融合文本和路径语义的知识图谱嵌入学习模型
2021-01-04韦丽娜蒋运承
肖 宝,韦丽娜,李 璞,蒋运承
(1. 北部湾大学电子与信息工程学院,钦州 535011; 2. 华南师范大学计算机学院,广州 510631;3. 郑州轻工业大学软件学院,郑州 450000; 4. 广西民族大学信息科学与工程学院,南宁 530006)
有着数以亿计的三元组(头实体,关系,尾实体)构成的知识图谱(如Freebase、WordNet)因具有高完备性、良好的结构和丰富语义关系等特点已经成为了Web搜索引擎[1]、问答系统[2]和推荐系统[3]等智能应用的关键基础资源. 知识图谱嵌入学习是这些基础资源得以有效利用的重要技术手段,在语义计算、提高知识推理效率、解决数据稀疏和融合异质信息等方面起到关键的作用[4].
最简单有效的知识图谱嵌入学习模型是TransE模型[5],该模型把实体和关系映射到一个低维的语义向量空间上,空间上的关系向量是头实体向量到尾实体向量平移的距离,其扩展模型有TransH[6]、TransR[7]和TransD[8]等. 针对Trans系列模型只考虑实体间的关系而忽略多步间接路径的语义关系的问题,LIN等[9]提出PTransE模型,利用路径约束资源分配的图算法获取多步关系路径,并用相加、按位相乘和循环神经网络方式对路径语义编码组合后融入TransE模型中. 由于只考虑实体间的结构信息,Trans系列模型难以应对数据稀疏、知识的不完整和关系的二义性问题[10],学者们试图用深度学习技术把文本、实体间的间接路径和实体类别等复杂信息融合到知识图谱嵌入学习中[11-14]. 其中,融入文本和实体结构信息以提高知识表示能力得到了最广泛的关注和研究. 如:WANG等[15]设计了基于知识库和文本联合嵌入模型,通过模型中的对齐模型(对齐锚文本和实体)融入Wikipedia的文本信息,提高了知识嵌入模型的性能;针对文献[15]提出的模型因锚点质量差而产生词污染的问题,ZHONG等[16]把融入的信息由Wikipedia文本改成了实体描述文本;针对上述融入文本信息的研究存在忽略文本词序且使用的实体名称存在歧义问题,XIE等[11]提出了DKRL模型,利用卷积神经网络[17]和CBOW(Continuous Bag-of-Words)[18]2种深度学习方法捕捉隐藏在文本中的“上下文”语义信息并融入TransE模型中,取得了极其显著的效果;针对DKRL模型存储参数多和计算效率低的问题,FAN等[19]设计了一个单层的基于概率的具有同样性能的联合模型(RLKB模型);针对融入文本信息的模型存在噪声问题,AN等[10]设计了一个基于文本的注意力机制的增强模型;针对融入路径语义信息的PTransE模型把路径上所有的关系进行组合会存在噪声(路径上很多关系和实体对知识表示是无用的),使得一些重要的路径没有得到足够重视的问题,NIE和SUN[13]提出了TKGE模型,利用文本为不存在关系的实体建立“文本语义关系”,然后用PRA(Path Ranking Algorithm)算法[20]获取从源结点到目的结点的多条路径,训练时借助Bi-LSTM[21]模型和注意力机制[22]寻找重要的路径融合到TransE模型中,与TransE、TransR、PTransE模型相比,TKGE模型在元组分类、关系预测的任务中取得了更好的效果.
综上所述,目前的研究仍然存在3个主要问题:(1)实体间的多步路径的语义仍然没有得到合理的运用,如TKGE融合的路径仍然可能存在噪声;(2)只有文本的浅层语义(如词嵌入)被融合到系统中,隐藏的潜在文本语义没有得到合理的利用;(3)忽略了“不同关系对路径上的结点及其属性的关注度应该是不同的”原则,影响了知识表示的准确性和有效性.
针对上述问题,本文提出了融合文本和路径语义的知识图谱嵌入学习模型(GETR,Graph Embe-dding with Text and Relation Path):首先,获取描述文本的主题信息,学习主题和词的向量表示并融入到实体向量表示中;然后,以随机游走算法[23]为基础,设计以PageRank算法与余弦相似度算法[24]为搜索策略的算法,以获取实体间相关度最高的多步关系路径;最后,以带自注意力机制的Transformer模型[25]和TransE模型为基础,设计融合文本信息和路径语义的联合模型学习知识图谱的嵌入表示.
1 关键技术
GETR模型的目的是尽可能多地融合知识图谱内外的文本和路径的语义信息到模型中. 实体描述文本和三元组结构信息是模型关注的重要资源,下面给出相关的基本概念.
定义1[13]三元组T={(h,r,t)},h,tE,rR,TS,其中:E、R和S分别表示知识图谱的实体集合、关系集合和元组集合;h是头实体,t是尾实体,r是关系;对于每一个三元组的实体h、t具有r关系. 每个实体都有描述文本.
