基于孪生网络结构的单样本图例检测方法
2020-12-31王超奇宫法明
王超奇,宫法明
(中国石油大学(华东)计算机科学与技术学院,山东 青岛 266580)
0 引 言
自从ImageNet[1]竞赛中引入卷积神经网络以后,各种使用卷积神经网络的方法就一直占据着目标检测准确率的榜首。其中影响最大且效果好的3种算法分别是:Faster R-CNN[2]、SSD(Single Shot MultiBox Detector)[3]和YOLO[4-5]。R-CNN系列使用RPN(Region Proposal)和ROI(Region of Interest)技术来提高准确率和实时性,而SSD在RPN的基础上提出了多尺度检测框架,提高了小目标的检测率。YOLO系列则实现了端到端(end-to-end)的目标检测,在大幅度提升检测效率的同时也利于网络优化。但在目标检测领域快速发展的同时,还有一些问题仍有待解决,例如特征的有效学习。
对于深度学习而言,学习到高鲁棒性的特征是高准确率的基础。目前,在机器学习应用中,能够学习到有效特征的计算开销是极大的,而且在复杂情况下是非常困难的。一个典型的例子就是单样本学习(one-shot learning)[6],其中必须在只给出每个类的一个样本的情况下,对剩余样本做出正确的预测。施工图图例检测就是一种单样本学习问题,施工图样例如图1所示。
图1 施工图样例
施工图中间部分是图纸区域,右上角是图例区域(不同施工图可能不一样),其他部分包含了无用信息。施工图一般为A3纸大小,分辨率一般为3508×4961或更高。图纸和图例部分分别如图2和图3所示,图例像素一般为25×25左右,在图纸中往往与背景重合较多。图例检测即需要在图纸区域中检测出不同图例的种类和位置。这项工作可以大幅提升相关工作人员的看图速度,同时能够降低漏看、误看的概率,提高工作效率,具有重要的理论研究和应用价值。
图2 部分图纸区域
图3 图例区域
图例检测具有其特殊性,包括施工图(输入图像)分辨率较大、图例(检测目标)较小、图例的尺度不变性和个体独立性(不同类别图例间差距巨大)等特点。结合单样本学习的特性,本文使用结构简单且易于优化的SSD目标检测框架,在此基础上进行按需调整,提出一种新的SiameseSSD检测框架以解决训练集过少、小目标难以检测以及大图像输入等问题。
本文的主要贡献是通过微调SSD框架,在此基础上加入孪生网络结构,提出SiameseSSD检测框架,利用大图像裁剪与单样本数据增强等方法解决以上几个问题。在图例检测任务上达到了91.3%(IOU=0.5,CONF=0.8)的准确率,较其他目标检测算法有一定优势,基本可以满足实际工作的需求。
1 相关工作
1.1 单样本学习
