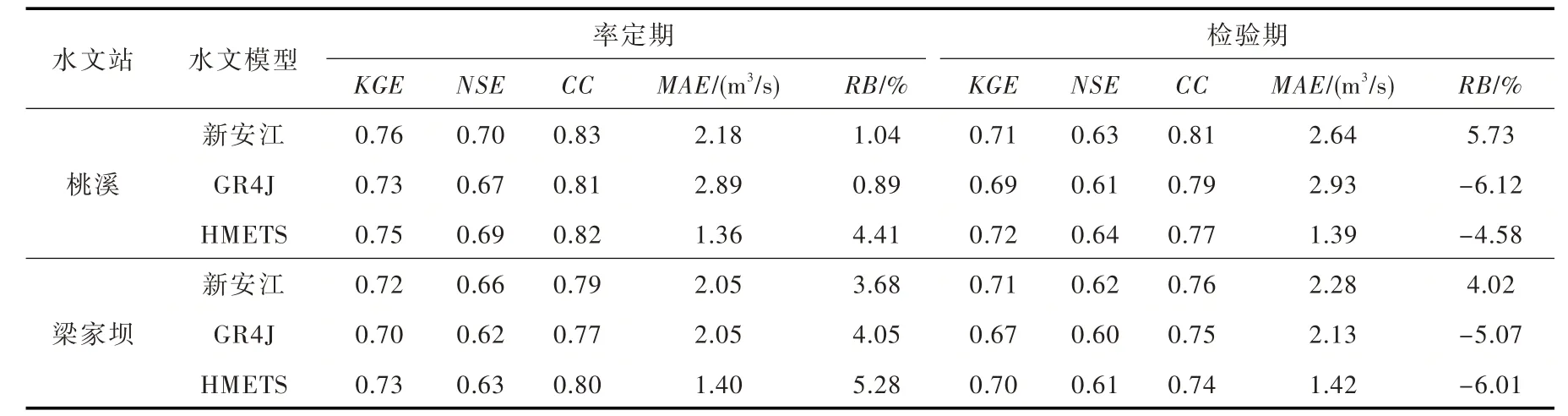
表3 巢湖流域2个水文站不同水文模型率定期和检验期的评价指标结果
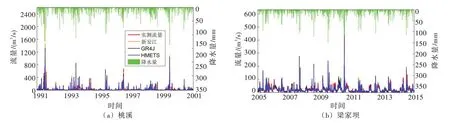
图8 桃溪和梁家坝水文站实测和水文模型模拟的日流量过程
4.5 卫星集成和再分析气象数据集的水文模拟精度评估前文通过多个评价指标和方式验证了MSWEP V2日降水和ERA5日气温数据经偏差校正后,对巢湖流域地面站网观测系列的模拟偏差较小,其中BMA 模式的校正能力最优,能够满足气象应用需要,但是其水文效用如何有待进一步评估。利用巢湖流域支流杭埠河上桃溪水文站(1991—2010年)和西河梁家坝水文站(2005—2014年)资料,系统地评估校正数据集在水文模拟方面的适用性。采用BMA 模式校正后的系列气象数据分别驱动新安江、GR4J和HMETS模型,通过交叉验证方法划分水文模型的率定期和检验期[16],即以奇数年的KGE系数作为目标函数,而以偶数年的KGE系数检验模拟效果,水文模型率定期和检验期的评价指标如表3所示,模拟的日流量系列和实测过程对比结果见图8。结合表3和图8可以看出:3个模型在2个试验流域的模拟结果存在一定的不确定性,说明水文模型会对径流模拟造成一定的误差,尤其是对洪峰的模拟能力相对较差;但是巢湖流域主要关注旬、月尺度的径流过程,基本满足要求;3个模型均能取得较好的模拟效果,率定期和检验期的KGE系数超过0.67;结合NSE和RB 等水量误差评价指标可以看出,基于校正后气象数据集驱动流域水文模型,能够取得相对较小的水量误差;BMA模式校正的日降水、气温系列能够满足水文模拟的应用要求。
5 结论
本文融合巢湖流域有限的地面气象观测数据、高精度MSWEP-V2 卫星集成降水数据集和欧洲中期天气预报中心的ERA5 气温数据,采用基于分位数映射的日偏差校正方法、基于月尺度的回归校正和等率校正等3种方法,对遥测栅格降水和再分析气温日系列进行校正;再采用BMA方法描述各偏差校正系列的后验分布优选相应权重,得到融合多种偏差校正模式的日降水、气温系列,最后选取2个试验子流域分别基于新安江、GR4J和HMETS模型评估其水文模拟适用性及精度。主要结论如下:(1)MSWEP V2 降水和ERA5 气温数据集在巢湖流域均存在一定的模拟偏差,故在流域水文模拟应用领域有必要开展气象数据偏差校正;偏差校正模型需要可靠的观测资料进行率定,该流域具有空间密度较高的自动气象站,为构建校正模型提供了良好的适用条件;对于地面观测站点稀少的地区,降水受地形、气候等多种因素影响较大,其偏差校正方法的稳定性有待进一步探讨。(2)4种偏差校正方法对气温变量进行校正后,整体上均得到较低的模拟误差,其中DBC方法对气温极值的模拟能力最优,BMA方法次之;对于均值气温,DBC、RBC和BMA方法均能得到优良的校正效果,校正后各月均温与实测系列的差异一般在0.5℃以内,日气温的相关性系数均超过0.9。(3)日降水相较于气温系统误差偏大,LRBC方法对降水的校正能力相对较差,而BMA、DBC和RBC方法均取得较好的校正效果,这3种校正模式下大多数评价指标的相对偏差低于5%;基于国家基本气象台站长系列资料的泰勒图和回归分析结果显示,BMA方法优于其他模式,日降水的相关性系数接近0.8,月降水量的相关性系数超过0.94。(4)采用BMA模型偏差校正后的气象数据系列,分别驱动新安江、GR4J和HMETS 水文模型,结果显示在2个试验子流域均取得较好的模拟效果,率定期和检验期的KGE系数超过0.67,NSE和RB 等指标显示水文模型的水量误差较小。总体而言,BMA方法校正的日降水、气温系列能够满足水文模拟的应用要求。
多源气象数据融合及偏差校正对中小流域的水文模拟具有重要意义,对于地面站网密度较高的地区(例如巢湖流域),若气象观测系列较短,可以通过引入卫星降水和再分析数据集反演得到气象系列数据资料。基础气象数据、偏差校正方法、参数估计和水文模型等多个因素均会对流域径流模拟造成一定的不确定性,如何定量分离各环节对水文模拟偏差的贡献分量有待进一步探讨。