定义2[13]路径p=(h,r1,e1,…,em,rm,t)是知识图谱中以实体h为起始点到目标结点实体t所经过的由多个关系和多个实体构成的多步关系路径,其中ri、ei分别是路径上的第i个关系、实体,i(1,2,…,m).
要融合文本和路径信息,需在已有的知识图谱情况下,针对具体问题选择和设计合适的算法. GETR模型的关键技术问题是文本语义扩展、文本语义融入、路径语义信息融入和联合训练,设计技术路线(图1)为:首先,用文本主题信息丰富实体描述文本的语义并获取主题和词嵌入向量;然后,用Bi-LSTM模型网络对主题和词向量编码,使之成为实体表示的组成部分;最后,使用自定义的随机游走策略从知识图谱中获取一条多步路径,并对路径语义信息编码后融入TransE模型.
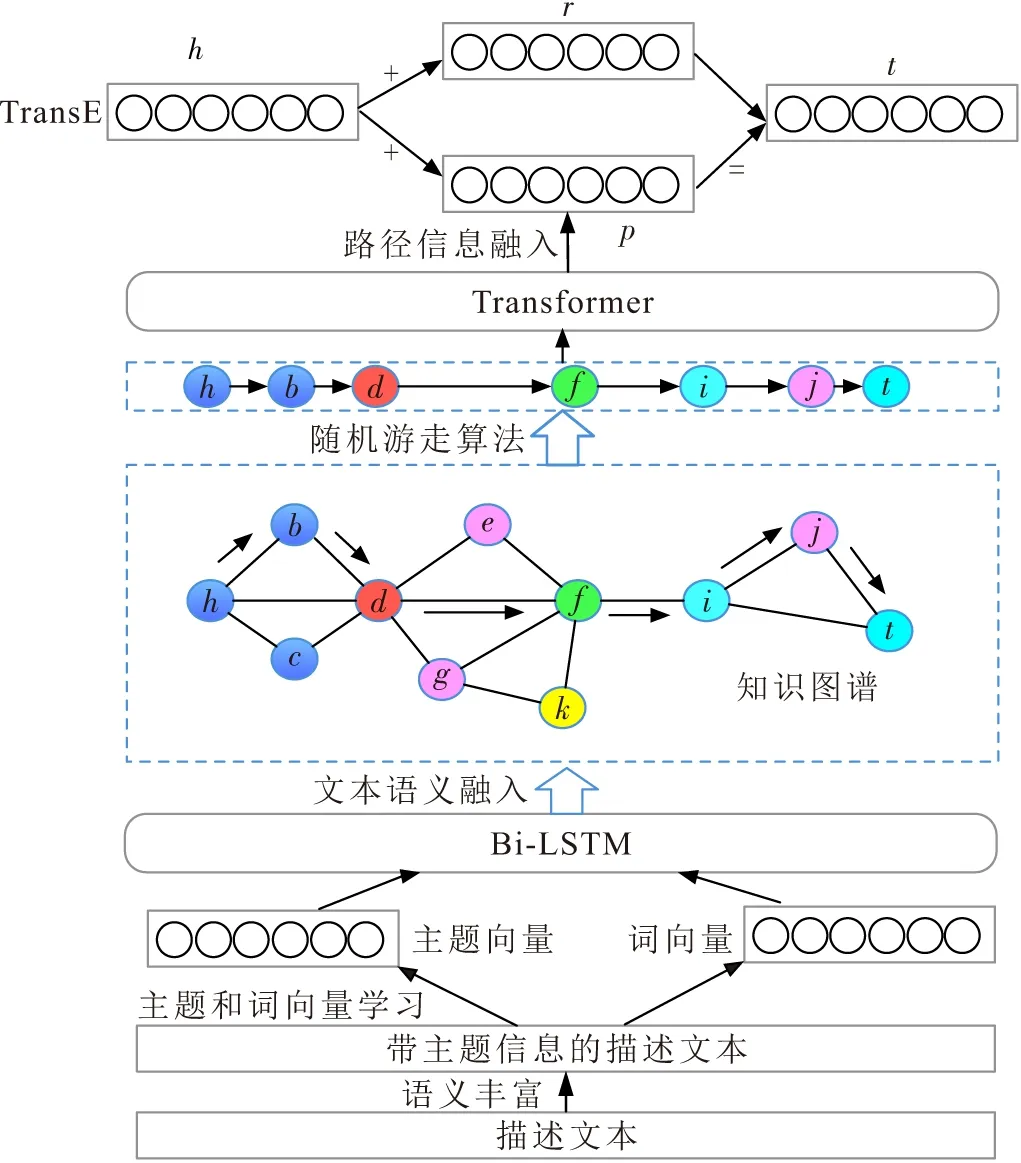
图1 融合文本和语义路径的知识图谱嵌入学习技术路线图
下面介绍GETR模型采用的关键技术LDA[26]、主题词嵌入学习[27]、随机游走算法[23]以及Transformer模型[25].