深度学习方法已经被证明是高效的机器学习方法,但是,深度学习往往都需要大量的标注数据集来训练模型,当样本每个类都只包含少量样本的情况下,深度学习方法就难以发挥作用。针对单样本学习问题,Chopra等人[7]提出了将输入映射成特征向量,使用2个特征向量来表达不同图像间的相似度。Koch等人[8]通过学习图像对之间的相似性,把单样本分类任务转化为图像验证任务,同时也证明了成对训练的有效数据集的大小足以用于训练模型。Vinyals[6]等人通过训练一个完整的近邻分类器,而不是学习相似度函数,来解决单样本学习任务,提供了一种单样本学习任务的新思路。
Santoro等人[9]解释了单样本学习和元学习的关系,揭示了单样本学习的实质。Bertinetto等人[10]和Li等人[11]通过孪生网络结构提取一对图像的特征,并使用互相关(cross-correlation)操作输出响应图,描述图像对之间的相似性,在目标跟踪任务上达到非常高的实时性。最近Zhang等人[12]引入贝叶斯条件概率理论,并使用孪生网络结构有效地解决了单样本目标检测问题,验证了孪生网络结构对单样本目标检测的有效性。鉴于以上研究,笔者认为把图像对进行互相关操作得到的响应图,作为一种特征图直接进行分类和边框回归是高效且可行的。同时,图像配对训练也可以有效地解决每一类样本过少的问题。
1.2 小目标检测
图例相对于图像来说显得过小,主流的目标检测方法几乎都通过不断的下采样来进行多尺度检测。相对地,在高层特征图上,感兴趣的目标可能就只有几像素。以YOLO为例,最终的预测网格只有13×13大小,相对于原图像(416×416)缩小了32倍,这意味着,如果对象很小,那么对于一个检测网格的影响可能非常小,难以检测。对于这个问题,Redmon等人[5]使用聚类调整了锚点框的位置,使目标定位更准确。Zhang等人[13]使用更低的特征图做检测,效果显著。Lin等人[14]提出的特征金字塔网络(Feature Pyramid Networks, FPN)通过上采样融合高层和低层特征图的信息,达到了目标检测的先进水平。但由于图例的结构简单(语义信息不足)、个体独立性(不同类图例差异巨大)和图像配对算法的限制,使得其难以训练。而SSD由于其结构简单,具有很大的改进空间,故本文尝试改进SSD并增大响应图来增强对小目标的检测效果。
1.3 大分辨率图像
由于大部分卷积神经网络结构具有固定性,在图片不符合其输入图像大小时,往往需要进行大小调整(resize)来适应网络结构,这种情况在LeNet[15]网络上就是如此。在Darknet[16]中,训练时会对短边进行填充从而保证长宽比,这虽然是一种解决方法,但这些都会带来问题,例如减少图像语义信息、降低对小目标的检测效果以及增加测试难度等。Van Etten等人[17]提出对大图像的分块裁剪算法,通过拼接结果并使用非极大值抑制(Non-Maximum Suppression, NMS)处理结果,这是一种不降低检测准确率前提下的大分辨率图像目标检测方法。
2 SiameseSSD检测框架
本章将介绍所提出的SiameseSSD检测框架,如图4所示。左侧是孪生网络结构的特征提取网络。右侧则是SSD框架的改良,对于一张特征图同时进行分类和边框回归。通过孪生网络提取特征向量后,使用相关操作(☆位置)得到响应图,同时作为SSD的输入。在SSD中,对于特征图上每一个网格,对应4个锚点框(anchor)和4×(k+4)个卷积核,4k个用于分类,4×4个用于边框回归。具体而言,改良SSD完成了分类和边框回归的工作;将图像输入到孪生网络的入口,通过整个SiameseSSD框架进行端到端的训练和检测。
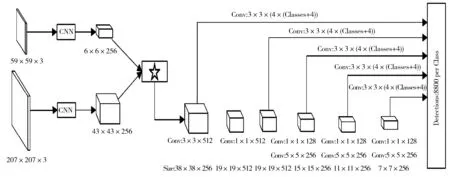
图4 SiameseSSD框架
2.1 孪生特征提取网络
在孪生网络中,本文采用不填充的全卷积网络。令Lτ表示翻译操作符(Lτx)[u]=x[u-τ],对于任意平移τ与整数步长k,如果满足公式(1):
h(Lkτx)=Lτh(x)
(1)
那么信号映射函数h是全卷积的。在图4中,59×59大小的输入图为模板图,而207×207大小的输入为检测图。设学习函数f(z,x),即将模板图z与检测图上相同大小的候选图像x进行比较,相同则返回高分。测试所有可能位置,并选择与目标之前外观具有最大程度相似的候选块x,从而学习训练函数f。更进一步,将深度卷积网络作为函数f。孪生网络对输入x、z用变换φ,定义:
f(z,x)=g(φ(z),φ(x))
(2)
用函数g组合输入表示,函数g即相关操作,用卷积[10-11]来实现。函数φ的结构如表1所示,表1是图4中CNN的结构信息,对2个输入进行相应处理。类似于Krizhevsky等人[18]的网络的卷积阶段。在每个卷积层后面(除了Conv5)都包含线性修正单元(Rectified Linear Unit, ReLU)模块。卷积时不引入填充,因为会违反图像的全卷积性。训练时在线性层加入BN(Batch Normalization)[19]。深度孪生卷积网络先前已应用于面部验证[20-21],关键点描述学习[22]和一次性字符识别[8]等任务,是使用孪生特征提取网络的基础。
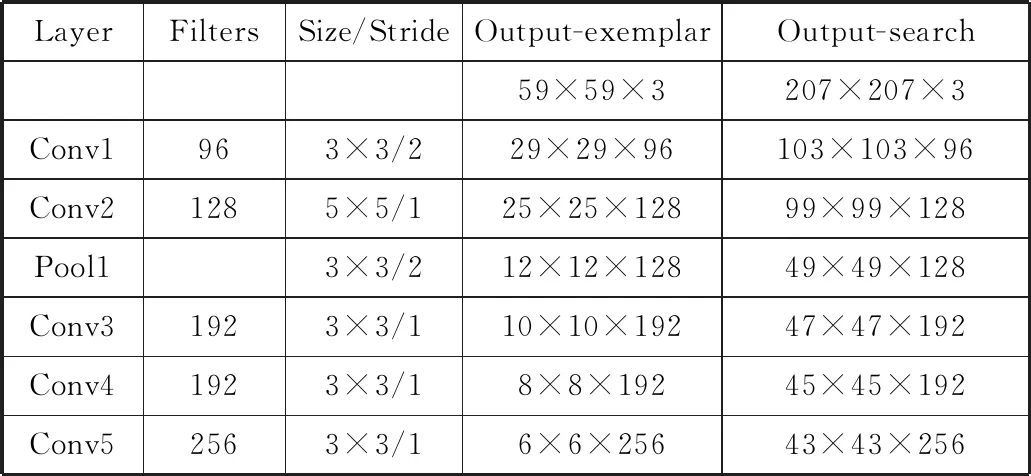
表1 卷积嵌入函数φ的体系结构(图4中的CNN)
2.2 SSD目标检测网络
SSD目标检测网络与SSD的结构大体相同。其中,输入图像38×38×256是孪生特征提取网络的输出。如图4所示,对于任意特征图的每个网格都会对应4×(k+4)个卷积核,k为图例的种类数量。配对图像从孪生网络进入,生成响应图后输入SSD,最后在SSD里完成图例检测。由于没有复杂的残差结构和多尺度特征融合,可以方便地进行端到端的训练和检测。检测与训练不同的是,模板图在前向传播一次以后即可驻存在内存中,与不同的检测图直接进行互相关操作即可。
相对于原始的SSD,本文做出许多微调。首先,Luo等人[23]的工作验证了图像感受野和下采样之间的关系,即有效感受野极大地影响不同尺度的目标的检出率。因此,本文认为当有效感受野能正好覆盖目标真实框时,可以有效提高小目标的检出率。因此,本文调整了特征图大小,即使是最高层的7×7特征图,有效感受野上仍然可以覆盖图例。本文舍弃了原SSD的高层特征图,使用5个低层的特征图来提高图例的检出率。