1.1 LDA和主题词嵌入
主题信息是一种潜在的文本语义,在自然语言处理领域(如语义相似度)可以起到重要的作用[28]. 通过主题信息可以观察到文本所属领域范围. 类别信息在知识图谱的知识表示学习上可以起到重要的作用[14]. 其实,主题也可以认为是实体的类别信息. LDA是一种基于概率的文档生成模型,可以将文档集中每篇文档的主题以概率分布的形式给出,而主题是参与训练词汇的概率分布. LDA生成文档的过程如下:
对于某一个文档中的第i个词wordi(i=(1,2,…,m):
(1)采样获取主题topici~Multinomial(θi),
(2)采样获取词wordi~Multinomial(φtopici),
其中,Multinomial()为多项分布运算函数,主题θi和词φtopici分别存储于文档到主题概率矩阵Θ以及主题到词的概率矩阵Φ中,而Θ和Φ通过Gibbs 采样得到.
主题词嵌入TWE(Topical Word Embedding)[27]是获取主题和词的语义表示向量的有效模型. 设有单词序列D={word1,word2,…,wordm}及单词相应的主题序列Z={topic1,topic2,…,topicm}. 对于单词-主题对〈wordi,topici〉,TWE模型基于Skip-Gram设计了TWE-1、TWE-2和TWE-3模型学习主题向量和词向量. 其中,TWE-1模型把每个主题视为一个伪词,可以更精确地捕捉文本的语义信息. 因此,本文选择TWE-1模型(图2)学习主题和词的嵌入向量.
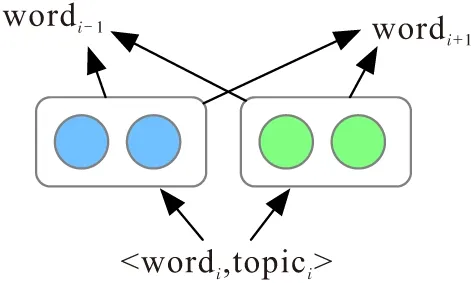
图2 TWE-1模型图
1.2 TransE模型
TransE模型认为在三元组T=(h,r,t)中,实体h、t在关系r的向量空间中存在着h+r≈t的关系,即t是h平移r距离后的最近邻结点. 训练中设定损失函数为:
(1)
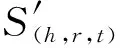
dr(h,t)=|lh+lr-lt|L1|L2,
(2)
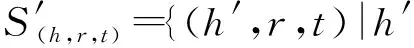
(3)
其中,lh、lt、lr分别是实体h、t及关系r的向量表示,L1和L2是距离的计算方式.
1.3 随机游走算法
随机游走算法的思想是从给定的图中的某一结点开始,以等概率的方式选取与之相连接的结点作为下一个起始点,采样的转移概率计算公式如下:
(4)
其中,ruv表示结点u与结点v的元组关系,Pu,v表示从结点u跳转到结点v的概率,Gu是结点u的度(如果是有向图,则为出度). 经过多次的跳转即可得到一条由多个结点构成的路径.
1.4 Transformer模型
Transformer模型是一种具有自注意力机制(Self-Attention)的序列到序列(Seq2seq)的深度学习网络模型,由编码器(Encoder)和解码器(Decoder)构成. 由于本文处理的不是序列到序列的任务,所以只介绍GETR模型使用到的编码器的知识:Transformer模型中,先对序列的每一步输入进行不同的线性转换,以获取查询、键和值3个向量,并把这些向量分别封装构建Q、K和V3个向量矩阵;然后利用Q、K计算注意力机制的权重,计算方法是对Q和K进行放缩点乘运算,对放缩点乘运算结果应用softmax函数,从而得到一个表示注意力大小的标量值;最后把标量值与向量V相乘获取带注意力的向量表示. 带注意力的向量表示计算过程如图3A所示,计算公式如下:
(5)
其中,dK是键向量K的维度大小.
多头自注意力机制层(Multi-head Self-Attention)和前馈神经网络层是模型的重要组件. 为了在不同的表示子空间里学习到重要的信息,多头自注意力机制将编码器的输入序列上的输入线性转换为多组的(Q,K,V),利用式(5)得到每头的新向量表示,然后将新向量拼接并做线性转换后输入到前馈神经网络层(图3B). 计算公式如下:
(6)

前馈神经网络层定义如下:
FFN(x)=max(0,xWf 1+bf 1)Wf 2+bf 2,
(7)
其中,f1、f2表示线性转换,Wf 1、Wf 2和bf 1、bf 2分别是2个线性转换的权值和偏置参数.
多头自注意力机制层和前馈神经网络层一般都后接一个相加和正则化层(Add & Normalize),此层与输入层有一个残参连接;正则化是层正则化[29]操作,即对每一笔数据都进行正则化;除了序列结点信息以外,模型输入信息通常还包括序列结点位置信息,结构如图3C所示. 位置信息编码方式如下:
PE(pos,2i)=sin(pos/10 0002i/dmodel),
(8)
PE(pos,2i+1)=cos(pos/10 0002i/dmodel),
(9)
其中,pos是位置序号,i是位置向量的维度索引序号.