锚点框的形状和大小也是有效感受野的影响因素之一。对于不同层次的特征图,接受域也不一样[24]。通过分析图例的长宽比以及在特征图上的占比,本文调整了SSD的锚点框尺寸(scale)为:
(3)
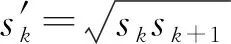
(4)
置信度损失(confidence loss)为Softmax损失,位置损失(localization loss)为Smooth L1 loss,并保留超参数α(实际设定为1)均衡2种损失。
2.3 训练阶段:端到端训练SiameseSSD
在训练阶段,本文从施工图数据集中取出相对应的一对样本对(来自同一张背景图片)。本文设定标注框IOU大于0.5的锚点框为正样本,小于的为负样本。由于图例结构简单(语义信息少)且具有个体独立性(不同类图例差异较大),特征学习速度可能会呈现先快后慢的情况,本文使用Adam[25]在不确定最佳初始学习率的情况下对SiameseSSD进行端到端的训练。同时,由于图片配对训练的机制会导致难易样本不均衡(easy sample overwhelming)的问题,本文使用RetinaNet[26]中提出的Focal loss,添加于Softmax损失前,有效地解决了不同种类图例的学习问题。
3 训练数据
本文的数据集采集于海洋采油厂的施工图中。为了解决样本过少的问题,本文采用了特殊的样本数据增强方法。如图5和图6所示。
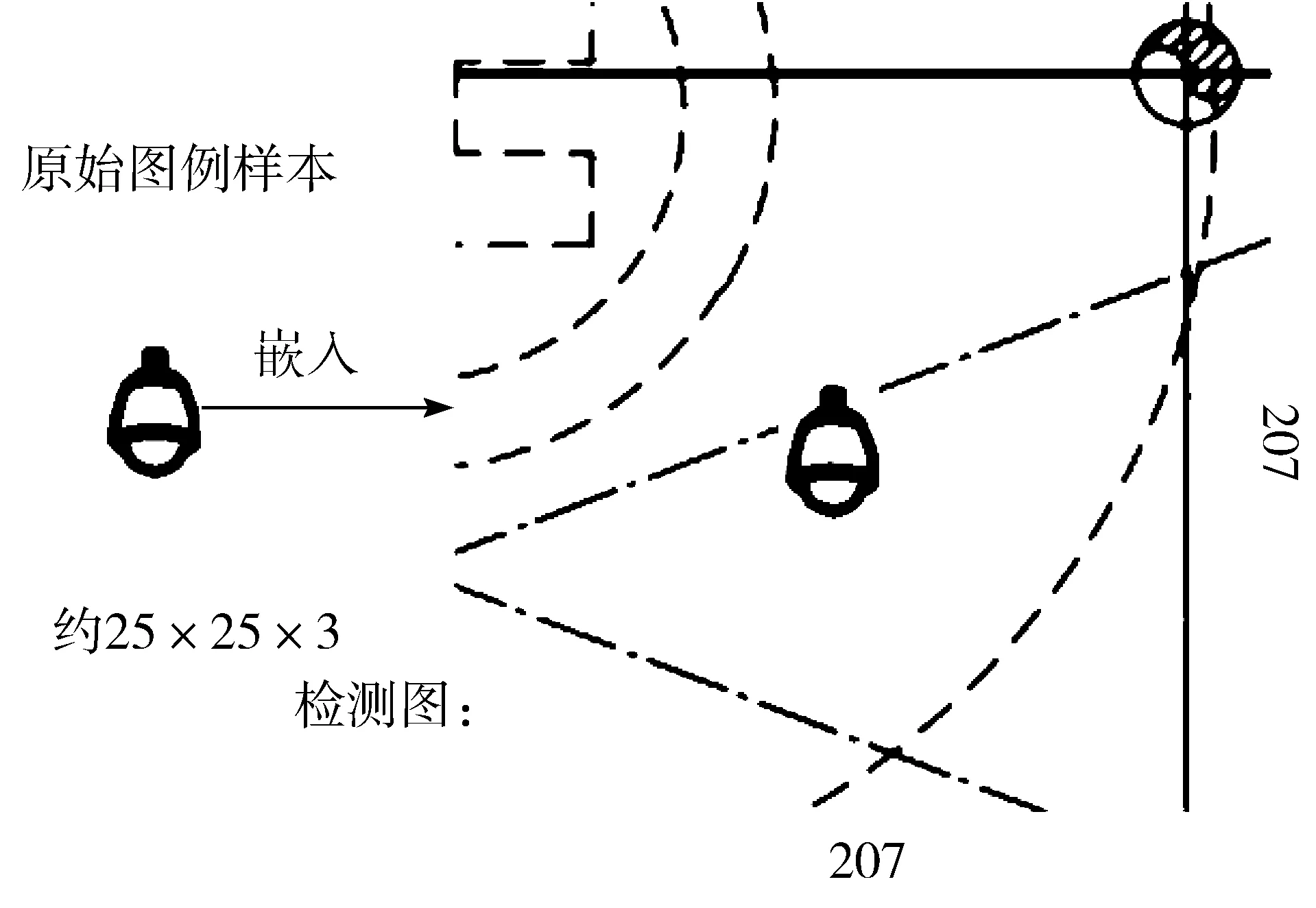
图5 通过图片嵌入获得检测图
本文采集了2份数据,一份是原始图例数据,即从图例区域通过标注获得的数据。另一份是背景图,本文从施工图的图纸区域中裁剪出207×207大小的背景图片,把图例样本嵌入到背景中心来获得检测图。要注意的是,嵌入的背景图不包含所嵌入的图例,避免错误标注的样本。同样地,通过裁剪检测图中心59×59的区域,就可以轻松获得模板图,这样就获得了一对样本对,如图6所示。
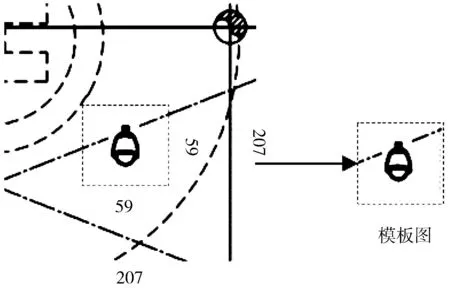
图6 通过图片裁剪获得模板图
同时,单样本数据增强是提高样本质量的有效手段。本文使用放大和缩小(通过随机裁剪)[3]、随机旋转等操作,成功地把数据集扩大了5~6倍。通过标注,本文一共获得样本对11780对,共37种图例,来自21张施工图。
4 测试数据
在数据增强之后,直接在数据集里选取一部分作为测试数据是不合适的,因为测试图像只来自于图纸的一部分,无法完全代表整个测试数据。同时,施工图还包含了很多无用信息,会使检测难度上升。本文借鉴Van Etten等人[17]使用的裁剪(crop)后拼接的方法来处理大分辨率的施工图图像,直接对标注后的施工图进行测试。大分辨率图像裁剪的结果如图7所示,实线框与虚线框的交界处即为重叠部分。