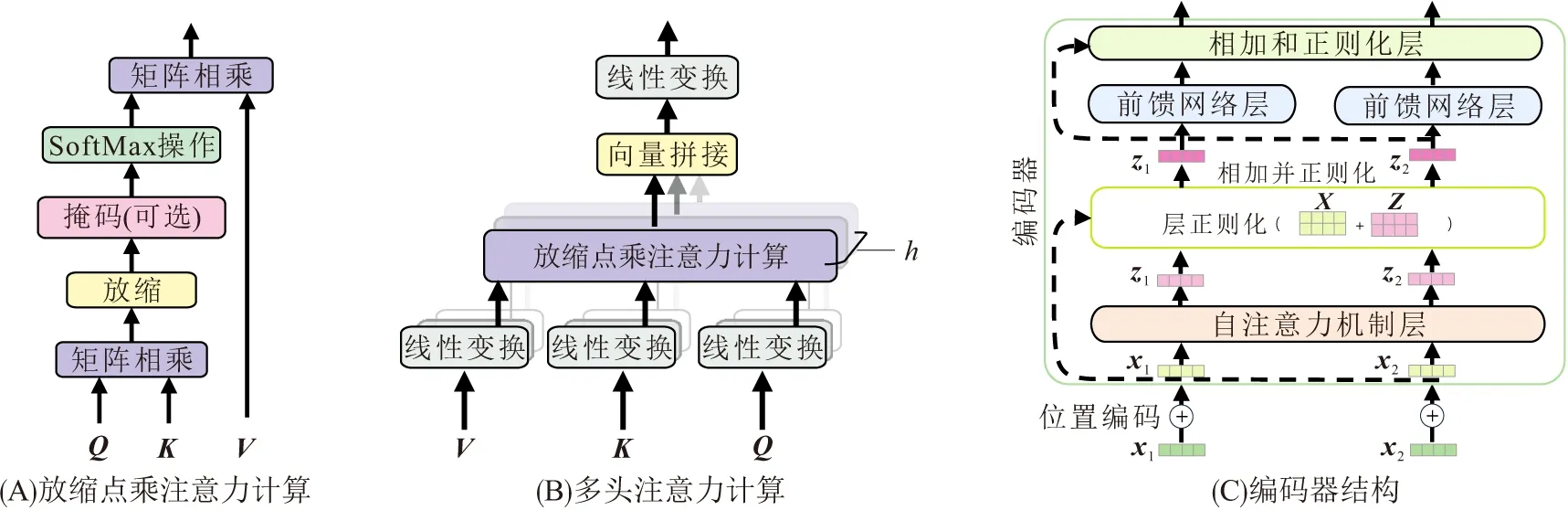
图3 多头自注意力机制图[25]
2 GETR模型
GETR模型的主要步骤是:学习和分配实体描述文本词的主题,以达到语义扩展目的;学习扩展后文本词和主题的嵌入向量表示,并将之融合到实体向量;设计带策略的随机游走算法,获取多步路径,并组合多步路径上的实体和关系的向量融入到TransE模型中进行联合训练. 模型架构见图4.

图4 融合文本和路径语义的知识图谱嵌入学习模型的架构
2.1 描述文本语义获取
为了能更好地反映词汇的主题信息,LDA模型使用的语料库是英文Wikipedia库. LDA模型在训练前先清洗语料库中对训练无用的辅助数据(如Category、File、MediaWiki等命名空间的文件);移除文本中的停用词并进行词干化. 设定窗口去掉出现频率过多或者过少的词,本文把窗口数值大小设定为出现在不同文章的次数小于20和大于文章总数的10%. 同样地,移除实体描述文本的停用词和词干化操作,然后用LDA学习到的主题库丰富清洗后的描述文本语义,即为实体描述文本中每一个词赋予一个主题. 每个词有可能属于多个主题,本文选取概率值最高的主题作为词汇的潜在语义信息.
利用TWE-1训练描述文本的词主题对,获取主题向量和词向量表示,并将其作为Bi-LSTM模型网络的输入. 为了更好地融合主题和词的语义信息,对于g时刻的LSTM模型的单元的输入门Ig、忘记门Fg、输出门Og、记忆状态Mg和隐藏状态hiddeng的修改公式如下:
Mg=Fg⊙Hg+Fg⊙Mg-1,
hiddeng=Og⊙tanhMg,
(10)

2.2 多步路径的语义获取
如果用经典随机游走方法从实体h游走到实体t获取由多个关系和实体构成的路径序列,结点的获取会偏向于度数大的结点,而这些结点往往不是路径上最佳的选择. 为此,根据实体的关系和描述文本特点引入PageRank算法与余弦相似度算法,以指导算法游走的方向,从而避免游走的盲目性. PageRank的算法思想是:统计有向图的所有结点的入度,入度值越大的结点越重要;余弦相似度算法是衡量文本相似度的重要方法,两向量的夹角越小表示相关度越高. 对于结点u到结点v,设计的算法游走公式如下:
(11)
其中:ruv表示结点u与结点v的元组关系;α是权值,用于调节PageRank算法与余弦相似度算法在选择结点时的权重;PageRank(v)是结点u的邻接结点v的PageRank值,定义如下:
(12)
其中,a是指向结点v的结点,Ga是结点a的出度;sim(utext,vtext)定义如下:
sim(utext,vtext)=cos(Vutext、Vvtext),
(13)
其中,utext、vtext是实体结点u、v的描述文本,Vutext、Vvtext则是相应文本的向量表示. 文本向量表示由主题向量和词向量组成:
(14)
其中,WS是文本utext或者vtext的词集合,TFwordi是描述文本中第i个词wordi的TF-IDF值,Vwordi、Vtopici分别是wordi及其对应主题的嵌入向量,concat(Vwordi,Vtopici)表示将Vwordi和Vtopici进行拼接操作.
带策略的随机游走算法获取的路径的结点对知识表示学习的影响作用是不同的,Transformer模型的自注意力机制使得重要的结点能够被赋予更大的权重值. 编码器的每一步输入由融合了文本信息的实体向量和关系向量融合而成. 融合的方式是:首先拼接实体向量和描述文本向量,对拼接后的向量进行线性转换,然后再将之与关系向量再次拼接和线性转换,从而获得编码器的输入向量. 组合过程公式如下:
(15)
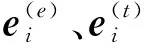
2.3 知识图谱嵌入学习向量
GETR模型是一个联合模型,训练时包括2条路径(图5):一条是直接路径(直接关系r),另一条是多步路径(间接组合关系p).
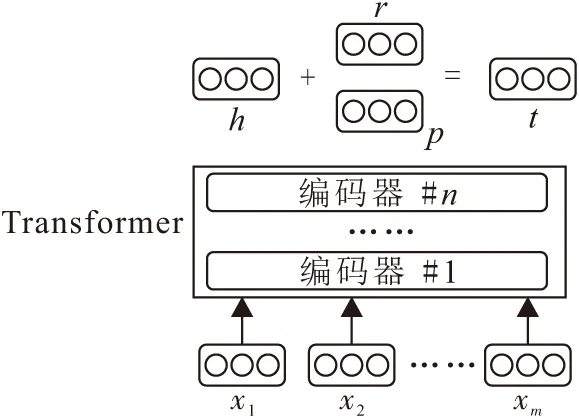
图5 联合模型训练示意图
由式(15)、(8)、(9),将路径中实体、实体描述文本和关系的向量连同路径中的位置信息进行组合作为模型的输入,与TransE模型联合训练. 模型设计的损失函数由2个部分构成:
L=L(h,r,t)+L(h,p,t),
(16)
其中:L(h,r,t)是直接路径的损失函数,由式(1)可得;L(h,p,t)是多步路径的损失函数. 在训练中,关系r尽可能与组合关系p相同,所以,最小化损失函数L(h,p,t)可以转换为损失函数L(p,r):
L(h,p,t)=L(p,r)=
log(1-d(p,r′)))),
(17)
其中,d(p,r)和d(p,r′)的计算公式如下:
d(p,r)=σ(log(exp(p·r))),
d(p,r′)=σ(log(exp(p·r′))).
(18)
模型训练中使用随机梯度下降方法,对所有h、r、t的向量表示约束满足‖lh‖2≤1,‖lr‖2≤1,‖lt‖2≤1.
3 实验结果与分析
评测知识表示学习模型的效率最常用的任务是知识图谱补全(实体和关系预测)以及元组分类. 为了较好地说明深度学习算法以及路径和文本的语义信息在模型中的作用,本文将GERT模型与具有代表性的基准模型(TransE、DKRL、TKGE模型)进行比较. 基准模型实验使用相关研究提供的源代码,训练和测试的数据均相同. 实验软件环境为:操作系统Ubuntu 18.04 LTS 64Bit,PyCharm,Pytorch,gensim;硬件环境:处理器Intel(R) Core(TM) i7-6700K CPU@4.0 GHZ,内存大小为32 G,NVIDIA Geforce TITAN Xp 12G GPU.
3.1 数据集
实验数据采用数据集FB15K[11]、FB20K[11]以及WN18[10]. FB15K和FB20K中的三元组数据来自FreeBase,WN18的三元组数据来自WordNet. FB20K对FB15K的实体进行了扩展,即FB20K中部分实体并没有出现在FB15K中. 数据集中的实体都有简短的描述文本,且这些文本在数据清洗后的长度大于等于3. 数据集的信息如表1所示.

表1 数据集统计信息Table 1 The statistics of datasets
由表1可以看到FB20K比FB15K多了5 019个实体,训练时训练数据集和验证数据集包含的三元组数据相同,但是测试集的三元组数据则不同,其目的是为了测试模型对新实体的适应程度.