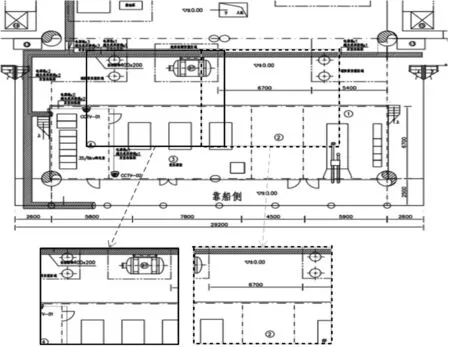
图7 大分辨率图像裁剪
设定重叠为15%,每次都裁剪207×207大小的测试图,在测试后合并同一施工图的结果,并使用NMS来去除那些重叠的检测框。施工图会预先进行离线标注,方便测试。模板图使用原始样本,嵌入59×59的空白背景中,使其分辨率与训练时一致。最终本文标注了测试样本共115个,共生成测试图3256张,共11种图例,来自6张训练过训练数据的施工图,最多产生11×3256种图像配对。
5 实验结果和分析
本文实验环境为:Intel Core i7-9750H @ 2.60 GHz ,16 GB DDR4 2666 MHz内存, Nvidia GeForce GTX 1660 Ti 6GB, Ubuntu-kylin 16.04,64位操作系统,Pytorch框架。由于孪生网络本身建立于单目标的配对比较上,在多目标任务上顺序执行检测会极大地影响检测速度。所以本文利用模型本身的可并行性,并行执行多目标检测任务,使多个种类的图例可以同时检测,最后统一检测结果。在该实验环境下,SiameseSSD检测器的检测速度达到61帧/s(fps)。由于图例检测的最终目的是为了在静态的施工图上检测出所有图例,以此满足看图、施工相关人员的需求,只要响应速度满足人的感受阈值即可。对于施工图而言,一张施工图在检测时一般裁剪出550张左右的检测图,以本文实验环境约需9 s,尚可满足看图者的需求,所以一般满足实际工作要求。最后,可以通过更新实验环境、增大裁剪大小并缩小检测图、减少检测范围等方法满足更严苛的速度要求。
5.1 施工图数据集结果
为了合理评价SiameseSSD在施工图数据集上的表现,本文挑选了Adaboost+Haar、YOLO、Faster R-CNN。它们分别是传统目标检测方法、深度学习下的单阶段(one-stage)目标检测方法和双阶段(two-stage)目标检测方法的代表性方法。由于结构上的不同,训练方法也不同。Adaboost中每类100张正样本、30张负样本。正样本为图例直接嵌入背景,负样本只存在背景(不包含图例)。YOLO和RCNN中每类100张样本,通过图例嵌入背景并进行旋转、缩放等操作制作样本。测试集与SiameseSSD的测试图一致。结果如表2所示。
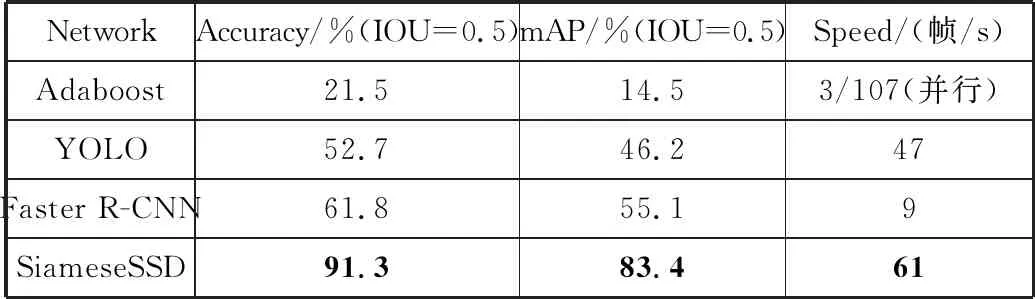
表2 施工图数据集各检测算法结果