3.2 模型参数设置
寻找最佳的模型参数是模型调试的重要任务.在特定数量和质量的数据样本以及硬件设备条件下,通常是根据相关研究总结出来的参数设定公式、已有相关模型的最优参数和实际经验方面进行参数调整. 如LDA主题数的初始粗略值的确定[30]、神经网络中参数的Kaiming初始化方法[31]. 一些需要手动调整的参数可通过经验和观察测试结果设置,如分类任务中的ROC曲线、神经网络层的Dropout值.对于学习率则设置衰减策略,即:每个Epoch后,学习率按指定的衰减率递减. 为了模型测试结果的公平性,有些参数不宜取得过于极端,如设置既深又宽的神经网络模型理论上会比浅而窄的模型具有更强的学习能力. 本文按照以上方式进行模型参数设置和调整,在设置参数范围后,寻找最优的参数组合.
实验中,按照相关文献[5,11,13]设定TransE、DKRL、TKGE模型的参数. 知识图谱关系的路径组合可能是一个庞大的集合,为了提高模型的训练效率,与PTransE模型一样,GETR模型只考虑长度小于等于3的路径.
模型训练时,GETR模型采用SGD优化器,TWE-1、LDA模型采用Adam优化器. 主题模型LDA的主题数topics[30]的计算公式如下:
(19)
其中,C是wikipedia的概念集合,WS是待分配主题的数据集词汇集合. 经过计算,LDA模型的主题数是659个. 训练中,选择该值附近的500、800、1 000、1 200、1 500进行训练,通过训练和困惑度(Perplexity)的观察选择最佳值. 主题向量维度dtopic和词向量的维度dword的设置方式参考TWE的设置方法,dtopic=dword{50,100,150,200,300,400},将获取到的主题向量和词向量应用于20NewsGroup分类任务,分类效果最佳时的向量维度为实体文本特征向量的维度. 为了兼顾与其他基准模型比较的公平性和GETR模型的特殊性,实体和关系向量维度dentity=drelation{100,150,200,250,300}. 通过观察发现当维度大于150时,TransE模型的效率提升不明显. 但是,在融入文本语义和路径语义信息的GETR模型上发现维度增加到250维之前,知识补全和实体分类的评测指标有较大幅度的提升,这可能是实体维度的增加为信息融合提供更宽裕的表征空间;式(1)和式(17)的γ{0.5,0.8,1.0};式(11)的α{0.2,0.5,0.6,0.8},α反映了结构信息和文本信息在随机游走算法的重要程度,因为测试集中很多结点只选取了原知识库的部分实体关系(即链接),难以很好地通过实体关系反映结点自身的作用,所以α值不宜过大.
神经网络的参数需要根据经验和实验测试结果确定,Bi-LSTM模型的隐单元大小size的初始值一般设置为输入和输出的维度平均值,测试中size{128,256,512,1 024},dropout{0.2,0.5,0.8},学习率lrlstm{0.001,0.01,0.1,1}. GETR模型的编码器模块参数多、计算复杂且耗时,且受限于硬件要求,不宜设置过高的参数. 本文在Transformer模型的基础上对编码器进行参数的设置:层数layers设置为8,序列长度seq_length设置为路径长度(为3),Self-Attention的头数q分别设置为4、6、8、12,学习率lratt设置为0.000 02,训练数据批大小batchsize分别设置为64、128、256、512,训练迭代次数iter是1 000,lrloss分别设置为0.001、0.01、0.1、1,γ分别设置为0.5、0.8、1.
经过多轮参数组合测试,得到的最佳设置参数是topics=800,dtopic=dword=300,dentity=drelation=200,γ=0.8,α=0.2,size=512,dropout=0.5,lrlstm=0.01,q=8,lratt=0.000 5,batchsize=512,lrloss=0.001.
3.3 知识补全
知识补全的任务是对于给定的三元组(h,r,t),能用算法寻找其中丢失的某一项. 知识补全分为实体补全和关系补全. 评价模型优劣的常用指标是平均数排名(Mean rank,即所有正确元组所排位置的平均值)和前n命中率(Hit@n,即排序中前n位里有正确元组数所占比例).
测试中,首先对测试集中的每个元组的头实体、尾实体和关系分别用训练集的所有实体和关系进行替换,以得到3组测试集;然后,用式(2)及L2距离计算测试集中的元组的距离值,并按该值进行升序排序(值越小,表示效果越好);最后,在排序的元组中查找并记录正确的三元组所在的排名位置并计算这些排名位置的平均值和前n命中率. 其中,实体补全评测通常采用Hit@10,关系补全评测则用Hit@1. 评测数据可能存在1个问题:测试集中存在被替换关系或者实体后的元组被认为是错误元组,但这些错误元组可能存在于训练集或者FreeBase中(即是正确的元组),这需要在排序结果中过滤掉这些元组. 所以,评测结果分为2种:一种是过滤前的结果,一种是过滤后的结果. 由GETR模型和TransE、DKRL、TKGE模型在FB15K和WN18数据集的实体补全和关系补全任务评测结果(表2至表5)可知:(1)GETR模型比其他的基准模型具有更精准的知识表示能力;(2)融合文本信息的模型都比TransE模型的效率高,其原因是文本的语义信息是基于结构的翻译模型的有利补充;(3)使用融合文本和路径的语义信息比只使用文本语义信息在提高模型的知识表示能力方面更加有效;(4)与TKGE模型相比,GETR模型在实体预测和关系预测中的平均数排名(Mean rank)分别至少提升了1位和0.09位,而实体预测的Hit@10和关系预测的Hit@1至少分别提升了0.8%和0.9%,可能的原因有2个:一是使用了主题模型扩展了文本的语义,二是带自注意力机制的Transformer模型比LSTM模型具有更强的学习能力.

表2 实体预测在FB15K数据集中的评测结果Table 2 The evaluation results of entity prediction on FB15K
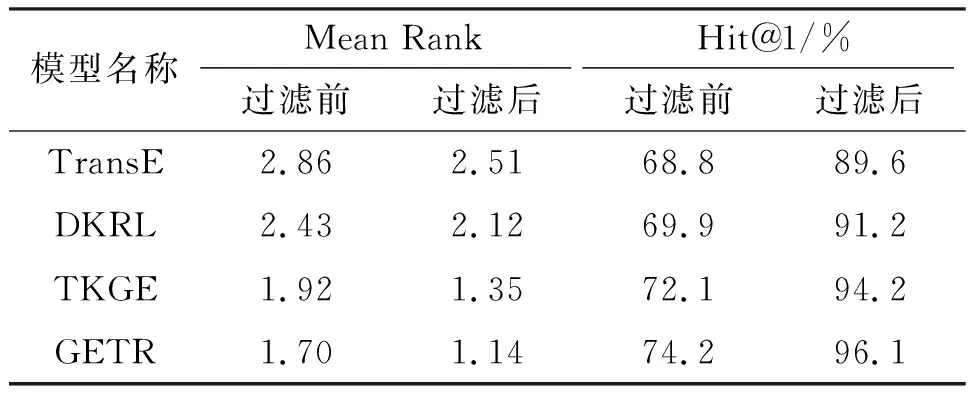
表3 关系预测在FB15K数据集中的评测结果Table 3 The evaluation results of link prediction on FB15K
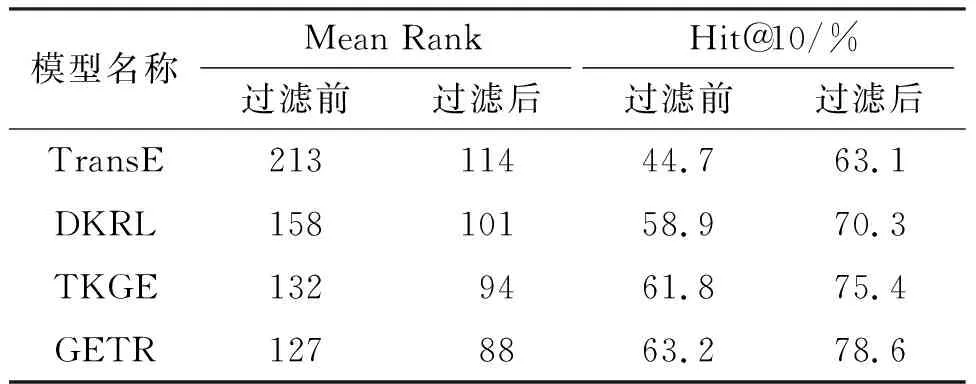
表4 实体预测在WN18数据集中的评测结果Table 4 The evaluation results of entity prediction on WN18
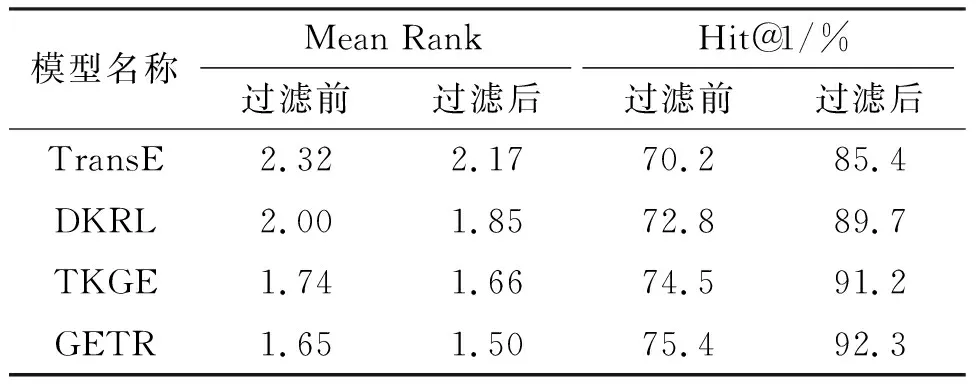
表5 关系预测在WN18数据集中的评测结果Table 5 The evaluation results of link prediction on WN18
3.4 实体分类
在许多知识库中,几乎每一个实体都有一个以上的类别,如实体Barack_Obama在Dbpedia中有Politician、President和Person等123个类别.文献[11]在实体关系集FB15K和知识库Freebase的基础上,专为实体分类任务构建了一个包含50个类别(共13 445个实体)的基准数据集,其中训练集实体、测试集实体数分别为12 113、1 332个. 构建的方法是抽取FB15K中所有实体的所有类别,选取出现频率最高的类别(不包含所有实体都拥有的公共类别)及与类别相关的实体作为数据集. 因为WN18中的实体没有明确的类别信息,所以分类任务只在FB15K和FB20K中进行测试.