由于Adaboost是个单目标分类器,检测多目标时多个分类器串联导致检测速度极慢。但由于其特征计算简单、参数较少,并行执行时获得了最快的检测速度。另一方面,其对无关区域的鲁棒性较差,导致准确率极低。YOLO和Faster R-CNN的准确率较低,可能是因为训练样本过少,无法获得有效训练。SiameseSSD相比于准确率第二的Faster R-CNN,在准确率上高出29.5个百分点。同时,比第二快的YOLO快了14帧/s。笔者认为,由于图例间不存在重叠现象(否则使用NMS会影响准确率),且一般都相隔一定距离,所以SiameseSSD对于图例的检测效果才会这么好。同时,相比于YOLO,本文使用207×207的输入图,并且在孪生特征提取网络里只做了少量简单运算,所以在检测速度上也会有优势。
5.2 验证SSD结构变化对于小目标检测的有效性
为了验证SSD的改变对于小目标检测的影响,本文设置对照试验,通过控制变量来检验结构改变对于性能的影响。对于所有的实验,本文都使用相同的输入,确保对照实验的有效性。
本文通过控制特征图每个网格的锚点框数量和改变锚点框的尺寸变化,通过同样的训练集和测试集,额外训练了2个模型,最终得到表3的结果。笔者认为,对于包含3和1/3锚点框的情况,由于锚点框的增多,对于目标的检测次数必然会增多,同时增多的卷积核也会增强特征学习能力,所以准确率略有提升。但检测速度的大幅下降,使得网络面对大分辨率施工图时不那么友好。而较小的锚点框尺寸变化幅度加强了整体对小目标的检测能力,但对检测速度并无影响,只在一定程度上影响目标定位的准确度(即平均IOU)。
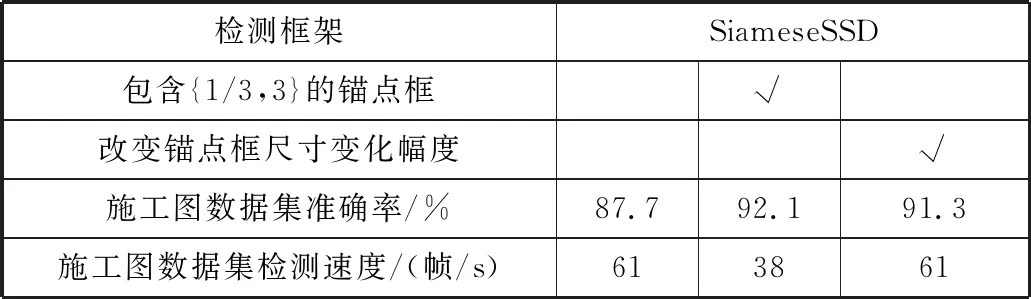
表3 锚点框对SiameseSSD性能的影响
相对而言,特征图大小的变化对于SiameseSSD性能的影响难以衡量,因为变量太多,排列组合下会产生很多种可能性,影响判断。如表4所示,本文通过改变最后一个卷积层的大小和步长来调整最后一层特征图的大小,之后通过一样的步骤进行训练和测试。通过控制变量,笔者发现准确率随特征图网格数变少有明显的下降趋势,但又存在一个下降缓慢的点(5×5)。通过分析,笔者认为有一部分的图例样本的特征学习正好在5×5特征图附近,使得其稍显异常。而8×8和6×6特征图对应的模型准确率与7×7都极为接近,说明该特征图大小分布极有可能尚未达到最优,微调任意层特征图的大小都有可能提高准确率。通过互补搜索技术组合[27]应该可以优化该网络。

表4 特征图大小对SiameseSSD性能的影响
表3和表4的结果在一定程度上验证了对SSD的适当改变可以有效提高准确率和检测速度。同时,也可以通过设置一些参数来控制准确率和检测速度的平衡,以适应不同场景下的不同实际需求。
6 结束语
本文提出将孪生网络结构与SSD目标检测框架结合用于图例检测,并结合图例本身的特点,调整了孪生特征提取子网和SSD子网的网络结构,构建SiameseSSD目标检测框架。通过在施工图数据集上的实验表明,该检测方法在单样本情况下的单目标检测任务上有非常优异的性能。但是,该检测方法受限于孪生网络结构的配对输入,一次前向传播只能检测一种目标,在资源受限的情况下检测速度不佳。为了提高检测速度,针对多目标检测进行结构调整,这是孪生网络结构应用于单样本多目标检测的关键,也是笔者下一步研究的重点。