实体分类任务是对给定的实体进行实体类型预测,这是一种多标签的元组分类任务(在数据集中,很多实体可能隶属于多个类型). 实体分类评估指标是MAP(Mean Average Precision)[22],其计算方式是:对具有m个类别的实体分类,设对某个实体分类得到k个正确类别的位置分别是p1,p2,…,pk(k≤m),n个测试实体分类的MAP为:
(20)
实验中,使用10次的十折交叉验证(10-fold cross-validation)方式抽取数据,使用scikit-learn的一对多策略的逻辑回归(One-vs-Rest Logistic Regression)算法完成分类的训练和评测. TransE模型没有在FB20K数据集上测试,原因是在该数据集上有较多新实体,TransE模型只考虑三元组的结构信息,测试结果比较差,其数据没有可比性. 由实体分类评测结果(表6)可知:GETR模型在FB15K、FB20K数据集上进行实体分类,结果优于其他基准模型;GETR模型在2个数据集上的MAP分别比同样融入文本和路径信息的TKGE模型高出2.3、3.6,表明合理地利用文本的潜在语义和多步语义路径信息对模型的效率提升具有很大的作用.
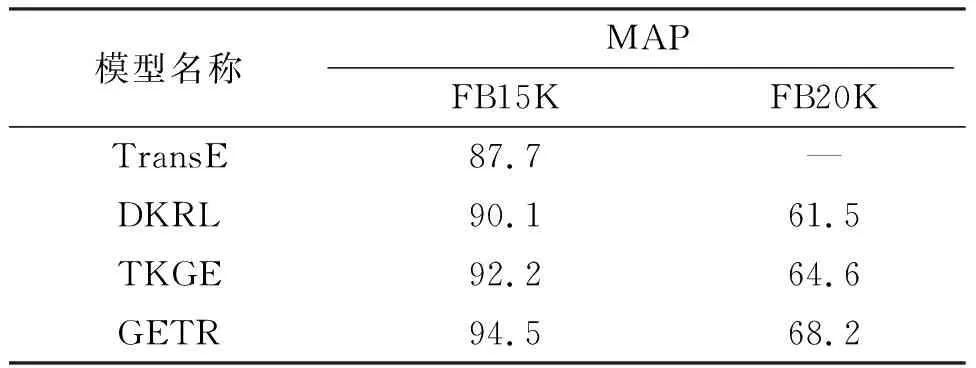
表6 实体分类的评测结果Table 6 The evaluation results of triple classification
无论是在知识补全还是实体分类任务上,本文设计的GETR模型比TransE、DKRL、TKGE模型的表现更优. 训练中,因为需要比基准模型更大的内存空间存储实体向量、词向量、主题向量和模型参数及自身运算复杂性,GETR模型的时间复杂度和空间复杂度更高. 但是,与同样融入路径语义的TKGE模型相比,GETR模型设置的路径随机游走策略可以更快速地寻找到高相关度的路径,降低了模型处理多条路径的复杂性,尤其在大规模的知识图谱知识库上,更能凸显GETR模型的优势.
4 结束语
本文提出的融合文本和路径语义的知识图谱嵌入学习模型(GETR模型),利用了LDA和TWE获取实体描述文本的主题向量和词向量,并用修改过的Bi-LSTM模型封装文本语义;设计了具有选择策略的随机游走算法获取实体间的多步路径;引入Transformer模型获取路径语义信息并融合到TransE模型进行联合训练. 实验表明:在实体预测和实体分类任务评测中,GETR模型比TransE、DKRL、TKGE模型的表现更优.
GETR模型存在2个主要优点:一是融入了文本主题信息使得实体具有更强更准确的表征能力,能有效地应对关系和实体的歧义问题;二是设计的随机游走算法可以快速地获取路径,在大规模的知识图谱中可以降低时间和空间的复杂度. 该模型适用于具有丰富的实体描述文本以及结构信息的知识图谱库,但仍存在一些问题:(1)获取游走的路径相对较短,游走策略只简单利用了结构和文本信息,则会漏掉一些重要的实体和关系信息,甚至会有一些噪声被错误地融入到模型中,这需要寻找一种效率更高的算法或者寻找更多有效的信息(如实体的分类信息);(2)模型的参数较多,训练复杂,难以保证所有参数设置的组合是最合理和最有效的. 下一步的工作将探索更加快捷、可靠的路径游走策略,改进复杂模型,在更大的知识图谱库中验证算法,从而获得能更好地适应不同智能应用系统的知识图谱嵌入表示模型.
